
Towards Feasible Solutions for Load Monitoring in Quebec Residences †

 , , , and
, , , and 
Abstract
:1. Introduction
Motivation
2. Fundamentals of NILM Concept
2.1. Mathematical Methods
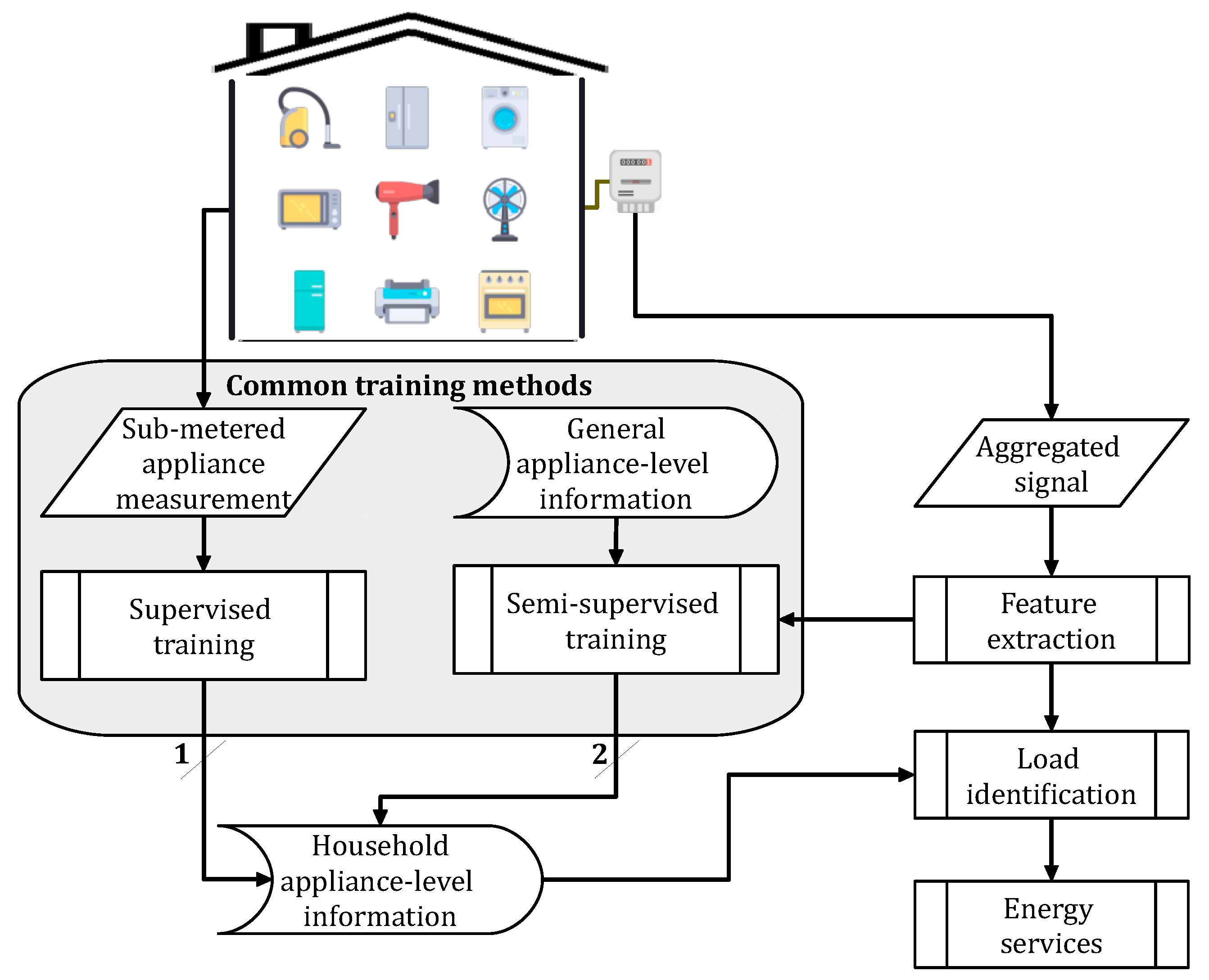
2.2. Learning Procedures
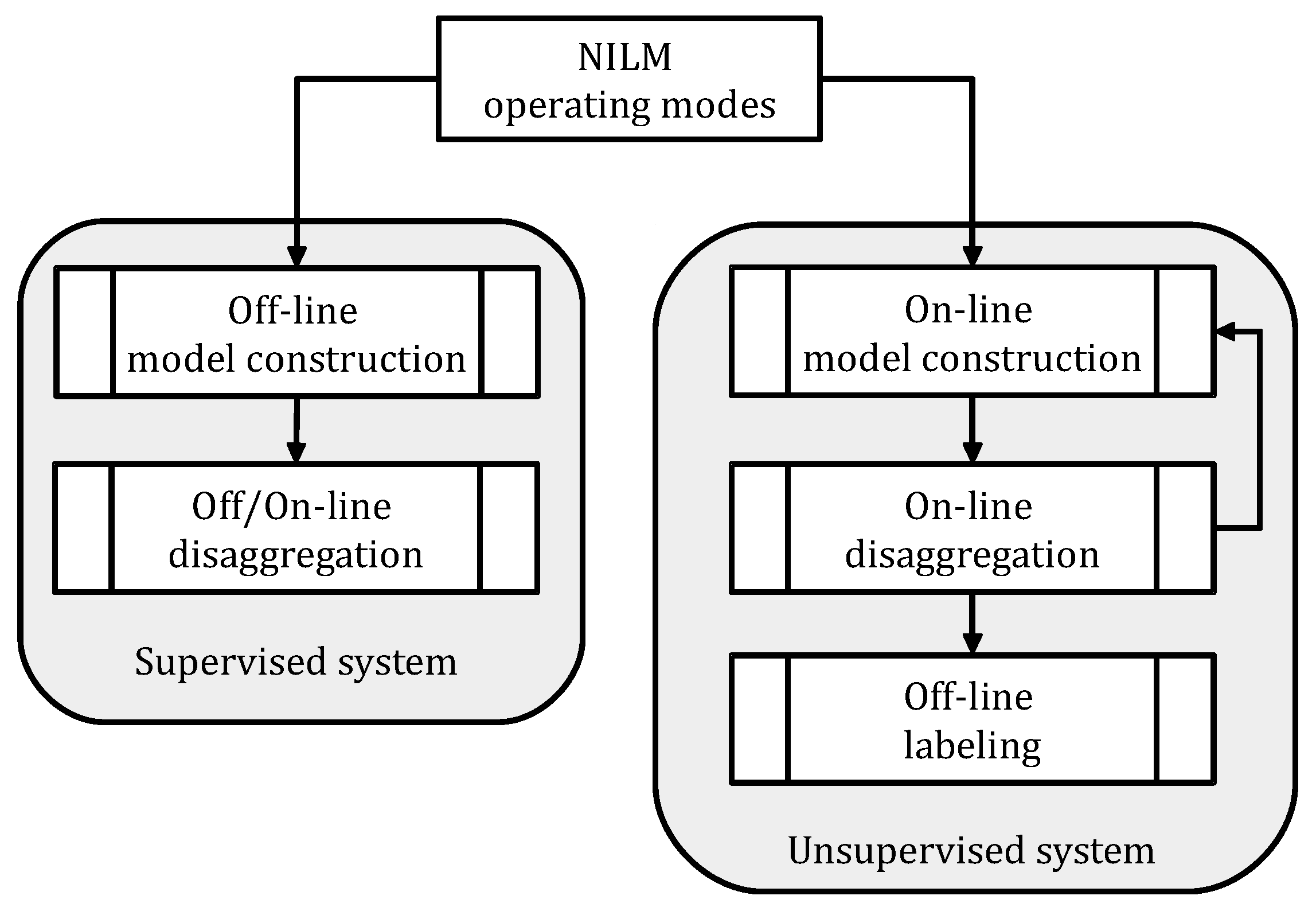
2.3. Operation Modes
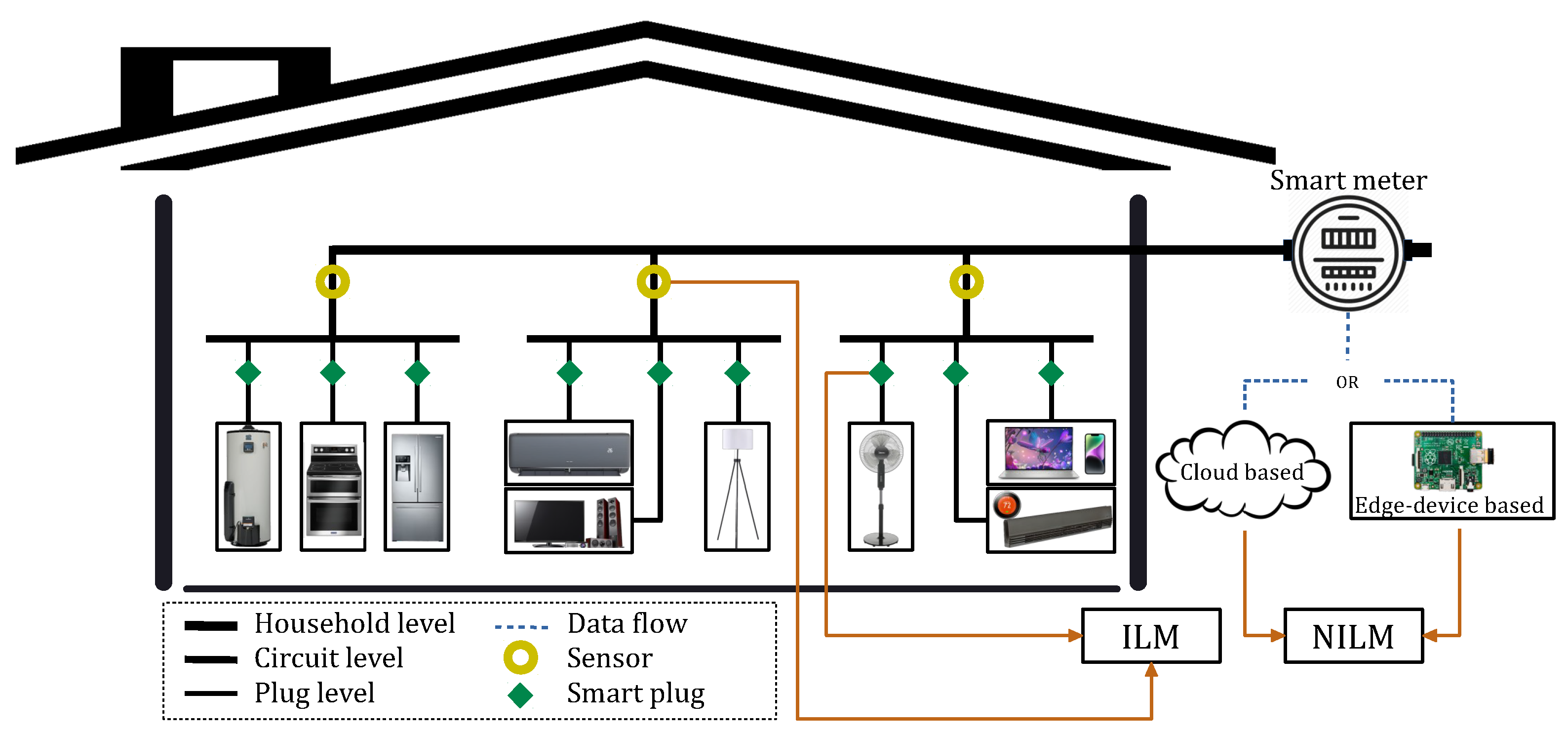
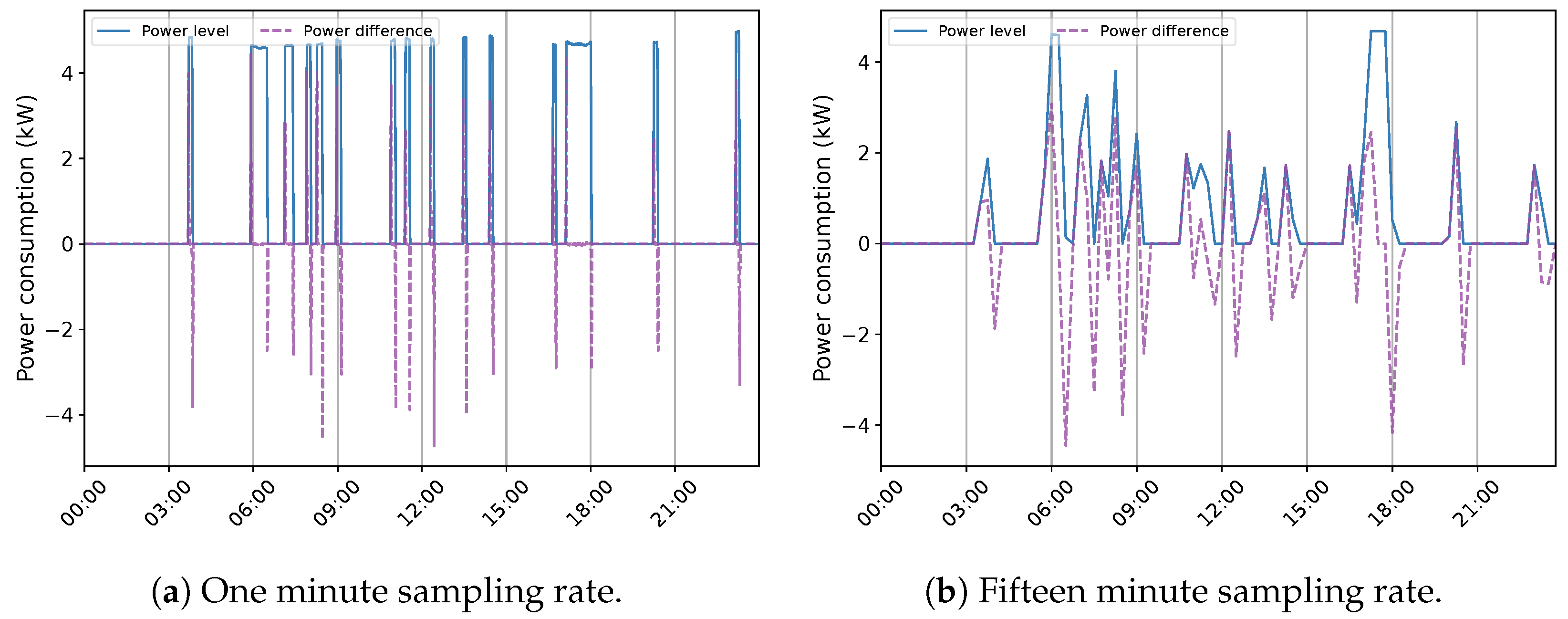
2.4. Data Source
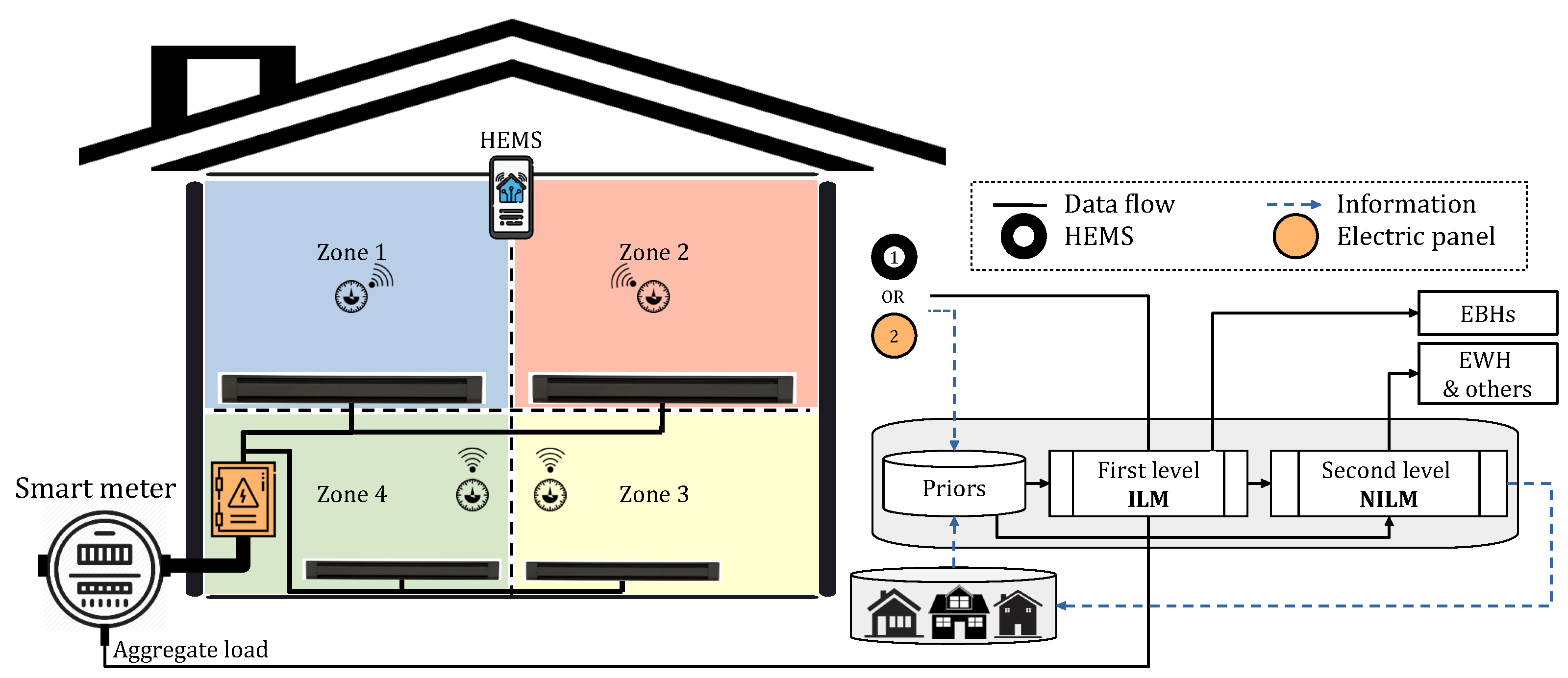
