
Joint Modal Alignment and Feature Enhancement for Visible-Infrared Person Re-Identification
Abstract
:1. Introduction
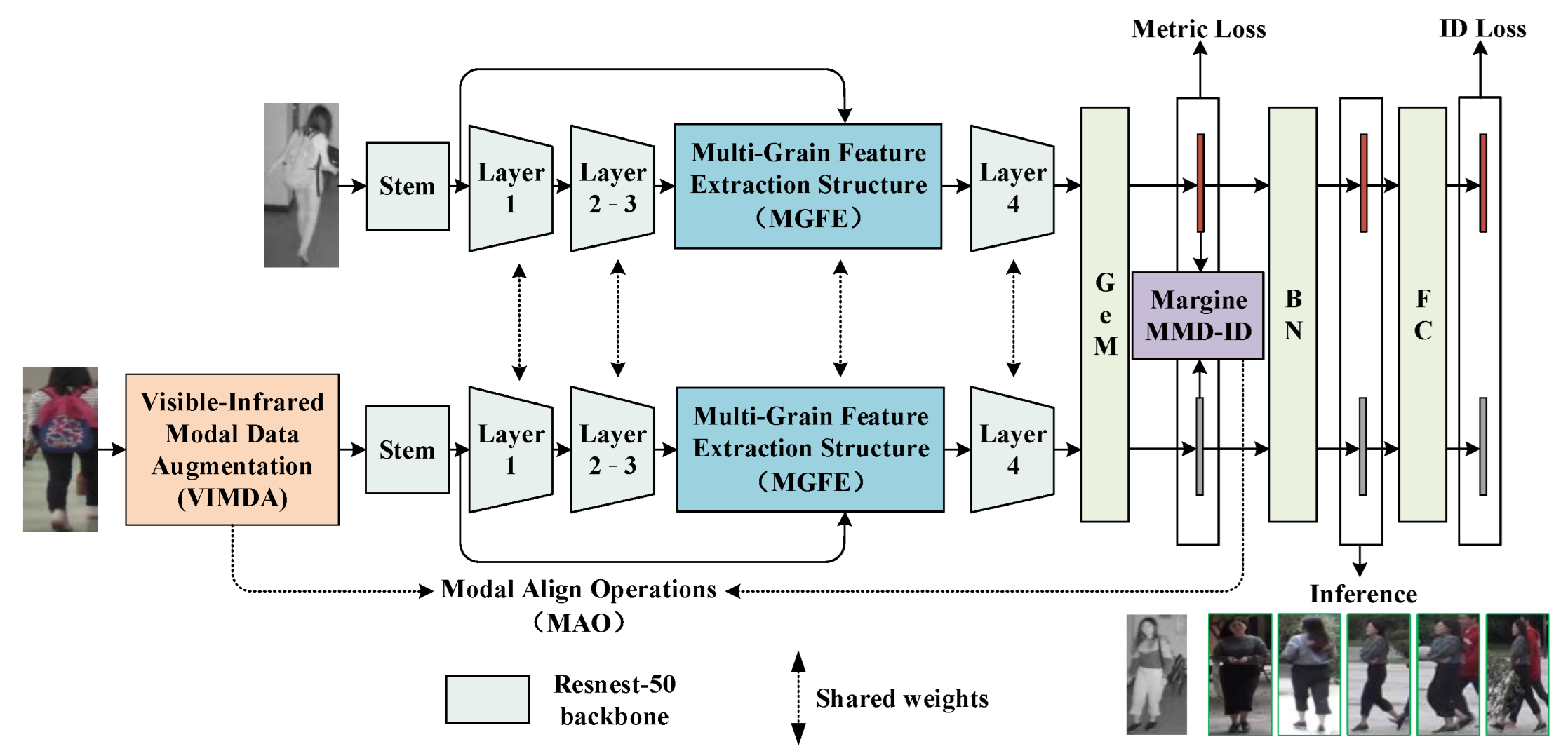
- The Joint Modal Alignment and Feature Enhancement (MAFE) network for visible-infrared person re-id is proposed to improve modal alignment and feature learning.
- Modal Align Operations (MAO), including Visible-Infrared Modal Data Augmentation (VIMDA) and Margin MMD-ID Loss, were introduced for modal alignment.
