
Hierarchical Fusion Network with Enhanced Knowledge and Contrastive Learning for Multimodal Aspect-Based Sentiment Analysis on Social Media

Abstract
:1. Introduction
- 1.
- An enhanced knowledge-based hierarchical fusion network is proposed to effectively capture the interactive semantic relationship between different modalities and aspects. The network builds element-level and structure-level fusion features, enhancing the leveraging of multimodal information for aspect-based sentiment analysis.
- 2.
- Modality-based and label-based contrastive learning is proposed. By leveraging the label features within the dataset and the enhanced image knowledge extracted from the data itself, the model can learn the common features associated with aspect-based sentiment across different modalities and analyze sentiment efficiency.
- 3.
- We conduct extensive experiments and provide thorough ablation studies to demonstrate the effectiveness of our proposed approach to multimodal aspect-based sentiment analysis.
2. Related Work
2.1. Aspect-Based Sentiment Analysis
2.2. Multimodal Sentiment Analysis
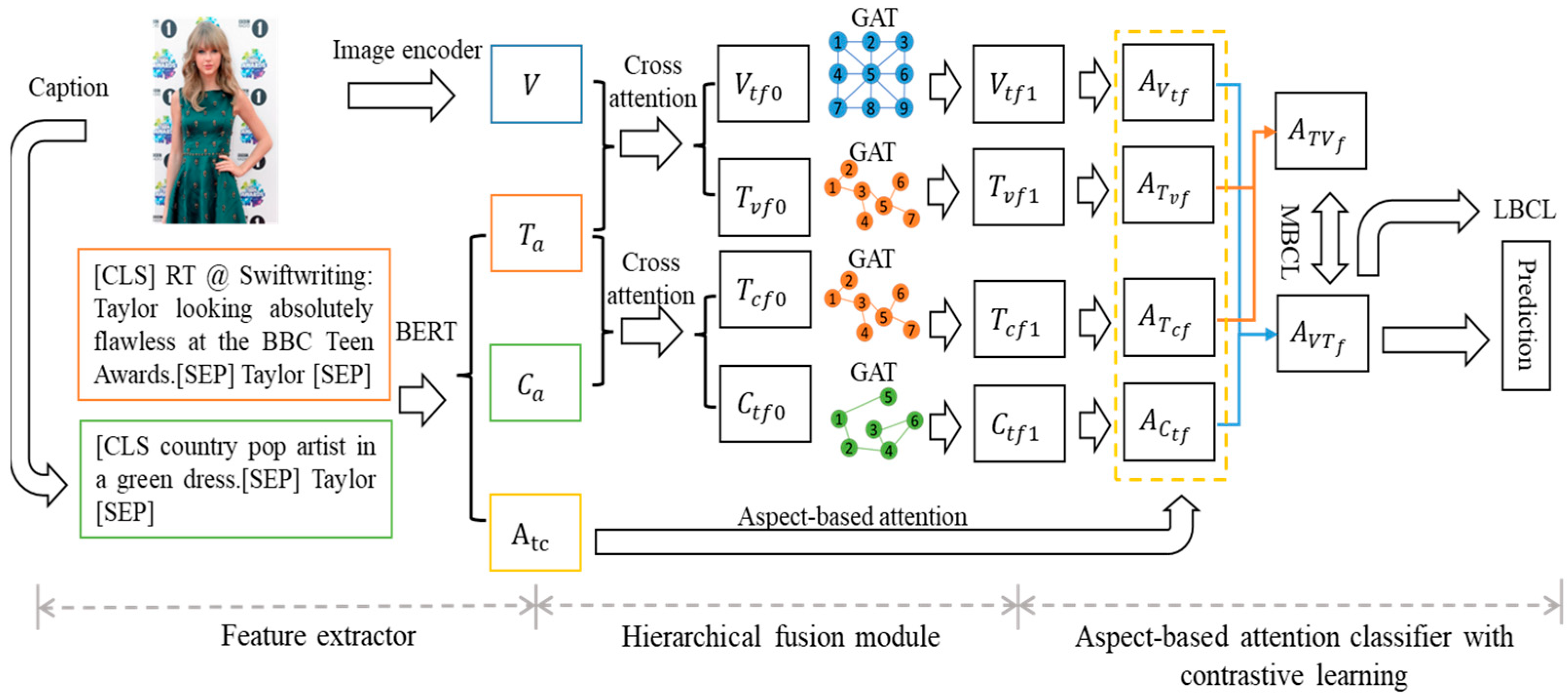
3. Methodology
3.1. Task Definition
3.2. Overview
3.3. Feature Extractor
3.4. Hierarchical Fusion Module
3.4.1. Element-Level Fusion
3.4.2. Structure-Level Fusion
3.5. Hierarchical Fusion Module
3.5.1. Aspect-Based Attention Module
3.5.2. Contrastive Learning
3.6. Final Objective Function
4. Experiments
4.1. Dataset and Model Settings
4.2. Baselines
- ResNet-Aspect: Utilizes visual features and aspect embeddings, which are extracted using ResNet and BERT, respectively. An attention layer is then applied to integrate all these features and embeddings and predict aspect-based sentiment analysis.
- ATAE [46]: Aspect embeddings are added to the attention-based Long Short-Term Memory (LSTM) networks, allowing the model to better capture important contextual information related to the aspect.
