1. Introduction
With the swift progression of new technologies, such as the internet of things (IoT) and artificial intelligence (AI), intelligent manufacturing has emerged as the new norm in the manufacturing sector. Despite this transformation, mechanical machining continues to hold a central role. Research has shown that real-time tool wear identification can enhance machine utilization by 50%, boost productivity by 35% and cut production costs by 30% [
1,
2,
3]. Therefore, the real-time and accurate identification of tool wear state holds paramount significance in enhancing the efficiency of manufacturing processes and the quality of final products.
The identification of tool wear conditions primarily relies on two monitoring approaches: direct and indirect methods. The direct monitoring method utilizes industrial cameras to directly observe the wear state of the tool, ensuring accurate assessments. However, it is susceptible to interference from cutting fluids and chips, and it requires the machine tool to be stopped during measurement, limiting its practical application [
4]. In contrast, the indirect monitoring method uses sensor data from the machining process. It establishes a mapping relationship with tool wear. This method provides online monitoring and aligns well with real-time production needs [
5]. The indirect monitoring method involves the stages of signal acquisition and preprocessing, feature extraction, feature selection and identification model development.
Direct utilization of the acquired signal data can introduce noise, potentially leading to misinterpretations [
6]. Therefore, data preprocessing, especially the employment of denoising techniques, is important to ensure the accurate identification of the tool wear state. After denoising, to avoid directly processing the substantial signal data and to mitigate the risk of overfitting and poor generalization in the identification model, numerous features characterizing tool wear are extracted from the denoised signal [
7]. However, not every feature is invariably sensitive to tool wear, necessitating the selection of extracted features.
Recursive feature elimination (RFE) is one of the commonly used feature selection approaches in machine learning. It can select a high-quality feature set and remove redundant and irrelevant features from the dataset [
8]. RFE is widely used for machine health diagnosis, prediction, product defect detection and other manufacturing applications [
9,
10,
11]. In the intricate scenarios of tool wear, the strength of RFE lies in its ability to account for interdependencies among features and progressively eliminate the least significant ones. Compared to basic linear correlation methods, RFE is more adept at uncovering complex relationships with the target variable, thereby selecting a more representative feature subset.
Selected signal features can be utilized as inputs, and a tool wear state identification model can be developed. Typical machine-learning models for tool wear identification encompass the artificial neural network (ANN), support vector machine (SVM), hidden Markov model (HMM) and random forest (RF), among others [
12]. Cao et al. [
13] introduced a tool condition monitoring approach integrated with a field fiber optic temperature measurement device, where spectral features were extracted and input into an ANN for tool state classification. Experimental results showed accuracy consistently above 90% during variable parameters. Basil et al. [
14] harnessed sensors to capture vibration data from lathes, employing the random forest algorithm to develop a real-time tool wear classification model, which exhibited notable classification prowess. However, these algorithms are prone to overfitting when processing small sample data. Moreover, since they predominantly rely on the empirical risk minimization principle for optimization, they are susceptible to falling into local optimum solutions, undermining the model’s accuracy and stability.
SVM fundamentally adheres to the structural risk minimization principle, effectively mitigating the risk of overfitting by incorporating regularization terms to control the model’s complexity. Moreover, studies highlight that the non-linear relationship between tool wear and monitoring signals, along with the limited training samples for model development, stand as two significant challenges in tool wear identification [
15]. Given SVM’s theoretical foundation in non-linear mapping and its efficacy in small sample machine learning, SVM has found widespread application in the field of tool wear state recognition [
16,
17,
18]. Nonetheless, the efficacy of SVM is significantly influenced by the selection of the penalty factor C and the kernel parameter γ, which directly dictate the model’s classification accuracy and generalization ability. Hence, to fully exploit the potential of SVM grounded in the structural risk minimization principle, it is vital to aptly optimize the penalty factor C and the kernel parameter γ [
19].
