1. Introduction
Hyperspectral image data are acquired through hyperspectral sensors, capturing both spatial and spectral information from the visible to infrared spectrum for each pixel [
1]. These images provide detailed spatial characteristics of objects along with their continuous diagnostic spectra [
2]. Due to the valuable combination of multiscale spectral and spatial information, hyperspectral data find applications in various domains such as agriculture [
3,
4], mineralogy [
5], earth observation [
6], and other related applications [
7,
8,
9]. How to classify hyperspectral images and extract multiscale features effectively is a hot topic for researchers. Various data processing techniques have been explored to effectively utilize acquired hyperspectral images, including unmixing, detection, and classification [
10]. How to use hyperspectral image classification is also a hotspot topic. In previous studies, traditional machine learning algorithms were employed for HSI classification, including k-nearest neighbor [
11], logistic regression [
12], Bayesian estimation [
13], and support vector machines [
14]. However, it was observed that these conventional classification approaches often resulted in misclassification. In addition, several methods for dimensionality reduction and spectral information extraction have been developed, such as principle component analysis [
15], independent component analysis [
16], and linear discriminative analysis [
17]. However, these methods tend to overlook the spatial correlation among pixels in a spatial dimension, which is crucial for optimal spatial feature extraction. To address this limitation, various mathematical operators have been developed, such as morphological profile [
18], extended morphological operator [
19], and extended multiattribute profile [
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47].
In recent years, deep learning models, especially convolutional neural networks, have shown significant advantages over traditional methods in extracting more relevant and discriminative multiscale features. In [
21], a stacked autoencoder and deep belief network were applied to extract multiscale features. These methods required a 1D feature as input. In [
22], a 2D-CNN was proposed to carry out principle component analysis after the dimensionality reduction process. In [
23], a more effective method for extracting spatial–spectral features in 3D-CNNs was proposed. In [
24], combining 3D and 2D-CNN characteristics to reduce the computational complexity and improve classification accuracy HybridCNN was proposed. In [
25], the author developed two stream residual deep feature fusion convolutional neural networks to fuse two branches to extract multiscale spatial spectral features. One branch was used for global feature extraction, and the other branch was used for local feature extraction. Moreover, recurrent neural networks [
26], generative adversarial neural networks [
27], graph neural networks [
28], and capsule networks were proposed [
29]. Conversely, encoder–decoder architectures are often employed in unsupervised multiscale feature learning to extract and reconstruct features from hyperspectral images [
43]. Nonetheless, it is widely acknowledged that deep learning methodologies demand a substantial amount of labeled samples and an extensive number of training epochs, posing significant challenges in hyperspectral image classification.
Recently, a new model vision transformer [
30] has exhibited better performance in the domain of computer vision. The transformer uses a self-attention mechanism to extract global dependencies. Attention mechanisms are also widely used in HSI classification. In [
31], the spectral–spatial attention network was designed to extract discriminative features from the HSI cube. Much work has been carried out to apply the vision transformer model to hyperspectral image classification. In [
32], spectral–spatial transformers (SST) were proposed. The author used a similar VGGNet model for spectral and spatial feature extraction and developed a relationship with a dense transformer. In [
33], the author proposed a new model called SpectralFormer. This model can learn GroupWise spectral information and design cross-layer transformer encoders. In [
34], the author introduced a spectral–spatial feature tokenization transformer for HSI classification; it uses 3D and 2D-CNN models for multiscale spatial and spectral features, in addition to a Gaussian weighted tokenizer. In [
35], the author used a convolution network with a transformer model called CT Mixer and introduced a novel local global multi-head self-attention. In [
36], the author proposed two branches of pure transformers: one is the spectral branch, and the other is a spatial branch. For the spectral branch, the author used a vision transformer for spectral features and for the spatial branch, the author used a swin transformer for spatial features; at the end, branch fusion strategy was used to learn joint features. Inspired by [
42], depending on the desired information, different types of features can be extracted, such as pixel-based and structure-based features. However, finding an efficient and universal approach to fuse these features optimally remains a challenge due to the subtle relationship between the data.
