
Bayesian-Optimized Hybrid Kernel SVM for Rolling Bearing Fault Diagnosis
 , and
, and
Abstract
:1. Introduction
2. Theoretical Basis
2.1. Hybrid Kernel SVM
- Polynomial kernel functions (Poly):
- Radial basis kernel function (RBF):
- Sigmoid kernel function:
| Algorithm 1: The proposed hybrid kernel |
| 1: Given training data , , = 1, 2,…, n where xi is a d-dimensional column vector and is the corresponding target value. 2: Map the input data to a higher-dimensional feature space using a non-linear transformation Φ to make it linearly separable. 3: Define a linear estimation function , where, w is the weight vector and b is the bias. 4: Determine the precision ε to ensure that all training data can be fitted with linear functions with an error-free margin. 5: Use the following algebraic equations to find the minimum risk: minimize: subject to: I = 1, …, n; where, C is a constant representing the degree of regularization. 6: Solve the duality problem using the optimization method: 7: Construct the Lagrangian function to obtain the regression function of the SVM as follows: 9: Combine the selected kernel functions to form a hybrid kernel function, such as the Poly and RBF hybrid kernel function described in the paper: , where . 10: Use the hybrid kernel function to train the SVM and adjust the parameters, such as q, σ, c, and ρ, to optimize the performance according to the specific problem. 11. Test the trained SVM on new data and evaluate its performance. |
2.2. BO
| Algorithm 2: Bayesian optimization |
| 1: For t = 1, 2, … do 2: Find xt by optimizing the acquisition function over the Gaussian Process (GP): 4: Augment the data 5: Update the GP 6: End for |
2.3. Bayesian-Optimized Hybrid Kernel SVM
- 1.
- In a hybrid kernel SVM, we define the sample dataset as , where, xi is a d-dimensional feature vector and yi ∈ {−1, 1} is the category label. The goal of the model is to learn a classifier such that it has the largest classification boundary on new data points x ∈ Rd. The optimization goal of a hybrid-core SVM can be expressed as:minimize:subject to:where,
- KPoly and KRBF are kernel function species;