- RAM [47]: Employs position-based weighting and multiple attention mechanisms to construct attention-based features. These features are then processed using a non-linear combination with GRU to predict sentiment for targets.
- MGAN [48]: Combines a fine-grained attention mechanism with a coarse-grained attention mechanism to capture word-level interactions between aspects and context, along with an aspect alignment loss to capture aspect-level interactions for the analysis.
- BERT [19]: A pre-trained language model that uses a stacked Transformer encoder architecture to capture bidirectional context, generate context-aware word features, and explore the relationship between the aspect and the sentence.
- MIMN [15]: Proposes a multi-interactive memory network for aspect-based sentiment analysis that uses two memory networks to model text and image data; contains multiple memory hops for attention extraction.
- ESAFN [16]: Utilizes attention mechanisms to generate aspect-sensitive textual representations and aspect-sensitive visual representations using an oriented visual attention mechanism. These are then fused with a bilinear interaction layer for prediction.
- EF-Net [40]: TABMSA uses an attention capsule extraction and multi-head fusion network with multi-head attention and ResNet-152 to analyze the sentiment of targeted aspects in a multimodal setting.
- ViBERT [49]: An extension of the BERT model that includes multiple pre-trained Transformer layers applied to the concatenation of both text and image features extracted from BERT and Faster R-CNN, respectively.
- Tombert [17]: Uses a target attention mechanism to derive aspect-sensitive visual representations by performing aspect–image matching and stack self-attention layers to capture multimodal interactions.
- EF-CapTrBERT [42]: Employs image translation in the input space to convert images into text. The resulting text is then combined with an auxiliary sentence and fed into the encoder of a language model using multimodal fusion.