In recent years, the development of intelligent optimization algorithms has progressed significantly, and researchers have designed algorithms inspired by some natural phenomena, such as gray wolf optimization (GWO) [
20], the whale optimization algorithm (WOA) [
21], sparrow search algorithm (SSA) [
22], northern goshawk optimization (NGO) [
23], and so on. These algorithms have been extensively utilized for parameter search optimization in SVM. Especially in the field of tool wear state identification, they play a key role in the training process of identification models. Stalin et al. [
24] introduced a tool wear prediction method, leveraging particle swarm optimization (PSO) for SVM tuning, and experimentally demonstrated that PSO can effectively optimize SVM parameters to achieve good prediction accuracy. Ying et al. [
25] introduced a broaching tool condition monitoring model optimized with GWO for SVM. The experimental results indicate that, compared to PSO-optimized SVM, the GWO-SVM method demonstrates advantages in terms of classification accuracy and optimization time. Gai et al. [
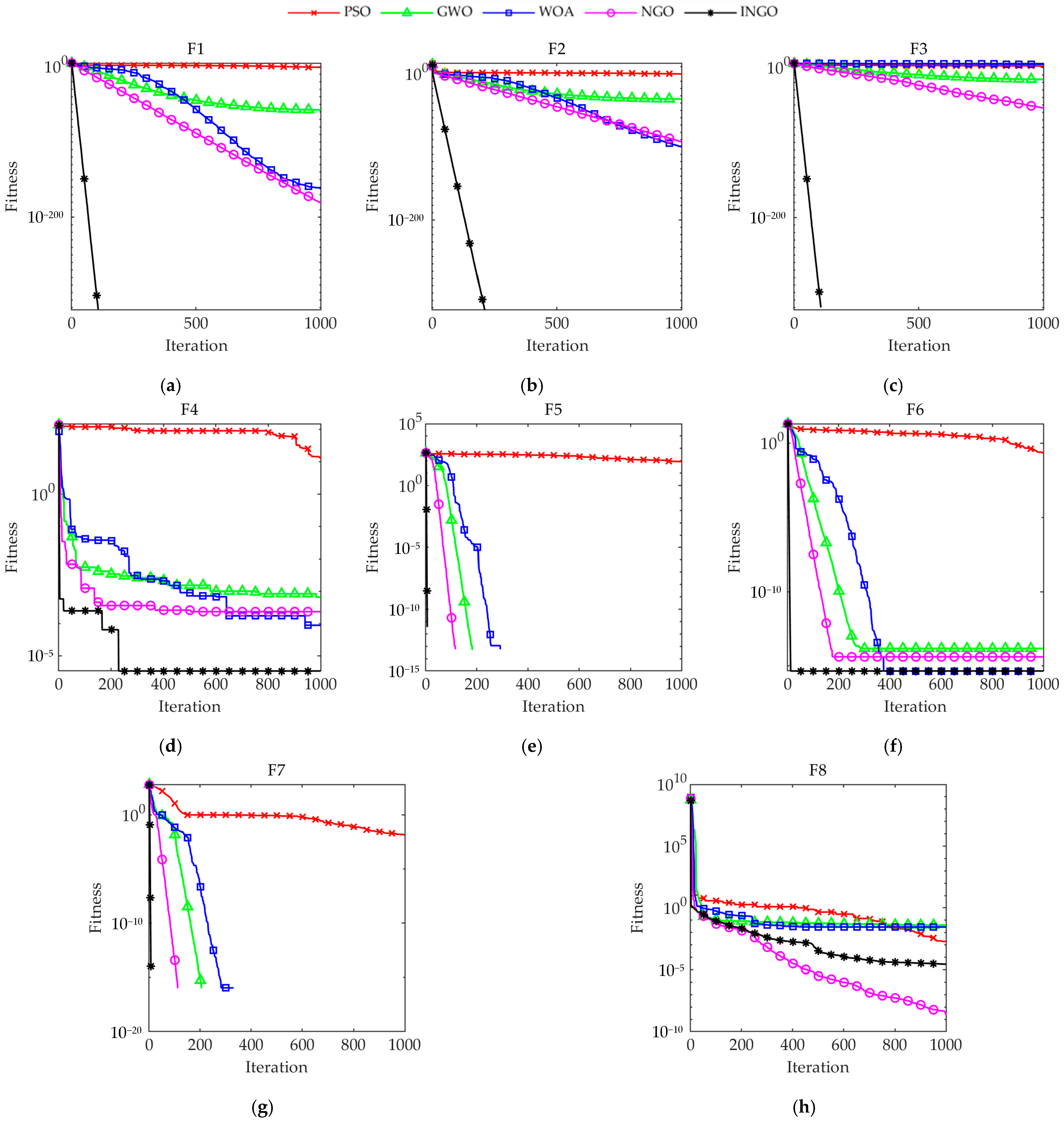
26] constructed a SVM classification model optimized with the WOA, designated for tool wear state identification. The approach’s efficiency and practicality were confirmed through milling wear experimentations. These research works underscore the significant potential of intelligent optimization algorithms in enhancing the performance of tool wear state identification approaches. By leveraging the strengths of these algorithms, researchers can monitor and predict tool wear more accurately and robustly. Although these algorithms show great potential in parameter search optimization, ensuring their convergence accuracy and stability in complex problems remains a challenge.
