
CNN-LSTM Hybrid Model to Promote Signal Processing of Ultrasonic Guided Lamb Waves for Damage Detection in Metallic Pipelines

Abstract
:1. Introduction
2. Framework of Machine Learning-Enriched CNN-LSTM Method for Damage Detection
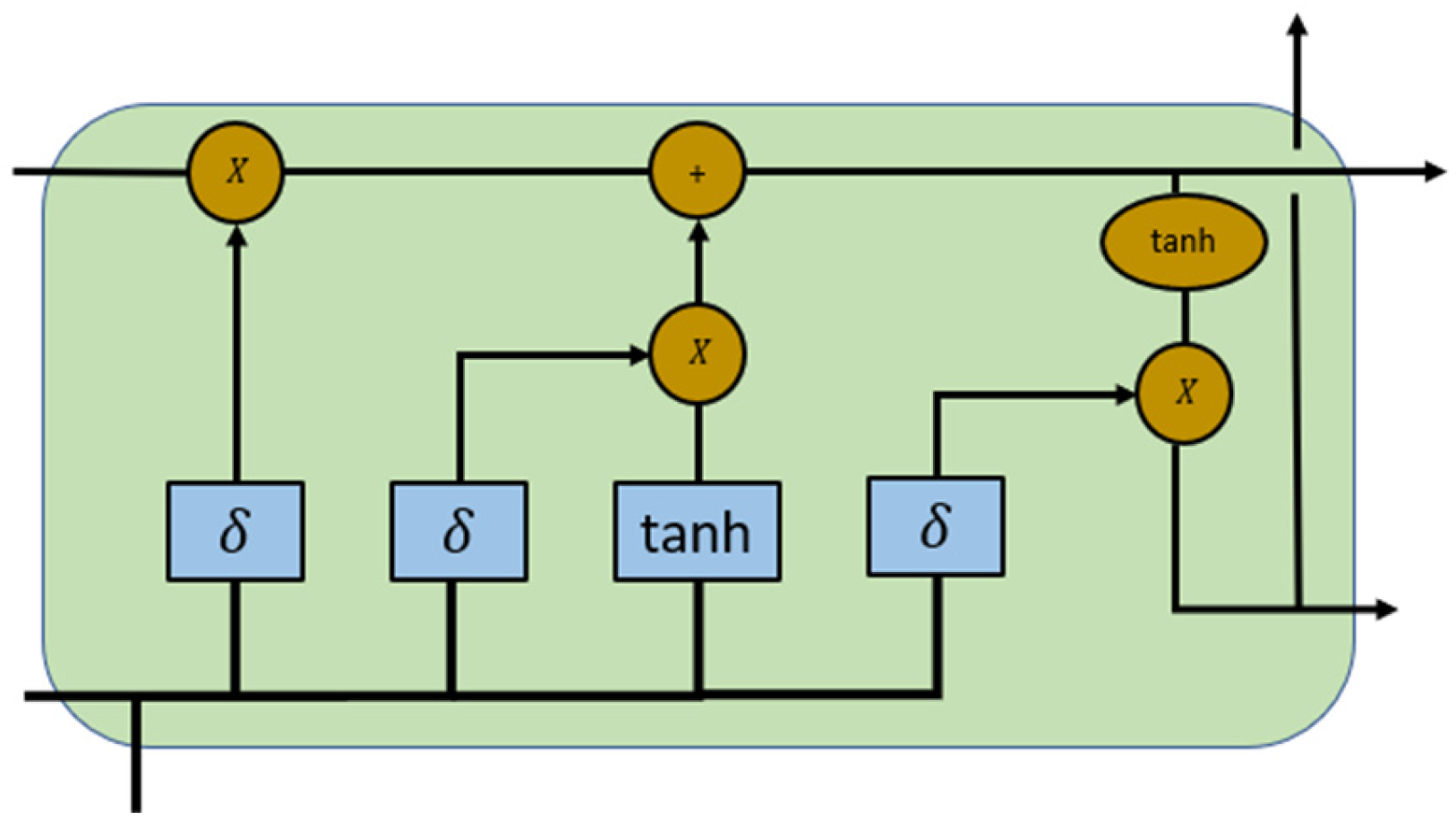
2.1. CNN-LSTM Hybrid Model
2.2. Features Extraction
2.2.1. Definition of Features
2.2.2. Data Dimension Reduction
Principal Component Analysis (PCA)
Kernel Principal Component Analysis (KPCA)
2.3. Evaluation of the Model Performance
2.3.1. Confusion Matrix and Accuracy as Performance Indicators
2.3.2. ROC Curve as Another Performance Indicator
3. Case Study
3.1. Ultrasonic Guided Waves Collected from Embedded Damaged Pipes
3.2. Data Denoiinge Using Wavelet Threshold Denoising
4. Results and Discussion
4.1. Classification Performance of CNN, LSTM, and the CNN-LSTM Model with Twenty-Nine Feature Parameter Series
4.2. Classification Performance of the CNN-LSTM Model with Denoised Data
4.3. Classification Performance of the CNN-LSTM Model with Predetermined Features
4.4. Classification Performance of the CNN-LSTM Model with Data Dimension Reduction
5. Further Discussion of the Effectiveness of the Hybrid Model under Noise Interference
5.1. Introduction of White Gaussian Noise into the Signals
5.2. Classification Performance of the CNN-LSTM Model with White Gaussian Noise Interference
5.3. Comparison of the Classification Performance of the CNN, LSTM, and CNN-LSTM Models
5.4. Detectability of Multiple Defects Using the CNN-LSTM Model
6. Conclusions
- The results revealed that the CNN-LSTM hybrid model exhibited a higher accuracy for decoding signals of ultrasonic guided waves for damage detection, as compared to individual deep learning approaches (CNN and LSTM), particularly under high noise interference.
- The results also confirmed that predetermined features, including time, frequency, and timey-frequency domains, improved the data classification. Interestingly, while it is well known that deep learning approaches could outperform shallow learning ones that often require hand-crafted features and, thus, could provide high capability for data classification through end-to-end manner with fewer physics restraints (“black box”), the election of features with certain physics (“physics-informed” feature extraction) could significantly improve the robustness of deep learning approaches.
- The data reduction (PCA and KPCA) used for the deep learning training/testing networks in this study display no apparent improvement to the data classification. However, with the increased volume of datasets, these methods could improve the efficiency in terms of shortening the computation time.
- The accuracy of the deep learning approaches could be dramatically affected by noise, which could stem from measurement and environment. The CNN-LSTM model still exhibited a high performance when the noise level was relatively low (e.g., SNR = 9 or higher), but the prediction dropped gradually to an unacceptable limit when the noise level in relation to SNR was 6, with the amplitude of the noise level approaching to that of the signals themselves. In comparison, the CNN and LSTM models failed early as expected, when the noise level was much higher.
