Abstract
Trajectory prediction aims to predict the movement intention of traffic participants in the future based on the historical observation trajectories. For traffic scenarios, pedestrians, vehicles and other traffic participants have social interaction of surrounding traffic participants in both time and spatial dimensions. Most previous studies only use pooling methods to simulate the interaction process between participants and cannot fully capture the spatio-temporal dependence, possibly accumulating errors with the increase in prediction time. To overcome these problems, we propose the Spatial–Temporal Interaction Attention-based Trajectory Prediction Network (STIA-TPNet), which can effectively model the spatial–temporal interaction information. Based on trajectory feature extraction, the novel Spatial–Temporal Interaction Attention Module (STIA Module) is proposed to extract the interaction relationships between traffic participants, including temporal interaction attention, spatial interaction attention, and spatio-temporal attention fusion. By adaptive allocation of attention weights, temporal interaction attention is a temporal attention mechanism used to capture the movement pattern of each traffic participant in the scene, which can learn the importance of historical trajectories at different moments to future behaviors. Since the participants number in recent traffic scenes dynamically changes, the spatial interaction attention is designed to abstract the traffic participants in the scene into graph nodes, and abstract the social interaction between participants into graph edges. Coupling the temporal and spatial interaction attentions can adaptively model the temporal–spatial information and achieve accurate trajectory prediction. By performing experiments on the INTERACTION dataset and the UTP (Unmanned Aerial Vehicle-based Trajectory Prediction) dataset, the experimental results show that the proposed method significantly improves the accuracy of trajectory prediction and outperforms the representative methods in comparison.
1. Introduction
Trajectory prediction aims to predict the movement intention of traffic participants in the future based on the historical observation trajectories, which plays an important role in intelligent transportation, self-driving, intelligent robots, etc. Compared with traditional trajectory prediction for just pedestrians, urban traffic scenarios involve pedestrians, vehicles and other traffic participants, which bring more difficulties. In this study, we focus on the traffic participants trajectory prediction task.
The trajectory prediction methods can be divided into traditional methods and deep-learning-based methods.
Traditional methods use manually designed models to predict trajectory, including the model of social forces [1], behavioral model [2], nonparametric statistical model [3], hidden Markov model [4], etc. For complex and crowded environments, the generalization of these methods is usually poor.
Compared with traditional trajectory prediction methods, the advantage of deep-learning-based trajectory prediction methods is that they do not rely on artificial design features, and can learn complex and diverse social interactions through training. The mainstream deep learning trajectory prediction methods are divided into Recurrent Neural Networks (RNN) [5,6,7], Generative Adversarial Networks (GAN) [8,9,10] and Graph Neural Networks (GNN) [11,12,13]. The RNN-based methods cannot achieve parallel processing, and the training speed and prediction performance usually need further improvement when dealing with multi-modal trajectories. The GAN-based methods can generate a trajectory distribution with multiple modalities, and also have some problems including unstable training and pattern collapse. The GNN-based methods can intuitively construct the topological relationship between traffic participants, and usually suffer degradation problems with deepening layers.
Based on these analyses, though all these methods based on RNN, GAN and GNN can model trajectories, the attention mechanisms [14,15,16,17] are key to effectively model the social interaction of surrounding traffic participants in both time and spatial dimensions. Furthermore, compared with the trajectory prediction task for just pedestrians, traffic participants including pedestrians, vehicles and others are with more complex behavioral patterns. Their motion states are affected by the historical trajectory and the social interaction of surrounding traffic participants. It is crucial to consider both the spatial and temporal interaction information. Yet, these previous methods just use pooling methods to simulate the interaction process between traffic participants, and cannot fully capture the spatio-temporal dependence between traffic participants in complex urban traffic scenarios, which may lead to the generation of some unreasonable prediction trajectories.
To overcome these problems, we propose the Spatial–Temporal Interaction Attention-based Trajectory Prediction Network (STIA-TPNet), which can effectively model the spatial–temporal interaction information. The trajectory prediction task is treated as a sequence prediction problem. The trajectory feature extraction module takes the historical trajectory information as input, and completes the extraction of key information by using embedding layers and LSTM networks. Based on trajectory feature extraction, the novel Spatial–Temporal Interaction Attention Module (STIA Module) is proposed to extract the interaction relationships between traffic participants, including temporal interaction attention, spatial interaction attention, and spatio-temporal attention fusion. The temporal interaction attention is a temporal attention mechanism used to capture the movement pattern of each traffic participant by adaptive allocating attention weights, which can learn the importance of historical trajectories at different moments to the future behaviors. Based on GNN structure to represent the dynamically changing participants, the spatial interaction attention is designed to abstract the participants in the scene into graph nodes, and abstract the social interaction between participants into graph edges. Coupling the temporal and spatial interaction attentions can adaptively model the temporal–spatial information and achieve accurate trajectory prediction. By performing experiments on the INTERACTION dataset [18] and the UTP (Unmanned Aerial Vehicle-based Trajectory Prediction) dataset, the experimental results show that the proposed method significantly improves the accuracy of trajectory prediction and outperforms the representative methods in comparison.
2. Related Works
In the trajectory prediction task for traffic scenarios, there are difficulties, including multiple interactive participants, multi-modal driver behavior, and inherent uncertainty in driver motion. Yet, previous methods just focus on pedestrians. The trajectory prediction methods can be divided into prediction methods based on traditional methods and deep-learning-based methods. We review the trajectory prediction methods in this section.
2.1. Trajectory Prediction Based on Traditional Methods
The model of social forces is a method that quantifies the interactions between participants as attraction and repulsion [1]. The social force model can be improved to improve trajectory prediction for large populations [19]. The explicit energy functions can also be used to estimate the hidden properties of participants [2]. Although the social force model can simulate the motion, the model only considers the action of force. The Gaussian process is used to predict the trajectories of each participant and the future trajectories based on the interaction potential function [3].
The hidden Markov model is commonly used to predict trajectories, which usually include three stages of Gaussian hybrid modeling, trajectory clustering and hidden Markov probability coding [4]. The nonparametric hidden Markov model can be used to predict the future trajectory [20]. Kitani et al. used inverse optimal control to train and optimize the model. Hidden Markov Decision Process Model [21] uses inverse optimal control to train and optimize the model, and can more effectively learn the motion intent.
In conclusion, the traditional trajectory prediction methods are usually simple. For complex and crowded environments, the generalization ability is usually poor. In addition, hand-designed features and rules limit their ability to learn unpredictable features in the real scenarios.
2.2. Trajectory Prediction Based on Deep Learning
In recent years, deep learning technology has developed rapidly. Compared with traditional trajectory prediction methods, the advantage of deep learning-based trajectory prediction methods is that they do not rely on artificial design features, and can learn complex and diverse social interactions through training. The mainstream deep learning trajectory prediction methods are divided into Recurrent Neural Networks (RNN)-based methods, Generative Adversarial Networks (GAN)-based methods and Graph Neural Networks (GNN)-based methods.
- (1)
- Trajectory prediction methods based on Recurrent Neural Network.
Introducing social functions to LSTM (Long Short-Term Memory), the Social LSTM [5] is proposed to treat the trajectory prediction problem as a sequence generation task. Based on the Social LSTM, a state refinement module [6] is proposed to adaptively refine the state of each traffic participant through a messaging framework. LSTM can also be improved with more LSTM models, to model the dependent information of participants, social rules, and scene environment [7].
Social Attention mechanism [14] can be used to describe the task of trajectory prediction; this model introduces social attention modeling of the influence of surrounding participants on the intention of target participants, overcoming the previous shortcomings of describing social interactions based on relative positions. Generating dense candidate targets based on probability [15] is an attention mechanism to select a trajectory. Zhao et al. [16] proposed a new multi-agent tensor fusion network with two parallel coded streams. Y-Net trajectory prediction network [17] used scene semantics and historical motion information to estimate the probability distribution and future position distribution of the final position. Using LSTM as social relation encoder, a Social Relation Attention-based Interaction aware LSTM (SRAI−LSTM) [22] utilizes social behavior to realize pedestrian trajectory prediction. This method continuously learns and updates the social relation feature from pedestrians’ relative positions. These methods reply on probabilities and attentions to generate the most possible trajectory.
As a popular structure for trajectory prediction, RNN-based methods have some problems. The training process is completed by minimizing the distance between the future trajectory and the groundtruth trajectory, so the model is biased towards predicting the average trajectory. However, the trajectory is multi-modal, so the prediction effect needs to be improved.
- (2)
- Trajectory prediction methods based on Generative Adversarial Network.
Generative Adversarial Network (GAN) is a common method to generate trajectories. The Social Gnerative Adversarial Network (Social GAN) [8] integrates LSTM and GAN to perform trajectory prediction. Based on Social GAN, physical attention and social attention can be used to consider physical and social interactions [9]. The graph-based generative adversarial network [10] can be used to better mimic the social interaction of moving targets through a graph attention mechanism. Amirian et al. [23] proposed the Info-GAN structure, which effectively solved the problem of pattern collapse and decline of GAN. Dendorfer et al. [24] proposed a multi-generator trajectory prediction model MG-GAN, which significantly reduces the number of samples outside the distribution. The spatio-temporal graph attention (GSTA) network [25] combines GAN and LSTM to design spatial attention structure and feature updating mechanisms in spatial domain, and temporal attention and feature selection modules in the temporal domain. Experimental results show that the GSTA improves the pedestrian trajectory prediction accuracy. Based on GAN, a mixed Conditional Auto Encoder Generative Adversarial Network (CAE-GAN) [26] model using the multi-loss function is proposed. The GAN in the CAE-GAN is used to extract features of the generated trajectories and generate trajectories that are close to the real trajectories.
The GAN-based trajectory prediction method solves the problem of predicting only one “average good” trajectory, and can generate a trajectory distribution with multiple modalities. However, models based on GAN networks also have some problems, such as unstable training and pattern collapse.
- (3)
- Trajectory prediction methods based on Graph Neural Network.
Graph Neural Network (GNN) is a common structure to perform trajectory prediction. Introducing a social spatio-temporal model to GNN can extract features by performing spatio-temporal convolution operations on the spatio-temporal graph [11]. Ivanovic et al. [12] proposed a multi-agent trajectory prediction framework Trajectron, which constructs participants into a dynamic temporal–spatial map to generate a multi-modal distribution of the future trajectories. The Trajectron model has been improved to the Trajectron++ version [13], which can generate dynamically feasible predictive trajectories for multiple traffic participants of different semantic types.
