1. Introduction
Recently, animal welfare has been discussed alongside intensive farming [
1,
2] for livestock species such as cattle, sheep, and horses, linking natural pasture benefits to animal health. Nevertheless, complications occur in raising livestock [
3], especially in constructing modern natural pastures and sustaining grassland resources which consequently influence animal welfare. Likewise, it is vital to design supporting modern monitoring equipment. Since animal behaviour is a good indicator of animal health, monitoring animal behaviour makes a good foundation for the timely detection of abnormalities. Despite that, manual observation makes it impossible to meet the schedule in pastures where animals are spatially active while being inefficient and costly when numerous animals are observed [
4]. Hence, the scenario constitutes the essentiality of using certain monitoring equipment to observe the daily animal behaviour in specific situations (e.g., watering holes, etc.). In other words, introducing automatic identification for analysing animal behaviour would benefit animal well-being in open pastures while improving the efficiency of farm monitoring [
5].
Presently, two predominant approaches in animal monitoring are: contact sensor devices and video surveillance-based camera devices. Sensor devices typically consist of: collars, cage covers, ear tags, and pedometers. These devices serve functions as positioning, temperature monitoring, acceleration, and sound sensors. The video surveillance devices are primarily camera-based computer vision methods. Here, the video data are combined with deep learning models for behavioural recognition, abnormal state recognition, and other observations of the animals’ daily behaviour. As a non-contact and cost-effective technology, computer vision is a prominent trend in animal behaviour recognition [
1,
6,
7,
8,
9,
10,
11]. Computer vision is consistently evident in research on smart farming in animal husbandry for pig, cattle, and sheep species, detecting behaviours that have led to crucial indicators for solving real-life production problems.
Researchers such as Nasirahmadi et al. have used captured images for processing to study the lying patterns of pigs under commercial farm conditions [
12,
13]. Meanwhile, Chen et al. [
14] conceptualised a ResNet50 convolutional neural network and long short-term memory (LSTM)-based method for pig drinking and water dispenser play behaviour recognition, with classification accuracies of 0.87 and 0.93 in the body and head regions of interest, respectively. Jiang et al. [
15] proposed an algorithm based on YOLOV3 for critical part detection in dairy cows in complex scenarios, and the algorithm detected each part with an average accuracy of 0.93. Similarly, Cheng et al. [
16] proposed a deep YOLOV5 network-based behaviour recognition model for sheep in housed scenes, showing that the algorithm can be used in structured settings with a deep learning model in a structured scenario. This exhibits that it is unnecessary to use a large amount of training data when the training data and the data generated in a real application have the same features. At the core of computer vision are the deep learning algorithms used for detection, the most important of which are convolutional neural networks (CNNs), capable of automatically learning invariant features in a task in a layered manner [
17]. Faster region-convolutional neural networks (R-CNNs) [
18] and ZFnet [
19] were used to identify the individual feeding behaviour of pigs [
20] by detecting the letters marked on the head. In surveillance videos, Faster R-CNN was used to detect dairy goats [
21].
Moreover, Wang et al. modified YOLOV3 based on the filter layer, which was employed to detect key parts of cows in natural scenes [
14,
22]. Wen et al. [
23] applied a convolutional neural network (CNN) for a cow detection and counting system, obtaining an accuracy of 0.957. A YOLOV5-ASFF target detection model to determine bovine body parts, namely, individual, head, and leg, is proposed by Qiao et al. [
24] in complex scenes. The target detection model is based on convolutional neural networks for feature extraction and is a contemporary computer vision method applied in all fields of precision agriculture. For instance, Zhao et al. [
25] utilised an improved YOLOV5-based method to accurately detect wheat spikes in unmanned aerial vehicle (UAV) images to address false detection and missed detection of spikes caused by occlusion conditions. Wang et al. [
26] built an image acquisition system based on a fruit pose adjustment device and used the deep learning-based YOLOV5 algorithm for the real-time recognition of apple stems/calyxes.
A Faster R-CNN model based on the Soft-NMS algorithm was used for real-time detection and localisation of sheep under complex feeding conditions [
27]. The current literature on sheep behaviour particularly refers to studies with intensive housing conditions, which make observation and data collection more accessible and convenient. Yet, fewer studies are related to computer vision applications under natural grazing conditions. The reasons could be that the large size of the pasture is not conducive to the application, and the density of sheep in free grazing conditions is too high, consequently placing greater demand on data acquisition and the robustness of subsequent models. To counter the challenge of monitoring sheep behaviour in pastures, an improved YOLOV5 recognition algorithm is proposed in this study to detect sheep’s daily behaviour (standing, feeding, and lying) in grazing pastures. At the same time, datasets were constructed for different shooting methods to verify the model’s generalisation capability and provide a basis for subsequent applications. This research has collected relevant data in conjunction with actual pasture scenarios, focusing on the behaviour of grassland-grazing sheep to design experimental studies.
2. Materials and Methods
2.1. Experiments and Data Acquisition
The site of the experiment is located in a grassland field of a small town of Xeltala, Hulunbeier, Inner Mongolia Autonomous Region of China, longitude: 120.00435, latitude: 49.34809. The field had a length of 40 m and a width of 10 m and was fenced into three small 40 m × 3.3 m areas with natural grass and watering basins, freely available for sheep feeding and drinking.
