1. Introduction
One of the enduring challenges for the autonomous agent in the field of geoinformatics, computer vision, and robotics is to determine its location in the environment. The concept of location is inherently relative, and one cannot describe the location of an object without providing a reference or map. For instance, the location of a person in a city can be specified by how far away that person is from a building, or the location can be pinned on a map. Without loss of generality, all localization techniques generally provide two basic pieces of information: (1) what is the current position (precise or coarse, 2D or 3D) of the object in some reference or map? (2) what is the orientation (2D or 3D) in that same reference or map? The first could be in the form of Cartesian or geographic latitude and longitude or coarse location such as on a certain road or intersection. The second could be a combination of roll, pitch, and yaw or a compass heading. We define the localization in this article as the act of finding an object’s coarse location against a 2D map. Despite many published studies, localization problems still require further research, especially when the global positioning system (GPS) signal is not available in the presence of tall buildings, jammed signals, or indoors [
1].
The human brain is a brilliant information processor and is exceptionally skilled at finding one’s location on a map. Such extraordinary abilities have attracted much attention from neuroscientists seeking to explore and model how the human brain performs this fundamental cognitive task. An early neuroscience study has shown that an internal map of the environment referred to as the “cognitive map” uses a graph representation to locate oneself [
2] and navigate to a designated destination [
3]. For instance, in vector-based navigation agents can simply find their location on a map based on the distance they traversed and corners they turned [
4,
5]. Understanding such a process and building computational models is crucial to offer advanced artificial intelligent capabilities to a number of applications, including path planning [
