
A Hardware-Friendly High-Precision CNN Pruning Method and Its FPGA Implementation


 ,
,
Abstract
:1. Introduction
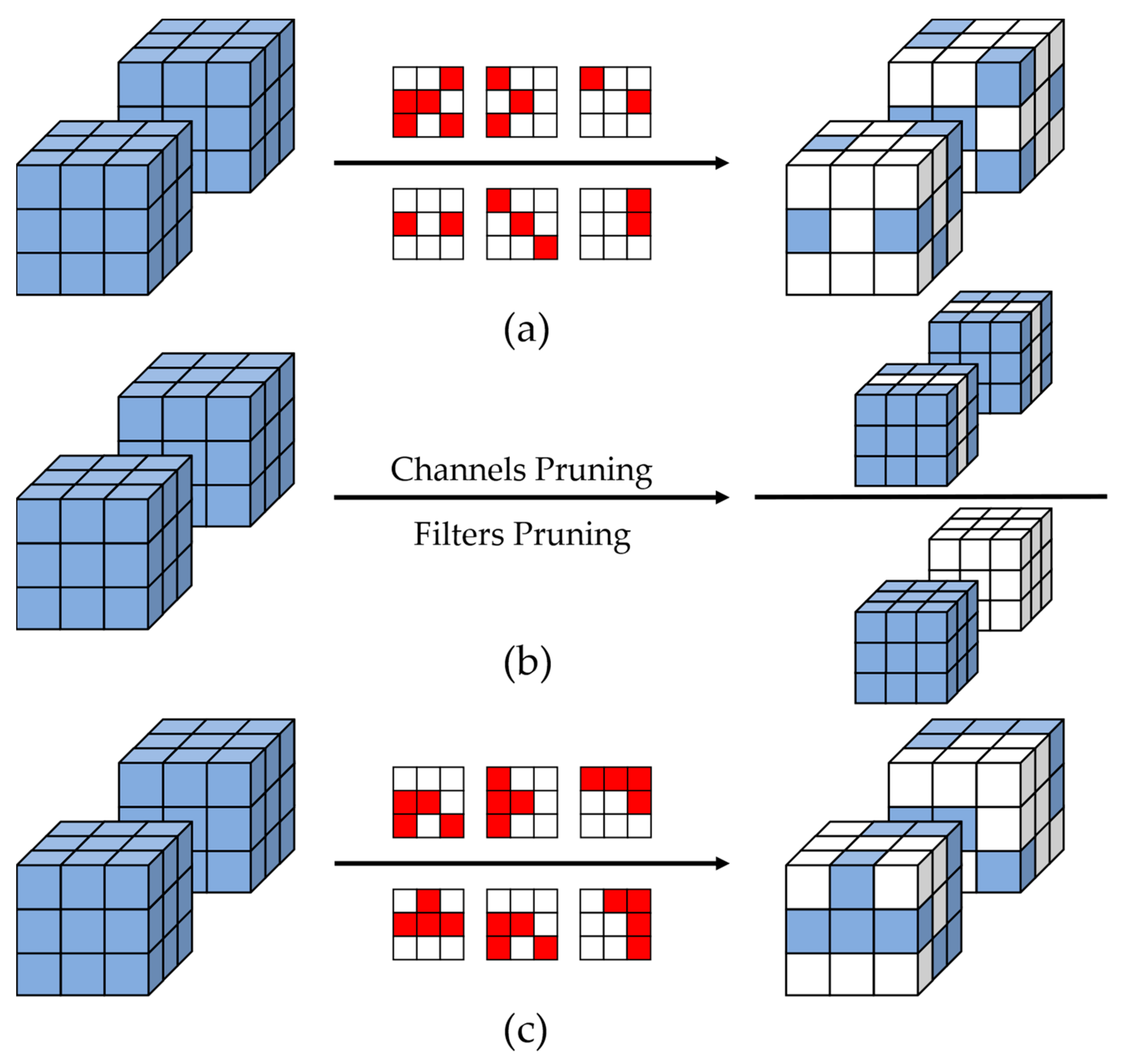
- In this study, we designed a CNN pruning method based on convolutional kernel row-scale pruning. It is highly practical by combining the high pruning rate and high accuracy features of non-structured pruning, high regularity and hardware- friendly features of structured pruning, and same number of remaining weights in each convolutional kernel of pattern pruning.