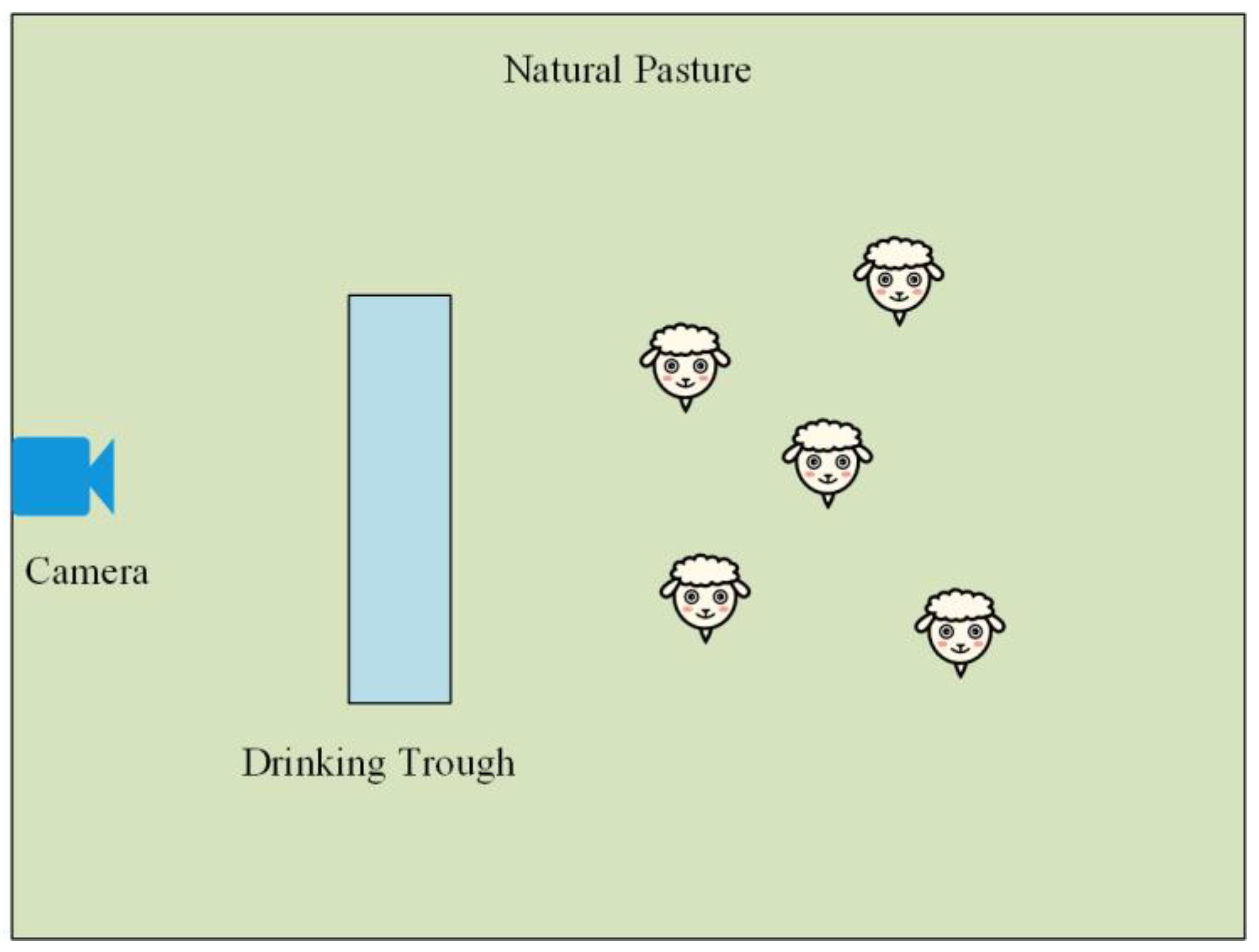
In the experiment, two movable fences were used to adjust area size, predominantly to facilitate comprehensive observation of the sheep’s behaviour during grazing using the camera, making it easier to change the experimental site after the grass vegetation was foraged. Two filming devices were selected for the experiment: a camera that was fixed to the fence (HIKVISION Fluorite Cloud H8 model) and a handheld recording device (Snapdragon S3 sports camera). The cameras were placed on both sides of the fence (
Figure 1a) to capture images of the sheep’s behaviour during free grazing. The camera positions and angles were manually adjusted on both sides of the fence to observe sheep behaviour completely.
The handheld device (
Figure 1b) was operated manually with a tripod, following the sheep’s daily behaviour through image recording. The two devices had different recording specifications; the camera device recorded in MP4 format at 1920 × 1080 and 30 frames per second, and the handheld device recorded in MP4 format with a pixel size of 1920 × 1440 at 30 frames per second. The experiment was conducted from 22 August 2022 to 19 September 2022, with a total of 22 sheep observed, with two sheep being observed in the experimental area each day in rotation to ensure that each sheep was included in the image data captured by both devices. All 22 sheep in our study were from the Hulunbeier breed, comprising 13 ewes and 9 rams, aged between one and two years. The selection criteria specifically required the exclusion of ewes with lambs or in labour to ensure that the research had only comprised healthy animals. More than 500 h of valid video for the experimental data were recorded. The behaviours observed during the experiment were feeding, standing, lying, walking, and running.
2.2. Dataset Construction
This study focuses on constructing a sheep behaviour dataset using the pictures of 22 sheep of different perspectives and states throughout the experiment. The images in the dataset were manually selected, considering the different lighting conditions throughout the day. The photos were selected based on the lighting conditions, and some nighttime observation photos were taken by the fixed camera video. The complete image dataset encompasses sheep feeding scenes in different weather conditions in the grassland, producing a complex data scene.
The pictures of sheep behaviour were taken both via video and handheld camera. A total of 1656 pictures were captured, of which 703 pictures were taken by fixed cameras and 953 pictures were captured by handheld devices. The sheep in the dataset had three behaviours: feeding, standing, and lying (
Table 1,
Figure 2). We then labelled the images to produce a label file that conformed to the YOLO training format. The images and tag files were divided into a dataset of 1490 images (1101 standing tags, 1952 feeding tags, and 600 lying tags) and a validation set of 166 images (105 standing tags, 210 feeding tags, and 67 lying tags). After this, we separated the data between the stationary camera and the handheld device for comparison training to test the model’s ability on different acquisition methods and scenes and the influence of the acquisition methods and scenes on the model.
