
A Personalized Task Allocation Strategy in Mobile Crowdsensing for Minimizing Total Cost


Abstract
:1. Introduction
- A cost estimation method is proposed by taking the user’s preference for the sensing task into consideration. Furthermore, the minimizing cost problem is formulated as solving a heterogeneous, asymmetric, multiple TSP.
- Through transforming multiple-TSP to single-TSP, we first propose a greedy algorithm: PTAM-Greedy when the task is urgent, which is proved to have a bound to the optimal solution.
- When the task is not urgent, we further propose a genetic algorithm mixed with heuristic: PTAM-Genetic to minimize the total cost. The genetic algorithm consumes a lot of calculation time while achieving a better total cost performance.
- We conduct a number of simulations based on three widely-used real-world traces. The simulation results show that, PTAM-Greedy achieves a bounded cost performance, and PTAM-Genetic achieves the lowest total cost compared with the other task allocation strategies.
2. System Overview
2.1. System Model
2.2. Problem Description
3. Personalized Task Allocation Strategy
3.1. Cost Estimation and Multiple-TSP Formulation
3.2. Transformation from Multiple-TSP to Single-TSP
- 1.
- We define the virtual location set corresponding to task location as . Moreover, we make user that there is only one edge that comes into and departs from .
- 2.
- Assume that is the first virtual location in visited by the path in the optimal solution, after that, the path will visit all the remaining virtual locations in before leaving .
- 3.
- The user route, , from the initial location to its corresponding terminal point in will not pass through any other users’ initial locations and terminal points.
- 4.
- The cost of the optimal solution is equal to the summation of all the route costs of users, i.e., .
3.3. Single-TSP Solution
3.3.1. Greedy Algorithm
| Algorithm 1 PTAM-Greedy. |
Input: the transformed graph G = (V,E, ) Output: a Hamiltonian tour on G
|
| Algorithm 2 GHT. |
Input: a graph G = (V,E, ) Output: a Hamiltonian tour on G
|
| Algorithm 3 GHTCAN. |
Input: a graph G = (V,E, ) Output: a Hamiltonian tour on G
|
