1. Introduction
Deep neural networks (DNNs) have achieved superior performance in a wide range of applications in computer vision [
1,
2], including image classification [
3,
4,
5,
6,
7,
8], object detection [
9,
10,
11,
12,
13], and semantic segmentation [
14,
15]. Nevertheless, the performance of these models significantly degrades under adversarial attacks, where crafted noise is added to the natural images imperceptible to human eyes. The objective of these attacks is to adversarially perturb the input data to mislead deep models to misclassified results [
16,
17]. This creates consequential concerns when DNNs are deployed in sensitive areas [
18], such as medical, military, and security applications.
One idea to defend deep neural networks (DNNs) from such adversarial attacks is through training the models that perform robustly on both clean and adversarially perturbed data. To attain a satisfactory performance, several defense mechanisms have been developed to alleviate the problem and increase the robustness of DNNs, where the most dominant defense approach is the technique called
adversarial training [
19].
In adversarial training, adversarial examples are generated on the fly using adversarial attacks, such as the Fast Gradient Sign Method (FGSM) and projected gradient descent (PGD), and used to train a more robust model. Since adversarial training is one of the most effective defense methods in the literature, it becomes the foundation of many other defense algorithms. Besides adversarial training, recent works in adversarial defense also used metric learning as a regularization mechanism. Deep metric learning [
20,
21,
22,
23,
24,
25] focuses on training models to learn effective distance or similarity metrics between data points. Triplet mining [
26], Proxy NCA [
27], Proxy Anchor [
28], and SoftTriple [
29] have widely recognized techniques. Triplet mining forms training triplets to optimize distances between similar and dissimilar samples. Proxy NCA optimizes a neighborhood-based classification objective using class proxies, while Proxy Anchor employs proxy vectors as class representatives to enhance inter-class and intra-class distances. Deep metric losses can be incorporated into adversarial training to improve model robustness. For example, Triplet Loss Adversarial (TLA) [