- Although this study attempted to provide a comparison to understand the effectiveness of the hybrid deep learning model, there are still certain drawbacks that could be improved in the future. The first one is the dataset which was limited to six common defects and may not be able to account for broader applications. The simple case we chose to try to demonstrate the concept may not account for more complicated signal propagation, reflection, and scatters, which could challenge the effectiveness of the proposed method.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, J.W.; Park, S. Magnetic Flux Leakage Sensing and Artificial Neural Network Pattern Recognition-Based Automated Damage Detection and Quantification for Wire Rope Non-Destructive Evaluation. Sensors 2018, 18, 109. [Google Scholar] [CrossRef] [Green Version]
- Ahn, B.; Kim, J.; Choi, B. Artificial Intelligence-Based Machine Learning Considering Flow and Temperature of the Pipeline for Leak Early Detection Using Acoustic Emission. Eng. Fract. Mech. 2019, 210, 381–392. [Google Scholar] [CrossRef]
- Carvalho, A.A.; Rebello, J.M.A.; Sagrilo, L.V.S.; Camerini, C.S.; Miranda, I.V.J. MFL Signals and Artificial Neural Networks Applied to Detection and Classification of Pipe Weld Defects. NDT E Int. 2006, 39, 661–667. [Google Scholar] [CrossRef]
- Feng, J.; Li, F.; Lu, S.; Liu, J.; Ma, D. Injurious or Noninjurious Defect Identification from MFL Images in Pipeline Inspection Using Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2017, 66, 1883–1892. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, B.; Lv, X.; Liu, K. Research on Pipeline Defect Detection Based on Optimized Faster R-Cnn Algorithm. In DEStech Transactions on Computer Science and Engineering; Destech Publications Inc.: Lancaster, PA, USA, 2018; pp. 469–474. [Google Scholar]
- Lu, S.; Feng, J.; Zhang, H.; Liu, J.; Wu, Z. An Estimation Method of Defect Size from MFL Image Using Visual Transformation Convolutional Neural Network. IEEE Trans. Industr. Inform. 2019, 15, 213–224. [Google Scholar] [CrossRef]
- Zhang, C.; Koishida, K. End-to-End Text-Independent Speaker Verification with Triplet Loss on Short Utterances. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Nagraniy, A.; Chungy, J.S.; Zisserman, A. VoxCeleb: A Large-Scale Speaker Identification Dataset. In Proceedings of the Annual Conference of the International Speech Communication Association, Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 2616–2620. [Google Scholar] [CrossRef] [Green Version]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Penn, G. Applying Convolutional Neural Networks Concepts to Hybrid NN-HMM Model for Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4277–4280. [Google Scholar] [CrossRef] [Green Version]
- Variani, E.; Lei, X.; McDermott, E.; Moreno, I.L.; Gonzalez-Dominguez, J. Deep Neural Networks for Small Footprint Text-Dependent Speaker Verification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4052–4056. [Google Scholar] [CrossRef] [Green Version]
- Mohamed, A.R.; Dahl, G.E.; Hinton, G. Acoustic Modeling Using Deep Belief Networks. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 14–22. [Google Scholar] [CrossRef]
