

Quality Control of Carbon Look Components via Surface Defect Classification with Deep Neural Networks


 , , ,
, , ,  ,
,  and
and
Abstract
:1. Introduction
- A new database composed of plain images of CFRP-covered components for the automotive sector is introduced. The database is intended to train and benchmark techniques to classify defective and non-defective parts, as well as for multi-class classification into non-defective, recoverable, and non-recoverable components, using the pictures only, without thermography or any other NDT techniques. The database includes 400 images (200 per class) intended for the binary classification task and 1500 images (500 per class) for the multi-class classification. All the images are 224 × 224 pixels (96 ppi) in a JPEG format. The database is publicly released in an open-access GitHub repository (the image database is publicly available at: https://github.com/airtlab/surface-defect-classification-in-carbon-look-components-dataset, accessed on 10 July 2023).
- A systematic comparison of ten models for the classification of surface defects is provided. The models are deep neural networks based on ten pre-trained Convolutional Neural Networks (CNNs), implemented to process the samples end to end, testing the effectiveness of transfer learning and fine tuning in the classification of the surface defects of carbon look components. Specifically, the tested pre-trained CNNs are VGG16 and VGG19 [21], ResNet50 version 2, ResNet101 version 2, and ResNet152 version 2 [22], Inception version 3 [23], MobileNet version 2 [24], NASNetMobile [25], DenseNet121 [26], and Xception [27]. The CNNs are combined with fully connected layers, trained from scratch on the proposed dataset. The source code of the comparison is publicly available in a GitHub repository (the source code of the experiments is publicly available at: https://github.com/airtlab/surface-defect-classification-in-carbon-look-components-using-deep-neural-networks, accessed on 10 July 2023).
- A real application of Industry 4.0 is demonstrated, proposing the use of DL to automate the control of surface defects of carbon look components.
2. Related Works
- They apply DL on top of NDT techniques, such as Infrared Thermography, to detect structural and inner defects inside the composite materials.
- They do not publicly release the data and the source code of the experiments performed to collect the accuracy metrics.
3. Materials and Methods
3.1. Proposed Image Database
- One dataset is binary, including two classes. A total of 200 images are labeled as “no defect” (Figure 1a), as they are with no defects or present limited recoverable porosities; 200 images are labeled as “defect” (Figure 1b), as they include weft discontinuities. This set of images is intended for binary classification, to test the performance of models that sort the components into defective or non-defective.
- The second dataset is multi-class, including three classes, i.e., “no defect”, with recoverable defects, and with non-recoverable defects. The dataset contains 1500 images, 500 per class. The “no defect” class (Figure 2a) includes images of components without any surface defect. The recoverable defect class (Figure 2b) includes images of components with limited porosities and the infiltration of external materials (such as aluminum). Such defects can be treated and corrected. Finally, the non-recoverable defect class (Figure 2c) includes images of components with weft discontinuites, severe porosities, and resin accumulations. In “HP Composite Spa”, these components are discarded, as their appearance cannot be recovered. With such dataset, we test the capability of the proposed models to classify multiple defect classes.
- Isolated porosities, i.e., isolated holes in the surface of the material that only damage the aesthetic performance, but not the structural tightness (an example is provided in Figure 2b).
- Infiltration of foreign objects (aluminum or polyethylene) on the material surface that can be removed.
- Severe porosities, i.e., where the holes in the surface of the material are not isolated and cover most of the surface (an example is provided in Figure 2c).
- Weft discontinuities, i.e., all the cases in which the characteristic texture of the interwoven carbon fiber bundles is altered, generally caused by a wrong overlapping of the materials or poor fiber adhesion to the mold (an example is provided in Figure 1b).
- Accumulations of resin caused by the imperfect calibration of the spaces between the two fiber molds and the silicone mandrel interposed between them.
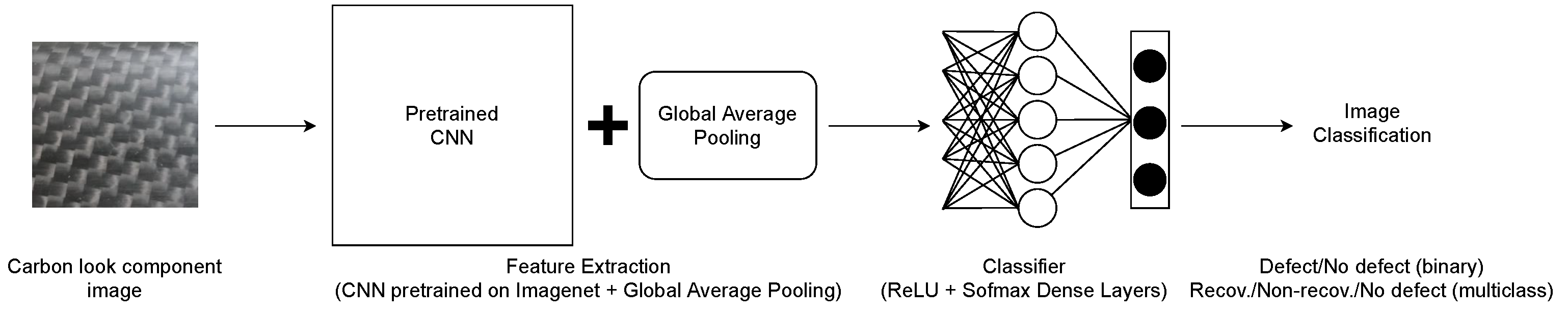
3.2. Proposed Classification Model
- The number of the CNN final layers to be fine-tuned on the proposed dataset, testing 8, 4, and 0. This means that, during the end-to-end training of the model, the weights were freezed for the starting layers of the pre-trained CNNs, while for the last 8 (or 4 or none) layers, the weights were modified with the backpropagation.