30] defines a triplet loss to enforce that the latent representations of clean and perturbed samples from the same class should be close and demonstrate compelling results against other sophisticated adversarial defense methods.
Adversarial training serves as the foundation for various defense methods, including those employing strong data augmentation [
31], auxiliary data for primary task robustness [
32], and class-fairness considerations [
33]. Despite the success of these adversarial defense methods, they mainly focus on the single-mode setting while ignoring the fact that real-world datasets usually have large intra-variations or multiple modes depending on data labeling. As deep learning models are deployed to more domains, researchers must collect or reorganize existing datasets for specific problems. For example, when classifying people by gender, each gender category will have multiple modes (such as race, age, and expression). When adversarial attacks are applied to such data, more data modes are created, reducing the effectiveness of standard adversarial training.
Based on the observation, we consider that samples of each class have multiple local clusters. The adversarial examples of the same class are misclassified into different classes.
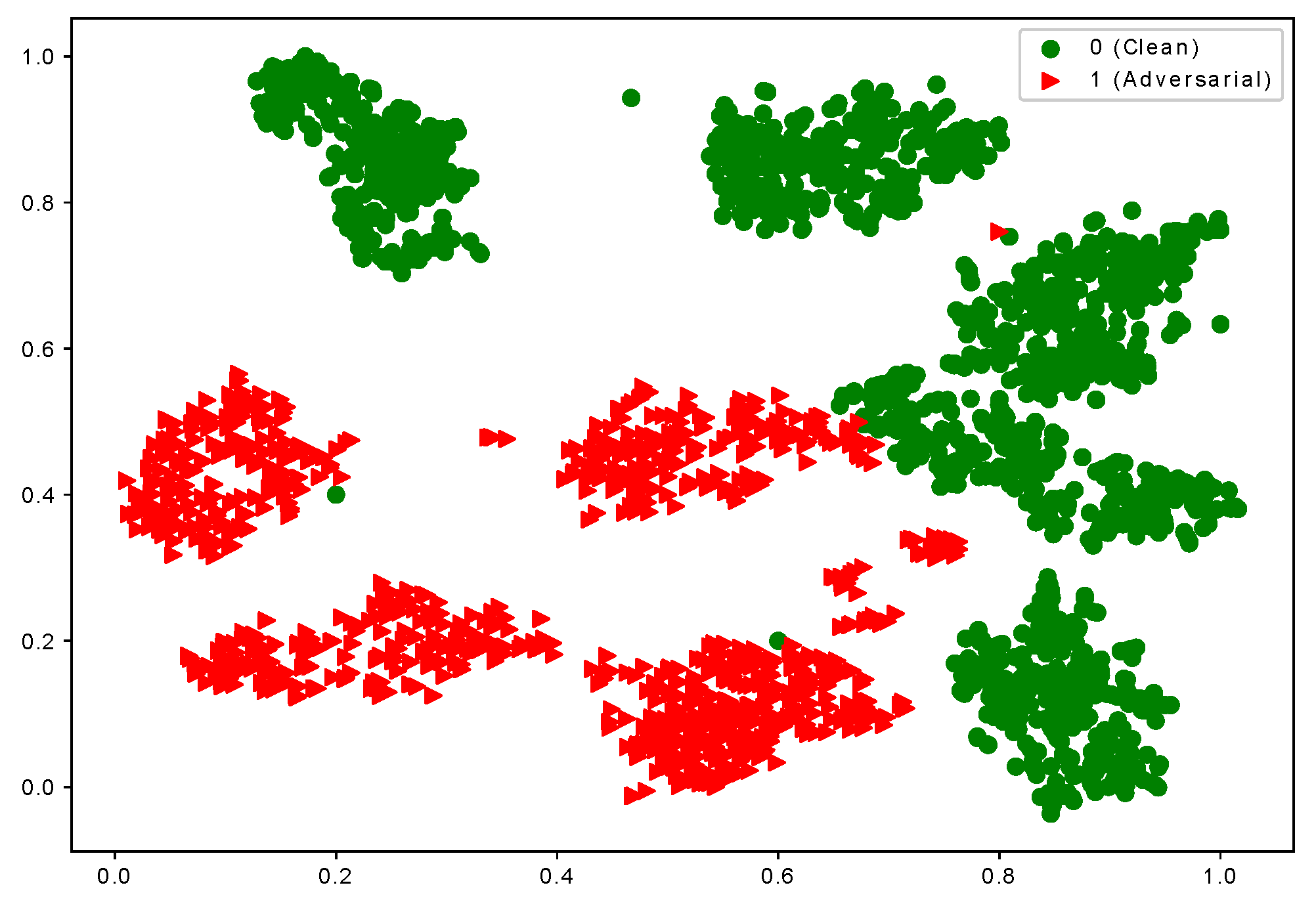
Figure 1 shows the visualization of the latent representation of hand-written Digit images from the MNIST dataset [
34] using t-SNE [
35]. To simulate the multi-mode data setting for illustration purposes, we reorganize the original ten-class MNIST dataset into a two-class structure (i.e., each new class contains the data of five classes, respectively.) The features of clean and adversarial examples are extracted from the last fully connected layer of the LeNet model (We use a modified LeNet [
36] architecture for all our experiments for the MNIST dataset). The model is trained on a modified MNIST dataset and used to extract features for testing data for visualization. The adversarial images belong to the same class (class 0 consisting of the digits
), and the model not only misclassifies them into different classes but also creates different local clusters. In
Figure 1, the red triangles indicate the adversarial samples with more than one cluster. Based on this observation, when the data for a class has multiple modes, the single-mode adversarial training is incapable of capturing the inherent structure of the data.