- Pan, H.; Zhang, Z.; Cao, Q.; Wang, X.; Lin, Z. Conditional Assessment of Large-Scale Infrastructure Systems Using Deep Learning Approaches (Conference Presentation). In Proceedings of the Smart Structures and NDE for Industry 4.0, Smart Cities, and Energy Systems, Online Only, USA, 27 April–8 May 2020; Volume 11382, p. 113820T. [Google Scholar] [CrossRef]
- Zhang, Z.; Tang, F.; Cao, Q.; Pan, H.; Wang, X.; Buildings, Z.L. Deep Learning-Enriched Stress Level Identification of Pretensioned Rods via Guided Wave Approaches. Buildings 2022, 12, 1772. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, X.; Pan, H.; Lin, Z. Corrosion-Induced Damage Identification in Metallic Structures Using Machine Learning Approaches. In Proceedings of the 2019 Defense TechConnect Innovation Summit, National Harbor, MD, USA, 8–10 October 2019; pp. 7–10. [Google Scholar]
- Zhang, Z.; Pan, H.; Lin, Z. Data-Driven Identification for Early-Age Corrosion-Induced Damage in Metallic Structures. In Proceedings of the Bridge Engineering Institute Conference, Honolulu, HI, USA, 22–25 July 2019. [Google Scholar]
- Zhang, Z.; Pan, H.; Wang, X.; Sensors, Z.L. Deep Learning Empowered Structural Health Monitoring and Damage Diagnostics for Structures with Weldment via Decoding Ultrasonic Guided Wave. Sensors 2022, 22, 5390. [Google Scholar] [CrossRef]
- Gui, G.; Pan, H.; Lin, Z.; Li, Y.; Yuan, Z. Data-Driven Support Vector Machine with Optimization Techniques for Structural Health Monitoring and Damage Detection. KSCE J. Civ. Eng. 2017, 21, 523–534. [Google Scholar] [CrossRef]
- Pan, H.; Azimi, M.; Gui, G.; Yan, F.; Lin, Z. Vibration-Based Support Vector Machine for Structural Health Monitoring. Lect. Notes Civ. Eng. 2018, 5, 167–178. [Google Scholar] [CrossRef]
- Lin, Z. Machine Learning, Data Analytics and Information Fusion for Structural Health Monitoring. In Proceedings of the 2019 International Conference on Artificial Intelligence, Information Processing and Cloud Computing, Kunming, China, 19–21 August 2019. [Google Scholar]
- Lin, Z.; Pan, H.; Wang, X.; Li, M. Data-Driven Structural Diagnosis and Conditional Assessment: From Shallow to Deep Learning. In Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2018; SPIE: Bellingham, WA, USA, 2018. [Google Scholar]
- Pan, H.; Azimi, M.; Yan, F.; Lin, Z. Time-Frequency-Based Data-Driven Structural Diagnosis and Damage Detection for Cable-Stayed Bridges. J. Bridge Eng. 2018, 23, 04018033. [Google Scholar] [CrossRef]
- Zhang, Z.; Pan, H.; Wang, X.; Tang, F.; Lin, Z. Ultrasonic Guided Wave Approaches for Pipeline Damage Diagnosis Based on Deep Learning. In Proceedings of the ASCE Pipelines 2022 Conference, Indianapolis, IN, USA, 29 July–3 August 2022; Volume 29. [Google Scholar]
- Pan, H.; Lin, Z.; Gui, G. Enabling Damage Identification of Structures Using Time Series–Based Feature Extraction Algorithms. J. Aerosp. Eng. 2019, 32, 04019014. [Google Scholar] [CrossRef]
- Zhang, Z.; Pan, H.; Wang, X.; Lin, Z. Machine Learning-Enabled Lamb Wave Approaches for Damage Detection. In Proceedings of the 2021 10th International Conference on Structural Health Monitoring of Intelligent Infrastructure, Porto, Portugal, 30 June–2 July 2021; Volume 30. [Google Scholar]
- Zhang, Z.; Pan, H.; Wang, X.; Lin, Z. Machine Learning-Enriched Lamb Wave Approaches for Automated Damage Detection. Sensors 2020, 20, 1790. [Google Scholar] [CrossRef] [Green Version]