Constructing a graph to represent the interaction between adjacent participants can improve the performance [27]. The multi-scale hypergraph neural network GroupNet [28] can capture pairwise and grouped interactions, effectively modeling complex social impacts. Zhang et al. [29] combined Graph Attention Networks and convolutional gated recursive units to infer the future location of multiple traffic participants simultaneously. Mo et al. [30] proposed a heterogeneous edge-enhanced graph attention network to comprehensively simulate the interaction between participants. Based on Graph Convolutional Network and gated linear units, the STHGLU method [31] includes an adaptive model to understand the relationships between the participants, and includes a lightweight trajectory prediction model to trajectory prediction. In order to model the spatial and temporal relationship of multiple participants under uncertainties, the B-STAR model [32] combines spatio-temporal graph network and Bayesian in the transformer encoder and decoder architecture.
Compared with RNN- and GAN-based methods, the trajectory prediction method based on GNN can intuitively construct the topological relationship between participants, and the prediction performance is also improved. GNN has advantages with shallow networks; as the number of network layers deepens, the robustness of the network may decline.
Based on these analyses, though all these methods based on RNN, GAN and GNN can model trajectories, the attention mechanisms [14,15,16,17] are key to effectively model the social interaction of surrounding traffic participants in both time and spatial dimensions. Most these previous methods just use pooling methods to simulate the interaction process between participants and cannot fully capture the spatio-temporal dependence, and may accumulate errors with the increase in prediction time. To overcome these problems, we propose the Spatial–Temporal Interaction Attention-based Trajectory Prediction Network (STIA-TPNet), which effectively models the spatial–temporal interaction information with a temporal flow branch and a spatial flow branch.
3. Method
The Spatial–Temporal Interaction Attention-based Trajectory Prediction Network (STIA-TPNet) is proposed to effectively model the spatial–temporal interaction information. Based on trajectory feature extraction, the novel Spatial–Temporal Interaction Attention Module (STIA Module) is proposed to extract the interaction relationships between traffic participants, including temporal interaction attention, spatial interaction attention, and spatio-temporal attention fusion. The temporal interaction attention is a temporal attention mechanism used to capture the movement pattern of each participant in the scene. The spatial interaction attention is designed to abstract the participants in the scene into graph nodes, and abstract the social interaction between participants into graph edges. Coupling the temporal and spatial interaction attentions can adaptively model the temporal–spatial information and achieve accurate trajectory prediction. The details of the proposed methods are as follows.
3.1. Trajectory Prediction Definition
The trajectory prediction task is treated as a sequence prediction problem. Based on the historical trajectories of the moving targets, social interaction information and the surrounding environment are modeled to understand the movement intention of the target; and the future trajectories of all participants can be estimated. The definition is as follows.
There are N interaction traffic participants . Each participant corresponds to a semantic category ; means is a vehicle; means is a pedestrian or cyclist. The trajectory has a historical trajectory and a real future trajectory. The sequence of observation trajectories in the historical time step is , where represents the two-dimensional coordinates of the participant at time t. The purpose of this study is to generate a sequence of future predicted trajectory from the time : , where .
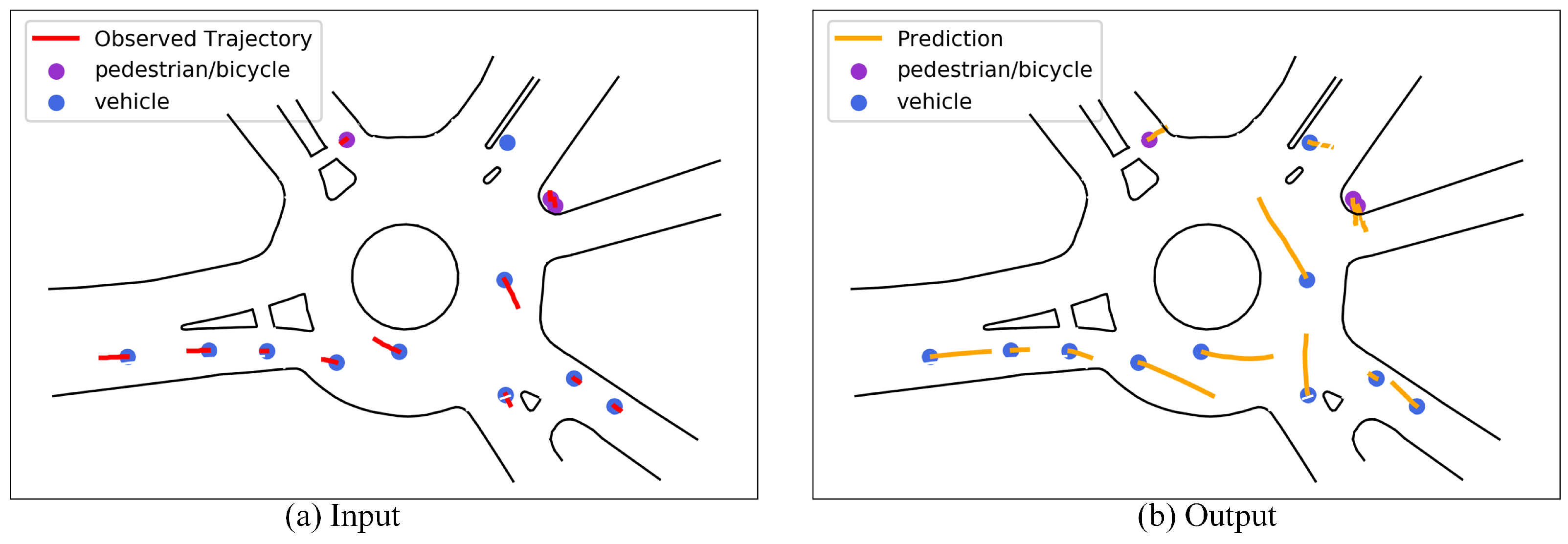
Figure 1 shows the input and output of the trajectory prediction task (the figure is taken from the traffic scenario named USA_Roundabout_FT in the INTERACTION dataset). Figure 1a is the observation trajectory of multiple participants in 1 s history. Figure 1b is the trajectory of several traffic participants in the next 3 s. Among them, the blue and purple dots represent the current location of the vehicle and pedestrian/cyclist, respectively; the solid red line represents the historical trajectory, and the solid orange line represents the predicted trajectory.
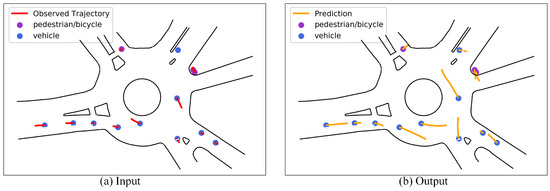
Figure 1.
Schematic diagram of the input and output of the trajectory prediction task.
3.2. Overall Network Framework
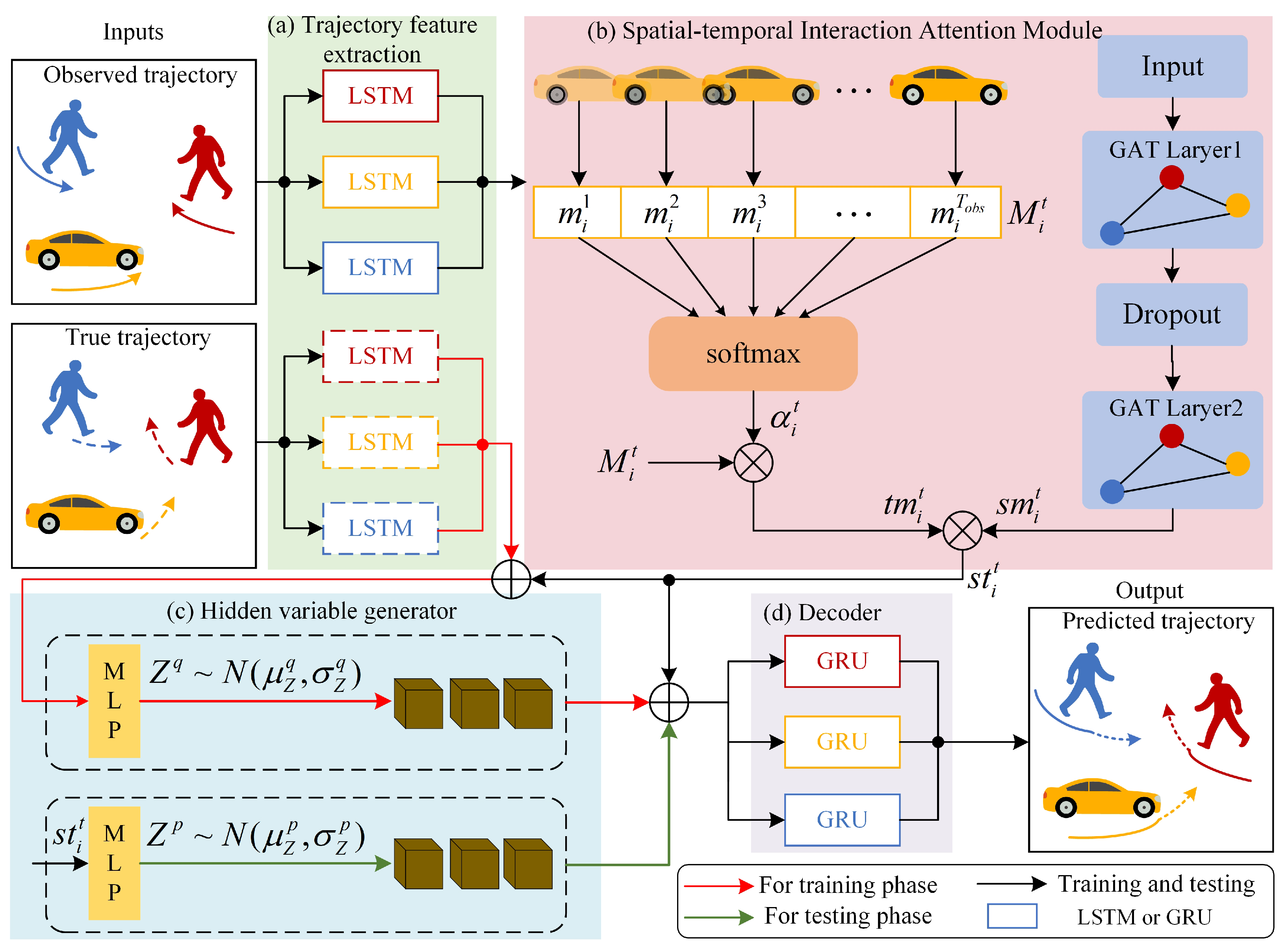
In real traffic scenarios, there are complex social interactions between pedestrians, vehicles, and other participants, which are difficult to model. We propose an STIA-TPNet to address this problem, which mainly consists of four parts shown in Figure 2.