4.3. Main Results
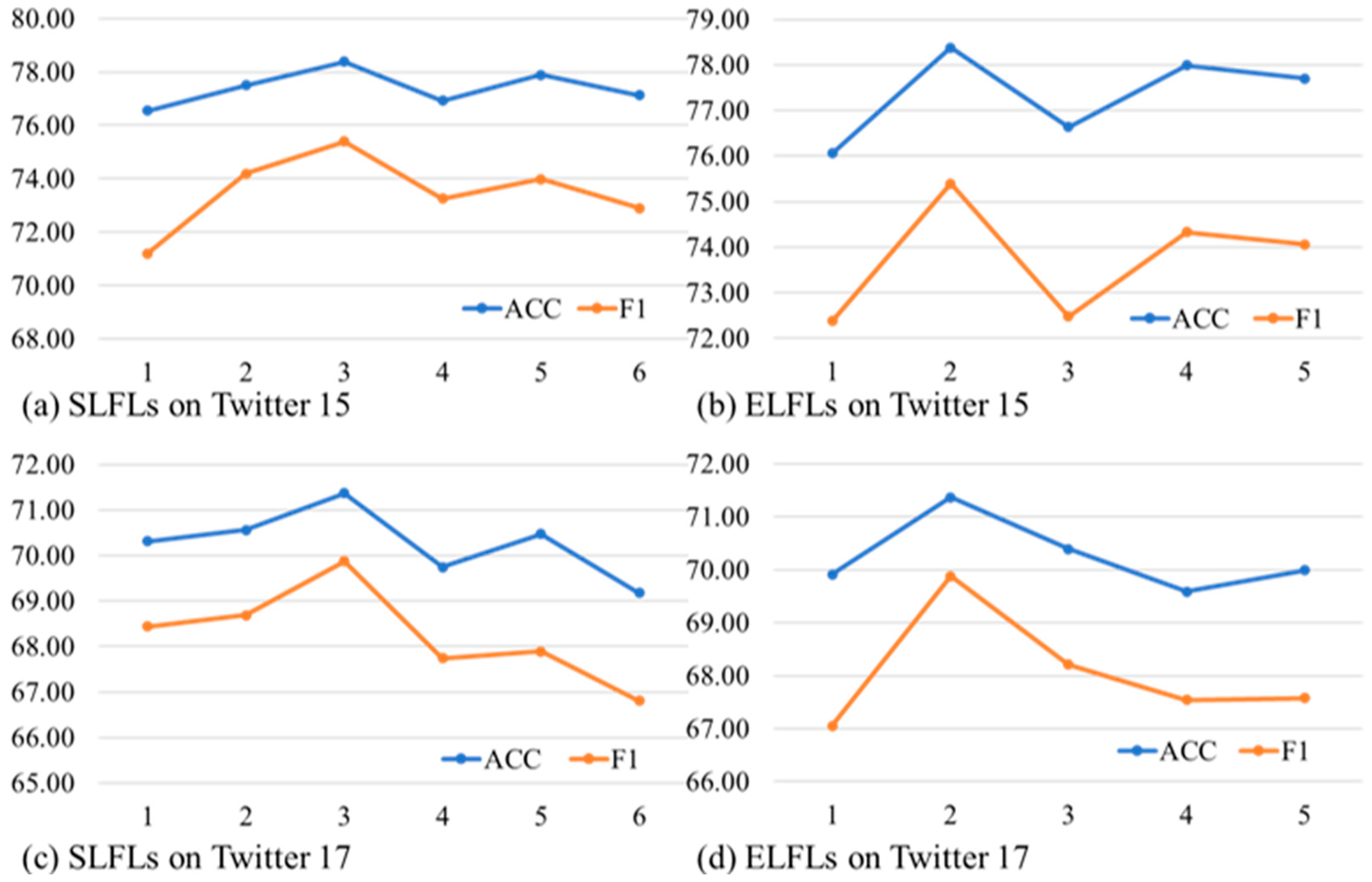
4.4. Ablation Studies
4.5. Case Study
5. Conclusions
6. Limitations and Further Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fellnhofer, K. Positivity and Higher Alertness Levels Facilitate Discovery: Longitudinal Sentiment Analysis of Emotions on Twitter. Technovation 2023, 122, 102666. [Google Scholar] [CrossRef]
- Li, J.; Wu, X.; Zhang, Y.; Yang, H.; Wu, X. DRS-Net: A Spatial–Temporal Affective Computing Model Based on Multichannel EEG Data. Biomed. Signal Process. Control 2022, 76, 103660. [Google Scholar] [CrossRef]
- Thakur, N. Sentiment Analysis and Text Analysis of the Public Discourse on Twitter about COVID-19 and MPox. Big Data Cogn. Comput. 2023, 7, 116. [Google Scholar] [CrossRef]
- Mehra, P. Unexpected Surprise: Emotion Analysis and Aspect Based Sentiment Analysis (ABSA) of User Generated Comments to Study Behavioral Intentions of Tourists. Tour. Manag. Perspect. 2023, 45, 101063. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis: A Survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Taherdoost, H.; Madanchian, M. Artificial Intelligence and Sentiment Analysis: A Review in Competitive Research. Computers 2023, 12, 37. [Google Scholar] [CrossRef]
- Vo, D.-T.; Zhang, Y. Target-Dependent Twitter Sentiment Classification with Rich Automatic Features. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; AAAI Press: Buenos Aires, Argentina, 2015; pp. 1347–1353. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. SemEval-2016 Task 5: Aspect Based Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 19–30. [Google Scholar]
- Ruder, S.; Ghaffari, P.; Breslin, J.G. A Hierarchical Model of Reviews for Aspect-Based Sentiment Analysis. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 999–1005. [Google Scholar]
- Liu, Q.; Zhang, H.; Zeng, Y.; Huang, Z.; Wu, Z. Content Attention Model for Aspect Based Sentiment Analysis. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; International World Wide Web Conferences Steering Committee Republic and Canton of Geneva: Geneva, Switzerland, 2018; pp. 1023–1032. [Google Scholar]
- Xue, W.; Li, T. Aspect Based Sentiment Analysis with Gated Convolutional Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 2514–2523. [Google Scholar]
- Xu, H.; Liu, B.; Shu, L.; Yu, P. BERT Post-Training for Review Reading Comprehension and Aspect-Based Sentiment Analysis. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 2324–2335. [Google Scholar]
- Sun, C.; Huang, L.; Qiu, X. Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 380–385. [Google Scholar]
- Geetha, M.P.; Karthika Renuka, D. Improving the Performance of Aspect Based Sentiment Analysis Using Fine-Tuned Bert Base Uncased Model. Int. J. Intell. Netw. 2021, 2, 64–69. [Google Scholar] [CrossRef]
