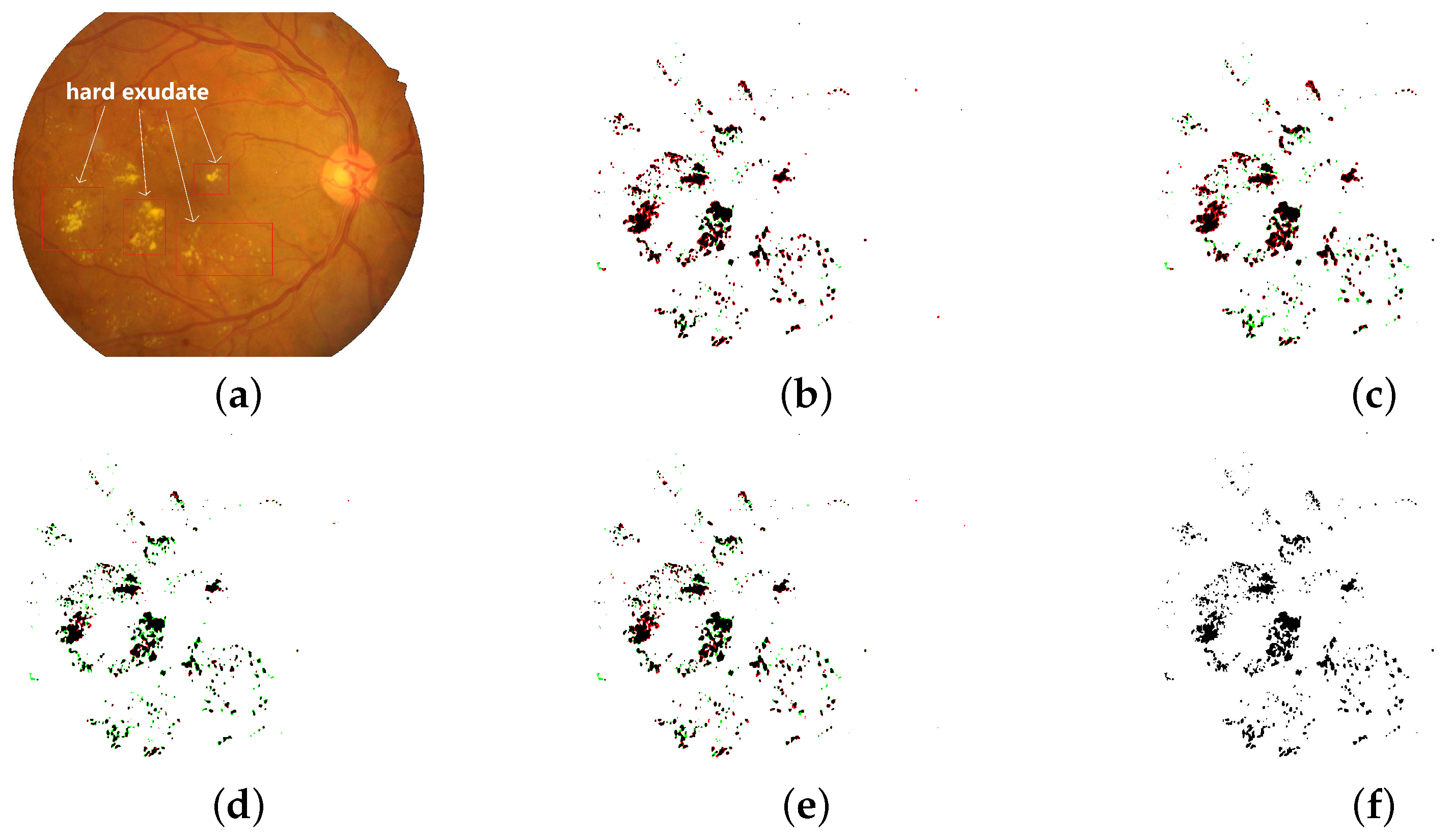
Figure 1.
Hard exudate segmentation binary maps of the LightEyes and other methods on the IDRiD dataset (TPs are marked as black, FPs are marked as red, and FNs are marked as green. JI denotes Jaccard similarity index). (
a) fundus image. (
b) HED [
7] (JI = 0.6663). (
c) L-Seg [
8] (JI = 0.6478) (
d) LWENet [
9] (JI = 0.6952). (
e) LightEyes (JI = 0.7159). (
f) ground truth.
Figure 1.
Hard exudate segmentation binary maps of the LightEyes and other methods on the IDRiD dataset (TPs are marked as black, FPs are marked as red, and FNs are marked as green. JI denotes Jaccard similarity index). (
a) fundus image. (
b) HED [
7] (JI = 0.6663). (
c) L-Seg [
8] (JI = 0.6478) (
d) LWENet [
9] (JI = 0.6952). (
e) LightEyes (JI = 0.7159). (
f) ground truth.
