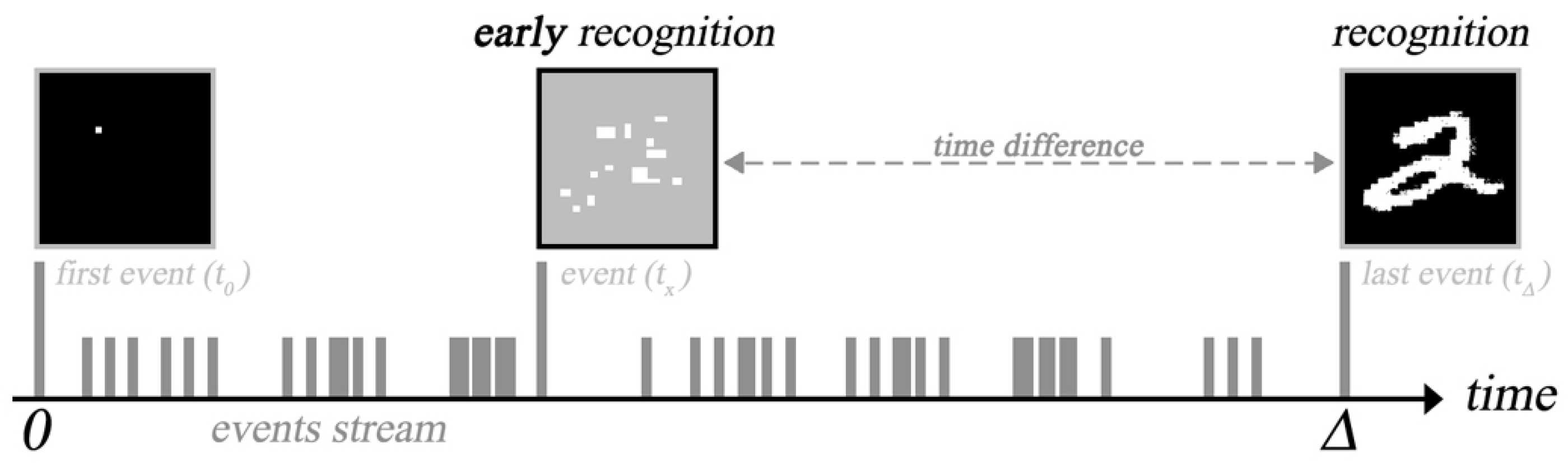
Figure 1.
Concept of early image recognition.
Figure 1.
Concept of early image recognition.
Figure 2.
CelePixel data acquisition setup.
Figure 2.
CelePixel data acquisition setup.
Figure 3.
CelePixel data acquisition conditions: (a) regular conditions; (b) with flickering light.
Figure 3.
CelePixel data acquisition conditions: (a) regular conditions; (b) with flickering light.
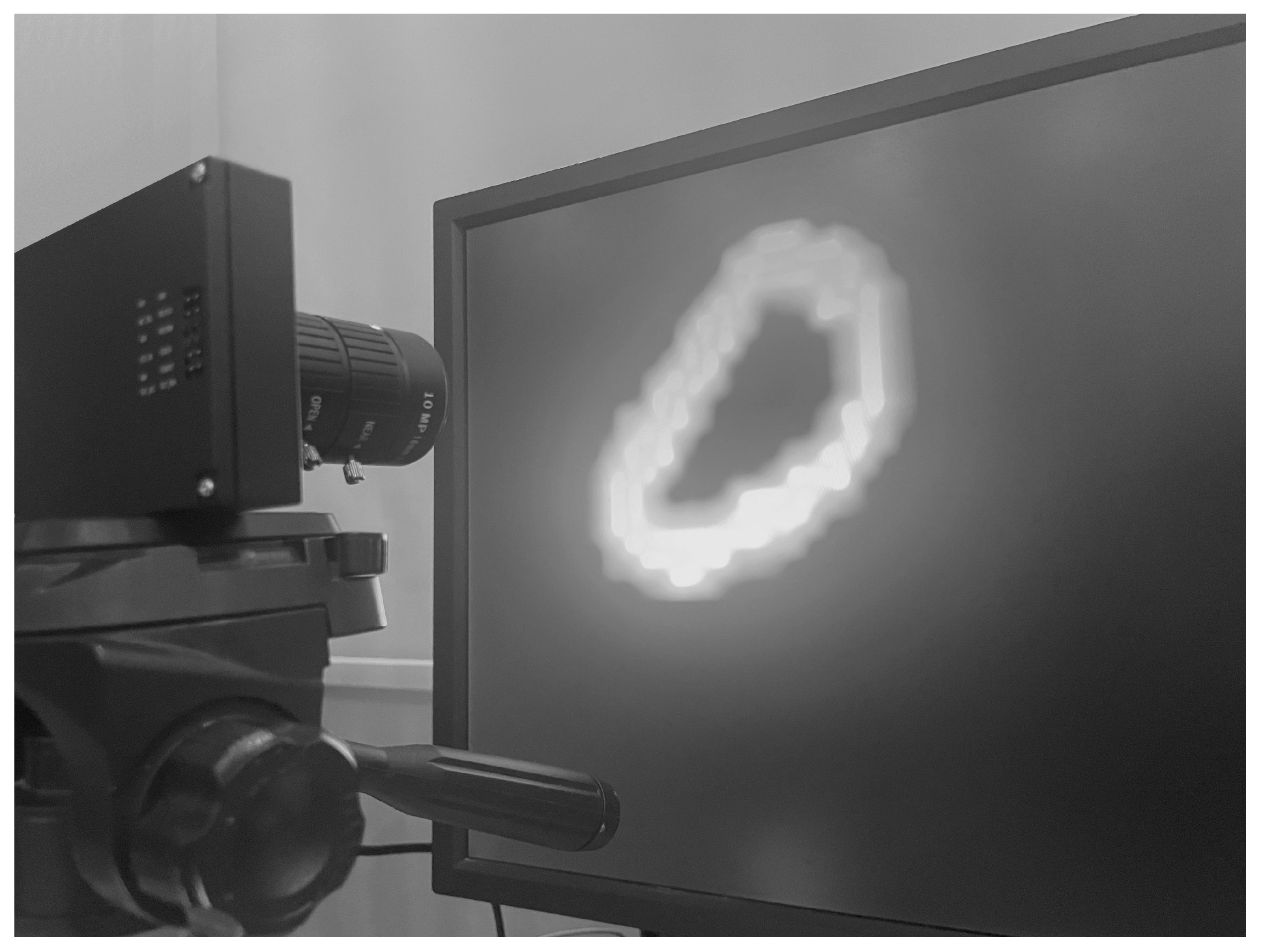
Figure 4.
(
A) ATIS mounted on a motorized pan-tilt unit. (
B) ATIS positioned in front of an LCD monitor [
20].
Figure 4.
(
A) ATIS mounted on a motorized pan-tilt unit. (
B) ATIS positioned in front of an LCD monitor [
20].
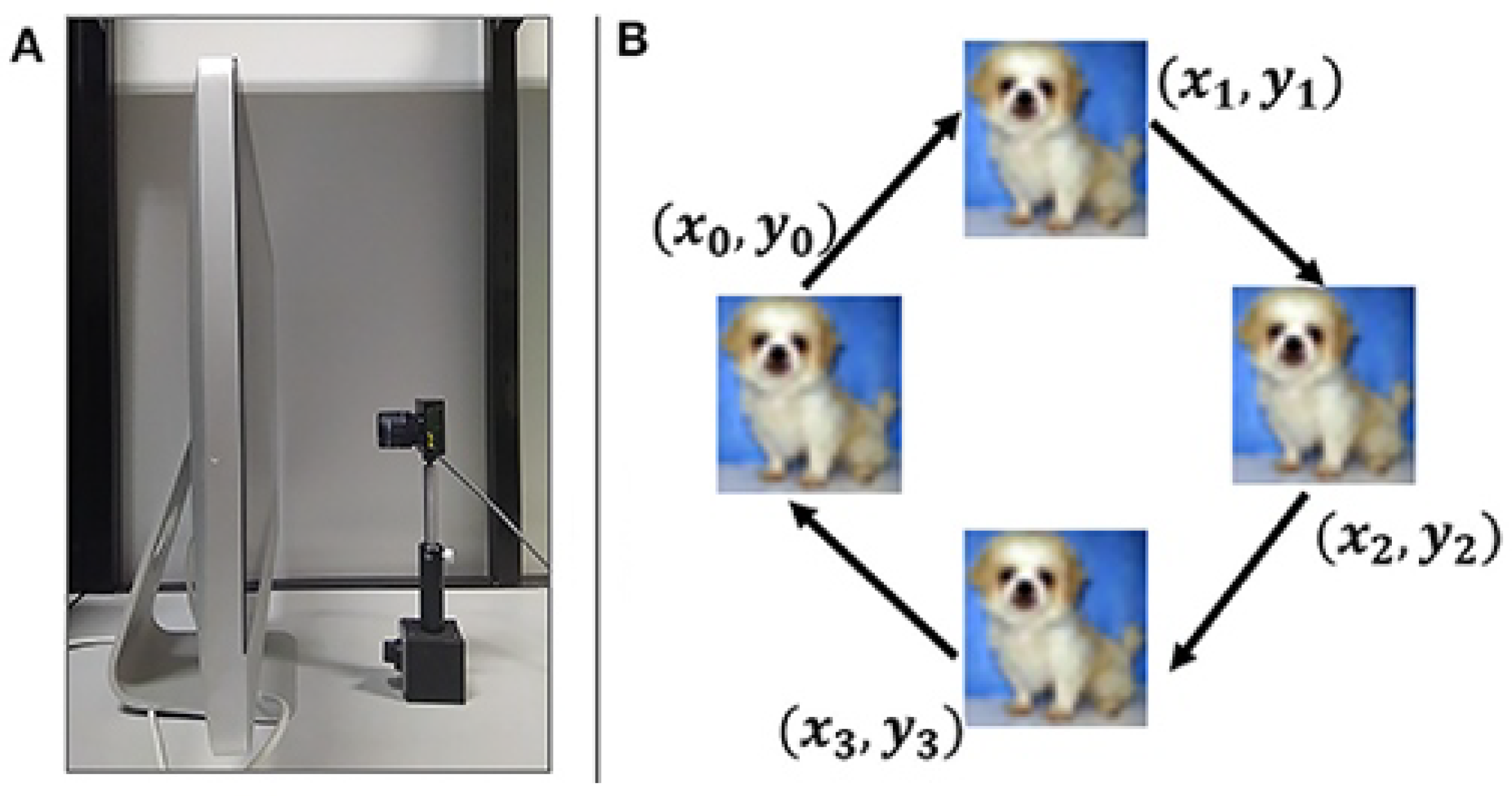
Figure 5.