In 2021, Mohammad et al. [
23] introduced the northern goshawk optimization (NGO) as an efficient population intelligence optimization algorithm characterized by fast convergence, robustness and high accuracy of operating results. In recent years, NGO has attracted the attention of many scholars. El-Dabah et al. [
27] utilized NGO for identifying the parameters of the photovoltaic module’s triple diode model, and the simulation results showed that NGO accurately extracted the model parameters with superior convergence rate and precision compared to alternative algorithms. Xu et al. [
28] developed a northern goshawk optimization–backpropagation artificial neural network (NGO-BP) model for forecasting blood concentration and pharmacokinetic parameters of MET306. The NGO has been successfully utilized in resolving a variety of engineering optimization problems, but how to further improve its convergence accuracy and speed is one of the issues, which this study attempts to address.
Building on the aforementioned research, we use an improved northern goshawk optimization algorithm to optimize the SVM’s penalty factor
C and kernel parameter
γ for tool wear state identification. First, the force, vibration and acoustic emission signals are gathered during the milling process. Next, to fully depict the correlation between the signals and tool wear, 245 features from the time, frequency and time–frequency domains are extracted from seven signal channels, forming the initial feature set. Third, to minimize the model’s runtime and data storage requirements while avoiding overfitting, the SVM-RFE model is utilized for feature selection, selecting the optimal feature set most closely related to tool wear. Fourth, the NGO is improved and applied for the first time to the parameter finding of SVM. Ultimately, the optimal feature set is input into the INGO-SVM model for training and prediction, achieving precise tool wear state identification. The feasibility and effectiveness of the proposed approach were validated using the Prognostic and Health Management Society Conference Data Challenge (PHM 2010) real-world dataset [
29]. Experimental results show that the method effectively screens features related to tool wear and exhibits strong learning ability to accurately identify tool wear state, achieving an identification accuracy of 97.9% with small sample data. This offers a novel approach for research on tool wear state identification.
The rest of this paper is organized in the following manner.
Section 2 offers an in-depth explanation of the proposed method and briefly examines related theories.
Section 3 presents the experimental setup relevant to this paper while providing a detailed discussion of the obtained results. Finally,
Section 4 serves as the conclusion of this paper.
2. Proposed Methodology
2.1. Support Vector Machine Recursive Feature Elimination (SVM-RFE)
SVM-RFE is an SVM-based sequential backward selection algorithm utilized for feature selection. The selected features have complementary characteristics, and in each cycle, the features with the lowest scores are removed. However, this does not imply that the top-ranked features alone can achieve the best classification performance for SVM. Multiple features need to be combined to achieve the optimal classification performance, facilitating the fusion of multi-sensor signal features. SVM-RFE involves the following main steps:
Step 1: Determine the kernel function type to be used in the SVM.
Step 2: Train the SVM model using the initial feature set and calculate the importance score Ks for each feature.
The SVM was originally developed for binary classification problems with linearly separable data. Due to the limited scope of the paper, the classification principle of the SVM is not elaborated here. In this paper, the square of the weight vector of the optimal hyperplane of the SVM, i.e.,
ω2, is used as the ranking criterion for each feature [
30,
31]. However, the problem of identifying tool wear state typically involves multiple wear classes, which requires a multi-classification strategy. Therefore, a one-vs-one (OVO) strategy is used, where each category constructs a binary subproblem with all other categories, and if
a is the number of categories, resulting in
subproblems. During each SVM-RFE training process,
A subproblems need to be solved to obtain
A ranking criterion scores. The
A ranking criterion scores are then summed to obtain the total score, i.e.,
, which is used as the criterion for feature ranking.
Step 3: Arrange the importance scores of all features in decreasing order and eliminate the feature with the lowest score.
Step 4: Continue iterating Steps 2 and 3 until the remaining features meet the feature reduction criteria.
2.2. Northern Goshawk Optimization
The Principle of NGO
The hunting strategy of the northern goshawk can be divided into two steps: detecting the prey, and pursuing and evading. The mathematical model formulated by NGO, inspired by these distinct hunting steps, is detailed below:
(1) Prey detection step (exploration step).
