Abstract
In this work, a new hydroelectric basin modelling approach is described and applied to the Pontecosi basin, Italy. Several types of data sources were used to learn the model: a number of weather stations, satellite observations, the reanalysis dataset, and basin data. With the goal of predicting the water level of the basin, the model was composed by three cascade modules. Firstly, different spatial interpolation methods, such as Kriging, Radial Basis Function, and Natural Neighbours, were compared and applied to interpolate the weather stations data nearby the basin area to infer the main environmental variables (air temperature, air humidity, precipitation, and wind speed) in the basin area. Then, using these variables as inputs, a neural network was trained to predict the mean soil moisture concentration over the area, also to improve the low availability due to satellite orbits. Finally, a non-linear auto regressive exogenous input (NARX) model was trained to simulate the basin level with different prediction horizons, using the data from the previous modules and past basin data (water level, discharge flow rate, and turbine flow rate). Accurate predictions of the basin water level were achieved within 1 to 6 h ahead, with mean absolute errors (MAE) between 2 cm and 10 cm, respectively.
1. Introduction
Water is one of most important resources of the world. Monitoring rivers, basins, and seas is a very important challenge for many different applications, from agricultural utilization to electric energy production [1]. Wrong management can lead to natural calamities, such as floods and dry rivers [2,3]. From an energy production point of view, basin level, and turbine water flow are deeply linked, and weather conditions can influence not only the basin level but also the plant operations [4]. Traditional physical models often struggle with parameters evaluation, and in any case a large measurement campaign must be conducted in the geographic area of study. Machine learning and black box modelling can overcome this problem, and for this reason a large number of studies in the literature related to water level forecasting and monitoring focus on artificial intelligence methods [5,6]. Main findings in [6] are:
- The results indicated that the applied forecasting models are efficient and trustworthy,
- Cross-station modeling revealed an optimistic modeling strategy for learning transfer modeling of using information of nearby site.
The second point above is one of the main motivations of this work.
A monthly [7,8,9,10,11] or daily [12,13,14,15] average water level time series is usually considered for lakes and basins, while a prediction within hours [16,17] or even minutes [18] is often necessary in the case floods. To predict water levels, most of these works use past measurements, although from different sources, of the water level itself, in an auto-regressive fashion. Some works also consider rainfall [14,18], and temperature as well [8]. Other than using local sensors, water level can be monitored by satellite altimeters [15] or radars [10,15]. Some of the cited works use feed-forward neural networks to predict the water level [9,16]. Very good prediction performance is reported in [16], with errors between 0.06 m and 0.12 m for 1 to 2 hours-ahead, respectively, using water level data from multiple stations, indicating that adding more data sources can be beneficial. Other works use support vector machines (SVM) [7,12] or adaptive neuro-fuzzy inference system (ANFIS) [8,13]. In the case of hourly (or less) forecast horizons, NARX neural networks are better suited [17,18]. Some works [11] focus on clustering algorithms and monitoring [10], while recently developed deep learning methods have also been applied [15,19]. In particular in [19] the LSTM (long short-term memory) approach, which is recent methodology belonging to the deep learning paradigm, was found to be more effective than SVM. Other methods, such as boosted decision trees and Bayesian linear regression were reported to be successful for daily water level prediction in a hydroelectric basin using also rainfall data as an input [14]. Successful applications of machine learning approaches for time series forecasting in the energy sector can be found also in the case of electricity price prediction [20], where Kalman filter and Echo State Networks are used, electrical load prediction [21], where a variant of the K-Nearest Neighbours algorithm is proposed, as well as prediction of the power generation from photovoltaic plants [22], and wind plants [23]. In [24], the Kalman filter is successfully applied as a data assimilation scheme for water level forecasting.
In this work, we focus on the Garfagnana valley hydroelectrical system, which is composed by several basins and power plants connected to each other. Managing the water resource all over the valley is a complex task, and knowing in advance the level of the basins would be of great convenience. Moreover, the need of an hydrological model is justified by the environmental challenges that nowadays are constantly on the spotlight: knowing the status of the water resource can be crucial to avoid natural calamities and to maintain the environmental flow.
The main objective of this work is to develop an accurate hourly forecasting model of the water level in a hydroelectric basin, exploiting a much larger number of data sources with respect to most of the literature.
In fact, a first contribution of this work is that a considerably large number of variables was used to create the model with respect to many other works related to water level forecasting. The data include several weather variables (temperature, humidity, precipitation, and wind speed) from 14 weather stations (WS) scattered throughout the geographical area of the basin (northwestern area of Tuscany), satellite measurements of the soil moisture concentration (SMC), reanalysis data of net solar radiance and snow depth, and hourly values of basin level, turbine flow rate and discharge flow rate. Moreover, data were collected for almost 19 consecutive months, 631 days, starting 6 June 2017, and ending 27 February 2019. The datasets and the variables were selected to address the main objective which is to improve the accuracy of the water level forecasting in the basin. Each one of the selected variables has a direct or indirect effect on the water level in the basin, where soil moisture concentration, precipitation, temperature, and air humidity are the most effective, besides the direct basin activity, such as turbine flow rate and discharge flow rate. Using a number of different sources was a main guideline of this project, intending to utilize all of the available data that could influence the outcome of the prediction, even if the expected influence was small.
A second contribution of this work is related to the articulate data preprocessing. In fact, some of the weather stations are several kilometers far from the basin. For this reason, the weather stations variables were spatially interpolated, considering the distance between each WS and the basin, to obtain an accurate average value in the basin area. In particular, three different spatial interpolation algorithms were tested (Kriging, Radial Basis Function, Natural Neighbour) and compared. Another problem is related to the low availability of the satellite SMC maps, which are obtained twice a week. To improve SMC availability, a neural network surrogate model was trained to predict SMC, using the spatially interpolated weather variables as inputs and the satellite SMC values as output.
