
Eye-Gaze Controlled Wheelchair Based on Deep Learning

Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
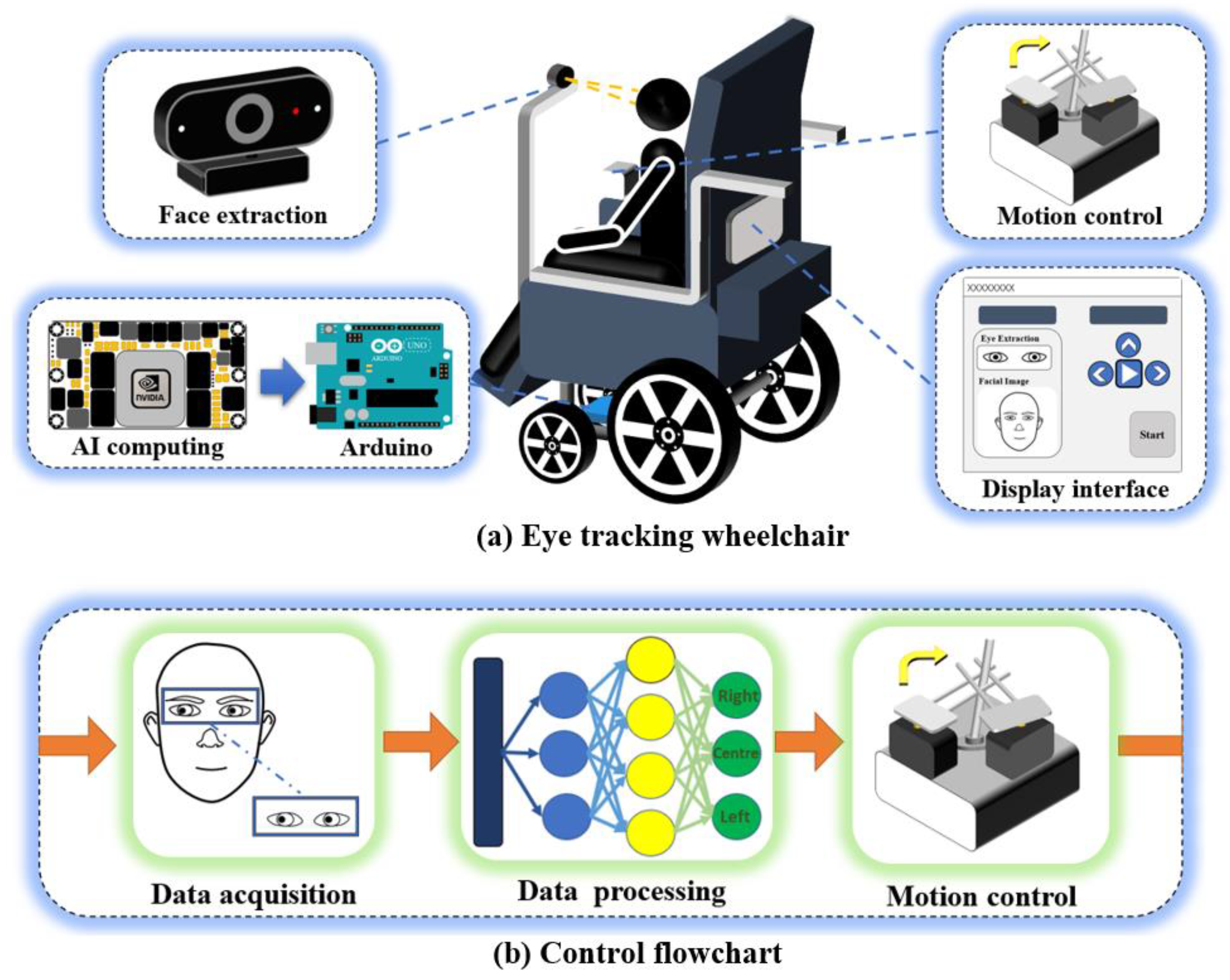
3.1. Eye-Tracking Wheelchair Program
3.2. Dataset Creation
3.2.1. Multidimensional Eye-Tracking Data Acquisition
- (1)
- Virtual scene acquisition
- (2)
- Real scene acquisition
3.2.2. Data Preprocessing
3.2.3. Unification of Datasets
4. Eye-Tracking Model Building
4.1. Eye-Gaze Direction Estimation
4.1.1. Inception Module
4.1.2. ResBlock Module
4.1.3. CBAM Module
4.2. Classification Network
4.2.1. Fully Connected Layer
4.2.2. Cross-Entropy Loss Function
5. The Design of the Eye-Tracking Wheelchair Control System
5.1. Motion Control Optimization
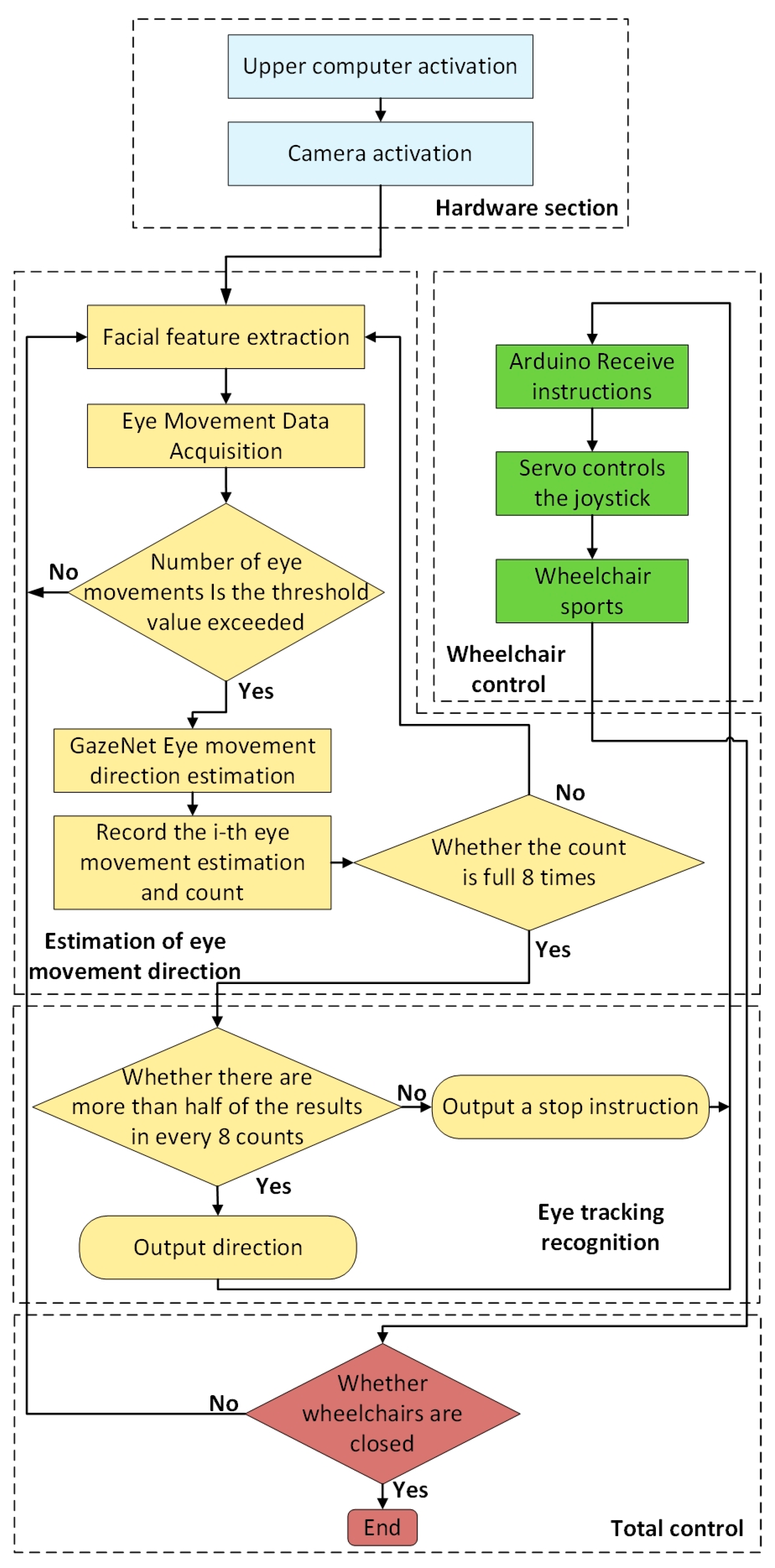
5.2. System Flow
5.2.1. Blink Detection
5.2.2. Saccades Processing
5.2.3. System Flow Chart
6. Experiments and Results Analysis
6.1. Evaluation of GazeNet’s Effectiveness
6.1.1. Hyperparameter Optimization
6.1.2. Assessment Measures and Methods
6.2. Reliability Analysis of Eye-Tracking Wheelchair Control
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Callupe Luna, J.; Martinez Rocha, J.; Monacelli, E.; Foggea, G.; Hirata, Y.; Delaplace, S. WISP, Wearable Inertial Sensor for Online Wheelchair Propulsion Detection. Sensors 2022, 22, 4221. [Google Scholar] [CrossRef] [PubMed]
- Li, Y. Hand gesture recognition using kinect. In Proceedings of the International Conference on Software Engineering and Service Science, Beijing, China, 22–24 June 2012; IEEE Computer Society: Washington, DC, USA, 2011; pp. 196–199. [Google Scholar]
- Adebayo, O.O.; Adetiba, E.; Ajayi, O.T. Hand Gesture Recognition-Based Control of Motorized Wheelchair using Electromyography Sensors and Recurrent Neural Network. In Proceedings of the International Conference on Engineering for Sustainable World (ICESW 2020), Ota, Nigeria, 10–14 August 2020; 1107. [Google Scholar]
- Nasare, R.K.; Yenurkar, G.K. Hand gesture based navigation control for automated wheelchair. Int. J. Latest Trends Eng. Technol. 2016, 8, 230–238. [Google Scholar]
- Ashley, S.; Jaydip, D. Hand Gesture-based Artificial Neural Network Trained Hybrid Human–machine Interface System to Navigate a Powered Wheelchair. J. Bionic Eng. 2021, 18, 1045–1058. [Google Scholar]
- Iskanderani, A.I.; Tamim, F.R.; Rana, M.M.; Ahmed, W.; Mehedi, I.M.; Aljohani, A.J.; Latif, A.; Shaikh, S.A.; Shorfuzzaman, M.; Akther, F.; et al. Voice Controlled Artificial Intelligent Smart Wheelchair. In Proceedings of the 2020 8th International Conference on Intelligent and Advanced Systems (ICIAS), Kuching, Malaysia, 13–15 July 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Jayakody, A.; Nawarathna, A.; Wijesinghe, I.; Liyanage, S.; Dissanayake, J. Smart Wheelchair to Facilitate Disabled Individuals. In Proceedings of the 2019 International Conference on Advancements in Computing (ICAC), Malabe, Sri Lanka, 5–7 December 2019; pp. 249–254. [Google Scholar] [CrossRef]