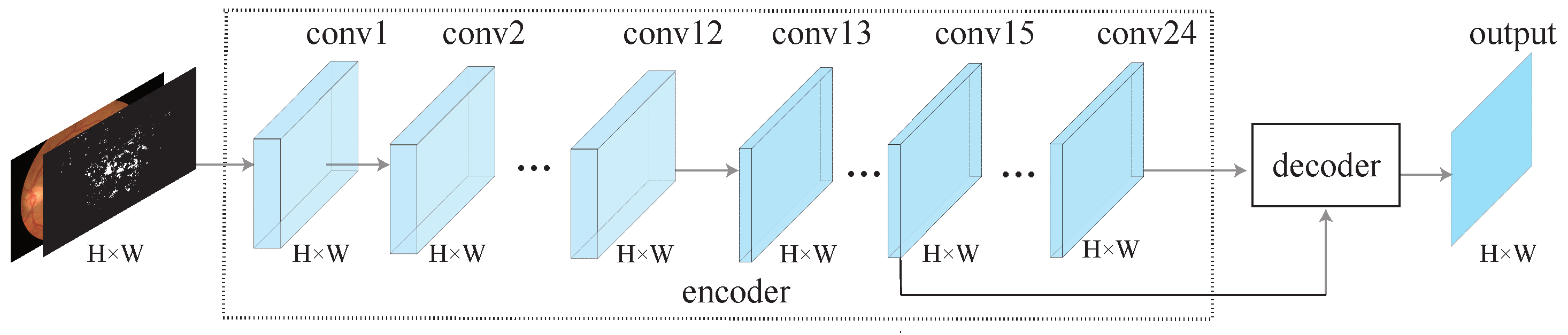
Figure 2.
An overview of the proposed LightEyes. For simplicity, nonlinear activation functions (ReLU) are omitted. The encoder maintains a high resolution representation directly to facilitate the segmentation of tiny lesions and vessels. To be specific, the encoder contains 24 convolutional layers, and the decoder uses features of the intermediate layer to generate output.
Figure 2.
An overview of the proposed LightEyes. For simplicity, nonlinear activation functions (ReLU) are omitted. The encoder maintains a high resolution representation directly to facilitate the segmentation of tiny lesions and vessels. To be specific, the encoder contains 24 convolutional layers, and the decoder uses features of the intermediate layer to generate output.
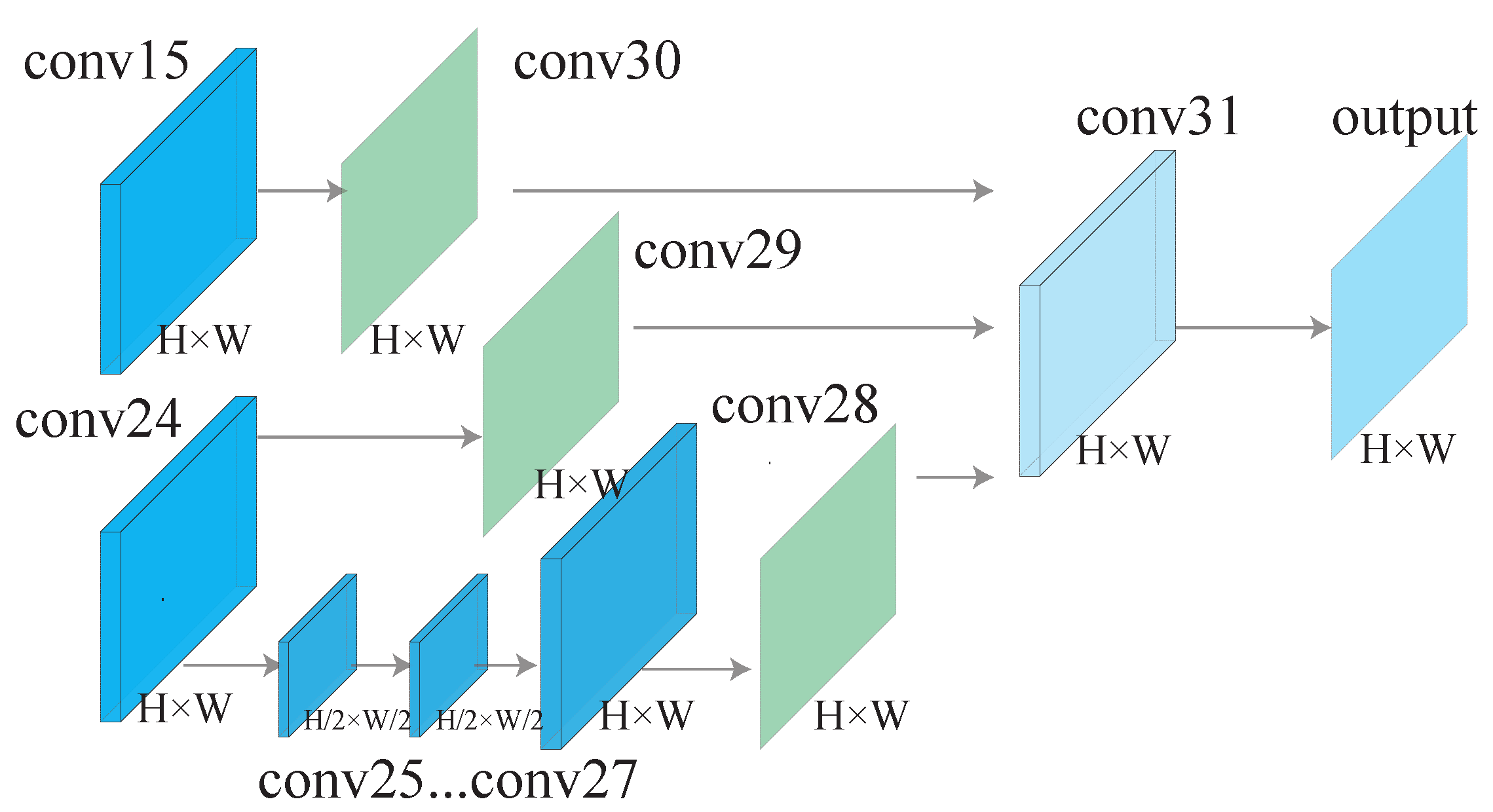
Figure 3.