As a final contribution, a state of the art NARX model was developed using all of the previously mentioned variables as inputs to predict the water level h hours ahead, for different values of the time horizon h. Hourly prediction of water levels, as well as NARX models, are most common in the case of flood prediction, but it can be certainly beneficial for the management of the hydroelectric basin for several operational reasons, especially in the case of several interconnected basins as in the case of the Garfagnana valley. As an example, an important activity in the hydroelectric basin is predictive maintenance [25,26], and an hourly prediction of the basin status can be conveniently used to perform condition monitoring and fault detection. In the previous work [25], the author proposed a self-organizing maps (SOM)-based methodology to condition monitoring and predictive maintenance in hydroelectric plants. In that work, a number of measured variables from the generations units equipment, such as currents, temperatures of the transformers oil and windings, sensor data from the electrical machines, dissolved gases, and many other variables, were used to learn the SOM model of the plant operation in nominal conditions. The model proposed in this work will be used as an additional module to aid the predictive maintenance algorithm to monitor the effective operation of the system and predict faults. In fact, having an accurate simulation of the water level in nominal conditions, allows to compare the real water level against the predicted water level, and a significant disagreement indicates an anomalous behaviour of the system.
In Section 2 the main characteristics of the hydrological system are presented, the input data of is presented and described in detail, the various models are formulated and their characteristics are highlighted. In Section 3, the results of the methods are presented and discussed. Section 4 reports the conclusions and future developments.
2. Materials and Methods
In this section, we introduce the main aspects of the Garfagnana hydrological system, whose dimension and complexity motivate the development of the accurate model presented in this work. After that, we present the main characteristics of the collected datasets, which consist in reanalysis data, weather stations data, satellite data, and basin data. Finally, we introduce the methodology, which is composed by three main modules: spatial interpolation of weather stations data, neural network modelling of satellite data, and basin modelling using NARX approach.
2.1. Garfagnana Hydrological System
The Garfagnana hydrological system is the most important on the Tuscany region, the main river is Serchio (111 km), whose source is located in Monte Sillano (1864 m), and its basin has a total catchment surface of 1500 Km. An overview of the Serchio basin is shown in Figure 1.
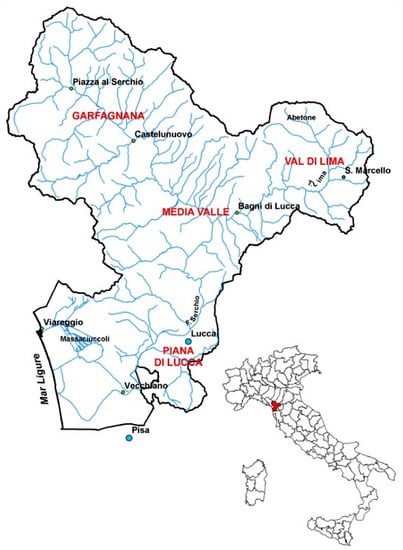
Figure 1.
Overview of Serchio basin.
Serchio goes through the Garfagnana valley until it reaches the Tirreno sea. The presence of large amount of hydro resource and its various distribution on the Garfagnana valley has influenced the realization of a complex system of river, basins, and power plants, as shown in Figure 2. The production of a specific power plant depends from the production of all the other power plants upstream. For example, if an upstream plant does not use the turbine for a certain period, the downstream basin will receive less water than usual. On the other side, the upstream basin will increase its water level. Optimizing the hydro resource all over the Garfagnana valley is one of the goals of this research. This kind of optimization is very complex because it requires a high level of coordination between all power plants of the area. The other main goal is to prevent the risk of flooding: the management of the hydro basin/plant must be handled in a safe way for the surrounding area. Knowing in advance the increase of water levels can help in taking the right decision and avoiding flooding. From a production point-of-view, having different basins at different altitudes requires a deep study for optimizing the global hydro resource. Being able to know the basin status in advance can strongly help the optimization process.
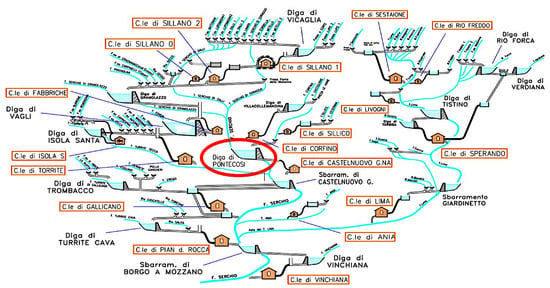
Figure 2.
Hydro system in the area of Garfagnana.
This work focuses on the Pontecosi basin which is located in the upper area of Garfagnana. An overview of the basin is shown in Figure 3. It is an artificial lake with a 30 m dam which serves as hydro-tank for the Castelnuovo hydroelectric power plant, located close to the lake. Castelnuovo power plant is the third biggest of the area; that justifies the importance of an accurate study of the hydro resource. In particular, Pontecosi basin is located at the heart (the middle-upper part) of the hydro-logical system, hence its good functioning is vital for the operation of the whole system, both upstream and downstream, for the reasons previously described. Having a good prediction of the water level of this basin is beneficial for the complete system as well.

Figure 3.
Pontecosi basin.
From an environmental safety point of view the basin status is represented by the water level of the basin: upper and lower bounds are set by environmental laws. Going over the upper bound can cause floods; on the other side, a minimum level of water must be preserved to ensure the environmental flow (EF). The water level (neat head) in a hydroelectric basin depends on several variables: the flow used by the turbine, for example, is a human activity that influences the net head value. Higher is the turbine generation, higher is the amount of water withdrawn from the basin. Another aspect that influences the net head value is the EF, a minimum water outflow imposed by environmental laws to ensure a proper life quality of the river ecosystem. The EF must be guaranteed in all conditions by the owner of the plant.
It is clear that an accurate prediction of the water level, from a control/optimization point of view, is crucial to maintain the levels within the upper and lower bounds, to avoid flooding and the detriment of the environmental flow, respectively. In addition, an accurate prediction of the water level at a particular basin can be used to optimally plan in advance the operations in the upper and lower basins.
2.2. Datasets Characteristics
Data from several sources were used in this project, and of course data from such heterogeneous origins were affected by many quality issues, such as missing values, outliers, etc. Fortunately, most of the environmental data (90%) was of good quality, requiring a moderate preprocessing consisting mainly in the imputation of the missing values and the removal (and successive imputation) of the outliers.