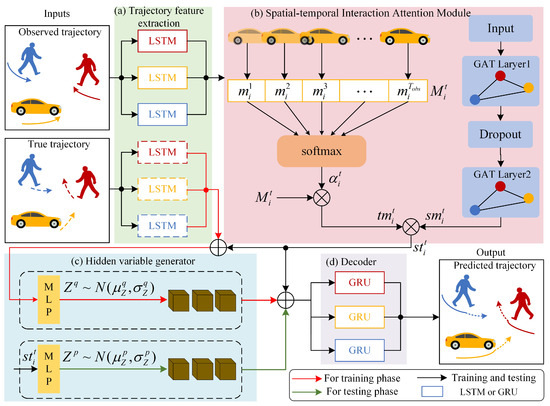
Figure 2.
Traffic participant trajectory prediction network based on spatial–temporal interaction attention.
Figure 2a is the trajectory feature extraction module, which encodes the historical trajectory and the real future trajectory, respectively, to capture the motion features. Figure 2b is the spatial–temporal interaction attention module, including two branches of temporal flow and space flow. Temporal interaction attention is used to capture the influence of historical trajectories at different moments on the motion of target participants, and spatial interaction attention is used to capture the social interaction of neighboring participants on the target. Fusing the two branches can obtain a spatial–temporal interaction attention representation. Figure 2c is the hidden variable generator, which uses conditional variational autoencoder sampling to obtain Gaussian hidden variables, which helps to generate multimodal trajectory prediction results. Figure 2d is the decoder, which is used to generate future trajectories.
3.3. Trajectory Feature Extraction
The trajectory feature extraction module takes the historical trajectory information of pedestrians, vehicles and other participants as input, and completes the extraction of key information by using embedding layers and LSTM networks.
Firstly, the coordinates of the ith traffic participant within the historical time step are embedded into a high-dimensional vector using the embedding layer ,
where, and represent the x and y coordinates of the traffic participant at time t; represents the embedding layer composed of linear layer and ReLU activation functions; and represents the weight matrix of the embedding layer.
Then, the embedded high-dimensional feature vector is used as the input of the LSTM network to capture the motion features of the traffic participant.
where, represents the hidden state vector of the LSTM network at time t, is the weight matrix of the LSTM network. To reduce complexity, these parameters are shared among all traffic participants in the scene.
The LSTM network is used to encode the real future trajectory sequence at the time steps to . The hidden state vector corresponding to the real future trajectory can be obtained.
where, represents the real future trajectory sequence, represents the real future trajectory feature vector of the traffic participant at time t, and represents the weight matrix of the LSTM network.
3.4. Spatial-Temporal Interaction Attention Module
The trajectory feature extraction module only extracts the independent motion features of each traffic participant in the scene, but cannot capture the interaction relationship between traffic participants. We propose the Spatial–Temporal Interaction Attention Module (STIA Module) to extract the interaction relationships between traffic participants, including temporal interaction attention, spatial interaction attention, and spatio-temporal attention fusion. Figure 3 shows the diagram of the STIA Module.
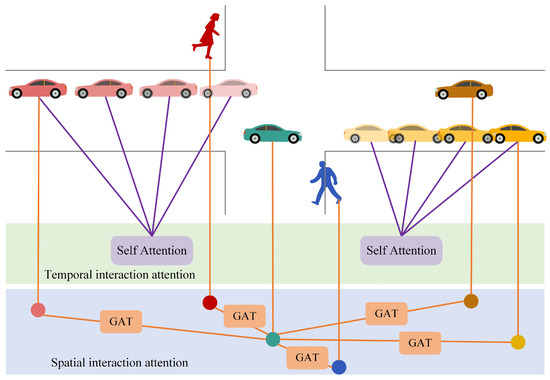
Figure 3.
Schematic diagram of spatial–temporal interaction attention module.
- (1)
- Temporal interaction attention
Pedestrians, vehicles and other traffic participants often have a fixed movement mode. Information for the previous time steps can help reason about the motion position of the next time step. Therefore, temporal context information is very important for trajectory prediction tasks, making the network pay different attentions to different parts of historical trajectories.
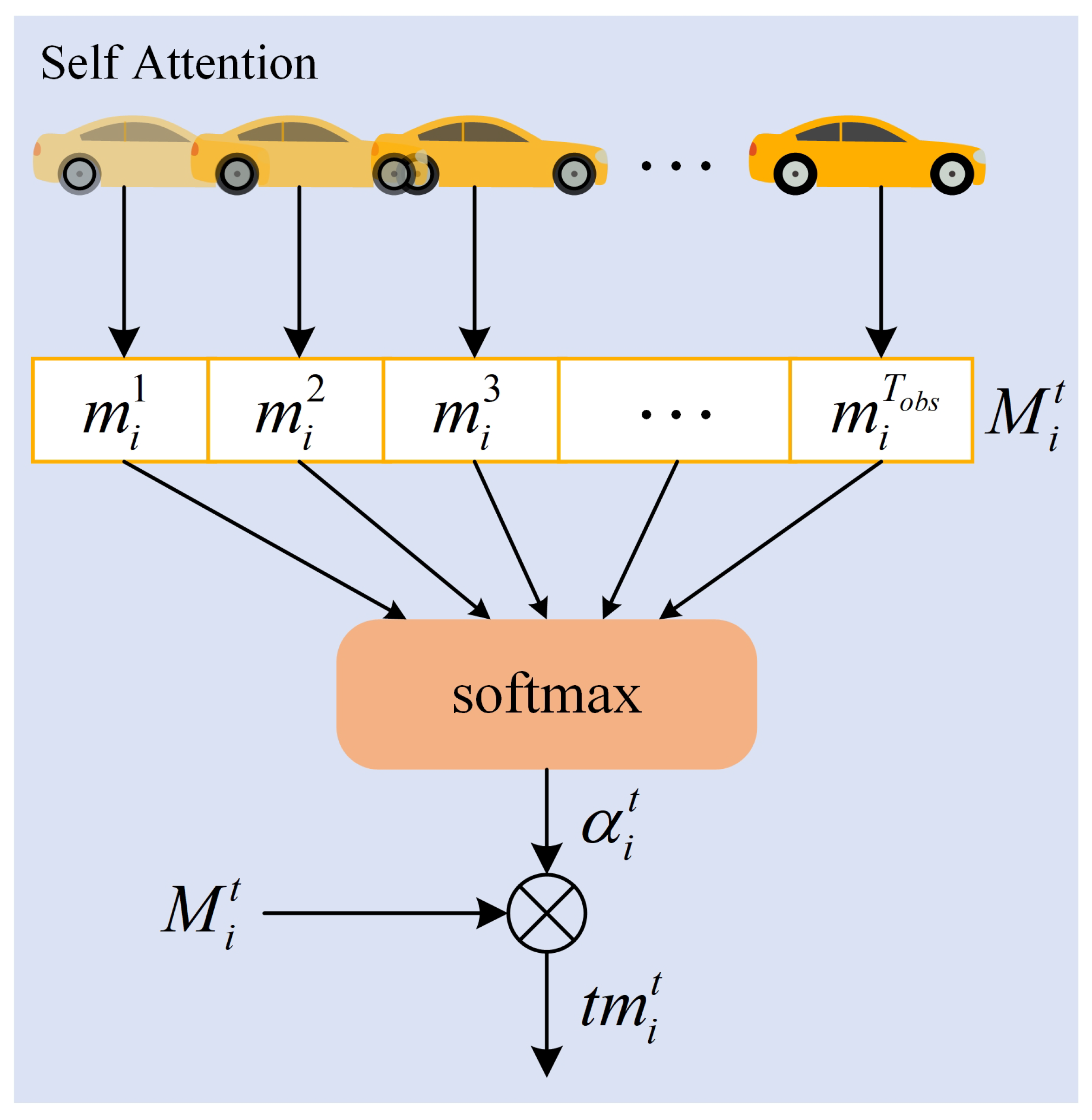
Temporal interaction attention is a temporal attention mechanism used to capture the movement pattern of each traffic participant in the scene; and by adaptive allocation of attention weights, it can learn the importance of historical trajectories at different moments to the future behaviors. This study uses the Self-Attention mechanism to model time dependence. Figure 4 shows the structure of temporal interaction attention.
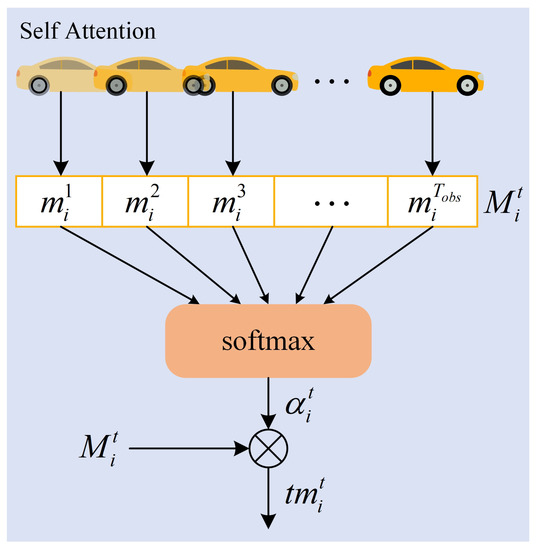
Figure 4.
Temporal interaction attention structure diagram.
The trajectory feature extraction module uses the LSTM network to encode the observation trajectory of each traffic participant at the historical time step . And the time context representation of the hidden state vector in the time step can be obtained.
where, is the output of Formula (2), which represents the hidden state vector of the ith traffic participant at time t, reflecting the historical trajectory characteristics of an traffic participant. is the historical time step, and d is the dimension of each hidden state. represents the time context vector.
Taking the temporal context vector as input and processing it by using the self-attention mechanism, the attention weight coefficient can be obtained, so as to adaptively learn important information from the time domain. By using the combination of Tanh and Softmax functions, the output value can be mapped to the normalized range of ,
where, represents a weight matrix with parameters shared by all traffic participants. represents the normalized exponential function, which ensures that the sum of all calculated weights is 1. represents the Tanh activation function. indicates the attention weight coefficient.
Finally, the attention weight coefficient and the time context vector are weighted summed, to obtain the vector representation of time attention,
where, represents the temporal attention vector.
