
Wearable Sensor-Based Human Activity Recognition with Transformer Model


Abstract
:
1. Introduction
2. Methods
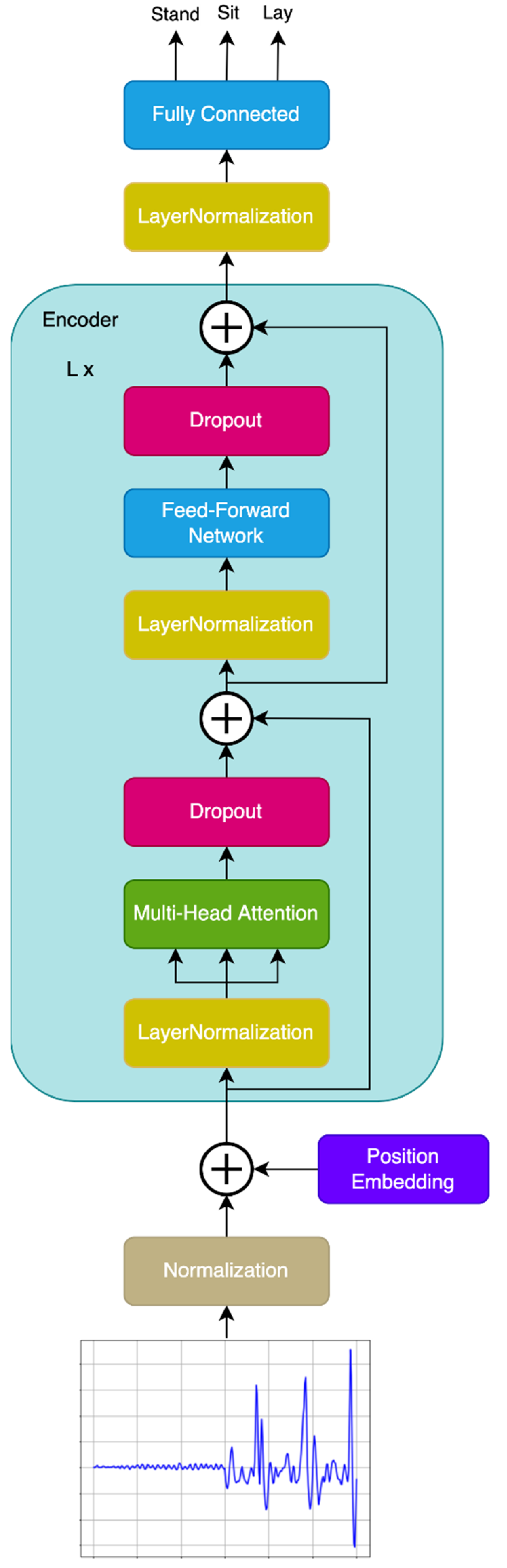
2.1. Transformer Model
2.2. Vision Transformer Model
2.3. KU-HAR Dataset
2.4. Transformer Model for Human Activity Recognition
2.5. Data Augmentation
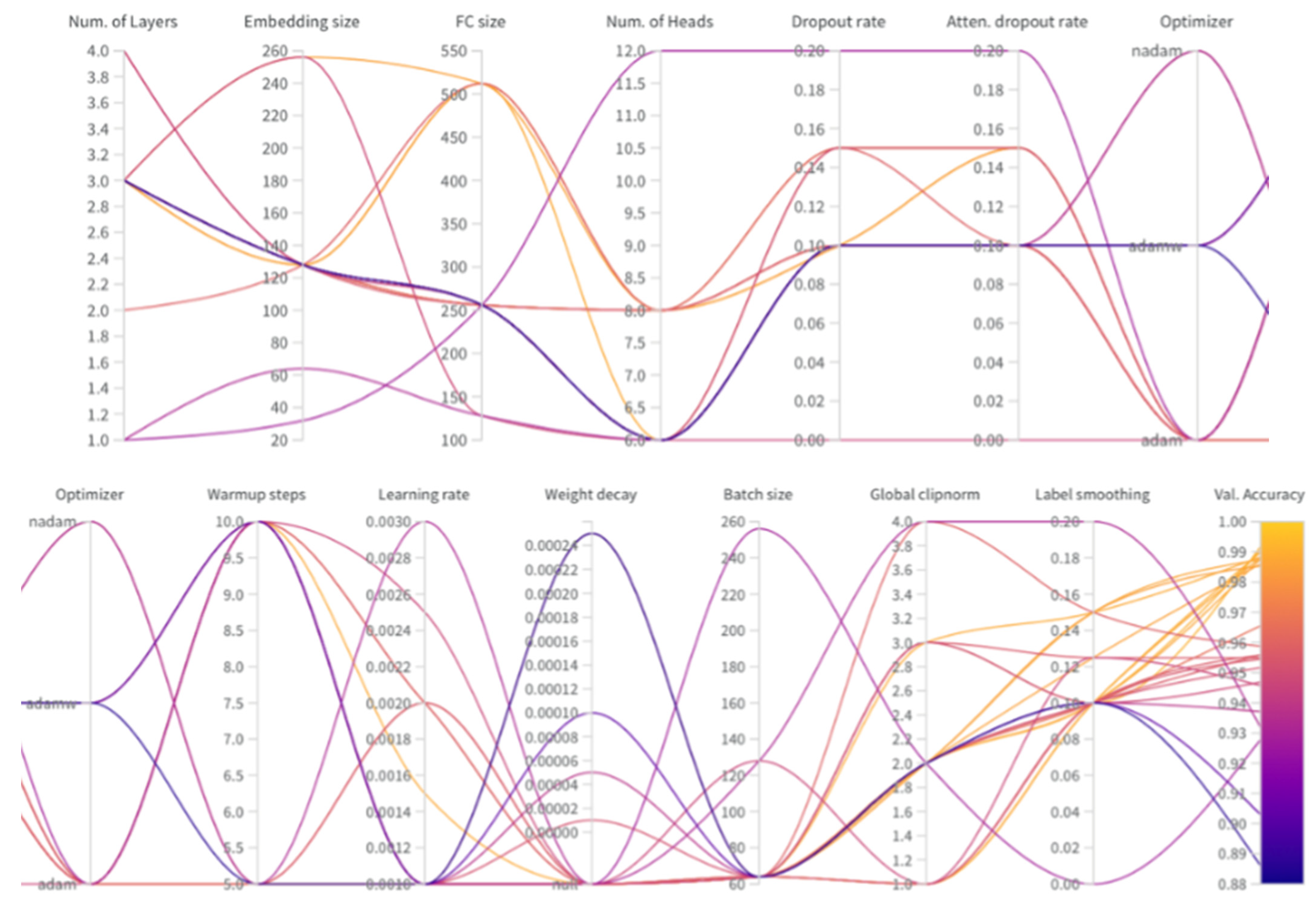
2.6. Finding Optimal Hyperparameters
3. Results
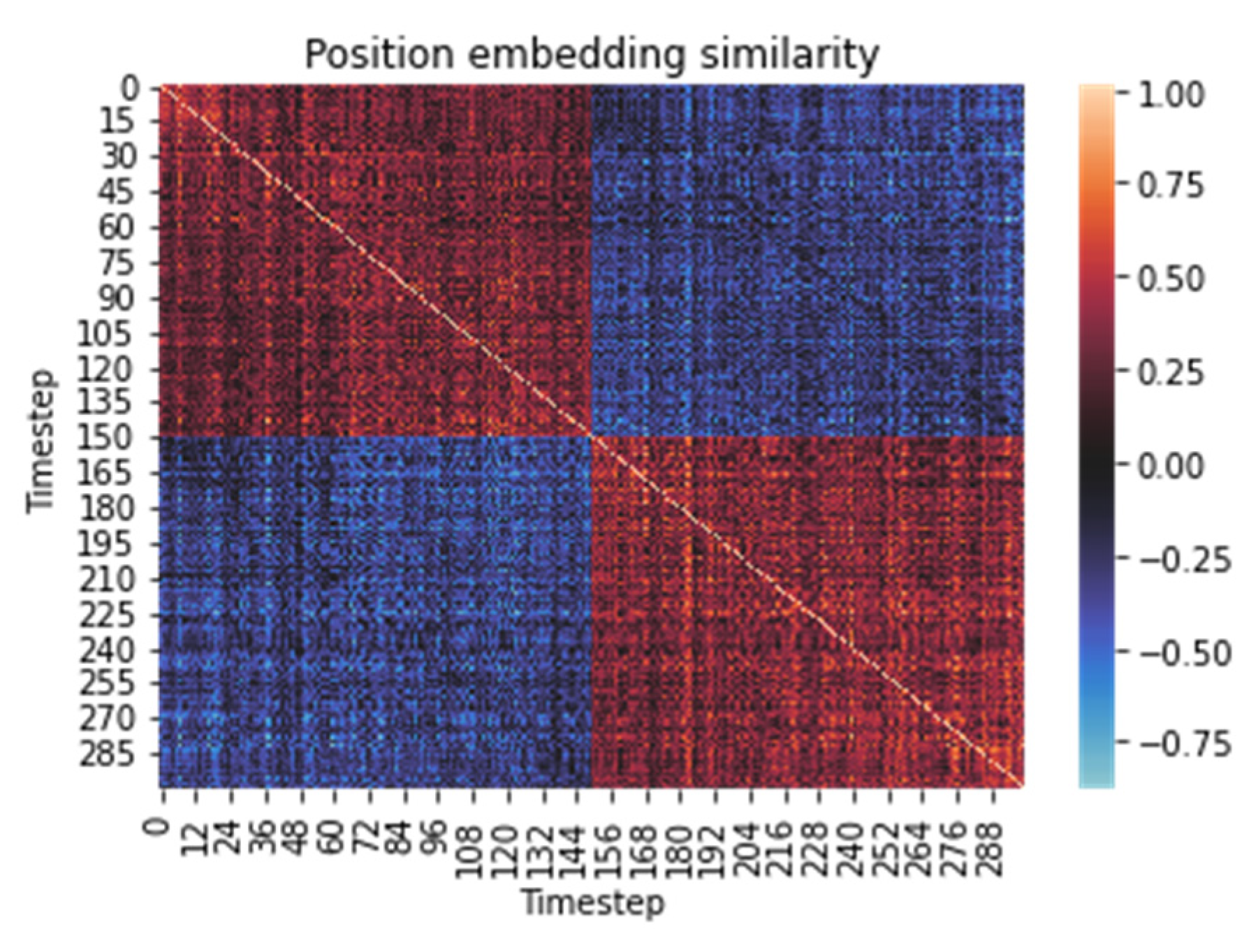
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. A review of multimodal human activity recognition with special emphasis on classification, applications, challenges and future directions. Knowl.-Based Syst. 2021, 223, 106970. [Google Scholar] [CrossRef]
- Ensastiga, S.A.L.; Rodríguez-Reséndiz, J.; Estévez-Bén, A.A. Speed controller-based fuzzy logic for a biosignal-feedbacked cycloergometer. Comput. Methods Biomech. Biomed. Eng. 2021, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Sánchez-Reyes, L.M.; Rodríguez-Reséndiz, J.; Avecilla-Ramírez, G.N.; García-Gomar, M.L.; Robles-Ocampo, J.B. Impact of eeg parameters detecting dementia diseases: A systematic review. IEEE Access 2021, 9, 78060–78074. [Google Scholar] [CrossRef]
- Sanchez-Reyes, L.M.; Rodriguez-Resendiz, J.; Salazar-Colores, S.; Avecilla-Ramírez, G.N.; Pérez-Soto, G.I. A High-accuracy mathematical morphology and multilayer perceptron-based approach for melanoma detection. Appl. Sci. 2020, 10, 1098. [Google Scholar] [CrossRef] [Green Version]
- González, A.K.; Bolivar, S.G.; Rodríguez-Reséndiz, J. Implementation of a Socket for Hip Disarticulation based on Ergonomic Analysis. In Proceedings of the 2018 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES), Sarawak, Malaysia, 3–6 December 2018; pp. 341–345. [Google Scholar] [CrossRef]