2.2.1. Reanalysis Dataset
Reanalysis dataset [27] were initially created to improve the performance of the Numerical Weather Prediction (NWP) models. NWP models need data about the initial state of weather variables: reanalysis data can provide it. Reanalysis datasets are generated by several data assimilation schemes and models. Data assimilation is a class of techniques which mixes different data sources, in order to obtain an output with less uncertainty than the original data. In this case, data assimilation uses machine learning (ML) algorithms instead of physical laws: this is mainly pushed by the complexity of the laws that rule all the weather variables.
Reanalysis dataset contains a large set of weather variables, extended on a large date–time range. The decision to use also this kind of data source is related to the possibility of having more inputs to the basin status model, hence increasing its performance.
The dataset used in this work is the ERA-Interim [27] which is released by European Centre for Medium-Range Weather Forecasts (ECMWF). This dataset is based on a 2006 Integrated Forecast System (IFS). The main properties are: 4-D variational analysis, 80 km of horizontal resolution, and 60 vertical levels (from the surface to 0.1 hPa). Similarly to satellite based observations, reanalysis dataset is provided in a gridded way: a matrix is associated with a specified position (latitude and longitude) and time. In comparison with satellite data, reanalysis has a lower resolution (80 km vs. 5 km): the accuracy of reanalysis data on a small area around Pontecosi basin is lower with respect to satellite data. Considering this, the variables selected from the reanalysis dataset were:
- Net solar radiance,
- Snow depth.
These variables are less influencing the basin status, with respect to rain and soil moisture concentration (SMC), so the lower accuracy of these variables can be accepted.
2.2.2. Weather Stations Data
Weather stations (WS) are the most direct way to measure a weather variable. Usually, a WS is a complex system of sensors including not only the sensing elements, but also a data acquisition and transmission system. High-quality weather stations are composed by expensive products, so usually they are installed in key points of the area to be observed. In this project, we considered the following four weather variables acquired from weather stations:
- Mean daily temperature (°C),
- Mean daily air humidity (%),
- Total daily precipitation (mm),
- Mean daily wind speed (km/h).
A total of 14 weather stations were used in this project, which are located in a large area nearby the Garfagnana Valley, as shown in Figure 4. The chosen weather stations belong to three different providers:
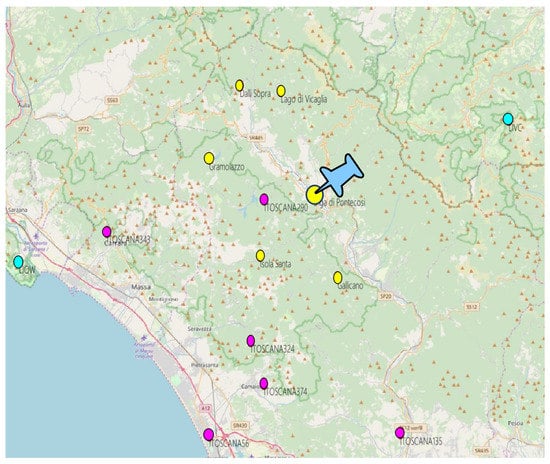
Figure 4.
Weather stations positions. Yellow points are the plant owner stations, magenta points are Wunderground stations, and cyan points are Aeronautica Militare stations.
- Wunderground Personal Weather Stations (PWS) is a platform which offers weather observation datasets. PWS used in this work are located close to the Garfagnana area. The 6 weather stations are marked with a magenta circles in Figure 4, and they provide all 4 variables with worst-case availability of 90%. Wunderground dataset is the core of the input data of this project due to the high availability and proximity to the basin;
- Plant Owner Weather Stations. Plant owner made a weather measurements campaign in the Garfagnana valley. This dataset contains temperatures and air humidity from 6 weather stations located very close to Pontecosi area (yellow points), so they have high relevance with respect to the other providers;
- Aeronautica Militare (AM) Syrep stations are located far from the other stations, however additional two AM stations were selected to cover lack of availability of other providers (cyan points in the map). In addition, AM is the only authority which can certificate weather observations in Italy, so the data quality is generally very high.
2.2.3. Satellite Data
Nowadays, satellite observations are widely used in many fields, from the environmental study to military use. Satellite images are gridded data: it means that values are stored in a matrix, which is geo-referenced through a raster object. For longitudes between 80° North to 80° South, the raster object is usually based on a coordinate system called Universal Transverse Mercator (UTM), while for polar zones, Universal Polar Stereographic (UPS) projection is used. UTM system divides the Earth into 1200 zones: each of them has a size of 6° in longitude and 8° in latitude. The Pontecosi zone is named 32N. Inside the zone, each point is defined within a grid. The images used in this project have a 8074 × 9885 resolution. To select a smaller area than the original, latitude and longitude can be converted in UTM coordinates: so a smaller matrix can be extracted. In this project, satellite data images consist of soil moisture concentration (SMC) maps of the area. More in-depth, SMC values are mapped on a wide area of Tuscany, and a small area around Pontecosi can be extracted as shown in Figure 5. Satellite SMC images are available only twice a week. Averaging the values in the image a single scalar SMC value can be obtained, that represents the average soil moisture concentration around the basin.
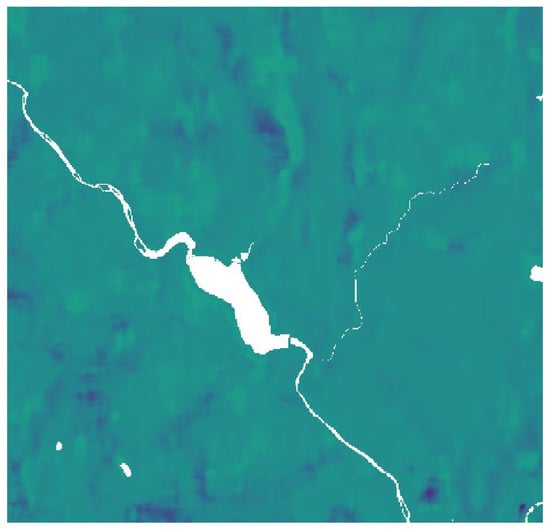
Figure 5.
Soil moisture concentration satellite map around Pontecosi.
2.2.4. Basin Data
Pontecosi basin data were necessary to generate a basin model. Variables included in this dataset are:
- Basin level,
- Turbine flow rate,
- Discharge flow rate.
Each variable is given with a hourly time-step. It is important to note that these data contain several discharge flow events, which are major events during which the discharge flow outlet is activated to prevent flooding. The amount of water released by the basin during this kind of event is huge and it deeply influences the basin level.