- (2)
- Spatial interaction attention
In real traffic scenarios, vehicles and pedestrians interact with surrounding traffic participants. Therefore, effective modeling of the spatial interaction information of the target traffic participant and other participants is the key to predicting the future motion. Hence, we introduce a spatial interaction attention mechanism to capture spatial interaction information between all traffic participants at each time step.
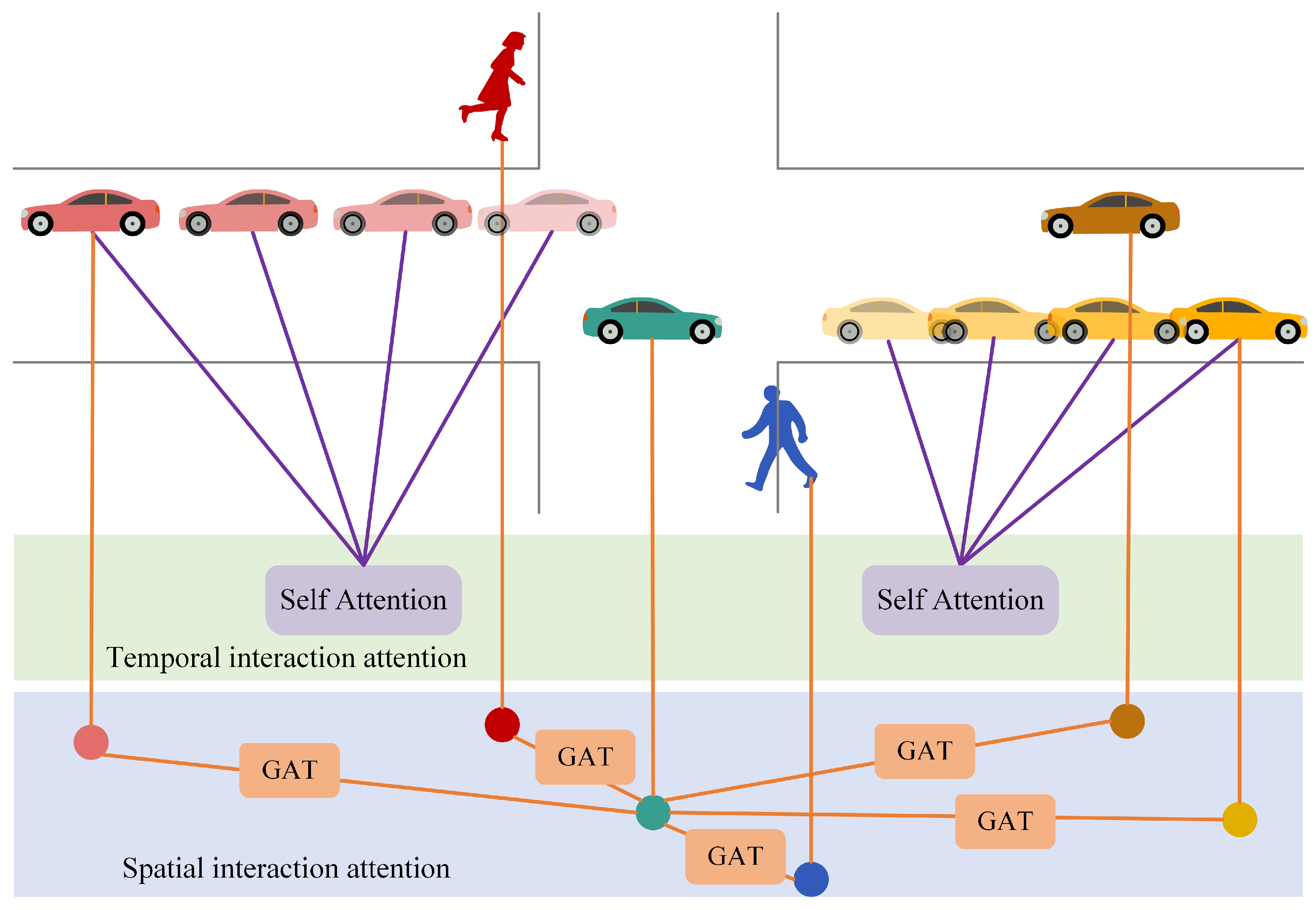
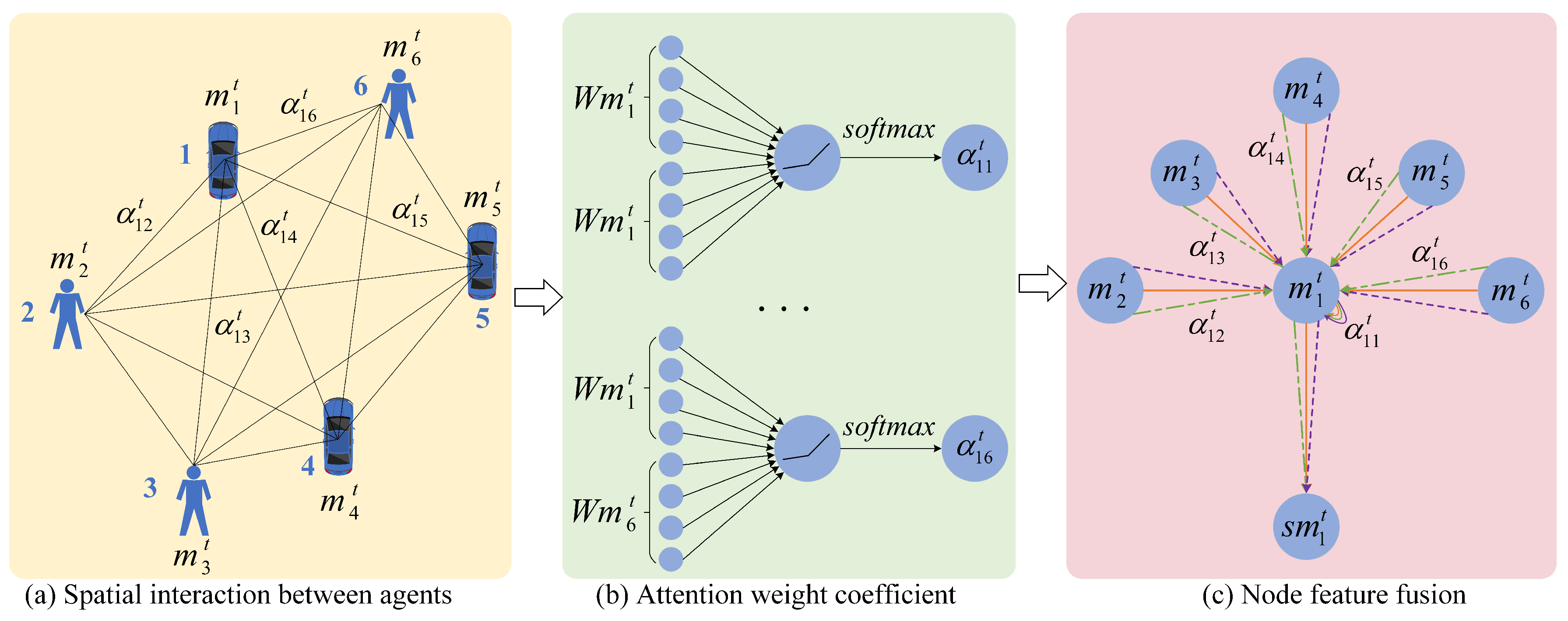
Since the participants number in recent traffic scene dynamically changes, the self-attention mechanism in the time domain cannot be used to obtain the weight information of the spatial domain. Inspired by the mechanism of the graph attention network GAT [33], we abstract the traffic participants in the scene into graph nodes, and abstract the social interaction between traffic participants into graph edges. Figure 5 shows the structure diagram of spatial interaction attention. (a) shows the spatial interaction between several traffic participants, and the value next to the solid black line indicates the weight of the edge; (b) shows the calculation process of the attention weight coefficient; (c) shows the process of node feature fusion. Though the target may be affected by other neighboring traffic participants, just a part neighboring traffic participants affect the movement of the target; the spatial interaction attention method is constructed to adaptively assign weights to traffic participants in the scene, which indicates the degree of influence on the target movement.
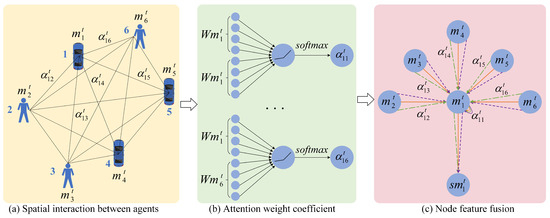
Figure 5.
Spatial interaction attention structure diagram.
In a graph with N nodes, the input to the graph attention layer is the initial feature of the node , where represents historical time and F represents the feature dimension of each node. After updating the node information, the output of the graph attention layer is , where represents the dimension of the output.
The motion state vector of the traffic participant in the historical observation time step is used as node information, and enter into the graph attention layer to obtain the interaction relationship between nodes. In order to learn the attention coefficient between node pairs , it is necessary to consider the influence of both nodes at the same time, and the calculation is
where, represents a single-layer feed-forward neural network, represents the weight vector of a single-layer feed-forward neural network, represents the concatenation operation, W represents the shared weight matrix between nodes, and represents the attention value between node i and node j.
The loss of node i information may result in the attention weight between not actually taking into account the information of node i. In order to avoid this problem, the LeakyReLU nonlinear activation function is used here. The attention coefficient obtained after the activation function operation is
where, represents the LeakyReLU activation function, and the LeakyReLU activation function is
After obtaining the attention coefficient between node i and its neighboring nodes, the Softmax activation function is used to regularize all attention coefficients. Figure 5b shows the process, and the calculation formula is
where, is the normalized exponential function, is an exponential function, represents the set of traffic participants adjacent to node i, and k represents the index of nodes in the set .
Finally, the normalized attention coefficient is weighted with the original motion state vector, to obtain the updated feature vector representation of node i, which is the output result of the attention layer of the single-layer graph
where, represents the Sigmoid nonlinear activation function, and represents the state vector that aggregates the trajectory features of neighboring traffic participants, reflecting the influence of the position of adjacent participants on the future motion of the target traffic participant.
In order to make the training learning process of attention more stable and prevent overfitting, the single-layer graph attention layer is expanded to multi-headed attention; and the transformation of Formula (11) is performed by introducing K independent attention mechanisms, and then the final spatial attention vector representation is obtained:
where, K is the number of heads, k represents the kth head, is the normalization coefficient calculated by the kth attention mechanism, and represents the corresponding weight matrix.