- Trifan, A.; Oliveira, M.; Oliveira, J.L. Passive sensing of health outcomes through smartphones: Systematic review of current solutions and possible limitations. JMIR mHealth uHealth 2019, 7, e12649. [Google Scholar] [CrossRef]
- Lorenzi, P.; Rao, R.; Romano, G.; Kita, A.; Irrera, F. Mobile devices for the real-time detection of specific human motion disorders. IEEE Sens. J. 2016, 16, 8220–8227. [Google Scholar] [CrossRef]
- Pardoel, S.; Kofman, J.; Nantel, J.; Lemaire, E.D. Wearable-sensor-based detection and prediction of freezing of gait in Parkinson’s disease: A review. Sensors 2019, 19, 5141. [Google Scholar] [CrossRef] [Green Version]
- Juen, J.; Cheng, Q.; Schatz, B. A natural walking monitor for pulmonary patients using mobile phones. IEEE J. Biomed. Health Inform. 2015, 19, 1399–1405. [Google Scholar] [CrossRef]
- Spanogianopoulos, S.; Sirlantzis, K.; Mentzelopoulos, M.; Protopsaltis, A. Human computer interaction using gestures for mobile devices and serious games: A review. In Proceedings of the 2014 International Conference on Interactive Mobile Communication Technologies and Learning (IMCL2014), Thessaloniki, Greece, 13–14 November 2014; IEEE: New York, NY, USA, 2014; pp. 310–314. [Google Scholar] [CrossRef]
- Anagnostis, A.; Benos, L.; Tsaopoulos, D.; Tagarakis, A.; Tsolakis, N.; Bochtis, D. Human activity recognition through recurrent neural networks for human–robot interaction in agriculture. Appl. Sci. 2021, 11, 2188. [Google Scholar] [CrossRef]
- Anderez, D.O.; Dos Santos, L.P.; Lotfi, A.; Yahaya, S.W. Accelerometer-based hand gesture recognition for human-robot interaction. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; IEEE: New York, NY, USA, 2019; pp. 1402–1406. [Google Scholar] [CrossRef]