6] and navigation [
7].
In parallel with the exploration of biological mechanisms for localization and navigation, engineered alternative solutions have also been designed to achieve such functionality. The most commonly used system is the GPS, which was established in the 1970s for outdoor positioning using the constellation of a satellite network [
8]. Apart from GPS, traditional relative localization typically utilizes visual or inertial information to simultaneously compute the platform’s pose and 3D environmental structure [
9]. Despite these studies, there is still no widely accepted solution for localization in challenging conditions, due to environmental confusers, sensor drifts, multi-path problems, and high computational costs.
Unlike the GPS embedded in devices, our brain’s system accesses location and navigation information by integrating multiple signals relating internal self-motion (path integration) [
10] and planning direct trajectories to goals (vector-based navigation) [
3,
11]. Recent research [
11,
12] has shown that the mammalian brain uses an incredibly sophisticated GPS-like localization and tracking system of its own to help recognize locations and guide them from one location to the next. One typical method used is called path integration [
10], a mechanism of calculating location simply by integrating self-motion information, including direction and speed of movement—a task carried out without reference to external cues such as physical landmarks. Another method suggested representing space as a graph structure in which nodes denote specific places and links are represented as roads between pairs of nodes [
5]. The resulting graph reflects the topology of the explored environment upon which localization and navigation can be directly implemented by the graph search algorithm. This paper aims at exploiting characteristics from these two methods together.
With the recent progress in deep learning, especially for graph neural networks (GNN) [
13,
14,
15,
16], researchers have shown powerful models that yield expressive embedding of non-Euclidean data and result in promising performances in a variety of tasks [