- Karim, A.B.; Haq, A.; Noor, A.; Khan, B.; Hussain, Z. Raspberry Pi Based Voice Controlled Smart Wheelchair. In Proceedings of the 2022 International Conference on Emerging Trends in Smart Technologies (ICETST), Karachi, Pakistan, 23–24 September 2022; pp. 1–5. [Google Scholar]
- Cao, W.; Yu, H.; Wu, X.; Li, S.; Meng, Q.; Chen, C. Voice controlled wheelchair integration rehabilitation training and posture transformation for people with lower limb motor dysfunction. Technol. Health Care Off. J. Eur. Soc. Eng. Med. 2020, 29, 609–614. [Google Scholar] [CrossRef] [PubMed]
- Mokhles, M. Abdulghani et al. Wheelchair Neuro Fuzzy Control and Tracking System Based on Voice Recognition. Sensors 2020, 20, 2872. [Google Scholar]
- Cojocaru, D.; Manta, L.F.; Vladu, I.C.; Dragomir, A.; Mariniuc, A.M. Using an Eye Gaze New Combined Approach to Control a Wheelchair Movement. In Proceedings of the 2019 23rd International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 9–11 October 2019; pp. 626–631. [Google Scholar] [CrossRef]
- Wanluk, N.; Visitsattapongse, S.; Juhong, A.; Pintavirooj, C. Smart wheelchair based on eye tracking. In Proceedings of the 2016 9th Biomedical Engineering International Conference (BMEiCON), Laung Prabang, Laos, 7–9 December 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Luo, W.; Cao, J.; Ishikawa, K.; Ju, D. A Human-Computer Control System Based on Intelligent Recognition of Eye Movements and Its Application in Wheelchair Driving. Multimodal Technol. Interact. 2021, 5, 50. [Google Scholar] [CrossRef]
- Wästlund, E.; Sponseller, K.; Pettersson, O.; Bared, A. Evaluating gaze-driven power wheelchair with navigation support for persons with disabilities. J. Rehabil. Res. Dev. 2015, 52, 815–826. [Google Scholar] [CrossRef]
- Bai, D.; Liu, Z.; Hu, Q.; Yang, J.; Yang, G.; Ni, C.; Yang, D.; Zhou, L. Design of an eye movement-controlled wheelchair using Kalman filter algorithm. In Proceedings of the 2016 IEEE International Conference on Information and Automation (ICIA), Ningbo, China, 1–3 August 2016; IEEE: Piscateville, NJ, USA, 2017. [Google Scholar]
- Gautam, G.; Sumanth, G.; Karthikeyan, K.C.; Sundar, S.; Venkataraman, D. Eye movement based electronic wheel chair for physically challenged persons. Int. J. Sci. Technol. Res. 2014, 3, 206–212. [Google Scholar]