- The Multi-Grain Feature Extraction (MGFE) Structure was constructed to obtain multi-grain and discriminative features.
- Experiments on the SYSU-MM01 and the RegDB showed that our proposed method achieved the SOTA.
2. Related Works
2.1. Visible-Infrared Person Re-Identification
2.2. Data Augmentation
2.3. Feature Extraction
3. Method
3.1. Overview
3.2. Modal Alignment Operations (MAO)
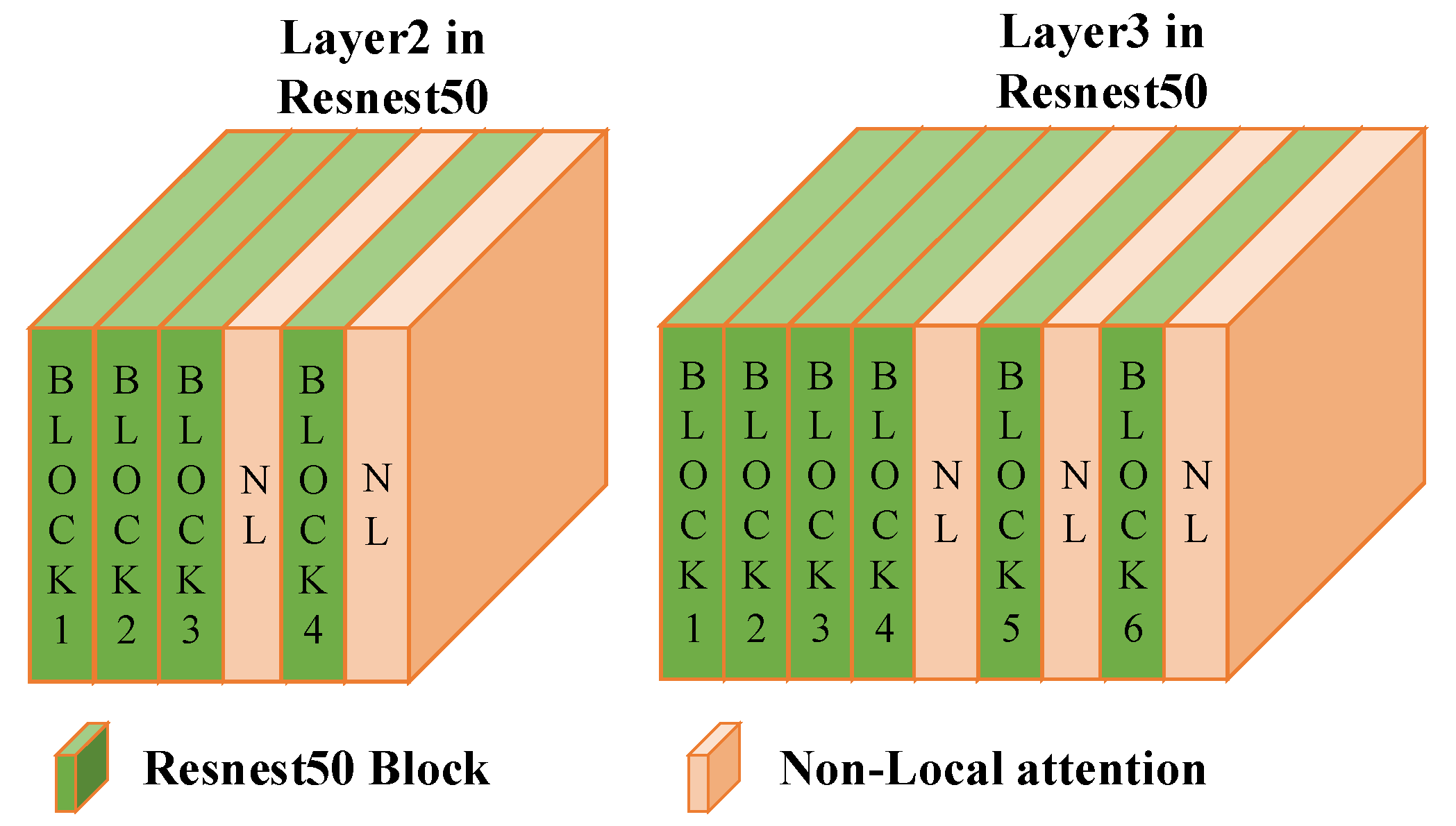
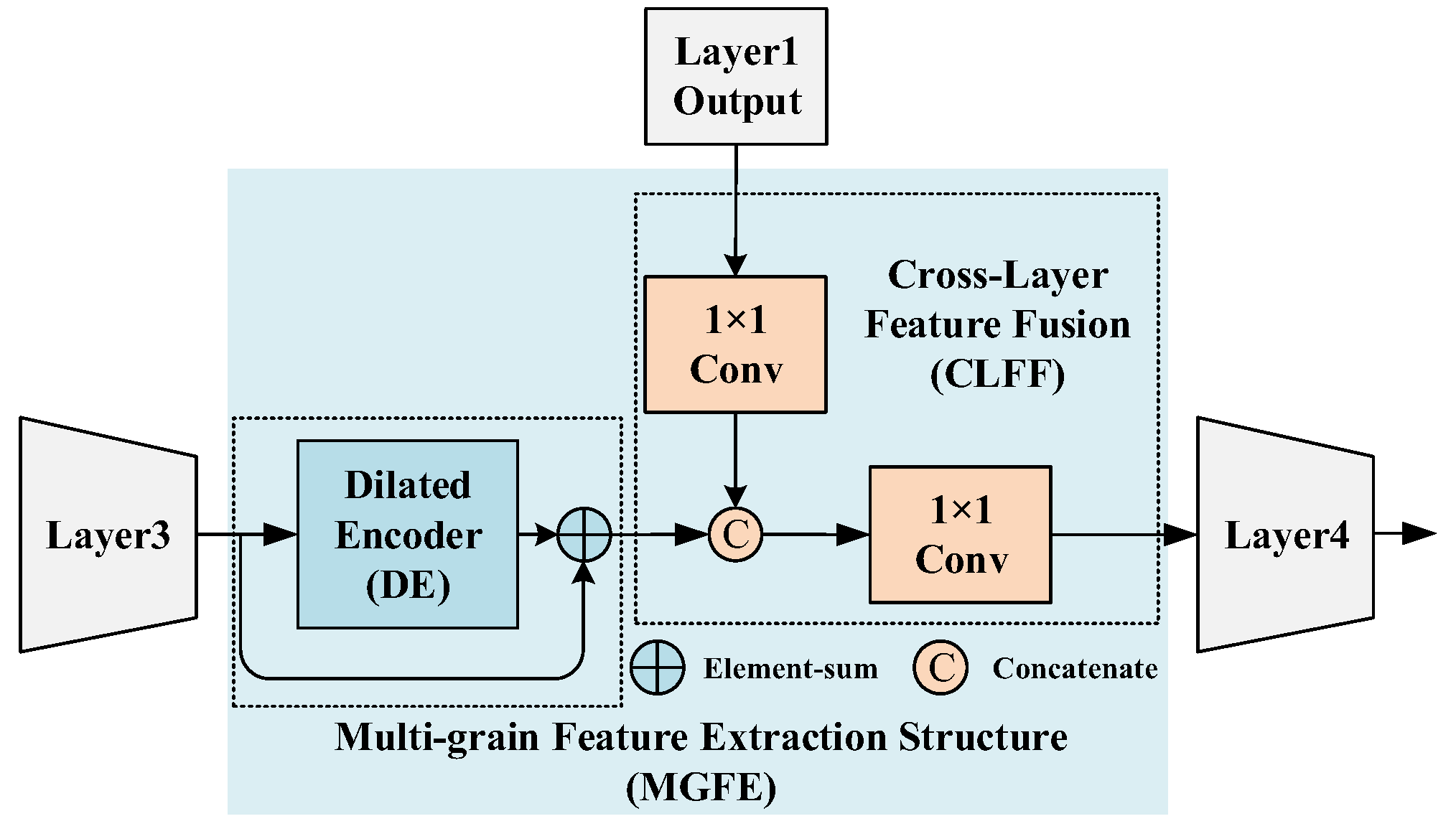
3.3. Multi-Grain Feature Extraction (MGFE) Structure
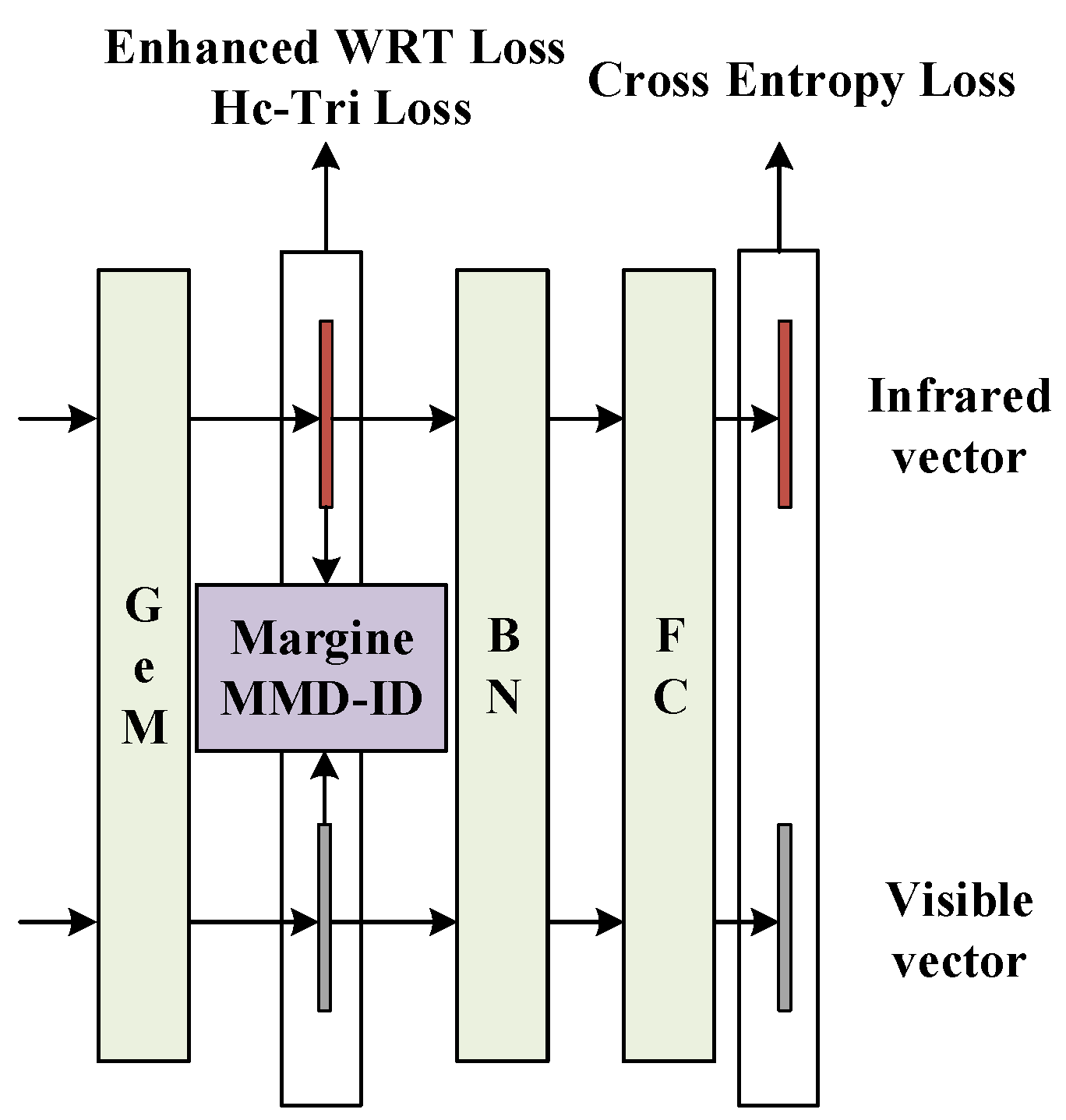
3.4. Loss Function
4. Experiments
4.1. Datasets and Evaluation Metric
4.1.1. Datasets
4.1.2. Evaluation Metric
4.2. Experimental Settings
4.2.1. Basic Settings
4.2.2. Test Settings
4.3. Comparison with Existing Methods
4.4. Ablation Study
4.4.1. Ablation Experiments of Each Component
4.4.2. Analysis of the probability ratio in VIMDA
4.4.3. Ablation Experiments of Cross-Layer Feature Fusion (CLFF)
4.4.4. Analysis of Different Backbones
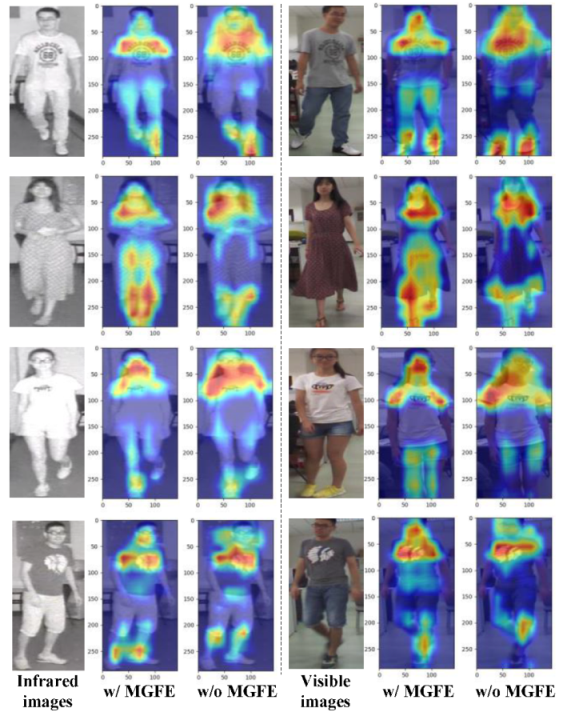
4.5. Visualization and Analysis
4.5.1. Heat Map Analysis of MGFE
4.5.2. Output of Visible-Infrared Person Re-ID Results
5. Discussion
5.1. Next Challenges and Future Perspective
5.2. Replicability of the Method
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Dong, Q.; Zhang, Z.; Liu, S.; Durrani, T.S. Cross-Modality Person Re-Identification via Local Paired Graph Attention Network. Sensors 2023, 23, 4011. [Google Scholar] [CrossRef] [PubMed]