- In this study, we developed a retraining method based on LR tracking, which sets the retraining learning rate according to the variation in the original training learning rate, which can more quickly achieve higher training accuracy than conventional retraining methods.
- In this study, we performed pruning experiments on the CIFAR10 classification dataset [38] on four CNN models dedicated to CIFAR10, AlexNet [39], VGG-16 [1], ResNet-56, and ResNet-110 [40], and compared the results with those of state-of-the-art methods. We conducted comparison experiments on two commonly used training learning rate variations [1,40,41] to verify the effectiveness and generality of the proposed LR tracking retraining method.
- In this study, we combined the KRP pruning method with our previously developed GSNQ quantization algorithm to propose a hardware-friendly high-precision CNN compression framework, which can match the original network performance while compressing the network by 27×. We designed a highly pipelined convolutional computation module on an FPGA platform based on this compression framework, which can skip all the zero calculations without excessive indexing and significantly reduce hardware resource consumption.
2. Proposed Method
2.1. Convolutional Kernel Row-Scale Regular Pruning (KRP)
2.2. LR Tracking Retraining
| Algorithm 1 One-time KRP pruning process. |
| Input 1: The pre-trained CNN model: |
| Input 2: Learning rate schedule of the original CNN training process: |
| 1: for do |
| 2: Determine the L1 norm of all rows by Equation (1) |
| 3: Keep the row with the largest L1 norm, prune the other weights, and update |
| 4: end for |
| 5: if there are FC layers |
| 6: Set the pruning rate of FC layers for unstructured pruning and update |
| 7: Set the LR tracking retraining epoch and retraining learning rate to correspond to |
| 8: Update the weights with Equation (3) |
| Output: Row-scale regular pruning CNN model |
2.3. Hardware-Friendly CNN Compression Framework Based on Pruning and Quantization
2.4. FPGA Design
3. Experiments
3.1. KRP Pruning Comparative Experiments
3.1.1. Implementation Details
3.1.2. Comparative Experiments of LR Tracking Retraining Method
3.1.3. Comparison with State-of-the-Art Pruning Methods
3.1.4. Experiments on CNN Compression Framework Based on KRP and GSNQ
3.2. FPGA Design Experiments
3.2.1. Implementation Details
3.2.2. Results Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Lane, N.D.; Bhattacharya, S.; Georgiev, P.; Forlivesi, C.; Kawsar, F. An Early Resource Characterization of Deep Learning on Wearables, Smartphones and Internet-of-Things Devices. In Proceedings of the 2015 International Workshop on Internet of Things towards Applications, Seoul, Republic of Korea, 1 November 2015. [Google Scholar]
- Bhattacharya, S.; Lane, N.D. From smart to deep: Robust activity recognition on smartwatches using deep learning. In Proceedings of the IEEE International Conference on Pervasive Computing & Communication Workshops, Sydney, Australia, 14–18 March 2016. [Google Scholar]
- Pan, H.; Sun, W. Nonlinear Output Feedback Finite-Time Control for Vehicle Active Suspension Systems. IEEE Trans. Ind. Inform. 2019, 15, 2073–2082. [Google Scholar] [CrossRef]
- Lyu, Y.; Bai, L.; Huang, X. ChipNet: Real-Time LiDAR Processing for Drivable Region Segmentation on an FPGA. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 1769–1779. [Google Scholar] [CrossRef] [Green Version]
- Buslaev, A.; Seferbekov, S.; Iglovikov, V.; Shvets, A. Fully Convolutional Network for Automatic Road Extraction from Satellite Imagery. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 197–200. [Google Scholar]
