1. Introduction
Gestures are used for human interaction to express feelings, communicate non-verbal information, and increase the value of messages. A gesture can be an intuitive human–computer interface that helps machines understand body language for various purposes. Both online and offline applications, such as interacting with a computer, recognizing pedestrians and police hand signs in automated cars, gesture-based game control, and medical operations that use this technology are still in their infancy.
Two main approaches to detecting hand gestures are glove-based analysis and vision-based analysis. Glove-based techniques take advantage of sensors attached directly to the glove and accurately analyze hand movements. Vision-based methods can help users feel more comfortable without annoying physical limitations. They utilize a camera(s) to capture human hand signs and provide a more natural posture. The most essential ability of vision-based techniques is filtering out irrelevant and complex information and considering the most useful information during detection.
In this paper, we propose a general method of hand gesture recognition based on computer vision methods and compare the empirical results of input images with complex backgrounds. Recognizing different hand signs using an integrated structure based on saliency maps and histogram of oriented gradients (HOG) creates a filter for selecting target regions by ignoring irrelevant information. This leads to an increase in the performance of gesture recognition algorithms. These methods detect the exact regions of hand gestures and ignore complex backgrounds from input images. Lastly, we improve a convolutional neural network (CNN) with two blocks to identify hand postures for increasing accuracy and stability. We use the NUS Hand Posture Dataset II and the hand gesture dataset to demonstrate the performance of our model. In our experiments, we applied six diverse aggressive types of noise such as Gaussian, impulse, Laplacian, multiplicative-Gaussian, Poisson, and uniform to around 60% of our datasets to evaluate our model’s performance while encountering low-quality images.
The remainder of this paper is organized as follows.
Section 2 presents some related work on hand gesture detection.
Section 3 describes the framework of the proposed model for image saliency with the HOG model.
Section 4 describes the performance evaluation.
Section 5 provides a brief conclusion.
2. Related Work
Ajallooeian et al. [
1] used a saliency-based model of visual attention to find potential hand regions in video frames. The saliency maps of the differences between consecutive video frames are overlaid to obtain the overall movement of the hand. A Loci feature extraction method is used to obtain hand movement. Then, the extracted feature vector is used for training an SVM to classify the postures. Chuang et al. [
2] proposed a model that integrated image saliency and skin color information to improve the performance of the hand gesture detection model, with SVM utilized to classify hand gestures. Zhang et al. [
3] built up a method based on saliency and skin color detection algorithms, including a pixel-level hand detection method, region-level hand detection method, and a multiple saliency map fusion framework that achieves the deep integration of the bottom-up saliency and top-down skin color information. This method has excellent performance and is reliable against complex backgrounds. A saliency detection method using a top-down dark channel prior is developed to determine the hand location and contour of the gesture. Then, it is integrated with a graph-based segmentation approach to make a final confidence map for segmentation [
4].
Zamani and Rashidy [
5] after extracting the saliency map used principal component analysis (PCA) and linear discriminant analysis (LDA) in order to reduce dimension, minimize class external similarity, and maximize class internal similarity, which led to the accuracy reaching
using a 4-fold cross-validation. Yin and Davis [
6] developed a gesture salience method and a gesture spotting and recognition method based on hand tracking and concatenated hidden Markov models. Schauerte and Stiefelhagen [
7] trained a conditional random field to combine relevant features to multi-scale spectral saliency, salient object detection, probabilistic pointing cone, and probabilistic target maps to highlight image regions highly similar to the target object. Reducing the false positive rate in skin segmentation using saliency detection is a method that was proposed by Santos et al. [
8]. The weighted image is considered as input for the saliency detector, and the probability map is used to prevent discarding skin pixel adjustment to the boundary list. When it comes to using superpixel in the implementation of the saliency map, it can easily be replaced with a superpixel structure.