- Saber, S.; Meshoul, S.; Amin, K.; Pławiak, P.; Hammad, M. A Multi-Attention Approach for Person Re-Identification Using Deep Learning. Sensors 2023, 23, 3678. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.K.; Hsu, C.C.; Wang, W.Y. Person Re-Identification with Improved Performance by Incor-porating Focal Tversky Loss in AGW Baseline. Sensors 2022, 22, 9852. [Google Scholar] [CrossRef] [PubMed]
- Ren, D.; He, T.; Dong, H. Joint Cross-Consistency Learning and Multi-Feature Fusion for Person Re-Identification. Sensors 2022, 22, 9387. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Wan, L.; Li, Z.; Jing, Q.; Sun, Z. Neural feature search for rgb-infrared person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Fu, C.; Hu, Y.; Wu, X.; Shi, H.; Mei, T.; He, R. CM-NAS: Cross-Modality Neural Architecture Search for Visible-Infrared Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Jiang, K.; Zhang, T.; Liu, X.; Qian, B.; Zhang, Y.; Wu, F. Cross-Modality Transformer for Visible-Infrared Person Re-Identification. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XIV. Springer Nature: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Wei, Z.; Yang, X.; Wang, N.; Gao, X. Syncretic Modality Collaborative Learning for Visible Infrared Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Wu, Q.; Dai, P.; Chen, J.; Lin, C.W.; Wu, Y.; Huang, F.; Ji, R. Discover cross-modality nuances for visible-infrared person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Ye, M.; Lan, X.; Li, J.; Yuen, P. Hierarchical Discriminative Learning for Visible Thermal Person Re-Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, T.; Cheng, J.; Liu, S.; Yang, Y.; Hou, Z. RGB-Infrared Cross-Modality Person Re-Identification via Joint Pixel and Feature Alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Z.; Zheng, Y.; Chuang, Y.