Figure 5c shows the node feature fusion process of multi-head attention when . Among them, the straight lines of different colors and line types are used to distinguish the independent attention calculation process of different heads; and it can be seen that the output result of spatial interaction attention can be obtained by connecting the features of each head on average.
- (3)
- Temporal and spatial attention fusion
Temporal interaction attention can explain the influence of historical trajectory on the future trajectory, but cannot well represent the spatial interaction between traffic participants. Spatial interaction attention acts on the spatial dimension and ranks neighboring participants according to their influence on the target traffic participant, which can effectively captures the spatial interaction information; yet, the motion of a single traffic participant cannot be well modeled, so coupling the temporal-spatial interaction information is very important to achieve accurate trajectory prediction.
In order to adaptively select more important information in both the spatial domain and the time domain, the vector obtained by temporal interaction attention is fused with the vector obtained by spatial interaction attention; and finally the temporal–spatial attention vector can reflect temporal–spatial interaction.
3.5. Hidden Variable Generator
The motion of traffic participants have multimodal features, and there are a lot of uncertainties in the predicted future trajectories. Most of the existing trajectory prediction methods use hidden variables to generate multimodal prediction results. The hidden variables often ignore information about social interactions, and have insufficient information about contextual relationship. In order to make the hidden variables reflect the influence of social interaction, the Conditional Variational AutoEncoder (CVAE) [34] is used in this model to learn the parameters of the sampling distribution from historical trajectories and spatio-temporal interaction information.
The conditional variational autoencoder consists of three parts: the priori network , the recognition network and the generation network ; and they are implemented through a fully connected layer.
In the training phase, the temporal–spatial attention vector and the real future trajectory vector of the traffic participant are connected in series and jointly input into the recognition network , to predict mean and covariance ,
where, represents the identification network implemented with MLP. In the testing phase, since the real future trajectory sequence is unknowable, only the spatio-temporal attention vector is used as the input of the priori network , obtaining the mean and the covariance .
where, represents a priori network implemented with MLP. Through the training and learning of the network, the KL divergence loss between and is continuously optimized, and finally the hidden variable Z is sampled.
3.6. Decoder
In order to enhance the anti-interference and noise reduction ability of the decoder, the spatio-temporal attention and the hidden variable Z concat together, and input into the GRU network [35].
where, represents the hidden state vector of the GRU network at time t, and represents the weight of the GRU network. The hidden state vector output by the GRU network is input into the linear layer, and the future motion position of each traffic participant can be obtained.
where, and represent the horizontal and ordinate coordinates of the future position predicted by the traffic participant at time t, and represents the linear layer, is the weight of the linear layer.
4. Experimental Results and Analysis
4.1. Dataset
(1) INTERACTION dataset. The INTERACTION dataset [18] was built by the MSC Lab at the University of California, Berkeley, which contains many internationalized, diverse, complex and critical driving scenarios and vehicle motions. The motion data were collected from different countries and continents. The dataset collects motion data from four different traffic scenarios, including traffic circles, unsignalized intersections, merging and lane changing, and signalized intersections, involving a total of eleven different collection shot locations. In the traffic circle scenario, 10,479 motion trajectories from five different locations were recorded, with a duration of about 365 min; in the unsignalized intersection scenarios with three different locations, 14,867 trajectories were collected over a period of about 433 min; in the merge and lane change scenario, the data were taken from two different locations, which contained a total of 10,933 trajectories, with a duration of approximately 133 min; in the signalized intersection scenario, only one location was selected and it provided 3775 trajectories over approximately 60 minutes.
(2) UTP-dataset. The UAV-captured Trajectory Prediction Dataset (UTP-dataset) is a captured dataset based on UAV aerial photography in real urban scenarios, with 97.34 min videos, 2512 pedestrians and 2778 vehicles. In order to detect moving intelligences in videos, pedestrians, cyclists, and vehicles are detected and localized, and the position and orientation of each traffic participant is estimated using oriented bounding boxes. Subsequently, the Kalman filter and the Hungarian algorithm are used to achieve multi-target tracking. In order to facilitate the use of data for the model, the UTP dataset was divided into training, validation, and testing sets in order of , , and .
4.2. Evaluation Criteria and Experimental Settings
The Average Displacement Error (ADE) and Final Displacement Error (FDE) are selected to evaluate the performance of the trajectory prediction performance; the smaller values of these two parameters means more accurate prediction performance of future trajectories.
(1) Average Displacement Error (ADE): ADE is used to calculate the average Euclidean distance between the real trajectory and the predicted trajectory in the predicted time step, reflecting the average prediction performance.
where, and represent the predicted trajectory and real future trajectory of the traffic participant at the time, N represents the number of traffic participants in the scene, and the and represent the observation time and prediction time, respectively.
(2) Final Displacement Error (FDE): FDE is used to calculate the average Euclidean distance between the real trajectory and the predicted trajectory at the final position, reflecting the final prediction accuracy of the model,
where, and , respectively, represent the predicted trajectory and real future trajectory of the traffic participant at the final moment of prediction , N represents the number of traffic participants in the scene, and and represent the observation time and prediction duration, respectively.
4.3. Experimental Settings
The proposed STIA-TPNet method is based on the Pytorch. The hardware platform is a server equipped with an Intel Core i9-9900X CPU and three NVIDIA TITAN XP graphics cards. The operating system is Ubuntu 16.04 LTS, and the graphics driver version is CUDA 9.0. The software development platform is Pycharm2022.
The UTP dataset and the INTERACTION dataset are divided into training sets, validation sets and test sets, according to the proportions of , and . For UTP datasets, we set parameters and ; and for INTERACTION datasets, we set parameters and .
For neural network structure and parameters, the input dimension of Equation (1) is 2, the output dimension is 32. The dimension of the LSTM encoder in Equation (2) is 128. The bidirectional LSTM encoder with dimension 32 is used in Equation (3). The dimension of the GRU decoder is 256. Spatial interaction attention contains two graph attention layers; for the first layer, the input dimension of the first layer is 128, the output dimension is 64, and the number of attention heads ; for the second layer, the input dimension is 256, the output dimension is 128, and the number of attention heads . In the hyperparameter settings, the size of batch size is set to 256, which is a large setting according to the GPU memory; the size of the number of iterations is set to 150, and the learning rate is 0.001. With these settings, the loss value decreases fast and stable.
4.4. Trajectory Prediction Results on the UTP Dataset
In order to verify the effectiveness of the proposed method, some trajectory prediction methods are used for comparison, including Vanilla LSTM [36], Social LSTM [5], Social GAT [8], STGAT [37], Social STGCNN [11], DisDis [38], GSTA [25], Cae-gan [26], Social Implicit [39] and Trajectron++ [13].
Vanilla LSTM [36]: The basic LSTM encoder–decoder model that uses an LSTM network to encode the motion of a single target, and uses the LSTM decoder to obtain the predicted future trajectory of the participant in the decoding stage, without considering the social interaction between traffic participants.
Social LSTM [5]: The trajectory prediction model based on social LSTM uses the social interaction pooling layer to combine and share the state information of adjacent sequences, and effectively models the interaction effect between participants.
Social GAN [8]: The generative adversarial model that combines LSTM and GAN, and introduces distance-based pooling modules to obtain participant interaction representations. Among them, the generator generates multiple prediction trajectories, and the discriminator distinguishes the true and false trajectories.
STGAT [37]: The LSTM encoder–decoder model based on graph attention mechanism uses graph attention network to assign different weights to participants, and effectively models the local interaction and global interaction between participants.
Social STGCNN [11]: The trajectory prediction model based on a social spatio-temporal graph convolutional neural network firstly extract features through spatio-temporal convolution operations and then decodes the spatio-temporal features to obtain the prediction trajectory.
DisDis [38]: The trajectory prediction model based on the distribution discrimination method can predict the potential distribution and motion patterns of traffic participant personalization, through self-supervised contrast learning and discrete optimization of consistency constraints.
Social Implicit [39]: The socially implicit model includes social regions, social units, and social loss, and introduces implicit maximum likelihood estimation for training the model, which can generate trajectory prediction results close to the real trajectory.
Trajectron++ [13]: The trajectory prediction model based on graph structure and LSTM network uses LSTM encoding and extracting spatio-temporal information, and then uses a conditional variational autoencoder to generate multiple reasonable and feasible future trajectories.
GSTA [25]: The spatio-temporal graph attention (GSTA) network combines GAN and LSTM to design the spatial attention structure and feature an updating mechanism in the spatial domain, and temporal attention and feature selection module in the temporal domain. Experimental results show the GSTA improved the pedestrian trajectory prediction accuracy.
Cae-gan [26]: The mixed Conditional Auto Encoder Generative Adversarial Network (CAE-GAN) model based on the multi-loss function is proposed. The GAN in the CAE-GAN is used to extract features of the generated trajectories and generate trajectories that are close to the real trajectories.
The proposed STIA-TPNet model is compared with these methods on the UTP dataset, as shown in Table 1, where the best results are highlighted in bold. The proposed trajectory prediction method obtains an ADE distance of 5.56 pixels and an FDE distance of 10.21 pixels. Compared with other methods, our method reduces the average displacement error by and the final displacement error by . There are several reasons that contribute to this achievement. The temporal interaction attention can learn the importance of historical trajectories at different moments to the future behaviors. The spatial interaction attention can abstract the traffic participants and social interaction into graph nodes and edges. Coupling the temporal and spatial interaction attentions can adaptively model the temporal–spatial information and achieve accurate trajectory prediction.

Table 1.
Comparison of ADE and FDE results of different methods on UTP dataset.
In order to evaluate the influence of the spatio-temporal interaction attention module (STIA Module), ablation experiments are performed, as shown in Table 2. Baseline is a model without adding a temporal–spatial interaction attention module; STIA-TPNet is a model that introduces the temporal–spatial interaction attention module on the basis of the baseline.
Table 2.
Ablation experiment of STIA-TPNet on UTP dataset.
By analyzing the results of Table 2, it can be seen that the spatio-temporal interaction attention module has better ADE and better FDE. This result means that the STIA-TPNet can effectively capture the interaction between time domain and space domain. Therefore, the STIA-TPNet method achieves the optimal prediction error and can generate multiple prediction trajectories that conform to physical and social constraints.