In [
48], the author proposed a model for deep multiscale feature learning for distorted image quality assessment. The author proposed a two-branch network for distorted images and residual maps. The network consists of spatial pyramid pooling and feature pyramid, aiming to learn hierarchical multiscale features from images. In addition, the author of [
49] proposed DeepCervix, a hybrid deep feature fusion technique based on deep learning. In this method, various deep learning pre-trained models such as VGG16, VGG19, XceptionNet, and ResNet50 models are used to capture multiscale information to enhance the classification performance. In [
50], the author proposed a multiscale feature fusion model based on ResNet50 and VGG16; they extract multiscale feature vectors of the last layer before the softmax layer of these two models. In [
51], the author proposed the DeepFusion model to extract structural similarity features and sub-structure features and feed them into the interaction feature fusion module to encode interaction features. In [
52], the author proposed a deep feature fusion classification network (DFFCNet) based on EfficientNetV2 as a backbone network ResNet with channel attention and a spatial attention module to fuse the features. These methods adopt concatenation or adding techniques to fuse the features of branches, causing an increase in dimensionality and an increase in computational cost. However, these methods perform well and obtain multiscale features with fusion techniques, but they are not capable of extracting high-level multiscale features.
Therefore, to take advantage of different models and their ability to extract multiscale features, we propose a swin transformer [
34] with deep model architecture. To extract multiscale features, we propose a model that has three branches. First, we use a fully connected encoder–decoder with an attention module to reconstruct the spectral features. Secondly, we use a convolutional neural network to extract the multiscale spatial and spectral features. Third, we use a swin transformer to extract high-level multiscale features. Moreover, it is not easy to obtain satisfactory results using only one type of feature.
The main contributions of this paper are as follows:
Various deep multiscale feature learning models were identified with distinct feature extraction abilities, including an encoder–decoder for reconstruction features, CNNs for spatial features, and transformers for long-range or structural features.
The proposed model combines and fuses these diverse multiscale features to create a comprehensive representation of hyperspectral images.
We developed an effective weight fusion strategy to merge multiscale features, optimizing the integration process.
We highlighted the model’s ability to capture and utilize valuable spatial–spectral information, leading to improved accuracy in classification results compared to existing approaches.
The rest of the paper is organized as follows: Section II explains the methods, Section III presents the dataset and experimental evaluation, Section IV shows the results, Section V provides the discussion, and Section VI concludes the paper.
2. Methods
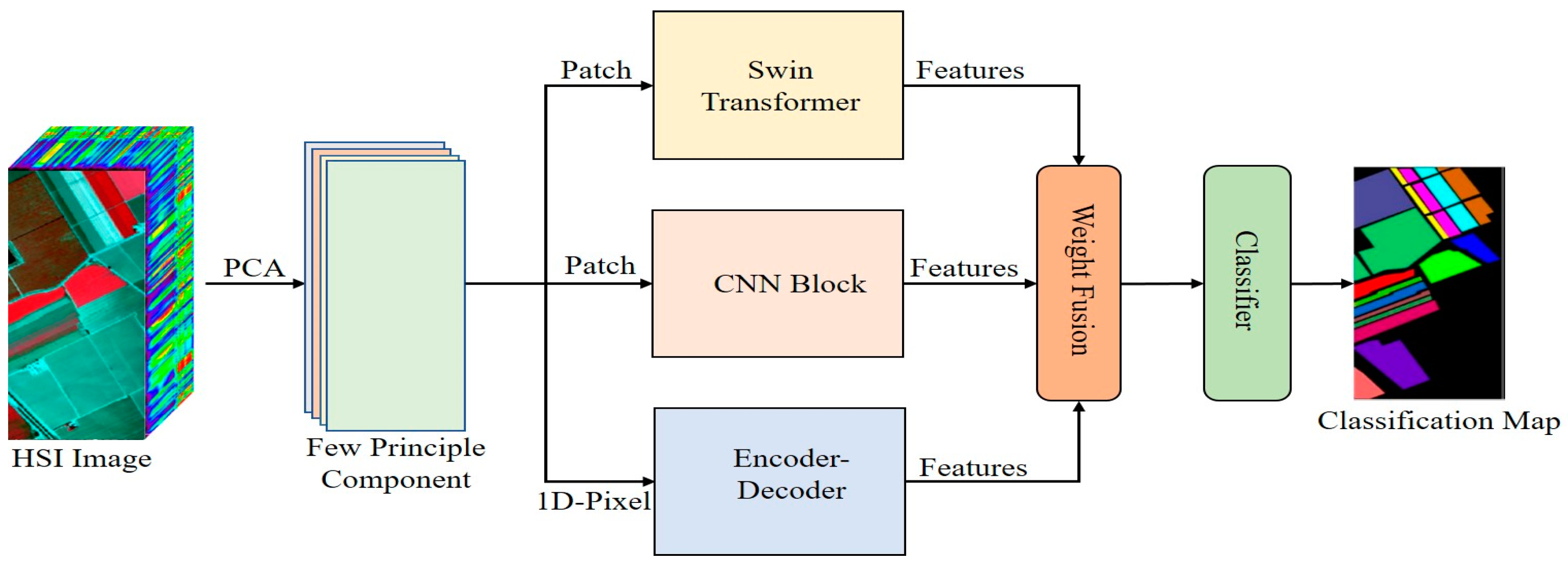
