
Spectral Efficiency Improvement Using Bi-Deep Learning Model for IRS-Assisted MU-MISO Communication System

 , ,
, ,  ,
,
Abstract
:1. Introduction
- A highly efficient DL-based SE analysis in the IRS-assisted MU-MISO downlink system is proposed, where a Wiener filter is employed to optimize the phase shift vector in the IRS elements during communication establishment.
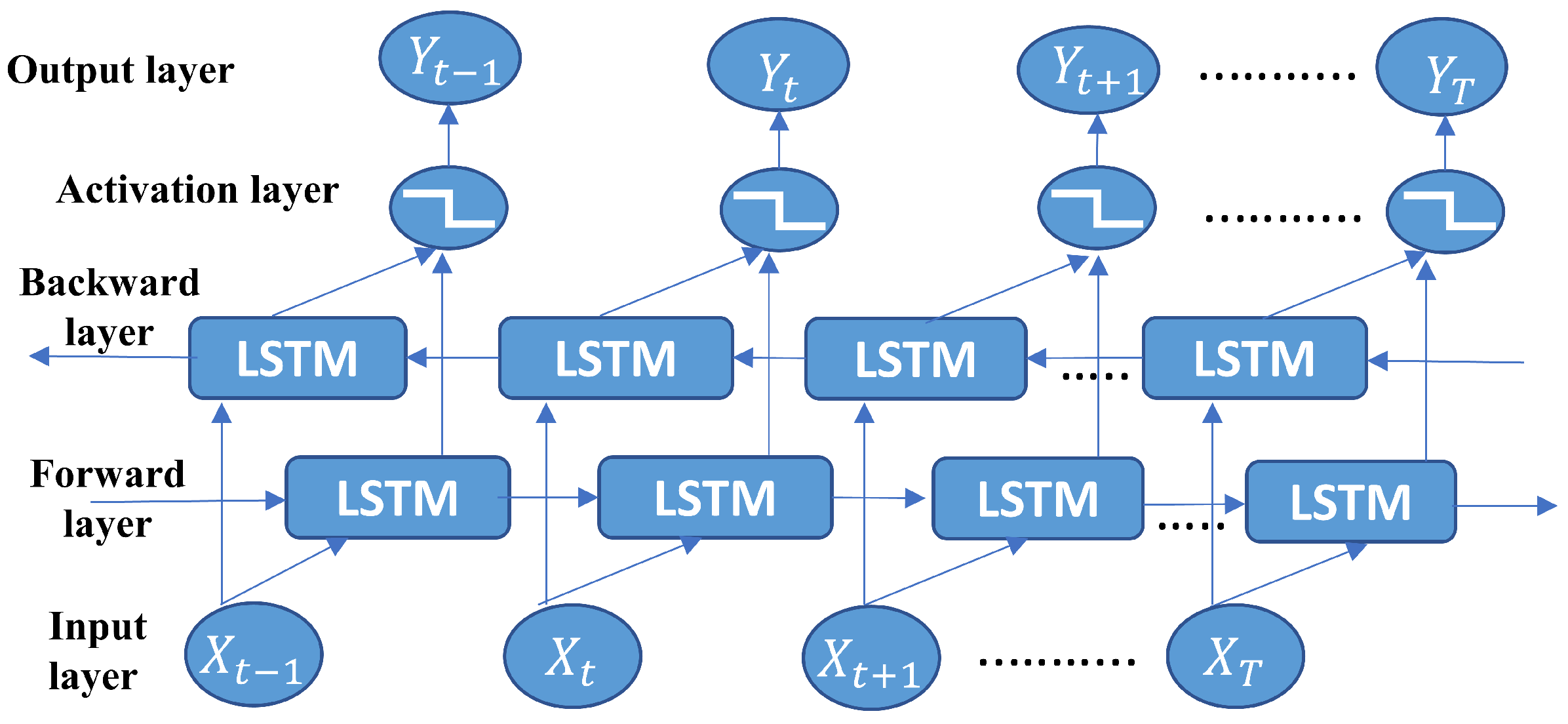
- The received simulated channel data are fed to the DL model, which is called the Bi-LSTM model during training. Due to the forward and backward training ability of Bi-LSTM hidden layers, it reduces the losses and improves the SE prediction in the online phase. To optimize the loss during training, the Adam optimizer is deployed.