The decoder architecture. The input of the decoder is conv15 and conv24, which are learnt by the encoder. The decoder consists of three branches, and the output of three branches are further concatenated to generate the output of the LightEyes. Moreover, there are three supervision losses after conv28, conv29, and conv30.
Figure 3.
The decoder architecture. The input of the decoder is conv15 and conv24, which are learnt by the encoder. The decoder consists of three branches, and the output of three branches are further concatenated to generate the output of the LightEyes. Moreover, there are three supervision losses after conv28, conv29, and conv30.
Figure 4.
Lesion segmentation binary maps of the LightEyes and other methods (TPs are marked as black, FPs are marked as red, and FNs are marked as green). The first and the second column denote EX segmentation on the IDRiD dataset, and the third row denotes MA segmentation on the IDRiD datasets. (a) fundus image (IDRiD). (b) fundus image (e-ophtha EX). (c) fundus image (IDRiD). (d) ground truth (EX). (e) ground truth (E1). (f) ground truth (M1). (g) HED (F1 = 0.8153, JI = 0.6881). (h) HED (F1 = 0.7645, JI = 0.6192). (i) HED (F1 = 0.4950, JI = 0.3280). (j) LWENet (F1 = 0.8396, JI = 0.7236). (k) LWENet (F1 = 0.7104, JI = 0.5529). (l) L-Seg (F1 = 0.5367, JI = 0.3668). (m) LightEyes (F1 = 0.8433, JI = 0.7289). (n) [LightEyes (F1 = 0.7827, JI = 0.6457). (o) LightEyes (F1 = 0.6177, JI = 0.4468).