In the initial step of the northern goshawk’s hunting process, it randomly chooses the prey and quickly launches an attack. The mathematical representation of the northern goshawk’s behavior in this step is as follows:
In this equation, Pi represents the prey’s position selected by the ith northern goshawk; represents the objective function value (i.e., the fitness value) of the prey’s location corresponding to the ith northern goshawk; k is a randomly chosen integer from [1, N]; represents the new position of the ith northern goshawk; represents the new position of the ith northern goshawk in the jth dimension; represents the fitness value based on the update of the ith northern goshawk following this step; r is a randomly generated value within [0, 1]; and I is a random integer of 1 or 2.
(2) Pursuit and fleeing step (development step).
After being attacked by the northern goshawk, the prey will attempt to flee. During the pursuit, northern goshawks are extremely fast and can catch their prey in various scenarios. Assuming the hunt takes place within a range of attack radius
R, the mathematical representation of the northern goshawk’s behavior in this step is as follows:
In this equation, t represents the current iteration count, and T represents the maximum iteration limit. represents the new position of the ith northern goshawk in the second step, while represents the new position of the ith northern goshawk in the jth dimension during the second step, and corresponds to the fitness value based on the update of the ith northern goshawk following this step.
2.3. Improvement of NGO (INGO)
The NGO has been widely used due to its high convergence accuracy and good robustness. However, it still has certain limitations:
During the population initialization step, the NGO employs a method, which generates the initial population randomly. This method results in a high degree of randomness and uneven distribution within the initial population, with individuals exhibiting significant disparities. This can easily lead to a lack of diversity in the population, potentially missing out on potential optimal solutions.
In the prey recognition step, the NGO relies heavily on two random numbers, “r” and “I”, to depict the random behaviors within the population. This excessive randomness might lead to unstable output results, thereby diminishing the quality of solutions.
As indicated in Equation (6), the greedy selection mechanism (GSM) governs the population position updates during the pursuit and evasion phases, which easily leads the algorithm into local optima traps.
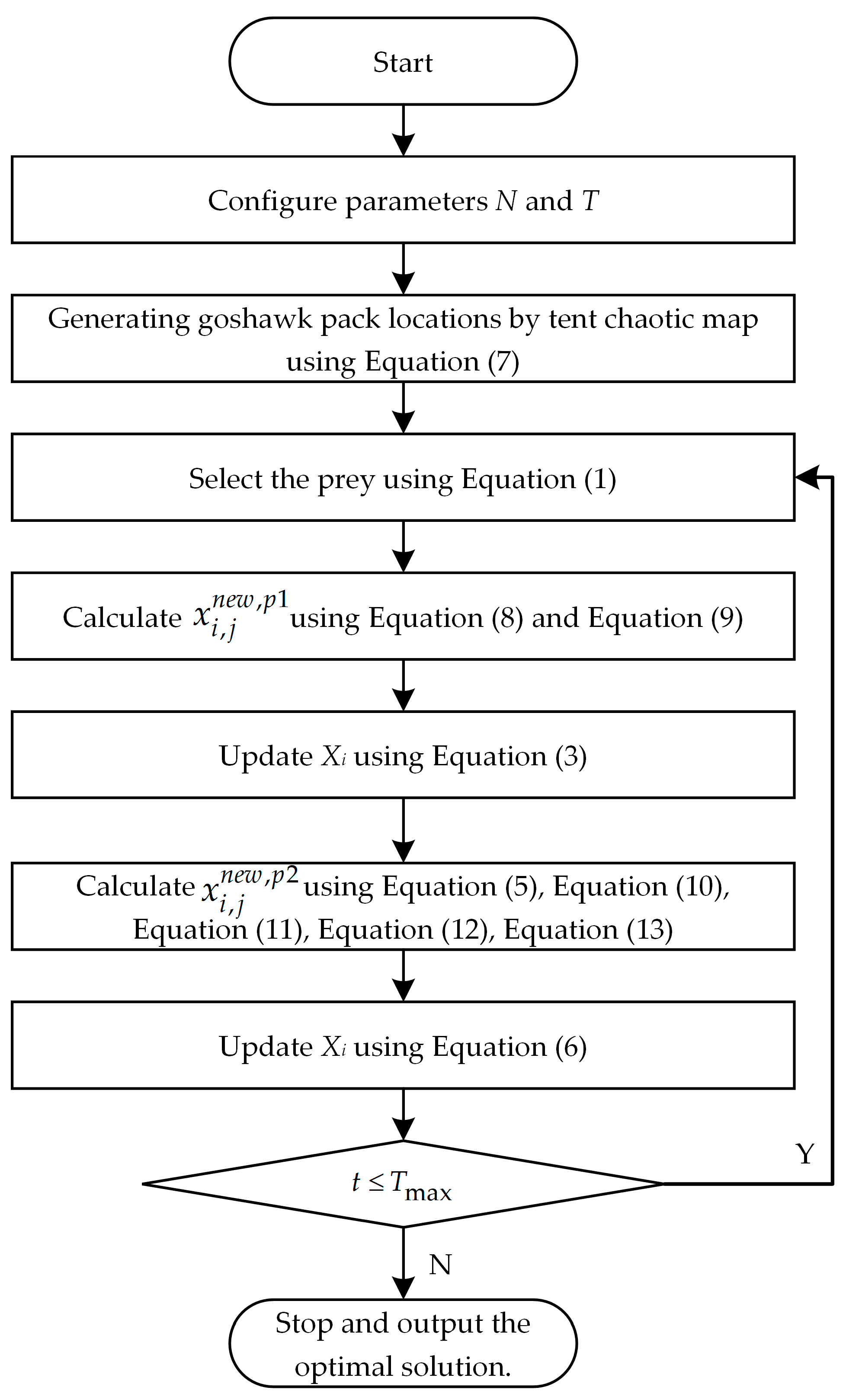