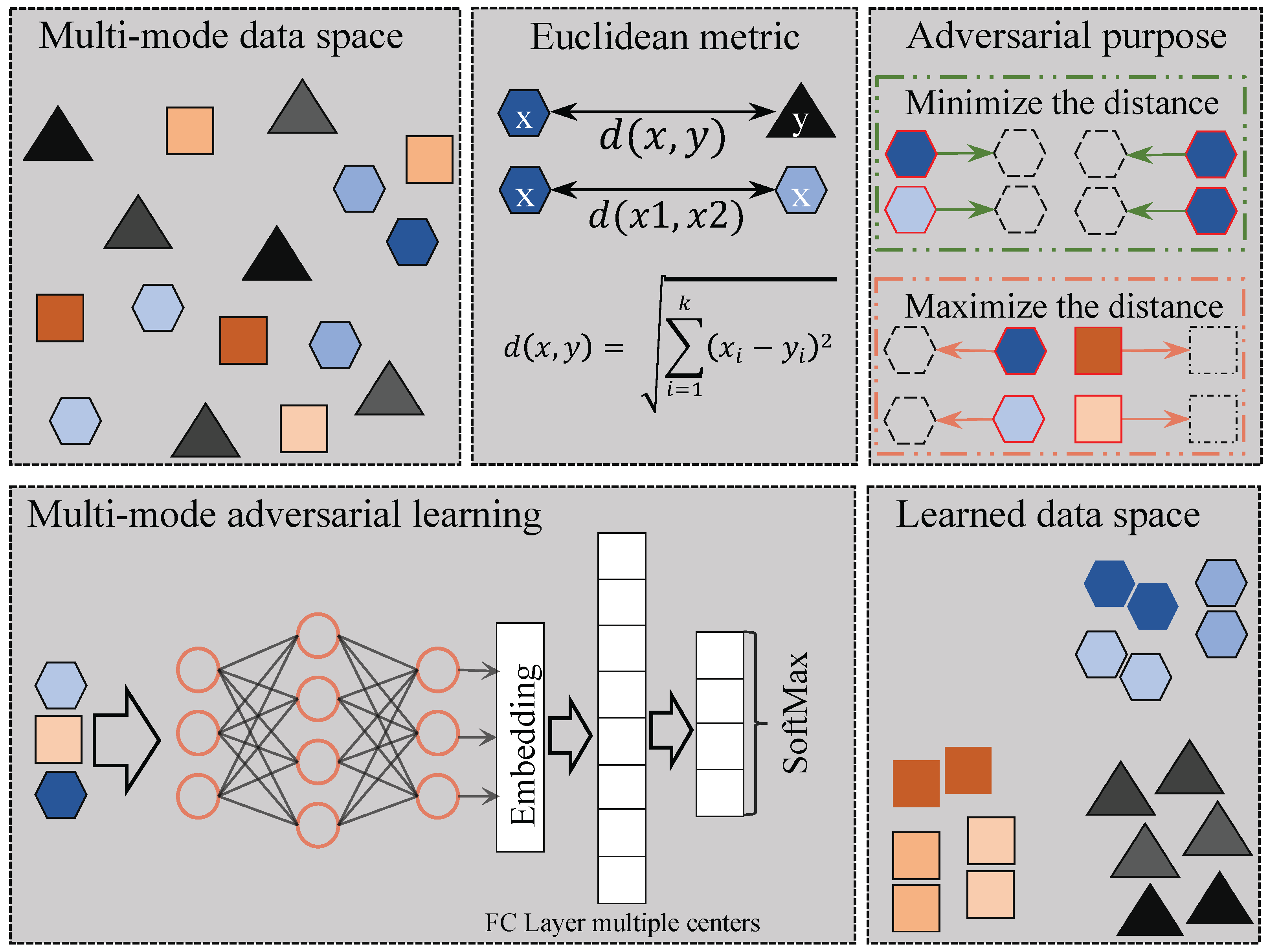
To tackle the problem of multi-modes, we propose an adversarial defense framework using adversarial training with multi-mode loss to accommodate the multiple centers of data.
Figure 2 shows the overall framework of the proposed method inspired by SoftTriple loss [
29], which allows each class to have multiple prototypes and can better capture the multi-mode nature of the real-world data as compared with other metric learning methods. A prototype represents the number of centers within each class of the dataset. Notably, a class can have multiple centers, which we refer to as prototypes. On the other hand, since vanilla PGD adversarial training [
19] is time-consuming, we also adopt the recent fast adversarial training approaches, including Free [
37] and Fast [
38], to speed up the training process.