2.2.1. Scenario Dataset Construction
To verify the effect of the scene on behavioural recognition, separate datasets were constructed for the scenes presented above, with photos taken by both the fixed camera and handheld camera (
Table 2). The angle of view of the sheep captured by the two camera types differed, with the fixed camera capturing a top view at about 30° and the handheld camera capturing a flat view at about 180° (
Figure 3).
2.2.2. The Difference between Scenarios
Two primary shooting scenarios were included to construct the scenario dataset: fixed and handheld cameras. While both methods produced different shooting angles, the primary difference was the impact of natural lighting on the resulting images. For the fixed camera, we conducted 24 h of shooting throughout the day, capturing the varying effects of sunlight on the camera images (
Figure 4). The scenarios were complex and diverse, resulting in significant differences between the images. In contrast, we conducted manual shooting at a closer distance with a higher proportion of sheep in the frame for the handheld camera. The impact of lighting on the images was less pronounced, resulting in fewer differences between pictures. Overall, these different shooting methods enabled us to capture various scenarios and lighting conditions, providing a comprehensive dataset for our research (
Table 3).
2.3. Data Enhancement
To make the model training converge faster to achieve better results and obtain a robust model, we used common data augmentation, where we changed the data systematically or randomly using code. For images, common data enhancements including flipping, adjusting colours, and adding random noise were applied (
Figure 5). We also used the Mosaic data enhancement method proposed in the YOLOV4 [
28] paper. The basic idea of Mosaic data enhancement is to stitch multiple images together to produce a new image. These images can be from different datasets or the same dataset. The stitched images can be used to train a grazing sheep behaviour recognition model to improve the model’s generalisation ability.