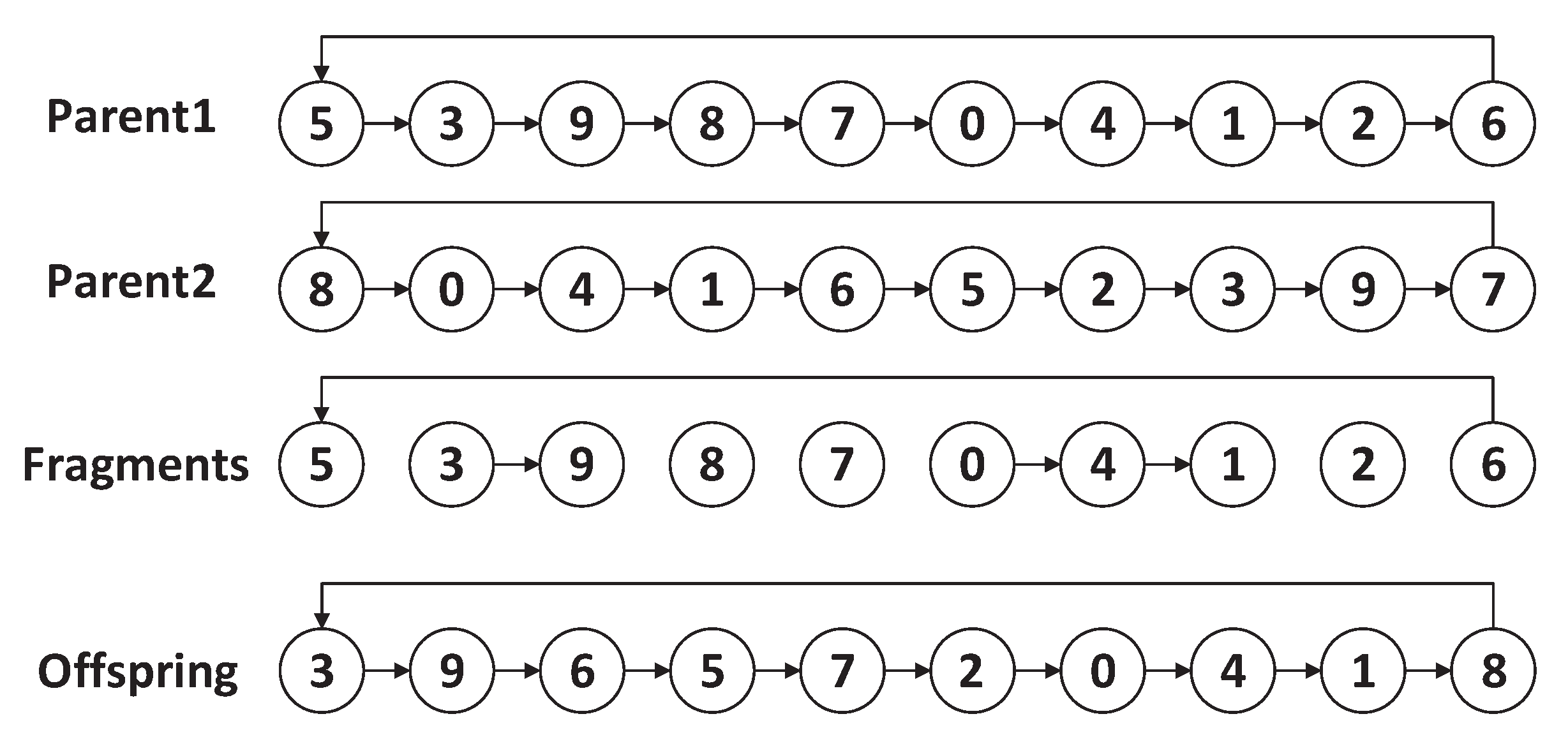
3.3.2. Genetic Algorithm
| Algorithm 4 PTAM-Genetic Algorithm. |
|
| Algorithm 5 PTAMG-crossover (). |
|
| Algorithm 6 PTAMG-mutation (g). |
|
4. Performance Evaluation
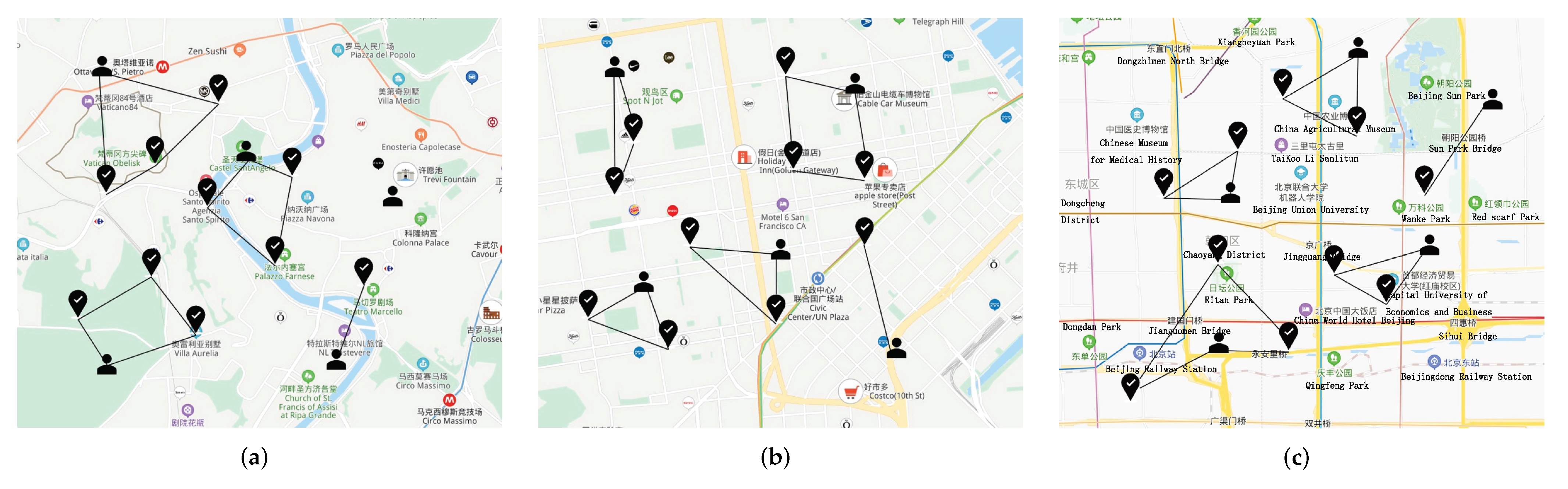
4.1. The Traces Used
4.2. Algorithms in Comparison
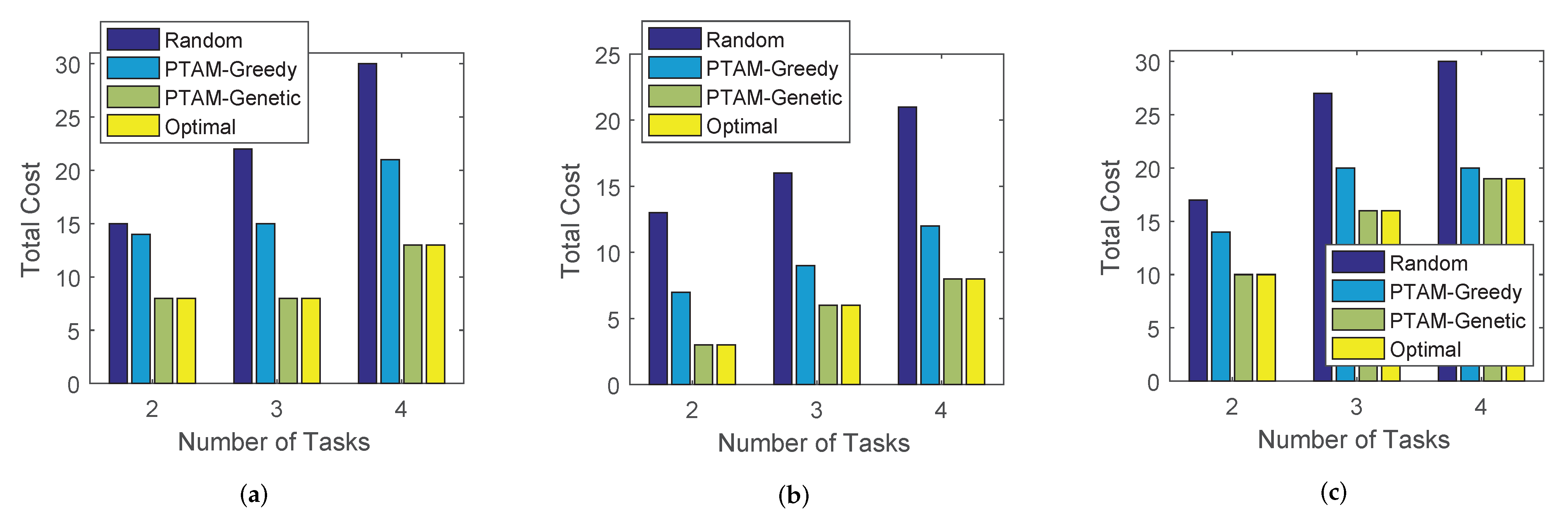
4.3. Simulation Results
5. Related Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ganti, R.K.; Ye, F.; Lei, H. Mobile crowdsensing: Current state and future challenges. IEEE Commun. Mag. 2011, 49, 32–39. [Google Scholar] [CrossRef]
- Zhou, T.; Xiao, B.; Cai, Z.; Xu, M.; Liu, X. From Uncertain Photos to Certain Coverage: A Novel Photo Selection Approach to Mobile Crowdsensing. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018. [Google Scholar]
- Lin, J.; Li, M.; Yang, D.; Xue, G.; Tang, J. Sybil-Proof Incentive Mechanisms for Crowdsensing. In Proceedings of the IEEE INFOCOM 2017—IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017. [Google Scholar]
- Xu, J.; Guan, C.; Wu, H.; Yang, D.; Xu, L.; Li, T. Online Incentive Mechanism for Mobile Crowdsourcing based on Two-tiered Social Crowdsourcing Architecture. In Proceedings of the 2018 15th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Hong Kong, China, 11–13 June 2018. [Google Scholar]
- Wang, B.; Kong, L.; He, L.; Wu, F.; Yu, J.; Chen, G. I (TS, CS): Detecting Faulty Location Data in Mobile Crowdsensing. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS 2018), Vienna, Austria, 2–6 July 2018. [Google Scholar]
- Wang, J.; Wang, F.; Wang, Y.; Zhang, D.; Wang, L.; Qiu, Z. Social-Network-Assisted Worker Recruitment in Mobile Crowd Sensing. IEEE Trans. Mob. Comput. 2018, 99, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Lin, S.; Zhang, J.; Ying, L. Crowdsensing for Spectrum Discovery: A Waze-Inspired Design via Smartphone Sensing. IEEE/ACM Trans. Netw. 2020, 28, 750–763. [Google Scholar] [CrossRef]
- Zhao, B.; Tang, S.; Liu, X.; Zhang, X. PACE: Privacy-Preserving and Quality-Aware Incentive Mechanism for Mobile Crowdsensing. IEEE Trans. Mob. Comput. 2020, 20, 1924–1939. [Google Scholar] [CrossRef]