- Huang, W.; Wu, H.; Chen, Q.; Luo, C.; Zeng, S.; Li, T.; Huang, Y. FPGA-Based High-Throughput CNN Hardware Accelerator With High Computing Resource Utilization Ratio. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4069–4083. [Google Scholar] [CrossRef] [PubMed]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both Weights and Connections for Efficient Neural Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28, pp. 1135–1143. [Google Scholar]
- Gale, T.; Elsen, E.; Hooker, S. The State of Sparsity in Deep Neural Networks. arXiv 2019, arXiv:1902.09574. [Google Scholar]
- Mocanu, D.C.; Lu, Y.; Pechenizkiy, M. Do We Actually Need Dense Over-Parameterization? In-Time Over-Parameterization in Sparse Training. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021. [Google Scholar]
- Jorge, P.D.; Sanyal, A.; Behl, H.S.; Torr, P.; Dokania, P.K. Progressive Skeletonization: Trimming more fat from a network at initialization. arXiv 2021, arXiv:2006.09081. [Google Scholar]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning Structured Sparsity in Deep Neural Networks. arXiv 2016, arXiv:1608.03665. [Google Scholar]
- Li, H.; Asim, K.; Igor, D. Pruning Filters for Efficient ConvNets. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks. arXiv 2018, arXiv:1808.06866. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2755–2763. [Google Scholar]
- Ding, X.; Hao, T.; Tan, J.; Liu, J.; Han, J.; Guo, Y.; Ding, G. ResRep: Lossless CNN Pruning via Decoupling Remembering and Forgetting. In Proceedings of the International Conference on Computer Vision, Online, 11–17 October 2021. [Google Scholar]
- Dong, W.; An, J.; Ke, X. PipeCNN: An OpenCL-Based FPGA Accelerator for Large-Scale Convolution Neuron Networks. arXiv 2016, arXiv:1611.02450. [Google Scholar]
- Liang, Y.; Lu, L.; Xie, J. OMNI: A Framework for Integrating Hardware and Software Optimizations for Sparse CNNs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2021, 40, 1648–1661. [Google Scholar] [CrossRef]
- Gao, S.; Huang, F.; Cai, W.; Huang, H. Network Pruning via Performance Maximization. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Niu, W.; Ma, X.; Lin, S.; Wang, S.; Qian, X.; Lin, X.; Wang, Y.; Ren, B. ACM PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning. Mach. Learn. 2020, 907–922. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Guo, F.M.; Niu, W.; Lin, X.; Tang, J.; Ma, K.; Ren, B.; Wang, Y. PCONV: The Missing but Desirable Sparsity in DNN Weight Pruning for Real-time Execution on Mobile Devices. arXiv 2019, arXiv:1909.05073. [Google Scholar] [CrossRef]
- Tan, Z.; Song, J.; Ma, X.; Tan, S.; Chen, H.; Miao, Y.; Wu, Y.; Ye, S.; Wang, Y.; Li, D.; et al. PCNN: Pattern-based Fine-Grained Regular Pruning Towards Optimizing CNN Accelerators. arXiv 2020, arXiv:2002.04997. [Google Scholar]
- Chang, X.; Pan, H.; Lin, W.; Gao, H. A Mixed-Pruning Based Framework for Embedded Convolutional Neural Network Acceleration. In IEEE Transactions on Circuits and Systems I: Regular Papers; IEEE: Piscataway, NJ, USA, 2021; Volume 68, pp. 1706–1715. [Google Scholar]
- Bergamaschi, L. Iterative Methods for Sparse Linear Systems; SIAM: Philadelphia, PA, USA, 2009. [Google Scholar]
- Bulu, A.; Fineman, J.T.; Frigo, M.; Gilbert, J.R.; Leiserson, C.E. Parallel sparse matrix-vector and matrix-transpose-vector multiplication using compressed sparse blocks. In Proceedings of the ACM Symposium on Parallel Algorithms and Architectures, Calgary, AB, Canada, 11–13 August 2009. [Google Scholar]