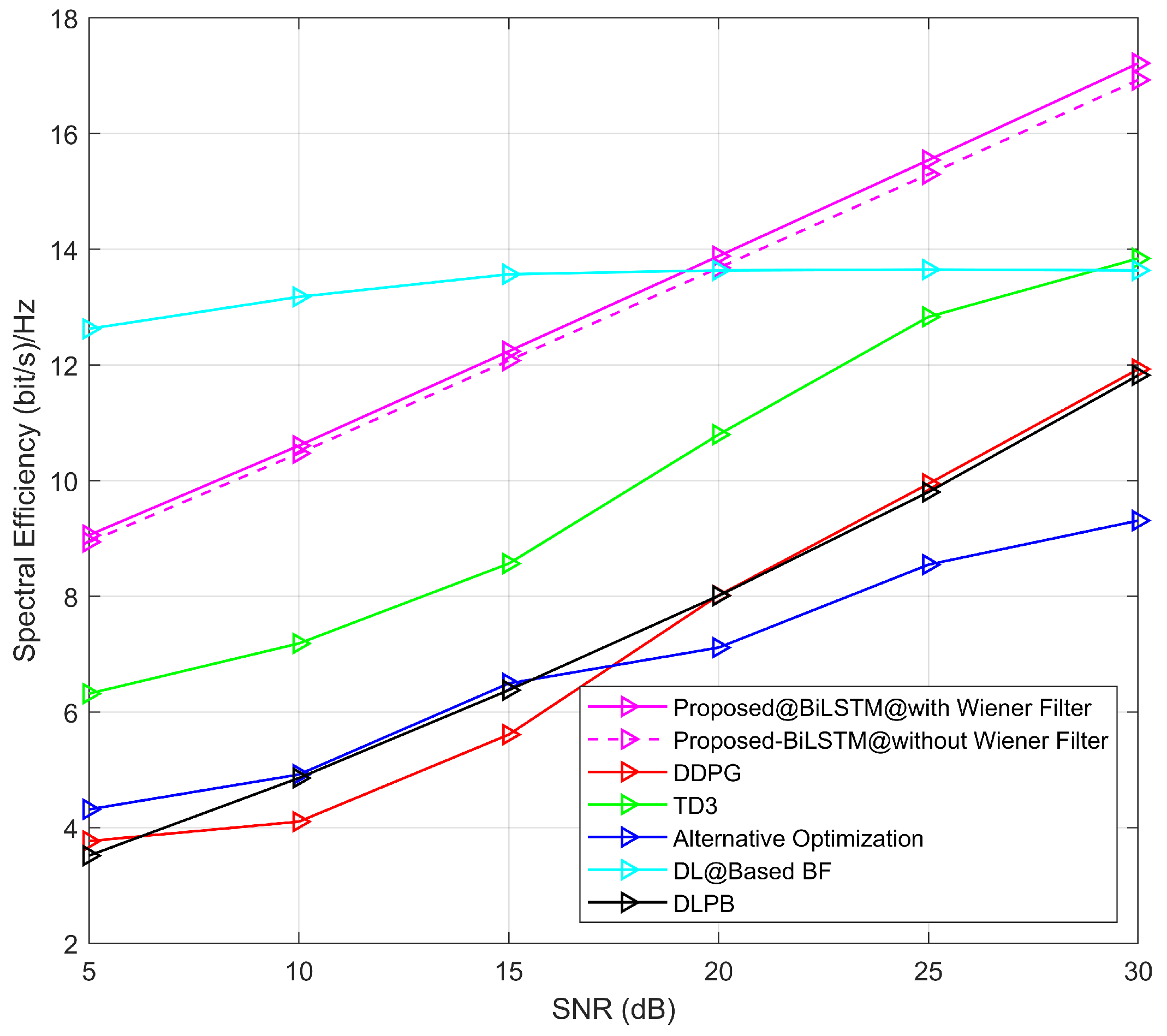
- To evaluate the effectiveness of the proposed model in terms of SE analysis and different signal-to-noise ratios (SNRs), comparative simulation outcomes are performed with alternative optimization, DL-based BF, DDPG, and TD3 models, respectively. The simulation results indicate that the proposed model outperforms the other methods very effectively.
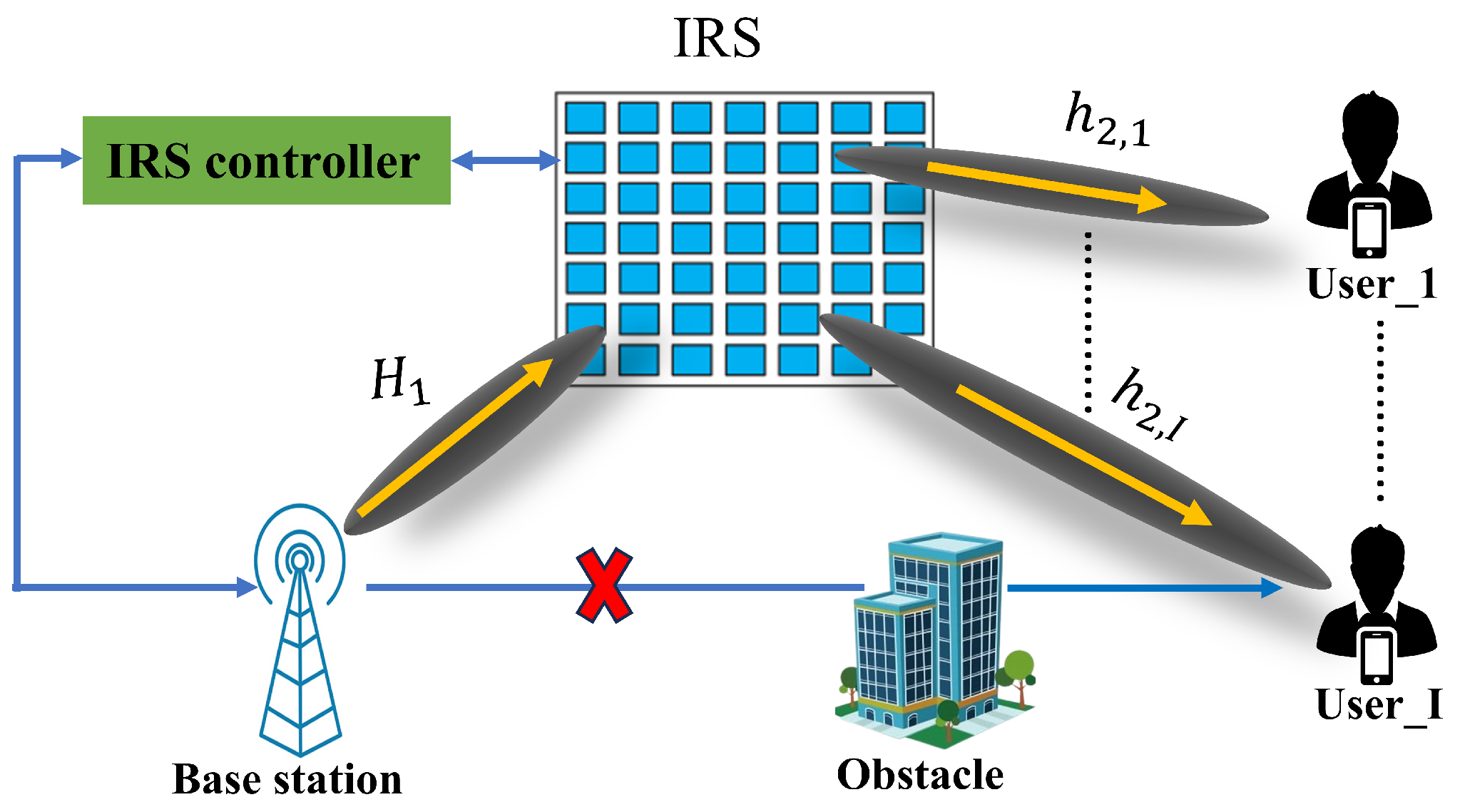
2. System Model
2.1. Signal Transmission Model
2.2. Channel Model
2.3. Computation of Optimal Phase Shift Using Wiener Filter
| Algorithm 1 Optimal phase shift using Wiener filter |
|
3. Deep Learning Model
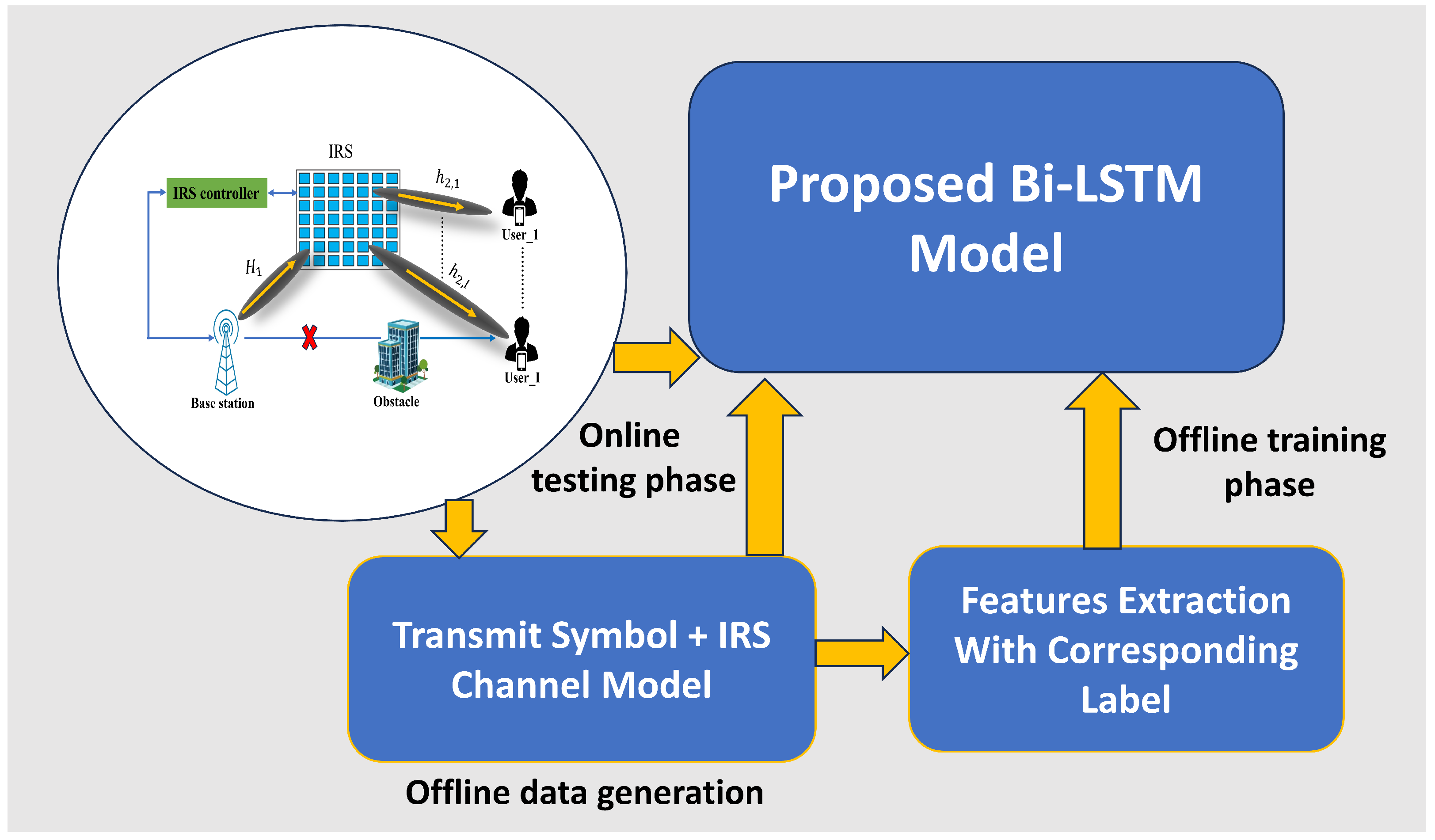
3.1. Data Generation
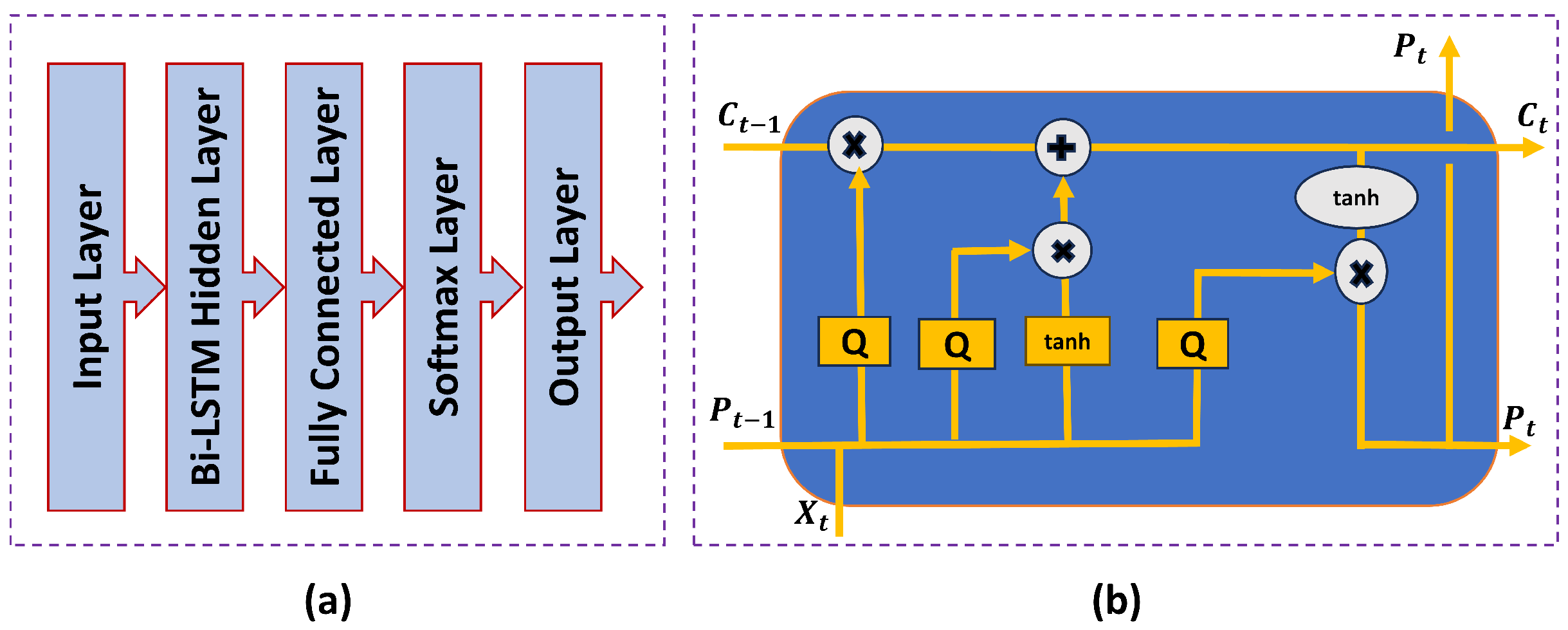
3.2. Proposed Model Structure
| Algorithm 2 Internal performance of Bi-LSTM model |
3.3. Training and Testing Procedure
| Algorithm 3 Bi-LSTM model training with simulation data |
|
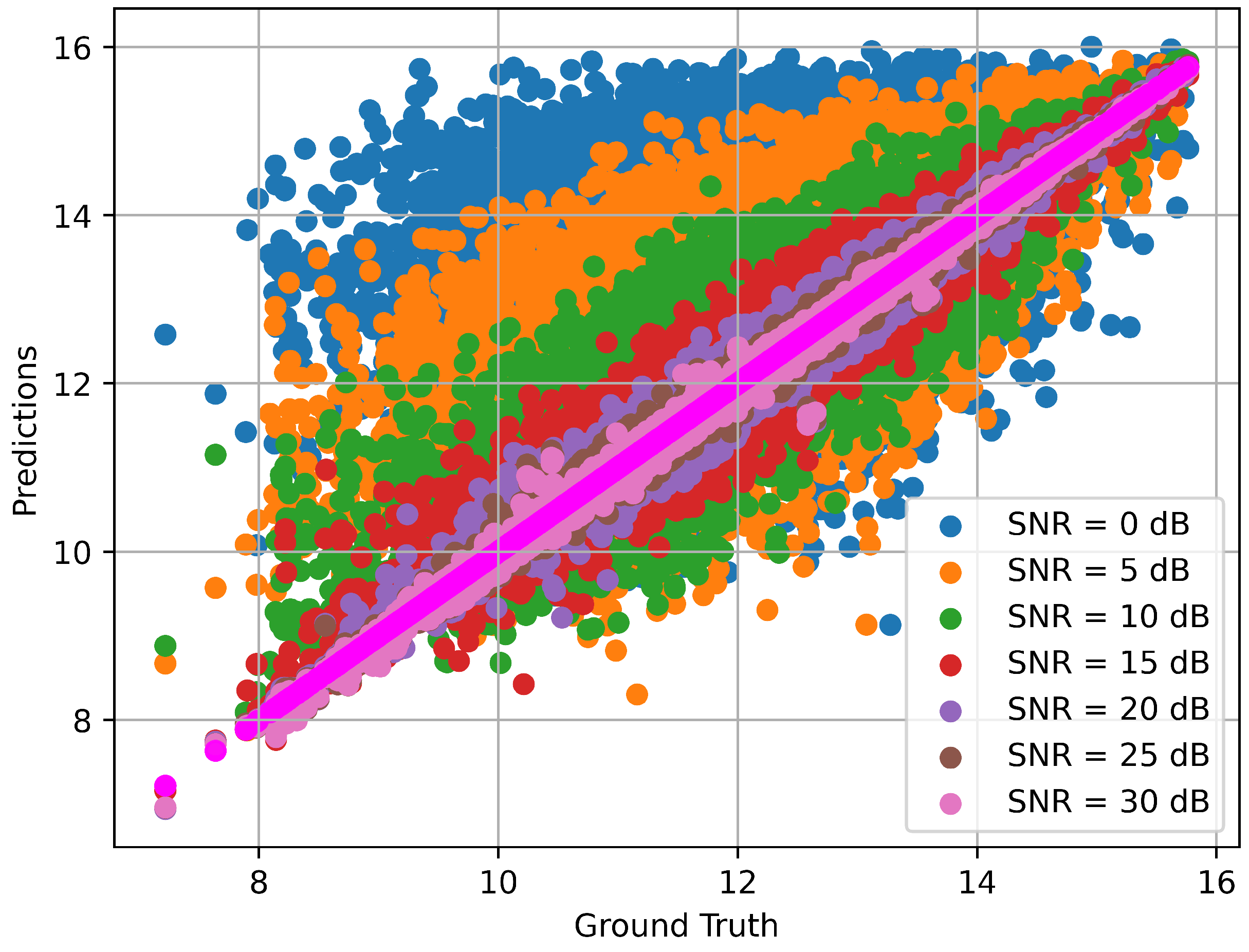
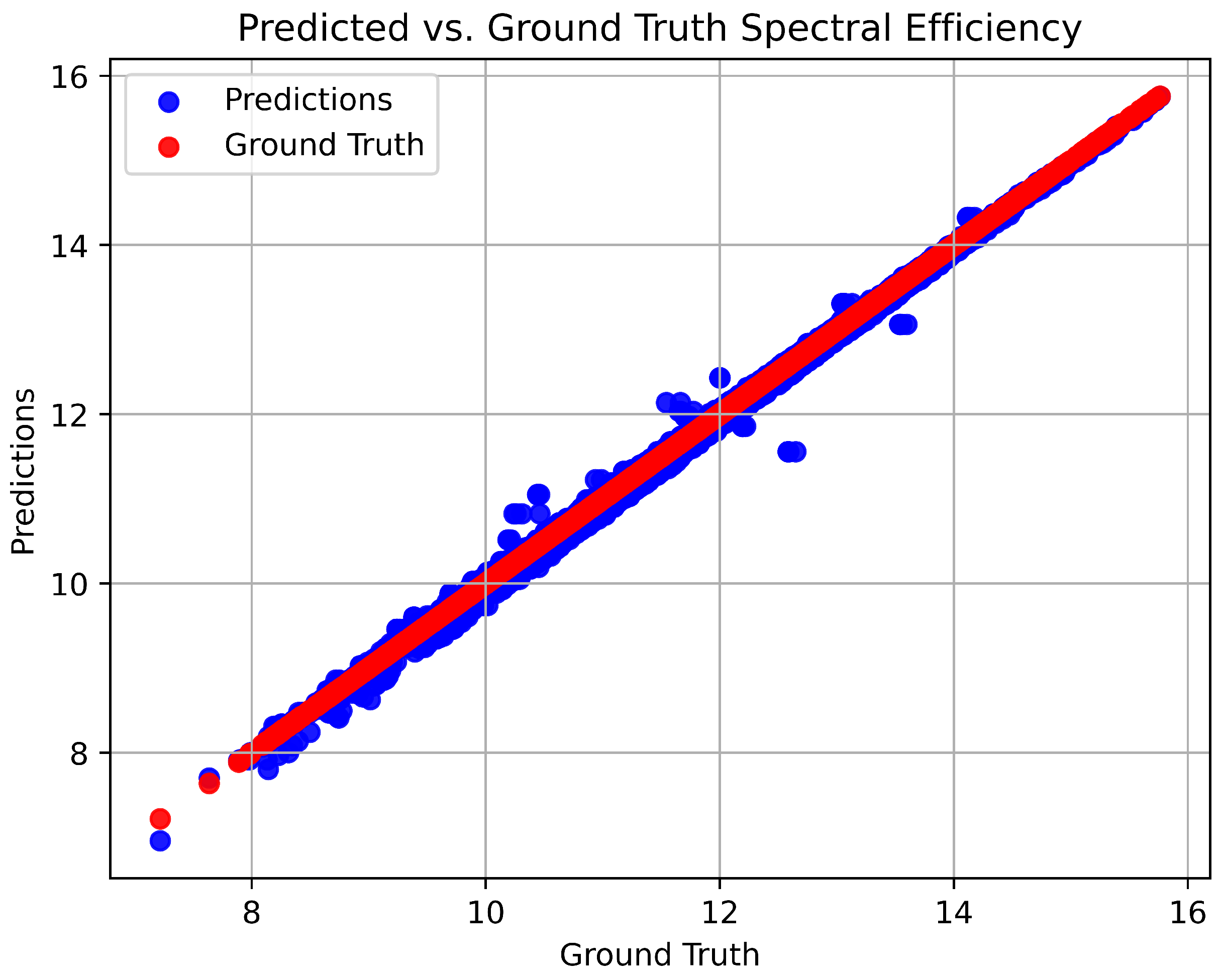
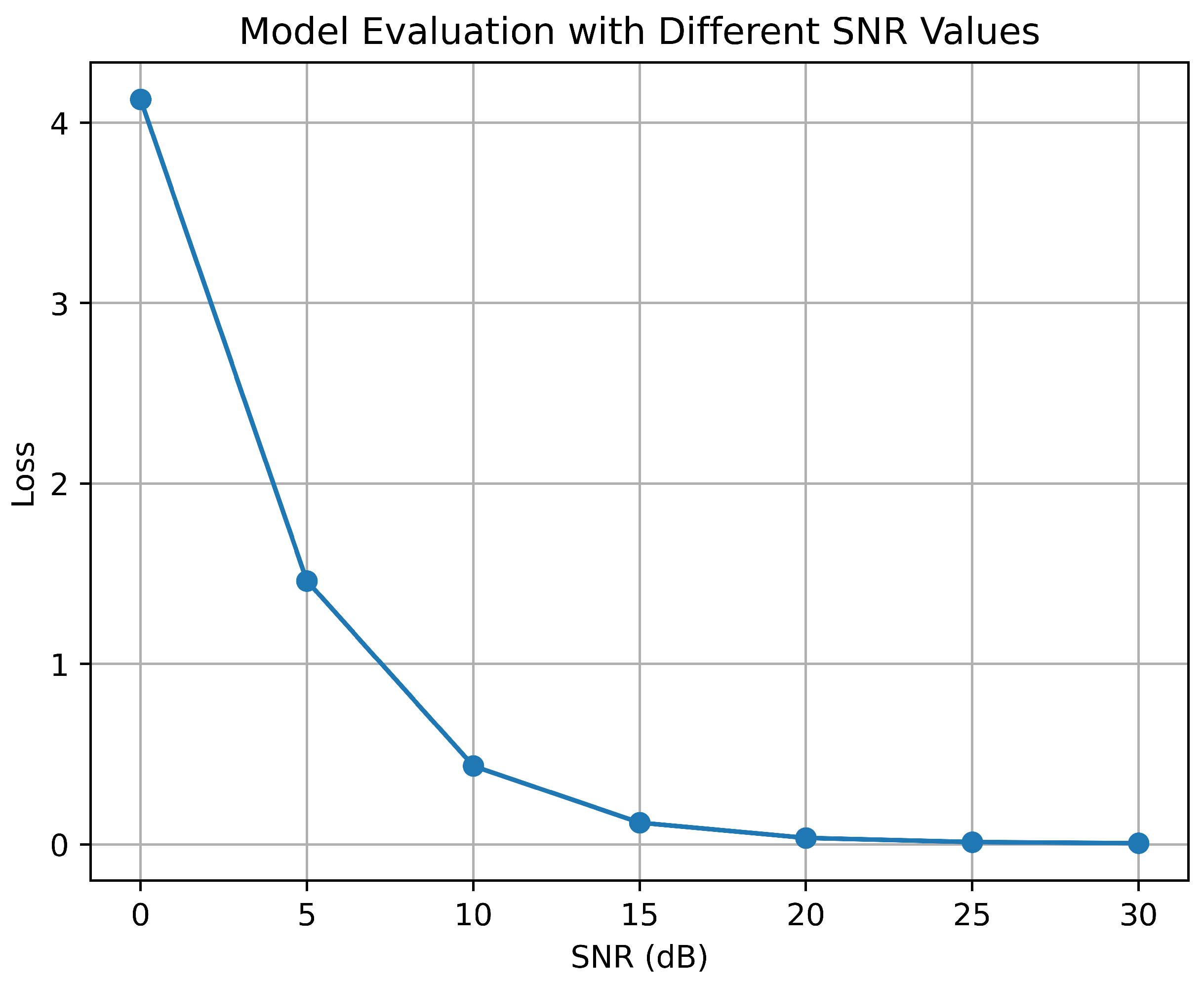
4. Simulation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Basar, E.; Di Renzo, M.; De Rosny, J.; Debbah, M.; Alouini, M.S.; Zhang, R. Wireless communications through reconfigurable intelligent surfaces. IEEE Access 2019, 7, 116753–116773. [Google Scholar] [CrossRef]
- Gong, S.; Lu, X.; Hoang, D.T.; Niyato, D.; Shu, L.; Kim, D.I.; Liang, Y.C. Toward smart wireless communications via intelligent reflecting surfaces: A contemporary survey. IEEE Commun. Surv. Tutor. 2020, 22, 2283–2314. [Google Scholar] [CrossRef]
- Yang, L.; Yang, J.; Xie, W.; Hasna, M.O.; Tsiftsis, T.; Di Renzo, M. Secrecy performance analysis of RIS-aided wireless communication systems. IEEE Trans. Veh. Technol. 2020, 69, 12296–12300. [Google Scholar] [CrossRef]