- Xiao, M.; Gao, G.; Wu, J.; Zhang, S.; Huang, L. Privacy-Preserving User Recruitment Protocol for Mobile Crowdsensing. IEEE Trans. Mob. Comput. 2020, 28, 519–532. [Google Scholar] [CrossRef]
- Jin, H.; He, B.; Su, L.; Nahrstedt, K.; Wang, X. Data-Driven Pricing for Sensing Effort Elicitation in Mobile Crowd Sensing Systems. IEEE/ACM Trans. Netw. 2019, 27, 2208–2221. [Google Scholar] [CrossRef]
- Wang, X.; Jia, R.; Tian, X.; Gan, X. Dynamic Task Assignment in Crowdsensing with Location Awareness and Location Diversity. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018. [Google Scholar]
- Zhu, Q.; Uddin, M.Y.S.; Venkatasubramanian, N.; Hsu, C.H. Spatiotemporal Scheduling for Crowd Augmented Urban Sensing. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018. [Google Scholar]
- Yang, D.; Xue, G.; Fang, X.; Tang, J. Crowdsourcing to smartphones: Incentive mechanism design for mobile phone sensing. In Proceedings of the 18th Annual International Conference on Mobile Computing and Networking, Istanbul, Turkey, 22–26 August 2012. [Google Scholar]
- Jin, H.; Su, L.; Chen, D.; Nahrstedt, K.; Xu, J. Quality of information aware incentive mechanisms for mobile crowd sensing systems. In Proceedings of the Sixteenth ACM International Symposium on Mobile Ad Hoc Networking and Computing, Hangzhou, China, 22–25 June 2015. [Google Scholar]
- Cheung, M.H.; Hou, F.; Huang, J.; Southwell, R. Distributed Time-Sensitive Task Selection in Mobile Crowdsensing. IEEE Trans. Mob. Comput. 2020, 20, 2172–2185. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Peng, Y.; Wu, F.; Tang, S.; Chen, G. ARETE: On Designing Joint Online Pricing and Reward Sharing Mechanisms for Mobile Data Markets. IEEE Trans. Mob. Comput. 2020, 19, 769–787. [Google Scholar] [CrossRef]
- Wang, X.; Jia, R.; Tian, X.; Gan, X.; Fu, L.; Wang, X. Location-Aware Crowdsensing: Dynamic Task Assignment and Truth Inference. IEEE Trans. Mob. Comput. 2020, 19, 362–375. [Google Scholar] [CrossRef]
- Malik, W.; Rathinam, S.; Darbha, S. An approximation algorithm for a symmetric Generalized Multiple Depot, Multiple Travelling Salesman Problem. Oper. Res. Lett. 2007, 6, 747–753. [Google Scholar] [CrossRef]