(
A) Recording setup of sensor positioned in front of an LCD monitor. (
B) Image movement sequence on screen [
21].
Figure 5.
(
A) Recording setup of sensor positioned in front of an LCD monitor. (
B) Image movement sequence on screen [
21].
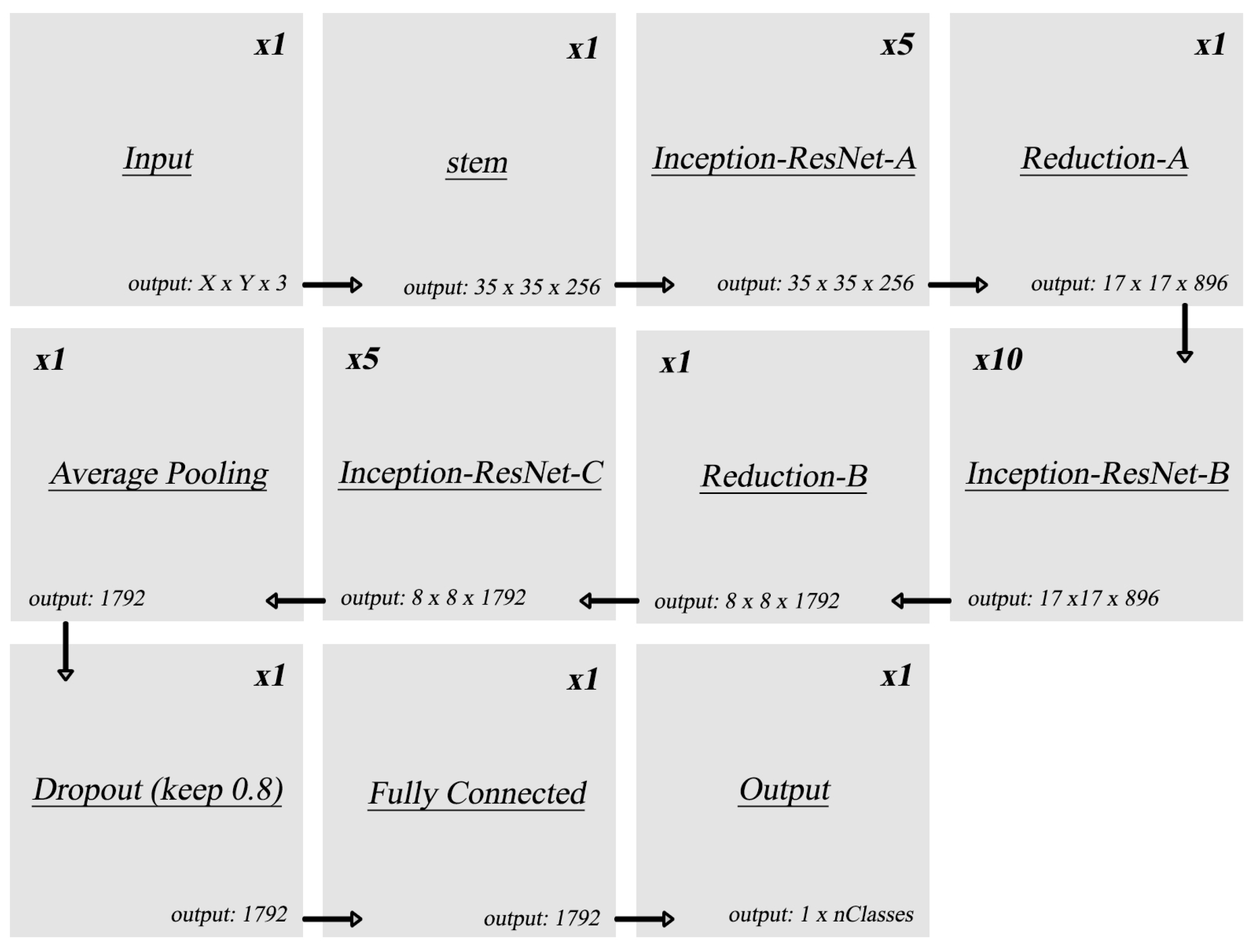
Figure 6.
Original InceptionResNetV2 architecture.
Figure 6.
Original InceptionResNetV2 architecture.
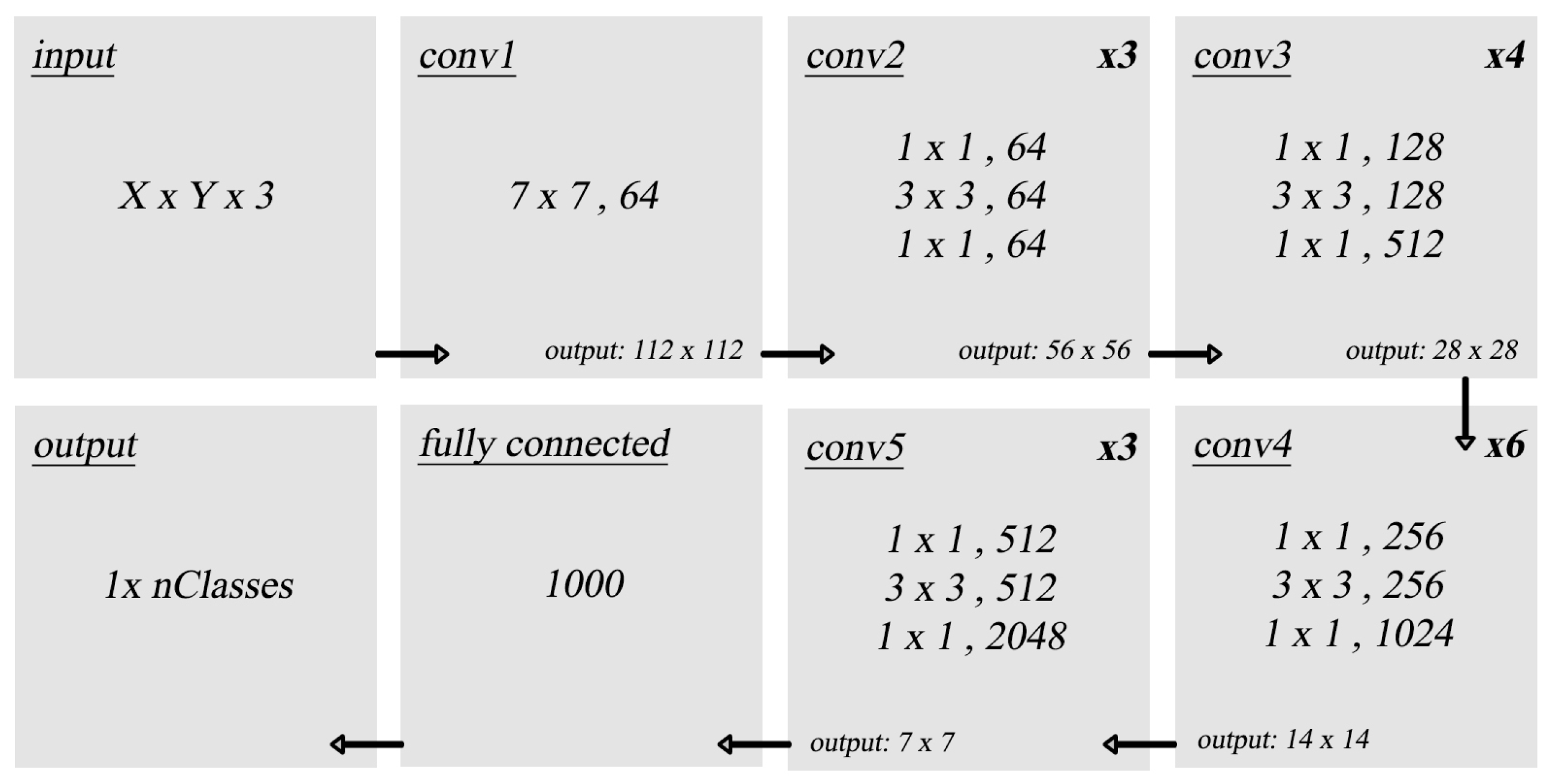
Figure 7.
Original ResNet50 architecture.
Figure 7.
Original ResNet50 architecture.
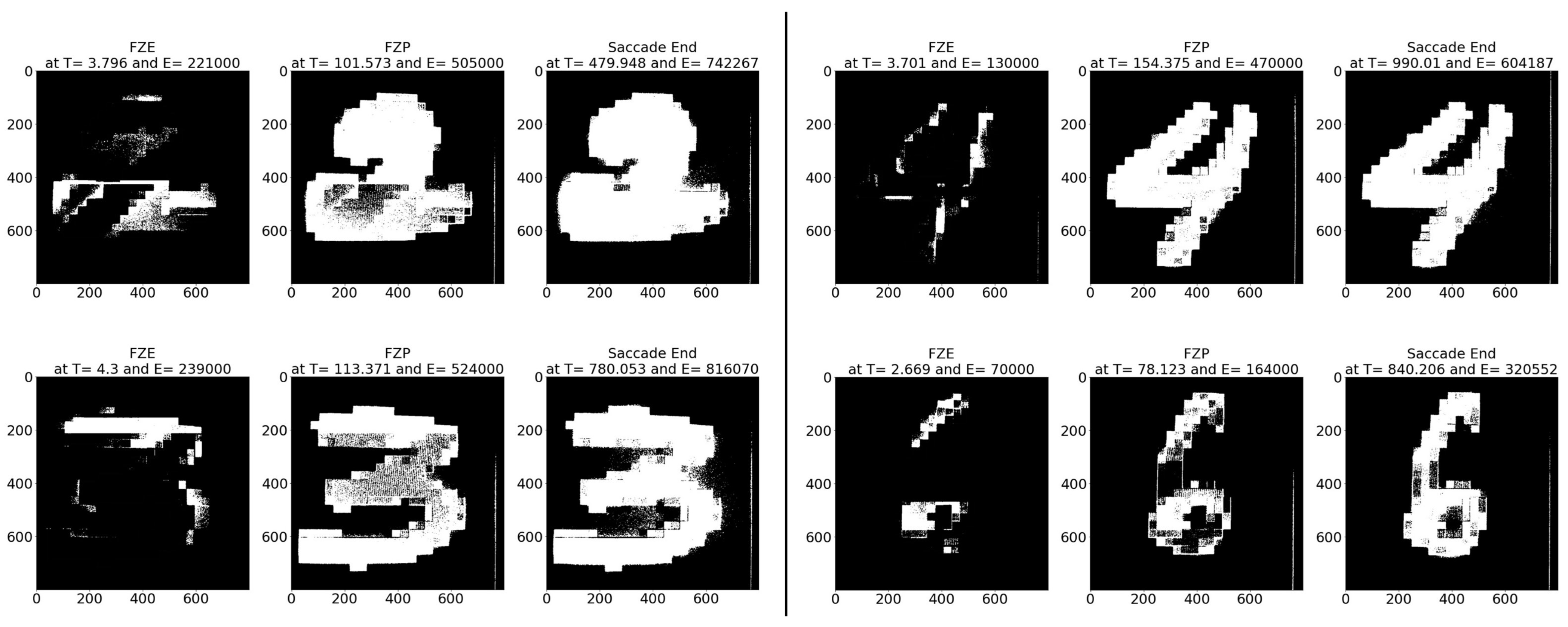
Figure 8.