Figure 1 presents the proposed model. This section will explain the structure of the model and how the model works. In this study, we attempt to extract multiscale features from an HSI cube and consider different level feature extraction methods. Then, we develop a three-branch network for low and mid-range features using a CNN, for high-level features using a swin transformer, and for reconstruction features using an encoder–decoder.
- (1)
Swin Transformer
The pivotal disparities between the swin transformer and vision transformer (ViT) reside in their fundamental feature mapping strategies. ViT yields singular low-resolution feature maps due to its employment of a global self-attention mechanism, which consequently results in a quadratic computational complexity concerning input image dimension. On the other hand, swin transformers employ a novel approach of merging image patches to construct hierarchical feature maps, offering an ingenious solution that curtails the computational intricacy to a linear scale with respect to input image dimension. This approach utilizes local windows for self-attention computation, affording enhanced efficiency and scalability in processing images of varying sizes. The characteristics of the swin transformer make the model suitable for vision tasks such as image classification, image detection, and image segmentation. Swin transformers can extract multiscale features in the spatial dimension.
The swin transformer model works by dividing the input image into non-overlapping patches. For the input of the model, first, we apply the dimensionality reduction technique to reduce the redundancy in data as well as computational complexity. In addition, without dimensionality reduction, overfitting occurs to alleviate the above problem; dimensionality reduction is important.
is the input of the model, where
represents the height width of the HSI image and
b represents the bands. y indicates the dimensionality reduction layer and y
. z represents the number of bands. After that, the patch token processes the input to the swin transformer. The model consists of shifted window self-attention, an MLP layer, and layer normalization layers. A patch-merging layer is adopted to reduce the number of tokens, and the model becomes deeper to generate spatial features. The core component of the swin transformer is shifted window self-attention. The shifted window technique is applied in image classification tasks.
Figure 2 shows the blocks of the swin transformer.
The window partition process is computed as follows:
where
represents the output of window multihead self-attention.
represents the MLP output at the
lth block. The process of window shifting shows in
Figure 3.
- (2)
The convolutional Neural Network (CNN)
The second model is the CNN, which has achieved great success in the computer vision domain. It can extract multiscale spatial–spectral features simultaneously. This characteristic facilitates the differentiation of ground object materials in classification tasks. Let the input image cube be
, where
represents the height and width of the image and
represents the channels of the image. The block diagram of the CNN block is shown in
Figure 4.