Based on the aforementioned analysis, in order to further enhance the optimization capabilities of the NGO, a new method termed INGO has been proposed. Initially, the population is initialized through tent chaos mapping—a process, which not only amplifies the diversity within the population but also facilitates the algorithm in identifying potential optimal solutions from a broader solution space, thereby augmenting its global search capabilities. Subsequently, an adaptive weight factor is introduced during the prey detection step of the NGO to dynamically adjust the search strategy. This adaptive weight factor is capable of automatically modulating the search strategy based on the progression of iterations, consequently reducing the algorithm’s randomness to a certain extent. In the pursuit and fleeing step, we incorporate a Levy flight strategy—a tactic, which renders the algorithm more flexible and diversified during the search process, effectively circumventing premature convergence to local optima. The improved algorithm flowchart is illustrated in
Figure 1, and the mathematical principles of the enhanced strategy are as follows:
2.3.1. Tent Chaos Mapping
Chaos mapping is especially adept at initializing populations in optimization algorithms; by substituting random parameters with chaos mapping, the algorithm is capable of generating initial solutions with excellent diversity within the search space [
32]. Utilizing the random chaotic sequences generated by tent chaos mapping facilitates the creation of the initial generation of the population. The universal formulation of tent chaos mapping is as follows:
where
.
2.3.2. Adaptive Weight Factor
During the prey detection step, we introduced a dynamically varying adaptive weight factor,
ω(
t), which changes according to the iteration count. In the early stages of iteration,
ω(
t) is set to a relatively high value, aiming to amplify the global search capability of the algorithm. As the iteration progresses,
ω(
t) will gradually decrease to 0.5, thereby enhancing the algorithm’s local search ability. This strategy assists in maintaining a balance between the global and local search capabilities of the algorithm, ultimately improving the convergence accuracy. The mathematical representation of the adaptive weight factor
ω(
t) is as follows:
where
t is the current iteration count, and
tmax is the maximum number of iterations. Consequently, after incorporating the adaptive weight factor, Equation (2) is updated as follows:
2.3.3. Levy Flight Strategy
The Levy flight originates from the integration of Levy’s symmetric stable distribution, serving as a method to generate special random step lengths. Addressing the issue of random searches, many scholars have incorporated this strategy to enhance algorithms, thereby achieving superior optimization results [
33,
34]. In this paper, the Levy flight strategy is introduced in the second phase of NGO to prevent the population from falling into local optima. The step length of Levy flight follows a heavy-tailed exponential probability distribution (Levy distribution), which adheres to the distribution formula with a step length of
s:
The step equation for the Levy flight process simulation is shown in Equation (11):
where
β = 1.5 [
35];
u and
v follow a normal distribution with
and
, respectively. The expressions for
and
are as follows:
where
represents the standard Gamma function integration operation.