2.3. Spatial Interpolation of Weather Stations Data
Point-wise data provided by Weather Stations (WS) cannot efficiently describe a weather variable in a large area. On the other hand, simply calculating an average value of the variables measured by several WS (which are several kilometers apart) can lead to large estimation errors. In these cases, the recommended practice is to use a spatial interpolator [28], which is a mathematical tool that can express a relationship between the spatial observations of a variable to predict its value in a different location. There is a large variety of spatial interpolators. In particular, Pontecosi basin is somewhat in a barycentric position with respect to all of the selected weather stations, then the nearest stations are expected to have a larger influence, while stations further away may have less influence. In order to accurately evaluate the relative weight of each weather station, a spatial interpolation algorithm is needed.
In this work we considered three main algorithms:
- Kriging [29];
- Radial Basis Function [30];
- Natural Neighbour [31].
The motivation of the choice of these three algorithms is that they represent three different main classes of spatial interpolation algorithms and they are extensively applied in the literature, being effective in a large number of applications. Kriging and Natural Neighbour make the prediction as a weighted linear combination of the values measured at the weather stations, while Radial Basis Function interpolates using Gaussian functions placed at the weather stations location.
The interpolated variable can be predicted in a specific new location as shown in Figure 6, most precisely, the interpolated values can be averaged over a specific area around the basin.
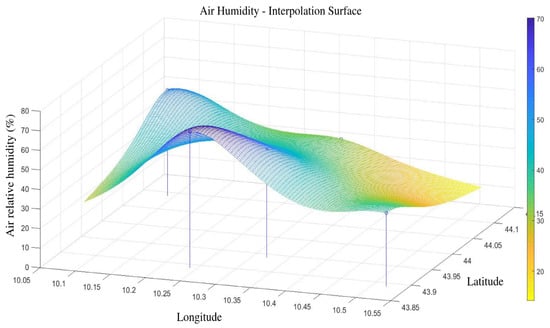
Figure 6.
Kriging interpolation of air humidity over the area of interest in an r day. Vertical lines localize the weather stations.
2.3.1. Kriging Interpolation
The term “Kriging” comes from Danie Krige, an engineer who first developed this particular method. Several variants of the the Kriging algorithm exist: in this work Ordinary Kriging is used. In the following, the n measurement sites are defined as “sample points”.
The Kriging prediction of a scalar quantity at an unobserved location is a linear combination of the observed values at sample points with scalar weights , :
The spatial variable represents a vector in a three-dimensional coordinate system. To obtain an unbiased predictor, the weights should sum to one and they are determined by minimizing the variance of the prediction error:
where denotes the expectation operator. The variance is minimized by the use of the so called semivariogram , which is needed to calculate the variance in (2) and can be fitted using the historical dataset of measurements of the quantity at the sample points. Based on the homogeneity of samples in the area where the random variable is distributed, its first and second moments are usually assumed to be stationary, which means:
- All random variables have the same mean, that can be estimated by the arithmetic mean of sampled values;
- The correlation between two random variables solely depends on the spatial distance between them and is independent of their location.
The two above assumptions of stationarity in the random variable are proposed in the geostatistical formalism in order to make the inference of some statistic values possible. Based on the actual measurements of the variables in the different weather stations the required homogeneity of each variable has been heuristically observed.
Under these assumptions the semivariogram is defined as:
where is the set of pairs of observations i, j, such that , and is the number of pairs in the set. The solution of Equation (2) is obtained using Lagrange multipliers as
where is the vector of estimated weights and is the mean value. Commonly used fitting functions of are shown in Table 1.

Table 1.
Fitting functions of the semivariogram.
After building the empirical semivariogram, using the available dataset and Equation (3), the next step is to choose the function that will fit it best. As can be seen in table, function expressions contains two unknown parameters and , the distance h and a shape parameter . The shape parameter is an hyper-parameter that can be freely selected by the user: different values will cause different and values, which are determined, after selecting , with a least square problem resolution.
2.3.2. Radial Basis Function Interpolation
Another commonly used spatial interpolation method relies on the Radial Basis Function (RBF). The predicted variable at an unknown location is calculated by the RBF interpolator as:
where the base RBF function is defined as:
After selecting the hyper-parameter , the weights are determined solving the least squares problem:
2.3.3. Natural Neighbour Interpolation
Natural neighbour interpolation is a method developed by Robin Sibson [31], which works with a similar principle to Kriging. The basic equation is:
The method differs in the way the weights are calculated, which is based on Voronoi tessellation of the discrete set of spatial points , also called centroids. Voronoi tessellation is a partition of the space into n regions (Voronoi cells), where cell i consists of all points of the space closer to than to any other centroid. We define as the space region corresponding to cell i in the tessellation with n centroids, and with the size of cell i, which can be the volume or the area of the space region depending on the space being tree-dimensional or two-dimensional, respectively. Given the new location , a new tessellation is computed using centroids, adding to the previous set of n centroids. The Sibson weight is calculated as the ratio of the size of the intersection between the new cell and the old cell with respect to the size of the new cell:
2.4. Satellite Soil Moisture Modelling
An important step of this project is the SMC modelling. SMC represents the volumetric water concentration and it is expressed as the ratio between the volume of water and and the total volume of considered soil:
Typical SMC values goes from 0.0 (completely dry) to 0.6 (fully wet). Values above 0.6 are usually associated with rivers, seas, etc., so they are not related to the soil and have to be discarded. In this project, satellite SMC images are available only twice a week: this depends mainly on the satellite orbit around the Earth. Days without observations have to be “imputed”, which means assigning a reasonable value to the missing observations. To accomplish this goal, an ML model was realized, based on the satellite observations of SMC in the time range of the archived data. The inputs of the SMC model are the output values of the interpolation step, described in the previous section, over the entire Pontecosi area, i.e., the following variables:
- Mean daily temperature on the area;
- Mean daily air humidity on the area;
- Total daily precipitation on the area;
- Mean daily wind speed on the area.