7,
17,
18]. In this paper, the characteristic of a topological map defined on the non-Euclidean domain makes graph neural network architectures very suitable for topological geolocalization problems.
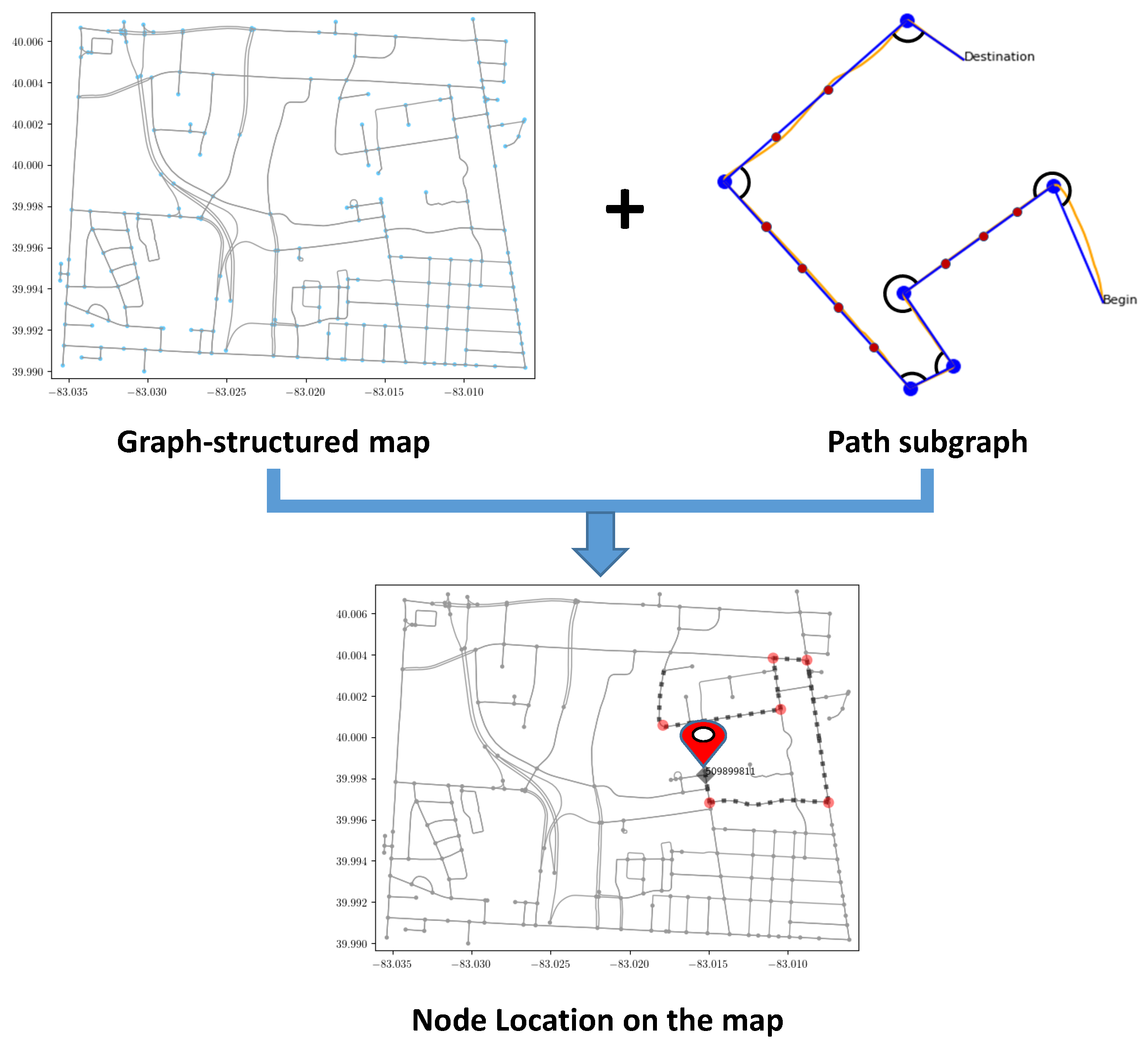
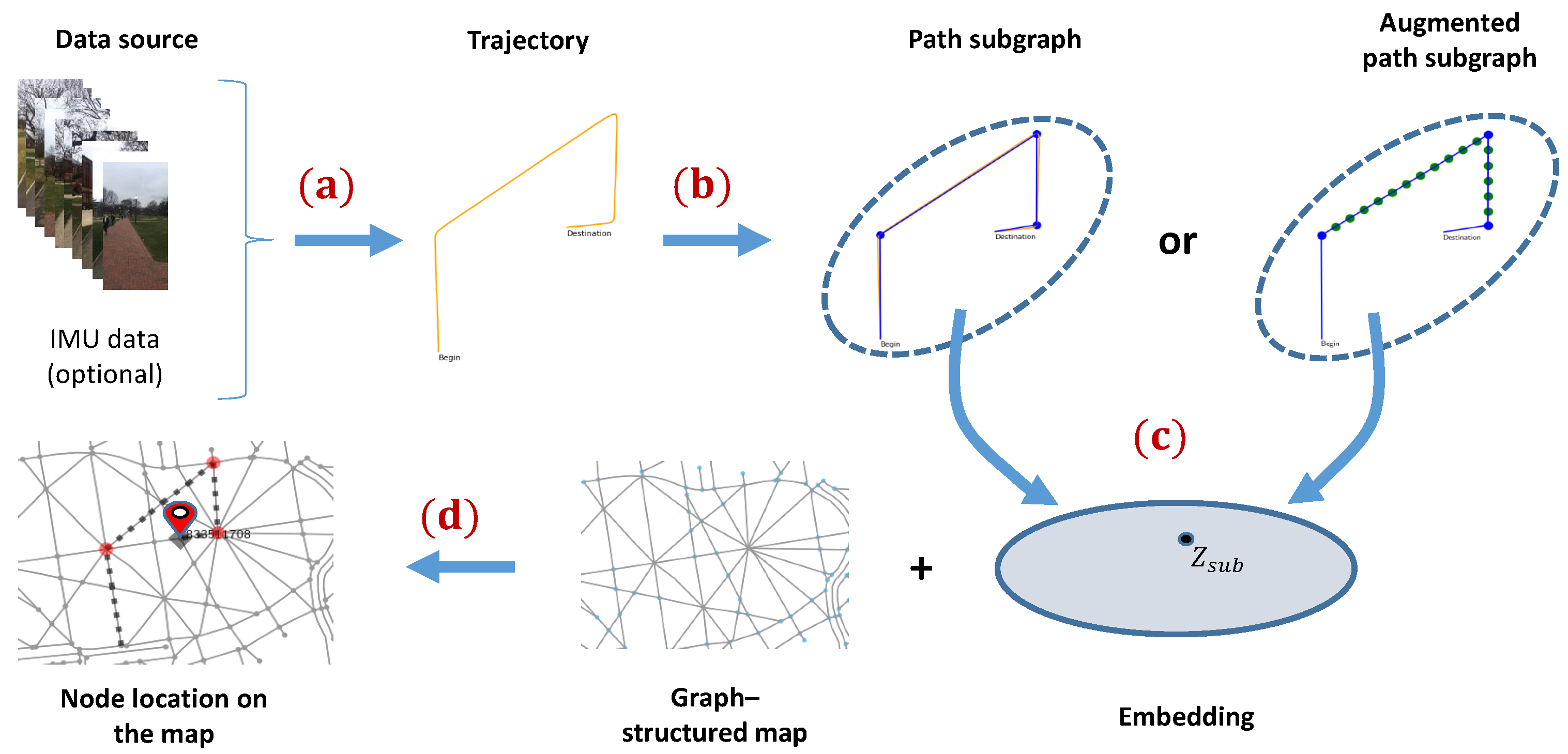
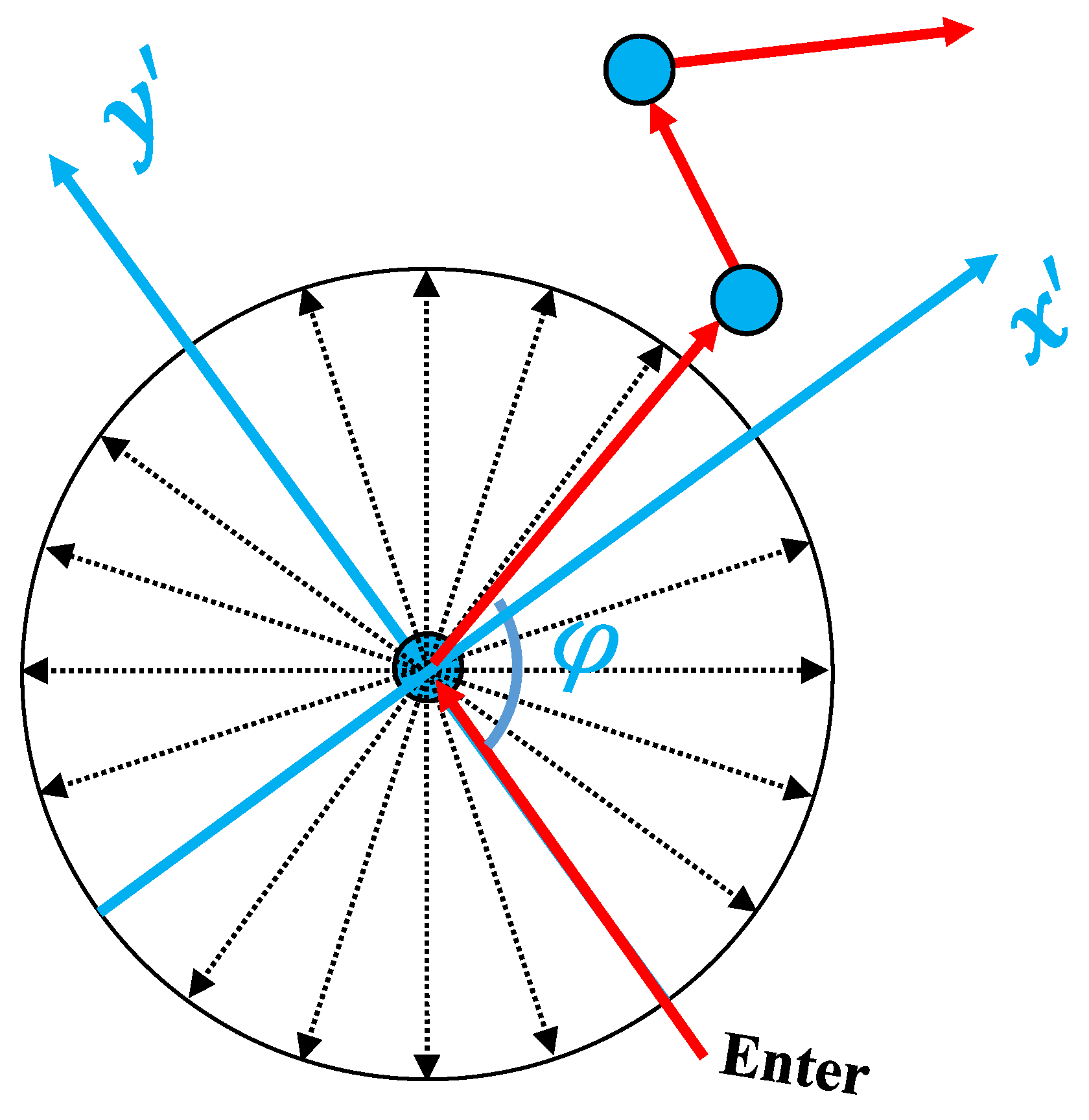
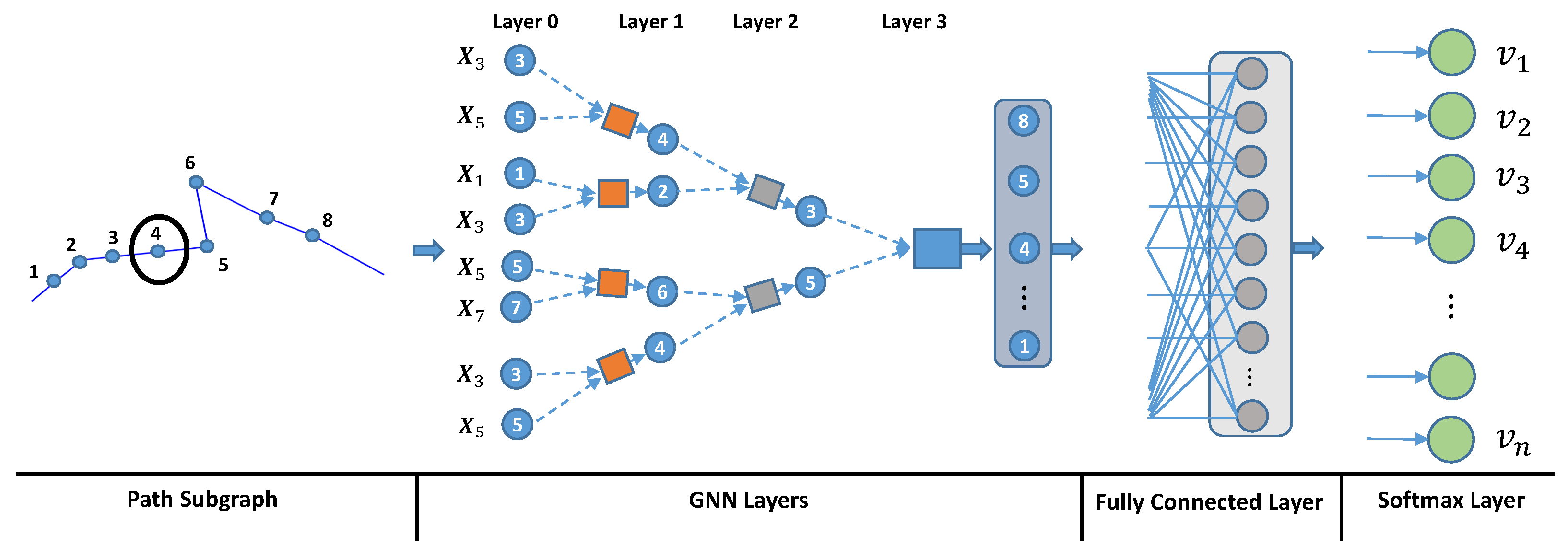
Inspired by those pioneering research from neuroscience and the progress in graph representation learning, we introduce a topological map-based subgraph learning method for localizing the platform using graph neural networks. As shown in
Figure 1, diverse traversed trajectories and corresponding node locations are obtained from a graph-structured map. We then construct a subgraph for the platform trajectories and perform subgraph embedding using graph neural networks. In our application, the unique node ID is the end of the path subgraph and is used as the location label for each subgraph. Therefore, our approach can be divided into two stages. First, the raw motion trajectory is constructed as a subgraph and embedded through a GNN architecture. Second, the embedded subgraph is classified using the fact that each node has a label. In order to demonstrate the effectiveness of the proposed approach, we trained the graph neural network using a large number of possible trajectories generated from the map data and tested the performance on real object trajectories generated using visual inertial odometry, which is the process of estimating the pose and trajectory of a system by fusing measurements from the camera and the inertial measurement unit (IMU) [
19]. Note that we use object trajectory throughout the article to indicate any motion trajectories obtained from different platforms, including pedestrians, robots, and vehicles.
The key contributions of this paper are as follows:
Introduce a novel motion trajectory-based topological geolocalization method using a graph neural network, which combines the benefits of vector-based navigation and the graph representation of a map.