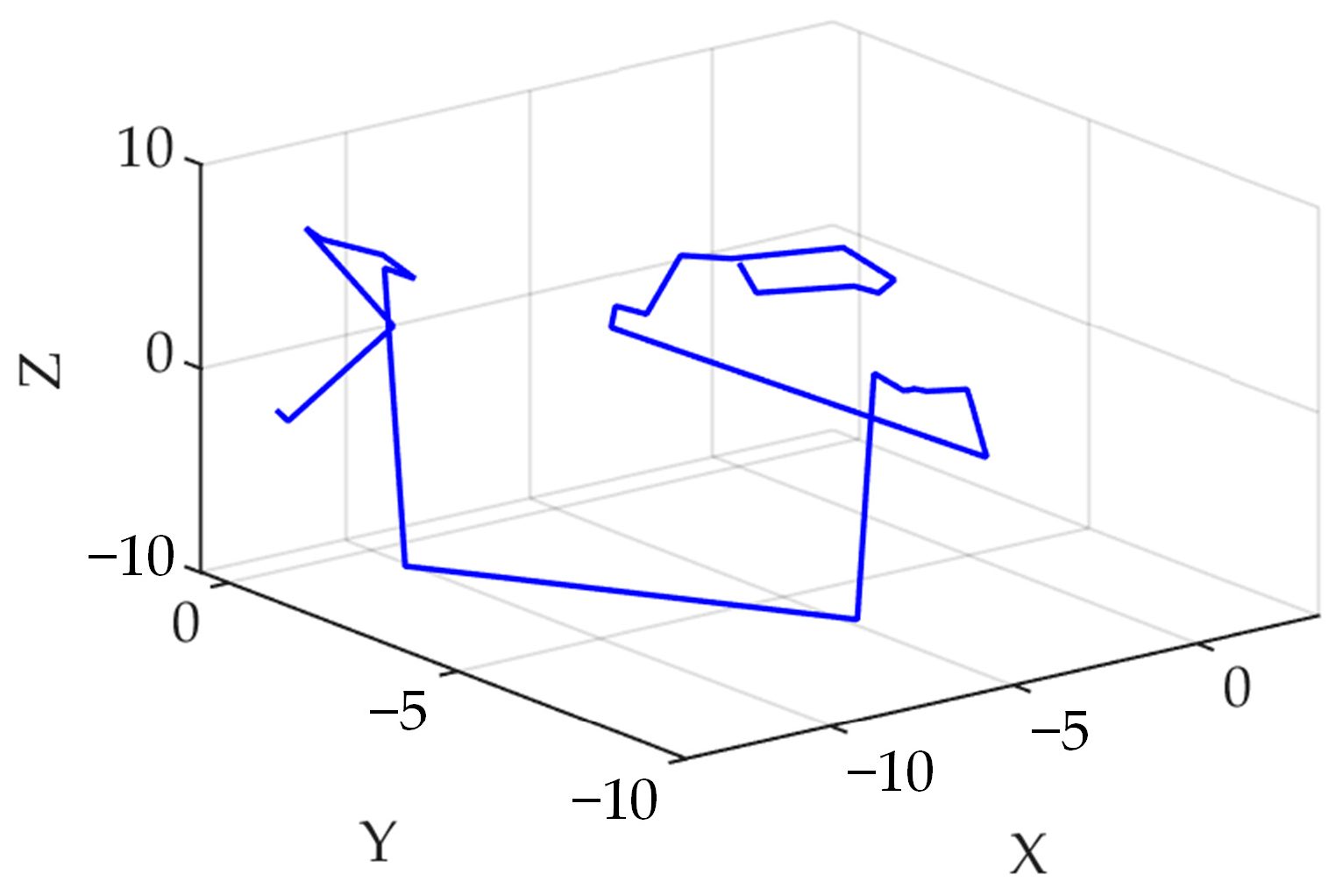
Figure 2 displays a schematic diagram of Levy flight in 3D space, which showcases the random search of the INGO in a 3D space. Equation (4) is transformed by adding the Levy flight strategy:
where
is the product of the element.