2.4. Model Improvement Implementation
2.4.1. YOLO Series Models
The You Only Look Once (YOLO) [
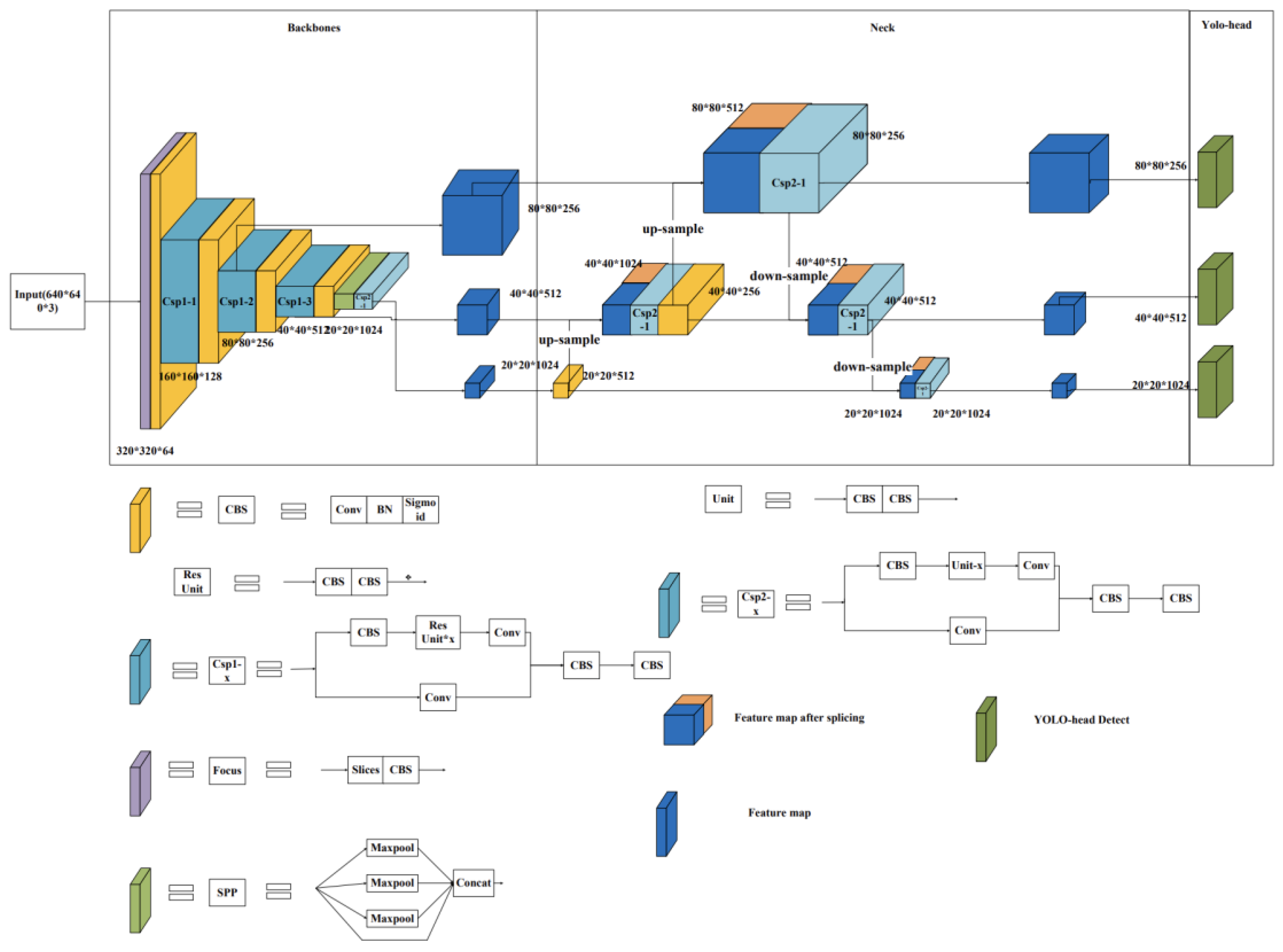
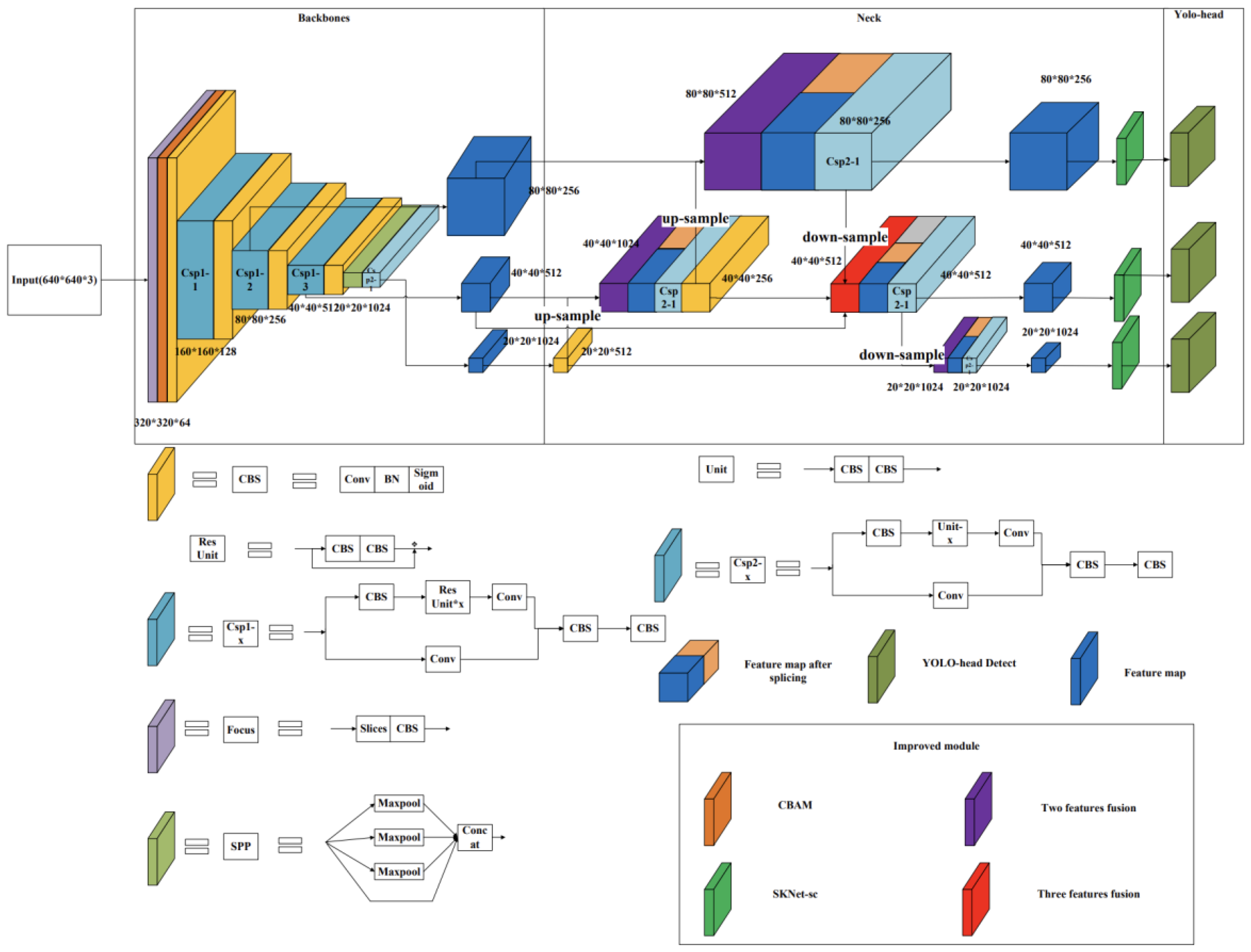
29] family is a fast target detection model for object recognition in images or videos, which differs from traditional classification and localisation models (e.g., the R-CNN family) by predicting multiple targets in a single step. The YOLO family of models includes YOLOV1, YOLOV2, YOLOV3, etc., with the latest version currently being the YOLOV8 model. The series of models consists of three main parts: a backbone network for extracting image features, a feature fusion layer for combining different scale features for prediction, and a YOLO detection head to give multiple predictions. The primary choice in this article is the YOLOV5s model (network structure as shown in
Figure 6) for improving daily behaviour recognition during sheep grazing. Three main modules were chosen to strengthen the network. Firstly, the convolutional block attention module (CBAM) [
30] was included to adjust the relationship between channel and space to enhance the performance of convolutional feature extraction. Then, the idea of the bidirectional feature pyramid network (BiFPN) [
31] was introduced in the feature fusion stage to configure weights on features of different scales for fusion. Lastly, the residual variant selective kernel networks-skip connect (SKNet-sc) was added. The SKNet-sc introduces the attention mechanism to the fused feature map to enhance the feature role and improve the accuracy for subsequent detection.
2.4.2. CBAMs
Factoring in many lighting conditions and diverse recognition scenes to improve extract image features, we introduced the CBAM. The CBAM can enhance the ability of convolutional neural networks (CNNs) to extract features by introducing channel and spatial attention mechanisms to improve network performance.