3. Quebec Residential Energy Usage Context
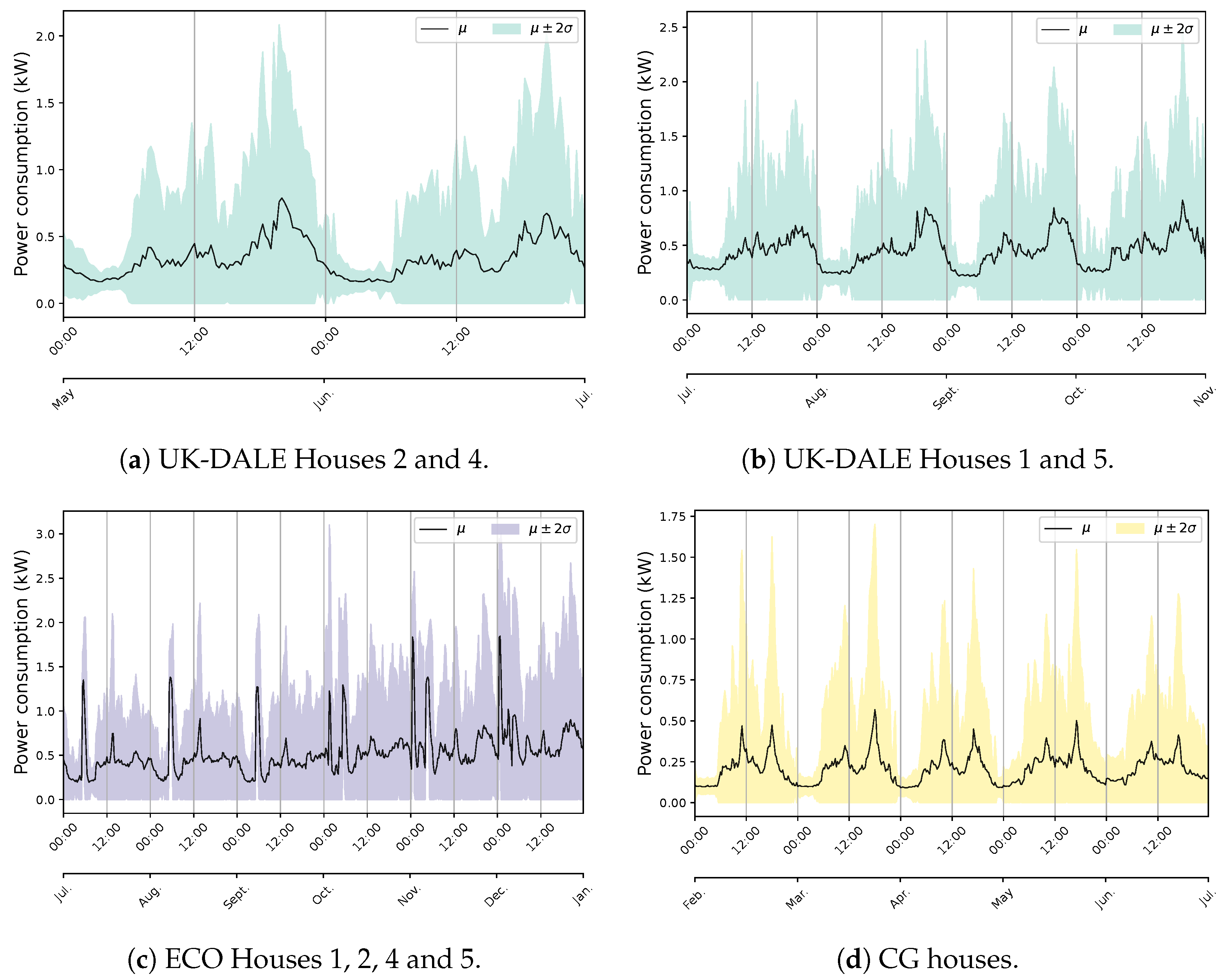
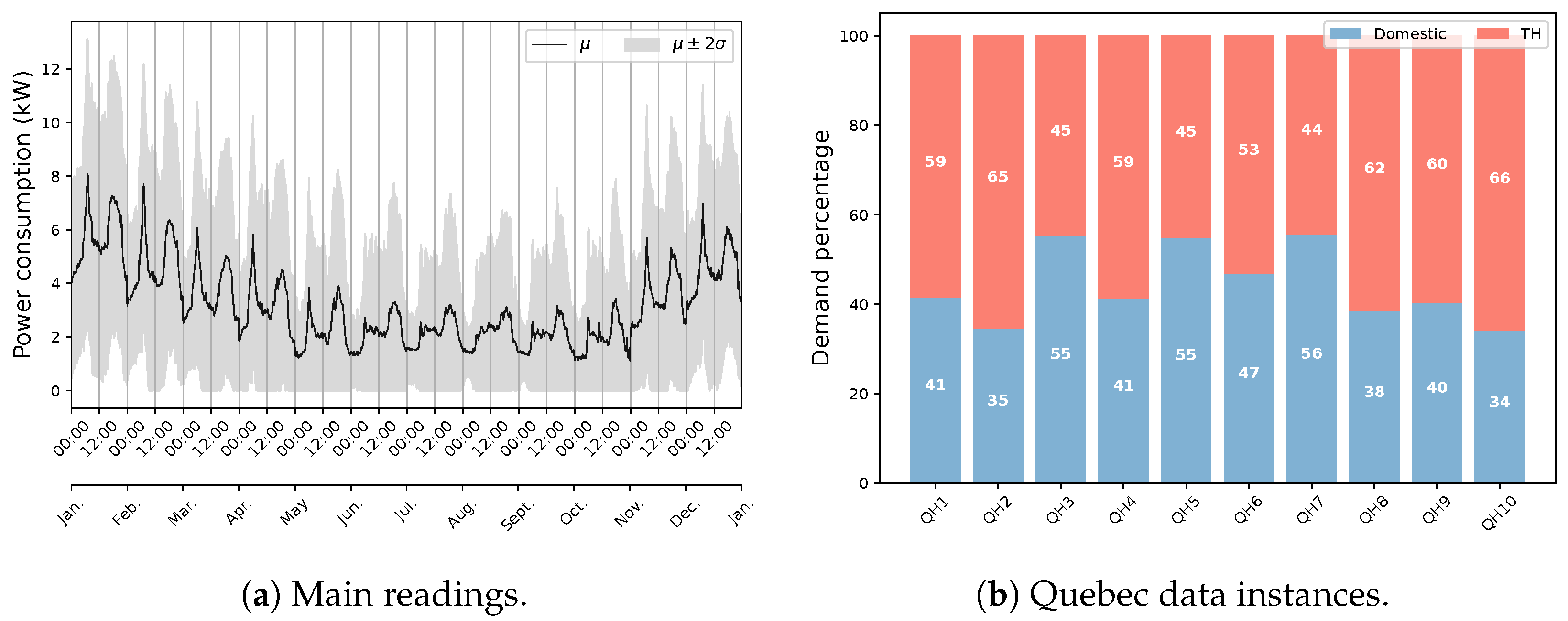
3.1. Quebec Residential Data Features
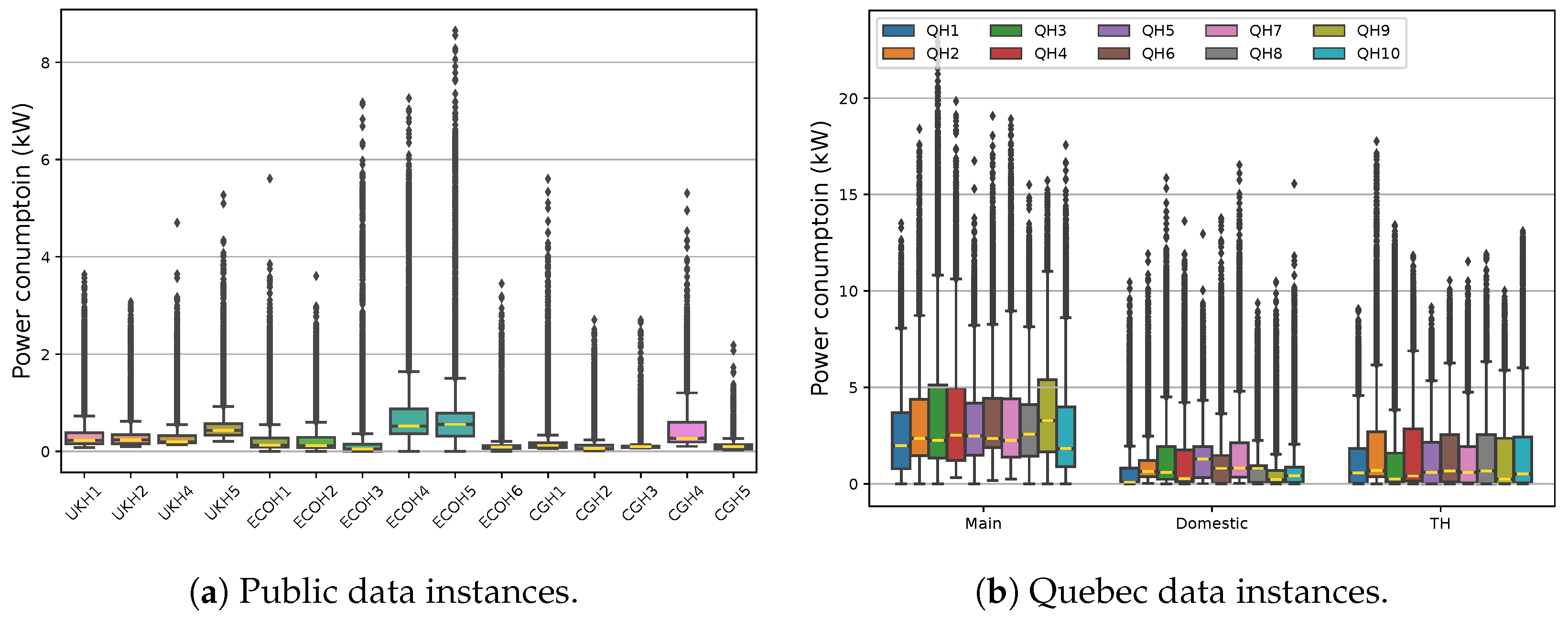
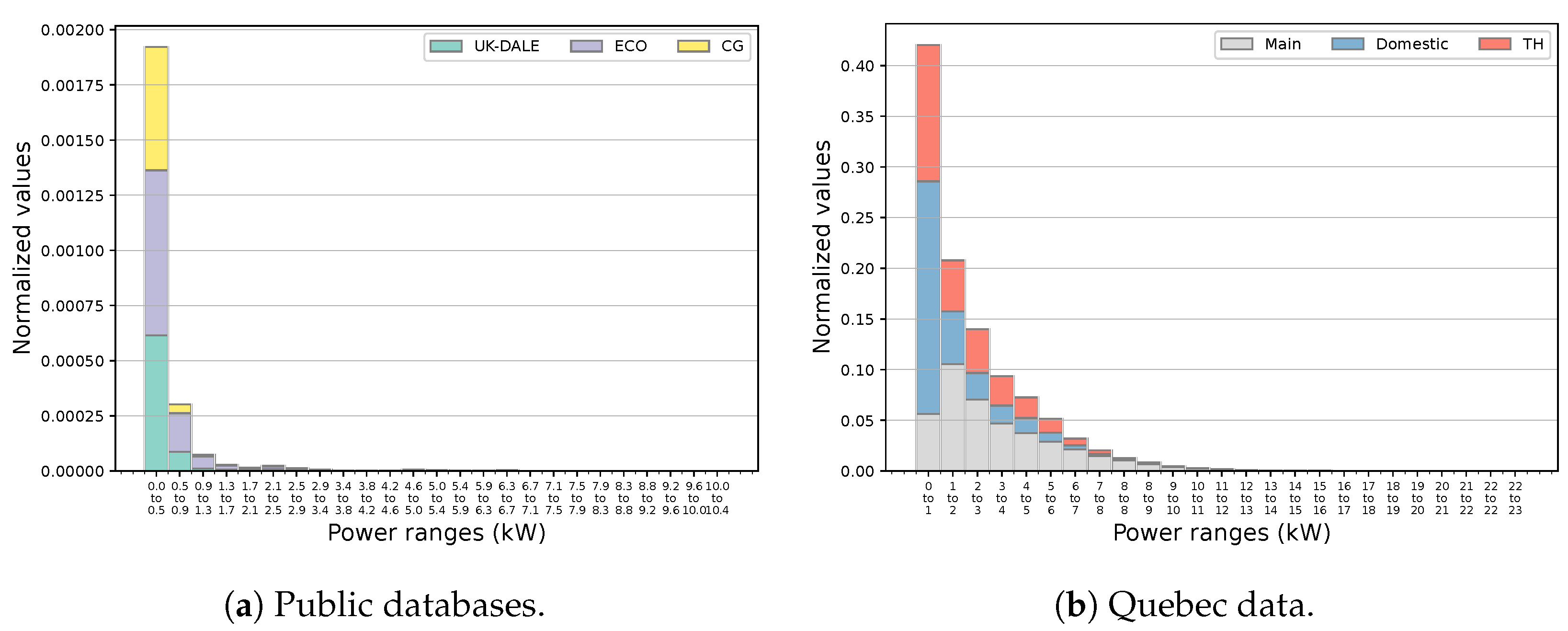
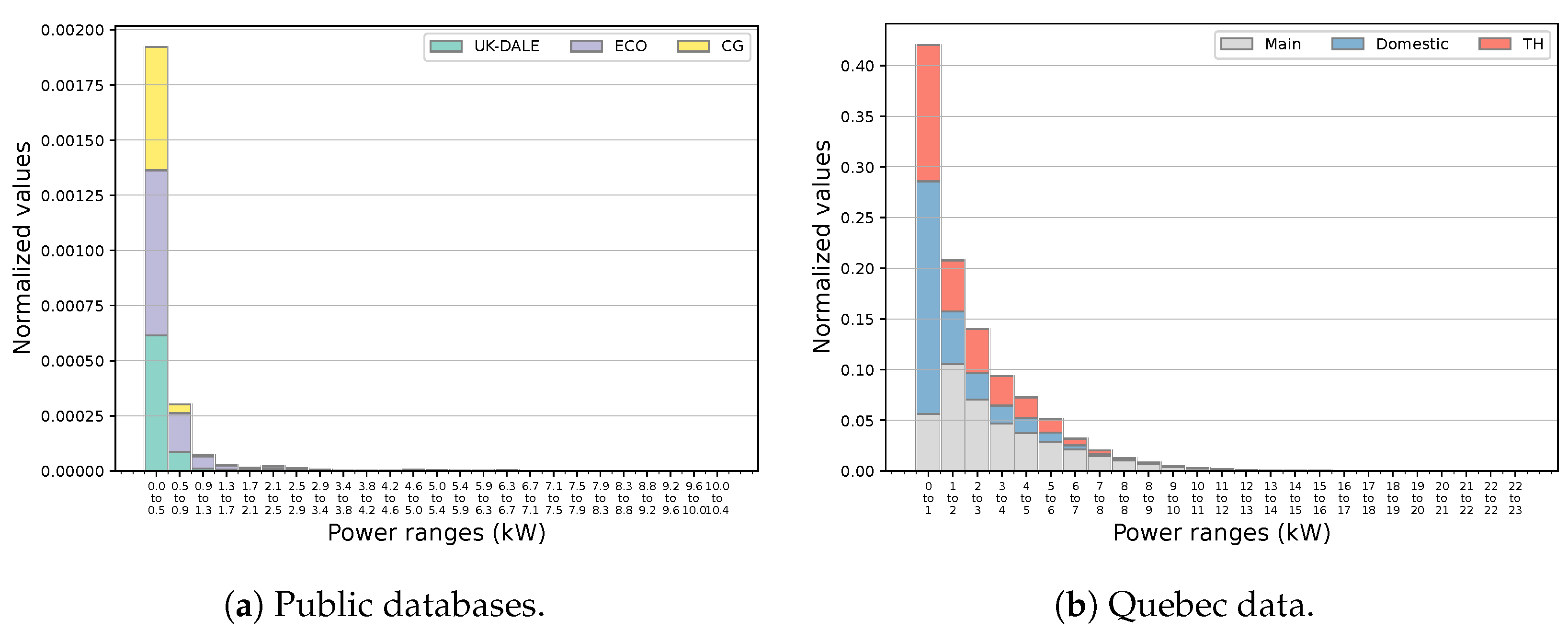
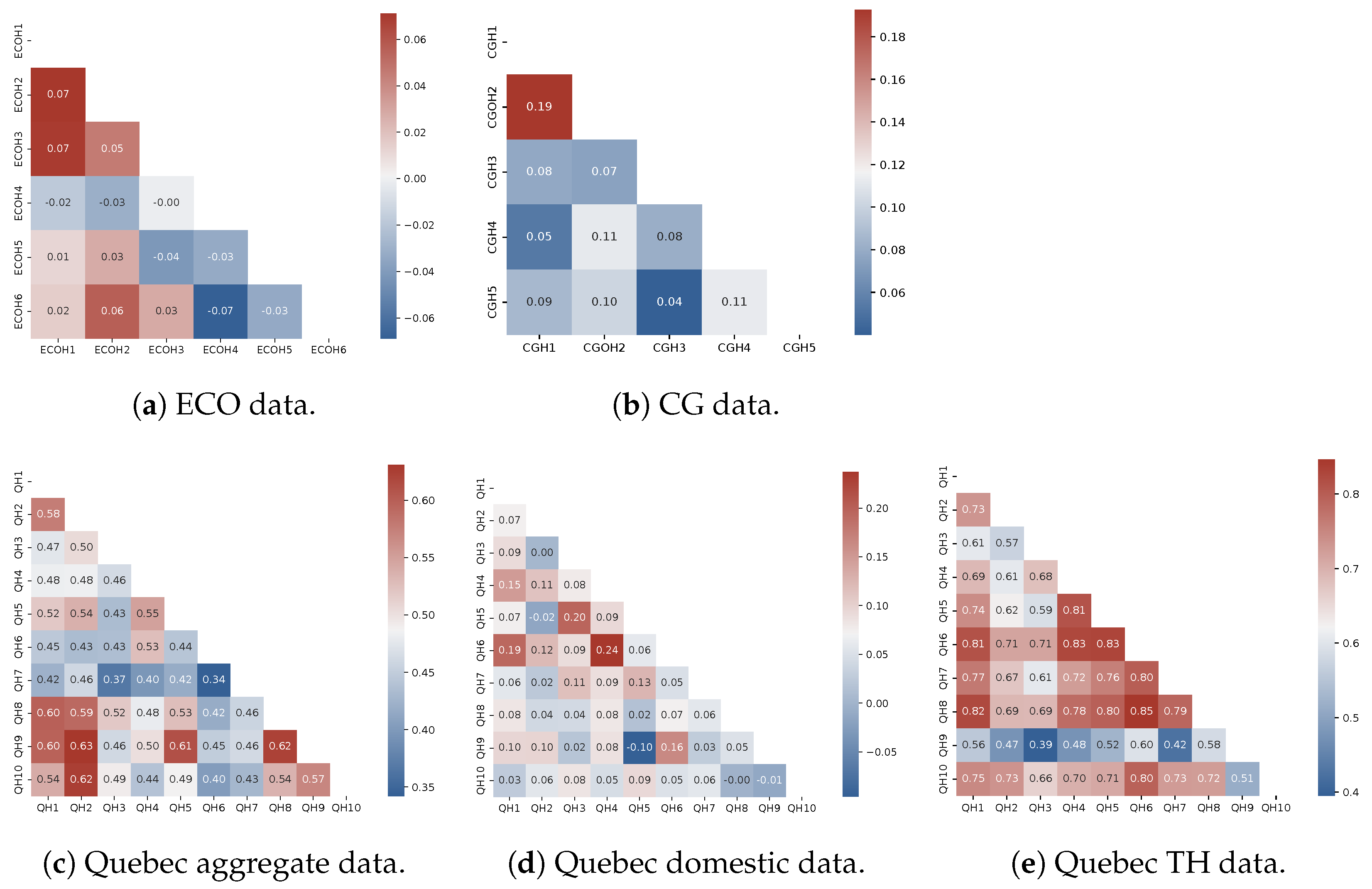
3.2. Quebec Comparative Data Statistics
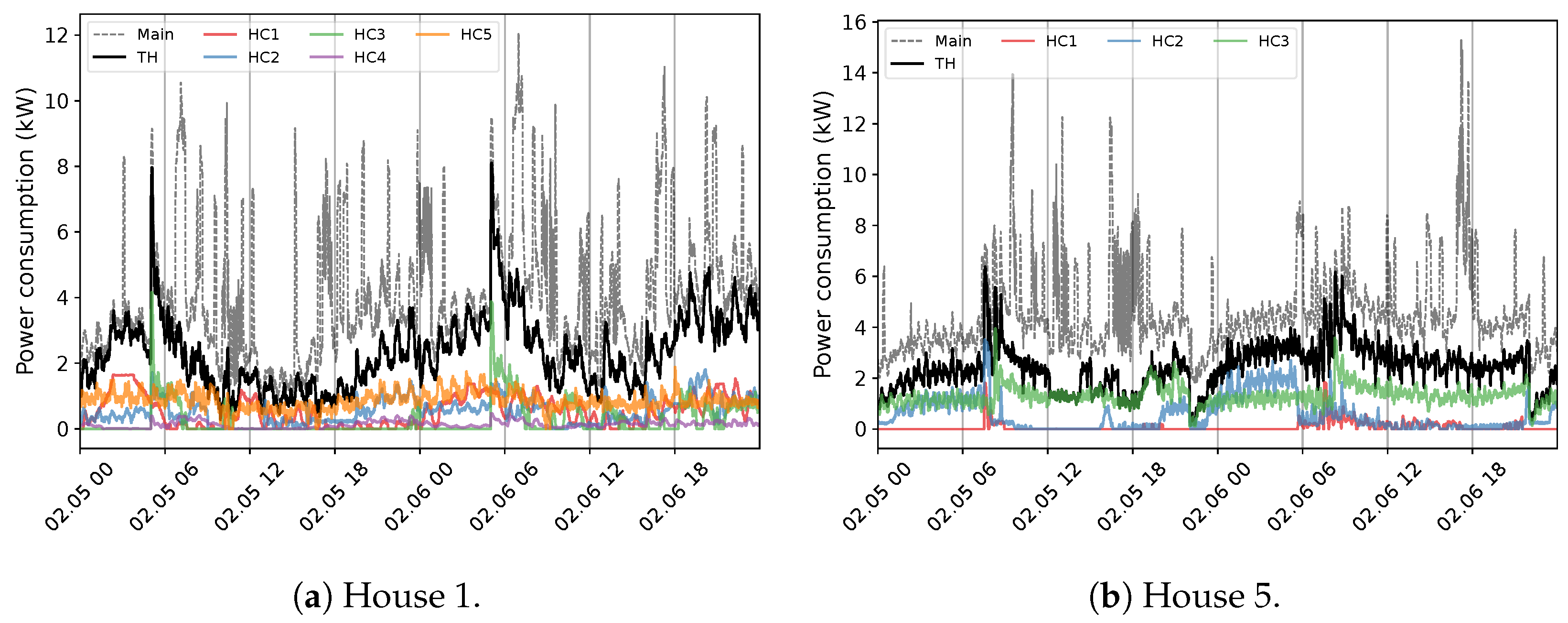
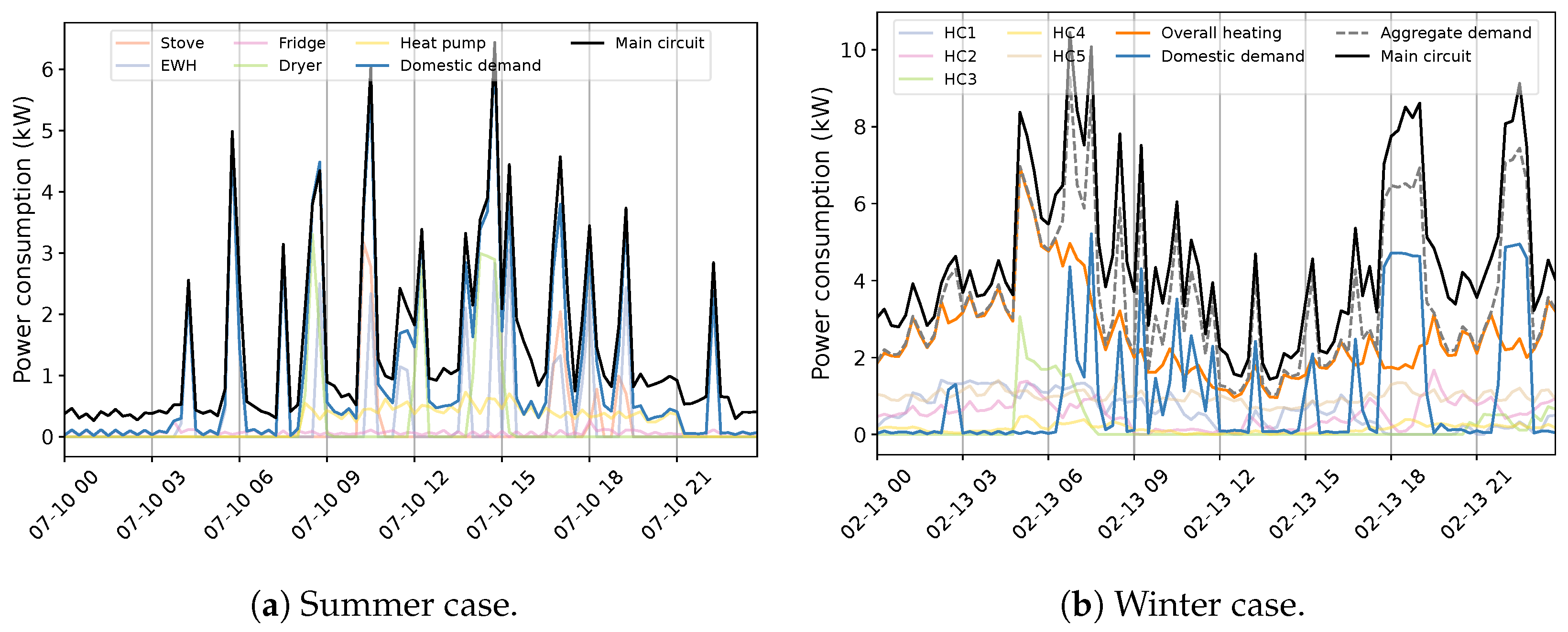
4. A Disaggregation Approach to Quebec Household Power Consumption
