


Hybrid Learning Models for IMU-Based HAR with Feature Analysis and Data Correction


Abstract
:1. Introduction
- In non-vision situations, one IMU sensor node is applied to distinguish the whole-body movement between motion transition and a continuous motion.
- We propose a method of generating images from time series data that visually indicate the characteristics of inertial signals and generate multiple fake images based on AE and GAN models to improve classification accuracy.
- We evaluate the accuracy and characteristics of classification models. The results show that XGBoost has the best results in non-uniform actions using a small amount of data.
- We evaluate the classification accuracy using fake images and select the best-accuracy to perform for data correction.
- We propose a real-time BAN system to correct inertial signal data and classify human body movements.
2. Related Works
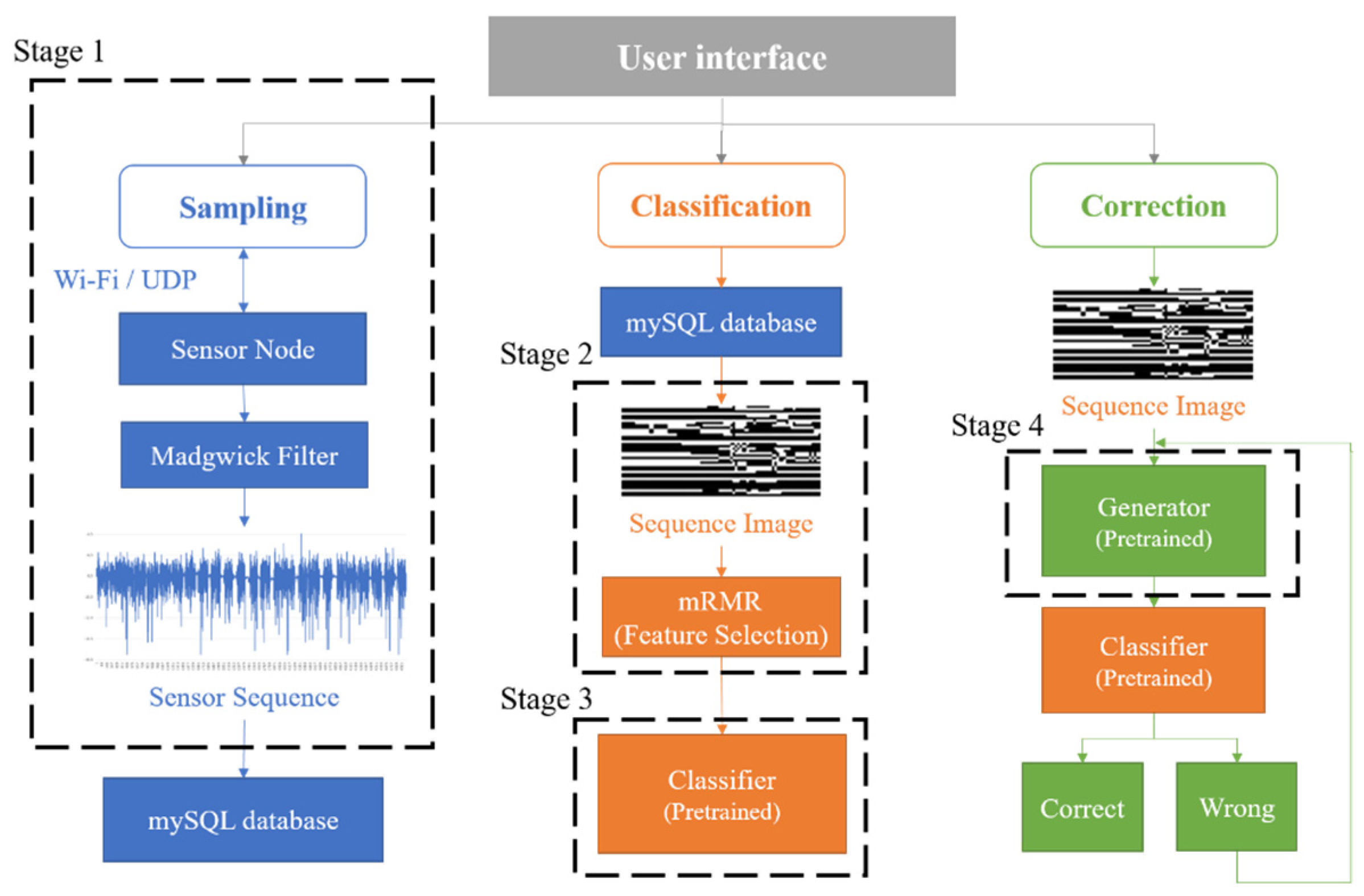
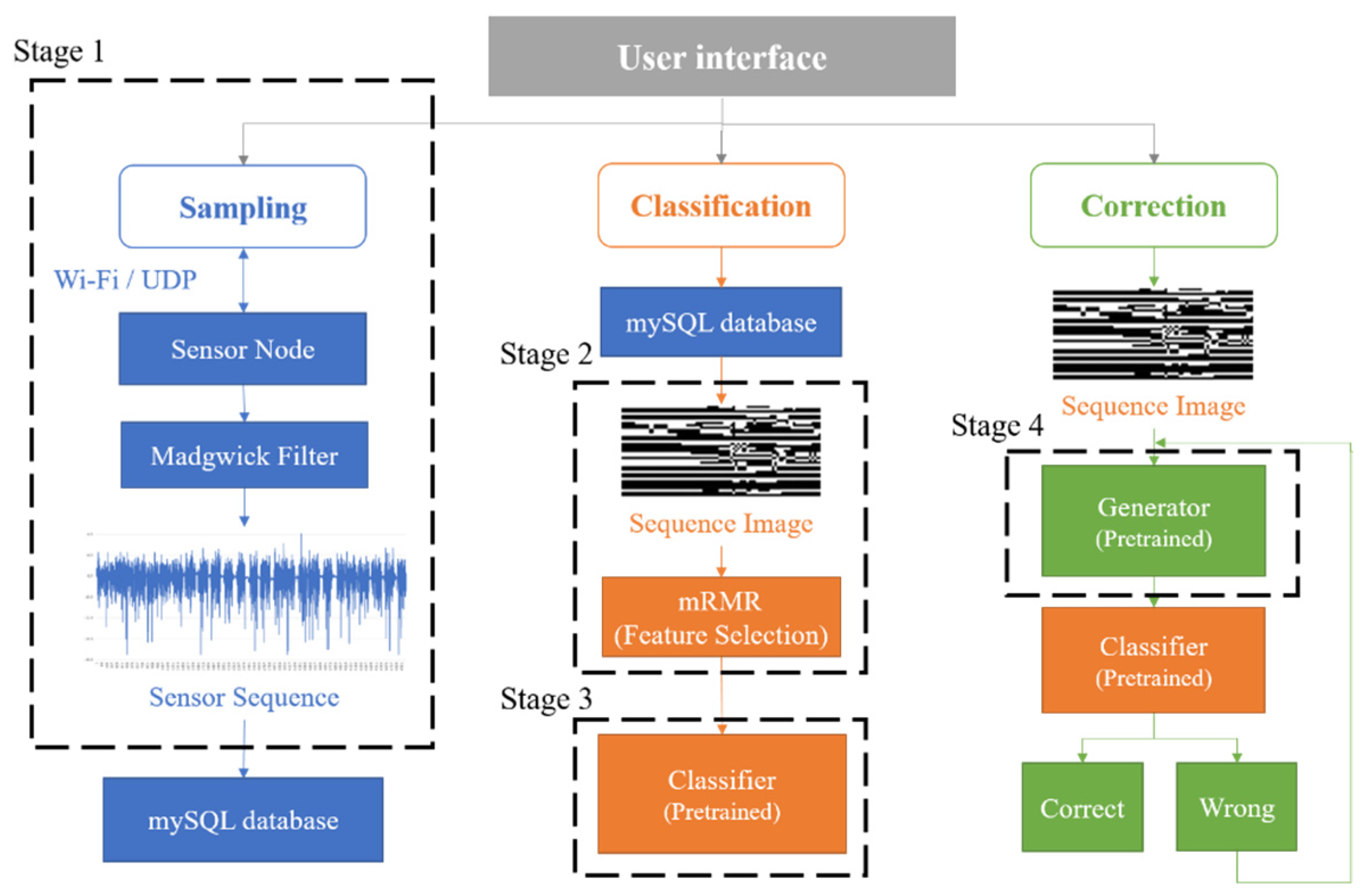
3. System Description
- Stage 1—Networked sensing and data sampling: The data collection process is performed via a BAN system based on Wi-Fi wireless technology.
- Stage 2—Data pre-processing: A new image generation method is developed to preserve the correlation between each inertial signal and filter features via the PCA and the minimum redundancy–maximum relevance (mRMR) feature selection algorithm. Moreover, images at various scales are generated to determine the appropriate image sizes.
- Stage 3—Activity classification: We determine effective models by integrating algorithms (e.g., traditional machine learning, deep neural network, and transfer learning) and hyperparameter optimization methods (e.g., K-Fold cross-validation, GS, and RS).
- Stage 4—Data generation: Multiple generative models are developed to implement data augmentation and improve data generalization. Then, we select the pre-trained generative model with the highest accuracy to execute data correction.