2.4. SVM Parameter Optimization
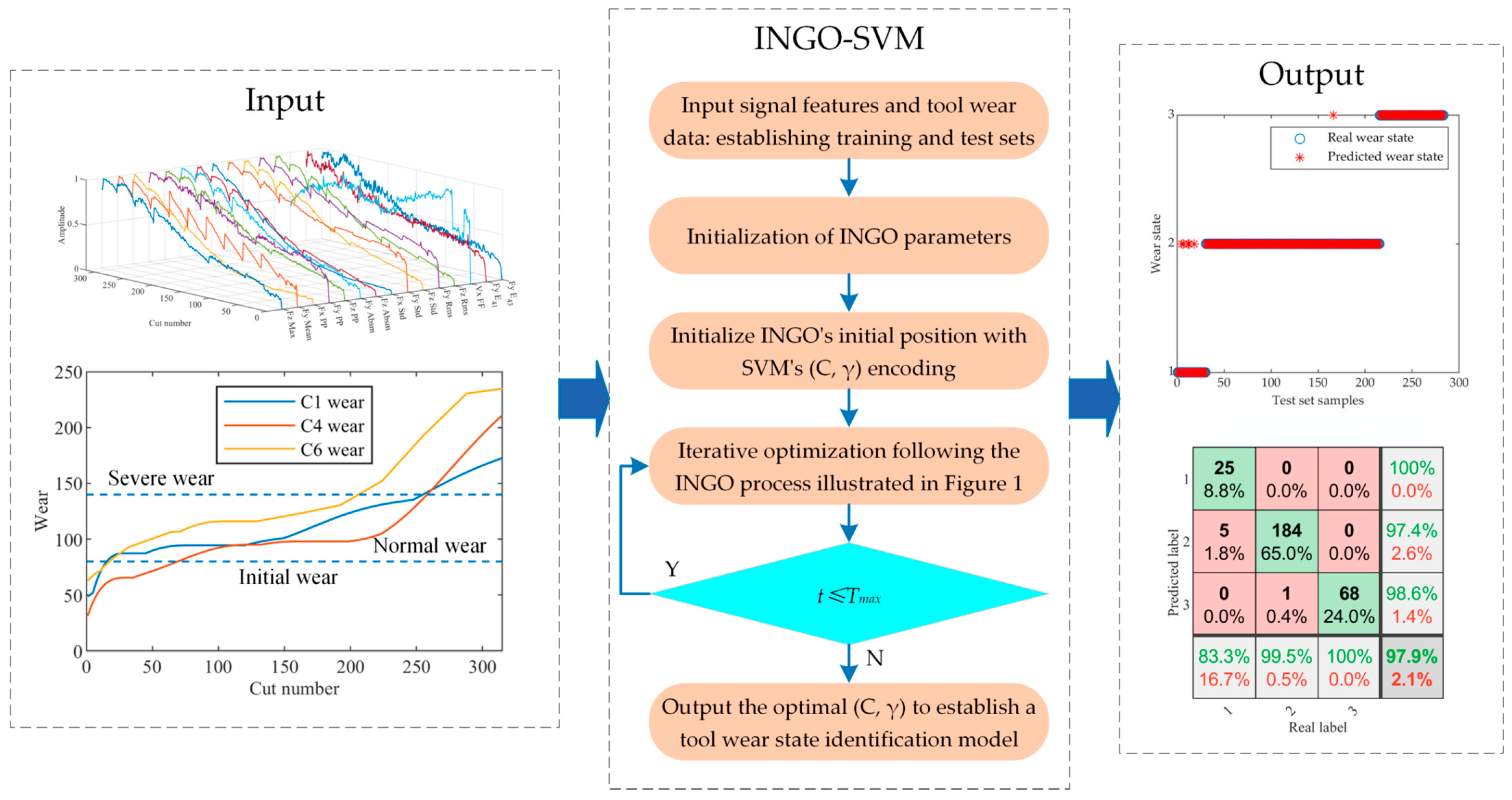
The INGO algorithm is introduced to search for the penalty factor C and kernel function parameter γ of the SVM in order to train an optimal identification model. The process of implementing INGO-SVM is outlined below.
Step 1: Input the training set and test set to establish the fitness function. In this study, the average classification error from five-fold cross-validation serves as the fitness function to evaluate the quality of individual positions, as depicted below:
where
S is the total number of samples;
S* is the number of samples correctly classified by the SVM; and
K is the K-fold cross-validation, where
in this paper.
Step 2: Initialization of INGO parameters, including the population size N, maximum iteration count Tmax and the range of optimization for the penalty factor C and kernel function parameter γ.