Figure 4.
Lesion segmentation binary maps of the LightEyes and other methods (TPs are marked as black, FPs are marked as red, and FNs are marked as green). The first and the second column denote EX segmentation on the IDRiD dataset, and the third row denotes MA segmentation on the IDRiD datasets. (a) fundus image (IDRiD). (b) fundus image (e-ophtha EX). (c) fundus image (IDRiD). (d) ground truth (EX). (e) ground truth (E1). (f) ground truth (M1). (g) HED (F1 = 0.8153, JI = 0.6881). (h) HED (F1 = 0.7645, JI = 0.6192). (i) HED (F1 = 0.4950, JI = 0.3280). (j) LWENet (F1 = 0.8396, JI = 0.7236). (k) LWENet (F1 = 0.7104, JI = 0.5529). (l) L-Seg (F1 = 0.5367, JI = 0.3668). (m) LightEyes (F1 = 0.8433, JI = 0.7289). (n) [LightEyes (F1 = 0.7827, JI = 0.6457). (o) LightEyes (F1 = 0.6177, JI = 0.4468).
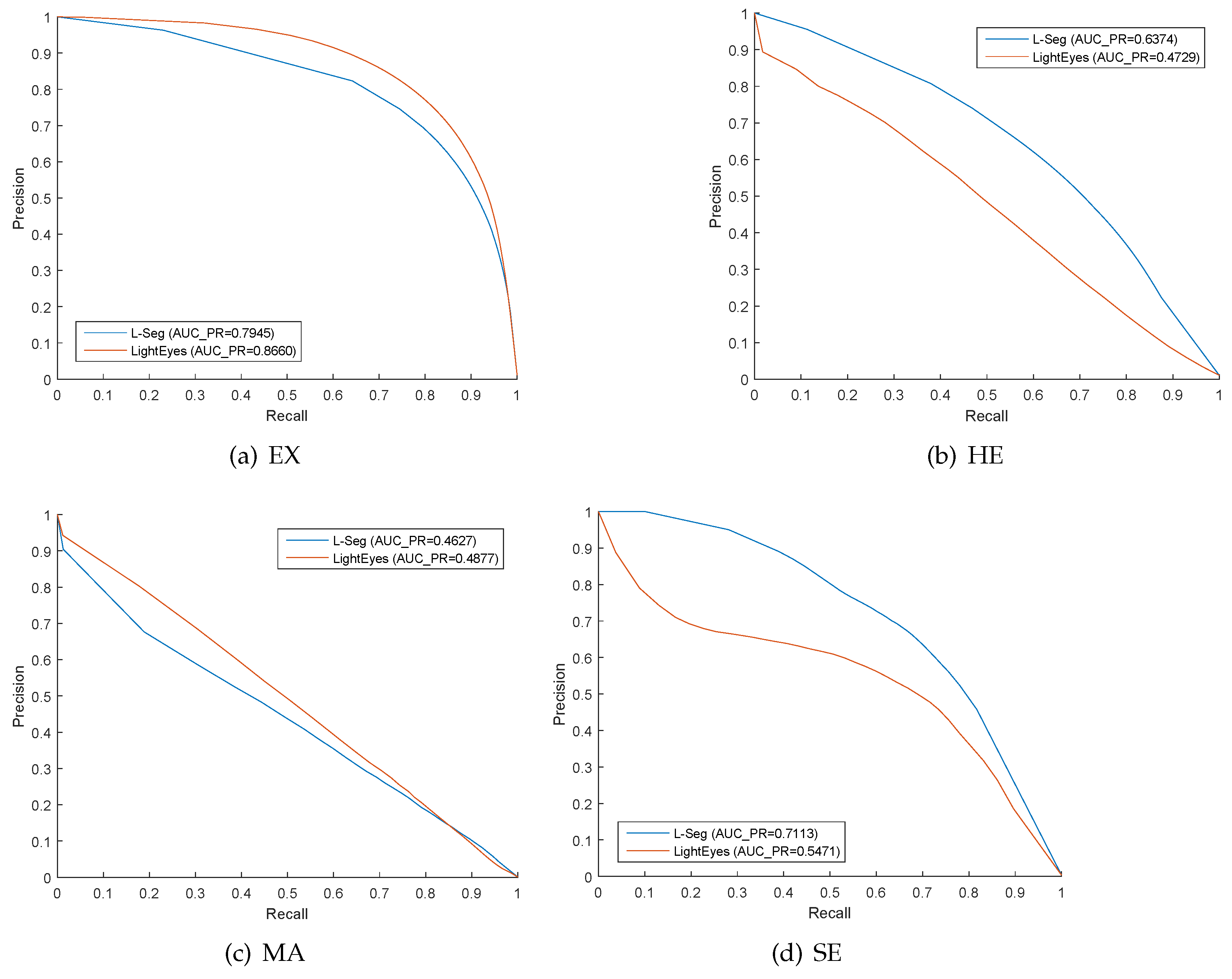
Figure 5.
P–R curves for hard exudate (EX), hemorrhage (HE), microaneurysms (MA), and soft exudate (SE) on IDRiD dataset.
Figure 5.
P–R curves for hard exudate (EX), hemorrhage (HE), microaneurysms (MA), and soft exudate (SE) on IDRiD dataset.
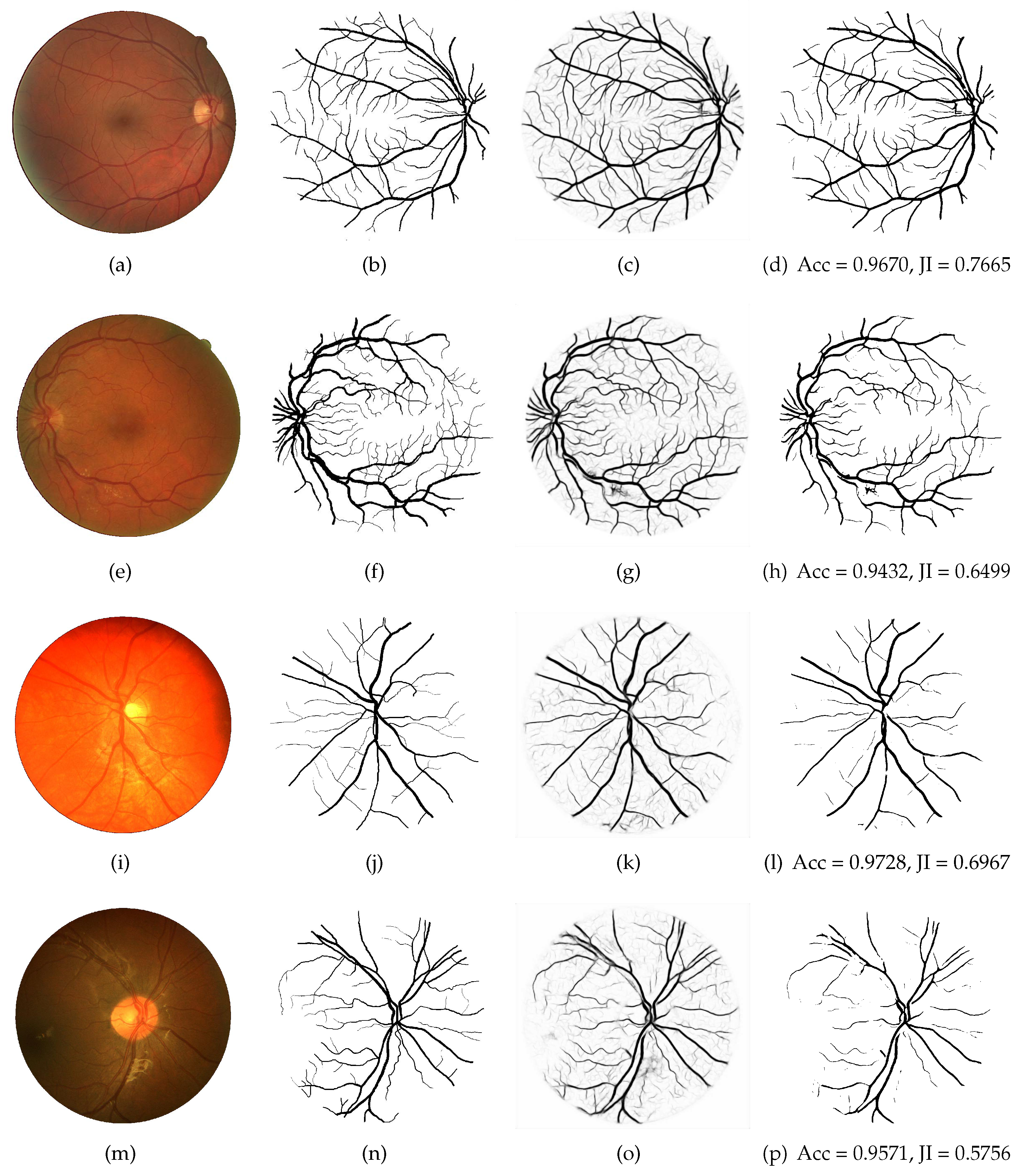
Figure 6.