- Pittner, S.; Kamarthi, S.v. Feature Extraction from Wavelet Coefficients for Pattern Recognition Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 83–88. [Google Scholar] [CrossRef]
- Shi, P.; An, S.; Li, P.; Han, D. Signal Feature Extraction Based on Cascaded Multi-Stable Stochastic Resonance Denoising and EMD Method. Measurement 2016, 90, 318–328. [Google Scholar] [CrossRef]
- Zhao, S.; Shi, P.; Han, D. A Novel Mechanical Fault Signal Feature Extraction Method Based on Unsaturated Piecewise Tri-Stable Stochastic Resonance. Measurement 2021, 168, 108374. [Google Scholar] [CrossRef]
- Zhang, W.; Zhou, H.; Bao, X.; Cui, H. Outlet Water Temperature Prediction of Energy Pile Based on Spatial-Temporal Feature Extraction through CNN–LSTM Hybrid Model. Energy 2023, 264, 126190. [Google Scholar] [CrossRef]
- Xu, J.; Sun, X.; Zhang, Z.; Zhao, G.; Lin, J. Understanding and Improving Layer Normalization. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Andhale, Y.; Masurkar, F.; Yelve, N. Localization of Damages in Plain And Riveted Aluminium Specimens Using Lamb Waves. Int. J. Acoust. Vib. 2018, 24, 150–165. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Rani, C.J.; Devarakonda, N. An Effectual Classical Dance Pose Estimation and Classification System Employing Convolution Neural Network–Long Short Term Memory (CNN-LSTM) Network for Video Sequences. Microprocess. Microsyst. 2022, 95, 104651. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Lughi, V. Deep Learning Neural Networks for Short-Term Photovoltaic Power Forecasting. Renew. Energy 2021, 172, 276–288. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutnik, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chen, C. Reliability Assessment Method for Space Rolling Bearing Based on Condition Vibration Feature. Master’s Thesis, Chongqing University, Chongqing, China, 2014. [Google Scholar]
- Kulkarni, A.; Chong, D.; Batarseh, F.A. Foundations of Data Imbalance and Solutions for a Data Democracy. Data Democr. Nexus Artif. Intell. Softw. Dev. Knowl. Eng. 2020, 83–106. [Google Scholar] [CrossRef]
- Akram, N.A.; Isa, D.; Rajkumar, R.; Lee, L.H. Active Incremental Support Vector Machine for Oil and Gas Pipeline Defects Prediction System Using Long Range Ultrasonic Transducers. Ultrasonics 2014, 54, 1534–1544. [Google Scholar] [CrossRef] [PubMed]
- Davoudabadi, M.-J.; Aminghafari, M. A fuzzy-wavelet denoising technique with applications to noise reduction in audio signals. J. Intell. Fuzzy Syst. 2017, 33, 2159–2169. [Google Scholar] [CrossRef]
- Wang, W.; Ruiying, D.; Wenru, Z.; Zhang, B.; Zheng, Y. A Wavelet De-Noising Method for Power Quality Based on an Improved Threshold and Threshold Function. Trans. China Electrotech. Soc. 2019, 34, 409–418. [Google Scholar] [CrossRef]
- Rachman, A.; Zhang, T.; Ratnayake, R.M.C. Applications of Machine Learning in Pipeline Integrity Management: A State-of-the-Art Review. Int. J. Press. Vessel. Pip. 2021, 193, 104471. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimensional Time Domain (with 10 Indicators) | |||
|---|---|---|---|
| Feature Index | Expressions | Features Index | Expressions |
| Mean value | Kurtosis | ||
| Root-mean-square value | variance | ||