- The optimizer to perform the error backpropagation, testing the Stochastic Gradient Descent (SGD) with a 0.9 momentum and Adam. For both, we compared different learning rates, i.e., 0.001 and 0.0001.
- The use of Batch Normalization for regularization between the Global Average Pooling and the first dense layer.
- The number of fully connected layers to be added to the pre-trained CNNs to perform the final classification. Specifically, we tested a single dense layer composed of 512 ReLU neurons followed by a final layer with Softmax activation, and two dense layers composed of 256 and 128 ReLU layers, followed by the Softmax layer.
4. Experimental Evaluation
4.1. Evaluation Protocol and Metrics
- The precision for each class, i.e., the ratio between the number of samples correctly classified as belonging to a class and the total number of samples labeled as that class in the test set.
- The recall for each class, i.e., the ratio between the number of samples correctly classified as belonging to a class and the total number of samples available for that class in the test set.
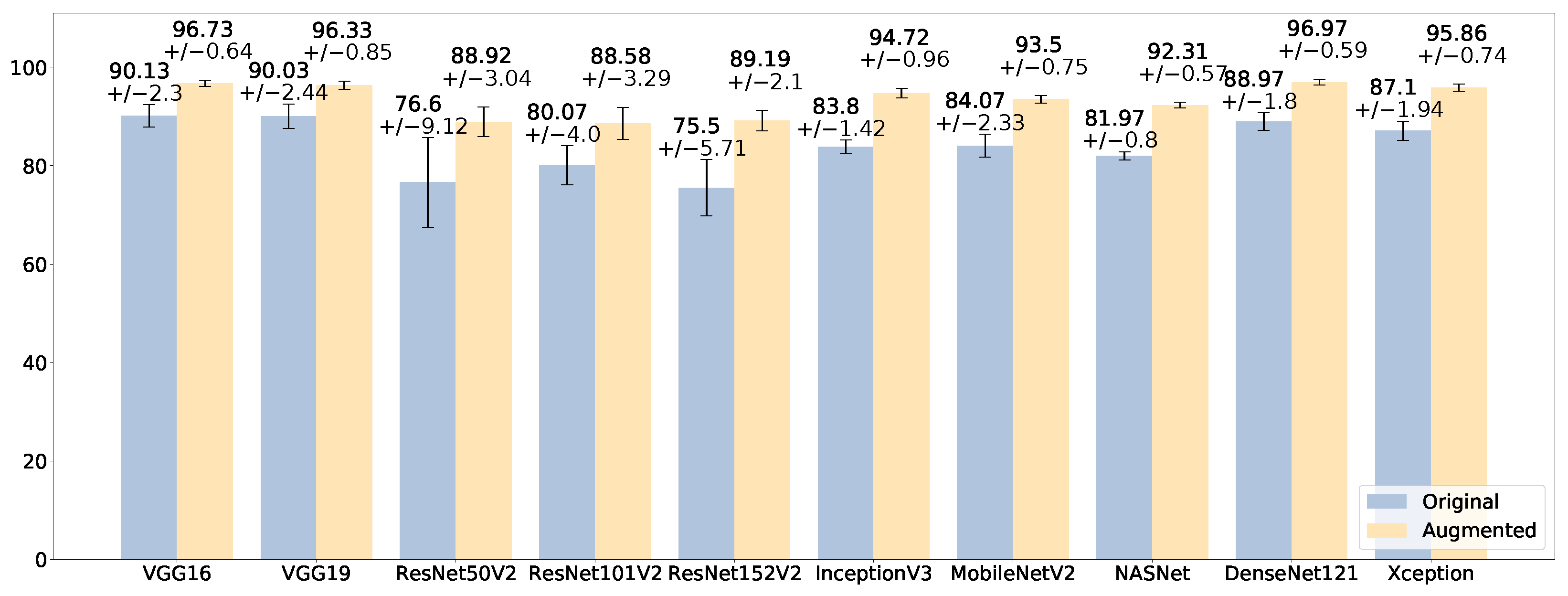
4.2. Results and Discussion
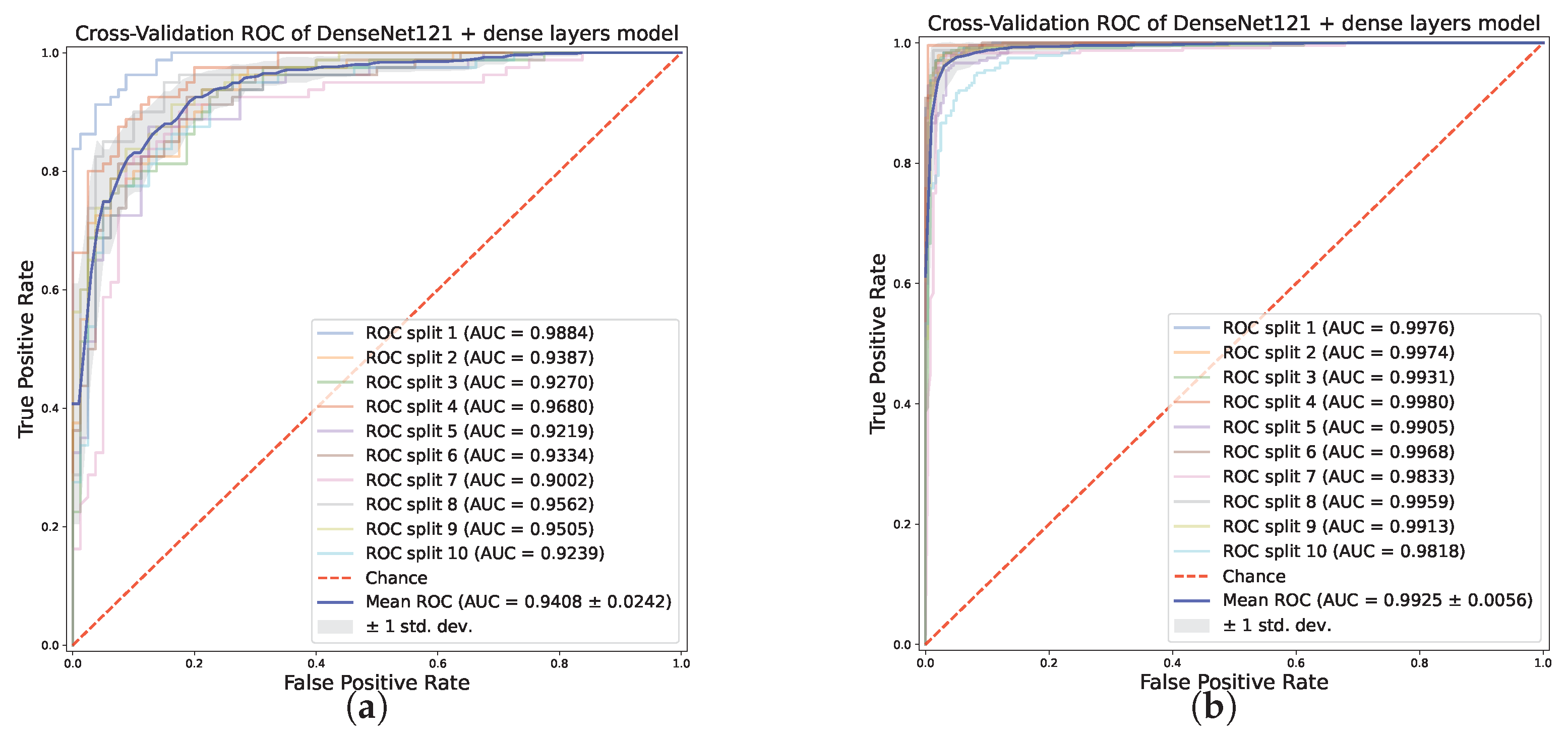
4.2.1. Results on the Binary Classification Task
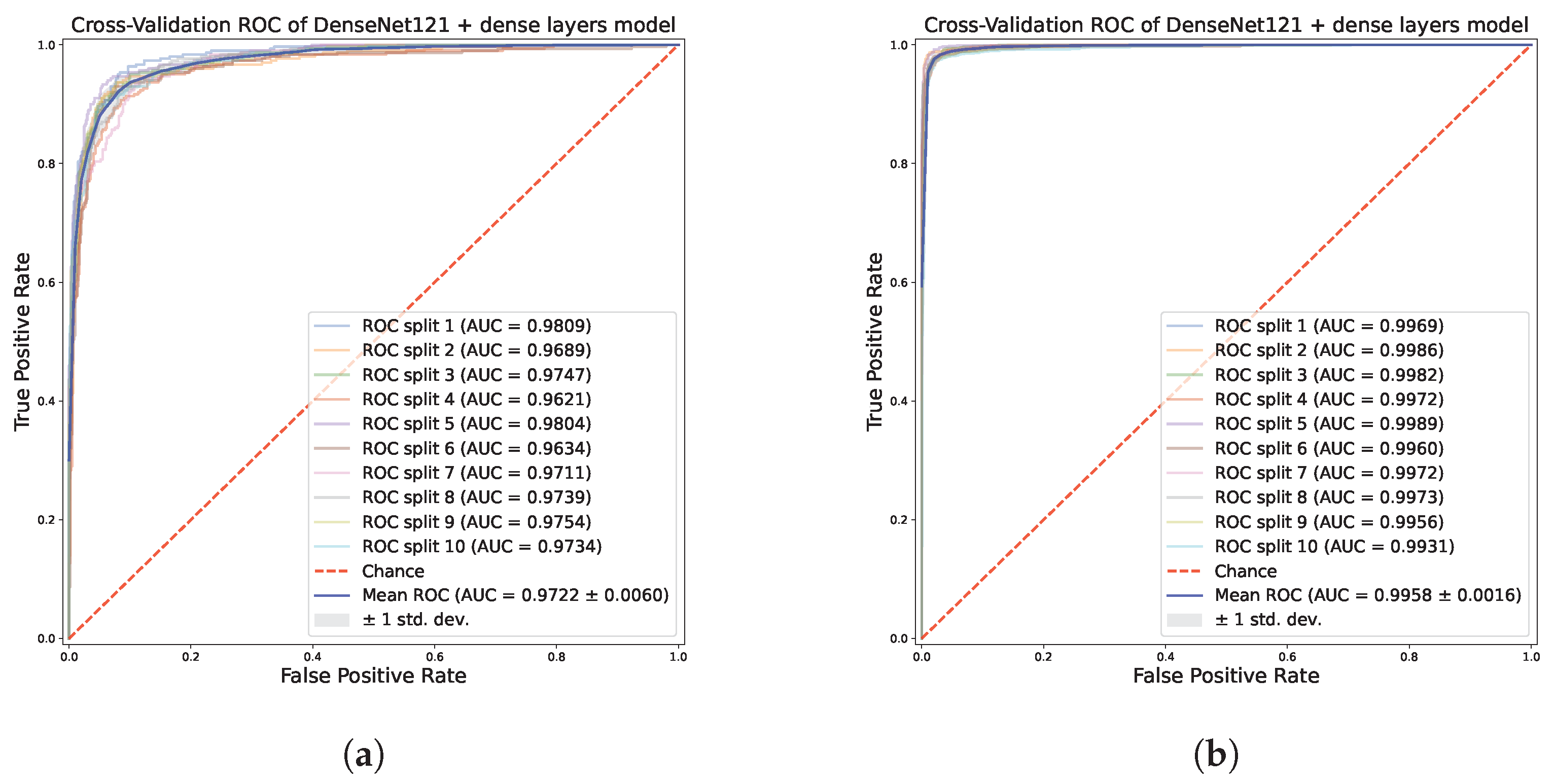
4.2.2. Results on the Multi-Class Classification
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lasi, H.; Fettke, P.; Kemper, H.G.; Feld, T.; Hoffmann, M. Industry 4.0. Bus. Inf. Syst. Eng. 2014, 6, 239–242. [Google Scholar] [CrossRef]
- Lee, J.; Davari, H.; Singh, J.; Pandhare, V. Industrial Artificial Intelligence for industry 4.0-based manufacturing systems. Manuf. Lett. 2018, 18, 20–23. [Google Scholar] [CrossRef]
- Zenisek, J.; Holzinger, F.; Affenzeller, M. Machine learning based concept drift detection for predictive maintenance. Comput. Ind. Eng. 2019, 137, 106031. [Google Scholar] [CrossRef]
- Zhou, X.; Hu, Y.; Liang, W.; Ma, J.; Jin, Q. Variational LSTM Enhanced Anomaly Detection for Industrial Big Data. IEEE Trans. Ind. Inform. 2021, 17, 3469–3477. [Google Scholar] [CrossRef]
- Gao, Z.; Dong, G.; Tang, Y.; Zhao, Y.F. Machine learning aided design of conformal cooling channels for injection molding. J. Intell. Manuf. 2021, 34, 1183–1201. [Google Scholar] [CrossRef]