-Y.; Satoh, S. Learning to Reduce Dual-Level Discrepancy for Infrared-Visible Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Ye, M.; Ruan, W.; Du, B.; Shou, M.Z. Channel augmented joint learning for visible-infrared recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Ling, Y.; Zhong, Z.; Cao, D.; Luo, Z.; Lin, Y.; Li, S.; Sebe, N. Cross-Modality Earth Mover’s Distance for Visible Thermal Person Re-Identification. arXiv 2022, arXiv:2203.01675. [Google Scholar]
- Jambigi, C.; Rawal, R.; Chakraborty, A. Mmd-reid: A simple but effective solution for visible-thermal person reid. arXiv 2021, arXiv:2111.05059. [Google Scholar]
- Wu, A.; Zheng, W.S.; Yu, H.X.; Gong, S.; Lai, J. RGB-infrared cross-modality person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Gao, Y.; Liang, T.; Jin, Y.; Gu, X.; Liu, W.; Li, Y.; Lang, C. MSO: Multi-Feature Space Joint Optimization Network for RGB-Infrared Person Re-Identification. In Proceedings of the 29th ACM International Conference on Multimedia, New York, NY, USA, 20–24 October 2021. [Google Scholar] [CrossRef]
- Liu, H.; Tan, X.; Zhou, X. Parameter Sharing Exploration and Hetero-Center Triplet Loss for Visible-Thermal Person Re-Identification. IEEE Trans. Multimedia 2020, 23, 4414–4425. [Google Scholar] [CrossRef]
- Hao, X.; Zhao, S.; Ye, M.; Shen, J. Cross-Modality Person Re-Identification via Modality Confusion and Center Aggregation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Kaiwei, J.; Jin, W.; Linyu, Z.; Xin, L.; Guoqing, L. Cross-modality person re-identification using local supervision. Appl. Res. Comput. 2023, 40, 1226–1232. [Google Scholar]