This was decided thanks to the high availability of this data and the intimate relationship between them and SMC. The target data of the neural network is the average SMC over the basin area obtained from the satellite images. A one hidden layer feed-forward neural network [32] was selected to model SMC as a function of the four weather variables, as shown in Figure 7. The hidden layer uses sigmoidal neurons and the training function employs the Bayesian regularization algorithm [33]. The number of neurons in the hidden layer was chosen through a model selection procedure: a 3-fold cross validation was performed.
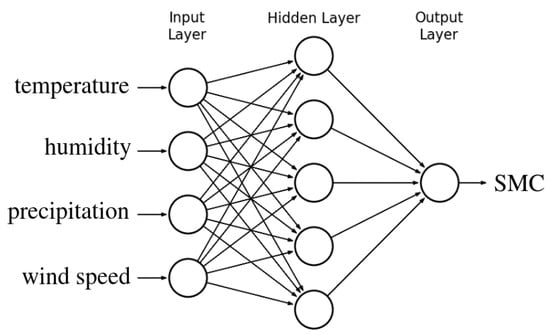
Figure 7.
Neural network to predict SMC values.
2.5. Basin Modelling
The core of this work is to predict the hydroelectric basin water level, that strongly depends not only on recent past levels but also on past turbine production and past weather events. According to this, a NARX model was created and tested: the possibility to have as inputs past level values makes the NARX choice suitable to this application.
NARX network is one of most common architectures used to model non-linear processes [34]. The basic principle is that the predicted output of the process depends on past values both of the input (that could also be multivariate) and the scalar output itself :
where is the non-linear function that describe the process (usually modelled with a neural network), and are the number of delayed inputs and outputs, respectively, while and represent the forecast horizons with respect to the input and output, respectively. Equation (11) describes the so called open loop-NARX, while if the predictions themselves are used in feedback in place of the measured outputs we have the so called closed-loop NARX:
The neural network is usually trained using the open-loop scheme, while the closed-loop approach can be used at the prediction step to achieve a forecast horizon larger than , as far as the exogenous input is known. However, the closed-loop scheme can propagate errors worsening the performance. Moreover, training using the closed loop approach may generate instability issues because of the back propagation of the information, while open loop training does not incur into this problem. Figure 8 shows the NARX scheme using a neural network with horizons and a scalar input. The actual model used in this work is better described in Section 3.3, in fact, the vector input contains many variables and particular choices are made for the forecast horizons.
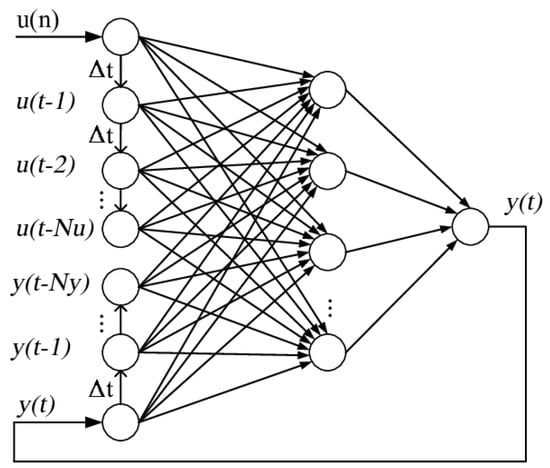
Figure 8.
NARX scheme using a neural network.
3. Results and Discussion
3.1. Interpolation of Daily Weather Stations Data Results
The three kinds of interpolators previously described were tested on the weather stations dataset. In particular they were optimized and tested on each of the four daily variables separately.
RBF and Kriging require one hyperparameter, that has to be known in advance, while Natural Neighbour does not require any. The hyperparameter chosen should be the one that generalizes best the spatial distribution of the variable. The procedure used to select hyperparameters is described in the following steps:
- 1.
- Hold out one station and consider it as the test station;
- 2.
- Perform a leave one out cross validation on the remaining stations and determine the hyperparameter;
- 3.
- Test the interpolator on the test station, taking as input all the remaining stations, and calculate the corresponding test error;
- 4.
- Repeat the procedure until all the stations had been the test station once;
- 5.
- Calculate averaged test error among all test stations.
This procedure was applied for each interpolator and variable, using the mean absolute error (MAE) as loss measure, defined as:
where N is the number of test observations, is the variable and is the predicted value. MAE is a universally accepted forecast error measurement, and it was also the metric of choice of the plant owner. The interpolator with lowest average MAE over all the test stations was chosen as the winning interpolator. This procedure was selected thanks to its robustness: each interpolator has been tested on every station, ensuring that the resulting model is optimized to perform well in each station of the dataset. As shown in Table 2, which reports the results of the above procedure, prediction errors of the Kriging interpolator are small and acceptable. In particular, Kriging, with Gaussian fitting function, was the winning interpolator for each variable. The second best performance is from Natural Neighbour interpolator, while RBF shows the worst performance, especially for the prediction of air humidity and wind speed. A Wilcoxon test for statistical significance of the different results shown in Table 2 was performed, and the test indicated that all differences are significant with 5% confidence. The results of Kriging and Natural Neighbour are very close to each other, while RBF outperforms Natural Neighbour only for the precipitation.
Table 2.
Averaged MAE of the interpolation methods.
3.2. Satellite Soil Moisture Modelling Results
The Kriging interpolator was used to generate daily values of the four weather variables over a grid over the Pontecosi area, as shown in Figure 6. In particular, the interpolated values were generated also for the days when the satellite SMC values are available. All the spatially interpolated values were then averaged to provide a single daily value for each variable, which are shown in Figure 9 over all the dataset time-span. The four variables are then used as inputs to the NN that shall predict the SMC as output.
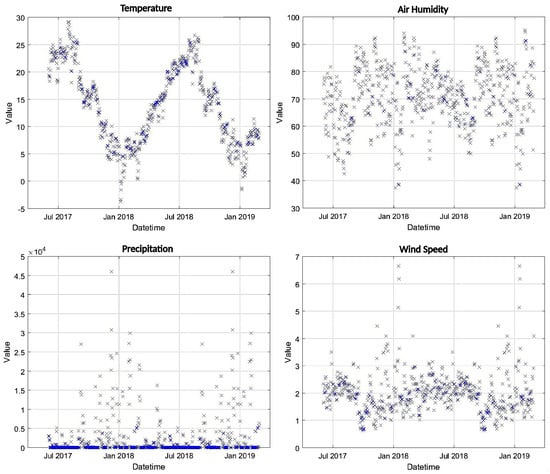
Figure 9.