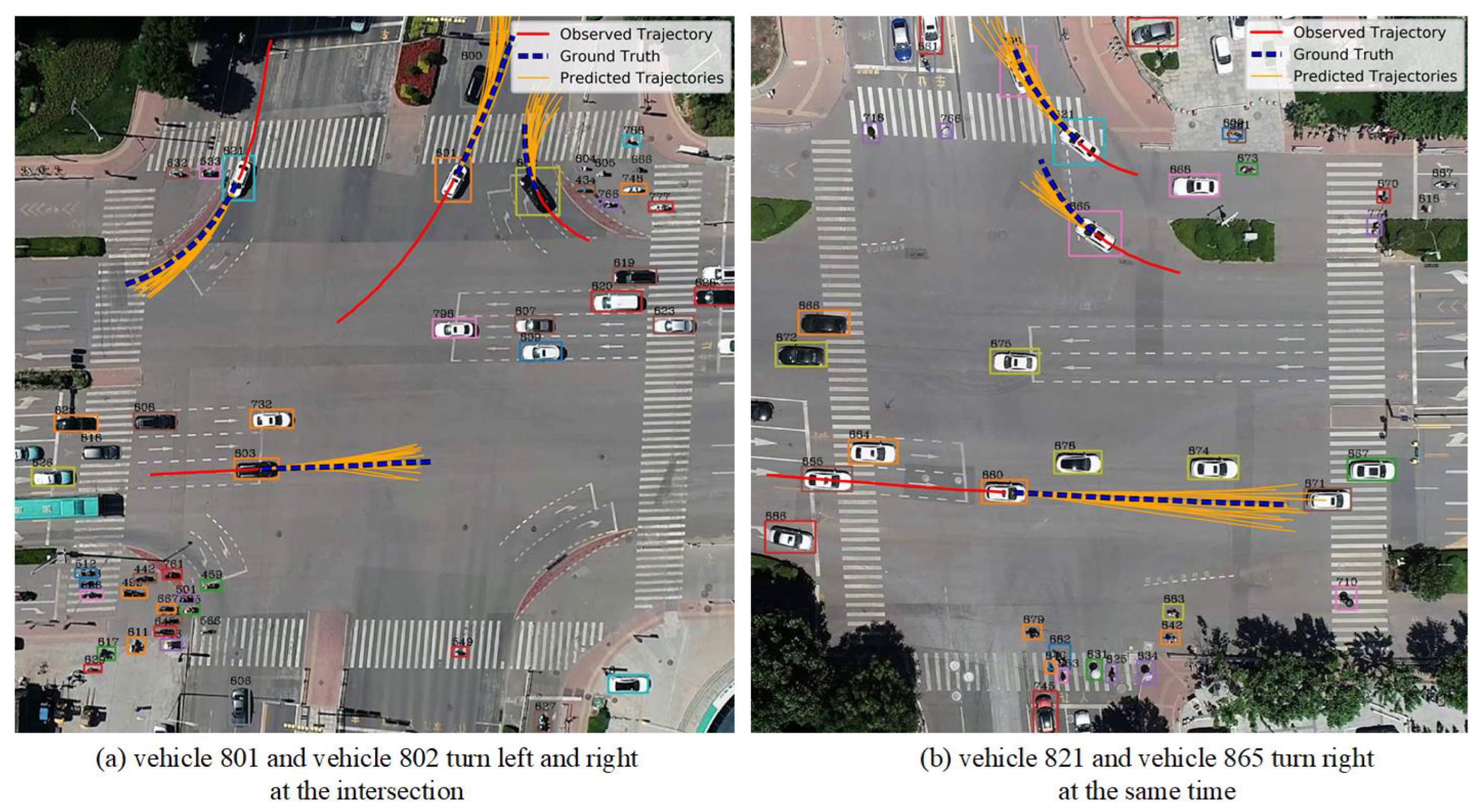
In order to better analyze the effect of our method, we visualize some scenarios in the UTP dataset, such as Figure 6. As shown, the solid red line in the figure represents the observed 3 s historical trajectory, the blue-dashed line represents the real future 3 s trajectory, and the solid orange line represents the predicted 20 future trajectories. In Figure 6a, vehicle 801 and vehicle 802 turn left and right at the intersection, respectively, in order to avoid interfering with the movement of the other party; vehicle 801 turns slightly along the left side of the road, and vehicle 802 turns along the right side of the road. In Figure 6b, vehicle 821 and vehicle 865 turn right at the same time, and the predicted trajectory can effectively avoid collisions. Therefore, the proposed STIA-TPNet trajectory prediction network can generate reasonable future trajectories in these complex traffic scenarios. The main reason is that our method can effectively capture the complex interaction information between traffic participants.
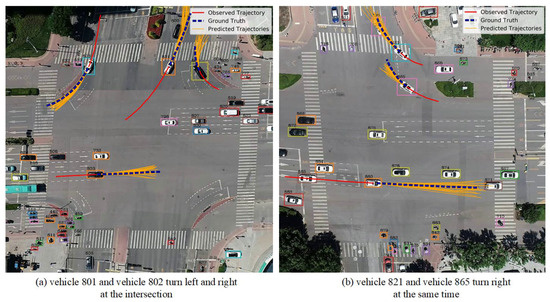
Figure 6.
Visualization results of trajectory prediction on UTP dataset.
4.5. Trajectory Prediction Results on the Interaction Dataset
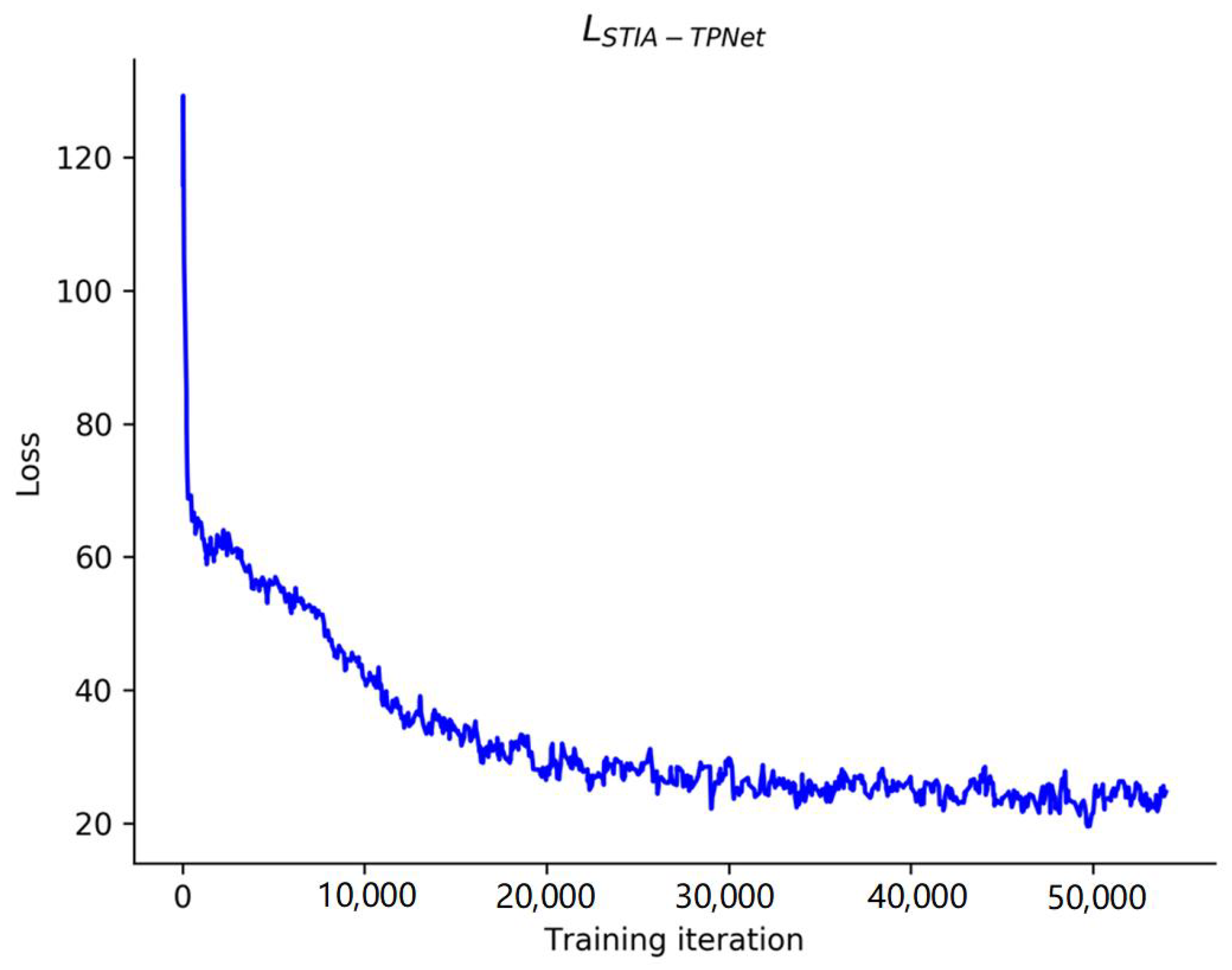
STIA-TPNet trains the resulting loss function curve on the INTERACTION dataset, shown in Figure 7. As the number of iterations gradually increases, the curve shows a tendency to decline and converge. This curve shows that our method can converge steadily with more than 50,000 training iterations.
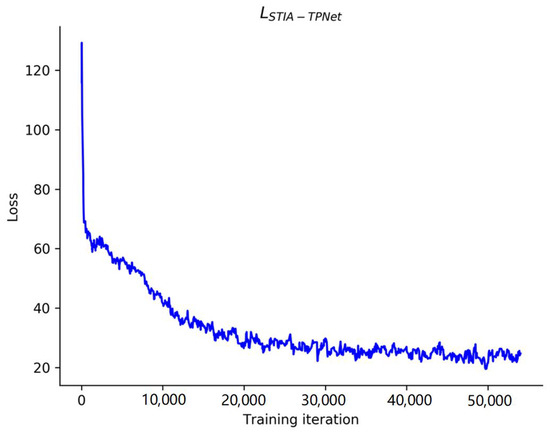
Figure 7.
Loss function curve of the STIA-TPNet model on the INTERACTION dataset.
Table 3 is the comparison results of trajectory predictions on the INTERACTION dataset. Smaller values indicate higher accuracy of trajectory prediction, and the optimal method is indicated in bold. It can be seen that the average displacement error and final displacement error calculated by the proposed algorithm are 0.45 m and 0.99 m, respectively. The spatio-temporal interaction attention module is used to effectively extract the interaction information between traffic participants, which improves the prediction accuracy of the model. Compared to other methods, the STIA-TPNet method reduces ADE by and FDE by . Based on trajectory feature extraction, the STIA Module can extract the interaction relationships between traffic participants. The main reason is that coupling the temporal and spatial interaction attentions can adaptively model the temporal–spatial information and achieve accurate trajectory prediction. Hence, our method can achieve the state-of-the-art results on both the UTP dataset and the INTERACTION dataset.