Step 3: The initial position of the northern goshawk is initialized using the tent chaos mapping, with individual positions encoded as (C, γ); this ensures a more uniform distribution of the initial population across the parameter range.
Step 4: Conduct iterative optimization following the INGO procedure outlined in
Figure 1.
Step 5: Evaluate whether the number of iterations meets the stopping criteria. If not, revert to Step 4. If satisfied, halt the algorithm iteration and output the optimal penalty factor C and kernel function parameter γ, establishing the SVM tool wear state identification model.
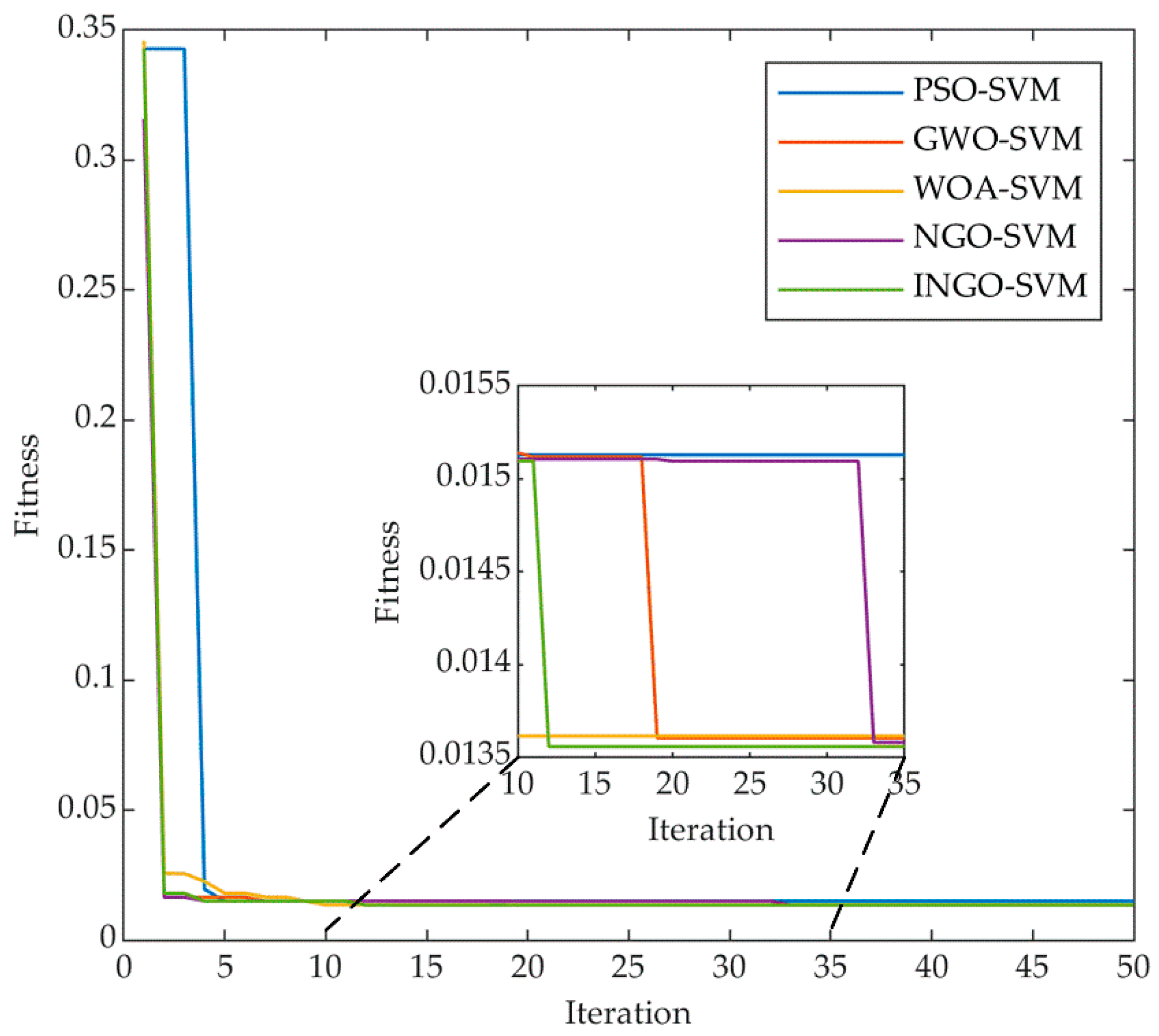
Figure 3 displays the flowchart of the INGO-SVM model.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}