Examples of the best and worst vessel segmentation results by the proposed the LightEyes on images from the DRIVE and CHASE_DB1 datasets. The first and second rows correspond to the highest and lowest accuracy on the DRIVE, and the third and fourth rows correspond to the highest and lowest accuracy on the CHASE_DB1. From column 1 to 4: original fundus images (a,e,i,m), ground truth (b,f,j,n), probability maps (c,g,k,o) and binary maps (d,h,l,p).
Figure 6.
Examples of the best and worst vessel segmentation results by the proposed the LightEyes on images from the DRIVE and CHASE_DB1 datasets. The first and second rows correspond to the highest and lowest accuracy on the DRIVE, and the third and fourth rows correspond to the highest and lowest accuracy on the CHASE_DB1. From column 1 to 4: original fundus images (a,e,i,m), ground truth (b,f,j,n), probability maps (c,g,k,o) and binary maps (d,h,l,p).
Table 2.
Configurations of the LightEyes (H and W below represent the height and width of the input image).
Table 2.
Configurations of the LightEyes (H and W below represent the height and width of the input image).
| | Layer | Input Size | Output Size | #Filters | #Param | Ops (H × W) |
|---|
| Encoder | conv1 | H × W × 3 | H × W × 16 | 16 | 448 | 512 |
| convi () | H × W × 16 | H × W × 16 | 16 | 2320 | 2800 |
| conv13 | H × W × 16 | H × W × 8 | 8 | 1160 | 1400 |
| convi () | H × W × 8 | H × W × 8 | 8 | 584 | 696 |
| Decoder | Pooling | H × W × 8 | H/2 × W/2 × 8 | - | 0 | - |
| convi () | H/2 × W/2 × 8 | H/2 × W/2 × 8 | 8 | 584 | 174 |
| conv28 | H/2 × W/2 × 8 | H/2 × W/2 | 1 | 73 | 21.75 |
| conv29 | H × W × 8 | H × W | 1 | 73 | 87 |
| conv30 | H × W × 8 | H × W | 1 | 73 | 87 |
| conv31 | H × W × 3 | H × W | 1 | 28 | 32 |
| | total | | | 316 | 35,551 | 41,117.75 |
Table 3.
Hyperparameter settings of LightEyes and comparison methods.
Table 3.
Hyperparameter settings of LightEyes and comparison methods.
| Methods | Dataset | Optimizer | Learning Rate | Iteration | Batch Size |
|---|
| L-Seg [8] | IDRiD | SGD | | 25,000 | 1 |
| e-ophtha EX | SGD | | 20,000 | 1 |
| HED [7] | IDRiD | SGD | | 25,000 | 1 |
| e-ophtha EX | SGD | | 20,000 | 1 |
| LWENet [9] | IDRiD | SGD | | 160,000 | 1 |
| e-ophtha EX | SGD | | 160,000 | 1 |
| LightEyes | IDRiD | ADAM | | 140,000 | 1 |
| e-ophtha EX | ADAM | | 140,000 | 1 |
| DRIVE | ADAM | | 60,000 | 1 |
| CHASE_DB1 | ADAM | | 60,000 | 1 |
| STARE | ADAM | | 20,000 | 1 |
Table 4.
Comparison of the LightEyes and other models on lesion segmentation (fps = , where is the inference time (exudate IO) of the model when the input image size of the model is 960 × 1440).
Table 4.