- Oberlin, P.; Rathinam, S.; Darbha, S. A Transformation for a Heterogeneous, Multiple Depot, Multiple Traveling Salesman Problem. In Proceedings of the American Control Conference, St. Louis, MO, USA, 10–12 June 2009; pp. 1292–1297. [Google Scholar]
- Johnson, D.; McGeoch, L.A. The Traveling Salesman Problem: A Case Study in Local Optimization. Local Search Comb. Optim. 1997, 1, 215–310. [Google Scholar]
- Blaser, M. An 8/13-approximation algorithm for the asymmetric maximum TSP. Siam J. Discret. Math. 2002, 17, 237–248. [Google Scholar]
- Reinelt, G. The Traveling Salesman: Computational Solutions for TSP Applications. Lect. Notes Comput. Sci. 1994, 840, 1–223. [Google Scholar]
- Louis, B.J. Fast Algorithms for Geometric Traveling Salesman Problems. Orsa J. Comput. 1992, 4, 387–411. [Google Scholar]
- Lin, S.; Kernighan, B.W. An Effective Heuristic Algorithm for the Traveling-Salesman Problem. Oper. Res. 1973, 21, 498–516. [Google Scholar] [CrossRef] [Green Version]
- Bracciale, L.; Bonola, M.; Loreti, P.; Bianchi, G.; Amici, R.; Rabuffi, A. CRAWDAD Dataset Roma/Taxi (v. 2014-07-17). 2014. Available online: http://crawdad.org/roma/taxi/20140717 (accessed on 20 January 2022).
- Piorkowski, M.; Sarafijanovic-Djukic, N.; Grossglauser, M. CRAWDAD Dataset Epfl/Mobility (v. 2009-02-24). 2009. Available online: http://crawdad.org/epfl/mobility/20090224 (accessed on 20 January 2022).
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.Y. Mining interesting locations and travel sequences from GPS trajectories. In Proceedings of the 18th International World Wide Web Conference, Madrid, Spain, 20–24 April 2009. [Google Scholar]
- Wang, E.; Yang, Y.; Wu, J.; Liu, W.; Wang, X. An Efficient Prediction-Based User Recruitment for Mobile Crowdsensing. IEEE Trans. Mob. Comput. 2018, 17, 16–28. [Google Scholar] [CrossRef]
- Li, G.; Cai, J. An Online Incentive Mechanism for Crowdsensing With Random Task Arrivals. IEEE Internet Things J. 2020, 7, 2982–2995. [Google Scholar] [CrossRef]
- Wang, J.; Wang, F.; Wang, Y.; Zhang, D.; Lim, B.Y.; Wang, L. Allocating Heterogeneous Tasks in Participatory Sensing with Diverse Participant-Side Factors. IEEE Trans. Mob. Comput. 2018, 18, 1979–1991. [Google Scholar] [CrossRef] [Green Version]