- Taylor, K.; Abdulla, U.A.; Helmer, R.J.; Lee, J.; Blanchonette, I. Activity classification with smart phones for sports activities. Procedia Eng. 2011, 13, 428–433. [Google Scholar] [CrossRef] [Green Version]
- Koh, B.H.D.; Lim, C.L.P.; Rahimi, H.; Woo, W.L.; Gao, B. Deep temporal convolution network for time series classification. Sensors 2021, 21, 603. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.L.; Hsaio, W.H.; Tu, Y.C. Time series classification with multivariate convolutional neural network. IEEE Trans. Ind. Electron. 2018, 66, 4788–4797. [Google Scholar] [CrossRef]
- Alemayoh, T.T.; Lee, J.H.; Okamoto, S. New sensor data structuring for deeper feature extraction in human activity recognition. Sensors 2021, 21, 2814. [Google Scholar] [CrossRef]
- Rosafalco, L.; Manzoni, A.; Mariani, S.; Corigliano, A. Fully convolutional networks for structural health monitoring through multivariate time series classification. Adv. Model. Simul. Eng. Sci. 2020, 7, 38. [Google Scholar] [CrossRef]
- Jiang, G.; He, H.; Yan, J.; Xie, P. Multiscale convolutional neural networks for fault diagnosis of wind turbine gearbox. IEEE Trans. Ind. Electron. 2018, 66, 3196–3207. [Google Scholar] [CrossRef]
- Gupta, R.; Rajan, S. Comparative analysis of convolution neural network models for continuous indian sign language classification. Procedia Comput. Sci. 2020, 171, 1542–1550. [Google Scholar] [CrossRef]
- Gu, F.; Khoshelham, K.; Valaee, S.; Shang, J.; Zhang, R. Locomotion activity recognition using stacked denoising autoencoders. IEEE Internet Things J. 2018, 5, 2085–2093. [Google Scholar] [CrossRef]
