Abstract
This paper proposes a vehicle-parking trajectory planning method that addresses the issues of a long trajectory planning time and difficult training convergence during automatic parking. The process involves two stages: finding a parking space and parking planning. The first stage uses model predictive control (MPC) for trajectory tracking from the initial position of the vehicle to the starting point of the parking operation. The second stage employs the proximal policy optimization (PPO) algorithm to transform the parking behavior into a reinforcement learning process. A four-dimensional reward function is set to evaluate the strategy based on a formal reward, guiding the adjustment of neural network parameters and reducing the exploration of invalid actions. Finally, a simulation environment is built for the parking scene, and a network framework is designed. The proposed method is compared with the deep deterministic policy gradient and double-delay deep deterministic policy gradient algorithms in the same scene. Results confirm that the MPC controller accurately performs trajectory-tracking control with minimal steering wheel angle changes and smooth, continuous movement. The PPO-based reinforcement learning method achieves shorter learning times, totaling only 30% and 37.5% of the deep deterministic policy gradient (DDPG) and twin-delayed deep deterministic policy gradient (TD3), and the number of iterations to reach convergence for the PPO algorithm with the introduction of the four-dimensional evaluation metrics is 75% and 68% shorter compared to the DDPG and TD3 algorithms, respectively. This study demonstrates the effectiveness of the proposed method in addressing a slow convergence and long training times in parking trajectory planning, improving parking timeliness.
1. Introduction
As an important part of intelligent transportation systems, autonomous driving systems can help or even replace the driver to complete the automatic control of a vehicle and achieve automatic parking. An automatic parking system can complete parking without collisions and without a driver steering wheel, which significantly reduces the probability of parking accidents []. Therefore, in recent years, automatic parking systems have become a research hotspot for automotive companies, universities, and R&D units.
The methods used for motion planning in automatic parking can be typically divided into rule-based [] and learning-based methods [,,]. Compared to these methods, deep reinforcement learning has the advantages of a strong solution capability and the ability to explore autonomously; numerous research scholars and institutions have used deep reinforcement learning to solve control problems [,] with excellent results. Although the reinforcement learning algorithm can explore samples autonomously, the contribution of successful samples to the change in neural network weights is easily overburdened because of the random strategy and numerous invalid samples at the early stage of training, resulting in the poor utilization of the samples or even failure to converge [,]. Zhang et al. [] used the artificial-parking control sequence for a fixed position with different heading angles of the starting position of the intelligent body (the terms vehicle, intelligent body, and algorithmic model in this study have the same meaning depending on the context) pretrained to allow the intelligent body to obtain samples with high return values without exploration in the initial stage. Q-Learning, proposed in [], is an incremental dynamic planning method applied to model-free reinforcement learning in Markov domains. It eventually learns the optimal behavior by continuously evaluating specific behaviors in a given state. However, it requires all behaviors to be repeatedly sampled and the action value function to be discrete. Deep Q-Learning (DQN), proposed in [,,], introduces high-dimensional perception into reinforcement learning through deep learning, combining convolutional neural networks with reinforcement learning. DQN can address discrete, low-dimensional action spaces. However, as the dimensionality of the discrete space actions increases, the number of actions grows exponentially and the curse of dimensionality appears. The large number of actions makes it difficult to achieve an effective search and the discretization process can lead to information loss. Reference [] proposed deterministic policy gradient (DPG) algorithms to demonstrate that deterministic gradient algorithms are more effective than stochastic gradient algorithms and prove their existence. Deep deterministic policy gradient (DDPG) algorithms are built on DPG using a depth function to approximate and learn the policy such that it can be applied in a high-dimensional, continuous action space []. The twin-delayed deep deterministic policy gradient (TD3) algorithm further enhances the learning performance of DDPG by improving the stability and convergence speed of the training process []. Bin Zhang [] stored failed and successful exploration experiences separately and set the sampling ratio that varies with the number of training rounds, so that the intelligent body can always learn from the successful samples. The literature [] draws inspiration from the Monte Carlo tree search method in AlphaGo [], generates parking data, and evaluates the data quality with a reward function to filter out low-quality data that may impact the intelligent body during random exploration. Schaul T. [] takes the TD error as the priority of the samples, and utilizes the SumTree data structure to store the samples, which results in a larger contribution to gradient computation. Priority sampling will help ensure that the samples contributing the most to the gradient computation are selected more easily.
Automatic-parking-path planning algorithms continue to experience certain shortcomings. In the training process, it is still necessary to obtain the samples required for learning using intelligence based on the current strategy interacting with the environment, and the quality of the samples influences the strategy update; the two are interdependent, and the algorithm tends to fall into a local optimum. Compared with robots, cars are incomplete systems []. They are laterally and vertically coupled, the parkable space is narrow, and the parking path and control sequence are sparse for a given initial condition. To reduce the learning difficulty, the common means are to fix the starting position training and relax the parking space limit. However, this also leads to the training of the obtained intelligent body compared to the traditional planning method planning ability, which is not strong and cannot meet the practical application of automatic parking requirements.
To further improve the real-time performance of the algorithm, considering that the model predictive control (MPC) method has the feature of being able to meet the demand of multi-constraint control, although it has difficulty guaranteeing an efficient nonlinear system optimization solution operation within the control cycle, this study uses the MPC method to complete the parking-space-finding scenario where lateral control is easy to achieve [,,]. Owing to the use of deep reinforcement learning and data fusion technology, it can accurately predict the vehicle motion state and achieve lateral stability control. Although all the above studies have realized the application of reinforcement learning algorithms in trajectory planning, there remains a major problem in that the output action of the model is discrete, which leads to the nonsmooth motion of the chassis and accelerates damage to the components. To solve this problem, this study applies the PPO algorithm to automatic parking trajectory planning to complete end-to-end reinforcement learning model training [].
