1. Introduction
A natural hazard is a potentially destructive physical event that can cause social and economic harm, fatalities or injuries, material damage, and environmental degradation. Worldwide [
1,
2], landslides are considered a significant natural hazard causing extensive damage to the environment and societies [
3,
4]. Like other countries, Pakistan is prone to natural hazards, including landslides, due to its high precipitation, geological setting, and rugged terrain with steep slopes [
5].
The foremost objective of landslide susceptibility analysis is identifying hazardous and high-risk areas, followed by appropriate actions to reduce negative impacts resulting from landslides [
4,
6]. The geographical information system (GIS) is widely used to document natural hazards, analyze environmental and infrastructure data, and provide hazard susceptibility maps [
7,
8]. The primary goals of such studies include recognizing and mapping landslide-prone zones. Landslide susceptibility assessments can be used to construct maps based on the local geo-environmental factors and the spatially explicit identification and zoning of possible landslide incidences in a particular region [
9,
10,
11,
12]. Landslide susceptibility maps (LSMs) are also important for planning and managing land use and reducing the risk of slope instability for the area under the study [
12].
Various approaches for developing landslide susceptibility maps (LSMs) based on GIS have been proposed and practiced during the last few decades. Natural hazard susceptibility analysis has been carried out via different multi-criteria decision-making (MCDM) techniques [
13]. The MCDM techniques run clear hierarchical decision structures that make it possible for different groups of experts in the domain and any evaluator, even non-expert participants, e.g., members of the local community, to be involved in a decision-making problem [
14]. The MCDM techniques can reflect the real perception of spatial issues like any natural disaster susceptibility assessment by involving the mentioned groups via dynamic questionnaire surveys. Therefore, many landslide susceptibility studies used various MCDM techniques like the analytical hierarchical process (AHP) [
15], the analytical network process [
16], or the technique for order of preference by similarity to ideal solution (TOPSIS) [
17]. Although the MCDM techniques have been widely used in several natural disaster susceptibility assessments, they have not always resulted in satisfactory results due to the preferences of different stakeholders [
14].
During the last two decades, machine learning (ML) techniques have been used for natural disaster assessments like LSM [
18]. Each ML technique has different advantages and shortcomings. The ML techniques are trained based on part of the inventory data set, and expert knowledge is mainly helpful for defining the optimal parameters of the ML techniques [
19,
20,
21]. Various ML techniques have been proposed and experienced in landslide susceptibility analysis and LSM. However, the most widely used ones have been the support vector machine (SVM) [
22], linear regression (LR) [
23], logistic regression (LGR) [
24,
25,
26], and multivariate regression [
27,
28]. Although the ML techniques are increasingly getting more popular for LSM, there is no evidence that a particular ML technique is the best for a specific natural hazard assessment or study area [
29].
The ML technique of SVM is also among the methods that have been implemented for mapping landslide susceptibility. Its results have been found superior to other conventional ML methods by several studies [
2,
22,
30]. The reason is that the workability of SVM is not affected by high dimensional data, which means that it can handle the high number of landslide conditioning factors. Numerous studies have also found the performance of LGR as quite optimal compared to other ML techniques, e.g., [
31,
32,
33]. Moreover, numerous statistical methods have also been combined with ML approaches to develop hybrid forms, such as the rough set-SVM [
34], the adaptive neuro-fuzzy inference system [
35], ANN-MaxEnt-SVM [
36], step-wise weight assessment ratio analysis [
37], and ANN-fuzzy logic [
38,
39] to achieve better accuracies for the susceptibility analysis. However, more recently, deep learning algorithms such as the recurrent neural network and convolutional neural network [
40,
41,
42,
43] are also being applied for landslide susceptibility assessments. Moreover, the landslide inventory dataset plays an essential role in the training of both machine and deep learning algorithms as well as the accuracy assessment of any LSM model, such as GIS-based MCDM. Therefore, a comprehensive dataset of historical landslides is an important input for understanding the landslide susceptibility of the area under investigation [
43].
The Chitral district is situated in northern Pakistan in the Hindu Kush range. Due to the rugged topography and active seismicity, the Hindu Kush range is a hazardous event hotspot. This part of northern Pakistan has recently been experiencing several landslides every year. As mentioned by Ali and Biermanns [
5], aside from the general conditioning factors of lithology, relief, geological structure, and geo-mechanical properties, the conditioning factors (temperature variation, seismicity, precipitation, and active or inactive loads) are the primary cause of landslides. In most of the Chitral district (34%), the observed altitude is about 4500 m above sea level [
44]. The climatic conditions of the eastern Hindu Kush are classified as high-altitude continental. There is a significant inconsistency in the annual rainfall throughout the region [
45]. Glaciers and ice or snow cover more than 12% of the district permanently [
46]. Roohi and Ashraf [
47] documented 187 icy waters (a combination of water and ice) in the Chitral valley with an approximate area of 9 km
2. Moreover, the increasing anthropogenic activities, the changing global climate, and the dynamic tectonic nature of the region have been causing more landslides. All these factors make our selected case study area vulnerable to landslides. Landslide susceptibility assessment and LSM provide crucial information for hazard mitigation in this area. So far, to the best of our knowledge, no study has done landslide inventory documentation and susceptibility mapping altogether in this area. In addition, no comparison studies exist for this study area and some of the datasets used in this study have never been used before in this area. Therefore, it is essential to consider the mapping accuracies of various methods for such a sensitive area and highlight the best-performing model.
The objective of this research was to carry out a landslide susceptibility analysis of the Chitral district in northern Pakistan and compare three ML techniques: LGR, LR, and SVM, besides the two MCDM techniques: AHP and TOPSIS. The study used multiple datasets from recent sources and developed various models. Thus, this research will provide policymakers with a baseline for further studies to mitigate landslides. This research is organized as follows. In the next section, the study area including the geology and geomorphology characteristics is introduced. In
Section 3, the proposed methodology for landslide inventory generation is presented in detail, together with the applied machine learning and MCDM models in the study. Results of inventory mapping, correlation analysis of the conditioning factors, and LSMs are reviewed in
Section 4. In
Section 5, the lesson learned is discussed.
2. Study Area
The Chitral district, having a latitude and longitude of 36° 15′ 0″ N and 72° 15′ 0″ E, respectively, represents most of the northern region of Pakistan’s Khyber Pakhtunkhwa province. Chitral district is based on the drainage system of the eastern Hindu Kush range. On the northeastern side of the study area, at 4500 m above sea level, lies the Karambar Glacier, from which the Chitral River commences. The Shishi River at Drosh, the Tirich-Torikho River near Buni, and the Lutkho River at Chitral are the main streams in Chitral [
48].
In the northwest, the Upper Hindu Kush is separated by the Chitral tributary from the Lower Hindu Kush in the southeast. The main valley courses downwards from 2800 m above sea level in the northeast to 2000 m above sea level in the southwest over 300 km. Glaciated Mountain ranges with altitudes between 5500 m and 7700 m border the main valley on both sides. At the northwestern verge of the Chitral basin, the Upper Hind Kush reaches altitudes of 5500 m and 7500 m and is home to one of the world’s tallest summits, Tirich Mir (7706 m). At the southeastern verge of the Chitral valley, the Lower Hindu Kush reaches altitudes between 5000 m and 7000 m. In places, the local reliefs reach elevations above 4500 m, but in most areas, it is just above 2500 m [
49].