Daily values of the weather variables after averaging the Kriging interpolation over the area of interest.
The result of a 3-fold cross-validation is shown in Figure 10. The optimal number of neurons in the hidden layer results to be 4, and the corresponding MAE values are around 0.035. From Figure 10 it is clear that the MAE is nearly independent from the number of neurons, so this choice is not critical, resulting in MAE values between 0.035 and 0.06, depending on the number of neurons. Considering that all observed SMC values are between 0.1 and 0.35 the NN model can be considered accurate. Figure 11 shows the correlation matrix between all the variables, including SMC. In particular, SMC is most correlated with temperature and air humidity, while a low correlation can be observed with the wind speed. On the other hand, the humidity has a strong negative correlation with wind speed (−0.58), as a decrease in air humidity is expected for higher wind speeds, however this has little effect on soil moisture concentration. SMC is expected to be the variable most influencing the water level of the basin, therefore the correlation analysis shows that the other important variables are temperature, air humidity, and precipitation.
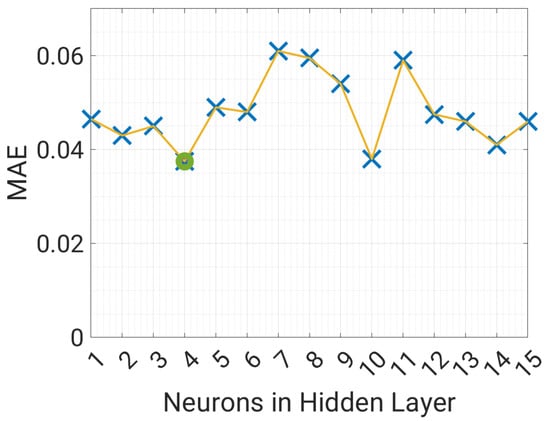
Figure 10.
Selection of the number of neurons of the NN to predict SMC.

Figure 11.
Correlation matrix.
3.3. Basin Modelling Results
The basin water level was modelled using the NARX model shown in Equation (11). Considering that the basin data (water level, turbine flow rate, and discharge flow rate) are provided hourly, we consider an hourly time-step in the NARX model. The exogenous input is composed by two flow rates and seven environmental variables: four of them are from Kriging interpolation of weather stations (temperature, air humidity, precipitation, and wind speed), two of them are from reanalysis dataset (snow depth, net solar radiance), and the last is SMC as predicted by the trained NN model. All the seven weather variables have a daily temporal resolution, and during day d we assume constant intra-day hourly values equal to the last known values of day . Regarding the output water level it is measured in meters above sea level (a.s.l), and it represents also the tenth input to the NARX model as depicted in the complete scheme of the system shown in Figure 12. The time delays were set to , , while model was trained for different values of the forecast horizon . The resulting NARX equation can be then written as:
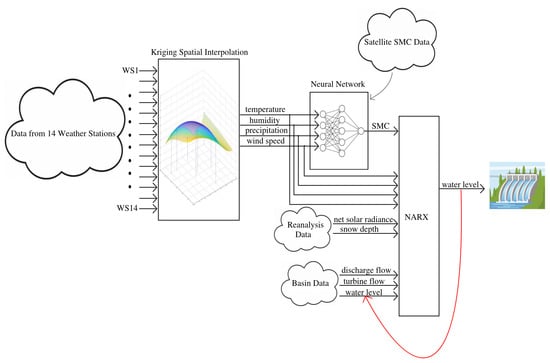
Figure 12.
Complete schematic of the forecasting model.
The NARX training period includes the first 500 days of data, and the test set consists in the successive 131 days. We used an expanding window approach: the test predictions during day d were obtained including day in the training set. Figure 13 and Figure 14 show a comparison of the measured level against the predicted level using an horizon and , respectively. From these figures it can be appreciated that the prediction is able to accurately anticipate even abrupt changes of the water level, such as the one on 27 October, both with 1 or 6 h ahead. The average error is in both cases within few centimeters. Of course, the prediction at 6 h ahead shows a generally worse performance with respect to 1 h ahead, still sudden and significant changes are well predicted. Globally speaking, the mean absolute error MAE in the test set as a function of the forecast horizon is shown in Figure 15. The plant operator assumed as acceptable an error lower than 0.1 m, which is reached with a maximum of 6 h of time horizon. Therefore, our model produces acceptable results for , while with the average error is within 0.02 m. If we move to larger time horizons, such as 12 h or 24 h, the average absolute error increases to 15 cm and 20 cm, respectively, indicating a less than linear increase, considering that we have an error of 10 cm with 6 h ahead. For this reason, even the prediction at 24 h ahead can still be considered of interest, as far as an error of 20 cm is small with respect to the decisions that can be made based upon these predictions.
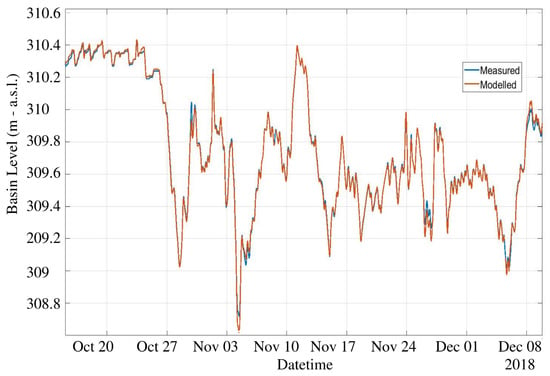
Figure 13.
Predicted level during test period, comparison between NARX model and measured for h ahead. MAE is 2 cm.
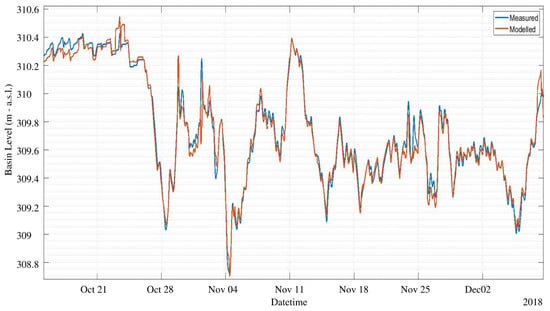
Figure 14.