In summary, this paper integrates the MPC method and deep reinforcement learning PPO algorithm into two automatic parking processes by segmenting the parking processes, respectively. Moreover, the PPO algorithm network architecture is improved by considering convergence and stability, and the reward function is designed through four dimensions such that the algorithm can be trained to master environment awareness and safe path planning, and can actively avoid additional dangerous obstacles and find safer paths. Finally, a simulation platform is built to train the intelligent body, analyze and evaluate its performance, and verify the effectiveness of the algorithm.
2. Vehicle Model and Environment-Aware Design
2.1. Vehicle Kinematic Model
The kinematic constraints in the parking scenario were constructed based on a kinematic model of the entire vehicle. A kinematic model of the vehicle is displayed in Figure 1.
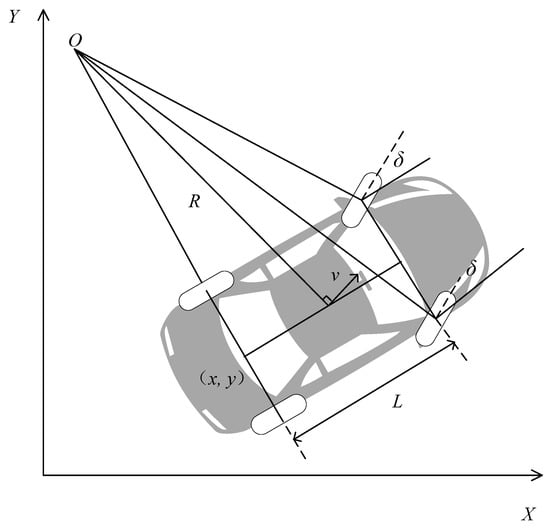
Figure 1.
Vehicle kinematic model.
Taking the midpoint of the rear axle of the vehicle as the reference point for the entire vehicle state, the attitude state vector of the entire vehicle is S = [x, y, φ]T and the expression of the kinematic model of the entire vehicle is
where (x, y) are the coordinates of the rear axle midpoint, φ is the vehicle heading angle, L is the axle distance, v is the rear axle speed, and δ is the front wheel steering angle.
2.2. Environment Perception Design
2.2.1. Self-Position and Velocity Information Perception
Common industrial satellite positioning accuracy can only achieve the meter level and cannot meet the requirements of indoor positioning in a small area [,]. Therefore, a smart parking lot that can provide a priori information regarding the environment was used as the experimental environment in this study, where the a priori information included parking lot vacancies and vehicle location. As the majority of parking lots consist of rectangles or near-rectangles, the actual scenario could be abstracted into the simulation displayed in Figure 2 based on the symmetry of the parking environment. Based on the geometric properties, we circled the training area within a certain range and transformed the coordinate system based on the upper, lower, left, right, and central parts of the working environment simulation diagram.
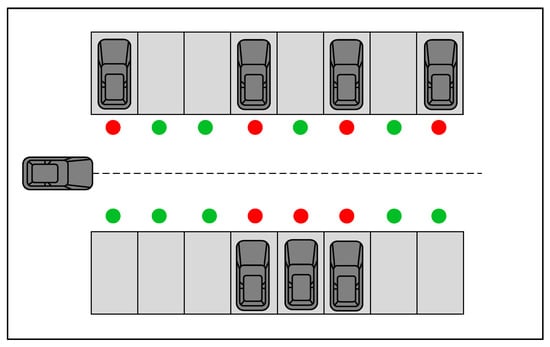
Figure 2.
Parking lot mockup.
To make the training more efficient, one side of the parking area was taken for coordinate transformation, thus completing the training of target parking spaces in the entire parking area. As illustrated in the Figure 3 below, take the lower left of the parking area as the origin, and take the horizontal and vertical axes. The horizontal coordinate remains unchanged, while the vertical coordinate increases the distance of the parking space upwards and the direction angle remains unchanged.The green dot means that the parking space is free, and the red dot means that the parking space is occupied. Region 2 can be obtained from region 1 by coordinate transformation.
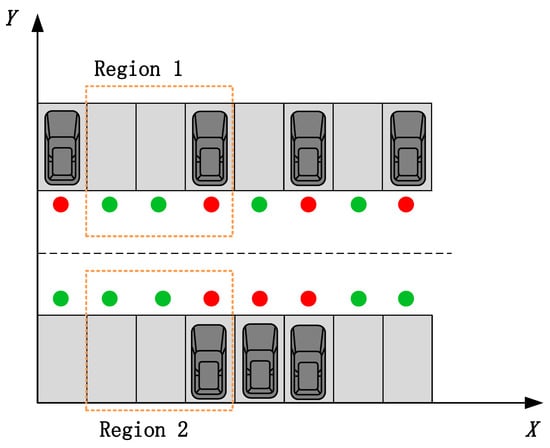
Figure 3.
Coordinate transformation.
The coordinate transformation of the vehicle attitude observation from bottom to top at different parking locations was as follows (units: m):
- Part I: ;
- Part II: ;
- Part III: No change;
- Part IV: .
2.2.2. Obstacle Information Perception
For obstacle sensing, a 16-wire LiDAR and camera were selected as obstacle-sensing sensors. The camera module sensing was part of the “finding a parking space” scenario; the vehicle’s own camera provided dynamic information on the parking space in the sensing field of view to determine whether the parking space was vacant or occupied. The camera test range was 120 ° with a depth of 10 m;Its field of view can be seen by the green area in Figure 4. When moving forward from the car, the camera module senses parking spots that fall within the field of view and determines if the parking spot is vacant. This action is achieved using the geometric relationship between the parking spot position and current vehicle pose. A parking spot is within the field of view if didmax and , where di is the distance to the parking spot and is the angle to the parking spot; the specific coordinates of the parking spot are based on its geometric center.