- Cadavid, J.P.U.; Lamouri, S.; Grabot, B.; Pellerin, R.; Fortin, A. Machine learning applied in production planning and control: A state-of-the-art in the era of industry 4.0. J. Intell. Manuf. 2020, 31, 1531–1558. [Google Scholar] [CrossRef]
- Peres, R.S.; Barata, J.; Leitao, P.; Garcia, G. Multistage Quality Control Using Machine Learning in the Automotive Industry. IEEE Access 2019, 7, 79908–79916. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using Deep Learning to Detect Defects in Manufacturing: A Comprehensive Survey and Current Challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef]
- Obregon, J.; Hong, J.; Jung, J.Y. Rule-based explanations based on ensemble machine learning for detecting sink mark defects in the injection moulding process. J. Manuf. Syst. 2021, 60, 392–405. [Google Scholar] [CrossRef]
- Polenta, A.; Tomassini, S.; Falcionelli, N.; Contardo, P.; Dragoni, A.F.; Sernani, P. A Comparison of Machine Learning Techniques for the Quality Classification of Molded Products. Information 2022, 13, 272. [Google Scholar] [CrossRef]
- Nash, W.; Drummond, T.; Birbilis, N. A review of deep learning in the study of materials degradation. npj Mater. Degrad. 2018, 2, 37. [Google Scholar] [CrossRef]
- Jorge Aldave, I.; Venegas Bosom, P.; Vega González, L.; López de Santiago, I.; Vollheim, B.; Krausz, L.; Georges, M. Review of thermal imaging systems in composite defect detection. Infrared Phys. Technol. 2013, 61, 167–175. [Google Scholar] [CrossRef]
- Poór, D.I.; Geier, N.; Pereszlai, C.; Xu, J. A critical review of the drilling of CFRP composites: Burr formation, characterisation and challenges. Compos. Part B Eng. 2021, 223, 109155. [Google Scholar] [CrossRef]
- Amor, N.; Noman, M.T.; Petru, M. Classification of Textile Polymer Composites: Recent Trends and Challenges. Polymers 2021, 13, 2592. [Google Scholar] [CrossRef]
- Vedernikov, A.; Tucci, F.; Carlone, P.; Gusev, S.; Konev, S.; Firsov, D.; Akhatov, I.; Safonov, A. Effects of pulling speed on structural performance of L-shaped pultruded profiles. Compos. Struct. 2021, 255, 112967. [Google Scholar] [CrossRef]
- Bang, H.T.; Park, S.; Jeon, H. Defect identification in composite materials via thermography and deep learning techniques. Compos. Struct. 2020, 246, 112405. [Google Scholar] [CrossRef]