Predicted level during test period, comparison between NARX model and measured for h ahead. MAE is 10 cm.
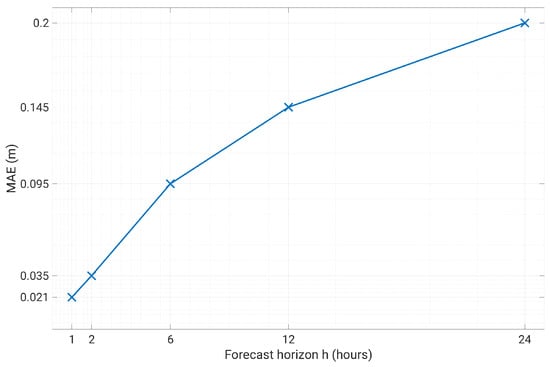
Figure 15.
Prediction error as a function of the forecast horizon.
4. Conclusions
The objective of this work was to develop a forecasting algorithm to aid a decision support system for the hydrological basin. The complete model is composed of several modules, the last of which is the basin model. To improve the performance, different data sources were used. Weather station data were managed through the use of spatial interpolators: this was necessary because of the large distances between weather stations and basin location. Different types of spatial interpolators were tested and compared, and Kriging was the best one. Soil moisture concentration values in days not available from satellite data were predicted using a neural network. Finally, a NARX model was created to predict the basin water level using past weather and basin data, tacking advantage of the previous modules. Predictions at different time horizons were simulated: acceptable results were achieved within 1 to 6 h ahead. In particular, the basin level can be known up to 6 h ahead with 10 cm accuracy. For larger values of h, the model produced larger errors, especially in the case of unpredictable discharge events. If these events are known in advance they can be integrated in the model improving its performance. The methodologies presented in this paper allowed to improve the input data quality and to model accurately an hydroelectric basin. As a future development, the author intend to integrate the model presented in this work with the condition monitoring model previously proposed in [25], also applied to photovoltaic plants [35], in order to improve the performance of the model based on SCADA (Supervisory Control And Data Acquisition) data [36] and self-organizing maps. As a second future development, we shall investigate the application of sensitivity analysis techniques, such as [37,38] to estimate the influence of the input variables to the performance of the model.
Funding
This research was funded by Hydrocontroller Regional Project.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The author wishes to acknowledge company i-EM (www.i-em.eu, accessed on 25 November 2022) for the support given in providing the data and testing the methods.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| NARX | Non-linear Auto Regressive eXogenous input |
| RBF | Radial Basis Function |
| EF | Environmental Flow |
| NWP | Numerical Weather Prediction |
| ML | Machine Learning |
| ECMWF | European Centre for Medium-Range Weather Forecasts |
| IFS | Integrated Forecast System |
| PWS | Personal Weather Stations |
| AM | Areonautica Militare |
| UTM | Universal Transverse Mercator |
| UPS | Universal Polar Stereographic |
| SMC | Soil Moisture Concentration |
| WS | Weather Stations |
| MAE | Mean Absolute Error |
| NN | Neural Network |
| SCADA | Supervisory Control and Data Acquisition |
References
- Boretti, A.; Rosa, L. Reassessing the projections of the world water development report. NPJ Clean Water 2019, 2, 1–6. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.A.; Waller, S.T. Remote Sensing Methods for Flood Prediction: A Review. Sensors 2022, 22, 960. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K.-W. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Gaudard, L.; Gilli, M.; Romerio, F. Climate change impacts on hydropower management. Water Resour. Manag. 2013, 27, 5143–5156. [Google Scholar] [CrossRef]
- Zhu, S.; Lu, H.; Ptak, M.; Dai, J.; Ji, Q. Lake water-level fluctuation forecasting using machine learning models: A systematic review. Environ. Sci. Pollut. Res. 2020, 27, 44807–44819. [Google Scholar] [CrossRef]
- Demir, V.; Yaseen, Z.M. Neurocomputing intelligence models for lakes water level forecasting: A comprehensive review. Neural Comput. Appl. 2022, 1–41. [Google Scholar] [CrossRef]
- Khan, M.S.; Coulibaly, P. Application of support vector machine in lake water level prediction. J. Hydrol. Eng. 2006, 11, 199–205. [Google Scholar] [CrossRef]
- Ehteram, M.; Ferdowsi, A.; Faramarzpour, M.; Al-Janabi, A.M.S.; Al-Ansari, N.; Bokde, N.D.; Yaseen, Z.M. Hybridization of artificial intelligence models with nature inspired optimization algorithms for lake water level prediction and uncertainty analysis. Alex. Eng. J. 2021, 60, 2193–2208. [Google Scholar] [CrossRef]
- Azad, A.S.; Sokkalingam, R.; Daud, H.; Adhikary, S.K.; Khurshid, H.; Mazlan, S.N.A.; Rabbani, M.B.A. Water Level Prediction through Hybrid SARIMA and ANN Models Based on Time Series Analysis: Red Hills Reservoir Case Study. Sustainability 2022, 14, 1843. [Google Scholar] [CrossRef]
- Bogning, S.; Frappart, F.; Blarel, F.; Niño, F.; Mahé, G.; Bricquet, J.-P.; Seyler, F.; Onguéné, R.; Etamé, J.; Paiz, M.-C.; et al. Monitoring Water Levels and Discharges Using Radar Altimetry in an Ungauged River Basin: The Case of the Ogooué. Remote Sens. 2018, 10, 350. [Google Scholar] [CrossRef]
- Becker, M.; Da Silva, J.S.; Calmant, S.; Robinet, V.; Linguet, L.; Seyler, F. Water Level Fluctuations in the Congo Basin Derived from ENVISAT Satellite Altimetry. Remote Sens. 2014, 6, 9340–9358. [Google Scholar] [CrossRef]
- Cao, Y.; Yin, K.; Zhou, C.; Ahmed, B. Establishment of landslide groundwater level prediction model based on GA-SVM and influencing factor analysis. Sensors 2020, 20, 845. [Google Scholar] [CrossRef] [PubMed]