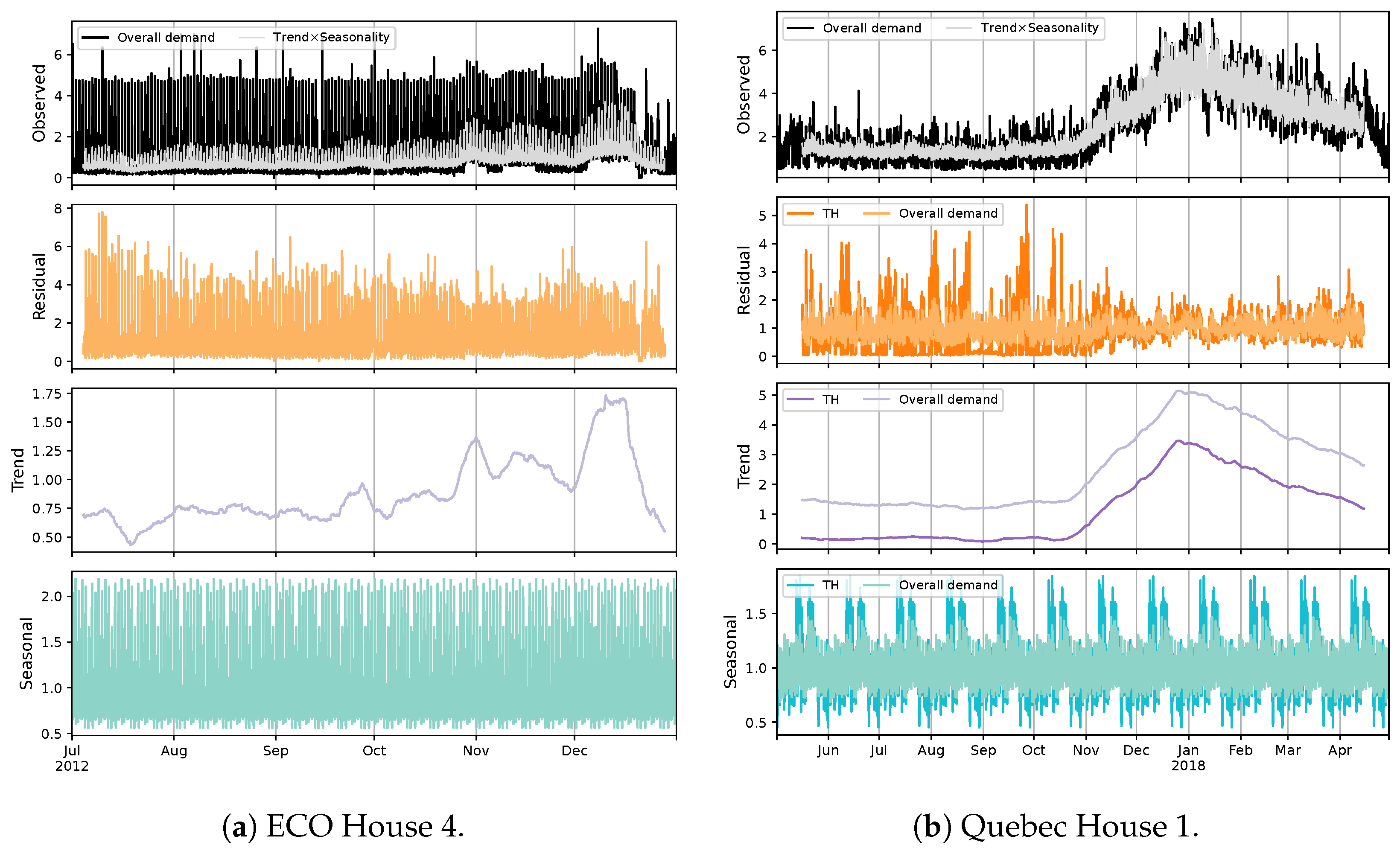
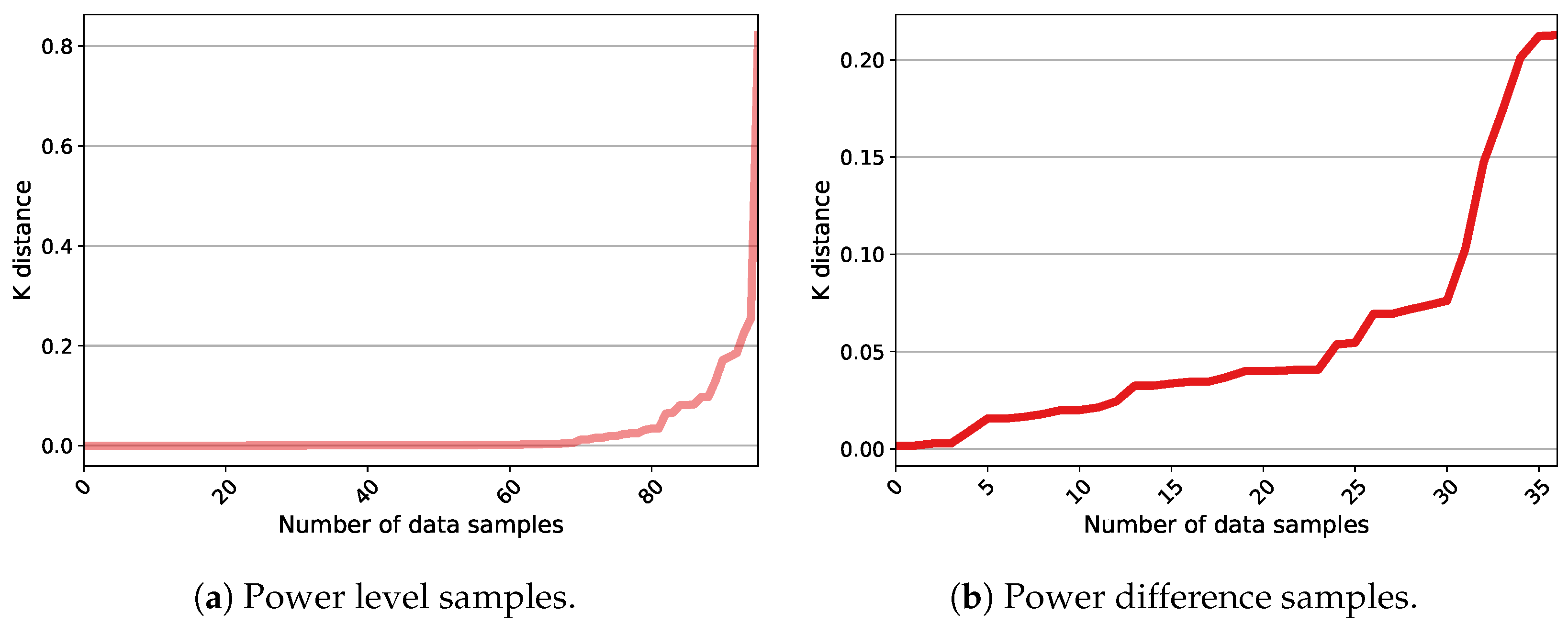
5. An Introductory NILM Practice in Quebec Residences
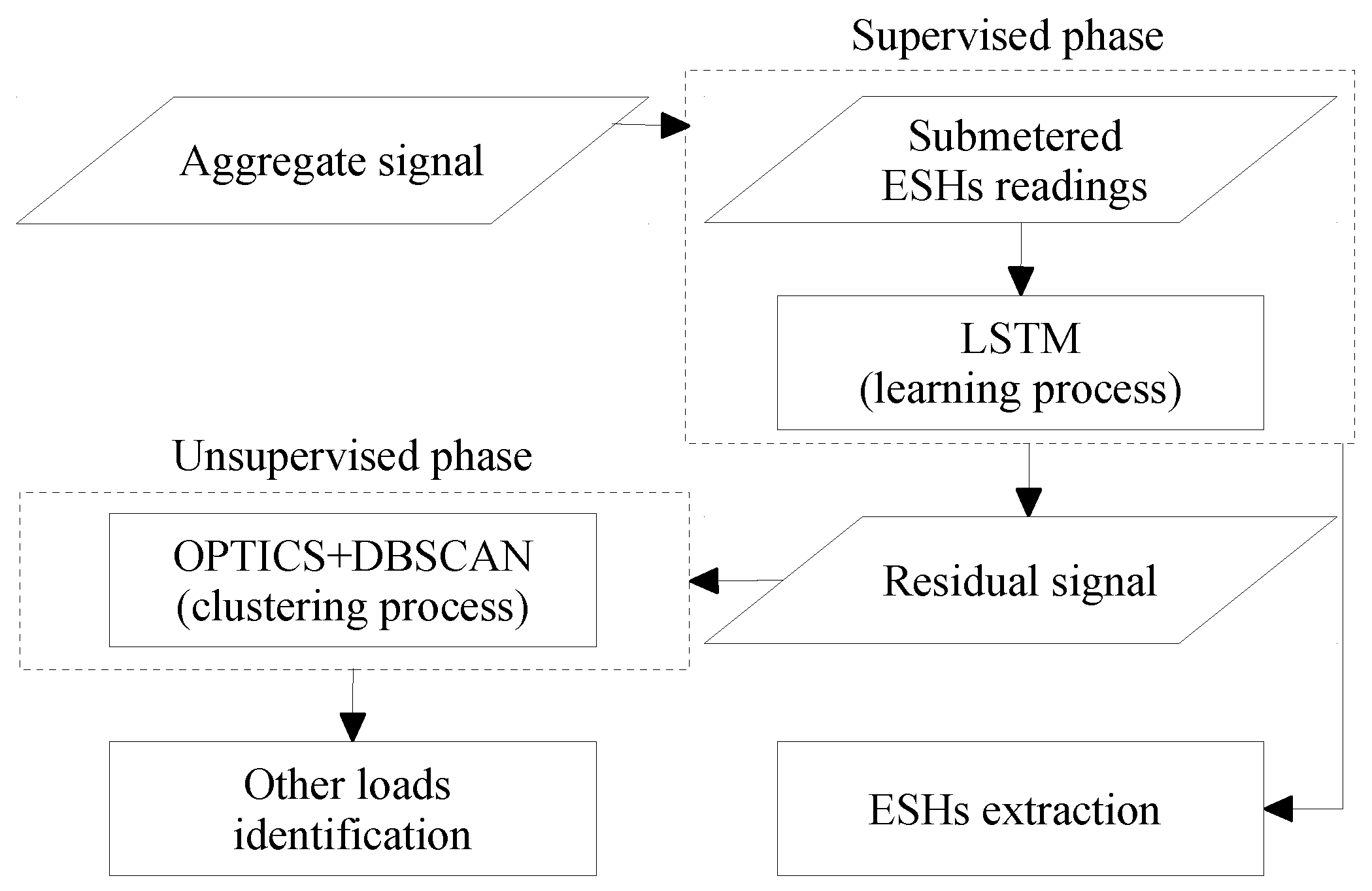
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hosseini, S.S.; Agbossou, K.; Kelouwani, S.; Cardenas, A. Non-intrusive load monitoring through home energy management systems: A comprehensive review. Renew. Sustain. Energy Rev. 2017, 79, 1266–1274. [Google Scholar] [CrossRef]