- Tamilselvan, P.; Wang, P. Failure diagnosis using deep belief learning based health state classification. Reliab. Eng. Syst. Saf. 2013, 115, 124–135. [Google Scholar] [CrossRef]
- Zebin, T.; Sperrin, M.; Peek, N.; Casson, A.J. Human activity recognition from inertial sensor time-series using batch normalized deep LSTM recurrent networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; IEEE: New York, NY, USA, 2018; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Tanisaro, P.; Heidemann, G. Time series classification using time warping invariant echo state networks. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; IEEE: New York, NY, USA, 2016; pp. 831–836. [Google Scholar] [CrossRef]
- Ronald, M.; Poulose, A.; Han, D.S. iSPLInception: An inception-ResNet deep learning architecture for human activity recognition. IEEE Access 2021, 9, 68985–69001. [Google Scholar] [CrossRef]
- Qin, Z.; Zhang, Y.; Meng, S.; Qin, Z.; Choo, K.K.R. Imaging and fusing time series for wearable sensor-based human activity recognition. Inf. Fusion 2020, 53, 80–87. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, J.; Li, J.; Tian, L.; Tu, P.; Cao, T.; An, Y.; Wang, K.; Li, S. Wearable sensor-based human activity recognition using hybrid deep learning techniques. Secur. Commun. Netw. 2020, 2020, 2132138. [Google Scholar] [CrossRef]
- Gao, W.; Zhang, L.; Huang, W.; Min, F.; He, J.; Song, A. Deep Neural Networks for Sensor-Based Human Activity Recognition Using Selective Kernel Convolution. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- TensorFlow: Time Series Forecasting. Available online: https://www.tensorflow.org/tutorials/structured_data/time_series (accessed on 25 January 2022).