Sample CeleX-MNIST test images at event (left) FZE, (middle) FPE, (right) saccade end.
Figure 8.
Sample CeleX-MNIST test images at event (left) FZE, (middle) FPE, (right) saccade end.
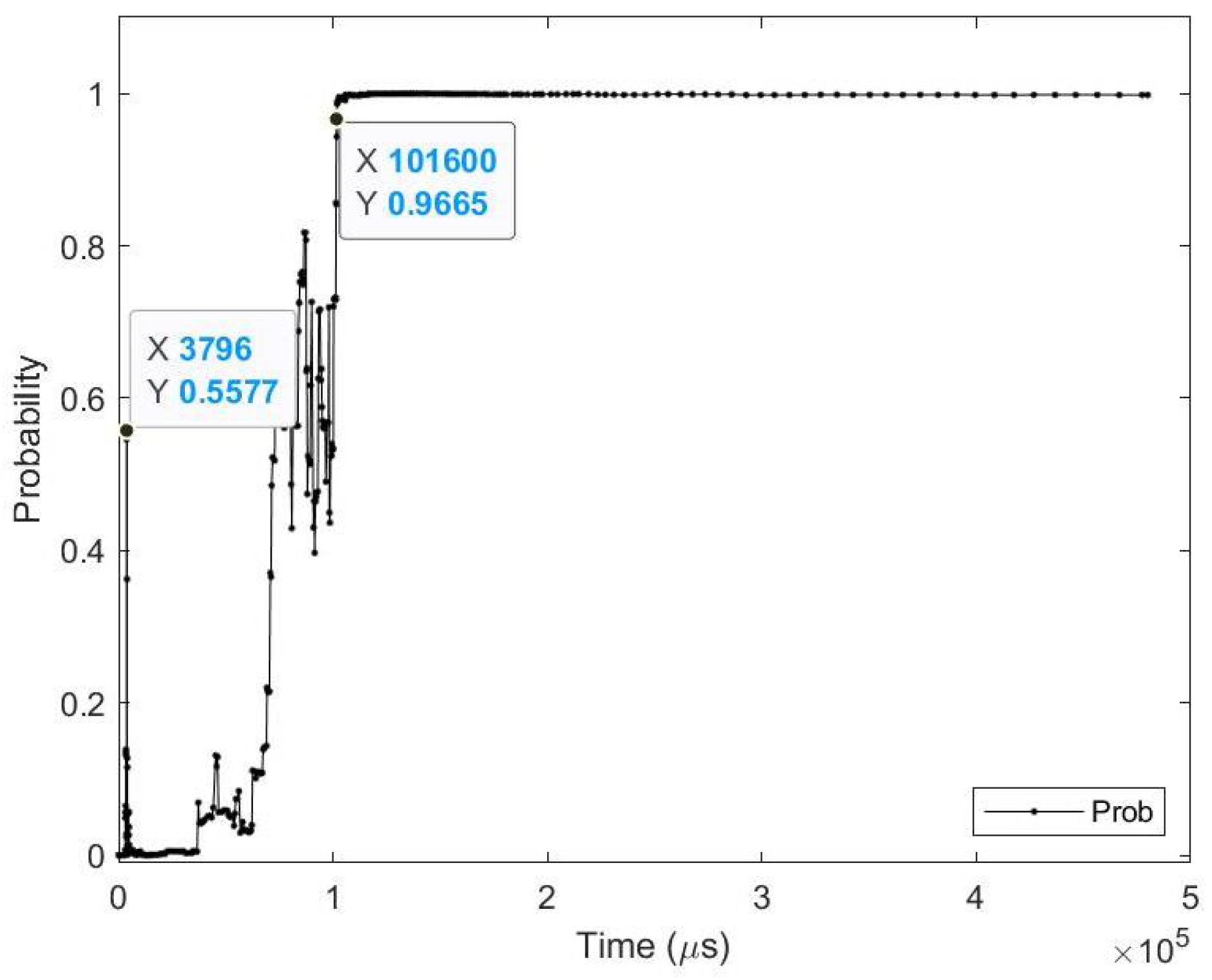
Figure 9.
Testing result of CeleX-MNIST class 2 image using time sequence.
Figure 9.
Testing result of CeleX-MNIST class 2 image using time sequence.
Figure 10.
Sample MNIST-DVS test images at event (left) FZE, (middle) FPE, (right) saccade end.
Figure 10.
Sample MNIST-DVS test images at event (left) FZE, (middle) FPE, (right) saccade end.
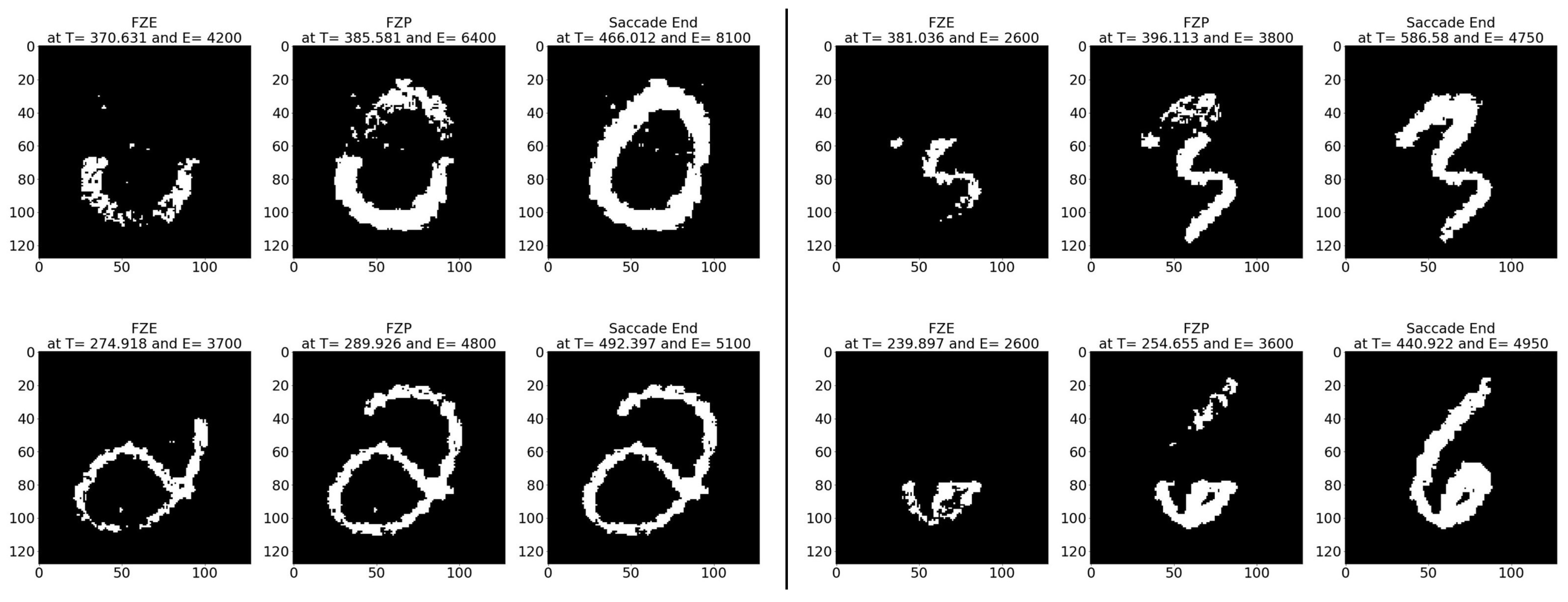
Figure 11.
Sample FLASH-MNIST test images at event (left) FZE, (middle) FPE, (right) saccade end.
Figure 11.
Sample FLASH-MNIST test images at event (left) FZE, (middle) FPE, (right) saccade end.