- Antoniou, E.; Bozios, P.; Christou, V.; Tzimourta, K.D.; Kalafatakis, K.; G. Tsipouras, M.; Giannakeas, N.; Tzallas, A.T. EEG-Based Eye Movement Recognition Using Brain–Computer Interface and Random Forests. Sensors 2021, 21, 2339. [Google Scholar] [CrossRef]
- Rao, E.V.K.; Reddy, N.Y.; Greeshma, B.V.S.S.; Reddy, Y.S.S.V. EEG Based Smart Wheelchair For Disabled Persons Using Non-Invasive BCI. In Proceedings of the 2022 International Conference on Computational Intelligence and Sustainable Engineering Solutions (CISES), Greater Noida, India, 20–21 May 2022; pp. 440–446. [Google Scholar] [CrossRef]
- Ngo, B.V.; Nguyen, T.H.; Tran, D.K.; Vo, D.D. Control of a Smart Electric Wheelchair Based on EEG Signal and Graphical User Interface for Disabled People. In Proceedings of the 2021 International Conference on System Science and Engineering (ICSSE), Ho Chi Minh City, Vietnam, 26–28 August 2021; pp. 257–262. [Google Scholar] [CrossRef]
- Joshi, K.; Soni, P.; Joshi, S.; Vyas, A.; Joshi, R. Cognitive-Chair: AI based advanced Brain Sensing Wheelchair for Paraplegic/Quadriplegic people. In Proceedings of the 2022 4th International Conference on Artificial Intelligence and Speech Technology (AIST), Delhi, India, 9–10 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Fadheel, B.A.; Mahdi, A.J.; Jaafar, H.F.; Nazir, M.S.; Obaid, M.S.; Musa, S.H. Speed Control of a Wheelchair Prototype Driven by a DC Motor Through Real EEG Brain Signals. In Proceedings of the 3rd International Conference on Engineering Sciences, Kerbala, Iraq, 4–6 November 2019; 2020; Volume 671, p. 012036. [Google Scholar]
- Ferracuti, F.; Freddi, A.; Iarlori, S.; Longhi, S.; Monteriù, A.; Porcaro, C. Augmenting robot intelligence via EEG signals to avoid trajectory planning mistakes of a smart wheelchair. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 223–235. [Google Scholar] [CrossRef]
- Griss, P.; Enoksson, P.; Tolvanen-Laakso, H.K.; Merilainen, P.; Ollmar, S.; Stemme, G. Micromachined electrodes for biopotential measurements. J. Microelectromechanical Syst. 2001, 10, 10–16. [Google Scholar] [CrossRef]
- Li, X.; Wee, W.G. An efficient method for eye tracking and eye-gazed FOV estimation. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 2597–2600. [Google Scholar] [CrossRef]
- Taher, F.B.; Amor, N.B.; Jallouli, M. A multimodal wheelchair control system based on EEG signals and Eye tracking fusion. In Proceedings of the 2015 International Symposium on Innovations in Intelligent SysTems and Applications (INISTA), Madrid, Spain, 2–4 September 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Çetintaş, D.; Firat, T.T. Eye-Tracking Analysis with Deep Learning Method. In Proceedings of the 2021 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Zallaq, Bahrain, 29–30 September 2021; pp. 512–515. [Google Scholar] [CrossRef]