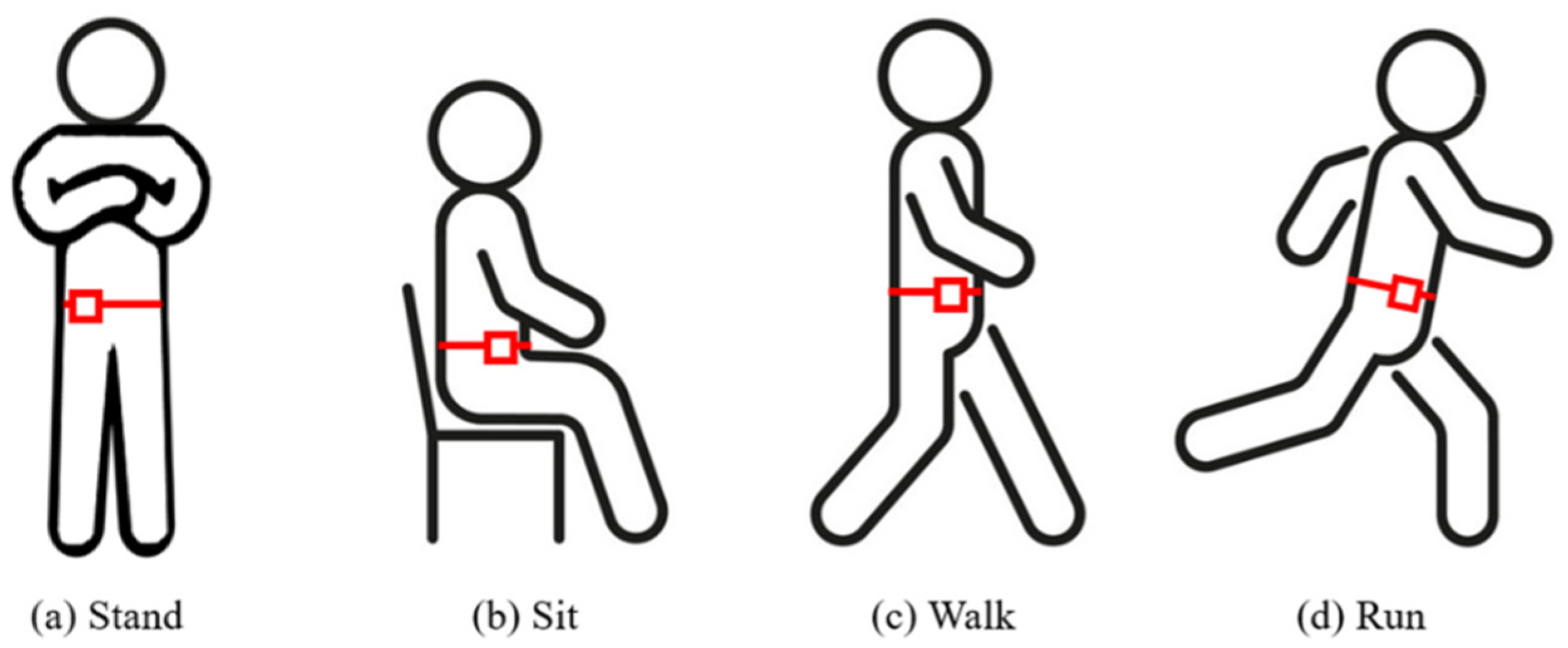
3.1. Stage 1: Networked Sensing and Data Sampling
3.2. Stage 2: Data Pre-Processing
3.3. Stage 3: Activity Classification
3.4. Stage 4: Data Generation
- (1).
- Autoencoder (AE)
- (2).
- Convolutional Variational Autoencoder (CVAE)
- (3).
- Generative Adversarial Network (GAN)
- (4).
- Adversarial Autoencoders (AAE)
- (5).
- Deep Convolutional Generative Adversarial Network (DCGAN)
- (6).
- Conditional GAN (CGAN)
4. System Evaluation
4.1. Singal Processing
4.2. Feature Engineering
4.3. Data Augmentation
4.4. Classifier and Generator
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qi, W.; Wang, N.; Su, H.; Aliverti, A. DCNN based human activity recognition framework with depth vision guiding. Neurocomputing 2022, 486, 261–271. [Google Scholar] [CrossRef]
- Bianchi, V.; Bassoli, M.; Lombardo, G.; Fornacciari, P.; Mordonini, M.; Munari, I.D. IoT Wearable Sensor and Deep Learning: An Integrated Approach for Personalized Human Activity Recognition in a Smart Home Environment. IEEE Internet Things J. 2019, 6, 8553–8562. [Google Scholar] [CrossRef]
- Kim, Y.W.; Joa, K.L.; Jeong, H.Y.; Lee, S. Wearable IMU-based human activity recognition algorithm for clinical balance assessment using 1D-CNN and GRU ensemble model. Sensors 2021, 21, 7628. [Google Scholar] [CrossRef] [PubMed]
- Antonelli, M.; Digo, E.; Pastorelli, S.; Gastaldi, L. Wearable MIMUs for the identification of upper limbs motion in an industrial context of human-robot interaction. In Proceedings of the 18th International Conference on Informatics in Control, Automation and Robotics (ICINCO 2021), Online, 6–8 July 2021; pp. 403–409. [Google Scholar]
- Ann, O.C.; Theng, L.B. Human activity recognition: A review. In Proceedings of the 2014 IEEE International Conference on Control System, Computing and Engineering (ICCSCE 2014), Penang, Malaysia, 28–30 November 2014. [Google Scholar]
- Zhou, H.; Hu, H. Human motion tracking for rehabilitation—A survey. Biomed. Signal Process. Control 2008, 3, 1–18. [Google Scholar] [CrossRef]
- Ayman, A.; Attalah, O.; Shaban, H. Smart System for Recognizing Daily Human Activities Based on Wrist IMU Sensors. In Proceedings of the 2019 International Conference on Advances in the Emerging Computing Technologies (AECT), Al Madinah Al Munawwarah, Saudi Arabia, 10 February 2020. [Google Scholar]
- Ambroziak, S.J.; Correia, L.M.; Katulski, R.J.; Mackowiak, M.; Oliveira, C.; Sadowski, J.; Turbic, K. An Off-Body Channel Model for Body Area Networks in Indoor Environments. IEEE Trans. Antennas Propag. 2016, 64, 4022–4035. [Google Scholar] [CrossRef]
- Euston, M.; Coote, P.; Mahony, R.; Kim, J.; Hamel, T. A complementary filter for attitude estimation of a fixed-wing UAV. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008. [Google Scholar]
- Madgwick, S.; Vaidyanathan, R.; Harrison, A. An efficient orientation filter for inertial and inertial/magnetic sensor arrays. In Proceedings of the IEEE International Conference on Rehabilitation Robotics, Zurich, Switzerland, 29 June–1 July 2011. [Google Scholar]
- Huynh, T.; Fritz, M.; Schiele, B. Discovery of activity patterns using topic models. In Proceedings of the 10th International Conference on Ubiquitous Computing—UbiComp, Seoul, Republic of Korea, 21–24 September 2008; p. 10. [Google Scholar]