- Liu, K.; Li, Y.; Yang, J.; Liu, Y.; Yao, Y. Generative Principal Component Thermography for Enhanced Defect Detection and Analysis. IEEE Trans. Instrum. Meas. 2020, 69, 8261–8269. [Google Scholar] [CrossRef]
- Fang, Q.; Ibarra-Castanedo, C.; Maldague, X. Automatic Defects Segmentation and Identification by Deep Learning Algorithm with Pulsed Thermography: Synthetic and Experimental Data. Big Data Cogn. Comput. 2021, 5, 9. [Google Scholar] [CrossRef]
- Wei, Z.; Fernandes, H.; Herrmann, H.G.; Tarpani, J.R.; Osman, A. A Deep Learning Method for the Impact Damage Segmentation of Curve-Shaped CFRP Specimens Inspected by Infrared Thermography. Sensors 2021, 21, 395. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Bray, D.E.; McBride, D. Nondestructive Testing Techniques; NASA STI/Recon Technical Report A; Wiley: Hoboken, NJ, USA, 1992; Volume 93, p. 17573. [Google Scholar]
- Gholizadeh, S. A review of non-destructive testing methods of composite materials. Procedia Struct. Integr. 2016, 1, 50–57. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Ma, Z.; Liu, Y.; Yang, J.; Yao, Y. Enhanced Defect Detection in Carbon Fiber Reinforced Polymer Composites via Generative Kernel Principal Component Thermography. Polymers 2021, 13, 825. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:abs/1502.03167. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Marani, R.; Palumbo, D.; Galietti, U.; D’Orazio, T. Deep learning for defect characterization in composite laminates inspected by step-heating thermography. Opt. Lasers Eng. 2021, 145, 106679. [Google Scholar] [CrossRef]
- Meng, M.; Chua, Y.J.; Wouterson, E.; Ong, C.P.K. Ultrasonic signal classification and imaging system for composite materials via deep convolutional neural networks. Neurocomputing 2017, 257, 128–135. [Google Scholar] [CrossRef]
- Gong, Y.; Shao, H.; Luo, J.; Li, Z. A deep transfer learning model for inclusion defect detection of aeronautics composite materials. Compos. Struct. 2020, 252, 112681. [Google Scholar] [CrossRef]
- Gao, Y.; Li, X.; Wang, X.V.; Wang, L.; Gao, L. A Review on Recent Advances in Vision-based Defect Recognition towards Industrial Intelligence. J. Manuf. Syst. 2022, 62, 753–766. [Google Scholar] [CrossRef]