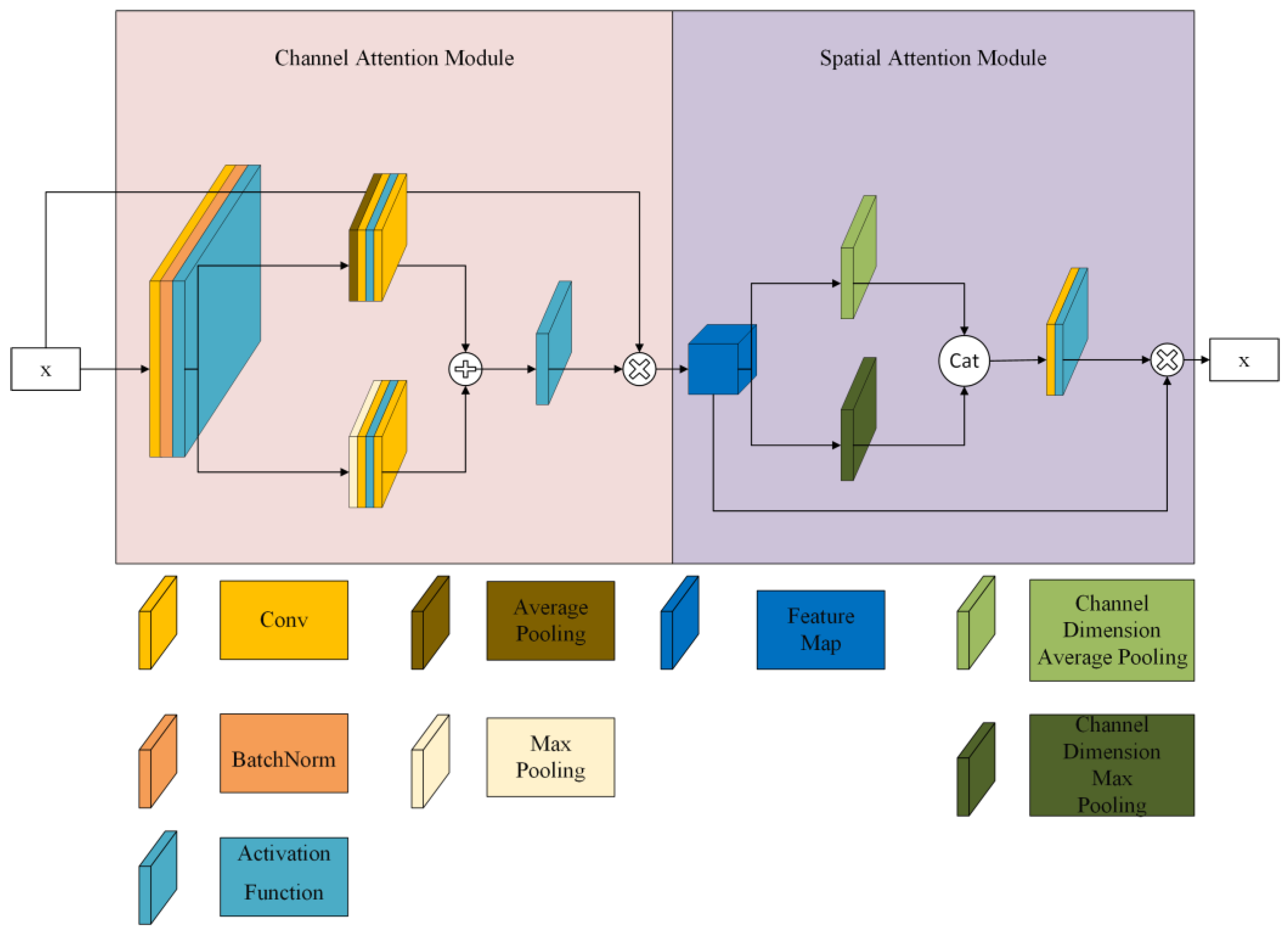
Sanghyun et al. [
30] proposed a CBAM (
Figure 7) that combines feature channel information and feature spatial information, which can be divided into two submodules: the channel attention module (CAM) and the spatial attention module (SAM). The channel attention module is mainly used to adaptively adjust the importance of each channel to improve the representation of features. The spatial attention module captures the spatial relationships in the feature map. By combining the CAM and SAM, the CBAM can adaptively adjust the channels and spatial relationships to improve the performance of the CNN.