- Lin, Z.; Lin, M.; Champagne, B.; Zhu, W.P.; Al-Dhahir, N. Secrecy-energy efficient hybrid beamforming for satellite-terrestrial integrated networks. IEEE Trans. Commun. 2021, 69, 6345–6360. [Google Scholar] [CrossRef]
- Lin, Z.; Niu, H.; An, K.; Wang, Y.; Zheng, G.; Chatzinotas, S.; Hu, Y. Refracting RIS-aided hybrid satellite-terrestrial relay networks: Joint beamforming design and optimization. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3717–3724. [Google Scholar] [CrossRef]
- Sun, Y.; An, K.; Zhu, Y.; Zheng, G.; Wong, K.K.; Chatzinotas, S.; Yin, H.; Liu, P. RIS-assisted robust hybrid beamforming against simultaneous jamming and eavesdropping attacks. IEEE Trans. Wirel. Commun. 2022, 21, 9212–9231. [Google Scholar] [CrossRef]
- Sun, Y.; An, K.; Zhu, Y.; Zheng, G.; Wong, K.K.; Chatzinotas, S.; Ng, D.W.K.; Guan, D. Energy-efficient hybrid beamforming for multilayer RIS-assisted secure integrated terrestrial-aerial networks. IEEE Trans. Commun. 2022, 70, 4189–4210. [Google Scholar] [CrossRef]
- Zhou, S.; Xu, W.; Wang, K.; Di Renzo, M.; Alouini, M.S. Spectral and Energy Efficiency of IRS-Assisted MISO Communication With Hardware Impairments. IEEE Wirel. Commun. Lett. 2020, 9, 1366–1369. [Google Scholar] [CrossRef]
- Rahman, M.H.; Sejan, M.A.S.; Aziz, M.A.; Kim, D.S.; You, Y.H.; Song, H.K. Spectral Efficiency Analysis for IRS-Assisted MISO Wireless Communication: A Metaverse Scenario Proposal. Mathematics 2023, 11, 3181. [Google Scholar] [CrossRef]
- Fang, F.; Xu, Y.; Pham, Q.V.; Ding, Z. Energy-Efficient Design of IRS-NOMA Networks. IEEE Trans. Veh. Technol. 2020, 69, 14088–14092. [Google Scholar] [CrossRef]
- Lin, Y.; Jin, S.; Matthaiou, M.; You, X. Channel Estimation and User Localization for IRS-Assisted MIMO-OFDM Systems. IEEE Trans. Wirel. Commun. 2022, 21, 2320–2335. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, M.; Zhang, G.; Cui, M. Achievable Rate Maximization for Intelligent Reflecting Surface-Assisted Orbital Angular Momentum-Based Communication Systems. IEEE Trans. Veh. Technol. 2021, 70, 7277–7282. [Google Scholar] [CrossRef]