- Zappi, P.; Lombriser, C.; Stiefmeier, T.; Farella, E.; Roggen, D.; Benini, L.; Tröster, G. Activity Recognition from On-Body Sensors: Accuracy-Power Trade-Off by Dynamic Sensor Selection. In Wireless Sensor Networks; Springer: Berlin/Heidelberg, Germany, 2008; pp. 17–33. [Google Scholar]
- Bachlin, M.; Plotnik, M.; Roggen, D.; Maidan, I.; Hausdorff, J.M.; Giladi, N.; Troster, G. Wearable Assistant for Parkinson’s Disease Patients with the Freezing of Gait Symptom. IEEE Trans. Inf. Technol. Biomed. 2009, 14, 436–446. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the ESANN 2013 Proceedings, 21th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013; pp. 437–442. [Google Scholar]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data. In Pervasive computing; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–17. [Google Scholar]
- Maurer, U.; Smailagic, A.; Siewiorek, D.P.; Deisher, M. Activity Recognition and Monitoring Using Multiple Sensors on Different Body Positions. In Proceedings of the International Workshop on Wearable and Implantable Body Sensor Networks (BSN’06), Cambridge, MA, USA, 3–5 April 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 113–116. [Google Scholar] [CrossRef]
- Ermes, M.; Parkka, J.; Mantyjarvi, J.; Korhonen, I. Detection of daily activities and sports with wearable sensors in controlled and uncontrolled conditions. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 20–26. [Google Scholar] [CrossRef]
- Lu, J.; Zheng, X.; Sheng, M.; Jin, J.; Yu, S. Efficient human activity recognition using a single wearable sensor. IEEE Internet Things J. 2020, 7, 11137–11146. [Google Scholar] [CrossRef]
- Ayman, A.; Attalah, O.; Shaban, H. An Efficient Human Activity Recognition Framework Based on Wearable IMU Wrist Sensors. In Proceedings of the 2019 IEEE International Conference on Imaging Systems and Techniques (IST), Abu Dhabi, United Arab Emirates, 9–10 December 2019. [Google Scholar]
- Kangas, M.; Konttila, A.; Winblad, I.; Jamsa, T. Determination of simple thresholds for accelerometry-based parameters for fall detection. In Proceedings of the 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 22–26 August 2007. [Google Scholar]
- Karantonis, D.M.; Narayanan, M.R.; Mathie, M.; Lovell, N.H.; Celler, B.G. Implementation of a real-time human movement classifier using a triaxial accelerometer for ambulatory monitoring. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 156–157. [Google Scholar] [CrossRef]
- Mascret, Q.; Bielmann, M.; Fall, C.; Bouyer, L.J.; Gosselin, B. Real-Time Human Physical Activity Recognition with Low Latency Prediction Feedback Using Raw IMU Data. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018. [Google Scholar]
- Han, J.; Song, W.; Gozho, A.; Sung, Y.; Ji, S.; Song, L.; Wen, L.; Zhang, Q. LoRa-Based Smart IoT Application for Smart City: An Example of Human Posture Detection. Wirel. Netw. Technol. Smart Cities 2020, 2020, 8822555. [Google Scholar] [CrossRef]
- mySQL Documentation: MySQL 8.0 Reference Manual. Available online: https://dev.mysql.com/doc/refman/8.0/en/ (accessed on 15 June 2023).