| Square-root amplitude | maximum value | ||
| Absolute mean amplitude | minimum value | ||
| Skewness | peak-to-peak value | ||
| Dimensionless time domain (with 6 indicators) | |||
| Waveform Index | peak index | ||
| pulse index | margin index | ||
| kurtosis index | Skewness Index | ||
| Number | Expressions | Number | Expressions |
|---|---|---|---|
| 1 | 8 | ||
| 2 | 9 | ||
| 3 | 10 | ||
| 4 | 11 | ||
| 5 | 12 | ||
| 6 | 13 | ||
| 7 |
| Predicted | |||
|---|---|---|---|
| Negative | Positive | ||
| Actual | Negative | TN | FP |
| Positive | FN | TP | |
| Sample ID | Damage Type | Training Sample | Testing Sample |
|---|---|---|---|
| P-1 | pipe with a small notch located at 1/3 L away from the left side | 240 | 96 |
| P-2 | pipe with a big notch located at 1/3 L away from the left side and a weldment at 2/3 L away from the left side | ||
| P-3 | pipe with a small notch at 1/3 L and a weldment at 2/3 L away from the left side | ||
| P-4 | pipe with a big notch shaped damage | ||
| P-5 | pipe with epoxy coating without damage | ||
| P-6 | pipe with epoxy coating with a weldment at 2/3 L away from the left side. |
| Deep Learning Models | Input | Output (Accuracy) | Training Time (s) |
|---|---|---|---|
| CNN | twenty-nine feature parameter series | 85.4% | 30 |
| LSTM | 86.5% | 37 | |
| CNN-LSTM | 94.8% | 45 |
| Deep Learning Models | Input | Accuracy | AUC |
|---|---|---|---|
| CNN-LSTM | With Original data | 77.1% | 0.770 |
| With Denoised data | 87.5% | 0.855 | |
| With twenty-nine feature parameter series | 94.8% | 0.950 | |
| Twenty-nine feature parameter series with PCA | 93.8% | 0.935 | |
| Twenty-nine feature parameter series with KPCA | 92.7% | 0.930 |
| Input | SNR (dB) | Accuracy | ||
|---|---|---|---|---|
| CNN | LSTM | CNN-LSTM | ||
| Twenty-nine feature parameter series (original signal) | NAN | 85.4% | 86.5% | 94.8% |
| Twenty-nine feature parameter series (noised signals) | 3 | 25.0% | 28.8% | 33.3% |
| 6 | 65.5% | 67.7% | 75.0% | |
| 9 | 76.8% | 78.5% | 83.3% | |
| 12 | 80.0% | 83.0% | 85.4% | |
| 15 | 83.0% | 84.6% | 93.8% | |
| Input | SNR (dB) | AUC | ||
|---|---|---|---|---|
| CNN | LSTM | CNN-LSTM | ||
| Twenty-nine feature parameter series (original signal) | NAN | 0.850 | 0.855 | 0.950 |
| Twenty-nine feature parameter series (noised signals) | 3 | 0.250 | 0.280 | 0.335 |
| 6 | 0.655 | 0.700 | 0.720 | |
| 9 | 0.775 | 0.780 | 0.840 | |
| 12 | 0.800 | 0.830 | 0.855 | |
| 15 | 0.830 | 0.845 | 0.950 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shang, L.; Zhang, Z.; Tang, F.; Cao, Q.; Pan, H.; Lin, Z. CNN-LSTM Hybrid Model to Promote Signal Processing of Ultrasonic Guided Lamb Waves for Damage Detection in Metallic Pipelines. Sensors 2023, 23, 7059. https://doi.org/10.3390/s23167059
Shang L, Zhang Z, Tang F, Cao Q, Pan H, Lin Z. CNN-LSTM Hybrid Model to Promote Signal Processing of Ultrasonic Guided Lamb Waves for Damage Detection in Metallic Pipelines. Sensors. 2023; 23(16):7059. https://doi.org/10.3390/s23167059
Chicago/Turabian StyleShang, Li, Zi Zhang, Fujian Tang, Qi Cao, Hong Pan, and Zhibin Lin. 2023. "CNN-LSTM Hybrid Model to Promote Signal Processing of Ultrasonic Guided Lamb Waves for Damage Detection in Metallic Pipelines" Sensors 23, no. 16: 7059. https://doi.org/10.3390/s23167059