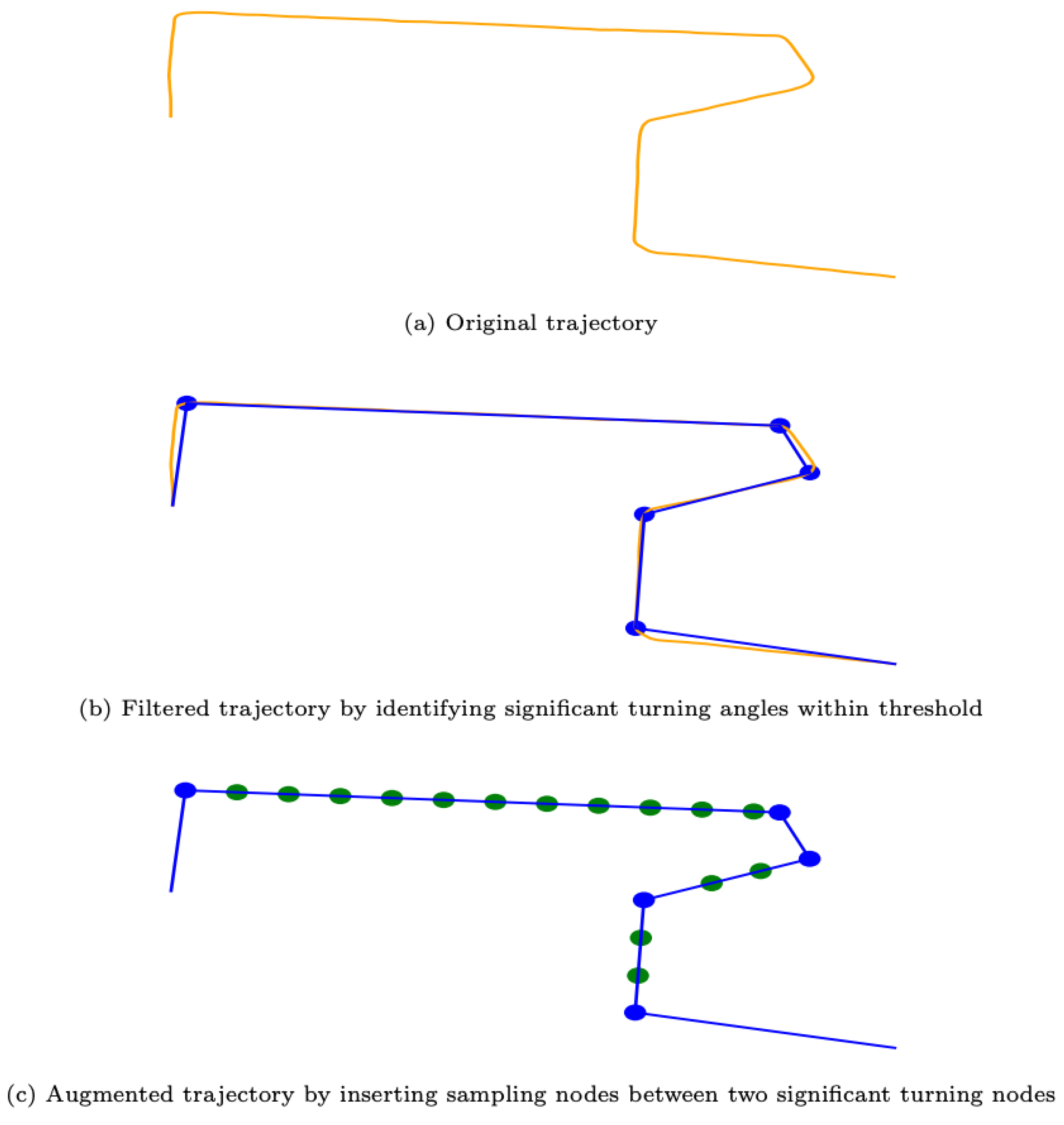
Design two different subgraph representations for motion trajectories: one is for the encoding direction and the other for encoding both direction and distance by inserting virtual nodes.
Demonstrate an affordable data collection setup that is used to generate visual-inertial navigation dataset to demonstrate the effectiveness of the proposed method in a practical setting.
2. Related Work
Visual Localization. A major category of work in the literature is dedicated to the use of images for localization, referred to as visual localization. These methods can be classified into photogrammetric localization [
20,
21,
22,
23] and retrieval-based localization [
24,
25]. The first set of approaches assumes the scene is represented by 3D sparse point clouds, which are commonly generated from structure from motion [
26]). Then, the camera pose for a given input image is directly estimated. The training dataset consists of pairs of images and the corresponding camera poses where the camera pose is usually represented by 6-DoF position and orientation. Despite their performance, the photogrammetric pipeline for generating and storing large 3D maps is not trivial and needs a large memory footprint. Another set of methods works by matching a given image to a database of location-tagged images or location-tagged image features. From the hand-craft features such as SIFT [
27], bag-of-visual words [
28], Fisher Vector [
29] and VLAD [
30], to the learned features [
31,
32], all of these approaches struggle to find a good representation robust to changes in viewpoint, appearance, and scale, which is a requirement hard to fulfill in practice. Furthermore, creating an up-to-date image/feature database seems at best costly if not impossible. There is also a potential privacy issue of storing visual descriptors in the database. Our approach mitigates the above deficiencies by using open-sourced 2D maps.
Probabilistic Localization. A common form of localization problem is to use sensory readings to estimate the absolute coordinates of the object on the map using Bayesian filtering [
33,
34,
35,
36,
37]. The authors of [
33] presented a Bayesian approach to model the posterior distribution of the position given the prior map, which is considered a classic method commonly adopted in the robotics field. However, this method requires GPS readings and endures a rigorous mathematical model. In more recent studies [
34,
35], the authors proposed a probabilistic self-localization method using OpenStreetMap and visual odometry where the location is determined by matching with road topology. The authors of [
36,
37] presented a localization approach based on stochastic trajectory matching using brute-force search. However, all of these methods require the generation and maintenance of posterior distributions, which lead to complicated inference and high computational costs. For interested readers, a more comprehensive reference about probabilistic approaches is given in [
38]. In contrast to the above methods, we avoid the complicated probabilistic inference process and propose an intuitive and learning-based approach.
Topological Localization. There are a small number of studies closely related to ours that uses topological map and deep learning. Traditional approaches utilize topological road structures and try to match features onto the map using Chamfer distance and Hamming distance [
39,
40]. Chen et al. [
7] proposed a topological approach to achieve localization and visual navigation using several different deep neural networks. However, the method aims at visual navigation problems and is only investigated in a small indoor environment. Wei et al. [
41] proposed a sequence-to-sequence labeling method for trajectory matching using a neural machine translation network. This approach was shown to only work well on synthetic scenarios where the input trajectory was synthetically generated with a known sequence of nodes from the map. In [
42], the author presented a variable-length sequence classification method for motion trajectory localization using a recurrent neural network, which largely inspired us to employ motion-based data to achieve localization. Zha et al. [
43] introduced a topological map-based trajectory learning method and utilized hypotheses generation and pruning strategies to achieve consistent geolocalization of moving platforms where the problems were formulated as conditional sequence prediction. In contrast, this paper focuses on the node localization problem on a topological map based on motion trajectory and develops a subgraph embedding classification model using a graph neural network, which generalizes sequence representation to graph representation and preferably fits the graph-based map structure.
Vector-Based Navigation. In neuroscience, much of the literature focuses on studying the mechanisms of animals’ ability to learn maps, as well as self-localization and navigation [
2,
11,
44]. These studies have shown that one typical method used in animals, such as desert ants, is path integration, which is a mechanism in which neurons calculate location by integrating self-motion. Self-motion includes direction and the speed of movement, which inspired us to utilize turning and distance information in this paper. In [
5], the authors elaborated on a topological strategy for navigation using place cells [
44,
45] and metric vector navigation using grid cells [
12], from a biological perspective. Our work can be considered as a mixture of topological and vector strategy, where the map is a graph representation, while navigation on the map is vector-based and includes direction and distance.