2.4.3. BiFPN Network Architecture
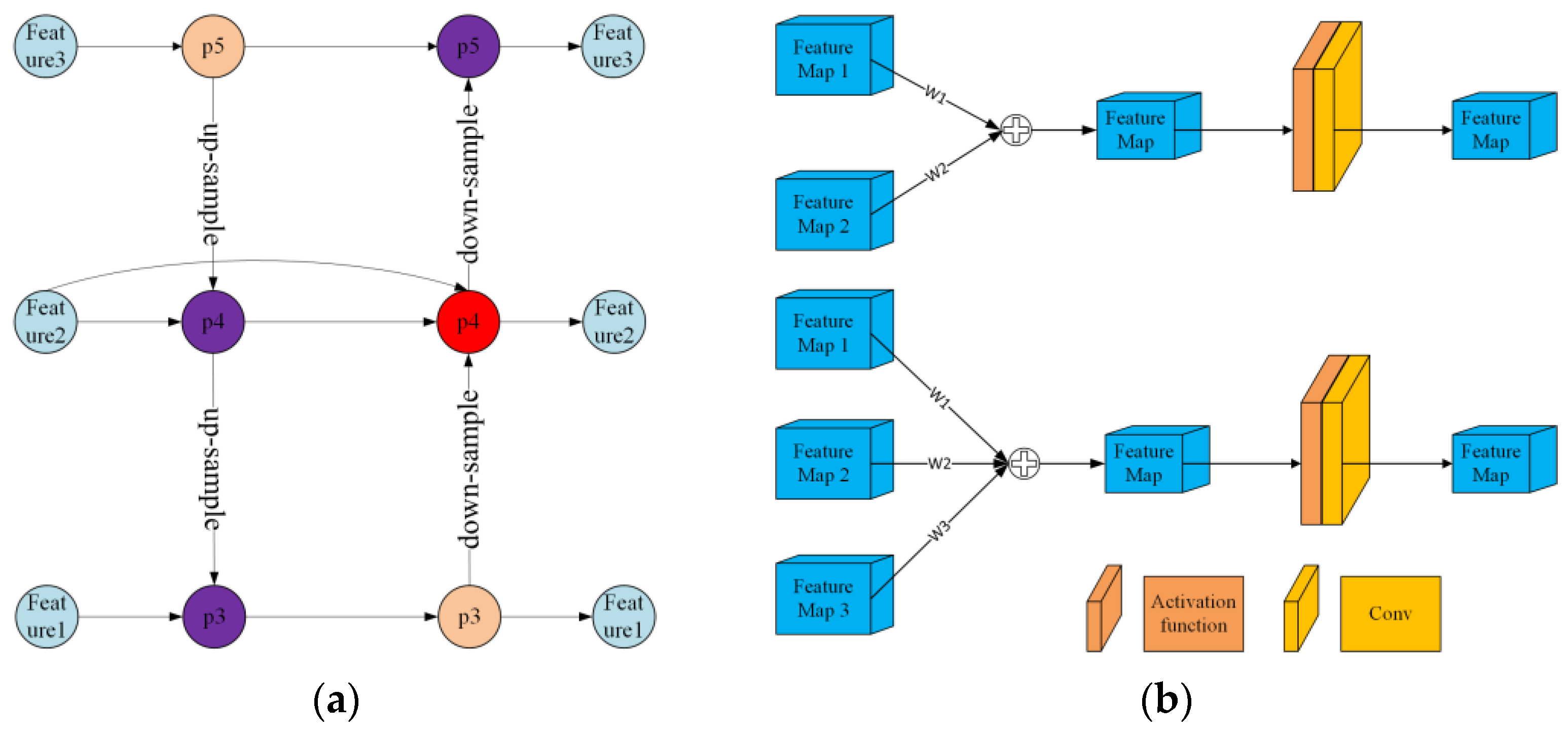
BiFPN is a shorthand for bidirectional feature pyramid network, which is a neural network architecture commonly utilised in computer vision tasks, especially in object detection and segmentation. This architecture is an extension of the feature pyramid network (FPN) and aims to address the challenge of detecting objects at varying scales in an image. The BiFPN is made up of multiple layers that refine and aggregate features from different levels of the feature pyramid. The significant innovation of the BiFPN lies in its use of both bottom-up and top-down pathways to transmit information across layers, allowing for bidirectional flow of information. This approach captures more detailed features at different scales, resulting in superior object detection and segmentation performance. We have introduced this structure into YOLOV5; the specific network fusion structure is shown in
Figure 8a. The main idea was to set different weights for different features, then add them together, and finally perform activation and convolution to obtain the fused features, as shown in
Figure 8b.
2.4.4. SKNet-sc Module
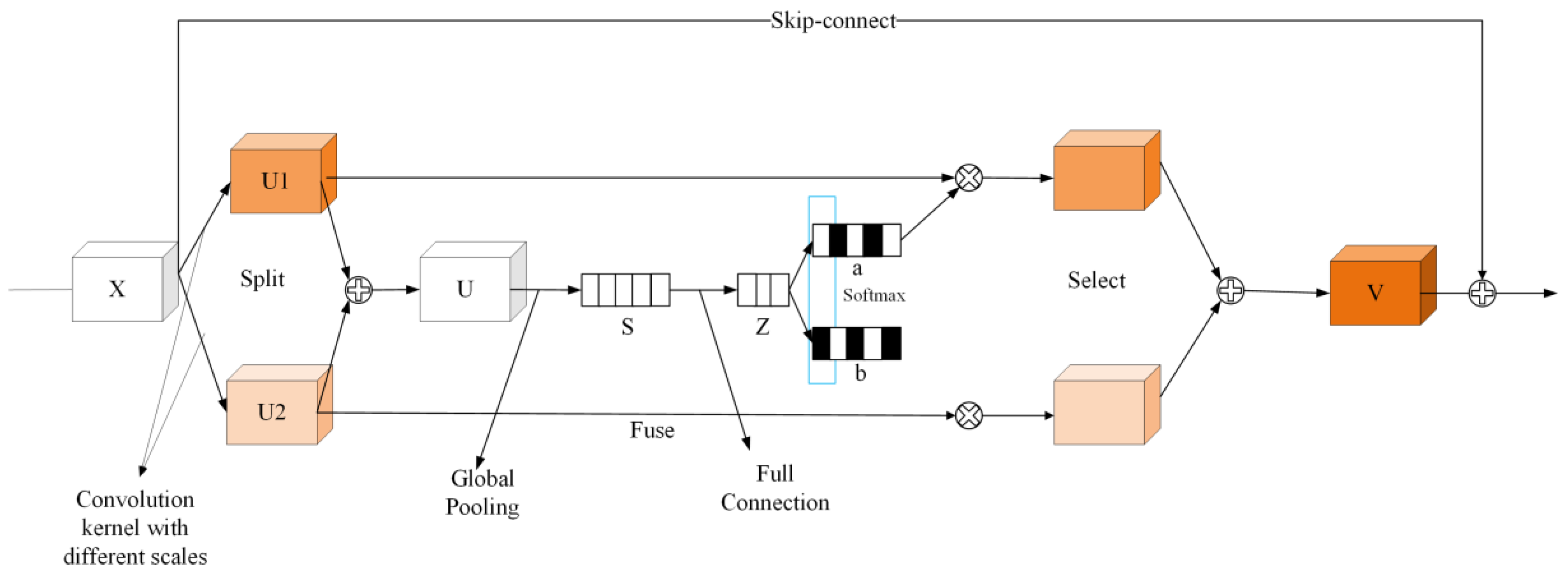
SKNet refers to selective kernel network, a neural network architecture developed to enhance the performance of convolutional neural networks (CNNs) in image recognition tasks. SKNet focuses on learning the importance of different convolutional kernel sizes at each network layer and selectively combining them to capture both local and global features in the input image. SKNet-sc is based on SKNet [
32] with the addition of a residual connection. SKNet employs dynamically selected convolutions to improve accuracy through three main operations: split, fuse, and select. Following these operations, a skip connection is established between the output and input to integrate the fused and filtered features with the original ones. The features are then scaled up to provide a foundation for subsequent detection using the detection head. The network structure is shown in
Figure 9.