- Yun, J.P.; Shin, W.C.; Koo, G.; Kim, M.S.; Lee, C.; Lee, S.J. Automated defect inspection system for metal surfaces based on deep learning and data augmentation. J. Manuf. Syst. 2020, 55, 317–324. [Google Scholar] [CrossRef]
- Chen, W.; Gao, Y.; Gao, L.; Li, X. A New Ensemble Approach based on Deep Convolutional Neural Networks for Steel Surface Defect classification. Procedia CIRP 2018, 72, 1069–1072. [Google Scholar] [CrossRef]
- Boikov, A.; Payor, V.; Savelev, R.; Kolesnikov, A. Synthetic Data Generation for Steel Defect Detection and Classification Using Deep Learning. Symmetry 2021, 13, 1176. [Google Scholar] [CrossRef]
- Liu, J.; Wang, C.; Su, H.; Du, B.; Tao, D. Multistage GAN for Fabric Defect Detection. IEEE Trans. Image Process. 2020, 29, 3388–3400. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Han, G.; Jia, G.; Shu, L. Modified DenseNet for Automatic Fabric Defect Detection with Edge Computing for Minimizing Latency. IEEE Internet Things J. 2020, 7, 9623–9636. [Google Scholar] [CrossRef]
- Gao, Y.; Gao, L.; Li, X.; Wang, X.V. A Multilevel Information Fusion-Based Deep Learning Method for Vision-Based Defect Recognition. IEEE Trans. Instrum. Meas. 2020, 69, 3980–3991. [Google Scholar] [CrossRef]
- Urbonas, A.; Raudonis, V.; Maskeliūnas, R.; Damaševičius, R. Automated Identification of Wood Veneer Surface Defects Using Faster Region-Based Convolutional Neural Network with Data Augmentation and Transfer Learning. Appl. Sci. 2019, 9, 4898. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Misra, I.; Zitnick, C.L.; Hebert, M. Shuffle and learn: Unsupervised learning using temporal order verification. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 527–544. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Huh, M.; Agrawal, P.; Efros, A.A. What makes ImageNet good for transfer learning? arXiv 2016, arXiv:1608.08614. [Google Scholar]
- Wu, J.; Leng, C.; Wang, Y.; Hu, Q.; Cheng, J. Quantized Convolutional Neural Networks for Mobile Devices. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4820–4828. [Google Scholar] [CrossRef]
- Li, D.; Wang, X.; Kong, D. DeepRebirth: Accelerating Deep Neural Network Execution on Mobile Devices. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, pp. 2322–2330. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fine-Tuning | Optimizer | Learning Rate | Batch Normalization | Dense 512 Units | Dense 256 Units | Dense 128 Units | |