GNN on Spatial Data. The idea of GNN is to generate representations of nodes, edges, or whole graphs that depend on the structure of the graph, as well as any feature information endowed by the graph. The basic GNN model can be motivated in a variety of ways, either from the perspective of a spatial domain [
15,
46] or a spectral domain [
47,
48]. Further comprehensive reviews can be found in [
13,
14,
49]. In recent years, the GNN has extended its applications to geospatial data due to its powerful ability to model irregular data structures. For example, the authors of [
50] combined the convolutional neural network and GNN to infer road attributes, which overcome the limitation of capturing the long-term spatial propagation of the features; the authors of [
51] presented a graph neural network estimator for an estimated time of arrival (ETA), which accounts for complex spatiotemporal interactions and has been employed in production at Google Maps; and the authors of [
52] improved the generalization ability of GNN through a sampling technique and demonstrated its performance on real-world street networks. Ref. [
53] proposed a GNN architecture to extract road graphs from satellite images.
As summarized above, the localization problem mainly follows the query-to-map paradigm. The representation and usage of query and map are different in the references. To infer the location given the query, numerous methods are proposed. Overall, while the proposed method in the paper has elements in common with the existing works, we develop a novel motion-based query representation and GNN-based learning method, which explicitly distinguish us from the above works.
5. Results and Analyses
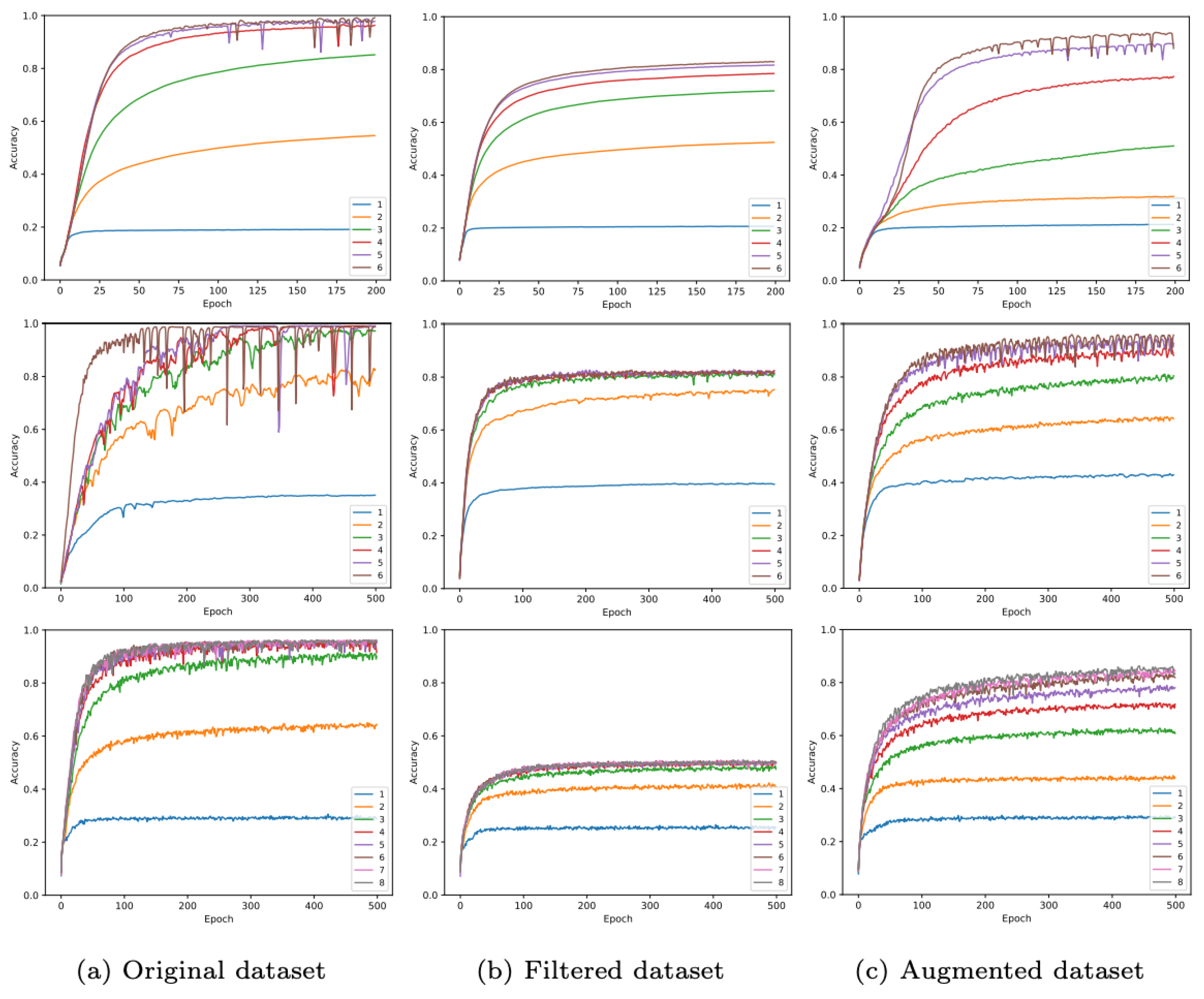
We have shown the training performance in
Figure 8 and observe that the graph neural network is able to learn the representation of path subgraph for each class and perform node classification with satisfying accuracy. To evaluate the performance, we choose to use the accuracy metric, which is also consistent with the other latest works where the classification accuracy is a major evaluation metric [
40,
61,
62]. The accuracy here is computed as:
where
is the correctness of prediction
of path subgraph
i and
N is the total number of subgraphs. The reason why we only choose accuracy as an evaluation metric is twofold. First, our training dataset does not have an imbalance issue, which is the major cause of using another evaluation metric, such as recall and precision. Second, due to the special aspect of our task, which is geolocalization, the difference between testing and training datasets is only simulated map-generated and real data. Therefore, we only focus on what percentage of real data can be correctly classified. The training performance in the original dataset is only used as a reference. However, the best accuracy can reach up to around 99% in this case, which demonstrates the effectiveness of the proposed method. For the other two cases, it can be observed that the performance of the augmented dataset is better than the filtered dataset because the filtered dataset only contains turning information while the augmented dataset encodes both turning and distance information. For maps with different sizes, the less complex environment obtains the best accuracy among the three maps, showing that the performance of the model is relevant to the map size. The large map area carries the difficulty in generating all possible trajectories on that map and ambiguity between different trajectories. In the ablation study discussed later, we also show the accuracy as a function of the route length.