- ρ is the weight of the kernel function;
- C is the penalty factor that controls the balance of interval error and class interval; and
- γ is a relaxation variable that allows some sample points to appear on the wrong side.
- 2.
- Assuming that the objective function f(x) is a Gaussian process for any x ∈ Rd, its prior distribution can be expressed as:where,
- m(x) is a function of the mean; and
- k(x, x′) is a function of covariance.
- 3.
- The expected loss of BO algorithms can be expressed as:where,
- L(x, y) is the loss function of the objective function; and
- p(y|x) is the probability density function of y given x.
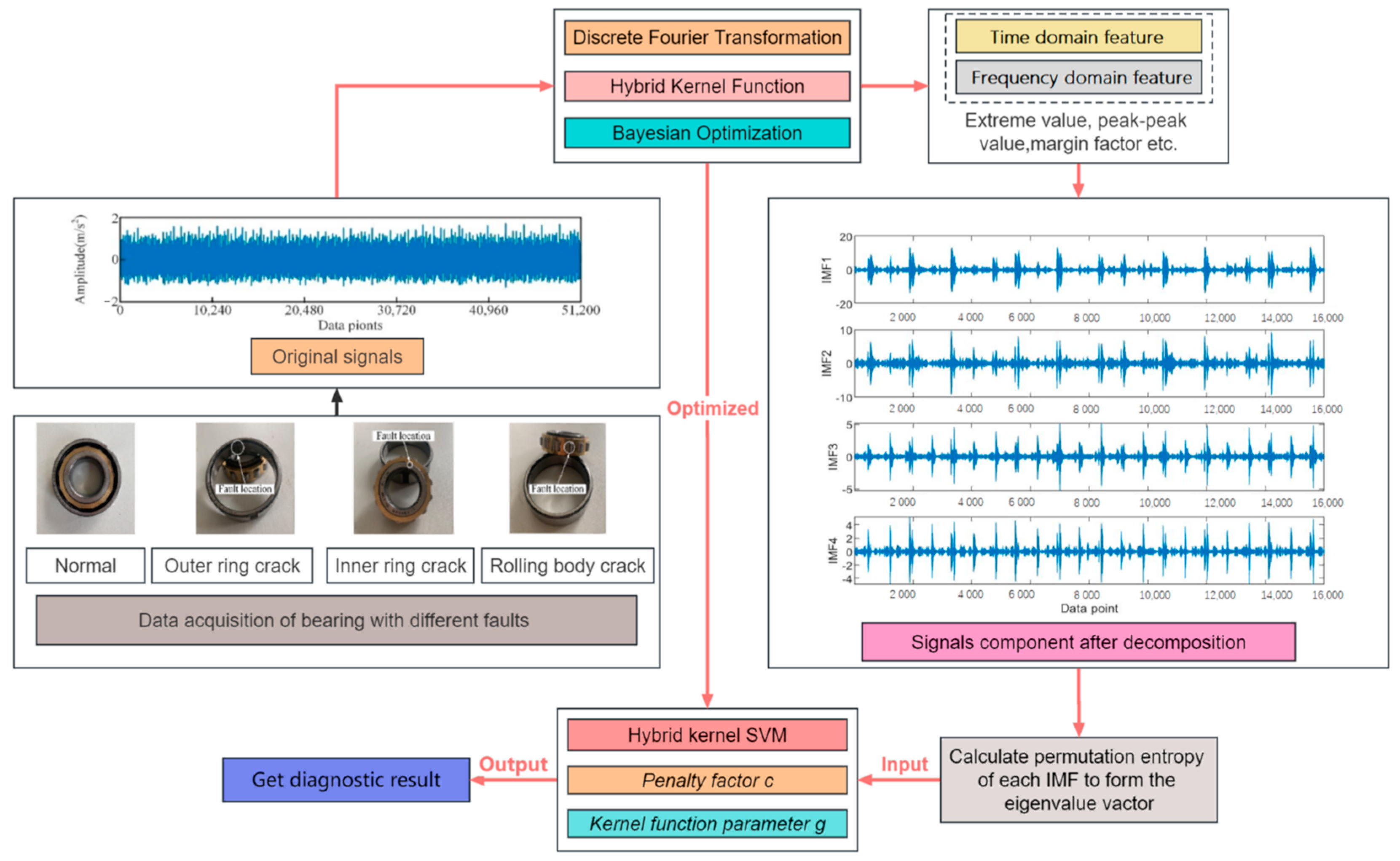
3. Bearing Fault Diagnosis Based on Bayesian-Optimized Hybrid Kernel SVM
- Define the search space for g. This can be conducted by specifying the range of values that g can take. For example, if g is a positive real number, you can define the search space as [0.1, 10].
- Define the objective function to be optimized. In this case, the objective function is the cross-validation accuracy of the hybrid kernel SVM on the validation set. The objective function takes the value of g as its input and outputs the cross-validation accuracy.
- Choose an acquisition function. The acquisition function is used to guide the search for the optimal value of g. Common acquisition functions include Expected Improvement (EI), Probability of Improvement (PI), and Upper Confidence Bound (UCB).
- Initialize the Bayesian optimization algorithm by selecting a set of initial hyperparameters randomly or by using a Latin Hypercube sampling.
- Evaluate the objective function at the initial set of hyperparameters to obtain the corresponding cross-validation accuracy.
- Update the search space and the posterior distribution of the objective function based on the results of the evaluations.
- Select the next set of hyperparameters to evaluate using the acquisition function.
- Repeat steps 5 to 7 until a termination criterion is met, such as the maximum number of evaluations or a target accuracy level.
- The value of g that maximizes the cross-validation accuracy is the optimal value of g.