- Xu, N.; Mao, W.; Chen, G. Multi-Interactive Memory Network for Aspect Based Multimodal Sentiment Analysis. Proc. AAAI Conf. Artif. Intell. 2019, 33, 371–378. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, J.; Xia, R. Entity-Sensitive Attention and Fusion Network for Entity-Level Multimodal Sentiment Classification. IEEEACM Trans. Audio Speech Lang. Process. 2020, 28, 429–439. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, J. Adapting BERT for Target-Oriented Multimodal Sentiment Classification. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; International Joint Conferences on Artificial Intelligence Organization: Macao, China, 2019; pp. 5408–5414. [Google Scholar]
- Yang, L.; Na, J.-C.; Yu, J. Cross-Modal Multitask Transformer for End-to-End Multimodal Aspect-Based Sentiment Analysis. Inf. Process. Manag. 2022, 59, 103038. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; Zhao, T. Target-Dependent Twitter Sentiment Classification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Portland, OR, USA, 2011; pp. 151–160. [Google Scholar]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. NRC-Canada-2014: Detecting Aspects and Sentiment in Customer Reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 437–442. [Google Scholar]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive Recursive Neural Network for Target-Dependent Twitter Sentiment Classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 23–24 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 49–54. [Google Scholar]
- Liu, F.; Cohn, T.; Baldwin, T. Recurrent Entity Networks with Delayed Memory Update for Targeted Aspect-Based Sentiment Analysis. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 278–283. [Google Scholar]
- Ma, Y.; Peng, H.; Cambria, E. Targeted Aspect-Based Sentiment Analysis via Embedding Commonsense Knowledge into an Attentive LSTM. Proc. AAAI Conf. Artif. Intell. 2018, 32. [Google Scholar] [CrossRef]
- Hoang, M.; Bihorac, O.A.; Rouces, J. Aspect-Based Sentiment Analysis Using BERT. In Proceedings of the 22nd Nordic Conference on Computational Linguistics, Turku, Finland, 30 September–2 October 2019; Linköping University Electronic Press: Turku, Finland, 2019; pp. 187–196. [Google Scholar]
- Essebbar, A.; Kane, B.; Guinaudeau, O.; Chiesa, V.; Quénel, I.; Chau, S. Aspect Based Sentiment Analysis Using French Pre-Trained Models. In Proceedings of the 13th International Conference on Agents and Artificial Intelligence, Online, 4–6 February 2021; SCITEPRESS-Science and Technology Publications: Vienna, Austria, 2021; pp. 519–525. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-Based Sentiment Classification with Aspect-Specific Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 4568–4578. [Google Scholar]