2.4.5. Improved YOLOV5 Model
In this study, three modules were chosen to improve YOLOV5. Before feature extraction, a CBAM was added to increase the channel and spatial attention to improve convolution performance. A subsequent convolution was performed to extract features using a BiFPN structure for feature fusion after feature extraction. The combining of features and weights of different sizes and scales to fuse features makes full use of the SKNet-sc structure for each of the three scales before detection. An attention mechanism was added to the fused features so that the feature map amplified more critical features and improved accuracy. The improved network model is shown in
Figure 10.
2.5. Model Evaluation
This study used model evaluation metrics commonly utilised in target detection, including Precision, Recall, F1-score, average precision (AP), mean average precision (mAP), frames per second (FPS), and model size to evaluate our experimental model. Precision indicates the proportion of results predicted to be true for a behaviour of sheep; Recall indicates the proportion of all data predicted to be true for a behaviour. The F1-score is used to assess the relationship between Precision and Recall evaluations. AP is the average accuracy for each classification of sheep’s behaviour. The mAP is an average of the average accuracy of the three behavioural classifications, resulting in the average accuracy of the model as a whole, which is the main evaluation indicator of the model. At the same time, the calculation of mAP adopts the calculation method of multiple IOU thresholds. The mAP@0.5 is the average accuracy of the three behaviours when the IOU threshold is 0.5. The mAP@0.75 is the average accuracy of the three behaviours when the IOU threshold is 0.75. The mAP@0.5:0.95 represents the average mAP of different IOU thresholds (from 0.5 to 0.95, step size 0.05). FPS is used to evaluate the speed of object detection, which refers to the number of images that can be processed per second.
For the above model evaluation metrics, the specific formulas are as follows: true positive (TP) is the number of positive samples detected correctly. False positive (FP) is the number of negative samples detected as positive. False negative (FN) is the number of positive samples detected as negative.
4. Discussion
When performing model training comparisons with photos from different shooting styles, the data from the two shooting styles differed; however, their label ratios were essentially the same. The models differed by only 0.6% on their respective validation sets’ mAP
@0.5, while mAP
@0.5 with models from different shooting styles across the entire dataset differed by less than 1%. Cheng et al. [
16] investigated the performance of sheep behaviour in housing on different picture features, with various features based on different shooting angles to build features, pointing out that very few data are needed to achieve good results when the scene is fixed. Yang et al. [
4] used a fully convolutional network (FCN) to segment images of lactating sows with different scenes, variable illumination, etc. When selecting data for the training model, there is a limit to the number of photos for the same scene. The model convergence cannot continue to improve accuracy after reaching a certain number of iterations. When performing behavioural recognition of sheep in grassland, multiple scenes of data collection are used to maintain the robustness of the model.
We selected the YOLOV5 model for improving the behavioural recognition model. As shown in
Table 7, YOLOV5 outperforms other models with only small differences in recognition accuracy, but with fewer parameters and faster inference speed. Additionally, previous studies on digital agriculture have extensively used and applied YOLOV5, which has demonstrated both high accuracy and fast inference speed. Therefore, we chose to utilise and improve the YOLOV5 model for our study. Qi et al. [
33] proposed an improved SE-YOLOV5 network model for identifying tomato virus diseases, which achieved a 1.87% increase in mAP
@0.5 compared to the original YOLOV5 model. The SE-YOLOV5 model can effectively detect regions affected by tomato virus diseases. Wang et al. [
34] proposed an enhanced YOLOV5-based method for detecting cow oestrus behaviour, which increased the model’s accuracy in identifying cow oestrus events by 5.9%. To improve the model, we explored the progress of the model accuracy by adding different modules. Hence, the recognition effect was improved by adding several modules. The final mAP
@0.5 showed an improvement of 1.7%, as shown in
Table 8. The results in
Figure 13 demonstrate the successful performance of the model in recognising sheep behaviour. Nevertheless, obscuration hindered the accuracy of judging the behaviour of the sheep. For instance, if the sheep’s position was relatively close to the picture, the sheep was unidentifiable, resulting in low accuracy. Additionally, the angle of the camera view has a significant impact on the quality of the image, and it may be beneficial to use multiple cameras to capture different perspectives of the sheep’s behaviour and obtain more comprehensive data.