To verify the effectiveness of the proposed approach, we perform extensive experiments in both normal single-mode and multi-mode settings. We evaluate the proposed method on four publicly available benchmarks: MNIST [
34], CIFAR10 [
39], CIFAR100 [
39], and Tiny ImageNet [
40]. For the multi-mode settings, since the commonly used CIFAR10 and CIFAR100 datasets are mainly single-mode for each class, we reorganize CIFAR10 from 10 classes to 2 classes and CIFAR100 from 100 classes to 10 classes to simulate the multi-mode setting for the experimental evaluations. In addition, since there are more intra-variations for the Tiny ImageNet dataset, we do not reorganize the dataset as for the CIFAR10 and CIFAR100 datasets and directly use it for the multi-mode evaluations.
The experimental results show that the proposed method can effectively improve the robustness of PGD [
19], Free [
37], and Fast [
38] adversarial training. Our method outperforms PGD and TLA by 2.22% on CIFAR10-2, 1.65% on CIFAR100-10, and 0.43% on Tiny ImageNet in the multi-mode situation and by 0.84% in single-mode on the CIFAR10 dataset. The clean accuracy (i.e., evaluating the performance using clean samples without applying any adversarial attacks) of the model normally drops after adversarial training. Instead, the clean accuracy of the proposed method has improved by 5% on CIFAR10-10 and 1.70% on CIFAR100-10 compared with state-of-the-art methods. This shows the merits of the proposed method under the multi-mode setting.
The main contributions of this work are as follows:
- 1.
As per our knowledge, this is the first work to introduce a multi-prototype in adversarial training and consider the multi-mode nature of real-world data.
- 2.
The proposed framework leverages adversarial training and uses multiple centers for each class to train robust classification models on multi-mode datasets and achieves superior performance compared to existing approaches.
4. Experiments and Analysis
The proposed method is evaluated to verify the robustness against state-of-the-art adversarial attacks and compare the results with existing methods. We conduct experiments on benchmark datasets: MNIST, CIFAR10, CIFAR100, and Tiny-ImageNet. We follow the same setting as [
19,
30,
37,
38] for a fair comparison. To begin with, we describe the datasets used and details the training settings in the following section. We further present details on each experiment and a discussion of the results. We follow the guidelines by Athalye et al. [
18] to check the validity of our claim.
4.1. Datasets
We conducted experiments based on widely used datasets for classification to demonstrate the effectiveness of the proposed method, including CIFAR10 [
39], CIFAR100 [
39], MNIST [
34], and Tiny ImageNet [
40]. During training, horizontal flipping and random cropping are used as data augmentation.
MNIST: This dataset consists of handwritten digits. It contains 60,000 training images and 10,000 testing images. MNIST is a ten-class dataset with gray-scale images with dimensions of .
CIFAR10: This is a ten-class dataset with RGB images with dimensions of . The number of images in the training set and test set is 50,000 and 10,000, respectively.
CIFAR100: The CIFAR100 dataset has 50,000 training and 10,000 testing images of 100 classes. Each image is an RGB image with a size of .
Tiny ImageNet: This has 200 classes and each image is RGB with dimension . It includes around 100,000 training images, 10,000 validation images, and 10,000 test images. Each class has 500 training images and 50 validation images.
For traditional single-mode settings, we mainly compare the proposed method with other approaches on the MNIST, CIFAR10, and CIFAR100 datasets. To verify the effectiveness of multi-mode settings, we further customize the CIFAR10 and CIFAR100 datasets to create multi-mode data for this experiment. The CIFAR10 dataset is converted into a 2-class dataset and denoted as CIFAR10-2. Similarly, the CIFAR100 dataset is converted into a 10-class dataset and uses the notation CIFAR100-10. The numbers of images in the CIFAR10-2 and CIFAR100-10 datasets are the same, and only the number of classes has been reduced. Unless specified, CIFAR10 and CIFAR100 are the original datasets. In addition, since there are more intra-variations for the Tiny ImageNet dataset, we do not reorganize the dataset as for the CIFAR10 and CIFAR100 datasets and directly use it for the multi-mode evaluation.