Table 3.
Comparison of ADE and FDE results of different methods on INTERACTION dataset.
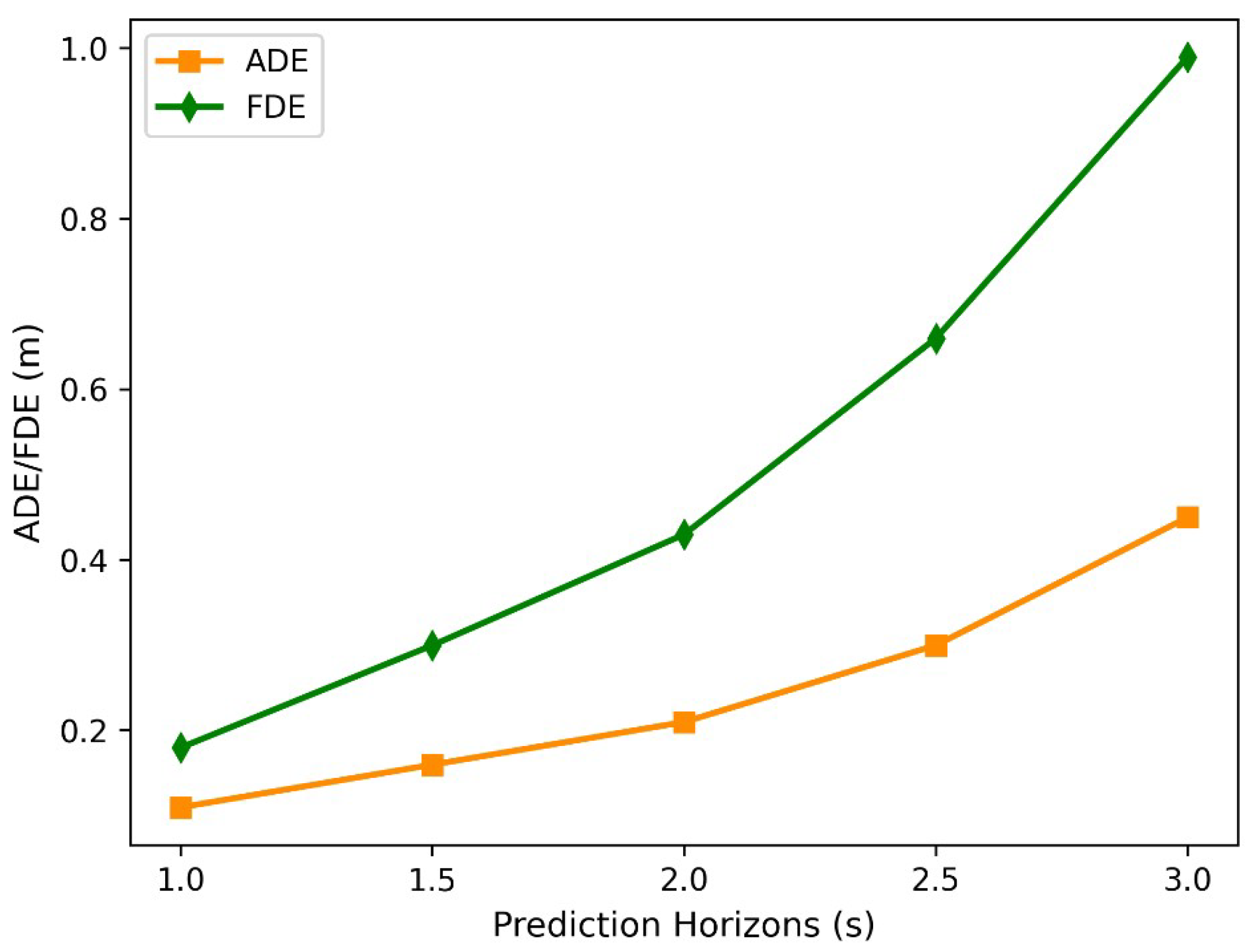
The interval of 1 s to 3 s in the prediction time domain is divided at 0.5 s intervals, and the STIA-TPNet algorithm is experimented on the INTERACTION dataset. Figure 8 shows the variation curves of the average displacement error (ADE) and final displacement error (FDE) of the STIA-TPNet method with the predicted time domain; the solid orange and green lines correspond to ADE and FDE, respectively. The prediction process is often under complex and changeable traffic scenarios. The trajectory prediction is sensitive to prediction time, and a longer prediction time often means a larger prediction error. As the prediction time increases, the average displacement error and the final displacement error gradually increase. Hence, in the trajectory prediction task, the prediction time needs to be considered according to different applications.
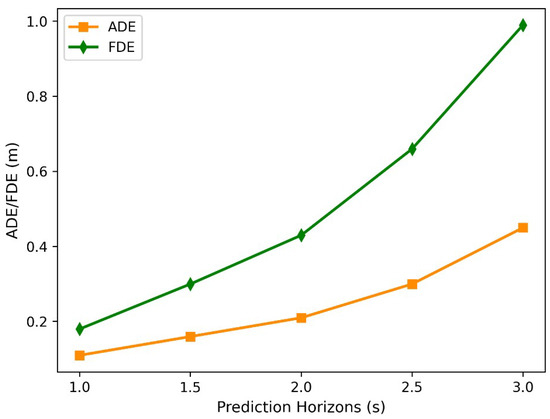
Figure 8.
ADE and FDE of different prediction horizons on the INTERACTION dataset.
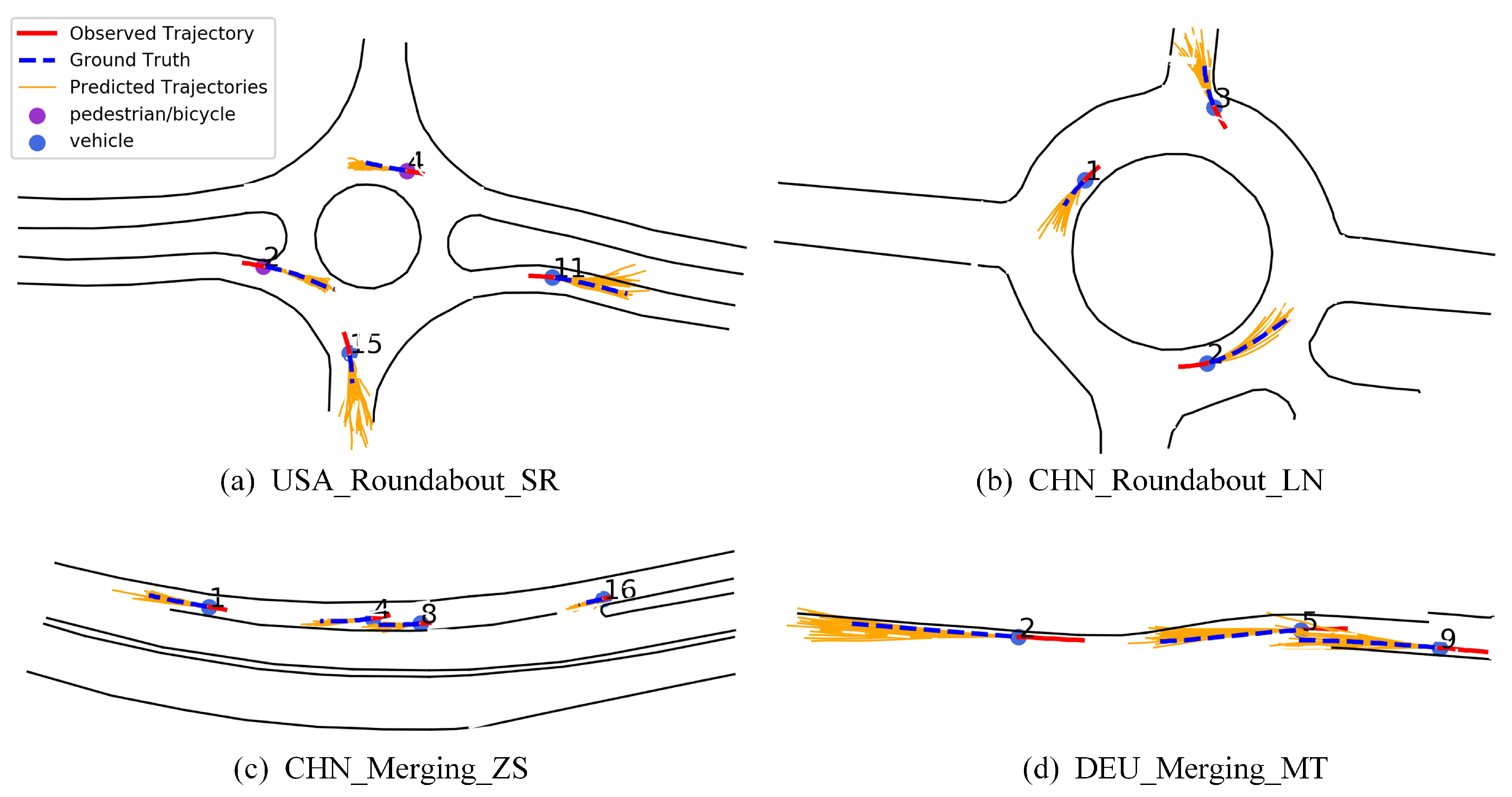
Figure 9 shows the trajectory prediction results of some traffic scenarios in the INTERACTION dataset; the solid red line is the observation trajectory; the blue dashed line is the real future trajectory; the solid orange line is the predicted multiple future trajectories; the blue dot represents the vehicle; and the purple dot represents the pedestrian or cyclist. Figure 9a corresponds to the scene USA_Roundabout_SR, where pedestrians 2 and 4 are about to enter and leave the roundabout, so the predicted trajectory travels along the inside of the roundabout. Figure 9b is the scenario CHN_Roundabout_LN, where vehicle 3 exits the roundabout from the intersection, and the prediction results are in line with the movement trend. Figure 9c corresponds to the scene CHN_Merging_ZS, where vehicles 1, 4, 8, and 16 drive normally along the lane lines. Figure 9d is the scenario DEU_Merging_MT, where the road changes from a two-lane to a single lane, so vehicles 2 and 5 drive on the right side of the single lane. The proposed method can predict trajectories measured by time. Considering vehicle speed, faster vehicles have longer predicted trajectories. Although there is a certain deviation between the predicted trajectory and the actual trajectory, the overall trend of the predicted trajectory is close to the real situation; these prove the effectiveness of our trajectory prediction network based on spatio-temporal interaction attention, which can generate accurate and reliable predicted trajectories. The main reason is that the spatio-temporal interaction attention can generate the most possible trajectory from a batch of trajectories.