After using principle component analysis (PCA) to reduce the dimension of data to remove noise and redundancy,
c is decreased to
D. Input reduced data convert into small patches, and the process involves generating patches
centered at the spatial location of (a, b), which covers spatial window size (
s ×
s). Given
M convolution kernel to input feature weights
, the output can be computed as
where
denotes the activation function. After the convolution layer is used to reduce the spatial size and extract more discriminative features, the maxpooling layer is used, where MP denotes the maxpool operation
After reduction, the spatial size batch normalization layer is used to normalize the incoming batches, which helps to train the model faster. After the normlization layer, an activation function is used called a rectified linear unit (ReLU) to introduce non-linearity to output neurons. One convolution block consists of a CNN layer, MXPOOL layer, batch normalization layer, and ReLU layer. In this paper, block three is set with a (8, 16, 32) filter size and one stride kernel size, 3 × 3, is used in all blocks.
- (3)
Encoder–Decoder (ED)
The third part of the model is the encoder–decoder, which is an unsupervised feature extraction method. Generally, the encoder–decoder is implemented in two ways: it is fully connected [
34] and fully convolutional. In this paper, we choose a fully connected method with a band attention module (BAM).
The fundamental principle behind this type of encoder–decoder is to reconstruct the band information. This involves the retrieval of complete spectral details using a limited set of informative bands.
Figure 1 shows that the overall architecture encompasses three key components: the band attention module (BAM), band reconstruction weights (BRW), and reconstruction network (RecNet).
Figure 5 shows the internal process of encoder–decoder.
The band attention module (BAM) is a function of
g. Input
X produces non-negative weights, and the tensor shape is
where
denotes the trainable parameter of BAM. To ensure the enforceable non-negativity of the acquired weights, the sigmoid function is incorporated into the output layer of the BAM module using following formulation:
In order to establish an interaction between the initial inputs and their corresponding weights, a band-wise multiplication operation, denoted as BRW, is operated. This operation can be succinctly described as follows:
Subsequently, we proceed with the utilization of RecNet to reconstruct the initial spectral band from its reweighted counterpart. Analogously, RecNet is characterized as a function denoted by
h, which accepts a reweighted tensor
y as input and produces its corresponding predictions.
The reconstruction block simply consists of an MLP model with the same hidden neurons with a ReLU activation function for the reconstruction of features.
Figure 6 shows the basic diagram of encoder decoder process.
- (4)
Weight Fusion
We discover three branch-extracted features from the swin transformer, CNN, and a fully connected encoder–decoder. These branches could present various features or characteristics of the data. The goal of the weight fusion technique is to provide each branch with an appropriate level of importance when classifying the result. First, we assess the importance of each branch. This could be based on the relevance of the information it captures. Once we determine the importance scores, we multiply each branch’s information by its corresponding weights. Fusing these features by summing operation, the formulation of weight fusion is calculated as:
where
denotes two branches of CNN and ED fusion features and
denotes the weighted parameter range in between [0, 1].
where
is the final output after fusing three branch features. Again,
can multiply with transformer branch features.
- (5)
Classifier
Figure 7 shows the multilayer perceptron classifier, a neural network model. It consists of multilayers of interconnected nodes, where each node in a layer is connected to all nodes in the subsequent layers.
The input of the MLP classifier is multiscale features received from the weight fusion block; each node corresponds to specific weighted features and calculates the weighted sum. This weighted sum is then passed through an activation function ReLU. The activation function helps the network learn complex relationships within data. The second fully connected layer performs linear transformation, and the applied softmax function converts the output value into probabilities representing the likelihood of each class. The classes with the highest probability are predicted as the final classification.