- Han, S.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.; Dally, W. IEEE EIE: Efficient Inference Engine on Compressed Deep Neural Network. ACM SIGARCH Comput. Archit. News 2016, 44, 243–254. [Google Scholar] [CrossRef]
- Xilinx. 7 Series FPGAs Configuration User Guide (UG470); AMD: Santa Clara, CA, USA, 2018. [Google Scholar]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the Value of Network Pruning. arXiv 2018, arXiv:1810.05270. [Google Scholar]
- Lecun, Y.; Bottou, L.; Orr, G.B. Neural Networks: Tricks of the Trade. Can. J. Anaesth. 2012, 41, 658. [Google Scholar]
- Smith, L. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Frankle, J.; Carbin, M. The Lottery Ticket Hypothesis: Finding Sparse Trainable Neural Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Malach, E.; Yehudai, G.; Shalev-Shwartz, S.; Shamir, O. Proving the Lottery Ticket Hypothesis: Pruning is All You Need. arXiv 2020, arXiv:2002.00585. [Google Scholar]
- Sui, X.; Lv, Q.; Bai, Y.; Zhu, B.; Zhi, L.; Yang, Y.; Tan, Z. A Hardware-Friendly Low-Bit Power-of-Two Quantization Method for CNNs and Its FPGA Implementation. Sensors 2022, 22, 6618. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. Handb. Syst. Autoimmune Dis. 2009, 7. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012; Curran Associates, Inc.: Red Hook, NY, USA, 2013. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Guo, Y.; Yao, A.; Chen, Y. Dynamic Network Surgery for Efficient DNNs. In Proceedings of the NIPS, Barcelona Spain, 5–10 December 2016. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]
- Jia, D.; Wei, D.; Socher, R.; Li, L.J.; Kai, L.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lu, Y.; Wu, Y.; Huang, J. A Coarse-Grained Dual-Convolver Based CNN Accelerator with High Computing Resource Utilization. In Proceedings of the 2020 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Genova, Italy, 31 August–2 September 2020; pp. 198–202. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alche-Buc, F., Fox, E., Garnett, R., Eds.; NeurIPS: San Diego, CA, USA, 2019; Volume 32. [Google Scholar]
- Xu, Y.; Li, Y.; Zhang, S.; Wen, W.; Wang, B.; Qi, Y.; Chen, Y.; Lin, W.; Xiong, H. TRP: Trained Rank Pruning for Efficient Deep Neural Networks. arXiv 2020, arXiv:2004.14566. [Google Scholar]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Cong, J. Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the 2015 ACM/SIGDA International Symposium, New York, NY, USA, 22–24 February 2015. [Google Scholar]
- Xilinx. Vivado Design Suite User Guide: Synthesis; AMD: Santa Clara, CA, USA, 2021. [Google Scholar]
- Yuan, T.; Liu, W.; Han, J.; Lombardi, F. High Performance CNN Accelerators Based on Hardware and Algorithm Co-Optimization. Circuits Syst. I Regul. Pap. IEEE Trans. 2020, 68, 250–263. [Google Scholar] [CrossRef]
- You, W.; Wu, C. An Efficient Accelerator for Sparse Convolutional Neural Networks. In Proceedings of the 2019 IEEE 13th International Conference on ASIC (ASICON), Chongqing, China, 29 October–1 November 2019. [Google Scholar]
- Chao, W.; Lei, G.; Qi, Y.; Xi, L.; Yuan, X.; Zhou, X. DLAU: A Scalable Deep Learning Accelerator Unit on FPGA. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2017, 36, 513–517. [Google Scholar]
- Biookaghazadeh, S.; Ravi, P.K.; Zhao, M. Toward Multi-FPGA Acceleration of the Neural Networks. ACM J. Emerg. Technol. Comput. Syst. 2021, 17, 1–23. [Google Scholar] [CrossRef]
- Bouguezzi, S.; Fredj, H.B.; Belabed, T.; Valderrama, C.; Faiedh, H.; Souani, C. An Efficient FPGA-Based Convolutional Neural Network for Classification: Ad-MobileNet. Electronics 2021, 10, 2272. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Batch Size | Weight Decay | Momentum |