- Mokatren, M.; Kuflik, T.; Shimshoni, I. 3D Gaze Estimation Using RGB-IR Cameras. Sensors 2023, 23, 381. [Google Scholar] [CrossRef] [PubMed]
- Hu, L.; Gao, J. Research on real-time distance measurement of mobile eye tracking system based on neural network. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1561–1565. [Google Scholar] [CrossRef]
- Dragusin, D.; Baritz, M.I. Development of a System for Correlating Ocular Biosignals to Achieve the Movement of a Wheelchair. In Proceedings of the 2020 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 29–30 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Solea, R.; Margarit, A.; Cernega, D.; Serbencu, A. Head Movement Control of Powered Wheelchair. In Proceedings of the 2019 23rd International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 9–11 October 2019; pp. 632–637. [Google Scholar] [CrossRef]
- Juhong, A.; Treebupachatsakul, T.; Pintavirooj, C. Smart eye-tracking system. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Higa, S.; Yamada, K.; Kamisato, S. Intelligent Eye-Controlled Electric Wheelchair Based on Estimating Visual Intentions Using One-Dimensional Convolutional Neural Network and Long Short-Term Memory. Sensors 2023, 23, 4028. [Google Scholar] [CrossRef] [PubMed]
- Fuhl, W.; Kasneci, G.; Kasneci, E. TEyeD: Over 20 Million Real-World Eye Images with Pupil, Eyelid, and Iris 2D and 3D Segmentations, 2D and 3D Landmarks, 3D Eyeball, Gaze Vector, and Eye Movement Types. In Proceedings of the 2021 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Bari, Italy, 4–8 October 2021; pp. 367–375. [Google Scholar] [CrossRef]
- Fusek, R.; Sojka, E. Iris Center Localization Using Geodesic Distance and CNN. In Proceedings of the 9th Iberian Conference on Pattern Recognition and Image Analysis, IbPRIA 2019, Madrid, Spain, 1–4 July 2019; pp. 76–85. Available online: http://mrl.cs.vsb.cz/eyedataset (accessed on 1 January 2023).
- Constable, P.A.; Bach, M.; Frishman, L.J.; Jeffrey, B.G.; Robson, A.G. ISCEV Standardbfor Clinical Electro-oculography (EOG) 2019. Doc. Ophthalmol. 2019, 113, 205–212. [Google Scholar]
- Robinson, D.A. A Method of Measuring Eye Movement Using a Scleral Search Coil in a Magnetic Field. IEEE Trans. Bio-Med. Electron. 2021, 10, 137–145. [Google Scholar]
- Ohno, T.; Mukawa, N.; Yoshikawa, A. Abstract FreeGaze: A Gaze Tracking System for Everyday Gaze Interaction. In Proceedings of the Eye Tracking Research & Application Symposium, DBLP 2018, Warsaw, Poland, 14–17 June 2018; pp. 125–132. [Google Scholar]