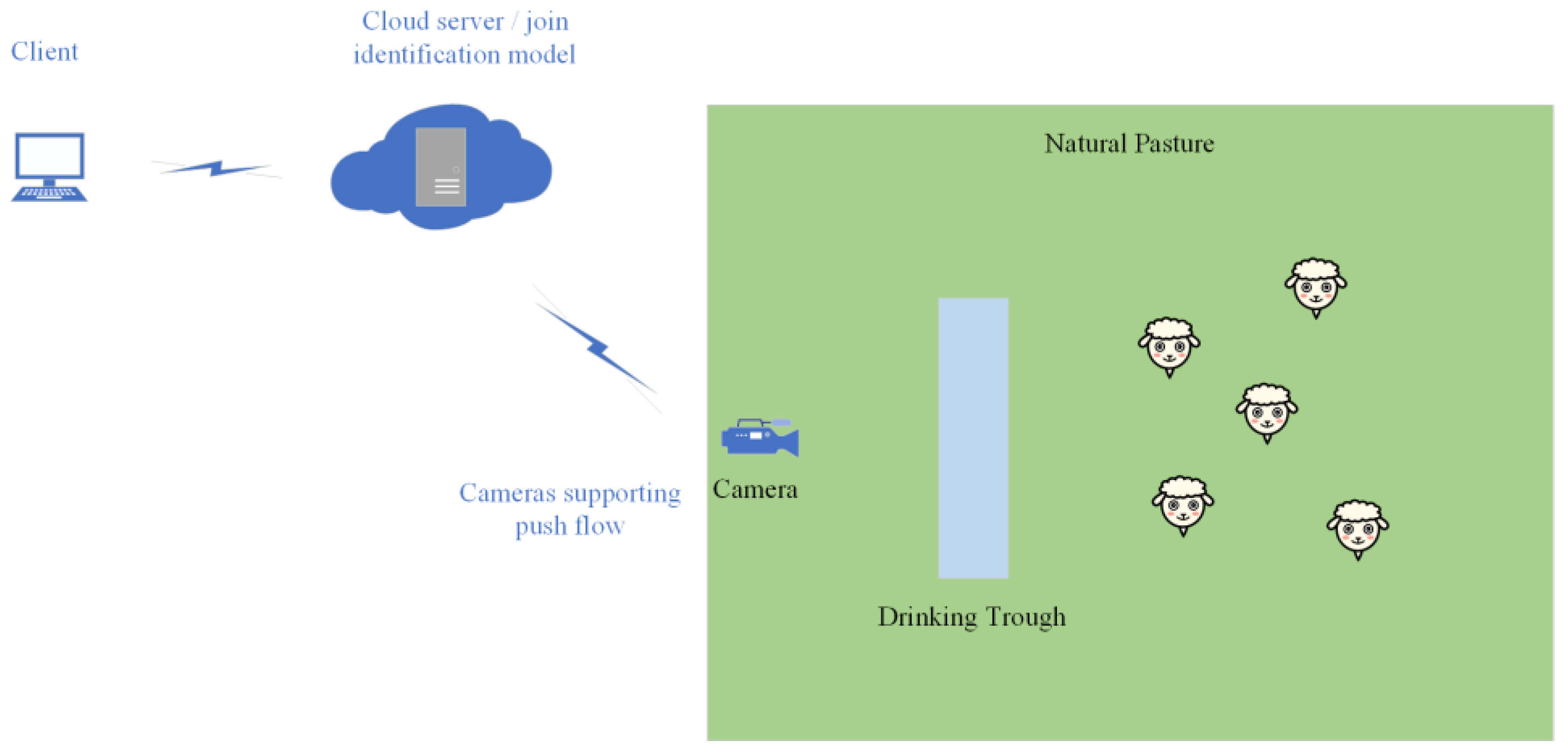
Real-time detection is a valuable application for models, as they can be integrated into real-time monitoring systems to maximise their benefits. This paper presents a design solution for a real-time system, providing guidance for model deployment. Wang et al. [
35] developed the YOLO-CBAM convolutional neural network model to detect Solanum rostratum Dunal seedlings and conducted real-time testing using an inspection vehicle equipped with cameras, image processors, and other devices. Real-time detection systems can either rely on server-side detection through network transmission or deploy models on edge devices for detection, with the choice mainly determined by the specific detection scenario.
Since this study focuses on the daily behavioural recognition of sheep in pastures, in the future, more scenarios in sheep abnormality recognition and sheep social behaviour can be combined to ensure more sensitive and timely recognition of abnormal sheep (those exhibiting behavioural abnormalities such as movement disorders and aggressive behaviour) in the pasture.
5. Conclusions
From the focal point of sheep behaviour recognition in the pasture, this study utilised different shooting methods to model sheep’s daily behaviour (standing, feeding, lying) based on the YOLOV5 algorithm in the pasture terrain. It can be conclusively stated that identifying sheep behaviour using two angles is feasible, giving the model a certain generalisation ability. Based on the YOLOV5 algorithm, the model was improved. The improvement was achieved by adding the CBAM, BiFPN module, and SKNet-sc module to the model, resulting in model mAP@0.5 enhancement, generating the highest value of 0.918, an increase of 1.7%. The study enables livestock researchers to observe sheep behaviour visually and clearly, thereby saving time and labour in various studies. This advancement facilitates researchers in acquiring data more rapidly, holding significant implications for remote observation and diagnosis within the realm of precision farming. However, there are certain limitations to this study. Firstly, the study site is relatively small, and it is recommended that in a real pasture application, cameras should be positioned at water sources and specific locations such as fence boundaries to enable multi-angle detection. Additionally, the sheep involved in the study were limited to a single breed and grazing scenario. To address these limitations, we plan to expand our research in two key ways. Firstly, we aim to investigate the behaviour of sheep in multiple breeds and flocks. Secondly, we plan to incorporate additional behaviours such as running, walking, and social interactions into our video-based behavioural recognition system. These improvements will enhance the utility of our research findings and facilitate remote observation and diagnosis in the context of precision farming.



 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}