In summary, we use the preprocessing technique principle component analysis (PCA) to reduce the noise and redundancy in data. After preprocessing, the input image data are embeded into three different branches: the first is a swin transformer to extract high-level features, the second is a convolutional neural network to extract low-level features, and the third is an encoder–decoder with a fully connected layer to extract reconstruction features from hyperspectral data. The details of working all branches is described in sections. After extracting multiscale features, the weight fusion technique is applied to fuse features, computational complexity is very low. Moreover, the classifier is used to classify the image.
4. Results
To compare the classification results of the proposed model, comparative experiments were conducted and the models used were SVM [
37], 2D-CNN [
38], 3D-CNN [
39], Hybrid [
22], DFFN [
41], Bam-CM [
42], ViT [
26], SwinT [
33], SSFTT [
30], and CT Mixer [
31].
The comparison classification result of the Xuzhou Dataset is shown in
Table 4. One can see that the quantitative result of the SVM-based method obtained 84.39% classification accuracy compared to a single deep model with fewer parameters. This means traditional classification methods still have some advantages in specific cases. On the other hand, as one can see, OA of state-of-the-art methods 3D, Hybrid, ViT, SwinT, and CT Mixer was 94.41%, 95.09%, 92.50%, and 95.72%, respectively; on the other hand, our proposed model obtained
classification accuracy on the Xuzhou dataset with
training samples.
Additionally, the observation reflects the effectiveness of the proposed model in seamlessly integrating features extracted from different models. As a result, it significantly enhances OA classification performance.
Figure 10 shows the classification maps of different methods on the Xuzhou dataset. As shown in the figure, more training samples and more model layers can obtain better results with less noise. As one can see, ViT obtains excellent classification accuracy with less noise and intra-class smoothness. In addition, the proposed model not only obtains multiscale spectral–spatial features but also includes high semantic features from the transformer and reconstruction features from the encoder–decoder. It can obtain a better classification map and obtain more information that is detailed. The comparison classification result of the Salinas dataset is shown in
Table 5. From the table, one can see first the shallow traditional multiscale feature learning method is lower than the deep learning model in terms of OA, AA, and Kappa coefficient. In contrast, 2D achieved the best result due to its spatial feature extraction capability. On the other hand, the proposed model is better than other multiscale feature learning models in terms of OA. Furthermore, SSFTT and CT Mixer performed better than other deep models. Additionally, our proposed model achieved better multiscale features among other single models and obtained the highest classification accuracy in some categories. SSFTT and CT Mixer use combined CNN and transformer models for feature extraction; the combination of both models is the best choice for local and global information.
Figure 11 shows the classification maps of different methods; as we can see, the SSFTT model and proposed model have less noise. Our classification is almost near to the ground truth image. As the level of noise increases, the accuracy of the classification maps tends to decrease. This observation highlights the importance of noise reduction techniques and the need to address and minimize noise effects to improve the accuracy of classification results. As one can see, the Xuzhou dataset and the proposed model improve 12.48%, 15.31%, 2.67%, 2.46%, 5.8%, 7.38%, 4.37%, 3.47%, and 1.15% OA accuracy compared to SVM, 2D-CNN, 3D-CNN, Hybrid, DFFN, Bam-CM, Vit, SwinT, SSFTT, and CT mixer. Traditional methods are not able to fully extract multiscale spectral–spatial features. The 2D-CNN has the ability to extract both spectral and spatial features, but for semantic features, in terms of semantic or high level features, CNNs are not able to extract these types of features. The transformer model has the ability to learn sematic features; however, a CNN and transformer combined can extract more discriminative features like CT Mixer in terms of improved classification accuracy. The comparison results of the WHU-Hi-LongKou dataset are shown in
Table 6 with different methods. In this experiment, one can see that the traditional method of SVM performed better than other deep models. Due to some class variability, the 2D-CNN network also performed well due to its spatial feature extraction capability. From the other state-of-the-art methods, vision transformer also performed well to extract long-range features. On the other hand, our proposed model performed significantly well in terms of OA, AA, and Kappa coefficient.