- Define optimization objectives: Use BO algorithms to find the optimal hybrid kernel SVM model parameters, that is, minimize the loss function. Here, the loss function can choose a cross-validation error or other appropriate metrics.
- Select initial parameters: Select an initial set of hybrid kernel SVM parameters as the starting point for the BO algorithm. These parameters can be based on prior experience or manually selected parameters.
- Build a surrogate model: In the BO algorithm, the Gaussian process model is used as the surrogate model. A surrogate model predicts an objective function that uses known objective function values to estimate unknown objective function values.
- Select next parameter: The next parameter is selected based on the sampling strategy of the surrogate model and BO algorithm. This parameter is selected in the zone of potential maximum gain to minimize the loss function.
- Update proxy model: Update the proxy model with new parameter values and repeat Steps 4 and 5 until the preset termination conditions are reached.
- Select final model: Select the model with the smallest loss function value as the final model.
- Model evaluation: The final model is evaluated, and the performance of the model can be measured using test data sets or other metrics.
4. Experimental Research Based on Public Data Set
4.1. Test Data Acquisition
4.2. Data Preprocessing and Feature Extraction
4.3. Fault Diagnosis Results and Comparative Analysis
- (1)
- Preprocessing: We preprocessed the dataset by removing the missing values and by standardizing the features.
- (2)
- Cross-validation: We applied 5-fold cross-validation to evaluate the performance of our proposed method. Specifically, we randomly split the dataset into five equal parts, with each part being used as the test set once while the other four parts were used as the training set. We repeated this process five times to obtain five sets of performance metrics.
- (3)
- Performance metrics: We used accuracy, precision, recall, F1-score (the harmonic mean of precision and recall), and AUC (Area Under the ROC Curve which is a metric that measures the ability of a model to distinguish between positive and negative classes) as performance metrics to evaluate the classification performance of our proposed method.
- (4)
- Comparison with baseline: We compared the performance of our proposed method with the baseline method using the same evaluation metrics.
5. Laboratory Test Research
5.1. Acquisition of Experimental Data
5.2. Data Preprocessing and Feature Extraction
5.3. Fault Diagnosis Based on Bayesian-Optimized Hybrid Kernel SVM
5.4. Comparative Analysis with Other Fault Diagnosis Models
6. Conclusions
- Experimental findings indicate that the use of DFT for feature extraction from the initial vibration signal and the obtained feature vector as input for the hybrid kernel SVM yields an average accuracy rate of 96.75% across five iterations. This technique offers notable benefits over alternative fault diagnosis methods, including high accuracy and consistent performance, thereby providing a promising novel approach for existing fault diagnosis procedures;