- Ancon, W.; Chengzhi, L.; Weishi, Z. Single-modality self-supervised information mining for cross-modality person re-identification. J. Image Graph. 2022, 27, 2843–2859. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Radenović, F.; Giorgos, T.; Ondřej, C. Fine-tuning CNN image retrieval with no human annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1655–1668. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.T.; Gil Hong, H.; Kim, K.W.; Park, K.R. Person Recognition System Based on a Combination of Body Images from Visible Light and Thermal Cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef] [PubMed]
- Choi, S.; Lee, S.; Kim, Y.; Kim, T.; Kim, C. Hi-CMD: Hierarchical Cross-Modality Disentanglement for Visible-Infrared Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Li, D.; Wei, X.; Hong, X.; Gong, Y. Infrared-Visible Cross-Modal Person Re-Identification with an X Modality. Proc. Conf. AAAI Artif. Intell. 2020, 34, 4610–4617. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Crandall, D.J.; Shao, L.; Luo, J. Dynamic Dual-Attentive Aggregation Learning for Visible-Infrared Person Re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVII 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Shao, L. Visible-Infrared Person Re-Identification via Homogeneous Augmented Tri-Modal Learning. IEEE Trans. Inf. Forensics Secur. 2020, 16, 728–739. [Google Scholar] [CrossRef]