- Sejan, M.A.S.; Rahman, M.H.; Shin, B.S.; Oh, J.H.; You, Y.H.; Song, H.K. Machine Learning for Intelligent-Reflecting-Surface-Based Wireless Communication towards 6G: A Review. Sensors 2022, 22, 5405. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Liu, X.; Gao, Y.; Zhang, C.; Zhang, W. Deep learning for channel tracking in IRS-assisted UAV communication systems. IEEE Trans. Wirel. Commun. 2022, 21, 7711–7722. [Google Scholar] [CrossRef]
- Yang, H.; Xiong, Z.; Zhao, J.; Niyato, D.; Xiao, L.; Wu, Q. Deep reinforcement learning-based intelligent reflecting surface for secure wireless communications. IEEE Trans. Wirel. Commun. 2020, 20, 375–388. [Google Scholar] [CrossRef]
- Rahman, M.H.; Sejan, M.A.S.; Aziz, M.A.; Baik, J.I.; Kim, D.S.; Song, H.K. Deep Learning-Based Improved Cascaded Channel Estimation and Signal Detection for Reconfigurable Intelligent Surfaces-Assisted MU-MISO Systems. IEEE Trans. Green Commun. Netw. 2023, 7, 1515–1527. [Google Scholar] [CrossRef]
- Feng, K.; Wang, Q.; Li, X.; Wen, C.K. Deep reinforcement learning based intelligent reflecting surface optimization for MISO communication systems. IEEE Wirel. Commun. Lett. 2020, 9, 745–749. [Google Scholar] [CrossRef]
- Xu, P.; Roosta, F.; Mahoney, M.W. Second-order optimization for non-convex machine learning: An empirical study. In Proceedings of the 2020 SIAM International Conference on Data Mining, Cincinnati, OH, USA, 7–9 May 2020; pp. 199–207. [Google Scholar]
- Wen, F.; Chu, L.; Liu, P.; Qiu, R.C. A survey on nonconvex regularization-based sparse and low-rank recovery in signal processing, statistics, and machine learning. IEEE Access 2018, 6, 69883–69906. [Google Scholar] [CrossRef]
- Jin, C.; Netrapalli, P.; Ge, R.; Kakade, S.M.; Jordan, M.I. On nonconvex optimization for machine learning: Gradients, stochasticity, and saddle points. J. ACM (JACM) 2021, 68, 1–29. [Google Scholar] [CrossRef]