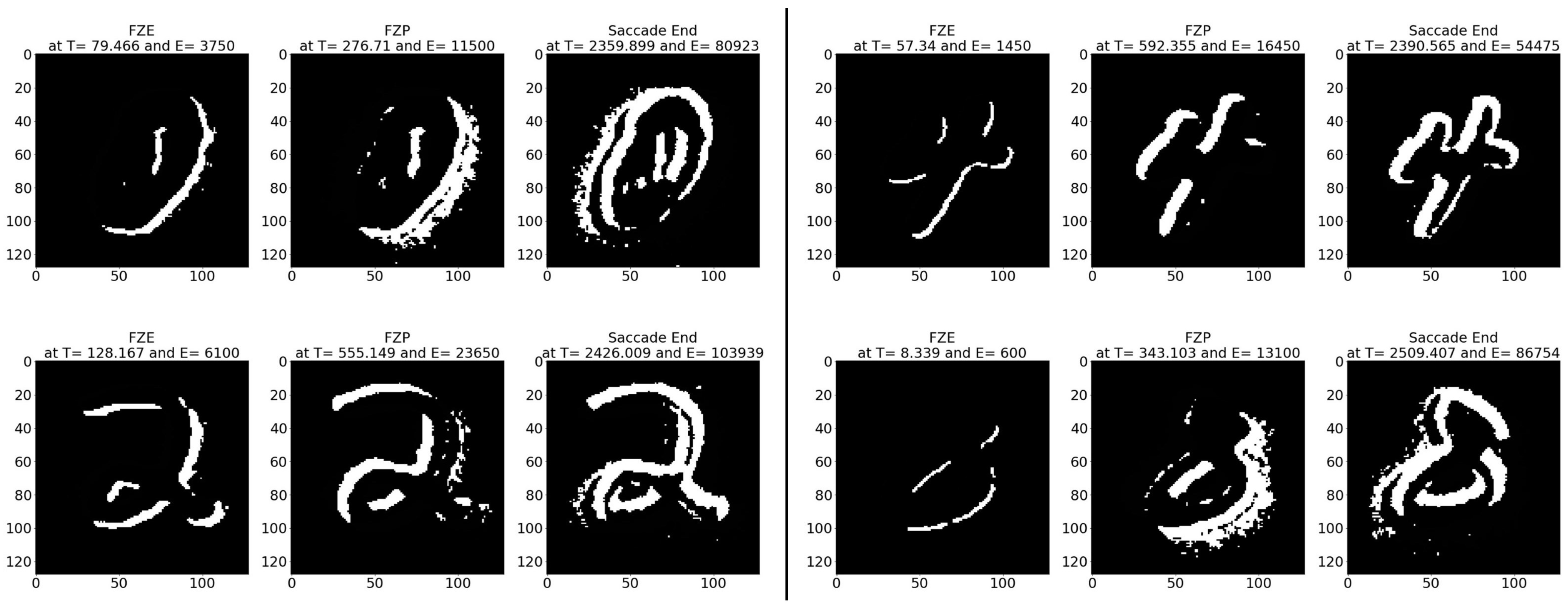
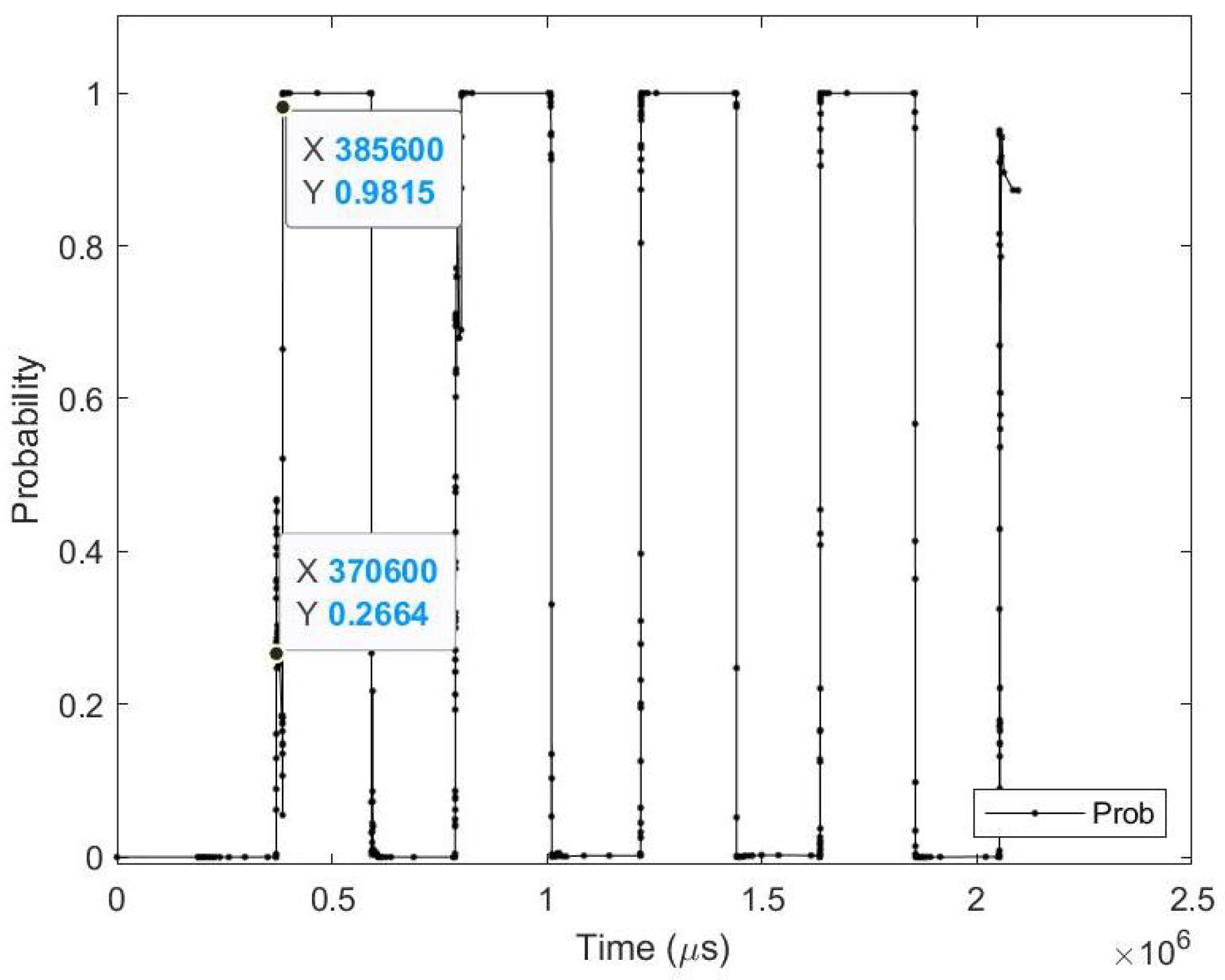
Figure 12.
Testing result of FLASH-MNIST class 0 image using time sequence.
Figure 12.
Testing result of FLASH-MNIST class 0 image using time sequence.
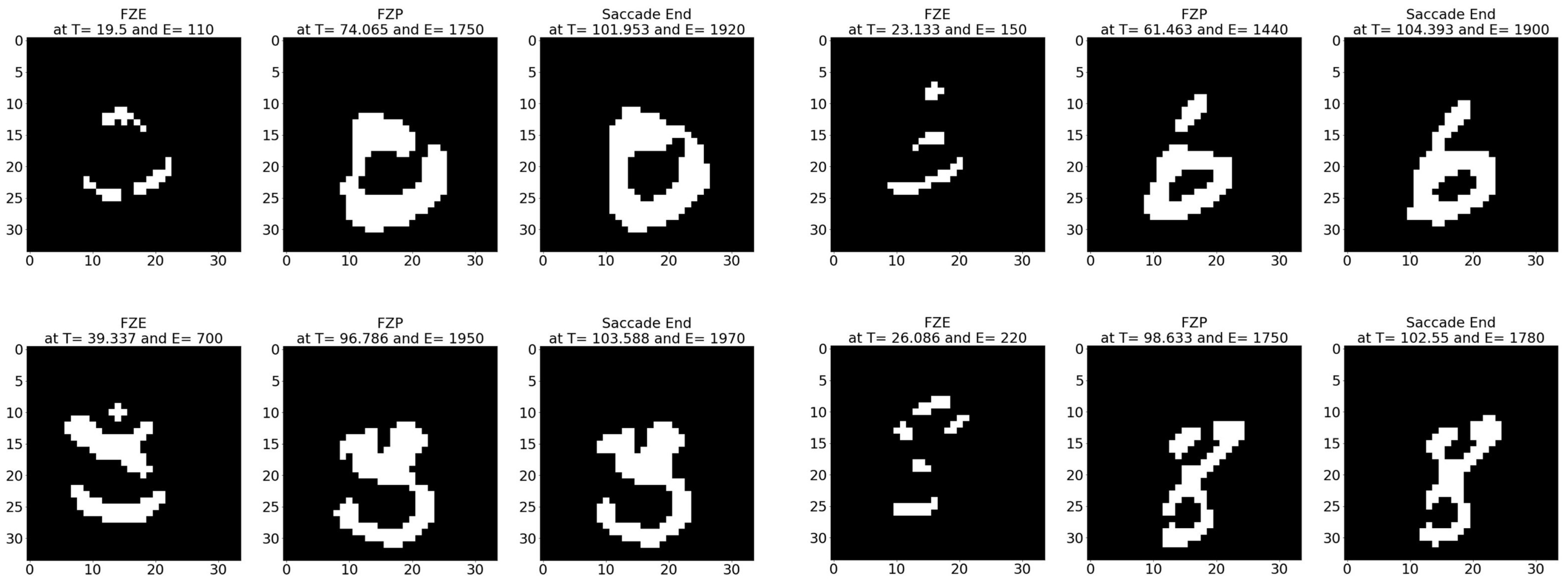
Figure 13.
Sample N-MNIST test images at event (left) FZE, (middle) FPE, (right) saccade end.
Figure 13.
Sample N-MNIST test images at event (left) FZE, (middle) FPE, (right) saccade end.