- Zhang, Q.; Lai, C.; Liu, J.; Huang, N.; Han, J. FMCNet: Feature-Level Modality Compensation for Visible-Infrared Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Liu, J.; Sun, Y.; Zhu, F.; Pei, H.; Yang, Y.; Li, W. Learning Memory-Augmented Unidirectional Metrics for Cross-modality Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. arXiv 2016, arXiv:1610.02391. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Venue | SYSU-MM01 | RegDB | ||||||
|---|---|---|---|---|---|---|---|---|---|
| All Search | Indoor Search | Visible to Infrared | Infrared to Visible | ||||||
| Rank1 | mAP | Rank1 | mAP | Rank1 | mAP | Rank1 | mAP | ||
| Hi-CMD [32] | CVPR2020 | 34.9 | 35.9 | - | - | 70.93 | 66.04 | - | - |
| X-Modal [33] | AAAI2020 | 49.9 | 50.7 | - | - | 62.21 | 60.18 | - | - |
| DDAG [34] | ECCV2020 | 54.75 | 53.02 | 61.02 | 67.98 | 69.34 | 63.46 | 68.06 | 61.8 |
| HAT [35] | TIFS2020 | 55.29 | 53.89 | 62.1 | 69.37 | 71.83 | 67.56 | 70.02 | 66.3 |
| NFS [6] | CVPR2021 | 56.91 | 55.45 | 62.76 | 69.79 | 80.54 | 72.1 | 77.95 | 69.79 |
| MSO [18] | ACMMM2021 | 58.7 | 56.42 | 63.09 | 70.31 | 73.6 | 66.9 | 74.6 | 67.5 |
| CM-NAS [7] | ICCV2021 | 61.99 | 60.02 | 67.01 | 72.95 | 84.54 | 80.32 | 82.57 | 78.31 |
| MCLNet [20] | ICCV2021 | 65.4 | 61.98 | 72.56 | 76.58 | 80.31 | 73.07 | 75.93 | 69.49 |
| SMCL [9] | ICCV2021 | 67.39 | 61.78 | 68.84 | 75.56 | 83.93 | 79.83 | 83.05 | 78.57 |
| CAJ [14] | ICCV2021 | 69.88 | 66.89 | 76.26 | 80.37 | 85.03 | 79.14 | 84.75 | 77.82 |
| MPANet [10] | CVPR2021 | 70.58 | 68.24 | 76.74 | 80.95 | 82.8 | 80.7 | 83.7 | 80.9 |
| FMCNet [36] | CVPR2022 | 66.34 | 62.51 | 68.15 | 74.09 | 89.12 | 84.43 | 88.38 | 83.86 |
| MAUM [37] | CVPR2022 | 71.68 | 68.79 | 76.97 | 81.94 | 87.87 | 85.09 | 86.95 | 84.34 |
| MAFE | ours | 74.85 | 71.7 | 80.85 | 84.06 | 91.17 | 81.81 | 90.05 | 80.27 |
| No. | MAO | MGFE | SYSU-MM01 (All Search) | |||