The geology and geomorphology of the pondered area are sophisticated and are described by displacements in numerous spatial directions over time. The local geology consists of carbonate and terrigenous deposits of the Paleozoic through the Mesozoic. From the continental shelf, the Neotethys and Paleo sedimentation reveal deposits resembling fly ash of the Karakorum and Pamir Block in the north and the south with the neighboring Kohistan Magmatic Block. Two prominent stratigraphic lineaments, specifically the Tirich Mir Suture Zone and the Northern Suture Zone, detach these tectonic features. The surface marine and fluvial deposits comprise conglomerates, carbonates, and sandstones of the Cretaceous to the Tertiary. They exist in the Karakorum Block’s intraplate structural lineament, namely, the Reshun Fault Zone. Significant twists and bends embody the regional structural elements because of the Cretaceous–Tertiary orogenic movements. These consist of a ductile distortion through the conflict phase alongside the Indus Suture Zone that resulted in the advancement of intricate makeups and crustal reduction and coagulating and elevating the ground. At the same time, a brittle distortion happened alongside Northern Structure Zone, which caused feeble foliations, cleavage surfaces, longitudinal faults, and macrofolds [
50].
The regional climate is classified as semi-arid. Severe temperatures (cold and hot), low rainfall, and dampness characterize the region as arid to semi-arid. The temperature fluctuates extensively in the region and varies depending on elevation, valley winds, and orography. The mean yearly temperature is 15.6 °C, but it can drop to −1 °C in January and go up to 35 °C in July. There are dry and warm summers in the region, while with moderate to heavy rain and snow the winters are cold [
49]. The region is scarcely affected by the monsoonal rainfall as it is in the rain shadow of the Himalayas [
45]. The average annual rainfall in the Chitral and Drosh city areas is 450 and 600 mm. Most of this rainfall occurs in the spring and winter seasons. With a monthly rainfall of 10–25 mm, the summer and autumn are dry. At high altitudes, the combination of westerly disturbances, and in the south, the influence of marginal monsoon significantly influences the harsh infrequent summer rains [
48]. Such a significant inconsistency in precipitation and temperature over different seasons of the year impacts the timely dissemination of landslide hazard in the region. The study area map is shown in
Figure 1e.
3. Materials and Methods
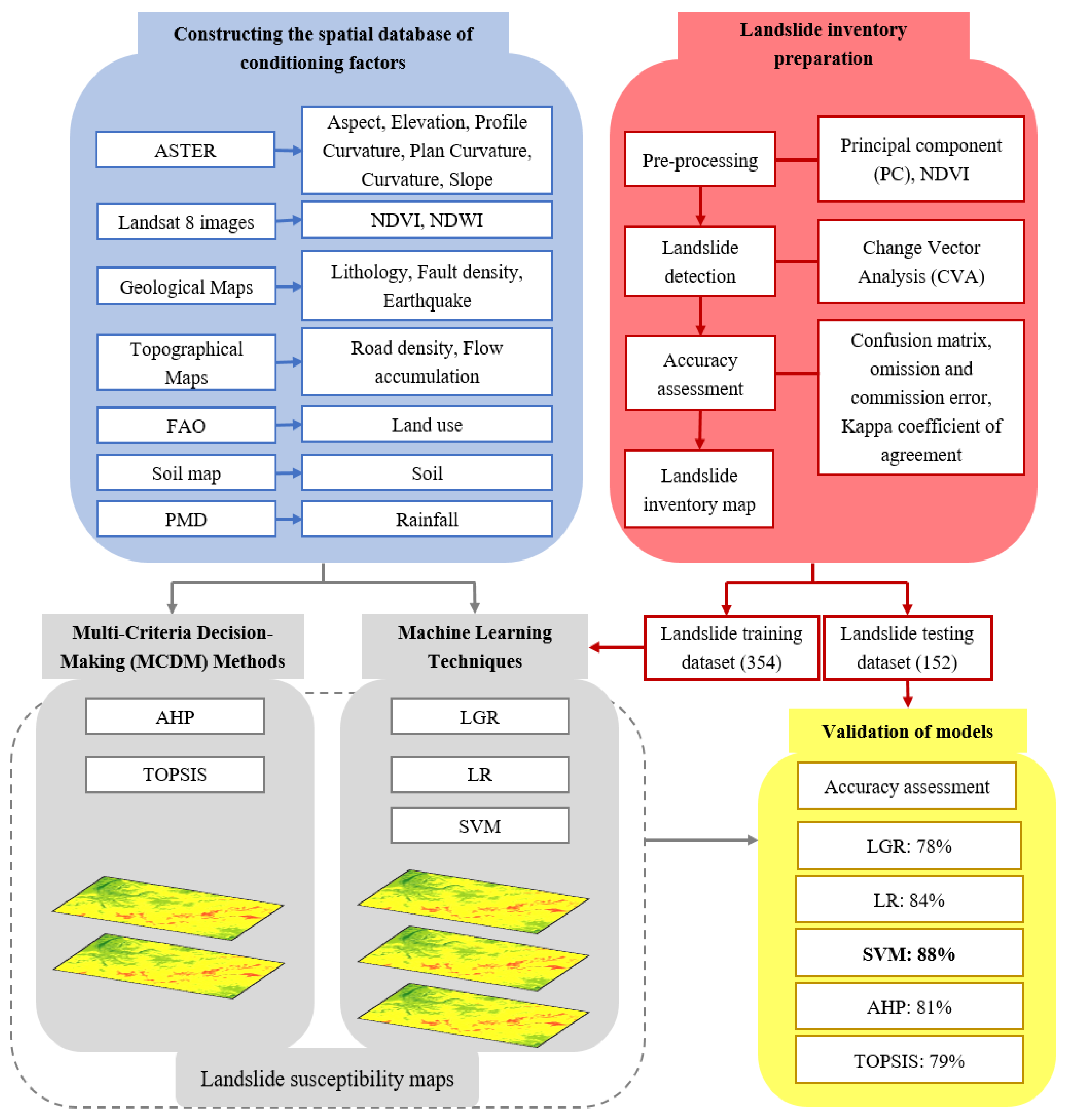
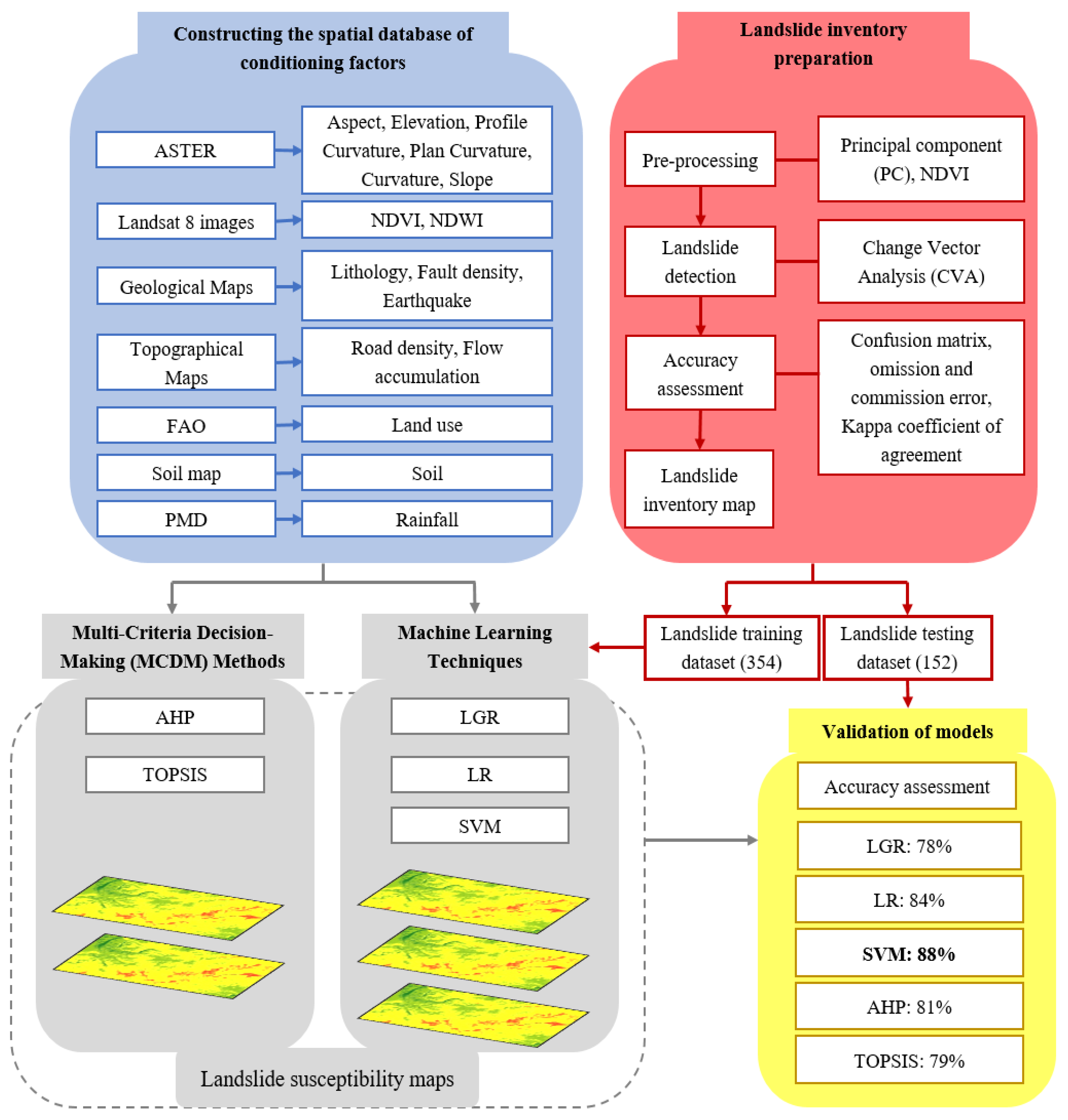
A landslide database for the current research was developed using satellite images, historical data, and official data from national departments. Based on the previous studies and specific study area features, sixteen conditional factors were used from topographical, hydrogeological, lithological, and geomorphological groups. Subsequently, the relative importance (weights) of the controlling elements were determined by different models. Lastly, the LSMs were developed in an ArcGIS environment by utilizing the obtained weights of the conditioning factors. A comprehensive overview of the methodology is presented in
Figure 2. The step-wise procedure constituting different methods for achieving the desired task is explained.
3.1. Landslide Inventory
In this study, GIS was used for data collection and processing. Past landslides, including their features and locations, are generally shown in the landslide inventory maps, but the processes that activated them are not illustrated. Creating a landslide inventory map is the critical first step. The modeling approach assumes that the key to figuring out future landslide occurrences lies in the past landslides. Thus, helpful information regarding the locations of previous landslides provided by the landslide inventory map also holds the potential for identifying areas at risk of future landslides.
Consequently, the first step is to create a highly accurate landslide inventory map [
41,
42,
43]. The landslide inventory map for this work was created using the landslide data from satellite images (LANDSAT-8) and historical records from official data from the national departments. The data highlighted 506 landslide positions (centroid) in the area. There are three different types of mass movements in the study region, namely rock fall, landslide, and debris flow. This study has processed these different types of mass movements as a single type of landslide event. The landslide inventory map of the study area is shown in
Figure 1e. Automatically generating a cartographic inventory of landslides through a change detection technique is further explained.