Figure 12 shows the classification maps of different methods. As one can see, SVM, 2DCNN, ViT, and our proposed model have competitive classification results from classification maps; therefore, there is less noise in the maps. Our proposed method can achieve high accuracy in some classes. If the number of samples is increased, the deep model layers model can achieve higher accuracy due to the computational complexity increase. Our proposed model shows impressive classification performance due to the best weight fusion design strategy. The weight fusion strategy makes full use of multiscale feature fusion from different branches. The reconstruction feature from the encoder–decoder model can enhance the fused feature more. Our proposed model systematically combined multiscale features. It can be seen from
Table 4,
Table 5 and
Table 6 that our proposed model obtained better results than other state-of-the-art methods.
5. Discussion
This paper developed a three-branch unified model to extract multiscale features. Hyperspectral image data have different kinds of features such as texture, structural features of data, and land cover object shape and size. Due to different model characterization, we used three different deep learning models to extract multiscale features at different levels and fused these multiscale features with weight fusion techniques to provide different features with different weights. It can be seen from
Table 4,
Table 5 and
Table 6 that the classical method SVM, several deep learning methods, 2D, 3D, Hybrid, DFFN, and Bam-CM, and recently introduced vision transformer-based methods, ViT, Swin Transformer, SSFTT, and CT Mixer, were considered for comparison.
Our experiment shows that the proposed methods achieve the best classification results in terms of overall accuracy (OA), average accuracy (AA), and Kappa coefficient (k) on the three publically available datasets. Taking the example of the WHU-Hi-LonhKou dataset, Hybrid and SSFTT models are not able to extract class C3 features. For class C4 and class C5, our proposed method achieved satisfactory results. The strength of our model in all classes except class C9 achieved more than 90% accuracy, which exhibits the robustness and discriminative power of the model. Compared with the CNN model and transformer model, the OA of the proposed method improved 0.91%, 4.84%, 3.66%, and 2.72% on the LK dataset with DFFN, Bam-CM, SSFTT, and CT Mixer models, respectively. The proposed model combines the advantage of each branch to extract different kinds of multiscale features at each level to improve the classification performance. Moreover, the proposed method adopts a comprehensive feature fusion technique that could potentially improve the model’s capability to extract multiscale information. In addition to the other deep feature fusion models, such as DeepCervix, multiscale feature learning methods cannot achieve semantic high-level features; also, they use concatenation and add methods to fuse multiscale features. These fusion techniques might introduce redundant information, especially if the branches capture similar multiscale features. Because of imbalance and small training samples, these models are susceptible to overfitting. On the other hand, our proposed model achieved satisfactory classification results on small training samples. The weight fusion technique facilitates the integration of multiscale features extracted by different modules. This fusion strategy can lead to more comprehensive and refined multiscale feature representation. By integrating multiple modules and fusion techniques, the model offers a holistic approach to hyperspectral image classification, potentially improving its ability to handle complex real-world scenarios. In terms of the feature fusion technique, weight fusion allows the model to assign different importance to features from different branches, emphasizing more relevant features; furthermore, weight fusion technique controls the dimensionality and reduces the computational cost.
5.1. Ablation Study
To highlight the effectiveness of the proposed model, an investigation was conducted on the Xuzhou dataset to examine the impact of different combinations of network components. The findings are presented in
Table 7; the result demonstrates that our fusion technique, as proposed, achieves superior performance when compared to other combination approaches.
5.2. Different Models on Different Training Samples over the Xuzhou Dataset
Model performance can be effectively evaluated by examining the classification accuracy across different numbers of training samples. To access this, we randomly selected 1%, 2%, 3%, and 5% data for training and the remaining for testing the model.
Figure 13 shows that the classification accuracy increases when the number of training samples increases. The strategy shows that the proposed model is always effective on a small number of training samples.




 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