- Li, Y.; Wang, L. Human Activity Recognition Based on Residual Network and BiLSTM. Sensors 2022, 22, 635. [Google Scholar] [CrossRef]
- Brownlee, J. How to Develop a Bidirectional LSTM For Sequence Classification in Python with Keras. Available online: https://machinelearningmastery.com/develop-bidirectional-lstm-sequence-classification-python-keras/ (accessed on 25 January 2022).
- Gupta, S. Deep learning based human activity recognition (HAR) using wearable sensor data. Int. J. Inf. Manag. Data Insights 2021, 1, 100046. [Google Scholar] [CrossRef]
- Gholamiangonabadi, D.; Kiselov, N.; Grolinger, K. Deep neural networks for human activity recognition with wearable sensors: Leave-one-subject-out cross-validation for model selection. IEEE Access 2020, 8, 133982–133994. [Google Scholar] [CrossRef]
- Sikder, N.; Nahid, A.A. KU-HAR: An open dataset for heterogeneous human activity recognition. Pattern Recognit. Lett. 2021, 146, 46–54. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- MATLAB Sequence-to-Sequence Classification Using Deep Learning. Available online: https://www.mathworks.com/help/deeplearning/ug/sequence-to-sequence-classification-using-deep-learning.html (accessed on 25 January 2022).
- Banos, O.; Garcia, R.; Holgado-Terriza, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A novel framework for agile development of mobile health applications. In International Workshop on Ambient Assisted Living; Springer: Cham, Switzerland, 2014; pp. 91–98. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; IEEE: New York, NY, USA, 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and smartwatch-based biometrics using activities of daily living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-aware human activity recognition using smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef] [Green Version]
- Doherty, A.; Jackson, D.; Hammerla, N.; Plötz, T.; Olivier, P.; Granat, M.H.; White, T.; van Hees, V.T.; Trenell, M.I.; Owen, C.G.; et al. Large scale population assessment of physical activity using wrist worn accelerometers: The UK biobank study. PLoS ONE 2017, 12, e0169649. [Google Scholar] [CrossRef]
- Ortiz-Echeverri, C.J.; Salazar-Colores, S.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A. A new approach for motor imagery classification based on sorted blind source separation, continuous wavelet transform, and convolutional neural network. Sensors 2019, 19, 4541. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.U.; Kim, J.W. Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and attention mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- TensorFlow. Available online: https://www.tensorflow.org (accessed on 25 January 2022).
- MATLAB Decrease Sample Rate by Integer Factor. Available online: https://www.mathworks.com/help/signal/ref/downsample.html (accessed on 25 January 2022).
- Atito, S.; Awais, M.; Kittler, J. Sit: Self-supervised vision transformer. arXiv 2021, arXiv:2104.03602. [Google Scholar]
- Brownlee, J. Random Oversampling and Undersampling for Imbalanced Classification. Machine Learning Mastery. 2020. Available online: https://machinelearningmastery.com/random-oversampling-and-undersampling-for-imbalanced-classification/ (accessed on 3 February 2022).