Vishwakarma et al. [
9] detected hand gestures in static hand posture images by following these steps: (a) segmentation of hand region, (b) applying the saliency method, and (c) extracting Gabor and pyramid histogram of oriented gradients (PHOG). The Gabor filter extracts the texture features at different orientations, and PHOG extracts the shape of the hand by calculating the spatial distribution of the skin saliency image. Finally, extracted features are classified by a support vector machine (SVM). The method based on RGB-D data is proposed to deal with large-scale videos to achieve gesture shape recognition. The inputs are expanded into 32-frame videos to learn details better, and the RGB and depth videos are sent to the C3D model to extract spatiotemporal features, which combine together to boost the performance of the model and avoid unreasonable synthetic data to the uniform dimension of C3D features [
10].
Yang et al. [
11] proposed saliency-based features and sparse representations for hand posture recognition utilizing sparsity term parameters and sparse coefficient computation. The histogram intersection kernel function was employed to deal with non-linear feature maps by mapping the original features into the kernel feature space and using sparse representation classification in the kernel of the feature space. The fast saliency model with a
kernel convolution was proposed to obtain the saliency map of the input images. Candidate regions are extracted from the saliency map using adaptive thresholding, connected domain filtering, and the HOG descriptor for each area [
12].
A two-stage hand gesture recognition is proposed to support a patient assistant system. The first step utilizes a saliency map to simplify hand gesture detection, and the second step classifies the patient’s postures. A novel combined loss function and a kernel-based channel attention layer are used to optimize the saliency detection model and emphasize salient features, respectively [
13]. Guo et al. [
14] proposed a motion saliency model based on a hierarchical attention network for action detection. They also defined combination schemes to link the attention and base branches to explore their impacts on the model. Regarding the characteristics of visual and thermal images, Xu et al. [
15] integrate CNN feature and saliency map fusion methods to achieve RGB-T salient object recognition. In this method, the salient object is separated from the background with a fine boundary, and the noise inside a salient object is effectively suppressed.
Ma et al. [
16] designed hand joint-based recognition based on a neural network and noisy datasets. To promote the availability of this model with noisy datasets, a nested interval unscented Kalman filter (UKF) with long-term and short-term memory (NIUKF-LSTM) network is proposed to improve the performance of the proposed model when dealing with noisy images. Evaluating the perceptual quality assessment owing to the quality degradation plays a vital role in visual communication systems. The quality assessment in such systems can be performed subjectively and objectively, and the objective quality assessment is taken into account thanks to its high efficiency and easy implementation [
17]. Since computer-generated screen content has many characteristics different from camera-captured scene content, estimating the quality of experiment (QoE) in various screen content is a piece of essential information for improving communication systems [
18]. The full-reference image quality assessment (IQA) metrics evaluate the distortion of an image generally by measuring its deviation from a reference or high-quality image. The reduced-reference and no-reference IQA metrics are used when the reference image is not fully available. In this case, some characteristics are driven by a perfect-quality image, and the distorted image’s deviation can be measured from these characteristics [
19,
20,
21].