- Abdallah, N.H.; Brahim, R.; Bouslimani, Y.; Ghribi, M.; Kaddouri, A. IoT device for Athlete’s movements recognition using inertial measurement unit (IMU). In Proceedings of the 2021 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT), Bandung, Indonesia, 27–28 July 2021. [Google Scholar]
- Siwadamrongpong, W.; Chinrungrueng, J.; Hasegawa, S.; Nantajeewqrqwat, E. Fall Detection and Prediction Based on IMU and EMG Sensors for Elders. In Proceedings of the 2022 19th International Joint Conference on Computer Science and Software Engineering (JCSSE), Bangkok, Thailand, 22–25 June 2022. [Google Scholar]
- Guerra, J.; Uddin, J.; Nilsen, D.; Mclnerney, J.; Fadoo, A.; Omofuma, I.B.; Hughes, S.; Agrawal, S.; Allen, P.; Schambra, H.M. Capture, learning, and classification of upper extremity movement primitives in healthy controls and stroke patients. In Proceedings of the 2017 International Conference on Rehabilitation Robotics (ICORR), London, UK, 17–20 July 2017. [Google Scholar]
- Kuni, R.; Prathivadi, Y.; Wu, J.; Bennett, T.R.; Jafari, R. Exploration of interactions detectable by wearable IMU sensors. In Proceedings of the 2015 IEEE 12th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Cambridge, MA, USA, 9–12 June 2015. [Google Scholar]
- Mathie, M.J.; Celler, B.G.; Lovell, N.H.; Coster, A.C.F. Classification of basic daily movements using a triaxial accelerometer. Med. Biol. Eng. Comput. 2004, 42, 679–687. [Google Scholar] [CrossRef] [PubMed]
- Oliver, A.S.; Anuradha, M.; Justus, J.J.; Maheshwari, N. Optimized low computational algorithm for elderly fall detection based on machine learning techniques. Biomed. Res. 2018, 29, 3715–3722. [Google Scholar] [CrossRef]
- Arif, M.; Kattan, A. Physical activities monitoring using wearable acceleration sensors attached to the body. PLoS ONE 2015, 10, e0130851. [Google Scholar] [CrossRef] [PubMed]
- Qin, Z.; Huang, G.; Xiong, H.; Choo, K.-K.R. A fuzzy authentication system based on neural network learning and extreme value statistics. IEEE Trans. Fuzzy Syst. 2019, 29, 549–559. [Google Scholar] [CrossRef]
- Eyobu, O.S.; Han, D.S. Feature Representation and Data Augmentation for Human Activity Classification Based on Wearable IMU Sensor Data Using a Deep LSTM Neural Network. Sensors 2018, 18, 2892. [Google Scholar] [CrossRef]
- Tao, W.; Lai, Z.H.; Leu, M.C.; Yin, Z. Worker Activity Recognition in Smart Manufacturing Using IMU and sEMG Signals with Convolutional Neural Networks. Procedia Manuf. 2018, 26, 1159–1166. [Google Scholar] [CrossRef]
- Aghdam, H.H.; Heravi, E.J. Guide to Convolutional Neural Networks; Springer: New York, NY, USA, 2017; Volume 10. [Google Scholar]
- Bruinsma, J.; Carloni, R. IMU-Based Deep Neural Networks: Prediction of Locomotor and Transition Intentions of an Osseointegrated Transfemoral Amputee. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 1079–1088. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Zhang, X.; Zhang, J. Subject Independent Human Activity Recognition with Foot IMU Data. In Proceedings of the 2019 15th International Conference on Mobile Ad-Hoc and Sensor Networks (MSN), Shenzhen, China, 11–13 December 2019. [Google Scholar]
- Hou, C. A study on IMU-Based Human Activity Recognition Using Deep Learning and Traditional Machine Learning. In Proceedings of the 2020 5th International Conference on Computer and Communication Systems (ICCCS), Shanghai, China, 15–18 May 2020. [Google Scholar]
- Ajani, O.S.; Hussieny, H.E. An ANFIS-based Human Activity Recognition using IMU sensor Fusion. In Proceedings of the 2019 Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 28–30 October 2019. [Google Scholar]
- Siddiqui, N.; Chan, R.H.M. Multimodal hand gesture recognition using single IMU and acoustic measurements at wrist. PLoS ONE 2020, 15, e0227039. [Google Scholar] [CrossRef]
- Lopes, J.; Simão, M.; Mendes, N.; Safeea, M.; Afonso, J.; Neto, P. Hand/arm Gesture Segmentation by Motion Using IMU and EMG Sensing. Procedia Manuf. 2017, 11, 107–113. [Google Scholar] [CrossRef]
- Tran, N.T.; Tran, V.H.; Nguyen, N.B.; Nguyen, T.K.; Cheung, N.M. On Data Augmentation for GAN Training. IEEE Trans. Image Process. 2021, 30, 1882–1897. [Google Scholar] [CrossRef]
- Alzantot, M.; Chakraborty, S.; Srivastava, M. SenseGen: A deep learning architecture for synthetic sensor data generation. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017. [Google Scholar]
- Norgaard, S.; Saeedi, R.; Sasani, K.; Gebremedhin, A.H. Synthetic Sensor Data Generation for Health Applications: A Supervised Deep Learning Approach. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018. [Google Scholar]
- Si, C.; Wang, W.; Wang, L.; Tan, T. Multistage Adversarial Losses for Pose-Based Human Image Synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 118–126. [Google Scholar]
- Wang, J.; Chen, Y.; Gu, Y.; Xiao, Y.; Pan, H. SensoryGANs: An Effective Generative Adversarial Framework for Sensor-based Human Activity Recognition. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Zhang, X.; Yao, L.; Yuan, F. Adversarial variational embedding for robust semi-supervised learning. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 139–147. [Google Scholar]
- Mathur, A.; Zhang, T.; Bhattacharya, S.; Velickovic, P.; Joffe, L.; Lane, N.D.; Kawsar, F.; Lio, P. Using Deep Data Augmentation Training to Address Software and Hardware Heterogeneities in Wearable and Smartphone Sensing Devices. In Proceedings of the 2018 17th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Porto, Portugal, 11–13 April 2018; IEEE: Manhattan, NY, USA, 2018; pp. 200–211. [Google Scholar]
- Soleimani, E.; Nazerfard, E. Cross-subject transfer learning in human activity recognition systems using generative adversarial networks. Neurocomputing 2020, 426, 26–34. [Google Scholar] [CrossRef]
- Si, C.; Wang, W.; Wang, L.; Tan, T. Multistage Adversarial Losses for Pose-Based Human Image Synthesis. In Proceedings of the 2022 7th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 22–24 June 2022. [Google Scholar]
- Jiang, W.; Yin, Z. Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks. In Proceedings of the 23rd ACM international conference on Multimedia, New York, NY, USA, 26–30 October 2015; pp. 1307–1310. [Google Scholar]
- MPU-9150 Nine-Axis (Gyro + Accelerometer + Compass) MEMS MotionTracking™ Device. Available online: https://invensense.tdk.com/products/motion-tracking/9-axis/mpu-9150-2/ (accessed on 15 June 2023).