Comparison of the LightEyes and other models on lesion segmentation (fps = , where is the inference time (exudate IO) of the model when the input image size of the model is 960 × 1440).
| Model | Pre-Train | #Params(M) | fps | MA (IDRiD) | EX (IDRiD) | EX (e-ophtha EX) |
|---|
| Pr | Re | F1 | Pr | Re | F1 | Pr | Re | F1 |
|---|
| HED [9] | Y | 14.3 | 5.9 | 0.4291 | 0.4799 | 0.4474 | 0.7414 | 0.7618 | 0.7515 | 0.5049 | 0.5727 | 0.5336 |
| FCRN [9] | Y | 22.5 | 7.1 | 0.3542 | 0.3312 | 0.3423 | 0.6018 | 0.6862 | 0.6412 | 0.3807 | 0.5073 | 0.4326 |
| L-Seg [8] | Y | 14.3 | 5.9 | 0.4677 | 0.4720 | 0.4698 | 0.7436 | 0.7479 | 0.7457 | – | – | – |
| LWENet [9] | Y | 1.9 | 11.1 | 0.4221 | 0.4162 | 0.4191 | 0.7826 | 0.7803 | 0.7815 | 0.4812 | 0.5147 | 0.4960 |
| LightEyes | N | 0.036 | 14.3 | 0.4960 | 0.4936 | 0.4948 | 0.7940 | 0.7933 | 0.7937 | 0.5409 | 0.5424 | 0.5417 |
Table 5.
Segmentation results of vessel on the DRIVE dataset (best results shown in bold).
Table 5.
Segmentation results of vessel on the DRIVE dataset (best results shown in bold).
| Input | Model | Se | Sp | Acc | AUC | JI | fps |
|---|
| Image | DRIU [32] | 0.7855 | 0.9799 | 0.9552 | 0.9793 | 0.6904 | 15.1 |
| BTS-DSN [21] | 0.7800 | 0.9806 | 0.9551 | 0.9796 | 0.6884 | 14.3 |
| LightEyes | 0.7896 | 0.9805 | 0.9562 | 0.9796 | 0.6965 | 51.3 |
| Patch | Three-stage FCN [29] | 0.7631 | 0.9820 | 0.9538 | 0.9750 | 0.6793 | – |
| MS-NFN [19] | 0.7844 | 0.9819 | 0.9567 | 0.9807 | 0.6978 | 0.1 |
| FCN [18] | 0.8039 | 0.9804 | 0.9576 | 0.9821 | 0.7087 | 0.5 |
| DUNet [22] | 0.7963 | 0.9800 | 0.9566 | 0.9802 | 0.7003 | 0.07 |
| Vessel-Net [46] | 0.8038 | 0.9802 | 0.9578 | 0.9821 | 0.7077 | – |
Table 6.
Segmentation results of vessel on the CHASE_DB1 dataset (best results shown in bold).
Table 6.
Segmentation results of vessel on the CHASE_DB1 dataset (best results shown in bold).
| Input | Model | Se | Sp | Acc | AUC | JI | fps |
|---|
| Image | BTS-DSN [21] | 0.7888 | 0.9801 | 0.9627 | 0.9840 | 0.6579 | 11.7 |
| LightEyes | 0.7709 | 0.9841 | 0.9647 | 0.9829 | 0.6651 | 19.6 |
| Patch | Three-stage FCN [29] | 0.7641 | 0.9806 | 0.9607 | 0.9776 | 0.6399 | – |
| MS-NFN [19] | 0.7538 | 0.9847 | 0.9637 | 0.9825 | 0.6538 | – |
| DUNet [22] | 0.8155 | 0.9752 | 0.9610 | 0.9804 | 0.6534 | 0.02 |
| Vessel-Net [46] | 0.8132 | 0.9814 | 0.9661 | 0.9860 | 0.6857 | – |
Table 7.
Segmentation results of vessel on the STARE dataset (best results shown in bold).
Table 7.
Segmentation results of vessel on the STARE dataset (best results shown in bold).
| Input | Model | Se | Sp | Acc | AUC | JI | fps |
|---|
| Image | DeepVessel [42] | 0.7412 | – | 0.9585 | – | – | – |
| BTS-DSN [21] | 0.8201 | 0.9828 | 0.9660 | 0.9872 | 0.7147 | 10.6 |
| DRIU [32] | 0.8036 | 0.9845 | 0.9658 | 0.9773 | 0.7097 | 11.6 |
| LightEyes | 0.7830 | 0.9864 | 0.9653 | 0.9820 | 0.7012 | 43.5 |
Table 8.
Comparison of proposed method and other vessel segmentation models (in the table, fps = , where is the forward propagation time of a single image with size 584 × 565).
Table 8.
Comparison of proposed method and other vessel segmentation models (in the table, fps = , where is the forward propagation time of a single image with size 584 × 565).
| Model | Input | Pre-Train | Pre-Process | Post-Process | #Params (M) | fps | Acc |
|---|
| DRIVE | CHASE_DB1 | STARE |
|---|
| Three-stage FCN [29] | patch | No | Yes | Yes | 20.4 | – | 0.9538 | 0.9607 | – |
| Vessel-Net [46] | patch | No | Yes | Yes | – | – | 0.9578 | 0.9661 | – |
| MS-NFN [19] | patch | No | Yes | Yes | 0.4 | 0.1 | 0.9567 | 0.9637 | – |
| DUNet [22] | patch | No | Yes | Yes | 0.9 | 0.07 | 0.9566 | 0.9610 | – |
| FCN [18] | patch | No | Yes | Yes | 0.2 | 0.5 | 0.9576 | – | – |
| DRIU [32] | image | Yes | No | No | 7.8 | 15.1 | 0.9552 | – | 0.9658 |
| BTS-DSN [21] | image | Yes | No | No | 7.8 | 14.3 | 0.9551 | 0.9627 | 0.9660 |
| MobileNet-Fundus | image | Yes | No | No | 0.27 | 43.5 | 0.9518 | 0.9560 | 0.9473 |
| LightEyes | image | No | No | No | 0.036 | 51.3 | 0.9562 | 0.9647 | 0.9653 |
Table 9.