3.1.1. Pre-Processing
We used principal components (PC) analysis [
51] to combine a large group of variables into a new smaller set [
52] without losing the original information. As a result, the efficiency of the classification procedure is amplified by reducing the dimensionality, and the possibility of detecting differences in land cover increases. The interpretation of the variability axes of the image (LANDSAT-8 image) is facilitated by PC analysis, which allows for most of the identifying features present in the bands and others specific only to certain bands. The images taken were cloud-free and close to the landslide events. The original
m bands were linearly combined to generate new variables (the components) in the PC analysis. Additionally, to reproduce the total variability
n, PC is ultimately required. In a smaller number of
m components, most of this variability is contained. As such, almost all the information is conserved; the dimensionality is reduced when the
m bands are replaced with
n components [
53].
The used threshold methods for the change detection were statistic and secant. Initially, the threshold values were set to > 50, and the change was visualized. These values were then varied to yield the maximum change in both images [
54,
55]. The resulting optimal threshold values are listed in
Table 1.
The photosynthetic pigments caused a sharp absorption peak showing the vegetation in the red wavelengths. However, they exhibit strong reflection in the infrared spectrum. As the wavelength increases, the smooth monotonic increase characterizes bare soil. However, a contrary behavior is exhibited by water bodies, except for lengths corresponding to blue, where there is significant absorption at all wavelengths [
56]. Based on radiometric data, it is likely to extract an index that evaluates chlorophyll density or green biomass density, as does the normalized difference vegetation index (NDVI), which is defined as a ratio of the difference between a near-infrared band and a red band, divided by their sum.
3.1.2. Change Detection
The change vector analysis (CVA) was used for change detection. The CVA model uses the magnitude and the direction of change between the images of the two dates for each co-registered pixel to define a change vector [
54]. If H = (h
1, h
2, …, h
n)
F and G = (g
1, g
2, …, g
n)
F, corresponding to two different dates (i.e., f
1 and f
2, the reflectance values of the pixels in two images, correspondingly, where the number of bands is given by n), then the succeeding equation can be used to determine the magnitude of the change ‖Δ
‖,
Using the characteristics of the same pixel on the two dates, the absolute magnitude of the total difference is given by ‖Δ
‖ [
57]. Consequently, a high rate of change is represented by a high ‖Δ
‖, and no change is represented by a pixel with a value of ‖Δ
‖ = 0.
The geometric concept of the CVA change detection method was applied to the PC images of each of the study dates. Referring to Equation (1), the three PCs of f
2 are represented by
, whereas the three PCs of f
1 are represented by H. Lastly, the change map created using CVA is represented by ‖Δ
‖.
Figure 1a, and b illustrates the pre- and post-landslide imagery.
Figure 1c shows the change detection results, while the identified landslide is shown in
Figure 1d.
3.1.3. Accuracy Assessment
From the LANDSAT-8 imagery dates, 193 polygons were sampled to gain ground–truth data based on the interpretation of colors in the satellite imagery to assess the accuracy of the change detection process. Using confusion matrices, the final thematic map produced with the unsupervised change detection method was compared with the ground–truth samples to obtain the omission–commission errors for each case.
We used the Kappa concordance coefficient of agreement [
58] to compute the variance between the detected map–reality agreement in the final thematic map and the map that would be arbitrarily anticipated. Regardless of random selection, the degree of adjustment only due to the categorization accuracy is defined as an effort by the Kappa index [
57]. The following Equation (2) was used to calculate the Kappa coefficient.
where
k,
n,
Xii, and
Xi+
X+
i represent the Kappa coefficient of agreement, the sample size, the observed agreement, and the expected agreement, respectively, in each category
i. The Kappa coefficient shows if the marked degree of agreement draws away or is not significantly different from the expected random agreement. The detected conformity highlights the diagonal of the confusion matrix, and the reality due to the randomness was calculated using the expected agreement [
59].