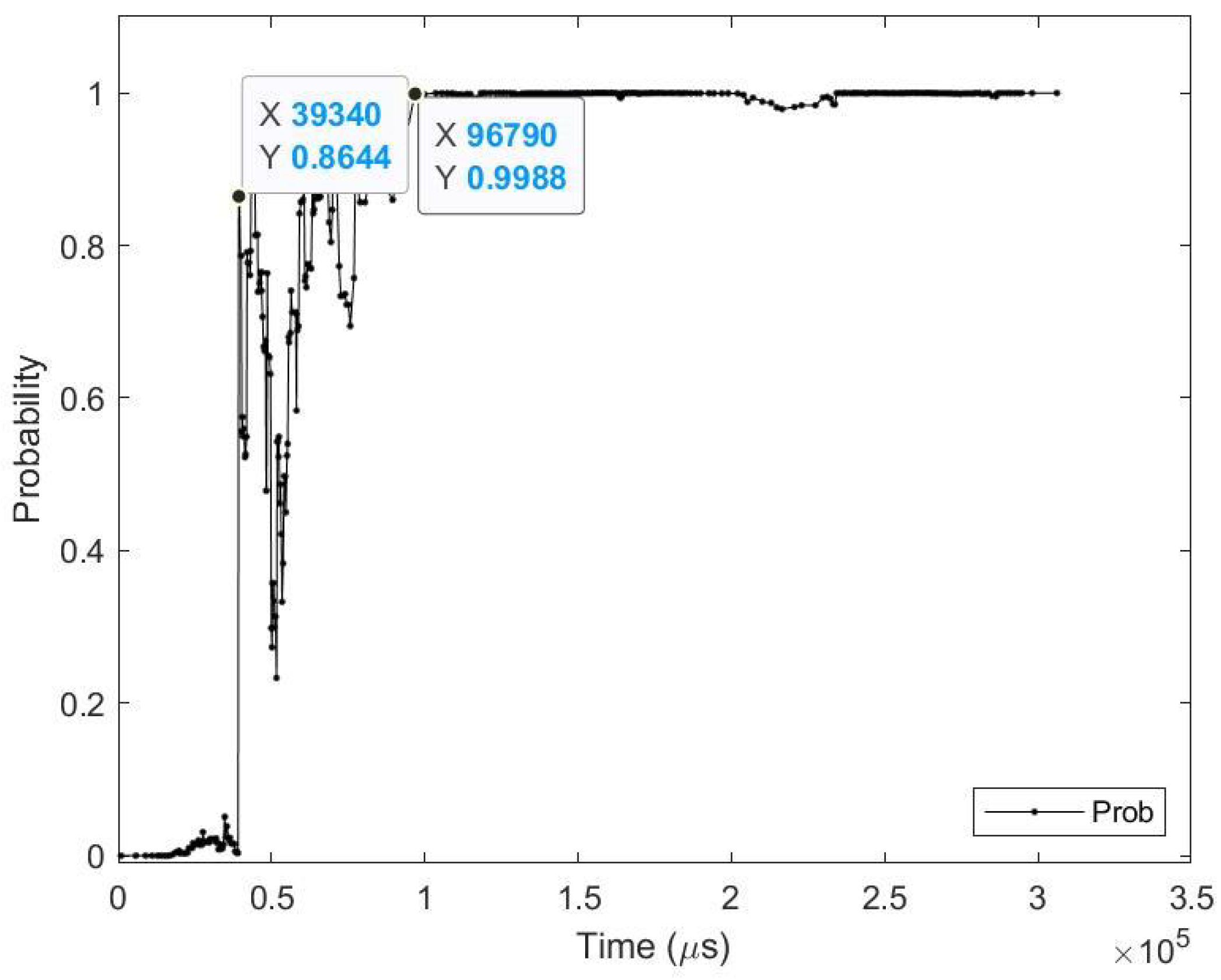
Figure 14.
Testing result of N-MNIST class 3 image using time sequence.
Figure 14.
Testing result of N-MNIST class 3 image using time sequence.
Figure 15.
Sample CIFAR-10 DVS test images at event (left) FZE, (middle) FPE, (right) saccade end. Row (1) left: airplane, right: cat. Row (2) left: automobile, right: dog.
Figure 15.
Sample CIFAR-10 DVS test images at event (left) FZE, (middle) FPE, (right) saccade end. Row (1) left: airplane, right: cat. Row (2) left: automobile, right: dog.
Figure 16.
Testing result of CIFAR-10 DVS class (automobile) image using time sequence.
Figure 16.
Testing result of CIFAR-10 DVS class (automobile) image using time sequence.
Figure 17.
Sample N-CALTECH101 test images at event (left) FZE, (middle) FPE, (right) saccade end. Row (1) left: accordion, right: ant. Row (2) left: anchor, right: chair.
Figure 17.
Sample N-CALTECH101 test images at event (left) FZE, (middle) FPE, (right) saccade end. Row (1) left: accordion, right: ant. Row (2) left: anchor, right: chair.
Figure 18.
Testing result of N-CALTECH101 class (accordion) image using time sequence.
Figure 18.
Testing result of N-CALTECH101 class (accordion) image using time sequence.
Figure 19.
Sample of noised original MNIST dataset (partial pictures).
Figure 19.
Sample of noised original MNIST dataset (partial pictures).
Table 1.
Dataset statistics results.
Table 1.
Dataset statistics results.
| Dataset | Average | Min X | Min Y | Max X | Max Y |
|---|
| Total E | Events | ON E | OFF E | Saccade T |
|---|
| CeleX-MNIST [this work] | 631 | 420,546 | 268,129 | 152,417 | 631 | 0 | 1279 | 0 | 799 |
| MNIST-DVS (Scale 4) [19] | 2261 | 17,011 | 8662 | 8349 | 2261.11 | 0 | 127 | 0 | 127 |
| MNIST-DVS (Scale 8) [19] | 2371 | 43,764 | 21,841 | 21,922 | 2370.70 | 0 | 127 | 0 | 127 |
| MNIST-DVS (Scale 16) [19] | 2412 | 103,144 | 50,985 | 52,158 | 2411.81 | 0 | 127 | 0 | 127 |
| FLASH-MNIST (Test) [19] | 2103 | 27,321 | 16,410 | 10,910 | 420.65 | 1 | 128 | 1 | 128 |
| FLASH-MNIST (Train) [19] | 2147 | 26,713 | 16,018 | 10,694 | 429.35 | 1 | 128 | 1 | 128 |
| N-MNIST (Test) [20] | 306 | 4204 | 2116 | 2087 | 102.07 | 1 | 34 | 1 | 34 |
| N-MNIST (Train) [20] | 307 | 4172 | 2088 | 2084 | 102.17 | 1 | 34 | 1 | 34 |
| CIFAR-10 [21] | 1300 | 183,145 | 76,870 | 106,276 | 54.19 | 0 | 127 | 0 | 127 |
| N-Caltech 101 [20] | 300 | 115,298 | 58,289 | 57,009 | 100.05 | 1 | 233 | 1 | 173 |
Table 2.
Testing metrics.
Table 2.
Testing metrics.
| Zero_Time | Average time of FZE (ms). |
| Zero_Event | Average event of FZE. |
| Zero_Prob | Average probability of FZE. |
| Perfect_Time | Average time of FPE (ms). |
| Perfect_Event | Average event of FPE. |
| Perfect_Prob | Average probability of FPE. |
| Time_Diff | Average time difference between FPE and FZE, which determines how early an image is detected in terms of time (ms). |
| Time % | Average time difference percentage between FPE and FZE, which determines how early an image is detected in terms of time. |
| Event_Diff | Average event difference between FPE and FZE, which determines how early an image is detected in terms of event number. |
| Event % | Average event difference percentage between FPE and FZE, which determines how early an image is detected in terms of event number |
| Sacc_Time_Diff | Average time difference between saccade end and FZE, which determines how early an image is detected in terms of time (ms). |
Table 3.
Average results for CeleX-MNIST test images.
Table 3.
Average results for CeleX-MNIST test images.
| Zero_Time | 39.69 (ms) | Zero_Prob | 56.20% |
| Perfect_Time | 51.46 (ms) | Perfect_Prob | 78.72% |
| Zero_Event | 153,598 (events) | Perfect_Event | 172,121 (events) |
| Time_Diff | 14.81 (ms) | Time % | 28.78% |
| Event_Diff | 32,558 (events) | Event % | 18.92% |
| Sacc_Diff | 613.73 (ms) | Sacc % | 93.98% |
Table 4.
Average results for (3) Categories of CeleX-MNIST test images.
Table 4.
Average results for (3) Categories of CeleX-MNIST test images.
| Class 3 (30 images) |
|---|
| Zero_Time | 51.81 (ms) | Zero_Prob | 47.72% |
| Perfect_Time | 64.18 (ms) | Perfect_Prob | 74.17% |
| Zero_Event | 198,633 (events) | Perfect_Event | 222,683 (events) |
| Time_Diff | 17.00 (ms) | Time % | 26.48% |
| Event_Diff | 36,016 (events) | Event % | 16.17% |
| Sacc_Diff | 621.71 (ms) | Sacc % | 92.31% |
| Class 6 (30 images) |
| Zero_Time | 65.37 (ms) | Zero_Prob | 50.95% |
| Perfect_Time | 80.19 (ms) | Perfect_Prob | 73.17% |
| Zero_Event | 189,450 (events) | Perfect_Event | 213,350 (events) |
| Time_Diff | 14.97 (ms) | Time % | 18.66% |
| Event_Diff | 29,550 (events) | Event % | 13.85% |
| Sacc_Diff | 636.20 (ms) | Sacc % | 90.68% |
| Class 9 (30 images) |
| Zero_Time | 38.11 (ms) | Zero_Prob | 49.71% |
| Perfect_Time | 54.68 (ms) | Perfect_Prob | 80.85% |
| Zero_Event | 158,433 (events) | Perfect_Event | 185,833 (events) |
| Time_Diff | 20.46 (ms) | Time % | 37.42% |
| Event_Diff | 40,066 (events) | Event % | 21.56% |
| Sacc_Diff | 557.90 (ms) | Sacc % | 93.61% |
Table 5.
Average results for CeleX-MNIST class 2 test image.
Table 5.
Average results for CeleX-MNIST class 2 test image.
| Zero_Time | 3.80 (ms) | Zero_Prob | 55.77% |
| Perfect_Time | 101.57 (ms) | Perfect_Prob | 96.65% |
| Zero_Event | 221,000 (events) | Perfect_Event | 505,000 (events) |
| Time_Diff | 97.7 (ms) | Time % | 96.26% |
| Event_Diff | 284,000 (events) | Event % | 56.24% |
Table 6.
Average results for MNIST-DVS test images.
Table 6.
Average results for MNIST-DVS test images.
| Zero_Time | 235.45 (ms) | Zero_Prob | 61.65% |
| Perfect_Time | 306.11 (ms) | Perfect_Prob | 87.22% |
| Zero_Event | 7616 (events) | Perfect_Event | 9834 (events) |
| Time_Diff | 108.69 (ms) | Time % | 35.51% |
| Event_Diff | 3400 (events) | Event % | 34.57% |
| Sacc_Diff | 2176.37 (ms) | Sacc % | 90.24% |
Table 7.
Average results for (3) categories of MNIST-DVS test images.
Table 7.
Average results for (3) categories of MNIST-DVS test images.
| Class 2 (1000 images) |
| Zero_Time | 546.72 (ms) | Zero_Prob | 47.71% |
| Perfect_Time | 578.64 (ms) | Perfect_Prob | 82.70% |
| Zero_Event | 17,582 (events) | Perfect_Event | 18,303 (events) |
| Time_Diff | 101.3 (ms) | Time % | 17.51% |
| Event_Diff | 1865 (events) | Event % | 16.31% |
| Sacc_Diff | 1865.09 (ms) | Sacc % | 77.33% |
| Class 4 (1000 images) |
| Zero_Time | 188.48 (ms) | Zero_Prob | 65.67% |
| Perfect_Time | 322.13 (ms) | Perfect_Prob | 78.24% |
| Zero_Event | 5185 (events) | Perfect_Event | 8546 (events) |
| Time_Diff | 179.34 (ms) | Time % | 55.67% |
| Event_Diff | 4633 (events) | Event % | 54.21% |
| Sacc_Diff | 2223.33 (ms) | Sacc % | 92.19% |
| Class 6 (1000 images) |
| Zero_Time | 452.23 (ms) | Zero_Prob | 50.70% |
| Perfect_Time | 515.07 (ms) | Perfect_Prob | 79.66% |
| Zero_Event | 12,301 (events) | Perfect_Event | 13,844 (events) |
| Time_Diff | 146.05 (ms) | Time % | 28.35% |
| Event_Diff | 3650 (events) | Event % | 26.36% |
| Sacc_Diff | 1959.59 (ms) | Sacc % | 81.25% |
Table 8.