Comparison with MobileNet on vessel segmentation (Best results are bold).
Table 9.
Comparison with MobileNet on vessel segmentation (Best results are bold).
| Dataset | Model | Se | Sp | Acc | AUC | JI | fps |
|---|
| DRIVE | MobileNet-Fundus | 0.6922 | 0.9772 | 0.9518 | 0.9570 | 0.5986 | 43.5 |
| LightEyes | 0.7896 | 0.9805 | 0.9562 | 0.9796 | 0.6965 | 51.3 |
| CHASE_DB1 | MobileNet-Fundus | 0.7006 | 0.9817 | 0.9560 | 0.9722 | 0.5922 | 25.0 |
| LightEyes | 0.7709 | 0.9841 | 0.9647 | 0.9829 | 0.6651 | 19.6 |
| STARE | MobileNet-Fundus | 0.6522 | 0.9816 | 0.9473 | 0.9604 | 0.5633 | 37.6 |
| LightEyes | 0.7830 | 0.9864 | 0.9653 | 0.9820 | 0.7012 | 43.5 |
Table 10.
Comparison with MobileNet on lesion segmentation (Best results are bold).
Table 10.
Comparison with MobileNet on lesion segmentation (Best results are bold).
| Lesion | Model | Pr | Re | F1 | JI | fps |
|---|
| MA | MobileNet-Fundus | 0.4072 | 0.4040 | 0.4056 | 0.2544 | 19.1 |
| LightEyes | 0.4960 | 0.4936 | 0.4948 | 0.3287 | 14.3 |
| EX(IDRiD) | MobileNet-Fundus | 0.7418 | 0.7381 | 0.7400 | 0.5872 | 19.1 |
| LightEyes | 0.7940 | 0.7933 | 0.7937 | 0.6579 | 14.3 |
Table 11.
Fps of the LightEyes and other models on Cambricon-1A and Cambricon-MLU270.
Table 11.
Fps of the LightEyes and other models on Cambricon-1A and Cambricon-MLU270.
| Hardware | Resolution | VGGNet-Based | ResNet-Based | LightEyes | LightEyes_A3 | LightEyes_A2 | LightEyes_A1 |
|---|
| L-Seg | BTS-DSN | FCRN |
|---|
| Cambricon-1A | 584 × 565 | 0.5 | 0.5 | 1.7 | 1.6 | 2.6 | 3.2 | 4.2 |
| 712 × 1072 | 0.2 | 0.2 | 0.7 | 0.7 | 1.2 | 1.4 | 1.9 |
| 960 × 999 | 0.2 | – | 0.5 | 0.6 | 0.9 | 1.1 | 1.6 |
| 1280 × 1280 | – | – | 0.3 | 0.3 | 0.6 | 0.6 | 0.9 |
| Cambricon-MLU270 | 584 × 565 | 7.9 | 7.3 | 3.4 | 3.9 | 4.5 | 6.4 | 9.5 |
| 712 × 1072 | 3.1 | 2.8 | 1.5 | 1.7 | 1.9 | 2.8 | 4.1 |
| 960 × 999 | 2.6 | 2.2 | 1.2 | 1.3 | 1.5 | 2.2 | 3.2 |
| 1280 × 1280 | 1.5 | 1.3 | 0.7 | 0.8 | 0.9 | 1.3 | 1.9 |
| Cambricon-MLU100 | 584 × 565 | 1.9 | 1.7 | 4.8 | 4.8 | 6.0 | 6.3 | 8.5 |
| 712 × 1072 | 0.8 | 0.6 | 2.4 | 2.1 | 2.6 | 2.8 | 3.8 |
| 960 × 999 | 0.7 | 0.5 | 1.9 | 1.7 | 2.1 | 2.2 | 3.0 |
| 1280 × 1280 | 0.4 | 0.3 | 1.1 | 1.0 | 1.1 | 1.2 | 1.7 |
Table 12.
Segmentation results when varying the number of filters in LightEyes (NC denotes the number of convolutional filters per convolution layer in the backbone of the LightEyes, and we use AUC/F1-score to evaluate vessel/lesion segmentation maps). Best results are bold.
Table 12.