3.2. The Spatial Database of Conditioning Factors
The conditioning factors in this study were chosen considering the accessible statistical data in the study area as per the study area characteristics such as topography, geological setting, etc., and the existing landslide susceptibility studies, which is a commonly applied approach. Consequently, based on former landslide susceptibility investigations [
36,
60,
61,
62,
63] and examination of the characteristics of the Chitral region, the following sixteen conditioning factors, namely aspect, elevation, distance from the fault, soil, flow direction, slope, precipitation, length from the roads, the normalized difference wetness index (NDWI), land use, earthquake activity, lithology, NDVI, plane curvature, profile curvature, and curvature, were selected for mapping the landslide susceptibility of the pondered area.
We obtained the six geomorphometric factors of the slope, aspect, elevation, and curvature from the Shuttle Radar Topography Mission (STRM) Digital Elevation Model (DEM), having a 30 m × 30 m resolution plane and profile curvature. The NDVI and NDWI were extracted using LANDSAT-8 satellite images. The infrared and red bands were used to calculate the NDVI with the formula
[
64,
65,
66]. However, short-wave infrared and green bands were used to compute the NDWI using the formula
NDWI =
G −
SWIRG +
SWIR. The land use map was prepared using data extracted from the Food and Agricultural Organization (FAO) 2009 dataset.
Furthermore, to create the thematic maps of earthquake activity, faults, and lithology, we used the geological maps of Pakistan at scales of 1:2,000,000. The soil map of Pakistan was used to generate the soil map of the study area. The Pakistan meteorological department (PMD) station data constructed the precipitation map. We used topographic maps and Google Earth Images to create the thematic road density map. Lastly, the data was normalized and standardized before further processing. All the maps of the landslide conditioning factors were normalized to avoid issues because of the data’s scale variability as it was acquired from different sources. All the thematic layers with different resolutions were transformed into a raster format with a resolution of 30 m × 30 m, similar to that of the derived DEM, as most of the factors were derived from DEM.
Furthermore, all the thematic layers were standardized by classifying every layer into five classes using natural break classification, and these classes were ranked from 1 (very low) to 5 (very high) based on the varying influence of each class on landslides. Ultimately, the data after normalization and standardization was checked for errors by comparing the layers with each other and looking for a difference value. The resulting difference was 0, showing no errors among the data.
3.3. Evaluation of Condition Factors
It is crucial to use only high-quality data when dealing with data mining methods as it directly affects prediction accuracy. The prediction process can be complex due to the high dimensionality of the training and validation sets, and the curse of dimensionality is that it always has poor prediction accuracies. Therefore, in this study, multicollinearity analysis was carried out for the selected conditioning factors to evaluate the factors so that the extraneous and redundant features could be removed.
Multicollinearity Analysis
Multicollinearity is a statistical trend that signifies an excellent correlation between two or more variables in a multiple regression model [
62]. The present study used variance inflation factor (
VIF) and tolerance (TOL) to spot multicollinearity among the considered conditioning factors. Suppose that a given independent variable set is defined by x = [1 × n], and
Rj2 signifies the determination coefficient when the
jth independent variable x
j is regressed against all other variables in the model. The following equation gives the
VIF value:
The inverse of the VIF value gives the TOL value, and it denotes the extent of linear correlation among individual variables. As the values of TOL and VIF are reciprocal to each other, this means that if the value of one of these indicators is lower, subsequently, the value of the other will be higher. A VIF value of more than 10 or a TOL value less than 0.1 indicates that the corresponding factors have multicollinearity and should not be considered for further analysis.
3.4. Training and Validation Database
Bui and Ho [
58] stated that landslide and non-landslide samples are required when using data mining techniques to produce LSMs. However, the extent of landslide statistics is far less than that of non-landslide statistics, even if all landslide statistics are exploited [
67]. Subsequently, in this study, along with the 506 landslide positions used to create the landslide inventory, 506 non-landslide positions were randomly selected in the area. Afterward, the landslide and the non-landslide points were randomly split with a ratio of 70/30. There are no established criteria for separating the data for susceptibility modeling. However, the ratio of 70/30 is the most practiced ratio for splitting data in the research community. Of all of the 506 landslide locations, 354 (70%) randomly sampled were used as training data to construct the models. The remaining 152 (30%) were used as testing samples for model validation. Similarly, for the non-landslide locations, 354 (70%) randomly sampled points were used for training and the remaining 152 (30%) for the model validation.
Subsequently, all landslide and non-landslide locations’ raster values in combination with the data of the 16 conditioning factors were used to build the training and validation datasets. A value of 1 was assigned to all landslide points and 0 to all non-landslide points to assemble the training and validation datasets.
3.5. Machine Learning (ML) Techniques
This study used three ML techniques for mapping the landslide susceptibility of the pondered area. R-Studio was used to implement LGR, LR, and SVM to calculate the importance of each contributing factor. In a 10-fold cross-validation process, the considered conditioning factors were used to construct the landslide models. All three models had the same structure, as they are all regression models [
68,
69,
70]. Thus, the architecture of the models included 16 input layers and 15 hidden layers. The epoch value was 150, and the loss function was the root mean square error function. The learning rate was 0.0067. The correlation value was calculated using all three models by comparing the predicted and observed outcomes in testing datasets. A higher value of correlation represents a more precise model calculation. A brief description of all ML methods used for susceptibility analysis follows.
3.5.1. Linear Regression (LR)
LR was used to define the parameters responsible for conditioning landslides in the study area and to investigate multivariate statistics. All the input datasets used in this study are used as input parameters for LR analysis, because all the considered factors contribute to landslides. The multiple linear regression method reveals how the changing standard deviation of predicators and independent variables changes landslide susceptibility. Moreover, in the study area for landslide susceptibility, this method helped make a linear function (model) and Equation (4). The theoretical model for this study is described as follows.
where, in each sampling unit, the occurrence of landslides is represented by L; for each mapping unit, the observed independent variables are represented by all the X’s; the B’s are the estimated coefficients (weights); and model error is represented by ℇ [
71].
3.5.2. Logistic Regression (LGR)
In the earth sciences, the most common statistical method used is the multiple regression method, which is articulated as the following linear Equation (5):
where the presence (1) or absence (0) of the landslide is represented by a dependent variable Y, the model’s intercept is b
0, and b
1 represents the partial regression coefficients… b
n, x
1 … x
n, which are the independent variables.
LGR is a multivariate analysis model that is convenient for forecasting the existence or nonexistence of a representative or consequence centered on assessments of a set of predictor variables, as Lee and Sambath [
72] stated. Yesilnacar and Topal [
73] noted that the basis for LGR is that the dependent variable is dichotomous. In this model, the predictors of the dependent variable are the independent variables. They can be calculated on an ordinal, small, break, or fraction scale.
3.5.3. Support Vector Machine (SVM)
SVM is an ML method based on the refinement of groups in a high-dimensional attribute space created via nonlinear alterations of the predictors [
74]. All considered conditional factors are used as input parameters for SVM analysis because of all the factors contributing to landslides. The basic theory of SVM is the statistical learning theory [
75]. For classifying datasets, an evaluation hyperplane is computed in this high-dimensional space. For susceptibility modeling, the potentials of SVM were demonstrated by Brenning [
76]. The effectiveness of working with high-dimensional and linearly non-separable datasets is the reason for the wide use of SVM in diverse applications and to deal with regression complications [
77,
78]. The SVM reduces both model complexity and error.