Average results for FLASH-MNIST test images.
Table 8.
Average results for FLASH-MNIST test images.
| Zero_Time | 336.79 (ms) | Zero_Prob | 66.80% |
| Perfect_Time | 335.82 (ms) | Perfect_Prob | 96.00% |
| Zero_Event | 3581 (events) | Perfect_Event | 3842 (events) |
| Time_Diff | 5.76 (ms) | Time % | 1.72% |
| Event_Diff | 324 (events) | Event % | 8.43% |
| Sacc_Diff | 83.86 (ms) | Sacc % | 19.94% |
Table 9.
Average results for (3) categories of FLASH-MNIST test images.
Table 9.
Average results for (3) categories of FLASH-MNIST test images.
| Class 0 (980 images) |
| Zero_Time | 372.41 (ms) | Zero_Prob | 63.15% |
| Perfect_Time | 375.58 (ms) | Perfect_Prob | 97.64% |
| Zero_Event | 4402 (events) | Perfect_Event | 4860 (events) |
| Time_Diff | 3.17 (ms) | Time % | 0.84% |
| Event_Diff | 458 (events) | Event % | 9.41% |
| Sacc_Diff | 51.60 (ms) | Sacc % | 12.20% |
| Class 3 (1010 images) |
| Zero_Time | 374.31 (ms) | Zero_Prob | 60.56% |
| Perfect_Time | 372.17 (ms) | Perfect_Prob | 96.87% |
| Zero_Event | 4229 (events) | Perfect_Event | 4532 (events) |
| Time_Diff | 2.36 (ms) | Time % | 0.63% |
| Event_Diff | 329 (events) | Event % | 7.27% |
| Sacc_Diff | 52.80 (ms) | Sacc % | 12.60% |
| Class 7 (1028 images) |
| Zero_Time | 369.08 (ms) | Zero_Prob | 65.89% |
| Perfect_Time | 366.89 (ms) | Perfect_Prob | 93.78% |
| Zero_Event | 3030 (events) | Perfect_Event | 3313 (events) |
| Time_Diff | 7.29 (ms) | Time % | 1.99% |
| Event_Diff | 350 (events) | Event % | 10.57% |
| Sacc_Diff | 42.62 (ms) | Sacc % | 10.14% |
Table 10.
Average results for FLASH-MNIST class 0 test image.
Table 10.
Average results for FLASH-MNIST class 0 test image.
| Zero_Time | 370.63 (ms) | Zero_Prob | 26.64% |
| Perfect_Time | 385.58 (ms) | Perfect_Prob | 98.15% |
| Zero_Event | 4200 (events) | Perfect_Event | 6400 (events) |
| Time_Diff | 14.95 (ms) | Time % | 3.88% |
| Event_Diff | 2200 (events) | Event % | 34.38% |
Table 11.
Average results for N-MNIST test images.
Table 11.
Average results for N-MNIST test images.
| Zero_Time | 32.47 (ms) | Zero_Prob | 67.09% |
| Perfect_Time | 39.65 (ms) | Perfect_Prob | 96.40% |
| Zero_Event | 358 (events) | Perfect_Event | 516 (events) |
| Time_Diff | 7.89 (ms) | Time % | 19.91% |
| Event_Diff | 167 (events) | Event % | 32.26% |
| Sacc_Diff | 69.60 (ms) | Sacc % | 68.18% |
Table 12.
Average results for (3) categories of N-MNIST test images.
Table 12.
Average results for (3) categories of N-MNIST test images.
| Class 5 (892 images) |
| Zero_Time | 25.17 (ms) | Zero_Prob | 66.09% |
| Perfect_Time | 29.88 (ms) | Perfect_Prob | 97.31% |
| Zero_Event | 207 (events) | Perfect_Event | 313 (events) |
| Time_Diff | 4.74 (ms) | Time % | 15.86% |
| Event_Diff | 107 (events) | Event % | 34.07% |
| Sacc_Diff | 76.90 (ms) | Sacc % | 75.34% |
| Class 8 (974 images) |
| Zero_Time | 34.89 (ms) | Zero_Prob | 67.58% |
| Perfect_Time | 44.24 (ms) | Perfect_Prob | 96.78% |
| Zero_Event | 396 (events) | Perfect_Event | 598 (events) |
| Time_Diff | 9.96 (ms) | Time % | 22.51% |
| Event_Diff | 210 (events) | Event % | 35.11% |
| Sacc_Diff | 67.18 (ms) | Sacc % | 65.81% |
| Class 9 (1009 images) |
| Zero_Time | 31.75 (ms) | Zero_Prob | 60.02% |
| Perfect_Time | 36.82 (ms) | Perfect_Prob | 95.01% |
| Zero_Event | 252 (events) | Perfect_Event | 357 (events) |
| Time_Diff | 6.33 (ms) | Time % | 17.19% |
| Event_Diff | 116 (events) | Event % | 32.36% |
| Sacc_Diff | 70.32 (ms) | Sacc % | 68.90% |
Table 13.
Average results for N-MNIST class 3 test image.
Table 13.
Average results for N-MNIST class 3 test image.
| Zero_Time | 39.34 (ms) | Zero_Prob | 86.44% |
| Perfect_Time | 96.79 (ms) | Perfect_Prob | 99.88% |
| Zero_Event | 700 (events) | Perfect_Event | 1950 (events) |
| Time_Diff | 57.45 (ms) | Time % | 59.36% |
| Event_Diff | 1250 (events) | Event % | 64.10% |
Table 14.
Average results for CIFAR-10 DVS test images.
Table 14.
Average results for CIFAR-10 DVS test images.
| Zero_Time | 88.96 (ms) | Zero_Prob | 44.99% |
| Perfect_Time | 123.42 (ms) | Perfect_Prob | 58.45% |
| Zero_Event | 18,519 (events) | Perfect_Event | 23,507 (events) |
| Time_Diff | 82.12 (ms) | Time % | 66.54% |
| Event_Diff | 14,239 (events) | Event % | 60.57% |
Table 15.
Average results for (3) categories of CIFAR-10 DVS test images.
Table 15.
Average results for (3) categories of CIFAR-10 DVS test images.
| Class Airplane (1000 images) |
| Zero_Time | 11.88 (ms) | Zero_Prob | 54.40% |
| Perfect_Time | 43.97 (ms) | Perfect_Prob | 92.69% |
| Zero_Event | 3960 (events) | Perfect_Event | 9679 (events) |
| Time_Diff | 33.77 (ms) | Time % | 72.98% |
| Event_Diff | 6062 (events) | Event % | 59.09% |
| Class Bird (380 images) |
| Zero_Time | 129.43 (ms) | Zero_Prob | 43.95% |
| Perfect_Time | 155.67 (ms) | Perfect_Prob | 45.78% |
| Zero_Event | 26,341 (events) | Perfect_Event | 26,521 (events) |
| Time_Diff | 32.09 (ms) | Time % | 16.86% |
| Event_Diff | 180 (events) | Event % | 0.68% |
| Class Cat (1000 images) |
| Zero_Time | 93.39 (ms) | Zero_Prob | 52.39% |
| Perfect_Time | 180.91 (ms) | Perfect_Prob | 65.54% |
| Zero_Event | 22,720 (events) | Perfect_Event | 35,133 (events) |
| Time_Diff | 87.52 (ms) | Time % | 48.38% |
| Event_Diff | 12,414 (events) | Event % | 35.33% |
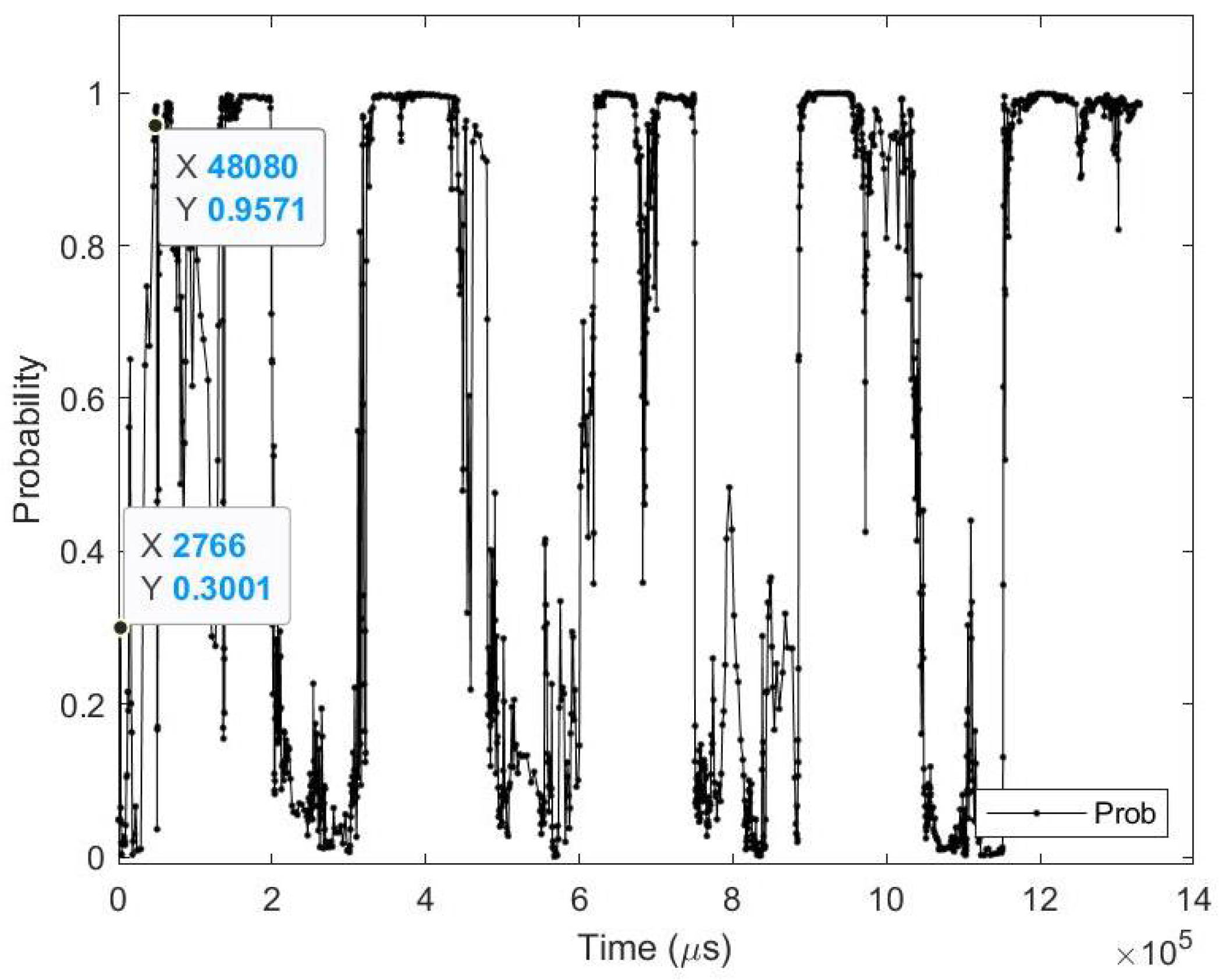
Table 16.