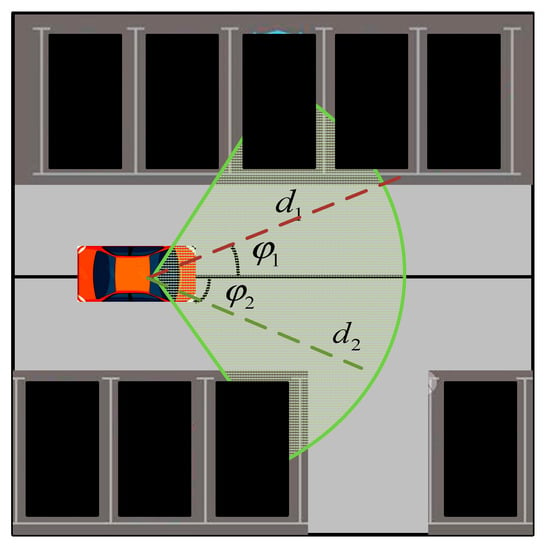
Figure 4.
Camera working scene simulation diagram.
3. Parking Method Framework Design
3.1. Overall Framework Design
In this study, the parking process was divided into two scenarios: finding a parking space and parking in a parking space. In the space-finding scenario, the controlled vehicle used the MPC method to track the planned driving trajectory at the vehicle field end. When the parking space was found and the parking action was executed, that is, in the parking space scenario, the controlled vehicle used the proximal policy optimization reinforcement learning algorithm to complete the parking action by controlling the entire vehicle speed and heading angle based on historical experience and the current environment. If the parking error was overly large or there was a parking safety risk, the training mode was opened in the current environment and the trial and error mechanism was used to complete the parking task in this mode, and the experience was updated as shown in Figure 5 below.
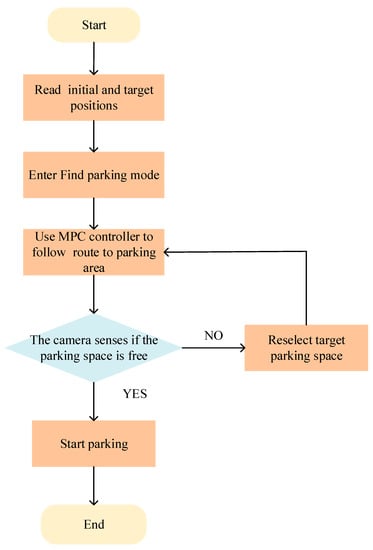
Figure 5.
Parking method flow chart.
In summary, in the case of narrow vertical parking spaces, the MPC and reinforcement learning controllers in this model were placed in the enabled subsystem blocks, which were activated with signals representing whether the vehicle had to search for an empty space or perform a parking action. The enabled signal was determined using the camera algorithm in the vehicle-mode subsystem. Initially, the vehicle was in the search mode and the MPC controller tracked the reference path. When the camera detected that the target parking space was empty, the parking mode was activated, and the reinforcement learning controller performed the parking action.
3.2. MPC Controller Design
To meet the demand for real-time online optimal control and improve vehicle stability control performance under multiple constraints, the MPC method was extensively applied to the lateral control of the vehicle. The MPC module controller in this study could obtain a priori information regarding the parking lot environment, including empty parking spaces and its own vehicle position. It combined the parking lot environment information and dynamic influencing factors to control the vehicle and select the fastest route to reach an empty parking space at a uniform speed.
From the above, it can be observed that the vehicle kinematic model can be considered as a control system with the input of the entire vehicle control vector u = [v, δ]T and the state quantity x(x, y, φ) for a given reference trajectory, which can be described with the motion trajectory of the reference vehicle, each point on which satisfies the above kinematic equations, where r represents the reference quantity in the general form of
where .
The linearized unmanned error model was obtained by applying a Taylor series expansion to Equation (2) at the reference trajectory point, neglecting the high-level term and subtracting it from the general form. To be able to apply the model to the design of the model predictive controller, the results were discretized; the results are represented as Equation (3):
where , , and T is the sampling period.
In the objective function, the solved variables were the control increments in the control time domain; the constraints could only be in the form of control increments or control increments multiplied by the transformation matrix. Therefore, the objective function was transformed into a standard quadratic form and combined with the constraints, as indicated in Equation (4):
where , , and is the tracking error in the predicted time domain.
In each control cycle, to complete the optimal solution of the objective function, we obtained the control input increment in the control time domain and the first element as the actual control input increment to act on the system into the next control cycle, and repeated the above process to achieve the tracking control of the vehicle trajectory.
3.3. PPO-Based Parking Trajectory Planning Process
3.3.1. Reinforcing the Learning Process
With the rise of artificial intelligence, reinforcement learning algorithms are increasingly used in the field of driverless vehicle control. The basic idea is to gain rewards by interacting with the environment and learning by doing so.
The reinforcement learning algorithm consists of several important parts: the intelligent body, environment, state, action, and reward. The learner and decision maker in reinforcement learning are called agents; the remaining parts that interact with the agent are called the environment. In the reinforcement learning process, the agent observes state parameter St in the environment at each time node t and makes a behavioral decision At. When the agent makes a behavioral decision, the state of the environment moves to the next state St+1. Moreover, the environment returns to Rt+1 based on the behavioral decision At makes with the agent in state St. The trajectory sequence of the interaction between the intelligence and environment can be expressed as follows:
As shown in Figure 6 below, reinforcement learning intelligence is unknown to the series of state environment variables during the control and learning process; it learns to update its strategy only with the return value Rt+1 and judges whether it exhibits good or bad behavior. Therefore, this study describes the interaction process between the vehicle model and parking space as a trial-and-error reinforcement learning process. In this study, we propose an intelligent vehicle trajectory planning method based on reinforcement learning PPO, which determines the steering wheel angle when tracking the vehicle by observing the lateral deviation, angular deviation, and path curvature between the intelligent vehicle and parking space. We also propose a multi-model fusion method for vehicle trajectory planning that integrates the vehicle model, road model, and return function into the reinforcement learning environment and interacts with the reinforcement learning subject. The main body of reinforcement learning is based on the actor–critic framework; it constructs the corresponding neural network and updates it with the PPO algorithm to complete the learning of the desired steering wheel angle in the process of tracking the trajectory.