- Zandi, H.; Kuruganti, P.T.V.; Vineyard, E.A.; Fugate, D.L. Home Energy Management Systems: An Overview. In Proceedings of the Proceedings of the 9th international conference on Energy Efficiency in Domestic Appliances and Lighting, Irvine, CA, USA, 13–15 September 2018; pp. 606–614. [Google Scholar]
- Hosseini, S.S.; Agbossou, K.; Kelouwani, S.; Cardenas, A.; Henao, N. A Practical Approach to Residential Appliances on-Line Anomaly Detection: A Case Study of Standard and Smart Refrigerators. IEEE Access 2020, 8, 57905–57922. [Google Scholar] [CrossRef]
- Sakib, N.; Hossain, E.; Ahamed, S.I. A Qualitative Study on the United States Internet of Energy: A Step Towards Computational Sustainability. IEEE Access 2020, 8, 69003–69037. [Google Scholar] [CrossRef]
- Hosseini, S.S.; Kelouwani, S.; Agbossou, K.; Cardenas, A.; Henao, N. Adaptive on-line unsupervised appliance modeling for autonomous household database construction. Int. J. Electr. Power Energy Syst. 2019, 112, 156–168. [Google Scholar] [CrossRef]
- Hosseini, S.S. Load Monitoring and Diagnosis of Residential Electrical Appliances. Ph.D. Thesis, Electrical and Computer Engineering Department, Université du Québec à Trois-Rivières, Trois-Rivières, QC, Canada, 2020. [Google Scholar]
- Oliver Parson. Disaggregated Homes: Overview of the NILM Field. Available online: https://blog.oliverparson.co.uk/2015/03/overview-of-nilm-field.html (accessed on 17 August 2023).