4.2. Implementation Details
The proposed method is implemented based on PyTorch and uses ResNet50 for Tiny ImageNet and ResNet18 [
4] for CIFAR10 and CIFAR100. To generate
d-dimensional embedding features, the output of layer 4 of the model is used with 512 hidden units using ResNet18 and 2048 for ResNet50. In all experiments, the model uses Stochastic Gradient Descent (SGD) with mini-batch size 32 for Tiny ImageNet and 128 for all other datasets, momentum 0.9, and weight decay
. We follow the standard training procedure and employ DAWNBench [
60] to train a robust model. We compare the proposed approach with TLA [
30,
61], PGD-AT [
19], Free [
37], and Fast [
38] across all three datasets as well as customized datasets.
Standard Training: We train the CIFAR10, CIFAR100, and Tiny ImageNet models for 120 epochs with an initial learning rate of 0.1 and reduce the learning rate by a factor of 10 after every 30 epochs during training. MNIST models were trained for 50 epochs using 0.01 as the initial learning rate, and the rate is reduced one time by a factor of 10.
DAWNBench: This competition has shown that the classifiers can be trained at significantly quicker times and at much lower cost than traditional training methods. A cyclic learning rate with a minimum of 0.001 and a maximum of 0.2 was utilized and it reduces the number of epochs needed to train the models. All the models were trained for 15 epochs.
PGD7 (7 steps of PGD attack) is used for PGD-based adversarial training. The number of modes for MNIST is 5, while for CIFAR10, CIFAR10-2, CIFAR100, CIFAR100-10 is 10, and for Tiny ImageNet is 20. If two modes are similar in the latent feature space, they are merged into one mode in the multi-mode settings. The number of modes is set to 1 in single-mode experiments. Free adversarial training takes FGSM steps with full step sizes followed by updating the model weights for N iterations on the same minibatch (also referred to as “minibatch replays”) where stands for the budget. This method uses replay (N) as 8 for CIFAR10, CIFAR10-2, CIFAR100, CIFAR100-10, and 4 for the Tiny ImageNet and MNIST datasets. Fast adversarial training uses FGSM with step size for CIFAR10,CIFAR10-2, CIFAR100, CIFAR100-10, and MNIST, while for Tiny ImageNet.
All training times are measured using a single GeForce GTX 1080Ti GPU. The proposed method has been tested against a variety of adversarial attacks including PGD, BIM, FGSM, and CW. PGD10 means 10 iterations of PGD adversarial attack with one random restart following [
37]. The
and
in Equation (
5) are 0.5 and 0.001, respectively for CIFAR10, CIFAR10-2, CIFAR100, and CIFAR100-10. While for MNIST and Tiny ImageNet,
= 0.5,
= 0.005 and
= 0.1,
= 0.001 are used, respectively.
To demonstrate the effectiveness of the proposed method, we use different epsilon and alpha values as shown in each experiment setting. The accuracies of clean examples and adversarial examples are measured to evaluate the performance of the proposed approach. For the MNIST dataset, a variant of the LeNet CNN architecture having batch normalization [
36] is used in our study. This architecture has two convolution layers (of stride 2) with each layer followed by ReLU, and then two fully connected layers, where the first is followed by ReLU as well. The hyperparameters of PGD adversarial example generation for the CIFAR10, CIFAR10-2, CIFAR100, and CIFAR100-10 datasets are
bounded with
and the step size
. Similarly, for the MNIST dataset, we use the hyperparameters with the step size
and
. For the Tiny ImageNet, we adopt
for training and
for validation with the step size
for both.
4.3. Experimental Results
As explained in
Section 4.2, we compare our method with three state-of-the-art adversarial training approaches in both standard and DAWNBench environments. Furthermore, we also present the results for MNIST, CIFAR10, CIFAR100, and Tiny ImageNet following the same setting as TLA [
30] for comparisons, and show the effectiveness of the proposed method using the standard dataset settings.