Average results for CIFAR-10 DVS class (automobile) test image.
Table 16.
Average results for CIFAR-10 DVS class (automobile) test image.
| Zero_Time | 2.77 (ms) | Zero_Prob | 30.01% |
| Perfect_Time | 48.08 (ms) | Perfect_Prob | 95.71% |
| Zero_Event | 1700 (events) | Perfect_Event | 7800 (events) |
| Time_Diff | 45.31 (ms) | Time % | 94.25% |
| Event_Diff | 6100 (events) | Event % | 78.21% |
Table 17.
Average results for N-CALTECH101 test images.
Table 17.
Average results for N-CALTECH101 test images.
| Zero_Time | 26.60 (ms) | Zero_Prob | 20.46% |
| Perfect_Time | 24.11 (ms) | Perfect_Prob | 45.46% |
| Zero_Event | 7701 (events) | Perfect_Event | 8778 (events) |
| Time_Diff | 12.58 (ms) | Time % | 52.15% |
| Event_Diff | 6074 (events) | Event % | 69.20% |
| Sacc_Diff | 73.45 (ms) | Sacc % | 73.41% |
Table 18.
Average results for (3) categories of N-CALTECH101 test images.
Table 18.
Average results for (3) categories of N-CALTECH101 test images.
| Class menorah (87 images) |
| Zero_Time | 18.17 (ms) | Zero_Prob | 18.33% |
| Perfect_Time | 427.92 (ms) | Perfect_Prob | 92.45% |
| Zero_Event | 3836 (events) | Perfect_Event | 8069.54 (events) |
| Time_Diff | 11.24 (ms) | Time % | 40.25% |
| Event_Diff | 5252 (events) | Event % | 65.09% |
| Sacc_Diff | 81.88 (ms) | Sacc % | 81.84% |
| Class stop_sign (64 images) |
| Zero_Time | 45.42 (ms) | Zero_Prob | 22.70% |
| Perfect_Time | 50.11 (ms) | Perfect_Prob | 52.7% |
| Zero_Event | 15,113 (events) | Perfect_Event | 19,893 (events) |
| Time_Diff | 27.71 (ms) | Time % | 55.31% |
| Event_Diff | 11,881 (events) | Event % | 59.73% |
| Sacc_Diff | 54.63 (ms) | Sacc % | 54.60% |
| Class yin_yang (60 images) |
| Zero_Time | 15.96 (ms) | Zero_Prob | 21.60% |
| Perfect_Time | 38.39 (ms) | Perfect_Prob | 70.39% |
| Zero_Event | 3200 (events) | Perfect_Event | 9685 (events) |
| Time_Diff | 28.32 (ms) | Time % | 73.76% |
| Event_Diff | 8649 (events) | Event % | 89.30% |
| Sacc_Diff | 84.09 (ms) | Sacc % | 84.05% |
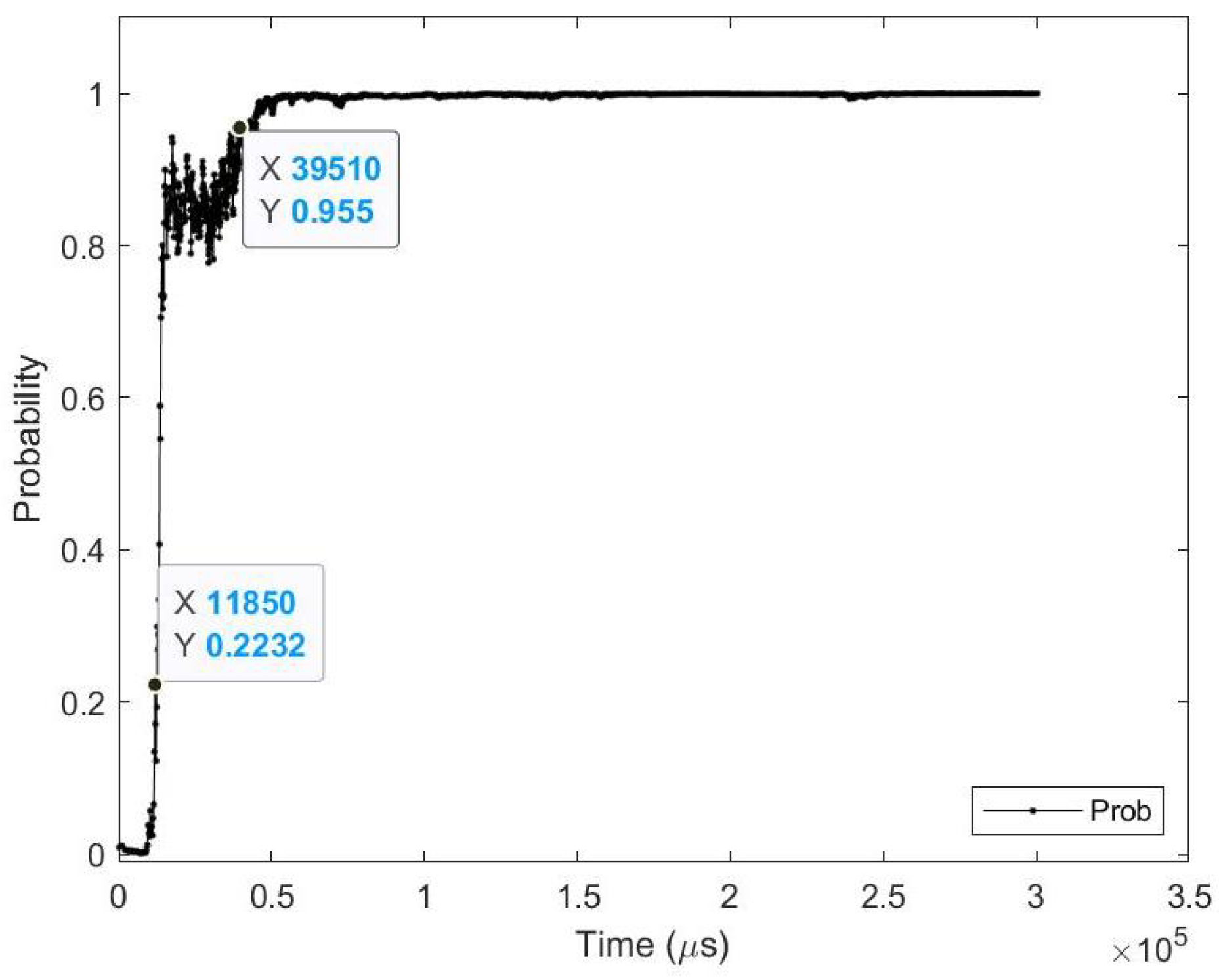
Table 19.
Average results for N-CALTECH101 class (accordion) test image.
Table 19.
Average results for N-CALTECH101 class (accordion) test image.
| Zero_Time | 11.85 (ms) | Zero_Prob | 22.32% |
| Perfect_Time | 39.51 (ms) | Perfect_Prob | 95.50% |
| Zero_Event | 1650 (events) | Perfect_Event | 18,100 (events) |
| Time_Diff | 27.65 (ms) | Time % | 70.00% |
| Event_Diff | 16,450 (events) | Event % | 90.88% |
Table 20.
Average PP results for CeleX-MNIST test images.
Table 20.
Average PP results for CeleX-MNIST test images.
| Zero_Time | 18.17 (ms) | Zero_Prob | 58.45% |
| Perfect_Time | 28.64 (ms) | Perfect_Prob | 81.29% |
| Zero_Event | 104,198 (events) | Perfect_Event | 133,067 (events) |
| Time_Diff | 13.85 (ms) | Time % | 47.35% |
| Event_Diff | 46,368 (events) | Event % | 35.87% |
| Sacc_Diff | 635.24 (ms) | Sacc % | 97.23% |
Table 21.
Average PP results for (3) categories of CeleX-MNIST test images.
Table 21.
Average PP results for (3) categories of CeleX-MNIST test images.
| Class 3 (30 images) |
| Zero_Time | 21.21 (ms) | Zero_Prob | 56.17% |
| Perfect_Time | 25.50 (ms) | Perfect_Prob | 81.07% |
| Zero_Event | 127,317 (events) | Perfect_Event | 141,867 (events) |
| Time_Diff | 8.75 (ms) | Time % | 34.31% |
| Event_Diff | 38,983 (events) | Event % | 27.48% |
| Sacc_Diff | 652.31 (ms) | Sacc % | 96.85% |
| Class 6 (30 images) |
| Zero_Time | 25.95 (ms) | Zero_Prob | 49.57% |
| Perfect_Time | 44.33 (ms) | Perfect_Prob | 85.98% |
| Zero_Event | 106,300 (events) | Perfect_Event | 164,700 (events) |
| Time_Diff | 21.04 (ms) | Time % | 47.47% |
| Event_Diff | 74,933 (events) | Event % | 45.50% |
| Sacc_Diff | 675.63 (ms) | Sacc % | 96.30% |
| Class 9 (30 images) |
| Zero_Time | 4.89 (ms) | Zero_Prob | 66.06% |
| Perfect_Time | 20.62 (ms) | Perfect_Prob | 95.64% |
| Zero_Event | 34,817 (events) | Perfect_Event | 103,483 (events) |
| Time_Diff | 15.73 (ms) | Time % | 76.28% |
| Event_Diff | 68,717 (events) | Event % | 66.40% |
| Sacc_Diff | 591.12 (ms) | Sacc % | 99.18% |
Table 22.