3. Proposed Method
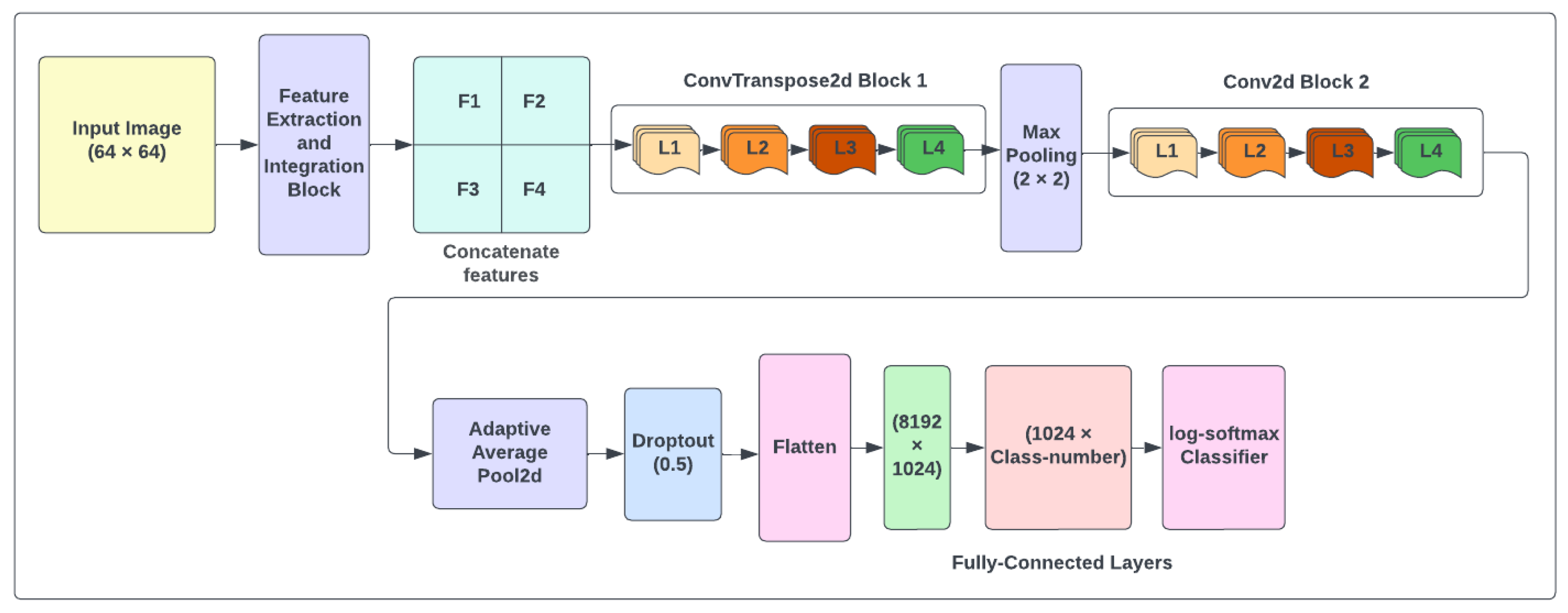
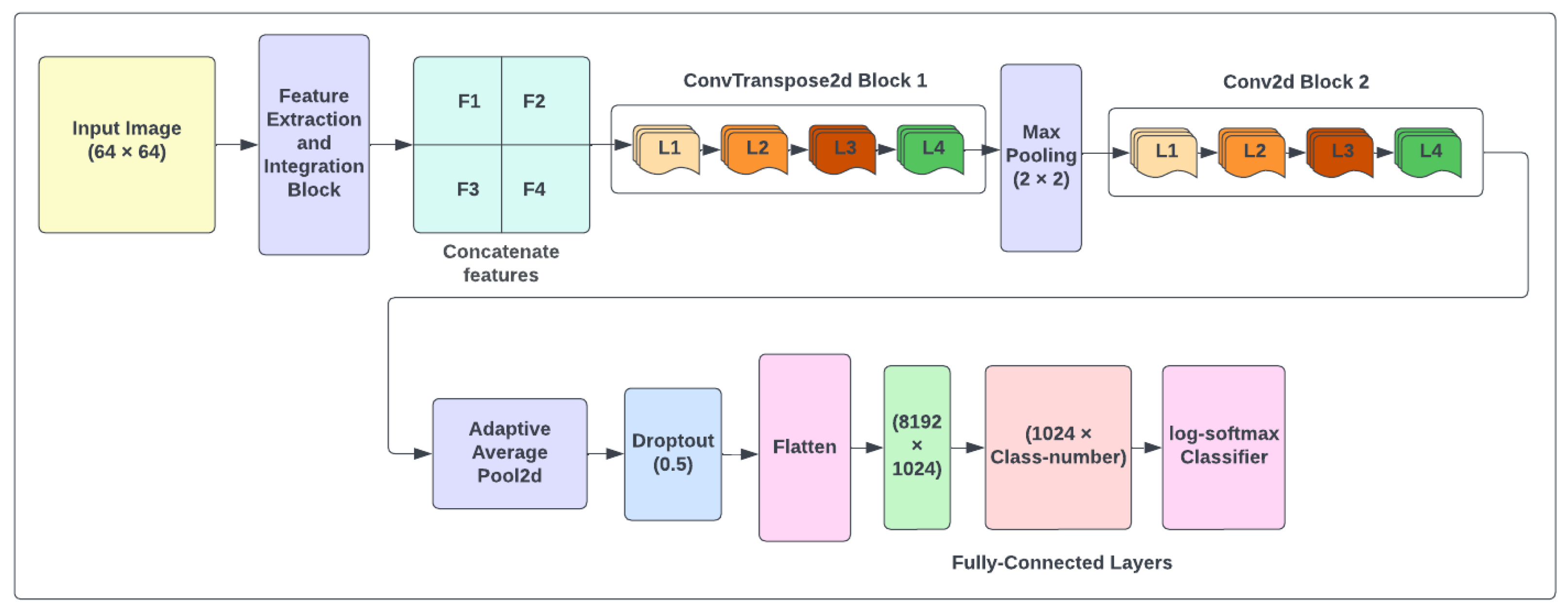
We introduce a method that eliminates the complexity of image backgrounds using features extracted from original images and binary operators. Detecting objects in complicated scenes is one of the challenging tasks in hand gesture recognition since it is difficult to recognize the intent object among many others. The proposed model provides an efficient system based on deep learning for recognizing the structure of hand postures in complex backgrounds by developing the architecture shown in
Figure 1.
In this architecture, the size of the input image is equal to