4.3.1. Performance Evaluations on Single-Mode Datasets
In the following experiments, we evaluate the proposed method on the MNIST, CIFAR10, and CIFAR100 datasets and compare the performance with other state-of-art defenses. To begin with, we compare the proposed method trained in different adversarial settings on CIFAR10, including standard PGD and fast adversarial training approaches, where Ours (PGD), Ours (Free), and Ours (Fast) indicate that to train the proposed method in the corresponding normal or fast adversarial training settings. For each method shown in
Table 1 with various single-step and multi-step white-box adversarial attacks, we use the same setting for training as depicted before. The proposed method improves the performance of all three methods (i.e., Fast, Free, and AT) without introducing a significant amount of additional training time, as shown in
Table 1.
With standard adversarial training procedure, Ours (PGD) produces the best adversarial robustness against various adversarial attacks. In the subsequent experiments, we primarily focus on reporting the performance of Ours (PGD). For
Table 2, we follow the same setting of [
30] and compare the proposed method with TLA, RoCL, ACL, and other competitive approaches on the MNIST, CIFAR10, and CIFAR100 datasets, and the results show that the proposed method is more robust than those methods against PGD attacks. The results reveal that, even for the single-mode data, the proposed multi-mode approach is still effective for performance improvement. We further compare the proposed method and ACL by conducting adversarial fine-tuning over their pre-trained models. The proposed method uses ACL pre-trained weights obtained by self-supervised learning as initialization of the model and then uses the proposed method to train the model. As demonstrated in
Table 2, the proposed method with ACL can further improve the performance.
4.3.2. Performance Evaluations on Multi-Mode datasets
Then, we further evaluate the robustness of the proposed method on the multi-mode datasets, CIFAR10-2, CIFAR100-10, and Tiny ImageNet. The details of the customized datasets are mentioned in
Section 4.1. The customized datasets simulate the multi-mode nature of the real-world datasets. This enables us to verify the effectiveness of the proposed method. We compare the proposed method with other baseline defense methods leveraging different deep metric learning regularization strategies, including TLA [
30], AT [
19], Free, [
37], ACL [
63], RoCL [
62], and Fast [
38].
Table 3 shows the compared results with other state-of-the-art adversarial defense methods in the multi-mode settings. Since ACL uses two independent batch normalizations, respectively, for clean and adversarial samples to pre-train the model and results in a better robust accuracy, we also utilize the same ACL adversarial batch normalization technique with the proposed method for better performance. For this purpose, we combine ACL with the proposed method (Ours (PGD)+ACL) by directly leveraging the model of ACL as the backbone of our approach, which also initialized its publicly available pre-trained weights for adversarial training. Furthermore, since ACL and RoCL pre-training are computationally expensive, ACL is only provided with the checkpoints of PGD for the CIFAR10 and CIFAR100 datasets. For this situation, we mainly evaluate the performances of RoCL, ACL, and Ours (PGD) + ACL on the CIFAR10-2 and CIFAR100-10 datasets. The results in
Table 3 show the proposed approach improves the performance of clean and adversarial samples consistently in both customized and Tiny ImageNet datasets and achieves better results than other approaches. Moreover, the performance of the proposed approach can be further improved when combined with ACL. Furthermore,
Table 4 shows the results compared with other state-of-the-art adversarial training methods against different adversarial attacks and a comparison using the CIFAR10 and CIFAR10-2 datasets. We also follow the settings of [
18] to evaluate the performance of the proposed method against targeted and untargeted attacks on the CIFAR10-2 and CIFAR100-10 datasets, and the results are shown in
Table 5. From these results, the proposed method achieves better performance than other approaches in different settings, especially for multi-mode settings. This demonstrates the effectiveness of our proposed method.
The experimental results show that the proposed method is not only better suited for the single-mode datasets but also further improves the performance on multi-mode datasets. Additional results of different hyper-parameters and settings are shown in
Section 5. In addition, we show more detailed analyses and experimental results on the multi-mode datasets in the discussion and ablation study in
Section 5.
4.4. Comparisons with Other Metric Learning Regularization Methods
The Deep Metric Learning algorithm learns similarity measures from raw images in embedding space. Triplet Loss Adversarial (TLA) [
30] proves that metric learning can be used in adversarial training to improve the robustness of the model. TLA [
30] uses triplet loss to train a robust model. We also use Proxy-Anchor [
28], Proxy-NCA [
27], and N-Pair [
6] losses for comparison with the proposed method.