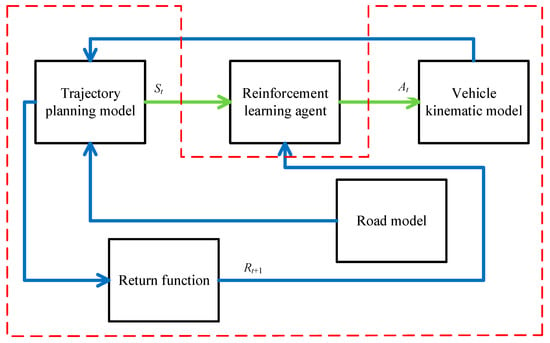
Figure 6.
Reinforcing learning process.
3.3.2. PPO Algorithm
In automatic parking trajectory planning for intelligent vehicles, the reinforcement learning subject agent updates its policy using the PPO algorithm (Algorithm 1), which is based on the policy optimization gradient. It is based on the actor–critic framework and can be applied to a continuous behavior space. PPO aims to make the policy select actions with a greater “advantage”, that is, with a considerably greater cumulative reward than predicted by the evaluator. However, we do not want to update the strategies excessively at once, which would likely cause optimization problems. In fact, if a strategy has high entropy, additional rewards are provided to motivate further exploration.
| Algorithm 1: PPO algorithm to update neural network process |
| 1. Initialize the weight parameters of the policy network (actor) and value function network (critic). Given the discount factor and greedy factor , the initial state of the vehicle is . |
| 2. Do the following for each time step: |
|
|
|
|
| . |
| 3. Repeat Step 2 until convergence or the maximum number of iterations is reached. |
4. Trajectory Planning Model Design
4.1. Action Strategy Actor–Critic Function Design
The actor–critic network structure is a strategy optimization method commonly used in reinforcement learning. It combines a policy network (i.e., a network that selects actions based on the current state) and a value function network (i.e., a network that estimates the value function of the current state), together with a value function network that is trained simultaneously. During training, the actor network selects actions using the current policy and updates them by sampling the rewards obtained to increase the overall reward. The critic network estimates the value function of its long-term reward based on the current state and assists the actor in updating the policy network such that the sampled rewards are more in line with the desired value function. Actor–critic networks such as continuous control and robot control are widely used in different reinforcement learning tasks.
In this section, the reinforcement learning agent training is performed using the proximal policy optimization algorithm actor–critic architecture, the goal of which is to learn policies that maximize the expected value of the cumulative payoff. To facilitate solving for the optimal policy, the merits of a state and action are evaluated using a value function, which corresponds to the actor network, and a strategy function, which corresponds to the critic network; the output of the actor network is the probability of taking each possible steering action when the vehicle is in a particular state; the output of the critic network is the state value function for that particular stance. In this case, the value function is defined as
The policy function is defined as
where γ is the initial learning rate, rt+k+1 is the return at state s when the kth training at moment t takes action a, st = s is the state value at moment t, st is for state s, s ∈ {s1, s2, …} is for the set of all states, at = a is the action value at moment t, at is for action a, a ∈ {a1, a2, …} is for the set of all actions, and V(st+1) is the value function with state s(t+1) and the cumulative return at state st:
The state and action value functions respond to the average expected return value of rounds obtainable from the current state or action, and thus can be used as decision indicators for reinforcement learning.
4.2. Algorithmic Network Framework Design
The PPO is a strategy optimization method that approximates the solution of the KL dispersion and avoids the regulation of different hyperparameters while ensuring convergence and stability. Based on the above strategy definition, the network architecture of the parking-planning model was designed as follows, including the input layer, actor network, and critic network.
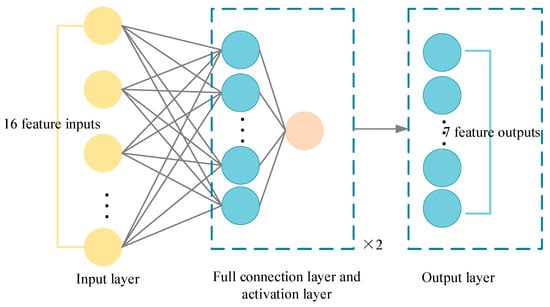
Figure 7.
Schematic diagram of actor network framework.
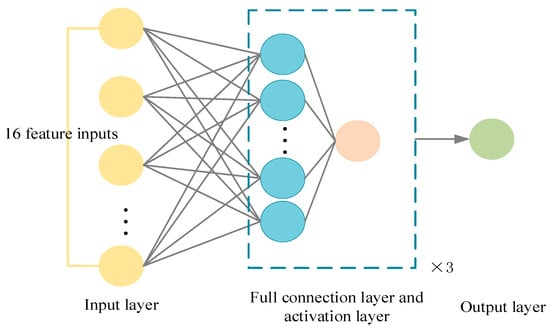
Figure 8.
Schematic diagram of critic network framework.
4.3. Reward Function Design
The reward function is the most critical part of the PPO algorithm and can guide the tuning direction of the deep neural network parameters []. According to the principles of reward value design, they can be classified as sparse, formal, or distributed reward functions. In the field of reinforcement learning, the sparse reward function is one of the most common, where the intelligence returns a positive value when it completes the task and zero when it does not [,,,,]; however, such a reward function is only suitable for solving single-action problems. For complex environments, the time required to complete the task is overly long, and the design of the reward function based on the above-mentioned reward function is prone to sparse reward functions and the invalidation of gradient information, which is not conducive to the learning of the algorithm.
Distributed reward functions originate from the probability theory; it is common practice to design reward functions based on a Gaussian distribution [,,,], which is currently less used. The formal reward function is a reward function that can be applied to a variety of complex environments, where the closer the intelligence is to the target, the larger the reward value obtained is, unlike the sparse reward function. In each state, the intelligent body can obtain the reward value; therefore, the formal reward function is more capable of improving the learning efficiency. According to the above analysis, this study used a formal reward function to design the reward function.