- Zaid, G.; Bossuet, L.; Dassance, F.; Habrard, A.; Venelli, A. Ranking loss: Maximizing the success rate in deep learning side-channel analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2021, 2021, 25–55. [Google Scholar] [CrossRef]
- Huang, C.; Mo, R.; Yuen, C. Reconfigurable intelligent surface assisted multiuser MISO systems exploiting deep reinforcement learning. IEEE J. Sel. Areas Commun. 2020, 38, 1839–1850. [Google Scholar] [CrossRef]
- Zohari, F.; Shahabi, S.; Ardebilipour, M. A Novel Deep Reinforcement Learning-based Approach for Enhancing Spectral Efficiency of IRS-assisted Wireless Systems. arXiv 2023, arXiv:2302.14706. [Google Scholar]
- Zahedi, Z.; Ardebilipur, M.; Dehrouye, F. Improved Spectral Efficiency of RIS-Aided 6G Communication Using Deep Learning. In Proceedings of the 2022 30th International Conference on Electrical Engineering (ICEE), Seoul, Republic of Korea, 28 June–2 July 2022; pp. 175–179. [Google Scholar]
- Bobrov, E.; Troshin, S.; Chirkova, N.; Lobacheva, E.; Panchenko, S.; Vetrov, D.; Kropotov, D. Machine learning methods for spectral efficiency prediction in massive mimo systems. arXiv 2021, arXiv:2112.14423. [Google Scholar]
- Perdana, R.H.Y.; Nguyen, T.V.; An, B. Adaptive User Pairing in Multi-IRS-aided Massive MIMO-NOMA Networks: Spectral Efficiency Maximization and Deep Learning Design. IEEE Trans. Commun. 2023, 71, 4377–4390. [Google Scholar] [CrossRef]
- Rahman, M.H.; Sejan, M.A.S.; Aziz, M.A.; Kim, D.S.; You, Y.H.; Song, H.K. Deep Convolutional and Recurrent Neural-Network-Based Optimal Decoding for RIS-Assisted MIMO Communication. Mathematics 2023, 11, 3397. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM—A tutorial into long short-term memory recurrent neural networks. arXiv 2019, arXiv:1909.09586. [Google Scholar]