- Experimental results demonstrate that the combination of Poly and RBF kernel functions in the hybrid kernel SVM, optimized by the BO algorithm, can suppress mode mixing successfully. Moreover, the use of permutation entropy as the feature vector and sample entropy as the fitness value allows for a more efficient feature extraction of fault samples. Gaussian regression process is then utilized to optimize the parameters c and g of hybrid kernel SVM, leading to increased accuracy and adaptability of the model classification. Impressively, this method has achieved a 100% single fault diagnosis rate; and
- In comparison with the alternative optimization algorithms, the BO approach presented in this study exhibits favorable performance in terms of optimization accuracy, algorithmic efficiency, and convergence. This method offers the added benefits of streamlined model training and efficient processing, thereby resulting in excellent diagnostic accuracy following training.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, C.; Li, H.; Zhao, X. Weak characteristic determination for blade crack of centrifugal compressors based on underdetermined blind source separation. Measurement 2018, 128, 545–557. [Google Scholar] [CrossRef]
- Duan, L.; Ren, Y.; Duan, F. Adaptive stochastic resonance based convolutional neural network for image classification. Chaos Solitons Fractals 2022, 162, 112429. [Google Scholar] [CrossRef]
- Wang, G.; Xiang, J. Remain useful life prediction of rolling bearings based on exponential model optimized by gradient method. Measurement 2021, 176, 109161. [Google Scholar] [CrossRef]
- Islam, M.M.; Prosvirin, A.E.; Kim, J.-M. Data-driven prognostic scheme for rolling-element bearings using a new health index and variants of least-square support vector machines. Mech. Syst. Signal Process. 2021, 160, 107853. [Google Scholar] [CrossRef]
- Nirwan, N.W.; Ramani, H.B. Condition monitoring and fault detection in roller bearing used in rolling mill by acoustic emission and vibration analysis. Mater. Today Proc. 2021, 51, 344–354. [Google Scholar] [CrossRef]
- Wang, Z.; Yao, L.; Chen, G.; Ding, J. Modified multiscale weighted permutation entropy and optimized support vector machine method for rolling bearing fault diagnosis with complex signals. ISA Trans. 2021, 114, 470–484. [Google Scholar] [CrossRef]
- Zeng, F.; Li, Y.; Jiang, Y.; Song, G. An online transfer learning-based remaining useful life prediction method of ball bearings. Measurement 2021, 176, 109201. [Google Scholar] [CrossRef]
- Pan, H.; Xu, H.; Zheng, J.; Tong, J. Non-parallel bounded support matrix machine and its application in roller bearing fault diagnosis. Inf. Sci. 2023, 624, 395–415. [Google Scholar] [CrossRef]
- Pan, H.; Xu, H.; Zheng, J.; Su, J.; Tong, J. Multi-class fuzzy support matrix machine for classification in roller bearing fault diagnosis. Adv. Eng. Inform. 2021, 51, 101445. [Google Scholar] [CrossRef]
- Liang, L.; Ding, X.; Wen, H.; Liu, F. Impulsive components separation using minimum-determinant KL-divergence NMF of bi-variable map for bearing diagnosis. Mech. Syst. Signal Process. 2022, 175, 109129. [Google Scholar] [CrossRef]
- Qin, A.-S.; Mao, H.-L.; Hu, Q. Cross-domain fault diagnosis of rolling bearing using similar features-based transfer approach. Measurement 2020, 172, 108900. [Google Scholar] [CrossRef]
- Basha, N.; Kravaris, C.; Nounou, H.; Nounou, M. Bayesian-optimized Gaussian process-based fault classification in industrial processes. Comput. Chem. Eng. 2023, 170, 108126. [Google Scholar] [CrossRef]