, which is given to the feature extraction and integration block as an input. Once the features have been extracted from the original images, the bitwise operators can mix these features to distinguish more details from hand-shaped textures.
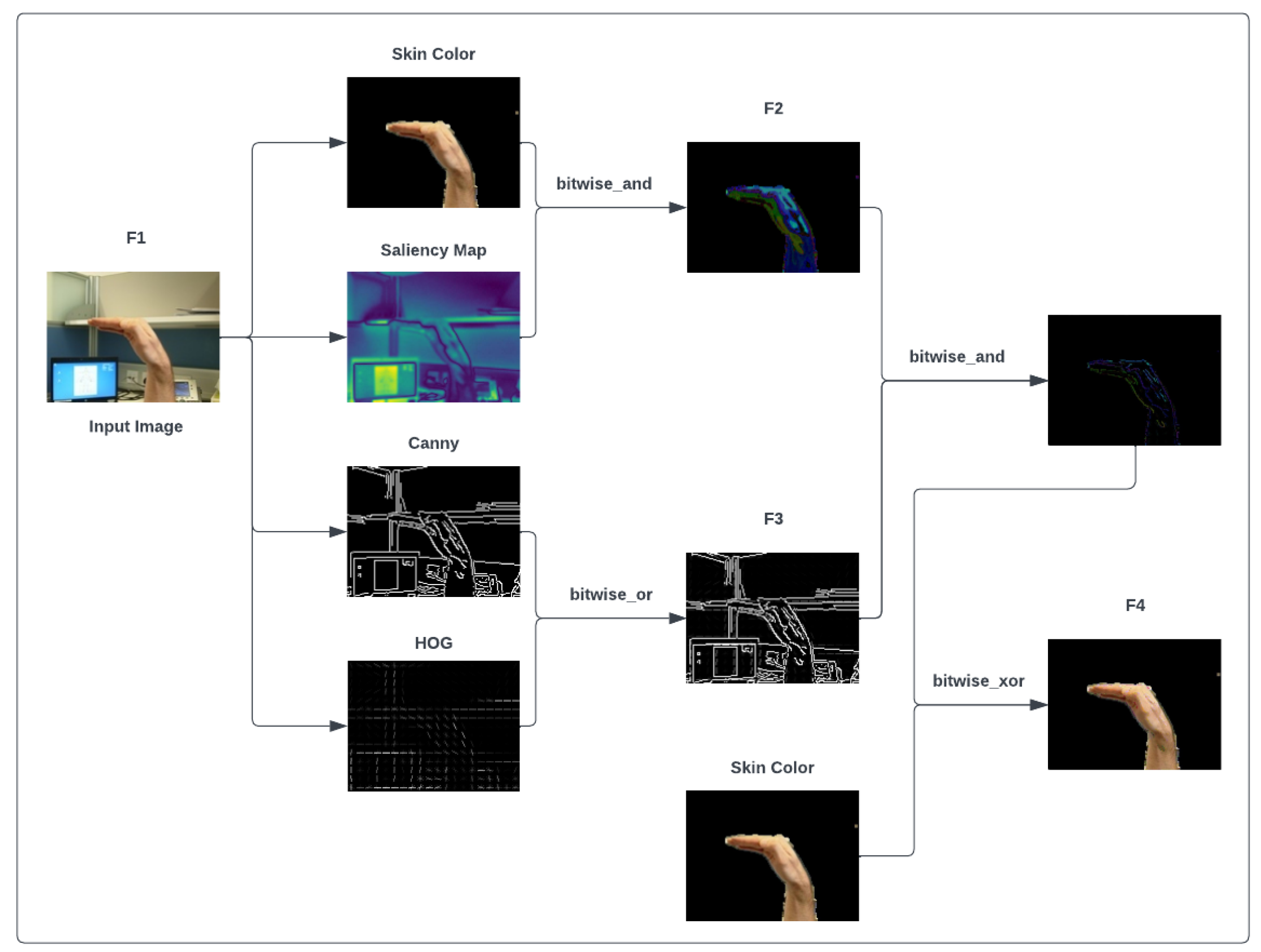
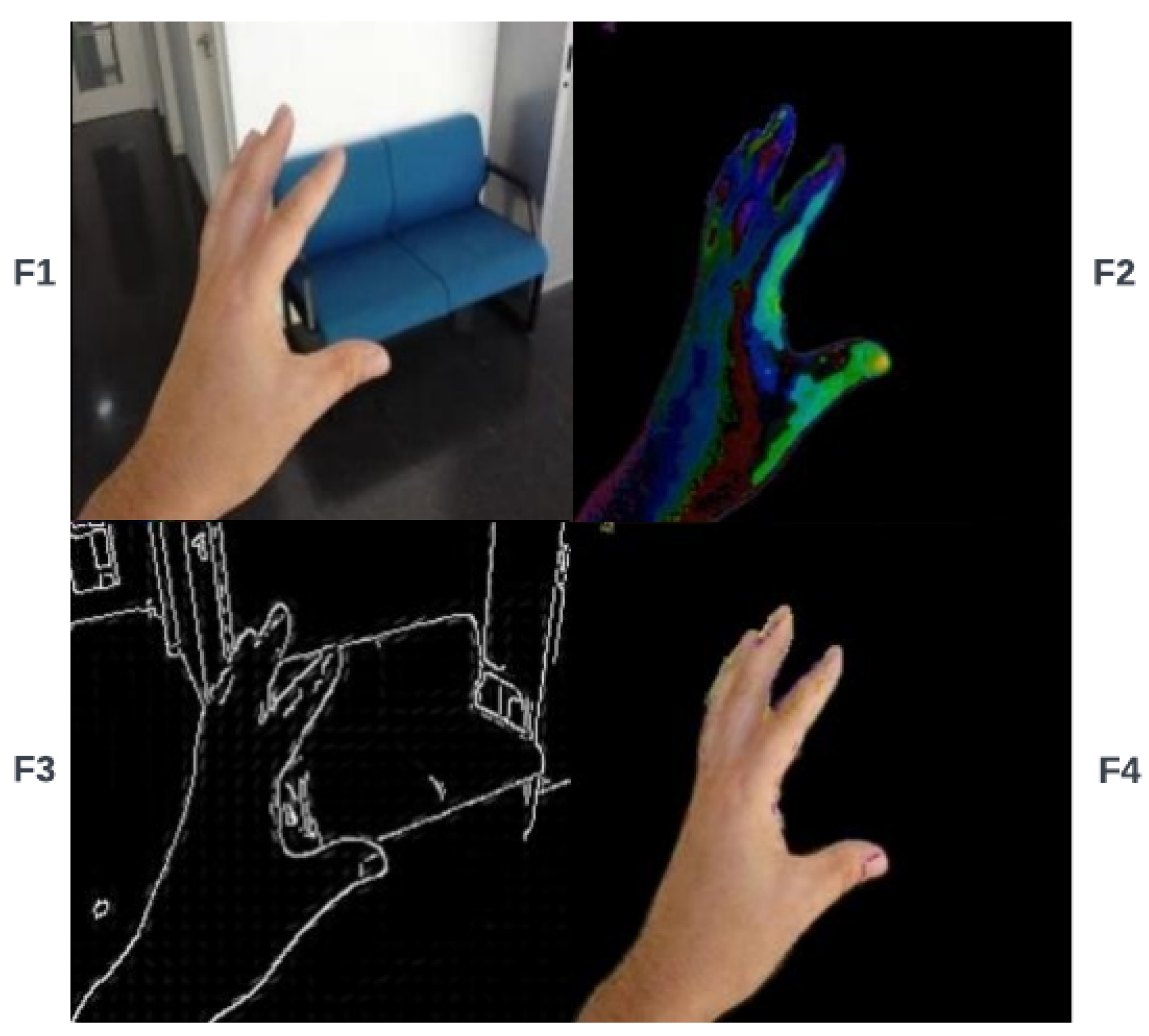
Figure 2 shows the process of the proposed feature extraction and integration model (see
Appendix A). First, skin color [
22], saliency [
23], Canny [
24], and HOG [
25,
26] features are extracted from the original image. The bitwise AND operator combines skin color and saliency feature maps, which gives us a new feature map. Using the bitwise OR operator, we perform a similar action for Canny edge detection and HOG features. Then, the two mixed feature maps produced by the previous steps are combined by the bitwise AND operator to make an exact region of hand shape, and the final result is mixed with skin color by the bitwise XOR operator to add hand region to the skin color information. Eventually, the output feature maps (F1, F2, F3, and F4) are given to the next block for concatenation. The F1–F4 features are represented by Equations (
1)–(
4):
where
is an original image;
,
,
, and
are skin color, saliency, Canny, and histogram of oriented gradient features, respectively; and F1, F2, F3, and F4 represent output features of the feature extraction and integration block. In the next step, all extracted features are concatenated and used as input for the classification section.
Table 1 demonstrates the improved CNN model summary used for classification. The total number of trainable parameters in this architecture is 9,026,502. As indicated in this table, there are two convolutional blocks, each with four layers. We utilized ConvTranspose2d with batch normalization and rectified linear unit (ReLU) activation in the first block in each layer. The padding and stride value is one, and the kernel size is three. The ConvTranspose2d layers are considered as the gradient of Conv2d and are used for creating features. In the second block, we used Conv2d instead of ConvTranspose2d layer with the same parameters to shrink our output to detect features. After each block, 2D MaxPooling reduces computational complexity in order to detect features in the feature maps. The fully connected layer with Flog-softmax is used to classify hand shapes.