The weight–reward function was designed from the perspective of obstacle avoidance and guidance by considering the relative direction and position of the vehicle, obstacles, and target points in the parking process. In addition, the trajectory reward function was added to the weight–reward function, and a collision-free parking test was conducted using an intelligent vehicle with a combined navigation system for target trajectory acquisition. The powerful learning ability of the PPO algorithm was used for trajectory learning, thus accelerating the convergence of the algorithm and using its reward mechanism to maintain the update amplitude of the control strategy within a reasonable range, reducing the exploration of invalid actions and improving the parking success rate.
For the parking task, the only goal of the intelligent body is to move to the target position, at which time a larger reward should be given to the intelligent body to prevent it from being overshadowed by other partial rewards. To ensure the accuracy of parking, parking is considered complete only when the vehicle moves to the target area and the final positional reward is obtained, including the base reward and the heading-angle deviation reward.
To ensure safe parking and avoid collisions with other obstacles, a collision penalty, , is required. A small yet positive reward value, , is given to the intelligent body when there is no collision to encourage it to explore the unknown area. When the minimum distance d between the body and boundary is less than the safe distance , a corresponding penalty is applied.
In numerous simple tasks (e.g., OpenAI inverted pendulum and mountain bike tasks), with only the above-mentioned mainline reward and collision penalty (sparse reward), intelligence can discover the goal of the task in sufficient explorations. However, parking-path planning is inherently a difficult exploration problem, and even if it is randomly explored one million times, it could possibly not once successfully reach the endpoint; a sparse reward is clearly not applicable. To ensure that the intelligent body receives feedback (dense reward) at all times and guides the intelligent body to move towards the target location, the guidance reward is increased. Distance-based guidance rewards can be considered as follows:
With the two distance-based rewards described above, despite scaling by factor k, the difference between the rewards at longer distances and closer distances can be overly large, causing the intelligence to be excessively “greedy” (spinning in place to gain more) or “reckless” (choosing to collide with obstacles to end the turn so as to not continue receiving negative rewards). Intelligence requires a smoother guidance reward; hence, the guidance reward is set to be calculated from the angle between the center of the vehicle’s rear axle and line connecting the target position and heading angle, with a positive reward for any angle; the smaller the angle (the faster the vehicle approaches the target position), the greater the reward. This enables the intelligent body to learn to not only approach the target position but also think in the long term and avoid choosing a longer detour (to avoid a collision) to reach the reward of the target.
In the reinforcement learning phase, the reward function has a major role in optimizing intelligent-body movements. The reward function was designed to satisfy the safety and stability requirements during the vehicle-parking process. The objective reward function rt is denoted as
where is the error between the position of the self-vehicle and target pose and heading angle ; is the steering angle; indicates whether the vehicle has been parked—when it has been parked, its value is “1”, otherwise its value is “0”; and indicates whether the vehicle has collided with an obstacle at time t—when a collision has occurred, its value is “1”, otherwise its value is “0”.
When training the intelligent body for trajectory planning, to ensure driving smoothness, the section of each trajectory should not be overly short; based on the length of each trajectory section in vertical parking, the control volume should be minimized to change within a 2 s time [] and the value of obtaining a penalty should be no less than the guiding role of trajectory reward, while referring to the setting of trajectory reward; as such, the control volume stability indicator reward can be set as
where denotes the time difference between the current moment and that of the last change in the control volume.
The final reward function is given with the following equation, where , , , and are the reward weights:
Based on the tasks to be accomplished in the vehicle-parking process and the design of the above reward function, it is necessary to define the design principles for the reward function; this study used the weight vector to design the overall reward function R, as in Equation (15).
The guidance reward function determines the motion direction of the vehicle parking to a certain extent and aims to guide the vehicle into the parking space successfully. If the guidance reward function requires an excessive weight, it can cause the trajectory deviation and corner increment to become larger. Therefore, the guidance reward function in this study uses the smallest weight. In the parking process, the purpose of the obstacle-avoidance reward function designed in this study is to avoid collisions; therefore, the obstacle-avoidance reward function is the reward function that must be used as a priority in the overall reward function; hence, it uses the greatest overall weight.
The target-reward function designed in this study enables the vehicle to reach the target location faster during the learning process, which is a critical part of the overall reward function. During vehicle operation, no collisions are necessary; therefore, the target-reward function weight is smaller than the obstacle-avoidance reward function weight.
In summary, the final overall reward function R in this study was designed as Equation (16):
5. Discussion
5.1. Simulation Design and Validation
Evaluation Index and Scenario Design for Algorithm Training
Considering the high cost of training a model directly in a real environment, a simulation environment was built to train the model. The simulation environment in this study was based on a simulator to build a vehicle model and an environment perception model. The effects on the simulation environment after the model was built are displayed in Figure 9.
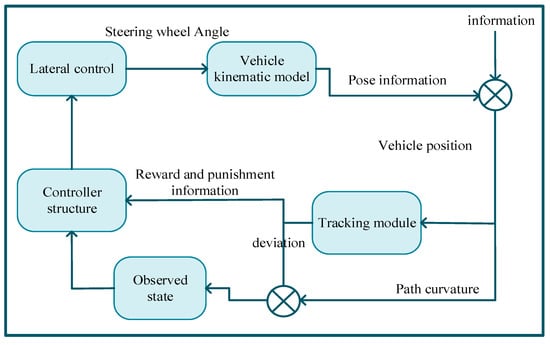
Figure 9.
Schematic diagram of simulation framework.
In this study, a joint MATLAB/Simulink simulation environment is used, and based on the above simulation environment, two types of training scenarios are set up, containing different obstacle distributions and destination areas. When the trajectory-tracking controller finds a free parking space, the trajectory planning controller assumes control and executes the pretrained parking operation. In this part, the intelligent body must preset the conditions. First, because of the symmetry of the parking lot, the lot can be abstracted as a smaller area adjacent to the left and right; here, it is taken as 22.5 m × 20 m, and the target point of parking is its horizontal center. Secondly, the vehicle sensing information is provided by the LiDAR, which uses its radial line segment along the center to determine the proximity of the self-car to other vehicles; the maximum distance is 6 m. Thirdly, the success criterion of the parking behavior is if the error between the center point of the self-car and target center is less than ±0.75 m and ±10°. Finally, the parking scene exit mark has three cases: beyond the training range, collision with an obstacle, and successful parking.