- Seo, Y.; Kim, S.; Kisi, O.; Singh, V.P. Daily water level forecasting using wavelet decomposition and artificial intelligence techniques. J. Hydrol. 2015, 520, 224–243. [Google Scholar] [CrossRef]
- Sapitang, M.; Ridwan, W.M.; Faizal Kushiar, K.; Najah Ahmed, A.; El-Shafie, A. Machine learning application in reservoir water level forecasting for sustainable hydropower generation strategy. Sustainability 2020, 12, 6121. [Google Scholar] [CrossRef]
- Baek, S.-S.; Pyo, J.; Chun, J.A. Prediction of Water Level and Water Quality Using a CNN-LSTM Combined Deep Learning Approach. Water 2020, 12, 3399. [Google Scholar] [CrossRef]
- Sung, J.Y.; Lee, J.; Chung, I.M.; Heo, J.H. Hourly water level forecasting at tributary affected by main river condition. Water 2017, 9, 644. [Google Scholar] [CrossRef]
- Faruq, A.; Abdullah, S.S.; Marto, A.; Abu Bakar, M.A.; Mohd Hussein, S.F.; Che Razali, C.M. The use of radial basis function and non-linear autoregressive exogenous neural networks to forecast multi-step ahead of time flood water level. Int. J. Adv. Intell. Inform. 2019, 5, 1–10. [Google Scholar] [CrossRef]
- Chang, F.J.; Chen, P.A.; Lu, Y.R.; Huang, E.; Chang, K.Y. Real-time multi-step-ahead water level forecasting by recurrent neural networks for urban flood control. J. Hydrol. 2014, 517, 836–846. [Google Scholar] [CrossRef]
- Liang, C.; Li, H.; Lei, M.; Du, Q. Dongting Lake Water Level Forecast and Its Relationship with the Three Gorges Dam Based on a Long Short-Term Memory Network. Water 2018, 10, 1389. [Google Scholar] [CrossRef]
- Crisostomi, E.; Gallicchio, C.; Micheli, A.; Raugi, M.; Tucci, M. Prediction of the Italian electricity price for smart grid applications. Neurocomputing 2015, 170, 286–295. [Google Scholar] [CrossRef]
- Tucci, M.; Crisostomi, E.; Giunta, G.; Raugi, M. A multi-objective method for short-term load forecasting in European countries. IEEE Trans. Power Syst. 2015, 31, 3537–3547. [Google Scholar] [CrossRef]
- Gigoni, L.; Betti, A.; Crisostomi, E.; Franco, A.; Tucci, M.; Bizzarri, F.; Mucci, D. Day-ahead hourly forecasting of power generation from photovoltaic plants. IEEE Trans. Sustain. Energy 2017, 9, 831–842. [Google Scholar] [CrossRef]
- Bai, L.; Crisostomi, E.; Raugi, M.; Tucci, M. Wind turbine power curve estimation based on earth mover distance and artificial neural networks. IET Renew. Power Gener. 2019, 13, 2939–2946. [Google Scholar] [CrossRef]
- Wang, X.; Babovic, V. Application of hybrid Kalman filter for improving water level forecast. J. Hydroinformatics 2016, 18, 773–790. [Google Scholar] [CrossRef]
- Betti, A.; Crisostomi, E.; Paolinelli, G.; Piazzi, A.; Ruffini, F.; Tucci, M. Condition monitoring and predictive maintenance methodologies for hydropower plants equipment. Renew. Energy 2021, 171, 246–253. [Google Scholar] [CrossRef]
- Piazzi, A.; Tucci, M.; Ruffini, F.; Crisostomi, E. One year Operation of an Innovative Condition Monitoring Technique in Four Hydropower Plants. In Proceedings of the 2020 IEEE PES Innovative Smart Grid Technologies Europe (ISGT-Europe), Delft, The Netherlands, 26–28 October 2020. [Google Scholar] [CrossRef]
- Dee, D.P.; Uppala, S.M.; Simmons, A.J.; Berrisford, P.; Poli, P.; Kobayashi, S.; Vitart, F. The ERA-Interim Reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 553–597. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D. Spatial interpolation methods applied in the environmental sciences: A review. Environ. Model. Softw. 2014, 53, 173–189. [Google Scholar] [CrossRef]
- Oliver, M.A.; Webster, R. Kriging: A method of interpolation for geographical information systems. Int. J. Geogr. Inf. Syst. 1990, 4, 313–332. [Google Scholar] [CrossRef]
- Wright, G.B. Radial basis function interpolation: Numerical and analytical developments. Ph.D Thesis, University of Colorado at Boulder, Boulder, CO, USA, 2003. [Google Scholar]
- Sibson, R. A brief description of natural neighbor interpolation (Chapter 2). In Interpreting Multivariate Data; Barnett, V., Ed.; John Wiley: Chichester, UK, 1981; pp. 21–36. [Google Scholar]
- Gurney, K. An Introduction to Neural Networks; CRC Press: London, UK, 2018. [Google Scholar]
- MacKay, D.J.C. Bayesian interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Lin, T.; Horne, B.G.; Tino, P.; Giles, C.L. Learning long-term dependencies in NARX recurrent neural networks. IEEE Trans. Neural Netw. 1996, 7, 1329–1338. [Google Scholar] [CrossRef]
- Betti, A.; Tucci, M.; Crisostomi, E.; Piazzi, A.; Barmada, S.; Thomopulos, D. Fault prediction and early-detection in large pv power plants based on self-organizing maps. Sensors 2021, 21, 1687. [Google Scholar] [CrossRef] [PubMed]
- Gigoni, L.; Betti, A.; Tucci, M.; Crisostomi, E. A scalable predictive maintenance model for detecting wind turbine component failures based on SCADA data. In Proceedings of the 2019 IEEE Power & Energy Society General Meeting (PESGM), Atlanta, GA, USA, 4–8 August 2019. [Google Scholar] [CrossRef]
- Barmada, S.; Musolino, A.; Raugi, M.; Tucci, M. Analysis of power lines uncertain parameter influence on power line communications. IEEE Trans. Power Deliv. 2007, 22, 2163–2171. [Google Scholar] [CrossRef]
- Barmada, S.; Musolino, A.; Rizzo, R.; Tucci, M. Multi-resolution based sensitivity analysis of complex non-linear circuits. IET Circuits Devices Syst. 2012, 6, 176–186. [Google Scholar] [CrossRef]















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).