5. Conclusions and Future Work
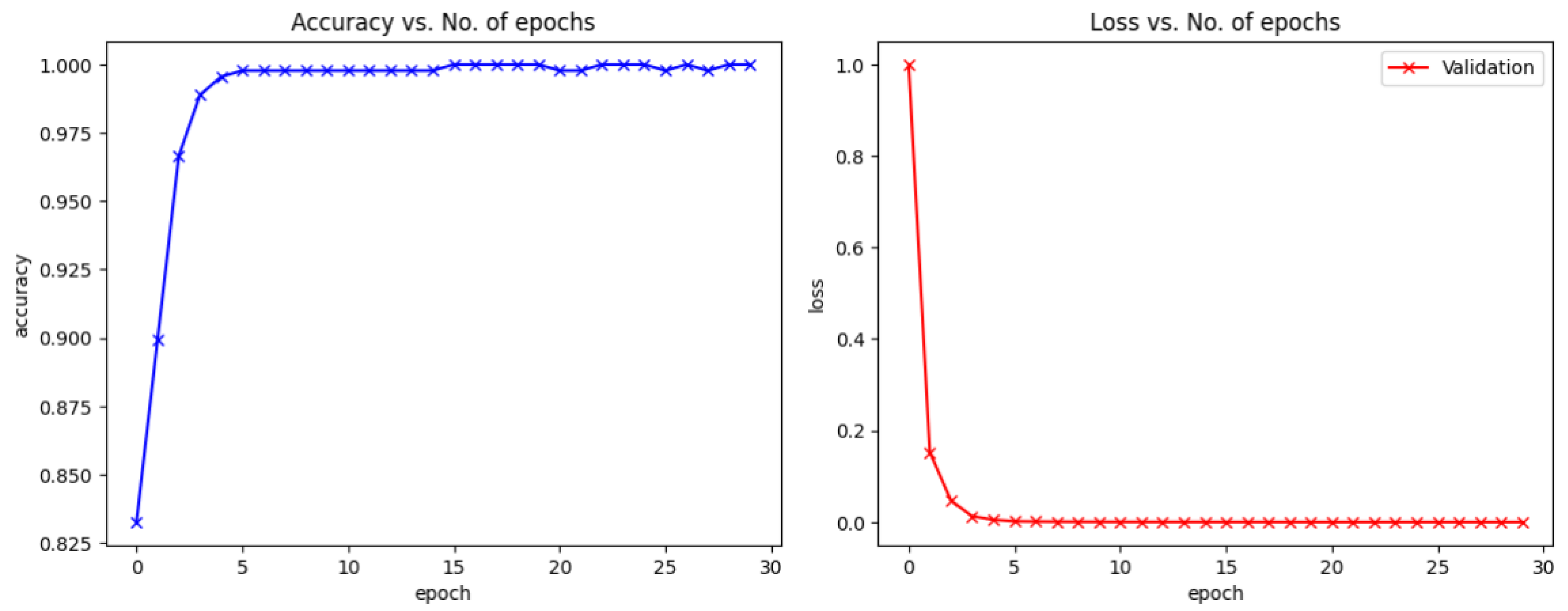
We introduced a novel method integrating the histogram of oriented gradients (HOG), skin color, Canny edge detection, and saliency maps using bitwise operators to detect hand postures with complex scenes by an improved CNN model. Using integrated feature maps identified the exact regions of the gestures in each input image and increased the accuracy. Apart from this, the proposed method enabled distinguishing postures better given complex backgrounds. The NUS hand posture II and the hand gesture datasets were used in the experiment, and the results showed that the proposed method improved the performance of hand gesture recognition in these datasets with and without image noises.
In our future work, we will address issues with the quality evaluation of image dehazing methods in vision-based hand gesture recognition systems. The image quality of experiments (QoE) is an essential aspect of various intelligent systems like those detecting hand postures since low-quality images or videos can have an adverse effect on identification performance. Evaluating gesture detection by incorporating audio-visual saliency will be considered in the next step of recognizing hand gestures.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}