- Liaqat, R.; Sajjad, I.A.; Waseem, M.; Alhelou, H.H. Appliance Level Energy Characterization of Residential Electricity Demand: Prospects, Challenges and Recommendations. IEEE Access 2021, 9, 148676–148697. [Google Scholar] [CrossRef]
- Huchtkoetter, J.; Reinhardt, A. A study on the impact of data sampling rates on load signature event detection. Energy Inform. 2019, 2, 24. [Google Scholar] [CrossRef]
- Xu, F.; Huang, B.; Cun, X.; Wang, F.; Yuan, H.; Lai, L.L.; Vaccaro, A. Classifier economics of Semi-Intrusive Load Monitoring. Int. J. Electr. Power Energy Syst. 2018, 103, 224–232. [Google Scholar] [CrossRef]
- Angelis, G.F.; Timplalexis, C.; Krinidis, S.; Ioannidis, D.; Tzovaras, D. NILM applications: Literature review of learning approaches, recent developments and challenges. Energy Build. 2022, 261, 111951. [Google Scholar] [CrossRef]
- Faustine, A.; Pereira, L.; Bousbiat, H.; Kulkarni, S. UNet-NILM: A Deep Neural Network for Multi-tasks Appliances State Detection and Power Estimation in NILM. In Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring, Virtual Event, 18 November 2020; pp. 84–88. [Google Scholar] [CrossRef]
- Iqbal, H.K.; Malik, F.H.; Muhammad, A.; Qureshi, M.A.; Abbasi, M.N.; Chishti, A.R. A critical review of state-of-the-art non-intrusive load monitoring datasets. Electr. Power Syst. Res. 2021, 192, 106921. [Google Scholar] [CrossRef]
- Völker, B.; Pfeifer, M.; Scholl, P.M.; Becker, B. Annoticity: A Smart Annotation Tool and Data Browser for Electricity Datasets. In Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring, Virtual Event, 18 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Lin, J.; Ma, J.; Zhu, J.; Liang, H. Deep Domain Adaptation for Non-Intrusive Load Monitoring Based on a Knowledge Transfer Learning Network. IEEE Trans. Smart Grid 2022, 13, 280–292. [Google Scholar] [CrossRef]
- Zhou, G.; Li, Z.; Fu, M.; Feng, Y.; Wang, X.; Huang, C. Sequence-to-Sequence Load Disaggregation Using Multiscale Residual Neural Network. IEEE Trans. Instrum. Meas. 2021, 70, 2503310. [Google Scholar] [CrossRef]
- D’Incecco, M.; Squartini, S.; Zhong, M. Transfer Learning for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2020, 11, 1419–1429. [Google Scholar] [CrossRef]
- Rafiq, H.; Shi, X.; Zhang, H.; Li, H.; Ochani, M.K.; Shah, A.A. Generalizability improvement of deep learning-based non-intrusive load monitoring system using data augmentation. IEEE Trans. Smart Grid 2021, 12, 3265–3277. [Google Scholar] [CrossRef]
- Cui, G.; Liu, B.; Luan, W.; Yu, Y. Estimation of Target Appliance Electricity Consumption Using Background Filtering. IEEE Trans. Smart Grid 2019, 10, 5920–5929. [Google Scholar] [CrossRef]
- Afzalan, M.; Jazizadeh, F. Residential loads flexibility potential for demand response using energy consumption patterns and user segments. Appl. Energy 2019, 254, 113693. [Google Scholar] [CrossRef]
- Soares, A.; Gomes, Á.; Antunes, C.H. Categorization of residential electricity consumption as a basis for the assessment of the impacts of demand response actions. Renew. Sustain. Energy Rev. 2014, 30, 490–503. [Google Scholar] [CrossRef]
- Hosseini, S.; Kelouwani, S.; Agbossou, K.; Cardenas, A.; Henao, N. A semi-synthetic dataset development tool for household energy consumption analysis. In Proceedings of the 2017 IEEE International Conference on Industrial Technology (ICIT), Toronto, ON, Canada, 22–25 March 2017; pp. 564–569. [Google Scholar] [CrossRef]
- Hart, G. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Wong, Y.F.; Ahmet Sekercioglu, Y.; Drummond, T.; Wong, V.S. Recent approaches to non-intrusive load monitoring techniques in residential settings. In Proceedings of the 2013 IEEE Computational Intelligence Applications in Smart Grid (CIASG), Singapore, 16–19 April 2013; pp. 73–79. [Google Scholar] [CrossRef]
- Bhotto, M.Z.A.; Makonin, S.; Bajić, I.V. Load Disaggregation Based on Aided Linear Integer Programming. IEEE Trans. Circuits Syst. II Express Briefs 2017, 64, 792–796. [Google Scholar] [CrossRef]
- Balletti, M.; Piccialli, V.; Sudoso, A.M. Mixed-Integer Nonlinear Programming for State-Based Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2022, 13, 3301–3314. [Google Scholar] [CrossRef]
- Kaselimi, M.; Protopapadakis, E.; Voulodimos, A.; Doulamis, N.; Doulamis, A. Towards Trustworthy Energy Disaggregation: A Review of Challenges, Methods, and Perspectives for Non-Intrusive Load Monitoring. Sensors 2022, 22, 5872. [Google Scholar] [CrossRef]
- GitHub—Nilmtk/Nilmtk: Non-Intrusive Load Monitoring Toolkit (Nilmtk). Available online: https://nilmtk.github.io/ (accessed on 17 August 2023).
- Henao, N.; Agbossou, K.; Kelouwani, S.; Dube, Y.; Fournier, M. Approach in Nonintrusive Type I Load Monitoring Using Subtractive Clustering. IEEE Trans. Smart Grid 2015, 8, 812–821. [Google Scholar] [CrossRef]
- Zhao, B.; Stankovic, L.; Stankovic, V. On a Training-Less Solution for Non-Intrusive Appliance Load Monitoring Using Graph Signal Processing. IEEE Access 2016, 4, 1784–1799. [Google Scholar] [CrossRef]
- Rammig, F.; Ditze, M.; Janacik, P.; Heimfarth, T.; Kerstan, T.; Oberthuer, S.; Stahl, K. Basic Concepts of Real Time Operating Systems. In Hardware-Dependent Software; Springer: Dordrecht, The Netherlands, 2009; pp. 15–45. [Google Scholar] [CrossRef]
- Shin, C.; Rho, S.; Lee, H.; Rhee, W. Data Requirements for Applying Machine Learning to Energy Disaggregation. Energies 2019, 12, 1696. [Google Scholar] [CrossRef]
- Zeifman, M.; Roth, K. Nonintrusive appliance load monitoring: Review and outlook. IEEE Trans. Consum. Electron. 2011, 57, 76–84. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, Z.J.; Kashani, A. Home appliance load modeling from aggregated smart meter data. IEEE Trans. Power Syst. 2015, 30, 254–262. [Google Scholar] [CrossRef]
- Barker, S.; Kalra, S.; Irwin, D.; Shenoy, P. Empirical Characterization, Modeling, and Analysis of Smart Meter Data. IEEE J. Sel. Areas Commun. 2014, 32, 1312–1327. [Google Scholar] [CrossRef]
- Pöchacker, M.; Egarter, D.; Elmenreich, W. Proficiency of power values for load disaggregation. IEEE Trans. Instrum. Meas. 2016, 65, 46–55. [Google Scholar] [CrossRef]
- Dinesh, C.; Makonin, S.; Bajic, I.V. Incorporating time-of-day usage patterns into non-intrusive load monitoring. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 1110–1114. [Google Scholar] [CrossRef]
- Restrepo, J.; Naranjo, F.; Barzola, J.; Otero, C.; Garcia, P. Load Identification for Smart Grid Management. In Proceedings of the 2019 IEEE PES Innovative Smart Grid Technologies Conference—Latin America (ISGT Latin America), Gramado, Brazil, 15–18 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Rehman, A.U.; Rahman Tito, S.; Nieuwoudt, P.; Imran, G.; Lie, T.T.; Valles, B.; Ahmad, W. Applications of Non-Intrusive Load Monitoring Towards Smart and Sustainable Power Grids: A System Perspective. In Proceedings of the IEEE 29th Australasian Universities Power Engineering Conference (AUPEC), Nadi, Fiji, 26–29 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Henao, N.; Agbossou, K.; Kelouwani, S.; Hosseini, S.; Fournier, M. Power Estimation of Multiple Two-State Loads Using A Probabilistic Non-Intrusive Approach. Energies 2018, 11, 88. [Google Scholar] [CrossRef]
- CleverGuard—Invisible Protection for Pensioners Based on Energy Data—CLEMAP Blog. Available online: https://www.cleverguard.care (accessed on 17 August 2023).
- Rafiq, H.; Manandhar, P.; Rodriguez-Ubinas, E.; Barbosa, J.D.; Qureshi, O.A. Analysis of residential electricity consumption patterns utilizing smart-meter data: Dubai as a case study. Energy Build. 2023, 291, 113103. [Google Scholar] [CrossRef]
- Dab, K.; Agbossou, K.; Henao, N.; Dubé, Y.; Kelouwani, S.; Hosseini, S.S. A compositional kernel based gaussian process approach to day-ahead residential load forecasting. Energy Build. 2022, 254, 111459. [Google Scholar] [CrossRef]
- Energy Disaggregation—Bidgely Utility AI—Energy Analytics. Available online: https://www.bidgely.com (accessed on 17 August 2023).