3.6. Multi-Criteria Decision-Making (MCDM) Techniques
3.6.1. Analytical Hierarchy Process (AHP)
Saaty [
79] developed the AHP method, a useful tool that uses the hierarchy principle to organize and analyze complex decisions. For the application of this method, a necessary first step is that the composite formless dilemma is broken down into its constituent aspects. These aspects are then arranged in hierarchical order. Afterward, based on the comparative status of each feature, values are allocated to subjective judgments; lastly, the decisions are integrated to decide the weightings to be allotted to these features [
80]. Each factor is valued compared to every other factor while structuring a pair-wise comparison matrix by allocating an overall comparative value between 1 and 9 to the traversing cell.
During the pair-wise comparisons of the factors in the AHP method, some consistencies may typically arise, as the judgments are driven by the subjective opinions of experts from various fields. However, the AHP method integrates an operative practice for checking the logical consistency in pair-wise comparisons. The consistency ratio (CR), as suggested by Saaty [
79], is a tool that determines the consistency of the matrix by using all the selected parameters and their paired comparisons [
12]. The matrix results are considered satisfactory if the value of CR is less than 0.1 [
77]; otherwise, the decisions need to be revised.
3.6.2. The Technique for Order Preference by Similarity to Ideal Solution (TOPSIS)
Ching and Yoon [
81] presented the TOPSIS method based on the Euclidean remoteness among choices and creating substitutes [
82]. This method was developed to solve decision-making problems because of incompatible and non-commensurable conditions. It consists of grading the substitutes based on the degree of adequacy ranked using the distance principle. It is readily used to solve various decision-making challenges. In this technique, the extreme detachment from the negative principle result and the briefest detachment from the principle outcome are the two conditions on which the ranking of alternatives is based [
83].
3.7. Landslide Susceptibility Mapping
According to the weights of the conditioning factors determined using various models, the raster layers were reclassified and weighted. A direct and straightforward tool to create susceptibility maps in GIS is the Weighted Overlay Method (WOM). Several researchers have used WOM to produce susceptibility maps [
84,
85,
86,
87,
88]. An overlay of raster layers was utilized to create susceptibility maps with all governing aspects. The landslide susceptibility indices for all pixels in the study region were also calculated to get the area percentages under different susceptibility classes.
5. Discussion
While most landslide susceptibility assessment methods are based on GIS technology, many different methods are available to perform the analysis. For the preparation of LSMs, the method used should be highly precise and unpretentious. This study applied delicate ML practices, namely SVM, LR, and LGR, combined with MCDM techniques TOPSIS and AHP to produce LSMs for the Chitral district. The primary step was to compile an inventory of landslides. The pre-landslide and post-landslide results were processed through a CVA to detect the landslides in the same areas.
Figure 1c shows the final landslide detection map produced after applying the detection results to detect the landslides. The user input in the CVA detection technique is the three PC images. A final landslide inventory map was produced after integrating the generated information and evaluated by the Kappa coefficient of the agreement. The results were also validated by the site examination of the study region. From zones identified as verified no-landslide out of a total of 193 polygons, 11 polygons (4356 pixels) agreed, and the remaining 181 polygons (11,352 pixels) corresponded to verified landslides.
Sixteen landslide-controlling factors were finalized based on the characteristics of the study region and a review of previously published research to produce the LSMs. Different factors contribute in a unique way to the initiation of a landslide event. The geological and topographical factors initiate a landslide. Yang and Qiao [
61] stated that the geological environment is greatly influenced by anthropogenic action. Nevertheless, an open-ended discussion is the accepted strategy for an assortment of landslide conditioning elements [
30]. The SRTM DEM with a spatial resolution of 30 m was considered to extract the geomorphological factors, i.e., elevation, gradient, feature, plain curvature, curvature, profile curvature, flow growth, and curvature. LANDSAT-8 satellite images were used to extract the NDVI and NDWI. Published geological maps of Pakistan were used to acquire lithology and fault data. The earthquake activity map was derived from the seismic hazard map of Pakistan. Road networks were derived from Google Earth Images, soil map data was acquired from FAO, and precipitation data was derived from PMD. Multicollinearity analysis was applied to estimate the correlation between the landslide conditioning factors. The outcomes are listed in
Table 3, which shows that no collinearity exists between the considered parameters; therefore, all factors were used for landslide prediction models. However, the profile curvature achieved the minimum value of TOL and the maximum value of VIF. The value of VIF for profile curvature is 9.23, which shows that the variation for this factor is high and is considerably correlated. There is a potential multicollinearity for profile curvature because its VIF value is very near to the threshold value. Therefore, its contribution for the ML models is low, and it can potentially cause an error in the developed models. Nevertheless, as the VIF and TOL values for profile curvature are within the acceptable range, profile curvature was considered for this analysis.
In the MCDM techniques, the spatial assessment was carried out to rate and prioritize the contributing datasets. For the ML techniques, the training and testing data analysis helped specify the weights of these contributing datasets. Overall, all the models show that precipitation, elevation, flow, slope, and NDWI have significant impacts. There is very little difference between the influences of these conditioning factors for different models. Thus, it can be concluded that the predictive ability of the applied models measures the conditioning factor’s influence on the LSM. However, conditioning factors behave differently towards different models. Additional analyses are essential to comprehensively explore the influences of all landslide conditioning factors.
Flow, precipitation, and NDWI are related to water content, and they are among the most significant influencing factors found in the region. The Chitral district is prone to occasional heavy precipitation and considerable snowfall in the winter. Maqsoom and Aslam [
88] conducted a study in a part of Northern Pakistan and concluded that the surface water flow, groundwater table, and short-duration high-intensity rainfall events trigger landslides. Flow accumulation helps to estimate the extent to which drainage streams can influence the occurrence of landslides. Streams can disturb the stability of a slope through erosion or by saturating the finer slope material fraction, thus causing a rise in the groundwater table [
89,
90]. The NDWI measures moisture accumulation at a particular location [
89]. Higher soil moisture levels may lead to a higher landslide susceptibility than lower moisture levels. Precipitation plays a dominant role in the occurrence of landslides. Many researchers have put forward numerous investigations regarding rainfall-induced landslides, e.g., [
2,
61,
62].
For the slope stability assessment, two important topographical factors considered in the previous studies in northern Pakistan are elevation and slope [
87]. Slope refers to the gradient of ground computed with the horizontal axis and directly impacts the landslides under the action of gravity [
88]. The investigated area exhibits an elevation of up to 7700 m above ground and hosts one of the world’s mightiest mountains, Tirich Mir in the Hindu Kush range. Higher elevation areas and steeper slopes have higher landslide susceptibility. Khan and Haneef [
48], in an investigation carried out in the Chitral district, mentioned that the population in this high-elevation mountainous area is restricted to tributary–junction fans. Closeness to steep valley slopes leaves these fans susceptible to hydrogeomorphic hazards involving floods, debris flows, and landslides.
The trial-and-error process was used to determine the ideal value of each operator for the ML models to obtain the maximum estimation performance. The landslide inventory was split between testing and training datasets to construct the models. The ML techniques were implemented using the R programming language. Both landslide and non-landslide locations were used to implement the ML techniques to produce the LSMs [
36,
91]. The models are applied to calculate the correlation value, which evaluates the functioning of the models [
91]. The LGR, LR, and SVM models were constructed and justified using relevant factors through training and validation datasets. Additionally, the models were formed using a 10-fold cross-validation process to decrease or remove the change and overfitting.
The LSMs for the research area were prepared by exploiting the weights of the datasets obtained from TOPSIS, AHP, LR, SVM, and LGR models. Finally, based on the similar interval technique, all the LSMs of the study area were classed into five susceptibility categories (very high, high, moderate, low, and very low) based on the Natural Break classification system. The final low susceptibility index value was classified as very low, and the high susceptibility index value was classified as very high. The in-between values were classified accordingly. Natural Break classification is a general function of ArcGIS–like most GIS systems—and can be applied for the landslide susceptibility classification of any region, although the absolute susceptibility index values will vary from region to region.