Average PP results for MNIST-DVS test images.
Table 22.
Average PP results for MNIST-DVS test images.
| Zero_Time | 29.85 (ms) | Zero_Prob | 62.87% |
| Perfect_Time | 43.81 (ms) | Perfect_Prob | 79.49% |
| Zero_Event | 998 (events) | Perfect_Event | 1495 (events) |
| Time_Diff | 24.47 (ms) | Time % | 50.46% |
| Event_Diff | 865 (events) | Event % | 51.42% |
| Sacc_Diff | 2366.45 (ms) | Sacc % | 98.76% |
Table 23.
Average PP results for (3) categories of MNIST-DVS test images.
Table 23.
Average PP results for (3) categories of MNIST-DVS test images.
| Class 2 (1000 images) |
| Zero_Time | 76.47 (ms) | Zero_Prob | 44.14% |
| Perfect_Time | 91.50 (ms) | Perfect_Prob | 61.66% |
| Zero_Event | 2308 (events) | Perfect_Event | 2696 (events) |
| Time_Diff | 48.53 (ms) | Time % | 53.04% |
| Event_Diff | 1455 (events) | Event % | 53.99% |
| Sacc_Diff | 2313.96 (ms) | Sacc % | 96.80% |
| Class 4 (1000 images) |
| Zero_Time | 23.18 (ms) | Zero_Prob | 72.23% |
| Perfect_Time | 36.18 (ms) | Perfect_Prob | 91.88% |
| Zero_Event | 610 (events) | Perfect_Event | 961 (events) |
| Time_Diff | 16.44 (ms) | Time % | 45.43% |
| Event_Diff | 438 (events) | Event % | 45.63% |
| Sacc_Diff | 2364.61 (ms) | Sacc % | 99.03% |
| Class 6 (1000 images) |
| Zero_Time | 21.75 (ms) | Zero_Prob | 59.56% |
| Perfect_Time | 34.78 (ms) | Perfect_Prob | 75.12% |
| Zero_Event | 547 (events) | Perfect_Event | 896 (events) |
| Time_Diff | 20.09 (ms) | Time % | 57.76% |
| Event_Diff | 527 (events) | Event % | 58.85% |
| Sacc_Diff | 2364.90 (ms) | Sacc % | 99.09% |
Table 24.
Average PP results for FLASH-MNIST test images.
Table 24.
Average PP results for FLASH-MNIST test images.
| Zero_Time | 335.37 (ms) | Zero_Prob | 72.52% |
| Perfect_Time | 338.37 (ms) | Perfect_Prob | 97.33% |
| Zero_Event | 3460 (events) | Perfect_Event | 3820 (events) |
| Time_Diff | 5.73 (ms) | Time % | 1.51% |
| Event_Diff | 391 (events) | Event % | 9.33% |
| Sacc_Diff | 83.86 (ms) | Sacc % | 19.94% |
Table 25.
Average PP results for (3) categories of FLASH-MNIST test images.
Table 25.
Average PP results for (3) categories of FLASH-MNIST test images.
| Class 0 (980 images) |
| Zero_Time | 371.17 (ms) | Zero_Prob | 61.54% |
| Perfect_Time | 374.80 (ms) | Perfect_Prob | 97.49% |
| Zero_Event | 4862 (events) | Perfect_Event | 5516 (events) |
| Time_Diff | 3.63 (ms) | Time % | 0.97% |
| Event_Diff | 654 (events) | Event % | 11.85% |
| Sacc_Diff | 51.60 (ms) | Sacc % | 12.20% |
| Class 3 (1010 images) |
| Zero_Time | 366.30 (ms) | Zero_Prob | 69.26% |
| Perfect_Time | 371.96 (ms) | Perfect_Prob | 97.55% |
| Zero_Event | 4723 (events) | Perfect_Event | 5059 (events) |
| Time_Diff | 7.21 (ms) | Time % | 1.94% |
| Event_Diff | 370 (events) | Event % | 7.31% |
| Sacc_Diff | 52.80 (ms) | Sacc % | 12.60% |
| Class 7 (1028 images) |
| Zero_Time | 377.81 (ms) | Zero_Prob | 68.64% |
| Perfect_Time | 384.87 (ms) | Perfect_Prob | 95.39% |
| Zero_Event | 3368 (events) | Perfect_Event | 3991 (events) |
| Time_Diff | 16.79 (ms) | Time % | 4.36% |
| Event_Diff | 718 (events) | Event % | 17.98% |
| Sacc_Diff | 42.62 (ms) | Sacc % | 10.14% |
Table 26.
Average PP results for N-MNIST test images.
Table 26.
Average PP results for N-MNIST test images.
| Zero_Time | 33.33 (ms) | Zero_Prob | 71.49% |
| Perfect_Time | 43.28 (ms) | Perfect_Prob | 96.38% |
| Zero_Event | 383 (events) | Perfect_Event | 592 (events) |
| Time_Diff | 10.79 (ms) | Time % | 22.49% |
| Event_Diff | 218 (events) | Event % | 36.33% |
| Sacc_Diff | 69.11 (ms) | Sacc % | 67.46% |
Table 27.
Average PP results for (3) categories of N-MNIST test images.
Table 27.
Average PP results for (3) categories of N-MNIST test images.
| Class 5 (892 images) |
| Zero_Time | 35.02 (ms) | Zero_Prob | 69.90% |
| Perfect_Time | 47.41 (ms) | Perfect_Prob | 9713% |
| Zero_Event | 476 (events) | Perfect_Event | 765 (events) |
| Time_Diff | 12.92 (ms) | Time % | 27.24% |
| Event_Diff | 298 (events) | Event % | 38.92% |
| Sacc_Diff | 67.59 (ms) | Sacc % | 65.87% |
| Class 8 (974 images) |
| Zero_Time | 49.57 (ms) | Zero_Prob | 71.91% |
| Perfect_Time | 59.69 (ms) | Perfect_Prob | 96.82% |
| Zero_Event | 854 (events) | Perfect_Event | 1077 (events) |
| Time_Diff | 11.47 (ms) | Time % | 19.21% |
| Event_Diff | 239 (events) | Event % | 22.18% |
| Sacc_Diff | 52.91 (ms) | Sacc % | 51.63% |
| Class 9 (1009 images) |
| Zero_Time | 22.55 (ms) | Zero_Prob | 71.26% |
| Perfect_Time | 30.42 (ms) | Perfect_Prob | 98.05% |
| Zero_Event | 117 (events) | Perfect_Event | 236 (events) |
| Time_Diff | 78.65 (ms) | Time % | 25.86% |
| Event_Diff | 119 (events) | Event % | 50.53% |
| Sacc_Diff | 79.99 (ms) | Sacc % | 78.01% |
Table 28.
Dataset recognition results summary.
Table 28.
Dataset recognition results summary.
| | Dataset | Total Average |
|---|
| MNIST | CIFAR 10 | N-CALTECH 101 |
|---|
| CeleX | DVS | FLASH | N | avg |
|---|
| Zero |
| Time (ms) | 36.7 | 235.5 | 336.8 | 32.5 | 160.4 | 89.0 | 26.6 | 126.2 |
| Prob % | 56.2 | 61.7 | 66.8 | 67.1 | 63.0 | 45.0 | 20.5 | 52.9 |
| Event | 153,598 | 7616 | 3518 | 358 | 41,273 | 18,519 | 7701 | 31,885 |
| Perfect |
| Time (ms) | 51.5 | 306.1 | 335.9 | 39.65 | 183.3 | 123.4 | 24.1 | 146.8 |
| Prob % | 78.7 | 87.2 | 96.0 | 96.4 | 89.6 | 58.5 | 45.5 | 77.1 |
| Event | 172,121 | 7616 | 3842 | 516 | 46,024 | 23,507 | 8778 | 36,063 |
| Time |
| Diff (ms) | 14.8 | 108.7 | 5.8 | 7.9 | 34.3 | 82.1 | 12.6 | 38.7 |
| Diff % | 28.8 | 35.5 | 1.7 | 19.9 | 21.5 | 66.5 | 52.2 | 34.1 |
| Event |
| Diff | 32,558 | 3400 | 324 | 167 | 9112 | 14,239 | 6074 | 9460 |
| Diff % | 18.9 | 34.6 | 8.43 | 32.3 | 23.6 | 60.6 | 69.2 | 37.3 |
| Saccade |
| Diff | 613.7 | 2176.4 | 83.9 | 69.6 | 735.9 | - | 73.5 | 603.4 |
| Diff % | 93.9 | 90.2 | 19.9 | 68.2 | 68.1 | - | 73.4 | 69.1 |
Table 29.
Dataset partial pictures recognition results summary.
Table 29.
Dataset partial pictures recognition results summary.
| | Dataset | Average |
|---|
| MNIST |
|---|
| CeleX | DVS | FLASH | N |
|---|
| Zero | | | | | |
| Time (ms) | 18.2 | 29.8 | 335.4 | 33.3 | 104.2 |
| Prob % | 58.5 | 62.9 | 73.5 | 71.5 | 66.6 |
| Event | 104,198 | 998 | 3460 | 383 | 27,260 |
| Perfect | | | | | |
| Time (ms) | 28.6 | 43.8 | 338.4 | 43.3 | 113.5 |
| Prob % | 81.3 | 79.5 | 97.3 | 96.4 | 88.6 |
| Event | 133,067 | 1495 | 3820 | 592 | 34,743 |
| Time | | | | | |
| Diff (ms) | 13.9 | 24.5 | 5.7 | 10.8 | 13.7 |
| Diff % | 47.3 | 50.5 | 1.5 | 22.5 | 30.5 |
| Event | | | | | |
| Diff | 46,368 | 865 | 391 | 218 | 11,960 |
| Diff % | 35.9 | 51.4 | 9.3 | 36.3 | 33.2 |
| Saccade | | | | | |
| Diff | 635.2 | 2366.5 | 85.6 | 69.1 | 789.1 |
| Diff % | 97.2 | 98.8 | 20.4 | 67.5 | 71.0 |
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}