- BNO055′s Datasheet. Available online: https://cdn-shop.adafruit.com/datasheets/BST_BNO055_DS000_12.pdf (accessed on 25 July 2023).
- The Register Map Document of the MPU9150. Available online: https://inertialelements.com/documents/resources_page/MPU9150-register-manual.pdf (accessed on 15 June 2023).
- MPU9150′s Datasheet. Available online: https://www.digikey.com/htmldatasheets/production/1474913/0/0/1/ak8963.html (accessed on 15 June 2023).
- Boerema, S.T.; Velsen, L.V.; Schaake, L.; Tönis, T.M.; Hermens, H.J. Optimal Sensor Placement for Measuring Physical Activity with a 3D Accelerometer. Sensors 2014, 14, 3188–3206. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Zhang, Y.; Lv, D.; Chen, X.; Lu, J.; Liu, J. A new improved maximal relevance and minimal redundancy method based on feature subset. J. Supercomput. 2023, 79, 3157–3180. [Google Scholar] [CrossRef] [PubMed]
- ONNX 1.15.0 Documentation: API Reference. Available online: https://onnx.ai/onnx/api/index.html (accessed on 20 June 2023).
- ML.NET Documentation: ML.NET API Reference. Available online: https://learn.microsoft.com/en-us/dotnet/api/?view=ml-dotnet (accessed on 20 June 2023).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Works | IMU Signals | Characteristics | Limitations |
|---|---|---|---|
| SensoryGAN [47] | Acc | Apply generative adversarial network to generate sensor data | Use corresponding generative models for individual actions |
| X. Zhang [48] | Acc Gyro Mag | Use the semi-supervised GAN | Control classification results using custom parameters |
| A. Mathur [49] | Acc Gyro | Incorporate the heterogeneity of different sensors to enrich the training set | The diversity of synthetic data is limited and not guaranteed. |
| E. Soleimani [50] | Acc | Realize the Transfer Learning and use GAN to generate source domain data from the target domain | Limited diversity of newly generated data |
| The Purposed System | Acc Gyro Mag | Enrich the training set via data synthesis based on generative models such as AE or GAN | Train the network with limited data |
| Product | Spec | ADC | Notes |
|---|---|---|---|
| BNO055 [54] | ±125°/s to ±2000°/s | 16 bits | gyros |
| ±2 g, ±4 g, ±8 g, ±16 g | 14 bits | accel | |
| ±1300 µT (x-, y-axis); ±2500 µT (z-axis) | 0.3 µT | mag | |
| MPU9150 [55] (the IMU used in this work) | ±250, ±500, ±1000, ±2000°/s | 16 bits | gyros |
| ±2 g, ±4 g, ±8 g, ±16 g | 16 bits | accel | |
| ±1200 µT | 13 bits (0.3 µT per LSB) | mag |
| Machine Learning | Hyperparameters | Definition | Search Range | Method |
|---|---|---|---|---|
| Linear SVM | Cost (c) | the penalty parameter | 1 × 10−5~1 × 104 | GS |
| Poly SVM | Cost (c) | the penalty parameter | 1 × 10−5~1 × 104 | GS |
| Degree | the polynomial degree used to find the hyperplane required to split the data | 2~6 | ||
| Gamma | the extent to which the influence of a single training example reaches | 0.1~100 | ||
| KNN | K | the K-Neighbors closest to the new data after calculating the distance | [3, 5, 7, 9, 11] | GS |
| LDA | - | - | - | - |
| HMM | - | - | - | - |
| DT | max_depth | the maximum depth of the tree | 1~100 | GS |
| min_samples_split | the minimum number of samples required to split an internal node | 1~40 | RS | |
| min_samples_leaf | the minimum number of samples required at a leaf node | 1~20 | ||
| RF | n_estimators | the number of trees present in the forest | 100~1000 | RS |
| max_depth | the maximum depth of the tree | 10~100 | ||
| min_samples_leaf | the minimum number of samples required to split an internal node | 1~20 | ||
| min_samples_split | the minimum number of samples required at a leaf node | 1~10 | ||
| AdaBoost | n_estimators | the number of base estimators or weak learners | 50~100 | GS |
| learning_rate | shrinking the contribution of each classifier | 1 × 10−3~5 × 10−1 | RS | |
| XGBoost | max_depth | the maximum depth of the tree | 3~10 | GS |
| min_child_weight | the minimum sum of the instance weight needed in a child | 5~8 | ||
| eta (learning_rate) | The step size shrinkage used in the update step to prevent overfitting | 1 × 10−2~3 × 10−1 | RS | |
| LightGBM | max_depth | limit the tree’s depth | 3~12 | GS |