|---|---|---|---|---|---|---|---|
| VGG16 | Last 8 | SGD | 0.0001 | - | ✓ | - | - |
| VGG19 | Last 8 | SGD | 0.001 | - | ✓ | - | - |
| ResNet50V2 | Last 8 | Adam | 0.0001 | - | ✓ | - | - |
| ResNet101V2 | Last 8 | Adam | 0.001 | - | ✓ | - | - |
| ResNet152V2 | Last 8 | Adam | 0.0001 | - | ✓ | - | - |
| InceptionV3 | Last 8 | SGD | 0.001 | - | ✓ | - | - |
| MobileNetV2 | 0 | Adam | 0.001 | - | - | ✓ | ✓ |
| NASNet | Last 4 | Adam | 0.0001 | - | - | ✓ | ✓ |
| DenseNet121 | Last 8 | Adam | 0.0001 | - | ✓ | - | - |
| Xception | Last 4 | Adam | 0.0001 | - | - | ✓ | ✓ |
| Fine-Tuning | Optimizer | Learning Rate | Batch Normalization | Dense 512 Units | Dense 256 Units | Dense 128 Units | |
|---|---|---|---|---|---|---|---|
| VGG16 | Last 8 | SGD | 0.001 | ✓ | ✓ | - | - |
| VGG19 | Last 8 | SGD | 0.001 | ✓ | ✓ | - | - |
| ResNet50V2 | Last 8 | Adam | 0.001 | - | ✓ | - | - |
| ResNet101V2 | Last 8 | Adam | 0.001 | - | ✓ | - | - |
| ResNet152V2 | Last 8 | Adam | 0.0001 | - | ✓ | - | - |
| InceptionV3 | Last 8 | Adam | 0.0001 | - | ✓ | - | - |
| MobileNetV2 | Last 8 | SGD | 0.0001 | - | ✓ | - | - |
| NASNet | Last 8 | Adam | 0.0001 | - | ✓ | - | - |
| DenseNet121 | Last 8 | Adam | 0.0001 | - | ✓ | - | - |
| Xception | Last 8 | Adam | 0.0001 | - | ✓ | - | - |
| Dataset | Total | Training | Validation | Test |
|---|---|---|---|---|
| Original Binary | 400 | 280 | 40 | 80 |
| Augmented Binary | 1200 | 840 | 120 | 240 |
| Original Multi-class | 1500 | 1050 | 150 | 300 |
| Augmented Multi-class | 4500 | 3150 | 450 | 900 |
| No Defect | Defect | |||
|---|---|---|---|---|
| Precision | Recall | Precision | Recall | |
| VGG16 | 85.26 ± 4.08% | 79.00 ± 9.23% | 81.03 ± 6.48% | 86.00 ± 5.15% |
| VGG19 | 85.01 ± 6.89% | 81.25 ± 8.16% | 82.71 ± 6.58% | 84.50 ± 9.60% |
| ResNet50V2 | 87.68 ± 5.60% | 77.75 ± 7.37% | 80.26 ± 5.84% | 89.00 ± 4.77% |
| ResNet101V2 | 89.89 ± 12.43% | 60.00 ± 17.64% | 71.18 ± 8.56% | 88.25 ± 21.51% |
| ResNet152V2 | 82.36 ± 4.79% | 78.25 ± 6.23% | 79.54 ± 4.13% | 82.75 ± 6.37% |
| InceptionV3 | 83.86 ± 5.87% | 73.25 ± 10.31% | 76.80 ± 6.94% | 85.50 ± 6.60% |
| MobileNetV2 | 83.83 ± 4.85% | 75.75 ± 5.13% | 77.96 ± 3.26% | 85.00 ± 5.81% |
| NASNet | 84.97 ± 5.64% | 76.25 ± 7.00% | 78.62 ± 5.32% | 86.25 ± 5.94% |