- Tang, S.; Zhu, Y.; Yuan, S. Intelligent fault diagnosis of hydraulic piston pump based on deep learning and Bayesian optimization. ISA Trans. 2022, 129, 555–563. [Google Scholar] [CrossRef]
- Garrido-Merchán, E.C.; Fernández-Sánchez, D.; Hernández-Lobato, D. Parallel predictive entropy search for multi-objective Bayesian optimization with constraints applied to the tuning of machine learning algorithms. Expert Syst. Appl. 2023, 215, 119328. [Google Scholar] [CrossRef]
- Yaman, O.; Yol, F.; Altinors, A. A Fault Detection Method Based on Embedded Feature Extraction and SVM Classification for UAV Motors. Microprocess. Microsyst. 2022, 94, 104683. [Google Scholar] [CrossRef]
- Li, C.; Ledo, L.; Delgado, M.; Cerrada, M.; Pacheco, F.; Cabrera, D.; Sánchez, R.-V.; de Oliveira, J.V. A Bayesian approach to consequent parameter estimation in probabilistic fuzzy systems and its application to bearing fault classification. Knowl. Based Syst. 2017, 129, 39–60. [Google Scholar] [CrossRef]
- Xiong, H.; Szedmak, S.; Piater, J. Scalable, accurate image annotation with joint SVMs and output kernels. Neurocomputing 2015, 169, 205–214. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.-H.; et al. Challenges in representation learning: A report on three machine learning contests. Neural Netw. 2015, 64, 59–63. [Google Scholar] [CrossRef]
- Han, T.; Zhang, L.; Yin, Z.; Tan, A.C. Rolling bearing fault diagnosis with combined convolutional neural networks and support vector machine. Measurement 2021, 177, 109022. [Google Scholar] [CrossRef]
- Perrone, V.; Donini, M.; Zafar, M.B.; Schmucker, R.; Kenthapadi, K.; Archambeau, C. Fair Bayesian Optimization. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society (AIES ‘21), Association for Computing Machinery, New York, NY, USA, 19–21 May 2021; pp. 854–863. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef]
- Tan, Y.; Wang, J. A support vector machine with a hybrid kernel and minimal vapnik-chervonenkis dimension. IEEE Trans. Knowl. Data Eng. 2004, 16, 385–395. [Google Scholar] [CrossRef]
- Sangeetha, R.; Kalpana, B. A Comparative Study and Choice of an Appropriate Kernel for Support Vector Machines. In Information and Communication Technologies. ICT 2010. Communications in Computer and Information Science; Das, V.V., Vijaykumar, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 101. [Google Scholar] [CrossRef]
- Riazi, A.; Saraeian, S. Sustainable production using a hybrid IPSO optimized SVM-based technique: Fashion industry. Sustain. Comput. Inform. Syst. 2023, 37, 100838. [Google Scholar] [CrossRef]
- Nieto, P.G.; Fernández, J.A.; Suárez, V.G.; Muñiz, C.D.; García-Gonzalo, E.; Bayón, R.M. A hybrid PSO optimized SVM-based method for predicting of the cyanotoxin content from experimental cyanobacteria concentrations in the Trasona reservoir: A case study in Northern Spain. Appl. Math. Comput. 2015, 260, 170–187. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, Y.; Song, J.; Liu, Q.; Dong, H. A novel optimized SVM algorithm based on PSO with saturation and mixed time-delays for classification of oil pipeline leak detection. Syst. Sci. Control. Eng. 2019, 7, 75–88. [Google Scholar] [CrossRef]
- Song, H.; Ding, Z.; Guo, C.; Li, Z.; Xia, H. Research on Combination Kernel Function of Support Vector Machine. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Wuhan, China, 12–14 December 2008; pp. 838–841. [Google Scholar] [CrossRef]