| num_leaves | control the complexity of the tree model | 20~100 | RS | |
| min_data_in_leaf | prevent overfitting in a leaf-wise tree | 200~1000 | ||
| CatBoost | iterations | the maximum number of trees that can be built | [10, 100, 150, 200, 250] | GS |
| depth | the depth of the tree | [2, 4, 6, 8] | ||
| learning_rate | the rate at which the model weights are updated after working through each batch of training examples | 0.03~0.1 | RS | |
| l2_leaf_reg | the coefficient for the L2 regularization term of the cost function | 0.2~3.0 |
| Deep Learning | Hyperparameters | Optimization | Layer Type | Layer Information |
|---|---|---|---|---|
| DNN | learning_rate (LR): 1 × 10−6 batch_size: 2 epochs: 300 | LR tuning from RS in the range of [1 × 10−7~5 × 10−5] | Fully Connected and Dropout [input] | input size: img_size × img_size, hidden units: 256, activation: relu, dropout: 0.4 |
| Fully Connected [hidden] | the number of layers: 4, hidden units: [16, 32, 64, 128], activation: relu | |||
| Fully Connected [output] | hidden units: output_size, activation: relu | |||
| BPNN | learning_rate (LR): 1 × 10−5 batch_size: 2 epochs: 500 | LR tuning from RS in the range of [5 × 10−5~3 × 10−4] | Dropout and Fully Connected [input] | input size: img_size × img_size, hidden units: 512, activation: relu, dropout: 0.5 |
| Dropout and Fully Connected [hidden] | hidden units: 128, activation: relu, dropout: 0.5 | |||
| Dropout and Fully Connected [output] | hidden units: output_size, activation: softmax, dropout: 0.5 | |||
| CNN | learning_rate (LR): 2 × 10−6 batch_size: 2 epochs: 300 | LR tuning from RS in the range of [1 × 10−7~5 × 10−5] | Conv2D and maxPool2D [input] | input size: [img_size, img_size, 1], kernels: [5 × 5], filters: 32, pool_size: [2 × 2], activation: relu |
| Conv2D and maxPool2D | kernels: [5 × 5], filters: 64, pool_size: [2 × 2], activation: relu | |||
| Dropout and Flatten | hidden units: 128, activation: relu, dropout: 0.5 | |||
| Fully Connected [output] | hidden units: output_size, activation: softmax | |||
| CapsNET | learning_rate (LR): 1 × 10−4 decay_rate: 1 × 10−6 batch_size: 4 epochs: 25 | LR tuning from RS in the range of [2 × 10−4~1 × 10−3] | Conv2D, BN, and MaxPool2D [input] | input size: [img_size, img_size, 1], kernels: [2 × 2], filters: 32, pool_size: [2 × 2], activation: relu |
| Conv2D, BN, and MaxPool2D | kernels: [2 × 2], filters: 64, pool_size: [2 × 2], activation: relu | |||
| Conv2D, BN, and MaxPool2D | kernels: [2 × 2], filters: 128, pool_size: [2 × 2], activation: relu | |||
| PrimaryCap | kernels: [2 × 2], dim_capsule: 4, n_channels: 16, strides: 1 | |||
| CapsuleLayer | num_capsule: output_size, dim_capsule: 4, num_routing: 3 | |||
| Dropout and Flatten | dropout: 0.8 | |||
| Fully Connected [output] | hidden units: output_size, activation: softmax |
| Generative Model | Neural Network | Layer Type | Layer Information | |
|---|---|---|---|---|
| AE | Encoder | Fully Connected [input] | input size: img_size × img_size, hidden units: 128, activation: sigmoid | |
| Fully Connected [output] | hidden units: 64, activation: sigmoid | |||
| Decoder | Fully Connected [input] | input size: 64, hidden units: 128, activation: sigmoid | ||
| Fully Connected [output] | hidden units: img_size × img_size, activation: sigmoid | |||
| CVAE | Encoder | Conv2D and maxPool2D [input] | input size: [img_size, img_size, 1], kernels: [3 × 3], filters: 64, pool_size: [2 × 2], activation: relu | |
| Conv2D and maxPool2D | kernels: [3 × 3], filters: 128, pool_size: [2 × 2], activation: relu | |||
| Flatten and Fully Connected [output] | hidden units: latent_dim | |||
| Decoder | Fully Connected [input] | input size: [latent_dim], hidden units: × 0.2564, activation: relu | ||
| Deconv2D and UnmaxPool2D | kernels: [3 × 3], filters: 128, pool_size: [2 × 2], activation: relu | |||
| Deconv2D and UnmaxPool2D | kernels: [3 × 3], filters: 64, pool_size: [2 × 2], activation: relu | |||
| Deconv2D and UnmaxPool2D [output] | kernels: [3 × 3], filters: 1, pool_size: [1 × 1] | |||
| GAN | Generator | Fully Connected and Dropout [input] | input size: img_size × img_size, hidden units: 128, activation: leakyrelu, dropout: 0.2 | |