In this paper, the interaction process between the vehicle model and the target parking space is described as a trial-and-error reinforcement learning process, which utilizes a depth function to approximate and learn the policy, which is needed to be able to be applied in a high-dimensional, continuous action space. Among the various deep learning methods, the DDPG method can be used for introductory continuous action space DRL algorithms to successfully train working policies on continuous action space tasks. The TD3 algorithm, as an optimized version of the DDPG algorithm, is also a deep reinforcement learning algorithm based on the AC architecture for continuous action space. The above two, as deep reinforcement learning algorithms commonly used for training continuous action space, are used as a control group for the research method and thus to verify the superiority of this research method.
5.2. Analysis of Algorithm Training Results
Based on the above training scenarios, the following training strategies were set:
- The number of training rounds was set to 200, and the model parameters were updated every 40 steps; if the round ended, the model was updated and the environment was reinitialized to start the next round of training.
- If the moving platform collided, went beyond the driving range, or reached the destination, the reward was returned, the model parameters were updated, and the initial environment was reinitialized to begin the next round of training.
To compare the effect of the proposed algorithm on parking, models based on the proposed algorithm and models based on the TD3 and DDPG algorithms were trained in this study. The training results are displayed in Figure 10.
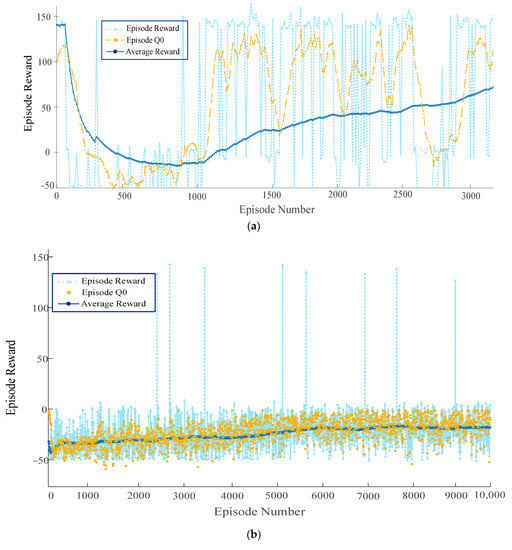
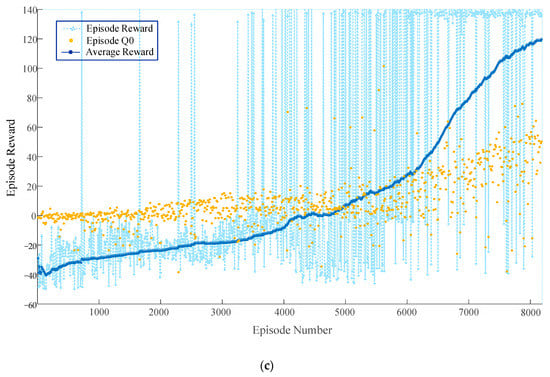
Figure 10.
Overall training results. (a) Episode reward for rlAutoParkingValet with PPOAgent; (b) episode reward for rlAutoParkingValet with DDPGAgent; (c) episode reward for rlAutoParkingValet with TD3Agent.
From the above figure, it can be seen that the training model based on the PPO algorithm successfully parked in the target parking space for the first time in 400 learning sessions, and the first parking success for the DDPG model and the TD3 model were the 2500th and 800th sessions, respectively. Meanwhile, it can be observed that the training models based on the DDPG and TD3 algorithms could not converge after 10,000 rounds of training, whereas the model based on the algorithm proposed in this study achieved convergence after nearly 2500 rounds of training. The training results indicate that the convergence speed of the model based on the proposed algorithm was significantly improved. When the number of training rounds reaches 1000, it can be observed that the fluctuation range of the average reward value of the improved PPO algorithm was significantly better than that of the traditional deep reinforcement learning algorithm, indicating that the effective exploration of the vehicle allows increasingly more empirical data to be obtained under the effect of the improved PPO algorithm. When the number of rounds reached 1500, the average reward value of the improved PPO algorithm indicated a significant increase, whereas the average reward value of the traditional algorithm remained near zero, and there was no significant increase, indicating that the vehicle did not learn a better control strategy. When the number of training rounds reached approximately 2500, the average reward value of the improved algorithm leveled off and remained at approximately 150, indicating that the vehicle had learned the desired control strategy. The convergence and generalization ability of the improved algorithm is studied through examples. Our simulation results indicate that the intelligences trained using the improved algorithms of MPC and PPO have a stronger planning and generalization power as well as larger parkable areas, compared with the traditional deep reinforcement learning methods.
It should also be noted that, owing to the introduction of the four-dimensional reward function evaluation, the reward was accumulated based on the number of steps; hence, the reward continued to fluctuate after the model converged; however, overall, it did not influence its task of reaching the destination. The model could search for an effective path to a destination and complete the parking task after autonomous learning. The paths learned by the model in the training scenario are displayed in Figure 11.
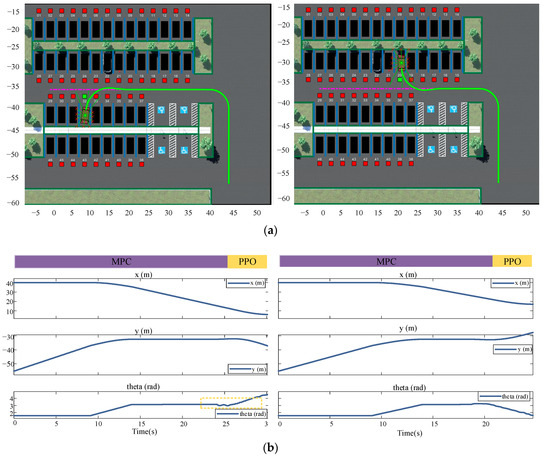
Figure 11.
Training-acquired path results and corresponding vehicle position information. (a) Parking paths are for spaces No. 32 and No. 20; (b) car position information is for parking spaces No. 32 and No. 20.