- Wu, X.; Tang, W.; Wu, X. Support Vector Machine Based on Hybrid Kernel Function. In Information Engineering and Applications; Information Engineering and Applications; Lecture Notes in Electrical Engineering Book Series; Zhu, R., Ma, Y., Eds.; Springer: London, UK, 2012; Volume 154. [Google Scholar] [CrossRef]
- Figuera, C.; Barquero-Pérez, Ó.; Rojo-Álvarez, J.L.; Martínez-Ramón, M.; Guerrero-Curieses, A.; Caamaño, A.J. Spectrally adapted Mercer kernels for support vector nonuniform interpolation. Signal Process. 2014, 94, 421–433. [Google Scholar] [CrossRef]
- Zhou, X.; Jiang, P.; Wang, X. Recognition of control chart patterns using fuzzy SVM with a hybrid kernel function. J. Intell. Manuf. 2015, 29, 51–67. [Google Scholar] [CrossRef]
- Zeng, Y.; Cheng, Y.; Liu, J. An efficient global optimization algorithm for expensive constrained black-box problems by reducing candidate infilling region. Inf. Sci. 2022, 609, 1641–1669. [Google Scholar] [CrossRef]
- Snoek, J.; Rippel, O.; Swersky, K.; Kiros, R.; Satish, N.; Sundaram, N.; Patwary, M.; Prabhat, M.; Adams, R. Scalable Bayesian Optimization Using Deep Neural Networks. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 2171–2180. [Google Scholar]
- Folch, J.P.; Lee, R.M.; Shafei, B.; Walz, D.; Tsay, C.; van der Wilk, M.; Misener, R. Combining multi-fidelity modelling and asynchronous batch Bayesian Optimization. Comput. Chem. Eng. 2023, 172, 108194. [Google Scholar] [CrossRef]
- Anh, D.T.; Pandey, M.; Mishra, V.N.; Singh, K.K.; Ahmadi, K.; Janizadeh, S.; Tran, T.T.; Linh, N.T.T.; Dang, N.M. Assessment of groundwater potential modeling using support vector machine optimization based on Bayesian multi-objective hyperparameter algorithm. Appl. Soft Comput. 2023, 132, 109848. [Google Scholar] [CrossRef]
- Zuo, X. Rolling Bearing Fault Diagnosis Based on Gaussian Dimensionality Reduction and Hybrid Core SVM Fusion. Master’s thsis, Wuhan University of Technology, Wuhan, China, 2017. [Google Scholar]
- Kouziokas, G.N. SVM kernel based on particle swarm optimized vector and Bayesian optimized SVM in atmospheric particulate matter forecasting. Appl. Soft Comput. 2020, 93, 106410. [Google Scholar] [CrossRef]
- Elsayad, A.M.; Nassef, A.M.; Al-Dhaifallah, M. Bayesian optimization of multiclass SVM for efficient diagnosis of erythemato-squamous diseases. Biomed. Signal Process. Control. 2021, 71, 103223. [Google Scholar] [CrossRef]
- He, C.; Wu, T.; Gu, R.; Jin, Z.; Ma, R.; Qu, H. Rolling bearing fault diagnosis based on composite multiscale permutation entropy and reverse cognitive fruit fly optimization algorithm—Extreme learning machine. Measurement 2020, 173, 108636. [Google Scholar] [CrossRef]
- Zhou, J.; Xiao, M.; Niu, Y.; Ji, G. Rolling Bearing Fault Diagnosis Based on WGWOA-VMD-SVM. Sensors 2022, 22, 6281. [Google Scholar] [CrossRef] [PubMed]
- Tek, Y.I.; Tuna, E.B.; Savaşcıhabeş, A.; Özen, A. A new PAPR and BER enhancement technique based on lifting wavelet transform and selected mapping method for the next generation waveforms. AEU—Int. J. Electron. Commun. 2021, 138, 153871. [Google Scholar] [CrossRef]
- Pelikan, M. Bayesian Optimization Algorithm. In Hierarchical Bayesian Optimization Algorithm: Toward a New Generation of Evolutionary Algorithms; Springer: Berlin/Heidelberg, Germany, 2005; pp. 31–48. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Type | Characteristic Components | |||||||