Table 6 illustrates the performance of all these losses. Results show that our method outperforms all other metric learning losses in adversarial settings, while TLA [
30] is the second best in terms of adversarial accuracy. TLA needs high computation power and time to train a model due to negative sample mining while our method does not use mining and trained the same classifier faster. The results demonstrate that our multi-mode approach performs more favorably than TLA and is faster because the data-to-prototype similarities are used instead of the data-to-data similarities.
5. Discussions and Ablation Studies
In this section, we also perform additional analyses to evaluate the effectiveness of different parameters under various attacks. We propose a multi-prototype adversarial defense method for multi-mode data. Our method builds upon recent advances in adversarial training [
18,
19,
30] and deep metric learning [
28,
29,
30] to learn representations that outperform prior work on adversarial attacks. We also use deep metric losses as regularization in adversarial training and present the results in
Table 6 for comparison with the proposed method.
We have thoroughly investigated the combination of the Adversarial Contrastive Learning (ACL) approach with other methods mentioned, such as PGD, Free and Fast, and TLA. In the case of combining ACL with PGD, it essentially duplicates the process ACL already performs during fine-tuning after self-supervision. As for Free and Fast, their training algorithm differs significantly from ACL, and incorporating ACL weights did not yield improved performance. Regarding TLA, utilizing ACL weights made the training process unstable, as TLA relies on triplet mining. Hence, the combination with ACL weights did not contribute to enhanced performance.
To further evaluate the proposed method, we compared the results on CIFAR10 and CIFAR10-2 with the state-of-the-art methods using seen (adversarial attack used during training) and unseen (adversarial attacks not used during training) adversarial attacks, shown in
Table 4. The performance under FGSM, BIM, PGD10, and CW adversarial attacks demonstrates that the proposed method is more robust than TLA. To compare the training complexity of TLA with the proposed method, let
and
U denote the dataset size, adversarial steps, classes, batches per epoch, and proxies of each class, respectively. We use the same training settings, including the number of epochs, batch sizes, etc, for all methods. The training time complexity of proxy-based losses (e.g., Proxy-NCA [