- Culière, F.; Leduc, L.; Belikov, A. Bayesian model of electrical heating disaggregation. In Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring, Virtual Event, 18 November 2020; pp. 25–29. [Google Scholar] [CrossRef]
- Deb, C.; Frei, M.; Hofer, J.; Schlueter, A. Automated load disaggregation for residences with electrical resistance heating. Energy Build. 2019, 182, 61–74. [Google Scholar] [CrossRef]
- Hosseini, S.S.; Delcroix, B.; Henao, N.; Agbossou, K.; Kelouwani, S. A case study on obstacles to feasible NILM solutions for energy disaggregation in quebec residences. In Proceedings of the 9th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, Boston, MA, USA, 2–3 November 2022; pp. 363–367. [Google Scholar]
- Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. Density-based clustering in spatial databases: The algorithm GDBSCAN and its applications. Data Min. Knowl. Discov. 1998, 2, 169–194. [Google Scholar] [CrossRef]
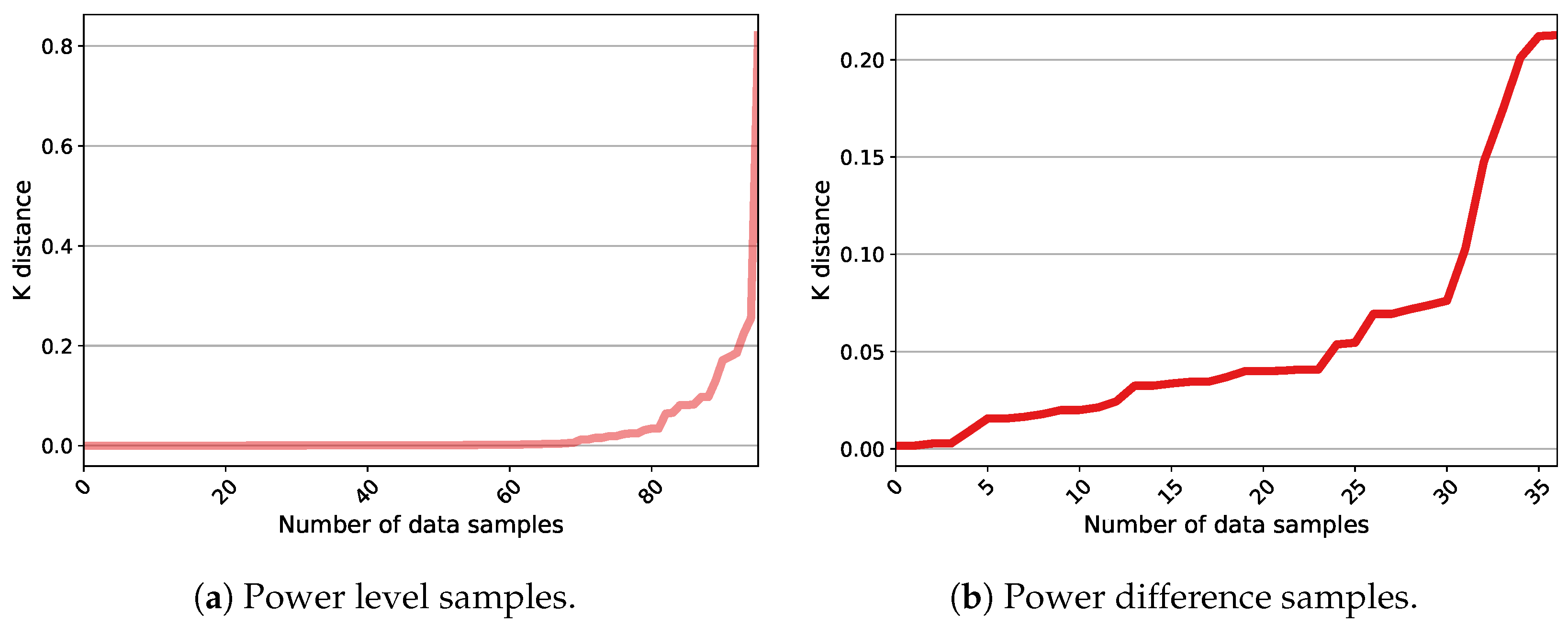
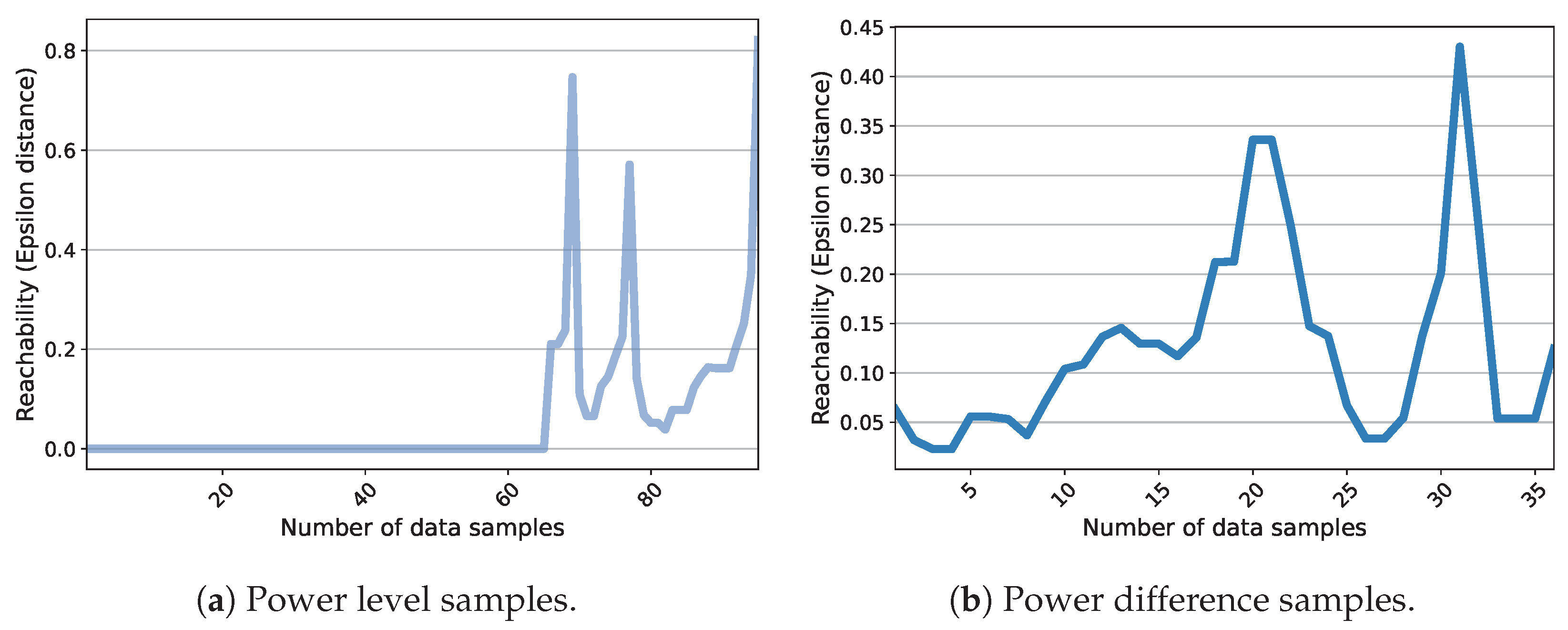
- Rahmah, N.; Sitanggang, I.S. Determination of Optimal Epsilon (Eps) Value on DBSCAN Algorithm to Clustering Data on Peatland Hotspots in Sumatra. Iop Conf. Ser. Earth Environ. Sci. 2016, 31, 012012. [Google Scholar] [CrossRef]
- Laouali, I.H.; Qassemi, H.; Marzouq, M.; Ruano, A.; Bennani, S.D.; El Fadili, H. A Survey On Computational Intelligence Techniques For Non Intrusive Load Monitoring. In Proceedings of the 2020 IEEE 2nd International Conference on Electronics, Control, Optimization and Computer Science (ICECOCS), Kenitra, Morocco, 2–3 December 2020; pp. 1–6. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Houses | Measuring Duration per House | Sampling Frequency | Site | |
|---|---|---|---|---|---|
| Appliance | Aggregate | ||||
| REDD | 6 | 3–19 days | 3 s | 1 s & 15 kHz | USA |
| UMass Smart | 3 | 3 months | 1 s | 1 s | USA |
| UK-DALE | 5 | 3–17 months | 6 s | 1–6 s & 16 kHz | UK |
| BLUED | 1 | 8 days | event label | 12 kHz | USA |
| AMPDs | 1 | 1 year | 1 min | 1 min | CDN |
| ECO | 6 | 8 months | 1 s | 1 s | CH |
| Tracebase | 15 | N/A | 1–10 s | N/A | DE |
| HES | 251 | 1–12 months | 2–10 min | 2–10 min | UK |
| iAWE | 1 | 73 days | 1–6 s | 1 s | IND |
| GreenD | 9 | 1 year | 1 s | 1 s | AT/IT |
| Data | MAE (kW) | MSE | RMSE (kW) | sMAPE (%) |
|---|---|---|---|---|
| House 1 | 0.39 | 0.41 | 0.64 | 46 |
| House 2 | 1.03 | 2.68 | 1.65 | 88 |
| House 3 | 0.72 | 1.71 | 1.31 | 56 |
| House 4 | 0.97 | 2.26 | 1.50 | 76 |
| House 5 | 0.48 | 0.69 | 0.83 | 46 |
| House 6 | 0.79 | 1.37 | 1.17 | 58 |
| House 7 | 0.67 | 0.99 | 0.99 | 69 |
| House 8 | 0.66 | 0.69 | 0.83 | 54 |
| House 9 | 0.56 | 0.66 | 0.81 | 45 |
| House 10 | 0.72 | 1.62 | 1.27 | 72 |
| Day | TECA (%) | MAE (kW) | MSE |
|---|---|---|---|
| 1st | 86 | 0.48 | 0.57 |
| 2nd | 86 | 0.41 | 0.52 |
| 3rd | 86 | 0.47 | 0.37 |
| 4th | 84 | 0.53 | 0.58 |
| 5th | 84 | 0.47 | 0.73 |
| 6th | 85 | 0.37 | 0.36 |
| 7th | 85 | 0.38 | 0.33 |
| Day | Detected Load (kW) and Related Device | |||||
|---|---|---|---|---|---|---|
| 1st | 2st | 3rd | 4th | 5th | Energy (%) | |
| 1st | 0.92 | 3.8 EWH | 2.3 EWH Stove | 1.9 EWH Stove | 4.6 EWH | 30 |
| 2nd | 0.75 | 2.9 EWH | 2.5 EWH | 1.8 EWH | - | 37 |
| 3rd | 0.89 | - | - | - | - | - |
| 4th | 0.93 | 2.9 EWH Stove Dryer | 4.4 EWH Stove | 3.7 EWH Stove | - | 38 |
| 5th | 0.82 | 3.8 EWH Stove | 3.2 EWH Stove Dryer | - | - | 23 |
| 6th | 0.81 | 3.1 EWH | - | - | - | 34 |
| 7th | 0.87 | 2.9 EWH Stove | 4.9 EWH | - | - | 35 |
| Day | Load (kW) | F1-Score (%) | TECA (%) |
|---|---|---|---|
| 1st | 3.8 4.6 | 25 25 | 54 55 |
| Total | 44 | - | |
| 2nd | 2.9 2.5 1.8 | 30 21 39 | 54 55 59 |
| Total | 62 | - | |
| 6th | 3.1 | 69 | 66 |
| 7th | 2.9 4.9 | 47 39 | 57 59 |
| Total | 70 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hosseini, S.S.; Delcroix, B.; Henao, N.; Agbossou, K.; Kelouwani, S. Towards Feasible Solutions for Load Monitoring in Quebec Residences. Sensors 2023, 23, 7288. https://doi.org/10.3390/s23167288
Hosseini SS, Delcroix B, Henao N, Agbossou K, Kelouwani S. Towards Feasible Solutions for Load Monitoring in Quebec Residences. Sensors. 2023; 23(16):7288. https://doi.org/10.3390/s23167288
Chicago/Turabian StyleHosseini, Sayed Saeed, Benoit Delcroix, Nilson Henao, Kodjo Agbossou, and Sousso Kelouwani. 2023. "Towards Feasible Solutions for Load Monitoring in Quebec Residences" Sensors 23, no. 16: 7288. https://doi.org/10.3390/s23167288
APA StyleHosseini, S. S., Delcroix, B., Henao, N., Agbossou, K., & Kelouwani, S. (2023). Towards Feasible Solutions for Load Monitoring in Quebec Residences. Sensors, 23(16), 7288. https://doi.org/10.3390/s23167288