- Coutinho, F.L.; Morimoto, C.H. Augmenting the robustness of cross-ratio gaze tracking methods to head movement. In Symposium on Eye Tracking Research & Applications; ACM: New York, NY, USA, 2019; pp. 59–66. [Google Scholar]
- Cerrolaza, J.J.; Villanueva, A.; Cabeza, R. Taxonomic Study of Polynomial Regressions Applied to the Calibration of Video-Oculographic Systems. In Proceedings of the 2008 Symposium on Eye Tracking Research & Applications (ETRA 2008), Savannah, GA, USA, 26–28 March 2008; pp. 259–266. [Google Scholar]
- Hennessey, C.; Lawrence, P. Improving the accurancy and reliability of remote systemcalibration-free eye-gaze tracking. IEEE Trans Biomed. Eng. 2009, 56, 1891–1900. [Google Scholar] [CrossRef]
- Xu, L.Q.; Machin, D.; Sheppard, P. A Novel Approach to Real-Time Non-Intrusive Gaze Finding. In Proceedings of the BMVC, London, UK, 4–7 September 2017. [Google Scholar]
- Tan, K.; Ahuja, D.J.K.N. Appearance-based Eye Gaze Estimation. In Proceedings of the IEEE Workshop on Applications of Computer Vision, Nashville, TN, USA, 19–25 June 2021; IEEE Computer Society: Washington, DC, USA, 2019. [Google Scholar]
- Jeong, C.; Kim, T. Eye Blink Detection Using Algorithm Based On dlib And OpenCV Library for Game Players In Competitive Environments. J. Int. Res. Med. Pharm. Sci. 2021, 16, 33–45. [Google Scholar]
- Robert, G.; Lucas, C.; Nicholas, L.; Jedediah, M.S.; Alexander, Z. New guidance for using t-SNE: Alternative defaults, hyperparameter selection automation, and comparative evaluation. Vis. Inform. 2022, 6, 87–97. [Google Scholar]
- Sunsuhi, G.S.; Albin Jose, S. An Adaptive Eroded Deep Convolutional neural network for brain image segmentation and classification using Inception ResnetV2. Biomed. Signal Process. Control. 2022, 78, 103863. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, Y.; Li, W.; Fu, W.; Cao, L. DRNet: A Deep Neural Network with Multi-Layer Residual Blocks Improves Image Denoising. IEEE Access 2021, 9, 79936–79946. [Google Scholar] [CrossRef]
- Wang, B.; Yan, X.; Li, D. An End-to-End Lane Detection Model with Attention and Residual Block. Comput. Intell. Neurosci. 2022, 2022, 5852891. [Google Scholar] [CrossRef]
- Ma, R.; Wang, J.; Zhao, W.; Guo, H.; Dai, D.; Yun, Y.; Li, L.; Hao, F.; Bai, J.; Ma, D. Identification of Maize Seed Varieties Using MobileNetV2 with Improved Attention Mechanism CBAM. Agriculture 2022, 13, 11. [Google Scholar] [CrossRef]
- Zhang, T.; Sui, Y.; Wu, S.; Shao, F.; Sun, R. Table Structure Recognition Method Based on Lightweight Network and Channel Attention. Electronics 2023, 12, 673. [Google Scholar] [CrossRef]