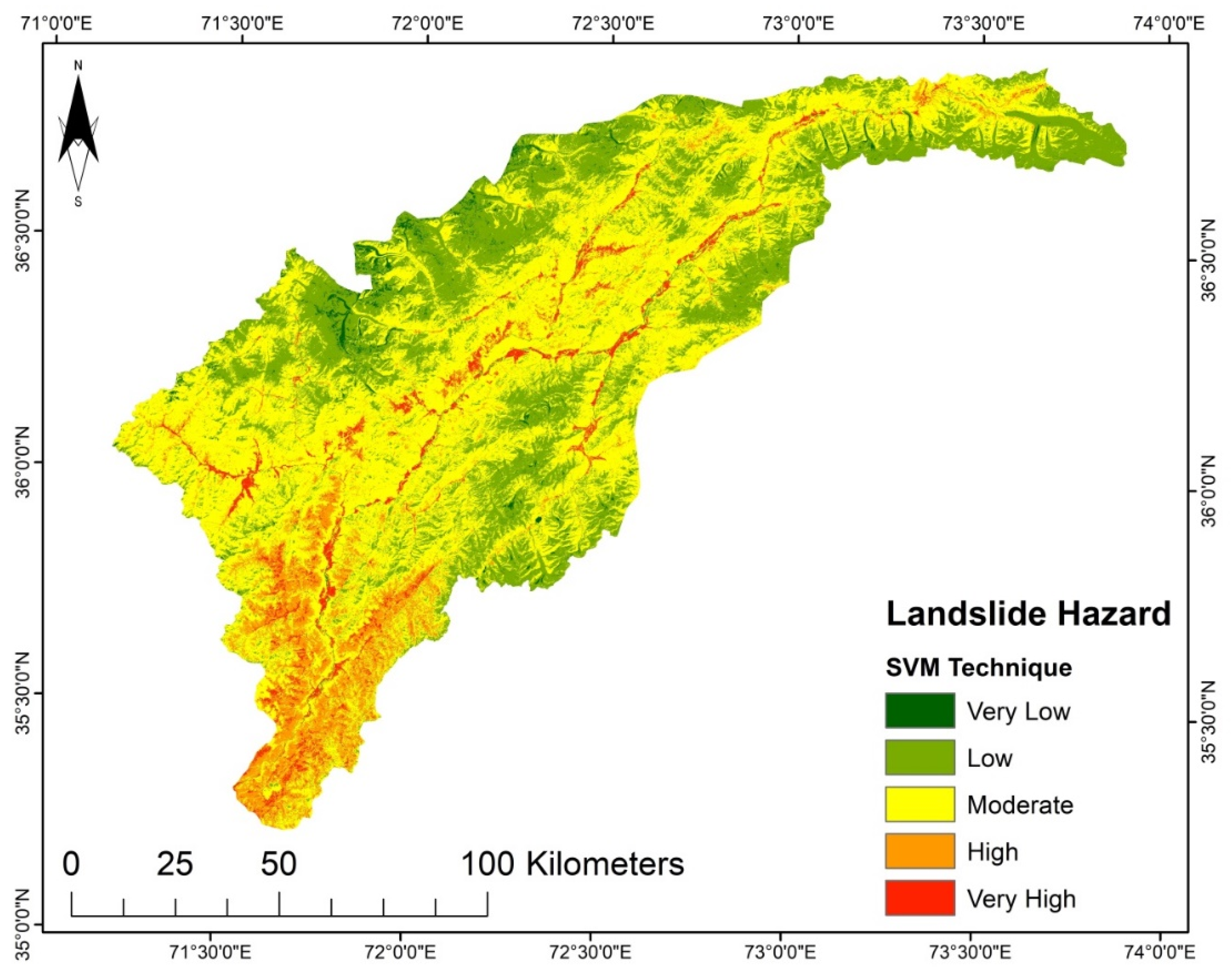
According to the LSM (
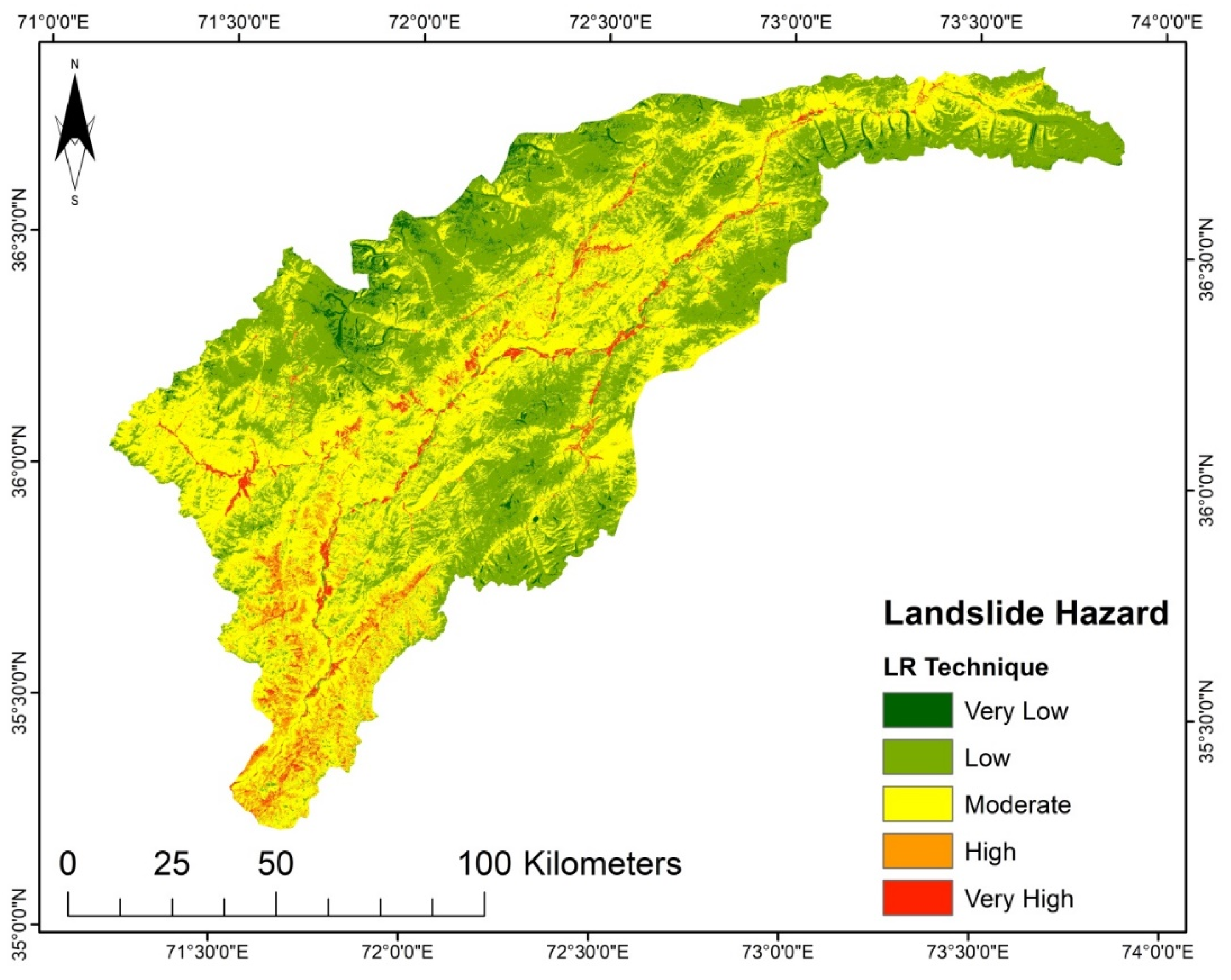
Figure 7) derived from SVM, the areas with elevated steep slopes and high precipitation are highly susceptible to landslides, while the upper north region and lower part fall into the very low to moderate susceptibility zone because of their gentle slope. Contrary to SVM, the LR model was observed to be less complex for training data selection. Based on the landslide inventory data, the LR model strived to fit a linear location and might place the landslide sites into the high and very high susceptibility classes. Likewise, the spatial distribution of hazard zones for the LR model susceptibility map is similar to those based on the other models, but they vary in proportions. The LSM derived from the LR shows that the areas with high flow accumulation and high moisture content in the soil are highly susceptible to landslides. Still, a significant part of the upper north region falls into very low to low susceptibility zones.