| Fully Connected [output] | hidden units: img_size × img_size, activation: tanh | |||
| Discriminator | Fully Connected [input] | input size: img_size × img_size, hidden units: 128, activation: leakyrelu | ||
| Fully Connected [output] | hidden units: 1, activation: [relu, sigmoid] | |||
| AAE | Gene-rator | Encoder | Flatten [input] | input size: [img_size, img_size, 1] |
| Fully Connected [hidden] | the number of layers: 2, hidden units: [512, 512], activation: leakyrelu | |||
| Fully Connected [output] | the number of layers: 2, hidden units: [latent_dim, latent_dim] | |||
| Decoder | Fully Connected [input] | input size: [latent_dim], activation: leakyrelu | ||
| Fully Connected [hidden] | hidden units: 512, activation: leakyrelu | |||
| Fully Connected [output] | hidden units: img_size × img_size, activation: tanh | |||
| Discriminator | Fully Connected [input] | input size: [latent_dim], hidden units: 512, activation: leakyrelu | ||
| Fully Connected [hidden] | hidden units: 256, activation: leakyrelu | |||
| Fully Connected [output] | hidden units: 1, activation: sigmoid | |||
| DCGAN | Generator | Fully Connected [input] | input size: [g_dim] | |
| Deconv2D and BN | kernels: [5 × 5], filters: 32, activation: leakyrelu | |||
| Deconv2D and BN | kernels: [5 × 5], filters: 16, activation: relu | |||
| Deconv2D and BN [output] | kernels: [5 × 5], filters: 1, activation: tanh | |||
| Discriminator | Conv2D and BN [input] | input size: [img_size, img_size, 1], kernels: [5 × 5], filters: 32, activation: relu | ||
| Conv2D and BN | kernels: [5 × 5], filters: 64, activation: relu | |||
| Fully Connected [output] | hidden units: 1, activation: sigmoid | |||
| CGAN | Generator | Fully Connected and BN [input] | input size: [latent_dim], hidden units: 64, activation: leakyrelu | |
| Fully Connected and BN [hidden] | the number of layers: 2, hidden units: [128, 256], activation: leakyrelu | |||
| Fully Connected [output] | hidden units: img_size × img_size, activation: tanh | |||
| Discriminator | Fully Connected [input] | input size: img_size × img_size, hidden units: 64, activation: leakyrelu | ||
| Fully Connected [hidden] | the number of layers: 2, hidden units: [128, 256], activation: leakyrelu | |||
| Fully Connected [output] | hidden units: 1, activation: sigmoid | |||
| Size | Original Feature | FE | |||||
|---|---|---|---|---|---|---|---|
| RF | XGBoost | RF | XGBoost | ||||
| Acc | The Best Method | Acc | The Best Method | ||||
| Sequence | 19 × 100 | 93.83% | 90.12% | 95.06% | mRMR_10% | 92.59% | mRMR_30% |
| Image | 19 × 100 | 92.59% | 92.59% | 95.06% | mRMR_10% | 91.36% | mRMR_10% |
| 60 × 100 | 91.36% | 90.12% | 95.06% | mRMR_5% | 86.42% | mRMR_10% | |
| 60 × 60 | 91.36% | 92.59% | 88.89% | mRMR_10% | 88.89% | mRMR_10% | |
| 100 × 100 | 93.83% | 91.36% | 95.06% | mRMR_5% | 93.83% | mRMR_5% | |
| Original Feature | FE—mRMR_5% | |||
|---|---|---|---|---|
| RF | XGBoost | RF | XGBoost | |
| Original | 93.83% | 91.36% | 95.06% | 93.83% |
| Re-training | 93.83% | 95.06% | 91.36% | 96.03% |
| Classifier | RF (Pre-Trained) | XGBoost (Pre-Trained) | |
|---|---|---|---|
| Generator | |||
| AE | 46.25% | 25.00% | |
| CVAE | 59.00% | 80.75% | |
| GAN | 51.50% | 51.50% | |
| AAE | 50.25% | 63.00% | |
| DCGAN | 44.25% | 47.75% | |
| CGAN | 35.00% | 41.25% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tseng, Y.-H.; Wen, C.-Y. Hybrid Learning Models for IMU-Based HAR with Feature Analysis and Data Correction. Sensors 2023, 23, 7802. https://doi.org/10.3390/s23187802
Tseng Y-H, Wen C-Y. Hybrid Learning Models for IMU-Based HAR with Feature Analysis and Data Correction. Sensors. 2023; 23(18):7802. https://doi.org/10.3390/s23187802
Chicago/Turabian StyleTseng, Yu-Hsuan, and Chih-Yu Wen. 2023. "Hybrid Learning Models for IMU-Based HAR with Feature Analysis and Data Correction" Sensors 23, no. 18: 7802. https://doi.org/10.3390/s23187802
APA StyleTseng, Y.-H., & Wen, C.-Y. (2023). Hybrid Learning Models for IMU-Based HAR with Feature Analysis and Data Correction. Sensors, 23(18), 7802. https://doi.org/10.3390/s23187802