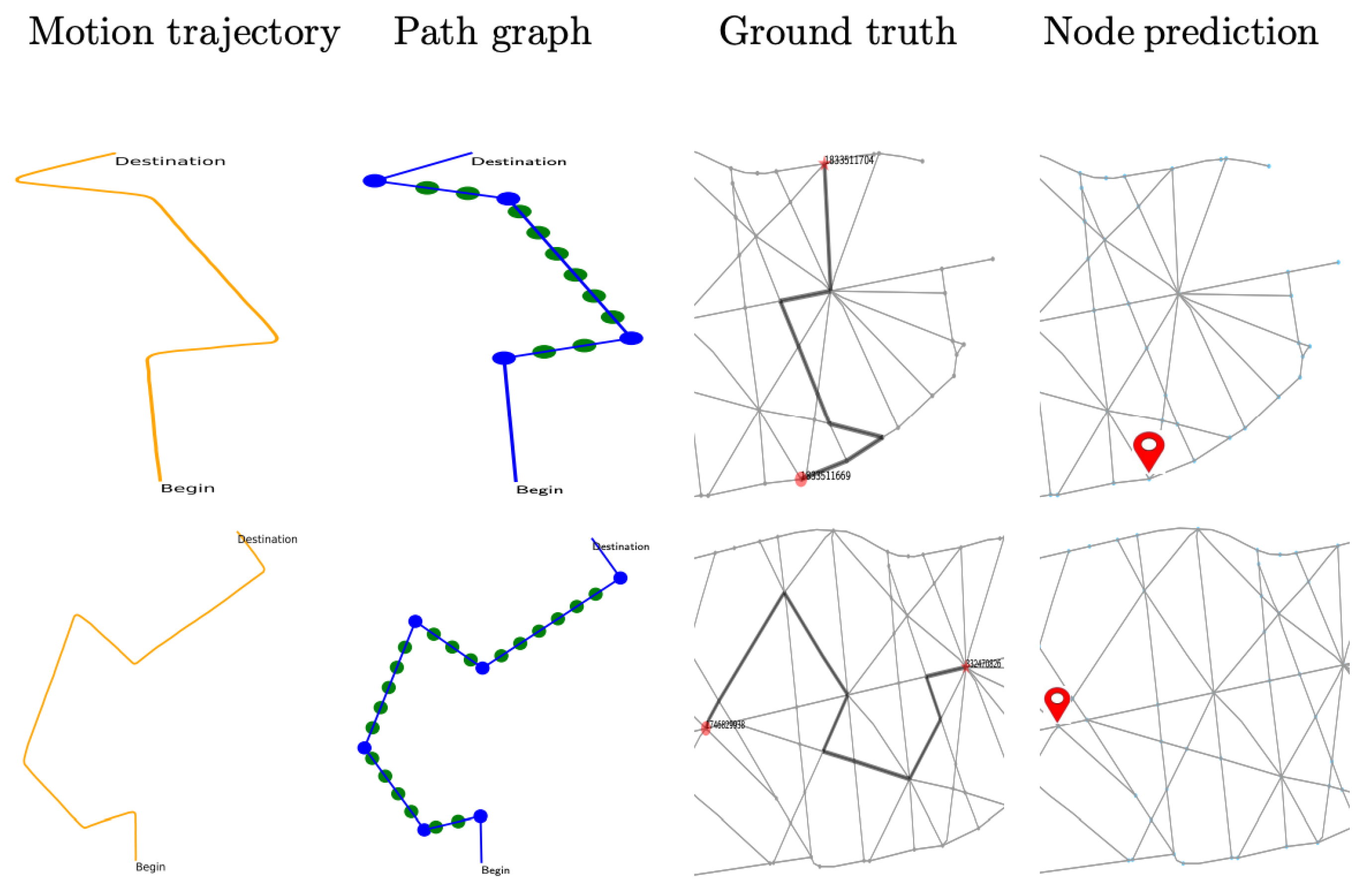
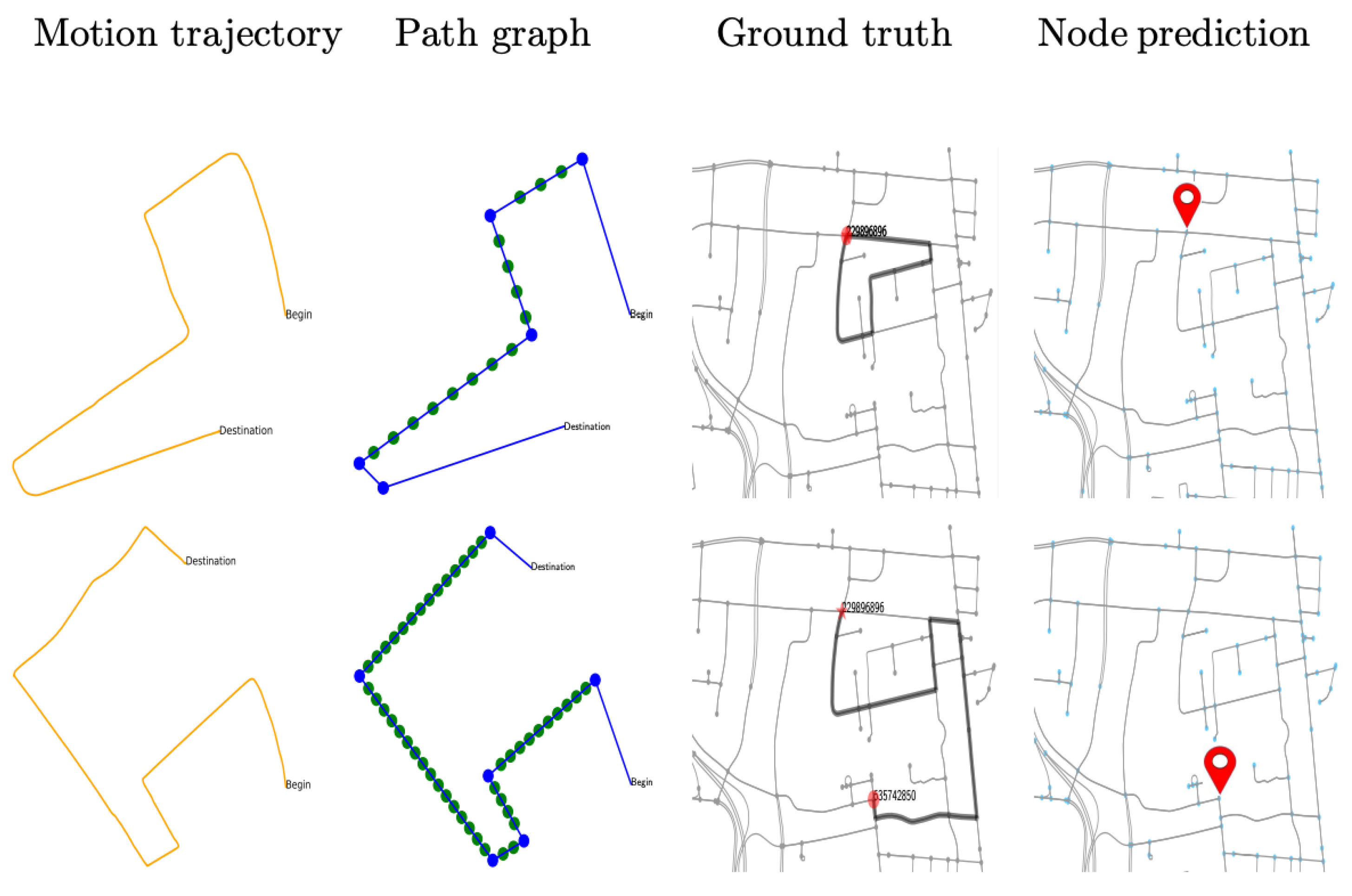
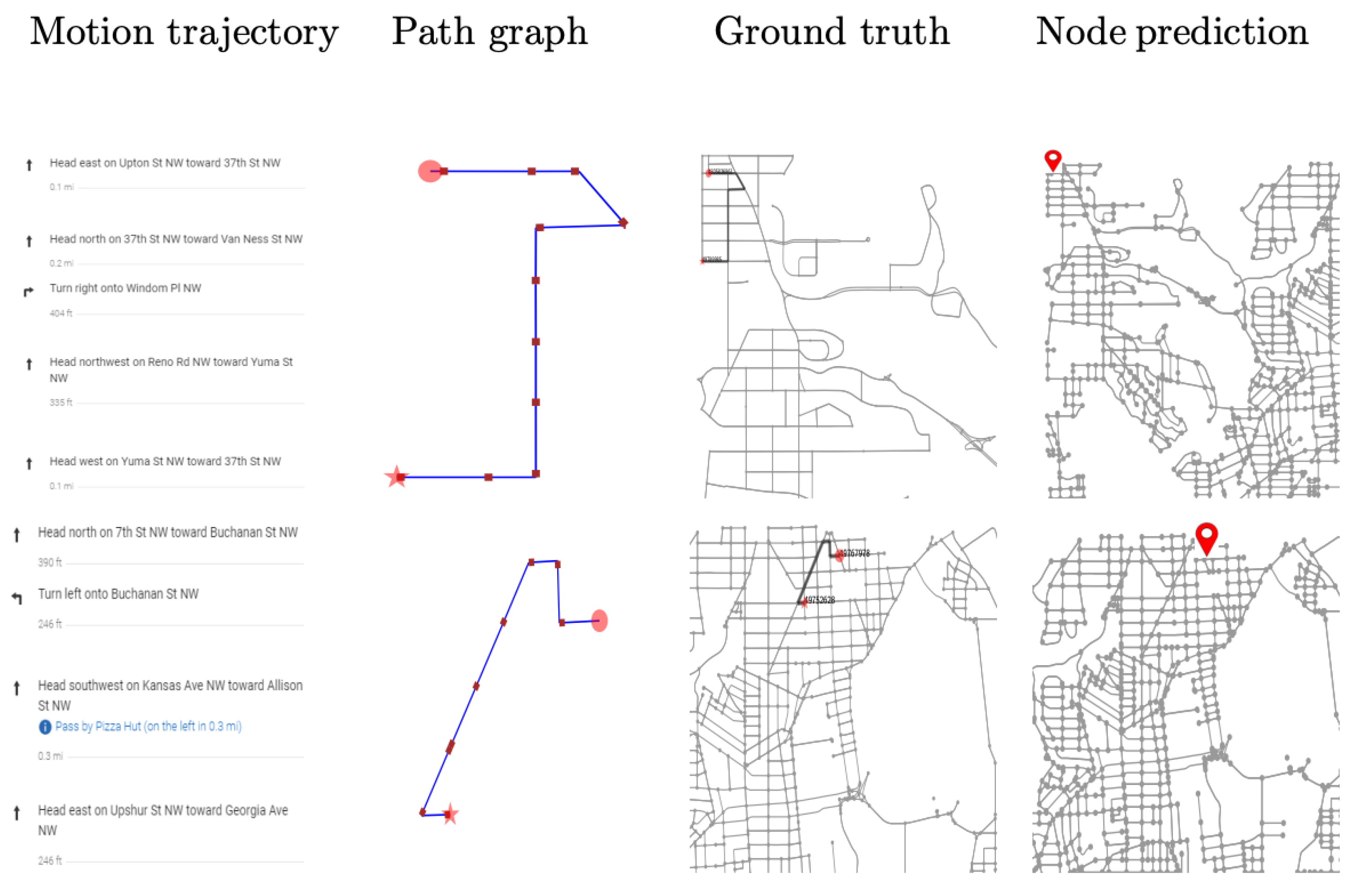
For generating testing trajectories, the raw data are first processed to construct the subgraph and tested using the trained network. The result is illustrated in
Table 3, where the classification accuracy in the small-sized map is observed to be 85% for augmented representation, 90% in the medium-sizeddriving map, and 84% in a large-sized city map. The visual presentation is provided in
Figure 9,
Figure 10 and
Figure 11 using six successful testing results, from which we should note that the quality of real trajectory affects the testing performances, while our approach is robust to noise due to discretization and sampling of virtual nodes. The failure cases during the testing are caused by two main factors. One is related to the training performance of the network, and the other one is related to the identification of the nodes where a turning occurs from the noisy trajectory generated using visual-inertial odometry.
5.1. Comparisons with Existing Methods
The proposed method is different from localization approaches in the published literature, and a direct comparison of the performance, especially in the context of platform navigation, is not possible; nonetheless, we include thematic and accuracy comparisons to several state-of-the-art localization approaches in
Table 4 in a number of descriptive and quantitative aspects for the case when the accuracy measure is defined similarly to ours. The methods that use OSM [
34,
35,
36] all adopt traditional probabilistic frameworks, which is complicated for modeling and inference. The work [
7,
63] solves localization in the navigation task using image-based deep learning, whereas ours is focused on localization alone based on the path subgraph. The two main studies [
41,
43] achieve close accuracy in a very small testing area, but our method is tested on a city-size map and can easily be extended to longer trajectories due to the message-passing mechanism of GNN.
The last approach [
61] achieves around 90% geolocalization accuracy using map tile embedding and street view image, which takes advantage of a contrastive learning technique and is still subject to the constraints of image appearance, while our motion-based localization shows better accuracy. Overall, the proposed method implements novel motion-based geolocalization on the graph representation of a map without an initial position.