- Smagulova, K.; James, A.P. A survey on LSTM memristive neural network architectures and applications. Eur. Phys. J. Spec. Top. 2019, 228, 2313–2324. [Google Scholar] [CrossRef]
- Shu, T.; Chen, J.; Bhargava, V.K.; de Silva, C.W. An energy-efficient dual prediction scheme using LMS filter and LSTM in wireless sensor networks for environment monitoring. IEEE Internet Things J. 2019, 6, 6736–6747. [Google Scholar] [CrossRef]
- Sun, W.; Li, P.; Liu, Z.; Xue, X.; Li, Q.; Zhang, H.; Wang, J. LSTM based link quality confidence interval boundary prediction for wireless communication in smart grid. Computing 2021, 103, 251–269. [Google Scholar] [CrossRef]
- Gupta, K.D.; Nigam, R.; Sharma, D.K.; Dhurandher, S.K. LSTM-Based Energy-Efficient Wireless Communication with Reconfigurable Intelligent Surfaces. IEEE Trans. Green Commun. Netw. 2021, 6, 704–712. [Google Scholar] [CrossRef]
- Shah, S.H.A.; Sharma, M.; Rangan, S. LSTM-based multi-link prediction for mmWave and sub-THz wireless systems. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Tsuchiya, Y.; Suga, N.; Uruma, K.; Fujisawa, M. LSTM-based Spectral Efficiency Prediction by Capturing Wireless Terminal Movement in IRS-Assisted Systems. In Proceedings of the 2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), Helsinki, Finland, 19–22 June 2022; pp. 1–5. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The Performance of LSTM and BiLSTM in Forecasting Time Series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3285–3292. [Google Scholar] [CrossRef]
- Xie, X.; Fang, F.; Ding, Z. Joint optimization of beamforming, phase-shifting and power allocation in a multi-cluster IRS-NOMA network. IEEE Trans. Veh. Technol. 2021, 70, 7705–7717. [Google Scholar] [CrossRef]