- NumPy. Available online: https://numpy.org (accessed on 3 February 2022).
- Pandas. Available online: https://pandas.pydata.org (accessed on 3 February 2022).
- Scikit-Learn. Available online: https://scikit-learn.org/ (accessed on 3 February 2022).
- WanDB: Hyperparameter Tuning. Available online: https://docs.wandb.ai/guides/sweeps (accessed on 3 February 2022).
- Shi, H.; Gao, S.; Tian, Y.; Chen, X.; Zhao, J. Learning Bounded Context-Free-Grammar via LSTM and the Transformer: Difference and Explanations. arXiv 2021, arXiv:2112.09174. [Google Scholar]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Standard Dataset | Paper | Data Structure | Method | Accuracy |
|---|---|---|---|---|
| KU-HAR [33] | This study | Standardization | HAR transformer | 99.2 |
| Sikder et al. [33] | fast Fourier transform | Random forest | 89.67 | |
| MHEALTH [36] | Qin et al. [25] | Gramian angular fields | GAF and ResNet | 98.5 |
| PAMAP2 [37] | Li et al. [29] | Standardization | 2D Conv + BiLSTM | 97.15 |
| Gao et al. [27] | Standardization | Conv + SKConv | 93.03 | |
| WISDM [38] | Alemayoh et al. [16] | Segmentation into a grayscale image that represents the time serie of signal | SC-CNN | 97.08 |
| Gupta [29] | RAW | CNN-GRU | 96.54 | |
| Alemayoh et al. [16] | Heuristic features | J48 decision tree | 90.04 | |
| HAPT [39] | Wang et al. [26] | Splice into two-dimensional matrix (like a picture) | CNN-LSTM | 95.87 |
| UK Bio-bank [40] | Zebin et al. [22] | RAW | LSTM + BN | 92 |
| Class Name | ID | Performed Activity | Duration Repetitions | No. Subsamples |
|---|---|---|---|---|
| Stand | 0 | Standing still on the floor | 1 min | 1886 |
| Sit | 1 | Sitting still on a chair | 1 min | 1874 |
| Talk-sit | 2 | Talking with hand movements while sitting on a chair | 1 min | 1797 |
| Talk-stand | 3 | Talking with hand movements while standing up or sometimes walking around within a small area | 1 min | 1866 |
| Stand-sit | 4 | Repeatedly standing up and sitting down (transition activity) | 5 times | 2178 |
| Lay | 5 | Laying still on a plain surface (a table) | 1 min | 1813 |
| Lay-stand | 6 | Repeatedly standing up and laying down (transition activity) | 5 times | 1762 |
| Pick | 7 | Picking up an object from the floor by bending down | 10 times | 1333 |
| Jump | 8 | Jumping repeatedly on a spot | 10 times | 666 |
| Push-up | 9 | Performing full push-ups with a wide-hand position | 5 times | 480 |
| Sit-up | 10 | Performing sit-ups with straight legs on a plain surface | 5 times | 1005 |
| Walk | 11 | Walking 20 m at a normal pace | ~12 s | 882 |
| Walk-backward | 12 | Walking backwards for 20 m at a normal pace | ~20 s | 317 |
| Walk-circle | 13 | Walking at a normal pace along a circular path | ~20 s | 259 |
| Run | 14 | Running 20 m at a high speed | ~7 s | 595 |
| Stair-up | 15 | Ascending on a set of stairs at a normal pace | ~1 min | 798 |
| Stair-down | 16 | Descending from a set of stairs at a normal pace | ~50 s | 781 |
| Table-tennis | 17 | Playing table tennis | 1 min | 458 |
| Total | 20,750 | |||
| Stand + Talk-Stand | Sit + Talk-Sit | Talk-Stand + Stand | Pick + Stand | Jump + Stand | Walk + Stand | Walk-Backward + Stand | Walk-Circle + Stand | Run + Stand | Stair-up + Stand | Stair-down + Stand | Table-Tennis + Stand |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Stand + Pick | Talk-sit + sit | Talk-Stand + Pick | Pick + Talk-Stand | Jump + Talk-Stand | Walk + Talk-Stand | Walk-backward + Talk-Stand | Walk-circle + Talk-Stand | Run + Talk-Stand | Stair-up + Talk-Stand | Stair-down + Talk-Stand | Table-tennis + Talk-Stand |