27] and Proxy-Anchor [
28]) is in general lower than pair-based (e.g., Triplet [
30] and N-Pair [
6] losses). Since triplet loss that inspects triplets of data has the complexity of
, which is reduced by negative batch mining strategy, the complexity of the TLA loss is
[
28]. SoftTriple loss uses multiple proxies per class and associates each data point with
U positive proxies and
negative proxies. The complexity of the SoftTriple loss is thus
. As stated, the complexity of the proposed loss is lower than TLA and other pair-based losses.
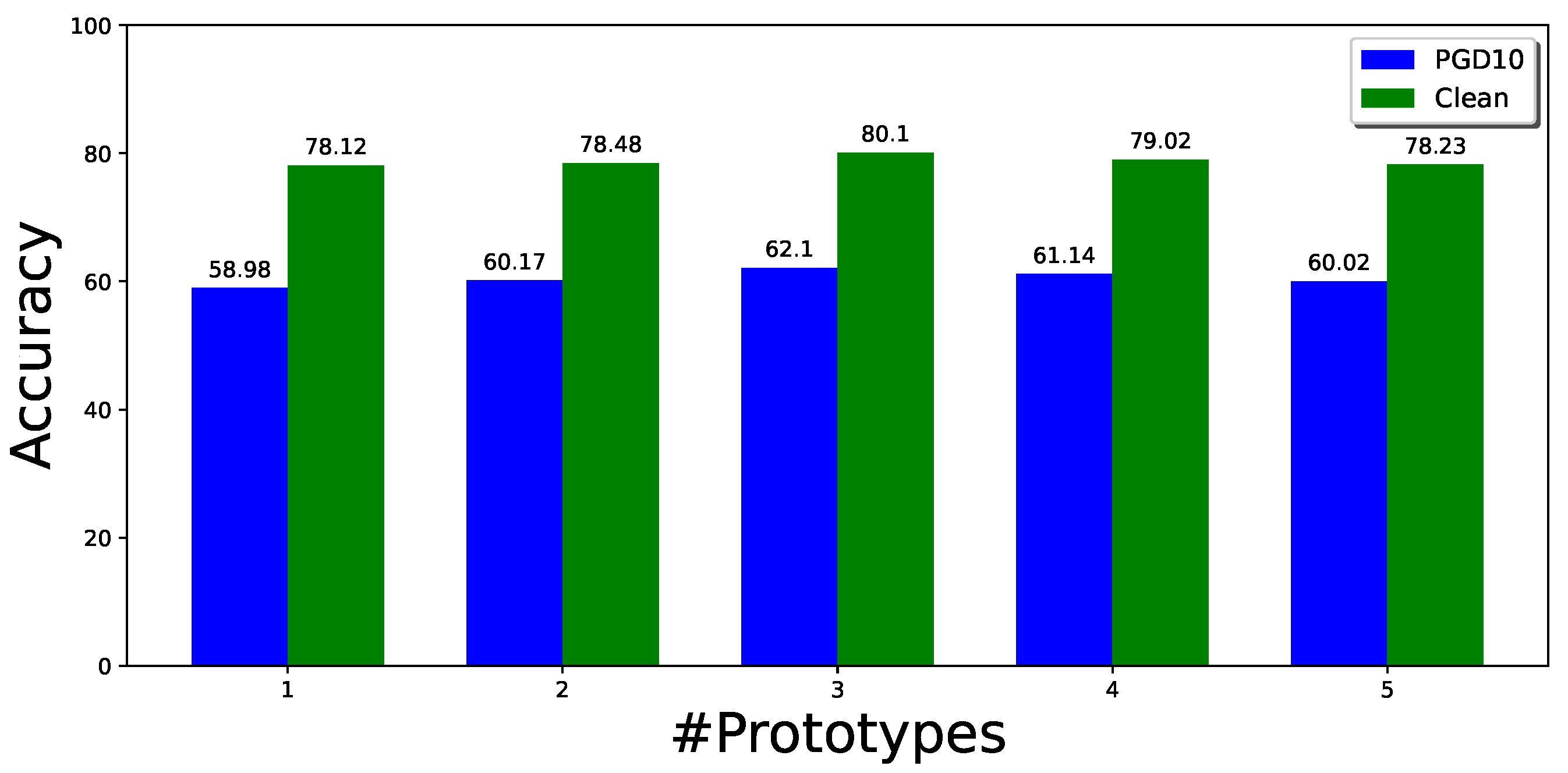
On the other hand, to better understand the effects of multiple modes in adversarial training, we also conduct experiments to explore the effects of changing the number of prototypes for each class for CIFAR10-2 under different cases.
Figure 3 shows the effect of different numbers of prototypes for each class on the robustness and clean accuracy. When the number of prototypes is increased, the performance improves up to a point and then slightly decreases. With three prototypes for each class, the method gives the best performance for this experiment. However, the performance can be further improved when the number of prototypes of each class varies. We show this in another experiment, where we initialized the number of classes with 10 for both classes in the CIFAR10-2 dataset. The prototypes are merged if they are close or similar in the latent feature space. The best performance on the CIFAR10-2 dataset, as demonstrated in
Table 7, is achieved when using three prototypes for class 0 and four prototypes for class 1.
Thus, we confirm that the number of prototypes plays an important role when training a robust classifier using adversarial training. Hyper-parameters also affect performance. Unlike TLA, our method does not depend too much on the batch size because we did not use negative sampling.
in Equation (
5) also affects the performance and we use different values to fine-tune it.
Table 8 shows the performance of different datasets using a range of
values and fixed
= 0.001 for the CIFAR10 and CIFAR10-2 datasets. We evaluate it in the range from 0.1 to 2 based on the experiment. As shown in
Table 8,
produces the best results for CIFAR10 and CIFAR10-2.






{kind=link}
{kind=link}
{kind=link}
{kind=link}