Figure 11 displays the trajectory display of the vehicle performing auto-parking when the vehicle is in target-free parking spaces Nos. 32 and 20. The solid green line is the trajectory of the vehicle center coordinates; the coordinate axes of the map are the Cartesian coordinate system used to mark the vehicle position after the abstraction of the parking environment. The coordinate values are displayed in positive and negative coordinates to reduce the training range using the parking lot coordinate conversion. To verify the generality of the parking-planning algorithm obtained from the training in this study, the location of the target parking space in the environment was changed and the starting position was fixed in the lower right corner of the environment. The code was used to control the generation of the target point location; the moving path was obtained as indicated in Figure 11. It can be observed from the figure that the vehicle continued to effectively avoid obstacles after changing the environment. The articulation curve of the two scenes marked by the dashed box in the figure is smooth, with a change amplitude of less than 0.1 rad and jitter is not apparent, which means that the vehicle did not have abrupt articulation nodes from the finding-parking-space link to the parking-space link in the entire process, and demonstrated acceptable comfort. Meanwhile, the trajectory planning examples for other target parking spaces in Figure 12 show that this research method can successfully complete parking operations in different environments and has strong generalization.
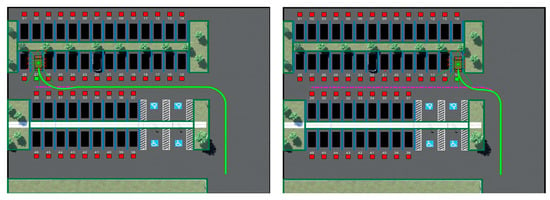
Figure 12.
Examples of other target parking trajectories.
In summary, this section verified the feasibility of the MPC method using the PPO algorithm for vehicle-parking-path planning. After reconstructing the neural network structure of the PPO algorithm and simulating the parking lot parking environment using simulation software, the MPC and PPO fusion algorithm proposed in this paper and the reinforcement learning algorithm established in the traditional manner were trained in this environment; the results confirm that the method proposed in this paper can make the neural network converge faster and also have a high success rate. The algorithm proposed in this paper can be effectively used in parking-path planning, and its training results have a certain degree of generality, such that when the parking environment changes, the trained neural network can continue to be used for path planning.
6. Conclusions
To solve the problems of an excessively long trajectory planning practice and slow training convergence in automatic parking, a parking trajectory planning model based on the PPO algorithm was proposed in this paper for the vehicle automatic parking scenario. Model training and real-world testing were completed with the following main conclusions.
- The model prediction method was combined with the PPO algorithm to make it more adaptable to parking environments. To solve the problems of traditional trajectory planning algorithms with poor-quality generated paths and sharper points at node connections, this study split the entire parking process into two scenarios: finding a parking space and parking planning, and merged the endpoint of trajectory tracking and the starting point of parking, which effectively improved the smoothness of the paths.
- A reward function evaluation method based on four-dimensional indicators was designed and a smoothing bias strategy was added such that the intelligent body could learn to approach the target location yet avoid choosing a long detour to reach the reward of the target. This method can substantially accelerate training. The results confirmed that the PPO algorithm with the introduction of four-dimensional evaluation metrics converged in 2500 training cycles, which is 75% and 68% less than the training times of the DDPG and TD3 algorithms, respectively. And the PPO-based reinforcement learning method achieved shorter learning times, totaling only 30% and 37.5% of DDPG and TD3, respectively.
- To verify the path planning and motion control, a vehicle kinematic model was established based on the Ackermann steering principle and tested in a simulation environment. The test results demonstrated that the model could effectively avoid obstacles and reach the destination under different target positions, thus verifying its effectiveness and acceptable adaptability to the environment. The parking path was smooth without breakpoints, ensuring the comfort of the automatic parking process.
In summary, this study conducted research on automatic parking technology and completed the design and improvement of path planning and motion control algorithms for the characteristics of the parking environment. The fusion of the MPC method and proximal policy optimization algorithm into the automatic parking scenario can significantly improve the planning efficiency of the parking trajectory and generate a smooth route. The results of this study further demonstrate that the method can improve the comprehensive driving performance and timeliness of automatic parking technology in terms of motion planning and control. However, the deep reinforcement learning algorithm designed in this study is applicable only to parking environments without interference. In a daily parking environment, moving objects such as pedestrians and vehicles can cause interference in the parking motion; therefore, subsequent research should focus on the dynamic obstacle-avoidance function.
Author Contributions
Conceptualization, J.S. and C.P.; Data curation, L.C.; Formal analysis, J.G.; Methodology, C.P.; Software, K.L.; Validation, K.L.; Writing—original draft, K.L. and L.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by The National Key Research and Development Program of China (grant number: No. 2022YFE0101000) and Chongqing Postdoctoral Research Special Funding Project (No. 2022CQBSHTB2010), and partially supported by school-level research projects (grant number: 22XJZXZD05).
Institutional Review Board Statement
Ethical review and approval were waived for this study because our study relied on simulation, not experiments that affect the human body or stimulate trauma.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the first author.