- Kipf, T.N. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Chen, C.; Teng, Z.; Zhang, Y. Inducing Target-Specific Latent Structures for Aspect Sentiment Classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, Canada, 2020; pp. 5596–5607. [Google Scholar]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-Based Sentiment Analysis via Affective Knowledge Enhanced Graph Convolutional Networks. Knowl. -Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Cambria, E.; Speer, R.; Havasi, C.; Hussain, A. Senticnet: A publicly available semantic resource for opinion mining. In Proceedings of the 2010 AAAI Fall Symposium Series, Arlington, VA, USA, 11–13 November 2010. [Google Scholar]
- Nandi, B.P.; Jain, A.; Tayal, D.K. Aspect Based Sentiment Analysis Using Long-Short Term Memory and Weighted N-Gram Graph-Cut. Cogn. Comput. 2023, 15, 822–837. [Google Scholar] [CrossRef]
- Chen, M.; Wang, S.; Liang, P.P.; Baltrušaitis, T.; Zadeh, A.; Morency, L.-P. Multimodal Sentiment Analysis with Word-Level Fusion and Reinforcement Learning. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 163–171. [Google Scholar]
- Hazarika, D.; Zimmermann, R.; Poria, S. MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1122–1131. [Google Scholar]
- Paraskevopoulos, G.; Georgiou, E.; Potamianos, A. Mmlatch: Bottom-Up Top-Down Fusion For Multimodal Sentiment Analysis. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 4573–4577. [Google Scholar]
- Li, Z.; Xu, B.; Zhu, C.; Zhao, T. CLMLF: A Contrastive Learning and Multi-Layer Fusion Method for Multimodal Sentiment Detection. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2022, Online, 10–15 July 2022; Association for Computational Linguistics: Seattle, WA, USA, 2022; pp. 2282–2294. [Google Scholar]
- Wang, D.; Guo, X.; Tian, Y.; Liu, J.; He, L.; Luo, X. TETFN: A Text Enhanced Transformer Fusion Network for Multimodal Sentiment Analysis. Pattern Recognit. 2023, 136, 109259. [Google Scholar] [CrossRef]
- Gu, D.; Wang, J.; Cai, S.; Yang, C.; Song, Z.; Zhao, H.; Xiao, L.; Wang, H. Targeted Aspect-Based Multimodal Sentiment Analysis: An Attention Capsule Extraction and Multi-Head Fusion Network. IEEE Access 2021, 9, 157329–157336. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1724–1734. [Google Scholar]
- Khan, Z.; Fu, Y. Exploiting BERT for Multimodal Target Sentiment Classification through Input Space Translation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3034–3042. [Google Scholar]
- Mokady, R.; Hertz, A.; Bermano, A.H. Clipcap: Clip prefix for image captioning. arXiv 2021, arXiv:2111.09734. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-Based LSTM for Aspect-Level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 606–615. [Google Scholar]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent Attention Network on Memory for Aspect Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 452–461. [Google Scholar]
- Fan, F.; Feng, Y.; Zhao, D. Multi-Grained Attention Network for Aspect-Level Sentiment Classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 3433–3442. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Split | Twitter-15 | Twitter-17 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pos | Neu | Neg | Total | AvgAspect | Len | Pos | Neu | Neg | Total | AvgAspect | Len | |