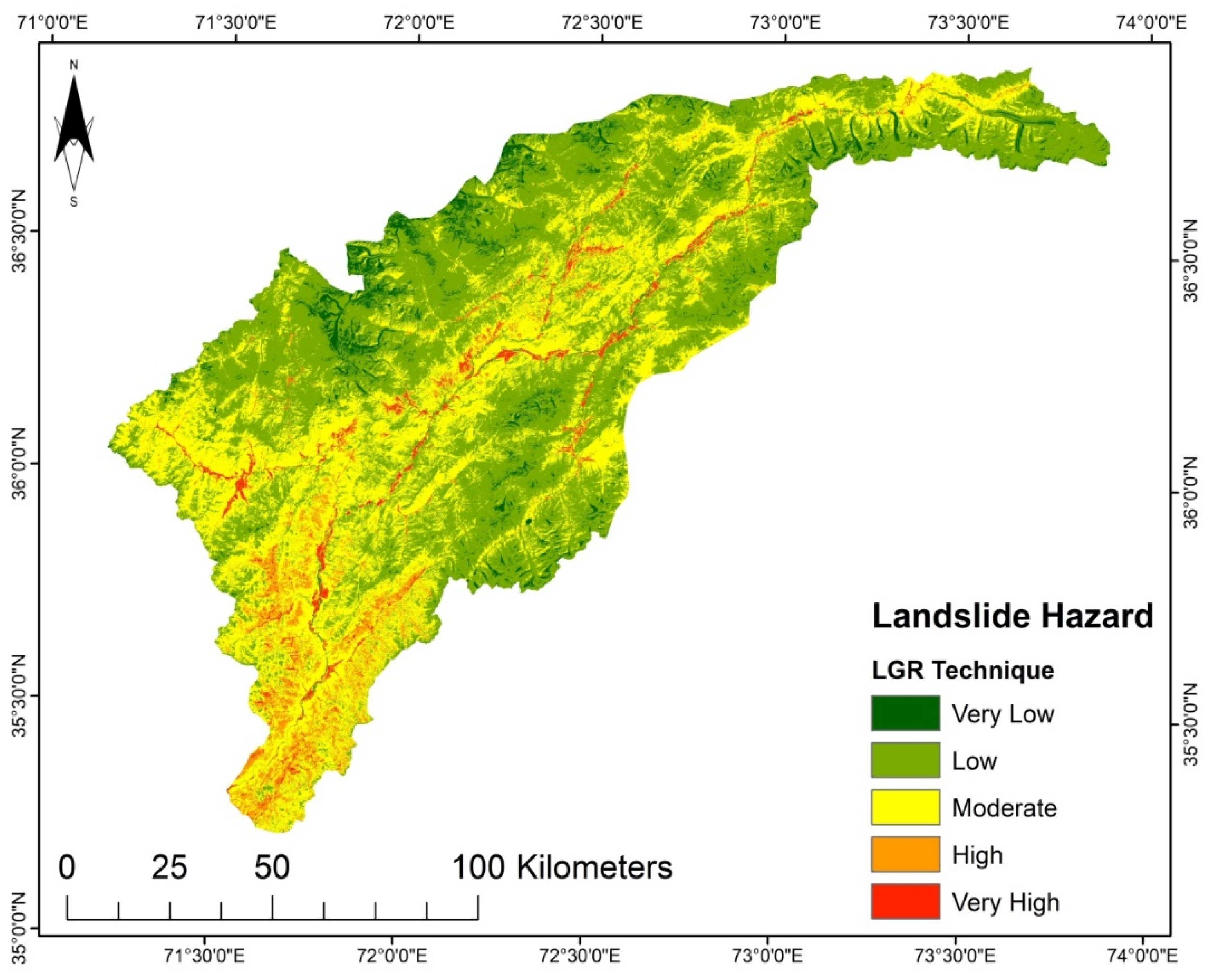
It was determined that the LGR model undoubtedly highlights the interrelation between landslides and instability factors. Besides the SVM and LR, the LGR approach was used due to data availability, and because it is an approach that does not take much time. The LSM derived from the LGR method indicates that the areas with steep slopes and high precipitation are highly susceptible. The upper north region has a very low susceptibility (
Figure 4). Though the AHP technique is primarily based on professional judgment, it is supposed that landslide conditioning factors are not impartial [
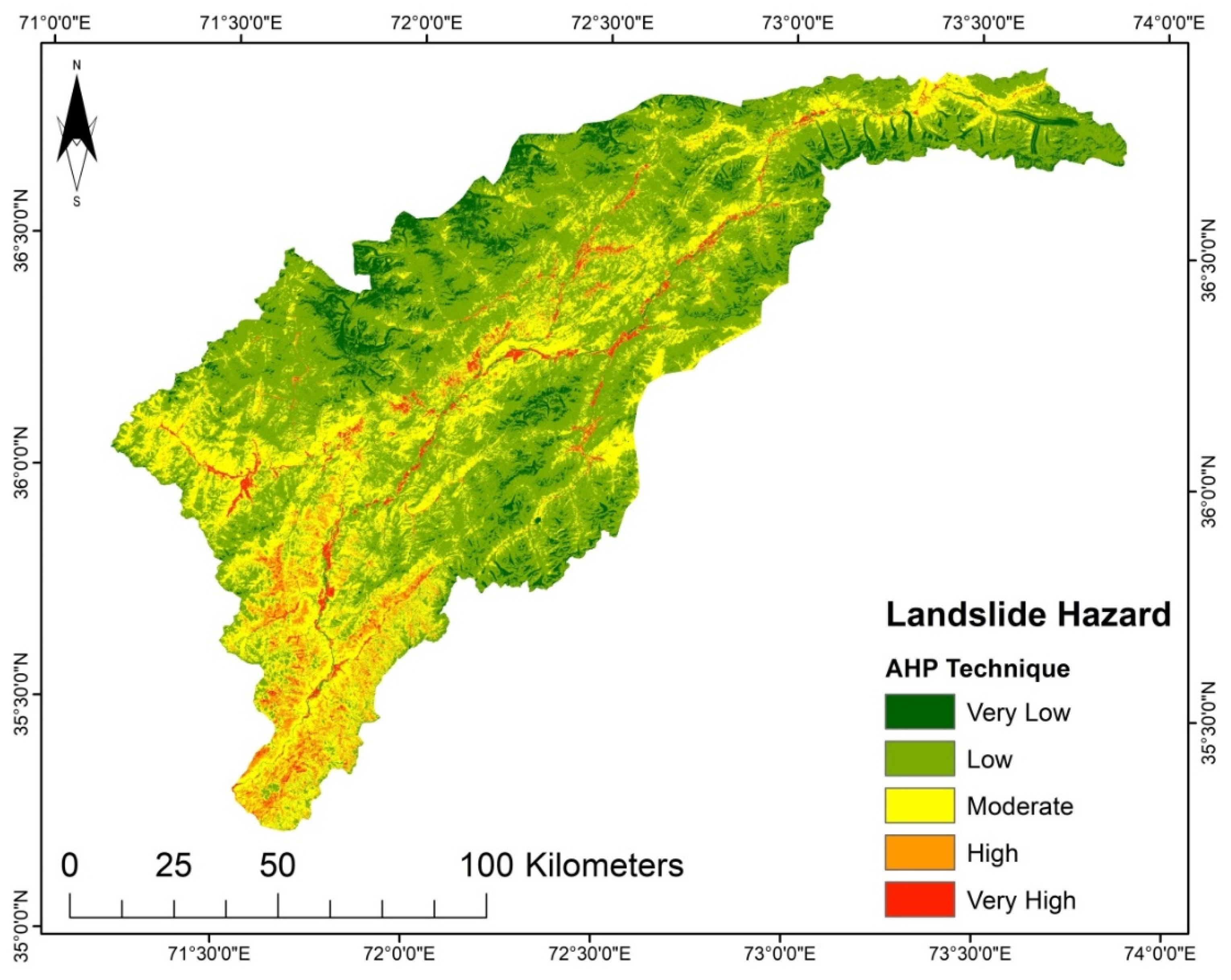
17]. The LSM obtained by AHP shows the high susceptibility regions in areas with steep slopes, high precipitation, and high moisture content, such as in the study area’s middle and lower regions (
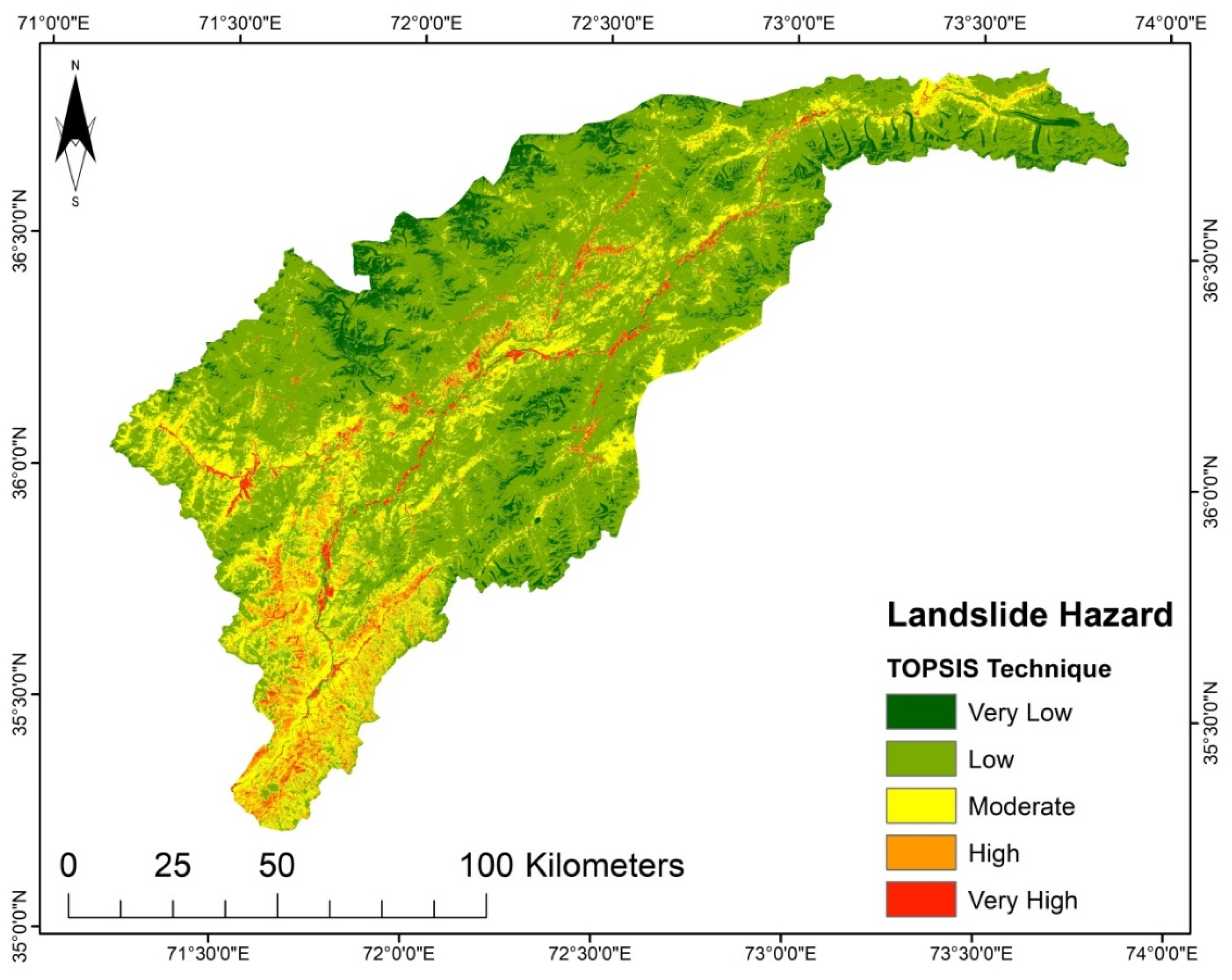
Figure 8). According to the LSM derived from TOPSIS, a significant portion of the area is classed as low to very low susceptibility. Only the lower southwest and a few central regions show a high to very high susceptibility (
Figure 8).
For each of the produced LSM resulting from the practiced models, the categorized five susceptibility groups vary in their percentages and positions in the considered region. The areas in km
2 and the proportions of all the zones of the susceptibility classes are given in
Table 7. The SVM and AHP models have higher area percentages in a very high susceptibility class than the other models. For SVM it is 7.53% (1091.17 km
2), and for AHP it is 7.31% (1059.29 km
2) of the study region that falls under the very high susceptibility class. Furthermore, AHP and TOPSIS have the most incredible area in the low susceptibility class, representing a 9.80% (1420.12 km
2) and 9.18% (1330.27 km