- Guo, B.; Liu, Y.; Wu, W.; Yu, Z.; Han, Q. ActiveCrowd: A Framework for Optimized Multitask Allocation in Mobile Crowdsensing Systems. IEEE Trans. Hum. Mach. Syst. 2017, 47, 392–403. [Google Scholar] [CrossRef] [Green Version]
- Ding, Y.; Chen, C.; Zhang, S.; Guo, B.; Yu, Z.; Wang, Y. GreenPlanner: Planning personalized fuel-efficient driving routes using multi-sourced urban data. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications (PerCom), Kona, HI, USA, 13–17 March 2017; pp. 207–216. [Google Scholar]
- Zhao, H.; Xiao, M.; Wu, J.; Xu, Y.; Huang, H.; Zhang, S. Differentially Private Unknown Worker Recruitment for Mobile Crowdsensing Using Multi-Armed Bandits. IEEE Trans. Mob. Comput. 2021, 20, 2779–2794. [Google Scholar] [CrossRef]
- Yang, S.; Han, K.; Zheng, Z.; Tang, S.; Wu, F. Towards Personalized Task Matching in Mobile Crowdsensing via Fine-Grained User Profiling. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 2411–2419. [Google Scholar]
- Wang, Z.; Pang, X.; Chen, Y.; Shao, H.; Wang, Q.; Wu, L.; Chen, H.; Qi, H. Privacy-Preserving Crowd-Sourced Statistical Data Publishing with An Untrusted Server. IEEE Trans. Mob. Comput. 2019, 18, 1356–1367. [Google Scholar] [CrossRef]
- An, B.; Xiao, M.; Liu, A.; Xu, Y.; Zhang, X.; Li, Q. Secure Crowdsensed Data Trading Based on Blockchain. IEEE Trans. Mob. Comput. 2021. [Google Scholar] [CrossRef]
- Wang, Z.; Hu, J.; Lv, R.; Wei, J.; Wang, Q.; Yang, D.; Qi, H. Personalized Privacy-preserving Task Allocation for Mobile Crowdsensing. IEEE Trans. Mob. Comput. 2018, 18, 1330–1341. [Google Scholar] [CrossRef]
- Jiang, C.; Gao, L.; Duan, L.; Huang, J. Data-Centric Mobile Crowdsensing. IEEE Trans. Mob. Comput. 2018, 17, 1275–1288. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Zhang, Z.; Wang, J.; Li, R.; Wan, S. A Green Stackelberg-Game Incentive Mechanism for Multi-Service Exchange in Mobile Crowdsensing. ACM Trans. Internet Technol. 2021, 22, 1–29. [Google Scholar] [CrossRef]