| Train | 928 | 1883 | 368 | 3179 | 1.34 | 16.72 | 1508 | 1638 | 412 | 3562 | 1.41 | 16.21 |
| Valid | 303 | 670 | 149 | 1122 | 1.33 | 16.74 | 512 | 517 | 144 | 1176 | 1.43 | 16.37 |
| Test | 317 | 607 | 113 | 1037 | 1.35 | 17.05 | 493 | 573 | 168 | 1234 | 1.45 | 16.38 |
| Parameters | Value |
|---|---|
| Max length of sentence | 50 |
| Max length of image caption | 50 |
| Embedding dimension | 400 |
| Layer number for Element-level fusion | 3 |
| Head number for cross-attention | 5 |
| Layer number for Structure-level fusion | 2 |
| Head number for graph attention | 2 |
| Weight for MBCL, | 1 |
| Weight for LBCL, | 1 |
| Batch size | 16 |
| Learning rate | 2 × 10−5 |
| Weight decay | 5 × 10−3 |
| Dropout rate | 0.5 |
| Max length of sentence | 50 |
| Max length of image caption | 50 |
| Embedding dimension | 400 |
| Modality | Method | Twitter-15 | Twitter-17 | ||
|---|---|---|---|---|---|
| ACC | F1 | ACC | F1 | ||
| Image | ResNet-Aspect | 59.49 | 47.79 | 57.86 | 53.98 |
| Text | ATAE | 70.30 | 63.43 | 61.67 | 57.97 |
| RAM | 70.68 | 63.05 | 64.42 | 61.01 | |
| MGAN | 71.17 | 64.21 | 64.75 | 61.46 | |
| BERT | 74.15 | 68.86 | 68.15 | 65.23 | |
| Image + text | MIMN | 71.84 | 65.59 | 65.88 | 62.99 |
| ESAFN | 73.38 | 67.37 | 67.83 | 64.22 | |
| EF-Net | 73.65 | 67.9 | 67.77 | 65.32 | |
| ViBERT | 73.76 | 69.85 | 67.42 | 64.87 | |
| TomBERT | 77.15 | 71.75 | 70.34 | 68.03 | |
| EF-CapTrBERT | 78.03 | 73.25 | 69.77 | 68.42 | |
| HF-EKCL (ours) | 78.38 | 75.39 | 71.37 | 69.88 | |
| Method | Twitter-15 | Twitter-17 | ||
|---|---|---|---|---|
| ACC | F1 | ACC | F1 | |
| w/o Contrastive learning | 76.83 | 73.09 | 70.48 | 68.65 |
| w/o enhanced knowledge | 77.90 | 73.93 | 71.05 | 69.03 |
| w/o structure-level fusion | 76.83 | 72.08 | 69.42 | 67.80 |
| HF-EKCL | 78.38 | 75.39 | 71.37 | 69.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Yamamura, M. Hierarchical Fusion Network with Enhanced Knowledge and Contrastive Learning for Multimodal Aspect-Based Sentiment Analysis on Social Media. Sensors 2023, 23, 7330. https://doi.org/10.3390/s23177330
Hu X, Yamamura M. Hierarchical Fusion Network with Enhanced Knowledge and Contrastive Learning for Multimodal Aspect-Based Sentiment Analysis on Social Media. Sensors. 2023; 23(17):7330. https://doi.org/10.3390/s23177330
Chicago/Turabian StyleHu, Xiaoran, and Masayuki Yamamura. 2023. "Hierarchical Fusion Network with Enhanced Knowledge and Contrastive Learning for Multimodal Aspect-Based Sentiment Analysis on Social Media" Sensors 23, no. 17: 7330. https://doi.org/10.3390/s23177330
APA StyleHu, X., & Yamamura, M. (2023). Hierarchical Fusion Network with Enhanced Knowledge and Contrastive Learning for Multimodal Aspect-Based Sentiment Analysis on Social Media. Sensors, 23(17), 7330. https://doi.org/10.3390/s23177330