2) portion of the investigation region, respectively. However, with an area of 45.18% (6547.03 km
2) and 43.37% (6284.75 km
2), the LGR and LR models are the dominant ones in the intermediate susceptibility class. Thus, it can be concluded that each technique reacts differently to the conditioning factors and the research area characteristics.
ML models can examine enormous volumes of data and uncover specific trends and patterns that would not be apparent to experts driving MCDM techniques. Moreover, ML models are great at handling multi-variety and multi-dimensional data. They can do this under uncertain or dynamic environments. However, one drawback of ML models is that they require enormous datasets to train on. These should be unbiased, complete, and of good quality. Nevertheless, trading this drawback of massive data requirements for better prediction accuracy is wise when dealing with disastrous modeling hazards.
The known landslide areas are utilized to validate the landslide susceptibility map. The established data on landslide positions were correlated with the landslide hazard maps to carry out the accuracy assessment. Overall, vital training data selection results were revealed by the spatial distribution of the landslide susceptibility zones. The results confirmed acceptable conformity between the hazard maps and the previously presented data on landslide positions, as can be seen from
Table 8. For the landslide susceptibility analysis, the SVM model achieved the maximum implementation accuracy with 88%, followed by the LR model (84%), AHP model (81%), TOPSIS model (79%), and lastly, the LGR model (78%). Even though the used models in this research yielded satisfactory results, it must be noted that the landslide inventory map directly affects the reliability of the products.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}