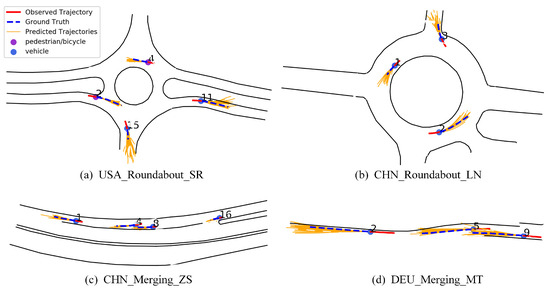
Figure 9.
Visualization results of trajectory prediction on INTERACTION dataset.
5. Discussion
The proposed method can generate accurate and reliable predicted trajectories. Some reasons may result in failures, including traffic light change, breaking traffic regulations, environmental constraint change. These reasons can not reflect on history trajectories, and may result in wrong predictions.
The proposed trajectory prediction can be applied in drone-based applications for intelligent driving, traffic optimization, intelligent monitoring, etc. In this study, all calculation is processed with our GPU server and the calculation time is 5.6 fps. Though the consuming time problem is not mainly considered in this study, we argue that cloud and edge calculation can also be used to promote the calculation ability in real applications. For example, the capture videos can be preprocessed on the drone and then sent to the server or cloud for further calculation.
6. Conclusions and Future Work
For traffic scenarios, pedestrians, vehicles and other traffic participants have social interactions of surrounding traffic participants in both time and spatial dimensions. In order to simulate the spatial–temporal interactions and capture the spatio-temporal dependence, we propose the Spatial–Temporal Interaction Attention-based Trajectory Prediction Network (STIA-TPNet).
The STIA-TPNet includes a temporal flow and a spatial flow. In the temporal flow, temporal interaction attention is used to analyze the importance of the historical trajectories to the future movement of the target participant; spatial interaction attention is to capture the interaction effect of neighboring traffic participants. Fusing the spatial–temporal interaction information can adaptively select the important information in the both time and spatial domains. Experiments on the two datasets show that the proposed method significantly improves the accuracy of trajectory prediction. In this study, the dataset size are still limited and the calculation ability in real applications is not fully considered. In the future, we aim to further improve the generalization ability with more training samples from different scenarios, and further re-implement our method in real applications.
Author Contributions
Data curation, S.L. and C.L.; investigation, S.L.; methodology, S.L. and J.X.; writing—original draft, S.L. and J.X.; writing—review and editing, C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by National Natural Science Foundation of China (62203242, 62176138, 62176136, U22A2058).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The founding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- Helbing, D.; Molnar, P. Social force model for pedestrian dynamics. Phys. Rev. E 1995, 51, 4282. [Google Scholar] [CrossRef] [PubMed]
- Yamaguchi, K.; Berg, A.C.; Ortiz, L.E.; Berg, T.L. Who are you with and where are you going? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1345–1352. [Google Scholar]
- Trautman, P.; Krause, A. Unfreezing the robot: Navigation in dense, interacting crowds. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 797–803. [Google Scholar]
- Morris, B.T.; Trivedi, M.M. Trajectory learning for activity understanding: Unsupervised, multilevel, and long-term adaptive approach. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2287–2301. [Google Scholar] [CrossRef] [PubMed]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Savarese, S. Social LSTM: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Zhang, P.; Ouyang, W.; Zhang, P.; Xue, J.; Zheng, N. SR-LSTM: State refinement for lstm towards pedestrian trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12085–12094. [Google Scholar]
- Xue, H.; Huynh, Q.D.; Reynolds, M. SS-LSTM: A hierarchical LSTM model for pedestrian trajectory prediction. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1186–1194. [Google Scholar]
- Gupta, A.; Johnson, J.; Li, F.F.; Silvio, A.; Alexandre, A. Social GAN: Socially acceptable trajectories with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2255–2264. [Google Scholar]
- Sadeghian, A.; Kosaraju, V.; Sadeghian, A.; Hirose, N.; Rezatofighi, S.H.; Savarese, S. Sophie: An attentive gan for predicting paths compliant to social and physical constraints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1349–1358. [Google Scholar]
- Kosaraju, V.; Sadeghian, A.; Martin-Martin, R.; Reid, I.; Savarese, S. Social-BiGAT: Multimodal trajectory forecasting using bicycle-gan and graph attention networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-STGCNN: A social spatio-temporal graph convolutional neural network for human trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14424–14432. [Google Scholar]
- Ivanovic, B.; Pavone, M. The trajectron: Probabilistic multi-agent trajectory modeling with dynamic spatiotemporal graphs. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2375–2384. [Google Scholar]
- Tim, S.; Boris, I.; Punarjay, C.; Marco, P. Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 683–700. [Google Scholar]
- Vemula, A.; Muelling, K.; Oh, J. Social Attention: Modeling attention in human crowds. In Proceedings of the IEEE international Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 4601–4607. [Google Scholar]
- Gu, J.; Sun, C.; Zhao, H. DenseTNT: End-to-end trajectory prediction from dense goal sets. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 15303–15312. [Google Scholar]
- Zhao, T.; Xu, Y.; Monfort, M.; Choi, W.; Baker, C.; Zhao, Y.; Wang, Y.; Wu, Y. Multi-agent tensor fusion for contextual trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12126–12134. [Google Scholar]
- Mangalam, K.; An, Y.; Girase, H.; Malik, J. From goals, waypoints & paths to long term human trajectory forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 15233–15242. [Google Scholar]
- Zhan, W.; Sun, L.; Wang, D. Interaction dataset: An international, adversarial and cooperative motion dataset in interactive driving scenarios with semantic maps. arXiv 2019, arXiv:1910.03088. [Google Scholar]
- Yu, B.; Zhu, K.; Wu, K.; Zhang, M. Improved OpenCL-based implementation of social field pedestrian model. IEEE Trans. Intell. Transp. Syst. 2019, 21, 2828–2839. [Google Scholar] [CrossRef]
- Figueiredo, F.; Ribeiro, B.; Almeida, J.; Faloutsos, C. Tribeflow: Mining & predicting user trajectories. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 695–706. [Google Scholar]
- Kitani, K.M.; Huang, D.A.; Ma, W.C. Activity forecasting. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 201–214. [Google Scholar]
- Peng, Y.; Zhang, G.; Shi, J.; Xu, B.; Zheng, L. SRAI-LSTM: A Social Relation Attention-based Interaction-aware LSTM for human trajectory prediction. Neurocomputing 2022, 490, 258–268. [Google Scholar] [CrossRef]
- Amirian, J.; Hayet, J.B.; Pettre, J. Social ways: Learning multi-modal distributions of pedestrian trajectories with gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 2964–2972. [Google Scholar]
- Dendorfer, P.; Elflein, S.; Leal-Taixe, L. MG-GAN: A multi-generator model preventing out-of-distribution samples in pedestrian trajectory prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13158–13167. [Google Scholar]
- Kong, W.; Liu, Y.; Li, H.; Wang, C.; Tao, Y.; Kong, X. GSTA: Pedestrian trajectory prediction based on global spatio-temporal association of graph attention network. Pattern Recognit. Lett. 2022, 160, 90–97. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, Q.; Cai, Y.; Wang, H.; Li, Y. CAE-GAN: A hybrid model for vehicle trajectory prediction. IET Intell. Transp. Syst. 2022, 16, 1682–1696. [Google Scholar] [CrossRef]
- Li, X.; Ying, X.; Chuah, C. GRIP: Graph-based interaction-aware trajectory prediction. In Proceedings of the IEEE Intelligent Transportation Systems Conference, Auckland, New Zealand, 27–30 October 2019; pp. 3960–3966. [Google Scholar]
- Xu, C.; Li, M.; Ni, Z.; Zhang, Y.; Chen, S. GroupNet: Multiscale hypergraph neural networks for trajectory prediction with relational reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6498–6507. [Google Scholar]
- Zhang, K.; Zhao, L.; Xiang, D.; Wu, L. AI-TP: Attention-based interaction-aware trajectory prediction for autonomous driving. IEEE Trans. Intell. Veh. 2023, 8, 73–83. [Google Scholar] [CrossRef]
- Mo, X.; Huang, Z.; Xing, Y.; Lv, C. Multi-agent trajectory prediction with heterogeneous edge-enhanced graph attention network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 9554–9567. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Y.; Sun, J.; Mao, T. An efficient Spatial-Temporal model based on gated linear units for trajectory prediction. Neurocomputing 2022, 492, 592–600. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Hu, J.; Yan, H.; Liu, Y. Bayesian Spatio-Temporal grAph tRansformer network (B-STAR) for multi-aircraft trajectory prediction. Knowl.-Based Syst. 2022, 249, 108998. [Google Scholar] [CrossRef]
- Velickovic, P.; Cucurull, G.; Casanova, A. Graph attention networks. arXiv 2019, arXiv:1910.03088. [Google Scholar]
- Sohn, K.; Yan, X.; Lee, H. Learning Structured Output Representation using Deep Conditional Generative Models. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.H. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Seong Hyeon, P.; ByeongDo, K.; Chang Mook, K.; Chung Choo, C.; Jun Won, C. Sequence-to-Sequence Prediction of Vehicle Trajectory via LSTM Encoder-Decoder Architecture. In Proceedings of the IEEE Intelligent Vehicles Symposium, Changshu, China, 26–30 June 2018; pp. 1672–1678. [Google Scholar]
- Huang, Y.; Bi, H.; Li, Z.; Tianlu, M.; Wang, Z. STGAT: Modeling spatial-temporal interactions for human trajectory prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6272–6281. [Google Scholar]
- Chen, G.; Li, J.; Zhou, N.; Ren, L.; Lu, J. Personalized trajectory prediction via distribution discrimination. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15580–15589. [Google Scholar]
- Mohamed, A.; Zhu, D.; Vu, W.; Elhoseiny, M.; Claudel, C. Social-Implicit: Rethinking Trajectory Prediction Evaluation and The Effectiveness of Implicit Maximum Likelihood Estimation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2022; pp. 463–479. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).