- Cao, Y. An Expression Recognition Model Based on Channel and Spatial Attention Fusion. J. Phys. Conf. Ser. 2022, 2363, 012016. [Google Scholar] [CrossRef]
- Imen, J.; Ihsen, A.; Anouar, B.K.; Ali, M.M. Deep learning-based hard spatial attention for driver in-vehicle action monitoring. Expert Syst. Appl. 2023, 219, 119629. [Google Scholar]
- Li, L.; Doroslovacki, M.; Loew, M.H. Approximating the Gradient of Cross-Entropy Loss Function. IEEE Access 2020, 8, 111626–111635. [Google Scholar] [CrossRef]
- Huber Holly, A.; Georgia Senta, K.; Finley Stacey, D. Systematic Bayesian Posterior Analysis Guided by Kullback-Leibler Divergence Facilitates Hypothesis Formation. J. Theor. Biol. 2022, 558, 111341. [Google Scholar] [CrossRef] [PubMed]
- Akihiro, K.; Kazu, N.; Rin, H.; Hideaki, K.; Yoshihisa, N. Eye fatigue estimation using blink detection based on Eye Aspect Ratio Mapping (EARM). Cogn. Robot. 2022, 2, 50–59. [Google Scholar]
- Yovan, L.; Kumar, P.; Singh, P.; Chand, J.; Narayana, U.H.; Sarojam, S.B.D.; Keshava, B. Submarine Groundwater Discharge (SGD): Impacts, challenges, limitations, and management recommendations. Groundw. Sustain. Dev. 2023, 21, 100903. [Google Scholar]
- Ren, S.; Wu, H.; Chen, W.; Li, D. Polarization Domain Spectrum Sensing Algorithm Based on AlexNet. Sensors 2022, 22, 8946. [Google Scholar] [CrossRef]
- Huang, B.; Liu, J.; Zhang, Q.; Liu, K.; Li, K.; Liao, X. Identification and Classification of Aluminum Scrap Grades Based on the Resnet18 Model. Appl. Sci. 2022, 12, 11133. [Google Scholar] [CrossRef]
- Wang, H. Residual Mask Based on MobileNet-V2 for Driver’s Dangerous Behavior Recognition. In Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence, Normal, IL, USA, 6–8 December 2019. [Google Scholar]
- Durrant-Whyte, H.; Bailey, T. Simultaneous Localization and Mapping (SLAM): Part I The Essential Algorithms. IEEE Robot. Autom. Mag. 2019, 2, 206–215. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Parameter Amount |
|---|---|---|
| GazeNet | 98.49% | 125,749 |
| AlexNet | 96.5% | 564,003 |
| ResNet18 | 97.5% | 11,178,051 |
| MobileNet-V2 | 96.9% | 2,227,715 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Huang, Z.; Liu, L.; Li, X.; Wei, K. Eye-Gaze Controlled Wheelchair Based on Deep Learning. Sensors 2023, 23, 6239. https://doi.org/10.3390/s23136239
Xu J, Huang Z, Liu L, Li X, Wei K. Eye-Gaze Controlled Wheelchair Based on Deep Learning. Sensors. 2023; 23(13):6239. https://doi.org/10.3390/s23136239
Chicago/Turabian StyleXu, Jun, Zuning Huang, Liangyuan Liu, Xinghua Li, and Kai Wei. 2023. "Eye-Gaze Controlled Wheelchair Based on Deep Learning" Sensors 23, no. 13: 6239. https://doi.org/10.3390/s23136239