5.2. Ablation Study
We evaluated the model performance on a different number of nodes in the path subgraph in
Table 5 and different graph convolution types in
Table 6. It can be observed that the more nodes in the path subgraph, the higher the accuracy becomes. We see that the augmented path representation performs significantly better than the filtered path representation, which verifies the hypothesis that the last node location is unique when more path information is incorporated. The accuracy in the large-sized city map is observed to be lower than the other two maps due to the Manhattan-like map structure, leading to more ambiguous repeating patterns. Overall, the medium-sized map performs better than the other two. We analyzed two major factors that could lead to this phenomenon. Within the same network architecture, the complexity of map structure is higher for the small-sized map, as we showed in
Table 1. Furthermore, the large-sized map has far more output labels than the other two, which can cause a decrease in performance. The experiments also show that in
Table 6, the GraphSAGE model obtains better results than other architectures.
5.3. Discussions
Our work differs from existing image-based geolocalization methods and is the first study to achieve geolocalization using a GNN to the best of our knowledge. Although we have evaluated our approach in three different sizes of map datasets using different route lengths, it is still necessary to clearly elaborate on several concerns and limitations of the proposed method.
5.3.1. Manhattan-World Ambiguity
The three maps are used in this article are all not equipped with repeated patterns. However, a few special road network structures exist, such as Manhattan-world or the lattice-structured environment, which pose a challenge to our motion-based method since a sequence of motions will correspond to multiple locations such as in the large-sized Washington D.C. map due to repeating trajectory patterns. However, there are a large number of one-way streets in a lattice-like road network, and a directed map graph can significantly reduce such ambiguity. The experiment on the Washington D.C. map shows the accuracy is still acceptable when the route length is increased, as shown in
Table 5.
5.3.2. Scalability
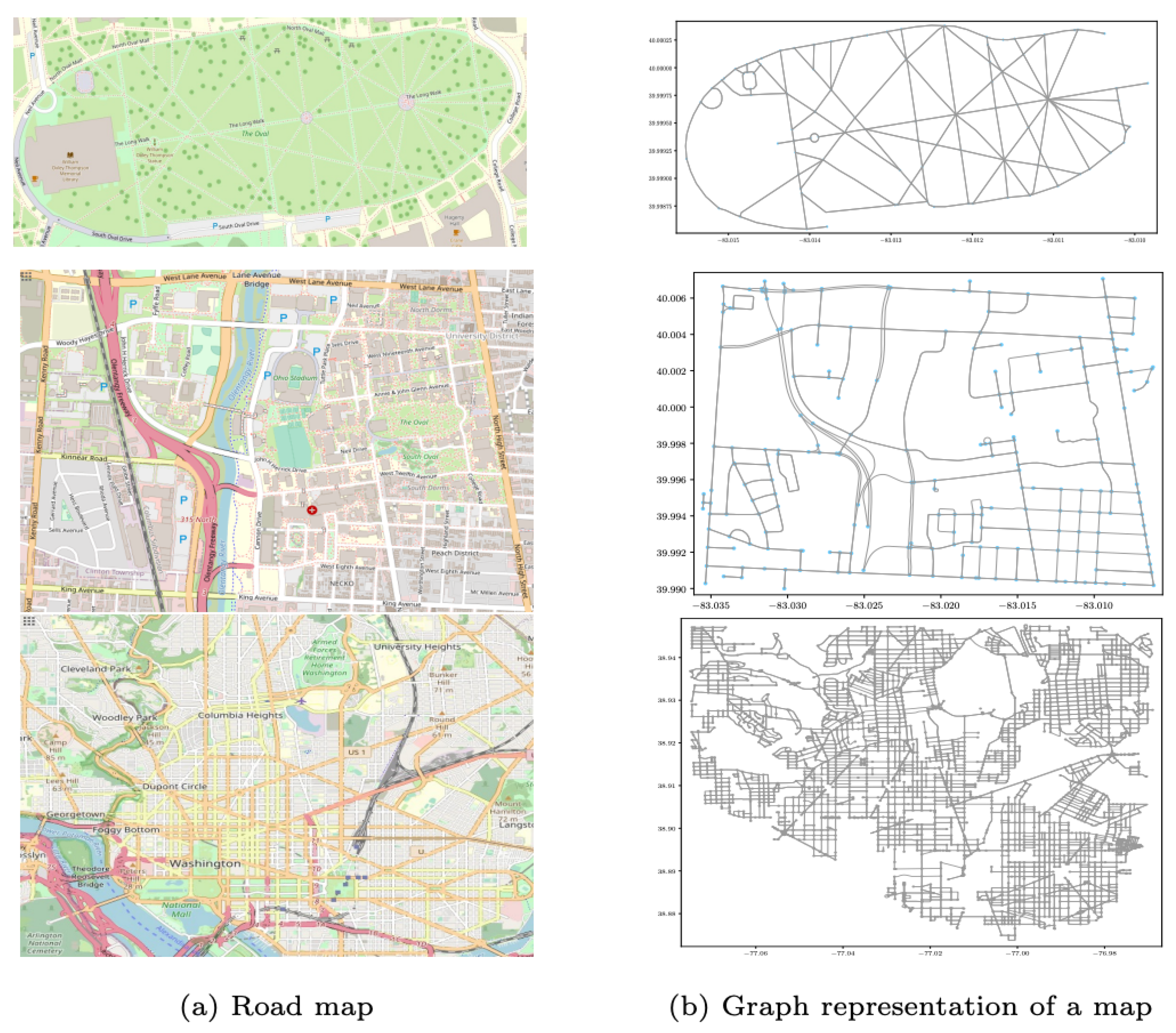
An important limitation of our method is the handling of significantly large map areas (100 km). This is due to the increased label space causing problems at the softmax classifier layer. Nonetheless, to verify if the proposed method can extend to the city-scale area and to understand how the map size impacts the performance, we have studied three different sizes: small-sized (0.1 km), medium-sized (6 km), and large-sized (100 km). The results show that the training accuracy in the large map is lower than the other two maps for the same trajectory window. However, the results still demonstrate an acceptable accuracy of around 85% for a 100 km region. We should also note that an increase in the path length as shown in the ablation study would reduce the ambiguity while increasing accuracy.
5.3.3. Image as Complementary Data
Although the visual data are considered to be a crucial distinguishable feature, much of the world is ever-changing, and maintaining updated images will likely remain a challenge. Our experiments on small- and medium-sized maps show the accuracy is still promising even without visual data as shown in
Figure 8. In lattice-like or Manhattan-world maps, the visual data would be helpful to some degree. Nonetheless, our work focuses on a pure motion-based approach where the motion data source is easy to fulfill in practice and is robust against changes in lighting and weather conditions across day times and seasons.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}