Acknowledgments
We would like to thank the researchers at the CQUPT (Chongqing University of Posts and Telecommunications, China) for their constructive suggestions during the planning and development of this research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yue, Z.; Cassandras, C.G. Decentralized optimal control of connected automated vehicles at signal-free intersections including comfort-constrained turns and safety guarantees. Automatica 2019, 109, 108563. [Google Scholar]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Pendleton, S.D.; Andersen, H.; Dux, X.; Shen, X.; Meghjani, M.; Eng, Y.H.; Rus, D.; Ang, M.H., Jr. Perception, planning, control, and coordination for autonomous vehicles. Machines 2017, 5, 6. [Google Scholar] [CrossRef]
- Claussmann, L.; Revilloud, M.; Gruyer, D.; Glaser, S. A review of motion planning for highway autonomous driving. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1826–1848. [Google Scholar] [CrossRef]
- Schwarting, W.; Alonso-Mora, J.; Rus, D. Planning and decision-making for autonomous vehicles. Annu. Rev. Control Robot. Auton. Syst. 2018, 1, 187–210. [Google Scholar] [CrossRef]
- Sung, I.; Choi, B.; Nielsen, P. On the training of a neural network for online path planning with offline path planning algorithms. Int. J. Inf. Manag. 2021, 57, 102142. [Google Scholar] [CrossRef]
- Chakraborty, N.; Mondal, A.; Mondal, S. Intelligent charge scheduling and eco-routing mechanism for electric vehicles: A multi-objective heuristic approach. Sustain. Cities Soc. 2021, 69, 102820. [Google Scholar] [CrossRef]
- Ngo, T.G.; Dao, T.K.; Thandapani, J.; Nguyen, T.T.; Pham, D.T.; Vu, V.D. Analysis Urban Traffic Vehicle Routing Based on Dijkstra Algorithm Optimization. In Communication and Intelligent Systems; Springer: Singapore, 2021; pp. 69–79. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. A brief survey of deep reinforcement learning. arXiv 2017, arXiv:1708.05866. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Zhang, P.; Xiong, L.; Yu, Z.; Fang, P.; Yan, S.; Yao, J.; Zhou, Y. Reinforcement learning-based end-to-end parking for automatic parking system. Sensors 2019, 19, 3996. [Google Scholar] [CrossRef]
- Thunyapoo, B.; Ratchadakorntham, C.; Siricharoen, P.; Susutti, W. Self-Parking car simulation using reinforcement learning approach for moderate complexity parking scenario. In Proceedings of the 2020 17th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Phuket, Thailand, 24–27 June 2020; pp. 576–579. [Google Scholar]
- Bejar, E.; Morn, A. Reverse parking a car-like mobile robot with deep reinforcement learning and preview control. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 0377–0383. [Google Scholar]
- Du, Z.; Miao, Q.; Zong, C. Trajectory planning for automated parking systems using deep reinforcement learning. Int. J. Automot. Technol. 2020, 21, 881–887. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Miculescu, D.; Karaman, S. Polling-systems-based Autonomous Vehicle Coordination in Traffic Intersections with No Traffic Signals. IEEE Trans. Autom. Control 2016, 65, 680–694. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Gupta, A.; Anpalagan, A.; Guan, L.; Khwaja, A.S. Deep Learning for Object Detection and Scene Perception in Self-Driving Cars: Survey, Challenges, and Open Issues. Array 2021, 10, 100057. [Google Scholar] [CrossRef]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 41–48. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2016, arXiv:1509.02971. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 18, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wu, J.; Shen, X.; Li, Y. Autonomous land vehicle path planning algorithm based on improved heuristic function of A-Star. Int. J. Adv. Robot. Syst. 2021, 18, 17298814211042730. [Google Scholar] [CrossRef]
- Boroujeni, Z.; Goehring, D.; Ulbrich, F.; Neumann, D.; Rojas, R. Flexible unit A-star trajectory planning for autonomous vehicles on structured road maps. In Proceedings of the 2017 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Vienna, Austria, 27–28 June 2017; pp. 7–12. [Google Scholar]
- Gurenko, B.V.; Vasileva, M.A. Intelligent system of mooring planning, based on deep q-learning. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Springer: Cham, Switzerland, 2021; pp. 369–378. [Google Scholar]
- Wu, Z.; Sun, L.; Zhan, W.; Yang, C.; Tomizuka, M. Efficient sampling-based maximum entropy inverse reinforcement learning with application to autonomous driving. IEEE Robot. Autom. Lett. 2020, 5, 5355–5362. [Google Scholar] [CrossRef]
- Jin, X.; Yan, Z.; Yin, G.; Li, S.; Wei, C. An adaptive motion planning technique for on-road autonomous driving. IEEE Access 2020, 9, 2655–2664. [Google Scholar] [CrossRef]
- Shi, Y.; Li, Q.; Bu, S.; Yang, J.; Zhu, L. Research on intelligent vehicle path planning based on rapidly-exploring random tree. Math. Probl. Eng. 2020, 2020, 5910503. [Google Scholar] [CrossRef]
- Jiang, C.; Hu, Z.; Mourelatos, Z.P.; Gorsich, D.; Jayakumar, P.; Fu, Y.; Majcher, M. R2-RRT*: Reliability-based robust mission planning of offroad autonomous ground vehicle under uncertain terrain environment. IEEE Trans. Autom. Sci. Eng. 2021, 19, 1030–1046. [Google Scholar] [CrossRef]
- Ayawli, B.B.K.; Chellali, R.; Appiah, A.Y.; Kyeremeh, F. An overview of nature-inspired, conventional, and hybrid methods of autonomous vehicle path planning. J. Adv. Transp. 2018, 2018, 8269698. [Google Scholar] [CrossRef]
- Sharma, O.; Sahoo, N.C.; Puhan, N.B. Recent advances in motion and behavior planning techniques for software architecture of autonomous vehicles: A state-of-the-art survey. Eng. Appl. Artif. Intell. 2021, 101, 104211. [Google Scholar] [CrossRef]
- Hao, Y.; Almutairi, F.; Rakha, H. Eco-driving at signalized intersections: A multiple signal optimization approach. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2943–2955. [Google Scholar]
- Qiangqiang, G.; Li, L.; Xuegang, B. Urban traffic signal control with connected and automated vehicles: A survey. Transp. Res. Part C Emerg. Technol. 2019, 101, 313–334. [Google Scholar]
- Xiao, L.; Wang, M.; Schakel, W.; van Arem, B. Unravelling effects of cooperative adaptive cruise control deactivation on traffic flow characteristics at merging bottlenecks. Transp. Res. Part C Emerg. Technol. 2018, 96, 380–397. [Google Scholar] [CrossRef]
- Liao, X.; Wang, Z.; Zhao, X.; Han, K.; Tiwari, P.; Barth, M.J.; Wu, G. Cooperative ramp merging design and field implementation: A digital twin approach based on vehicle-to-cloud communication. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4490–4500. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).