|---|---|---|---|
| AlexNet | 64 | 0.0001 | 0.9 |
| VGG-16 | 64 | 0.0001 | 0.9 |
| ResNet-56 | 128 | 0.0001 | 0.9 |
| ResNet-110 | 128 | 0.0001 | 0.9 |
| Networks | Methods | Pruning Type | Pruning Rate | Accuracy | Δ Accuracy |
|---|---|---|---|---|---|
| VGG-16 (Baseline: 92.76%) | Pruning filters | Structured | 69.7% | 90.63% | −2.13% |
| Lottery ticket | Structured | 69.7% | 92.03% | −0.73% | |
| ITOP | Nonstructured | 70.0% | 92.99% | +0.23% | |
| KRP | Between both types | 70.0% | 92.54% | −0.22% | |
| ResNet-56 (Baseline: 92.66%) | Pruning filters | Structured | 70.0% | 90.66% | −2.00% |
| Lottery ticket | Structured | 70.0% | 91.20% | −1.46% | |
| TRP | Structured | 66.1% | 91.72% | −0.94% | |
| ResRep | Structured | 66.1% | 91.84% | −0.82% | |
| ITOP | Nonstructured | 66.7% | 93.24% | +0.58% | |
| KRP | Between both types | 66.7% | 91.87% | −0.79% | |
| KRP | Between both types | 63.8% | 92.65% | −0.01% |
| Network | Accuracy | ||
|---|---|---|---|
| Baseline | KRP | KRP and GSNQ | |
| VGG-16 | 92.76% | 92.54% (−0.22%) | 92.79% (+0.03%) |
| ResNet-56 | 92.66% | 91.87% (−0.79%) | 92.56% (−0.10%) |
| ResNet-110 | 93.42% | 92.66% (−0.76%) | 93.28% (−0.14%) |
| Modules | Bit Width | LUTs | FFs | DSPs |
|---|---|---|---|---|
| Module 1: implement multiplication by on-chip DSPs | 4 bits | 375 | 293 | 9 |
| Module 2: implement multiplication by on-chip LUTs | 4 bits | 499 | 257 | 0 |
| Module 3: based on GSNQ only | 4 bits | 397 | 273 | 0 |
| Module 4: based on KRP and GSNQ | 4 bits | 162 | 165 | 0 |
| Module 1: implement multiplication by on-chip DSPs | 3 bits | 250 | 268 | 9 |
| Module 2: implement multiplication by on-chip LUTs | 3 bits | 402 | 226 | 0 |
| Module 3: based on GSNQ only | 3 bits | 263 | 237 | 0 |
| Module 4: based on KRP and GSNQ | 3 bits | 124 | 134 | 0 |
| Modules | Bit Width | LUTs | FFs | DSPs |
|---|---|---|---|---|
| Module 1: implement multiplication by on-chip DSPs | 4 bits | 13,438 (7.82%) | 11,463 (3.33%) | 288 (32%) |
| Module 2: implement multiplication by on-chip LUTs | 4 bits | 16,906 (9.83%) | 9960 (2.90%) | 0 (0.00%) |
| Module 3: based on GSNQ only | 4 bits | 13,917 (8.10%) | 10,824 (3.15%) | 0 (0.00%) |
| Module 4: based on KRP and GSNQ | 4 bits | 5481 (3.19%) | 6051 (1.76%) | 0 (0.00%) |
| Module 1: implement multiplication by on-chip DSPs | 3 bits | 9430 (5.49%) | 9938 (2.89%) | 288 (32%) |
| Module 2: implement multiplication by on-chip LUTs | 3 bits | 13,849 (8.06%) | 9037 (2.63%) | 0 (0.00%) |
| Module 3: based on GSNQ only | 3 bits | 9500 (5.53%) | 9348 (2.72%) | 0 (0.00%) |
| Module 4: based on KRP and GSNQ | 3 bits | 4231 (2.46%) | 4899 (1.42%) | 0 (0.00%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sui, X.; Lv, Q.; Zhi, L.; Zhu, B.; Yang, Y.; Zhang, Y.; Tan, Z. A Hardware-Friendly High-Precision CNN Pruning Method and Its FPGA Implementation. Sensors 2023, 23, 824. https://doi.org/10.3390/s23020824
Sui X, Lv Q, Zhi L, Zhu B, Yang Y, Zhang Y, Tan Z. A Hardware-Friendly High-Precision CNN Pruning Method and Its FPGA Implementation. Sensors. 2023; 23(2):824. https://doi.org/10.3390/s23020824
Chicago/Turabian StyleSui, Xuefu, Qunbo Lv, Liangjie Zhi, Baoyu Zhu, Yuanbo Yang, Yu Zhang, and Zheng Tan. 2023. "A Hardware-Friendly High-Precision CNN Pruning Method and Its FPGA Implementation" Sensors 23, no. 2: 824. https://doi.org/10.3390/s23020824
APA StyleSui, X., Lv, Q., Zhi, L., Zhu, B., Yang, Y., Zhang, Y., & Tan, Z. (2023). A Hardware-Friendly High-Precision CNN Pruning Method and Its FPGA Implementation. Sensors, 23(2), 824. https://doi.org/10.3390/s23020824