Segmentation results when varying the number of filters in LightEyes (NC denotes the number of convolutional filters per convolution layer in the backbone of the LightEyes, and we use AUC/F1-score to evaluate vessel/lesion segmentation maps). Best results are bold.
| Datasets | NC = 2 | NC = 4 | NC = 8 | LightEyes | NC = 32 | NC = 48 | NC = 64 |
|---|
| DRIVE | – | 0.9734 | 0.9794 | 0.9796 | 0.9796 | 0.9797 | – |
| CHASE_DB1 | 0.9535 | 0.9722 | 0.9798 | 0.9829 | 0.9818 | 0.9805 | – |
| STARE | 0.9359 | 0.9744 | 0.9798 | 0.9820 | 0.9863 | 0.9843 | – |
| IDRiD (EX) | 0.6741 | 0.7775 | 0.7868 | 0.7937 | – | – | – |
| IDRiD (MA) | – | 0.4769 | 0.4956 | 0.4948 | – | – | – |
Table 13.
Segmentation results when varying the network depth (NL denotes the number of convolutional layers in the backbone of the LightEyes, and we use AUC/F1-score to evaluate vessel/lesion segmentation maps). Best results are bold.
Table 13.
Segmentation results when varying the network depth (NL denotes the number of convolutional layers in the backbone of the LightEyes, and we use AUC/F1-score to evaluate vessel/lesion segmentation maps). Best results are bold.
| Datasets | NL = 6 | NL = 12 | NL = 18 | NL = 24 | NL = 30 | NL = 36 |
|---|
| DRIVE | 0.9703 | 0.9746 | 0.9754 | 0.9770 | 0.9752 | 0.9735 |
| CHASE_DB1 | 0.9539 | 0.9739 | 0.9751 | 0.9763 | 0.9737 | 0.9769 |
| STARE | 0.9419 | 0.9650 | 0.9634 | 0.9729 | 0.9781 | 0.9681 |
| IDRiD (EX) | 0.7452 | 0.7610 | 0.7849 | 0.7689 | – | – |
| IDRiD (MA) | 0.4618 | 0.4711 | 0.4669 | – | – | – |
Table 14.
Comparison of segmentation results and the number of parameters (Fps was measured under input with size 712 × 1072 and 584 × 565 on the IDRiD and DRIVE). Best results are bold.
Table 14.
Comparison of segmentation results and the number of parameters (Fps was measured under input with size 712 × 1072 and 584 × 565 on the IDRiD and DRIVE). Best results are bold.
| Model | Params | MA | EX(IDRiD) | DRIVE |
|---|
| Pr | Re | F1 | fps | Pr | Re | F1 | Se | Sp | Acc | AUC | fps |
|---|
| LightEyes_A1 | 28369 | 0.4864 | 0.4797 | 0.4830 | 36.4 | 0.7533 | 0.7561 | 0.7547 | 0.7769 | 0.9800 | 0.9540 | 0.9760 | 79.4 |
| LightEyes_A2 | 33625 | 0.4913 | 0.4973 | 0.4943 | 27.8 | 0.7833 | 0.7855 | 0.7844 | 0.7849 | 0.9808 | 0.9558 | 0.9788 | 58.5 |
| LightEyes_A3 | 35377 | 0.4903 | 0.4935 | 0.4919 | 27.0 | 0.7937 | 0.7932 | 0.7934 | 0.7783 | 0.9814 | 0.9555 | 0.9788 | 56.2 |
| LightEyes | 35551 | 0.4960 | 0.4936 | 0.4948 | 25.6 | 0.7940 | 0.7933 | 0.7937 | 0.7896 | 0.9805 | 0.9562 | 0.9796 | 51.3 |
Table 15.
The performance of the LightEyes when varying the number of training samples on the hard exudate segmentation task (IDRiD dataset).
Table 15.
The performance of the LightEyes when varying the number of training samples on the hard exudate segmentation task (IDRiD dataset).
| Proportion | Pr | Re | F1 |
|---|
| 16.7% (9/54) | 0.7483 | 0.7488 | 0.7486 |
| 33.3% (18/54) | 0.7771 | 0.7762 | 0.7766 |
| 50% (27/54) | 0.7842 | 0.7852 | 0.7847 |
| 66.7% (36/54) | 0.7841 | 0.7838 | 0.7839 |
| 83.3% (45/54) | 0.7843 | 0.7820 | 0.7831 |
| 100% (54/54) | 0.7940 | 0.7933 | 0.7937 |
Table 16.
The performance of the LightEyes when varying the number of training samples on the vessel segmentation task (DRIVE dataset).
Table 16.
The performance of the LightEyes when varying the number of training samples on the vessel segmentation task (DRIVE dataset).
| Proportion | Se | Sp | AUC |
|---|
| 25% (5/20) | 0.7713 | 0.9799 | 0.9757 |
| 50% (10/20) | 0.7758 | 0.9810 | 0.9779 |
| 75% (15/20) | 0.7796 | 0.9806 | 0.9784 |
| 100% (20/20) | 0.7896 | 0.9805 | 0.9796 |
Table 17.
The performance of the LightEyes and comparison with other methods on the Messidor dataset.
Table 17.
The performance of the LightEyes and comparison with other methods on the Messidor dataset.
| Models | DeepLab-v2 [33] | UNet [49] | LightEyes |
|---|
| Dice Index | 0.9197 | 0.9567 | 0.9358 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