- Fu, M.; Zhou, Y.; Shi, Y.; Letaief, K.B. Reconfigurable Intelligent Surface Empowered Downlink Non-Orthogonal Multiple Access. IEEE Trans. Commun. 2021, 69, 3802–3817. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Chen, Y.; Poor, H.V. RIS enhanced massive non-orthogonal multiple access networks: Deployment and passive beamforming design. IEEE J. Sel. Areas Commun. 2020, 39, 1057–1071. [Google Scholar] [CrossRef]
- Chen, J.C. Hybrid beamforming with discrete phase shifters for millimeter-wave massive MIMO systems. IEEE Trans. Veh. Technol. 2017, 66, 7604–7608. [Google Scholar] [CrossRef]
- Wiener, N.; Wiener, N.; Mathematician, C.; Wiener, N.; Wiener, N.; Mathématicien, C. Extrapolation, Interpolation, and Smoothing of Stationary Time Series: With Engineering Applications; MIT Press: Cambridge, MA, USA, 1949; Volume 113. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Ahn, Y.; Kim, W.; Shim, B. Active user detection and channel estimation for massive machine-type communication: Deep learning approach. IEEE Internet Things J. 2021, 9, 11904–11917. [Google Scholar] [CrossRef]
- Jung, J.S.; Park, C.Y.; Oh, J.H.; Song, H.K. Intelligent reflecting surface for spectral efficiency maximization in the multi-user MISO communication systems. IEEE Access 2021, 9, 134695–134702. [Google Scholar] [CrossRef]
- Liu, C.; Liu, X.; Wei, Z.; Hu, S.; Ng, D.W.K.; Yuan, J. Deep learning-empowered predictive beamforming for IRS-assisted multi-user communications. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–7. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Explanation |
|---|---|
| At iteration t, the activation vector of forget gate | |
| Weight vector for forget gate | |
| Input vector of LSTM at iteration t | |
| The hidden state vector at iteration | |
| Bias vector of forget gate | |
| Q | Sigmoid activation function |
| Input gate activation vector at repetition t | |
| Weight vectors of input gate | |
| Bias vector of input gate | |
| Candidate gate activation vector at repetition t | |