- Karaliopoulos, M.; Koutsopoulos, I.; Titsias, M. First learn then earn: Optimizing mobile crowdsensing campaigns through data-driven user profiling. In Proceedings of the Seventeenth ACM International Symposium on Mobile Ad Hoc Networking and Computing, Paderborn, Germany, 5–8 July 2016; pp. 271–280. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| the set of users, the set of tasks, the set of users’ preferences | |
| the preferences of user i, the preferences of task location that could satisfy some preferences of users | |
| the initial location of the user i, the terminal point of the user i on the transformed graph | |
| the j-th virtual task location of user i | |
| the number of task locations, the number of users | |
| the cost of user i from to task | |
| the cost of user i from to | |
| the physical distance between and | |
| the physical distance between and | |
| the ’s preference level for task | |
| the discount for to task | |
| the path of user i in the transformed graph from the initial location to its corresponding terminal point in the optimal solution | |
| the tour of user i in multiple-TSP | |
| G | a transformed graph |
| V | the collection of nodes in graph G |
| E | the collection of edges in graph G |
| Y | a cycle cover in graph G |
| the cycles in cycle cover Y | |
| the set of all indices i, such that is a k-vertices-cycle () |
| Parameter | Results | |||
|---|---|---|---|---|
| PTAM-Greedy | Optimal | Proportion | Bound | |
| 62 | 62 | 1 | 1.19 | |
| 68 | 63 | 1.08 | 1.23 | |
| 70 | 64 | 1.06 | 1.26 | |
| 74 | 66 | 1.15 | 1.30 | |
| 77 | 74 | 1.04 | 1.34 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, H.; Zhao, H. A Personalized Task Allocation Strategy in Mobile Crowdsensing for Minimizing Total Cost. Sensors 2022, 22, 2751. https://doi.org/10.3390/s22072751
Gao H, Zhao H. A Personalized Task Allocation Strategy in Mobile Crowdsensing for Minimizing Total Cost. Sensors. 2022; 22(7):2751. https://doi.org/10.3390/s22072751
Chicago/Turabian StyleGao, Hengfei, and Hongwei Zhao. 2022. "A Personalized Task Allocation Strategy in Mobile Crowdsensing for Minimizing Total Cost" Sensors 22, no. 7: 2751. https://doi.org/10.3390/s22072751
APA StyleGao, H., & Zhao, H. (2022). A Personalized Task Allocation Strategy in Mobile Crowdsensing for Minimizing Total Cost. Sensors, 22(7), 2751. https://doi.org/10.3390/s22072751