|---|---|---|---|---|---|---|
| VIMDA | Margin MMD-ID Loss | CLFF | DE | Rank1 | mAP | |
| 1 | - | - | - | - | 68.7 | 65.7 |
| 2 | √ | - | - | - | 70.57 | 68.04 |
| 3 | √ | √ | - | - | 71.1 | 68.03 |
| 4 | √ | √ | - | √ | 72.02 | 68.84 |
| 5 | √ | √ | √ | - | 73.23 | 70.47 |
| 6 | √ | √ | √ | √ | 74.85 | 71.7 |
| Feature Fusion | SYSU-MM01 (All Search) | |
|---|---|---|
| Rank1 | mAP | |
| 0→2 | 69.63 | 66.34 |
| 1→2 | 68.74 | 65.41 |
| 0,1→2 | 67.73 | 64.31 |
| 0→R_O | 73.66 | 70.93 |
| 1→R_O | 74.85 | 71.7 |
| 2→R_O | 72.52 | 69.59 |
| 0,1→R_O | 73.64 | 70.04 |
| 0,2→R_O | 74.8 | 71.39 |
| 1,2→R_O | 72.56 | 68.41 |
| 0,1,2→R_O | 73.48 | 70.01 |
| Method | SYSU-MM01 (All Search) | |
|---|---|---|
| Rank1 | mAP | |
| Resnet50 | 64.93 | 62.26 |
| Resnet50_with_MAO and MGFE | 69.27 | 65.42 |
| Res2Net50 | 62.02 | 60.02 |
| Res2Net50_with_MAO and MGFE | 69.21 | 66.52 |
| Resnest50 | 68.7 | 65.7 |
| Resnest50_with_MAO and MGFE (proposed method) | 74.85 | 71.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, R.; Wang, R.; Zhang, W.; Wu, A.; Bi, Y. Joint Modal Alignment and Feature Enhancement for Visible-Infrared Person Re-Identification. Sensors 2023, 23, 4988. https://doi.org/10.3390/s23114988
Lin R, Wang R, Zhang W, Wu A, Bi Y. Joint Modal Alignment and Feature Enhancement for Visible-Infrared Person Re-Identification. Sensors. 2023; 23(11):4988. https://doi.org/10.3390/s23114988
Chicago/Turabian StyleLin, Ronghui, Rong Wang, Wenjing Zhang, Ao Wu, and Yihan Bi. 2023. "Joint Modal Alignment and Feature Enhancement for Visible-Infrared Person Re-Identification" Sensors 23, no. 11: 4988. https://doi.org/10.3390/s23114988