| Weight vectors of candidate gate | |
| Candidate gate bias vector | |
| Output gate activation vector at repetition t | |
| Weight vectors of output gate | |
| Output gate bias vector | |
| The cell state vector at repetition t | |
| The hidden state vector at repetition t | |
| The hidden state vector of Bi-LSTM layer output | |
| Hyperbolic tangent function | |
| The Bi-LSTM network forward sequence | |
| Backward sequence of the Bi-LSTM network |
| Parameters | Value |
|---|---|
| Number of samples | 10,000 |
| Number of base antenna | 8 |
| Number of transmission antenna | 8 |
| Noise type | AWGN |
| Total model layer | 5 |
| Number of LSTM hidden layer | 400 |
| Number of IRS elements | 8 |
| Learning rate | |
| Batch size | 100 |
| Number of epoch | 800 |
| Optimizer | Adam |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aziz, M.A.; Rahman, M.H.; Sejan, M.A.S.; Baik, J.-I.; Kim, D.-S.; Song, H.-K. Spectral Efficiency Improvement Using Bi-Deep Learning Model for IRS-Assisted MU-MISO Communication System. Sensors 2023, 23, 7793. https://doi.org/10.3390/s23187793
Aziz MA, Rahman MH, Sejan MAS, Baik J-I, Kim D-S, Song H-K. Spectral Efficiency Improvement Using Bi-Deep Learning Model for IRS-Assisted MU-MISO Communication System. Sensors. 2023; 23(18):7793. https://doi.org/10.3390/s23187793
Chicago/Turabian StyleAziz, Md Abdul, Md Habibur Rahman, Mohammad Abrar Shakil Sejan, Jung-In Baik, Dong-Sun Kim, and Hyoung-Kyu Song. 2023. "Spectral Efficiency Improvement Using Bi-Deep Learning Model for IRS-Assisted MU-MISO Communication System" Sensors 23, no. 18: 7793. https://doi.org/10.3390/s23187793
APA StyleAziz, M. A., Rahman, M. H., Sejan, M. A. S., Baik, J.-I., Kim, D.-S., & Song, H.-K. (2023). Spectral Efficiency Improvement Using Bi-Deep Learning Model for IRS-Assisted MU-MISO Communication System. Sensors, 23(18), 7793. https://doi.org/10.3390/s23187793