| Stand + Jump | Lay + Sit-up | Talk-Stand + Jump | Pick + Jump | Jump + Pick | Walk + Pick | Walk-backward + Pick | Walk-circle + Pick | Run + Pick | Stair-up + Pick | Stair-down + Pick | Table-tennis + Pick |
| Stand + Walk | Sit-up + Lay | Talk-Stand + Walk | Pick + Walk | Jump + Walk | Walk + Jump | Walk-backward + Jump | Walk-circle + Jump | Run + Jump | Stair-up + Jump | Stair-down + Jump | Table-tennis + Jump |
| Stand + Walk-backward | Talk-Stand + Walk-backward | Pick + Walk-backward | Jump + Walk-backward | Walk + Walk-circle | Walk-backward + Table-tennis | Walk-circle + Walk | Run + Walk | Stair-up + Walk | Stair-down + Walk | Table-tennis + Walk | |
| Stand + Walk-circle | Talk-Stand + Walk-circle | Pick + Walk-circle | Jump + Walk-circle | Walk + Run | Walk-circle + Run | Run + Walk-circle | Stair-up + Walk-circle | Stair-down + Walk-circle | Table-tennis + Walk-backward | ||
| Stand + Run | Talk-Stand + Run | Pick + Run | Jump + Run | Walk + Stair-up | Walk-circle + Stair-up | Run + Stair-up | Stair-up + Run | Stair-down + Run | Table-tennis + Walk-circle | ||
| Stand + Stair-up | Talk-Stand + Stair-up | Pick + Stair-up | Jump + Stair-up | Walk + Stair-down | Walk-circle + Stair-down | Run + Stair-down | Stair-up + Stair-down | Stair-down + Stair-up | Table-tennis + Run | ||
| Stand + Stair-down | Talk-Stand + Stair-down | Pick + Stair-down | Jump + Stair-down | Walk + Table-tennis | Walk-circle + Table-tennis | Run + Table-tennis | |||||
| Stand + Table-tennis | Talk-Stand + Table-tennis | Pick + Table-tennis | Jump + Table-tennis |
| Name | Description | Value |
|---|---|---|
| Epochs | Number of training episodes | 50 |
| Attention dropout rate | Dropout applied to the attention matrix | 0.1 |
| Batch size | Number of samples applied during training at once | 64 |
| Dropout rate | Dropout applied between layers | 0.1 |
| Embedding size | Size of features after projection signal and size of position embedding | 128 |
| Fully Connected (FC) size | Size of the first layer in the position-wise feed-forward network | 256 |
| Global clipnorm | Clipping applied globally on gradients | 3.0 |
| Label smoothing | Smoothing of the hard one-hot encoded classes | 0.1 |
| Optimizer | Optimizer used during training model | Adam |
| Warmup steps | Number of steps from the learning starts to reach learning rate maximum | 10 |
| Learning rate | The maximum value of learning rate after warmup | 0.001 |
| Learning rate scheduler | The scheduler that controls the learning rate during training | Cosine |
| No. Heads | Number of heads in multi-head attention | 6 |
| No. Layers | Number of encoder blocks in the entire model | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dirgová Luptáková, I.; Kubovčík, M.; Pospíchal, J. Wearable Sensor-Based Human Activity Recognition with Transformer Model. Sensors 2022, 22, 1911. https://doi.org/10.3390/s22051911
Dirgová Luptáková I, Kubovčík M, Pospíchal J. Wearable Sensor-Based Human Activity Recognition with Transformer Model. Sensors. 2022; 22(5):1911. https://doi.org/10.3390/s22051911
Chicago/Turabian StyleDirgová Luptáková, Iveta, Martin Kubovčík, and Jiří Pospíchal. 2022. "Wearable Sensor-Based Human Activity Recognition with Transformer Model" Sensors 22, no. 5: 1911. https://doi.org/10.3390/s22051911
APA StyleDirgová Luptáková, I., Kubovčík, M., & Pospíchal, J. (2022). Wearable Sensor-Based Human Activity Recognition with Transformer Model. Sensors, 22(5), 1911. https://doi.org/10.3390/s22051911