| DenseNet121 | 87.22 ± 4.62% | 85.25 ± 3.61% | 85.60 ± 3.04% | 87.25 ± 5.41% |
| Xception | 89.57 ± 2.69% | 87.64 ± 4.70% | 87.00 ± 5.68% | 89.75 ± 3.05% |
| No-Defect | Defect | |||
|---|---|---|---|---|
| Precision | Recall | Precision | Recall | |
| VGG16 | 93.71 ± 2.10% | 93.00 ± 3.01% | 93.10 ± 2.82% | 93.75 ± 2.12% |
| VGG19 | 94.45 ± 3.69% | 93.42 ± 3.34% | 93.58 ± 2.97% | 94.33 ± 4.15% |
| ResNet50V2 | 94.92 ± 3.40% | 94.75 ± 2.91% | 94.86 ± 2.56% | 94.75 ± 3.93% |
| ResNet101V2 | 92.58 ± 3.14% | 94.00 ± 3.09% | 94.00 ± 2.87% | 92.33 ± 3.45% |
| ResNet152V2 | 92.43 ± 2.08% | 91.67 ± 2.86% | 91.82 ± 2.43% | 92.42 ± 2.37% |
| InceptionV3 | 94.44 ± 4.12% | 91.33 ± 3.21% | 91.62 ± 3.01% | 94.50 ± 4.38% |
| MobileNetV2 | 96.88 ± 1.17% | 95.42 ± 1.50% | 95.50 ± 1.43% | 96.92 ± 1.18% |
| NASNet | 94.36 ± 2.42% | 92.33 ± 2.20% | 92.53 ± 1.98% | 94.42 ± 2.58% |
| DenseNet121 | 96.82 ± 2.43% | 97.33 ± 1.66% | 97.33 ± 1.63% | 96.75 ± 2.59% |
| Xception | 96.63 ± 1.37% | 97.17 ± 1.55% | 97.18 ± 1.50% | 96.58 ± 1.46% |
| No Defect | Recoverable | Non-Recoverable | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | |
| VGG16 | 88.05 ± 2.52% | 90.80 ± 2.96% | 89.93 ± 4.36% | 91.10 ± 3.11% | 93.00 ± 3.12% | 88.50 ± 4.50% |
| VGG19 | 88.89 ± 3.39% | 89.40 ± 4.50% | 89.70 ± 3.76% | 89.40 ± 3.80% | 91.95 ± 3.78% | 91.30 ± 2.57% |
| ResNet50V2 | 82.61 ± 5.45% | 61.60 ± 21.20% | 76.31 ± 7.41% | 79.70 ± 9.58% | 76.09 ± 12.47% | 88.50 ± 2.69% |
| ResNet101V2 | 79.19 ± 3.94% | 74.80 ± 11.04% | 80.93 ± 6.92% | 77.80 ± 5.36% | 81.38 ± 5.39% | 87.60 ± 5.68% |
| ResNet152V2 | 74.03 ± 4.89% | 72.60 ± 12.03% | 83.20 ± 7.15% | 69.90 ± 6.49% | 72.96 ± 9.34% | 84.00 ± 6.13% |
| InceptionV3 | 82.21 ± 3.83% | 79.60 ± 2.73% | 83.27 ± 1.90% | 83.60 ± 4.76% | 86.21 ± 2.72% | 88.20 ± 2.44% |
| MobileNetV2 | 78.01 ± 3.18% | 88.60 ± 3.01% | 85.14 ± 3.03% | 83.00 ± 3.19% | 91.00 ± 2.78% | 80.60 ± 5.10% |
| NASNet | 78.76 ± 3.02% | 77.50 ± 3.61% | 84.52 ± 2.99% | 83.70 ± 3.16% | 83.04 ± 2.52% | 84.70 ± 3.55% |
| DenseNet121 | 86.02 ± 2.85% | 87.10 ± 3.48% | 89.90 ± 3.02% | 88.40 ± 2.80% | 91.37 ± 3.53% | 91.40 ± 2.94% |
| Xception | 83.92 ± 3.95% | 87.10 ± 3.70% | 87.57 ± 2.41% | 87.30 ± 3.72% | 90.46 ± 3.79% | 86.90 ± 2.88% |
| No Defect | Recoverable | Non-Recoverable | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | |
| VGG16 | 95.54 ± 1.36% | 97.93 ± 0.94% | 97.96 ± 1.00% | 96.77 ± 1.21% | 96.80 ± 1.11% | 95.50 ± 1.39% |
| VGG19 | 95.29 ± 1.51% | 97.13 ± 1.14% | 97.17 ± 0.88% | 95.93 ± 1.39% | 96.61 ± 0.88% | 95.93 ± 1.67% |
| ResNet50V2 | 89.20 ± 3.61% | 85.93 ± 6.42% | 88.28 ± 5.15% | 90.97 ± 2.48% | 90.23 ± 4.49% | 89.87 ± 6.23% |
| ResNet101V2 | 87.27 ± 3.72% | 85.80 ± 9.26% | 91.78 ± 4.46% | 87.97 ± 3.84% | 87.81 ± 4.97% | 91.97 ± 3.63% |
| ResNet152V2 | 89.37 ± 3.36% | 86.93 ± 4.78% | 89.07 ± 2.96% | 90.47 ± 2.81% | 89.84 ± 4.84% | 90.17 ± 4.32% |
| InceptionV3 | 93.51 ± 1.77% | 95.13 ± 1.28% | 95.78 ± 0.61% | 94.60 ± 1.55% | 94.96 ± 1.44% | 94.43 ± 1.41% |
| MobileNetV2 | 91.05 ± 0.79% | 94.63 ± 1.26% | 95.45 ± 1.31% | 92.70 ± 1.33% | 94.21 ± 1.78% | 93.17 ± 1.34% |
| NASNet | 90.97 ± 1.20% | 92.47 ± 2.14% | 93.38 ± 1.57% | 91.20 ± 0.56% | 92.71 ± 1.33% | 93.27 ± 1.21% |
| DenseNet121 | 95.85 ± 1.38% | 97.20 ± 0.78% | 97.81 ± 0.91% | 96.30 ± 1.22% | 97.31 ± 0.96% | 97.40 ± 1.10% |
| Xception | 94.08 ± 1.72% | 96.77 ± 0.88% | 97.32 ± 1.24% | 95.83 ± 1.54% | 96.33 ± 1.24% | 94.97 ± 1.57% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silenzi, A.; Castorani, V.; Tomassini, S.; Falcionelli, N.; Contardo, P.; Bonci, A.; Dragoni, A.F.; Sernani, P. Quality Control of Carbon Look Components via Surface Defect Classification with Deep Neural Networks. Sensors 2023, 23, 7607. https://doi.org/10.3390/s23177607
Silenzi A, Castorani V, Tomassini S, Falcionelli N, Contardo P, Bonci A, Dragoni AF, Sernani P. Quality Control of Carbon Look Components via Surface Defect Classification with Deep Neural Networks. Sensors. 2023; 23(17):7607. https://doi.org/10.3390/s23177607
Chicago/Turabian StyleSilenzi, Andrea, Vincenzo Castorani, Selene Tomassini, Nicola Falcionelli, Paolo Contardo, Andrea Bonci, Aldo Franco Dragoni, and Paolo Sernani. 2023. "Quality Control of Carbon Look Components via Surface Defect Classification with Deep Neural Networks" Sensors 23, no. 17: 7607. https://doi.org/10.3390/s23177607
APA StyleSilenzi, A., Castorani, V., Tomassini, S., Falcionelli, N., Contardo, P., Bonci, A., Dragoni, A. F., & Sernani, P. (2023). Quality Control of Carbon Look Components via Surface Defect Classification with Deep Neural Networks. Sensors, 23(17), 7607. https://doi.org/10.3390/s23177607