|---|---|---|---|---|---|---|---|---|
| Feature 1 | Feature 2 | Feature 3 | Feature 4 | Feature 5 | Feature 6 | Feature 7 | Feature 8 | |
| Normal | 0.5125 | 0.6717 | 0.6203 | 0.8317 | 0.8202 | 0.7883 | 0.6913 | 0.8914 |
| 0.5195 | 0.6854 | 0.6270 | 0.8399 | 0.8247 | 0.7945 | 0.6906 | 0.8942 | |
| 0.5150 | 0.677 | 0.6279 | 0.8406 | 0.8237 | 0.7912 | 0.6909 | 0.8905 | |
| …… | ||||||||
| Inner ring fault | 0.4950 | 0.6514 | 0.6029 | 0.8090 | 0.7791 | 0.7616 | 0.6498 | 0.8403 |
| 0.5178 | 0.6752 | 0.6221 | 0.8362 | 0.8257 | 0.7938 | 0.6896 | 0.8975 | |
| 0.5172 | 0.6719 | 0.6267 | 0.8388 | 0.8242 | 0.7924 | 0.6855 | 0.8900 | |
| …… | ||||||||
| Outer ring fault | 0.5157 | 0.6713 | 0.6281 | 0.8365 | 0.8127 | 0.7848 | 0.6824 | 0.8766 |
| 0.5144 | 0.6748 | 0.6151 | 0.8225 | 0.8166 | 0.7899 | 0.6796 | 0.8774 | |
| 0.5140 | 0.6710 | 0.6208 | 0.8267 | 0.8067 | 0.7805 | 0.6815 | 0.8757 | |
| …… | ||||||||
| Rolling element fault | 0.5140 | 0.6710 | 0.6208 | 0.8267 | 0.8067 | 0.7805 | 0.6815 | 0.8757 |
| 0.5182 | 0.6835 | 0.6232 | 0.8277 | 0.8172 | 0.7867 | 0.6848 | 0.8898 | |
| 0.5152 | 0.6799 | 0.6255 | 0.8370 | 0.8108 | 0.7838 | 0.6805 | 0.8878 | |
| …… | ||||||||
| Methods | Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| Experiment 1 | Experiment 2 | Experiment 3 | Experiment 4 | Experiment 5 | Average | |
| Hybrid Kernel SVM | 97.33 | 96.00 | 98.66 | 94.00 | 97.33 | 97.34 |
| BO Hybrid Kernel SVM | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Method | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| Baseline | 0.85 | 0.87 | 0.83 | 0.85 | 0.91 |
| Proposed | 0.91 | 0.92 | 0.91 | 0.91 | 0.95 |
| Types | Specifications | Outer Diameter/mm | Inside Diameter/mm | Thickness/mm | Rollers Number | Roller Diameter/mm | Pitch/mm | Contact Angle/° |
|---|---|---|---|---|---|---|---|---|
| Cylindrical roller bearing | N205EM | 52 | 25 | 15 | 13 | 6.5 | 38.5 | 0 |
| Failure Type | c | g |
|---|---|---|
| Normal working | 4.23 | 0.01 |
| Inner ring cracks | 15.32 | 0.22 |
| Outer ring cracks | 25.78 | 2.48 |
| Rolling element cracks | 24.55 | 4.68 |
| Model | Number of Hyperparameters | Training Time (s) | Accuracy% | |||||
|---|---|---|---|---|---|---|---|---|
| Experiment 1 | Experiment 2 | Experiment 3 | Experiment 4 | Experiment 5 | Average | |||
| BP neural networks | 2 | 12.43 | 70.43 | 63.67 | 63.75 | 52.50 | 76.25 | 65.32 |
| Single kernel SVM | 1 | 5.23 | 77.20 | 76.25 | 82.05 | 74.63 | 76.45 | 77.32 |
| VMD-SVM | 2 | 18.43 | 87.50 | 87.50 | 90.00 | 81.25 | 78.75 | 85.00 |
| WGWOA-VMD-SVM | 3 | 53.22 | 92.50 | 93.76 | 92.50 | 92.50 | 96.25 | 93.50 |
| BO-HK-SVM | 2 | 31.57 | 100.00 | 97.78 | 100.00 | 100.00 | 99.67 | 99.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, X.; Wei, W.; Zhou, J.; Ji, G.; Hussain, G.; Xiao, M.; Geng, G. Bayesian-Optimized Hybrid Kernel SVM for Rolling Bearing Fault Diagnosis. Sensors 2023, 23, 5137. https://doi.org/10.3390/s23115137
Song X, Wei W, Zhou J, Ji G, Hussain G, Xiao M, Geng G. Bayesian-Optimized Hybrid Kernel SVM for Rolling Bearing Fault Diagnosis. Sensors. 2023; 23(11):5137. https://doi.org/10.3390/s23115137
Chicago/Turabian StyleSong, Xinmin, Weihua Wei, Junbo Zhou, Guojun Ji, Ghulam Hussain, Maohua Xiao, and Guosheng Geng. 2023. "Bayesian-Optimized Hybrid Kernel SVM for Rolling Bearing Fault Diagnosis" Sensors 23, no. 11: 5137. https://doi.org/10.3390/s23115137