
On-Device Execution of Deep Learning Models on HoloLens2 for Real-Time Augmented Reality Medical Applications


Abstract
:1. Introduction
- Provide an overview of applications, identified in the literature, in which deep learning models are directly executed on the HoloLens2.
- Assess the feasibility of executing models with various complexity on HoloLens2.
- Compare two popular frameworks for neural network inference, Windows Machine Learning (WinML) and Unity Barracuda, in terms of inference time (i.e., the time that the model takes to make a prediction on a new image).
- Provide benchmark inference time values for state-of-the-art DL models for different medical applications (e.g., Yolo and Unet models for surgical guidance).
2. Related Work
- Review papers (five papers excluded).
- Papers presenting datasets (1 paper excluded).
- Papers focusing on ML/DL model optimization (three papers excluded).
- Papers in which HoloLens2 is not used (three papers excluded).
- Papers in which the developed AR application does not integrate ML/DL models (25 papers excluded).
- Papers in which the integration of ML/DL models is performed by adopting a client-server architecture (39 papers excluded).
3. Materials and Methods
3.1. Microsoft HoloLens2
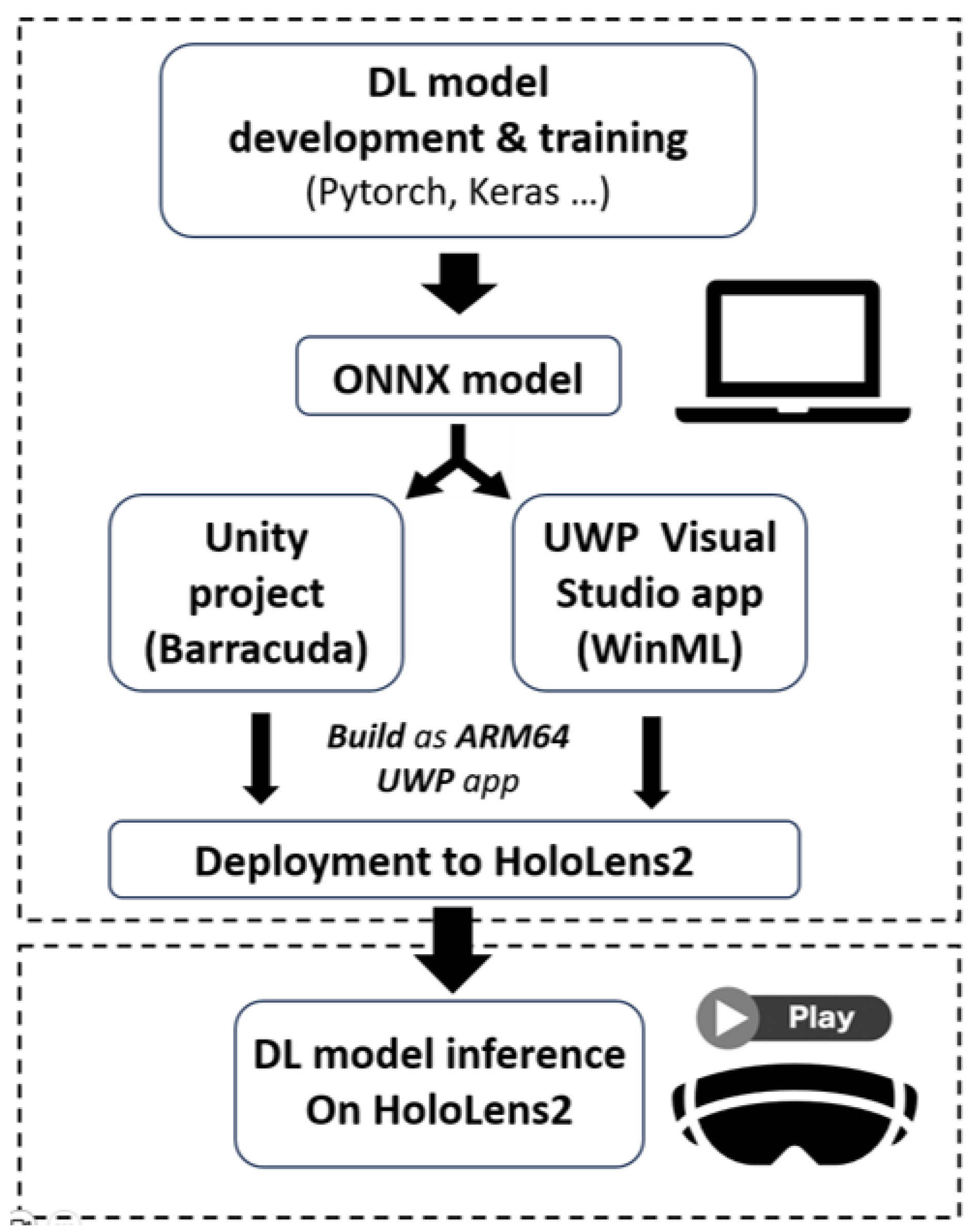
3.2. Deep Learning Integration on HoloLens2
3.2.1. Open Neural Network Exchange Model
3.2.2. Unity Barracuda
3.2.3. Windows Machine Learning
3.2.4. Evaluation Metric: Inference Time
- output = await model. EvaluateAsync(image);
- output = engine. worker. Execute(image). PeekOutput();
- engine. worker. FlushSchedule(true);
3.3. Experimental Design
3.3.1. Impact of Model Complexity on Inference Time
3.3.2. Feasibility of SOTA Models Integration
- SurgeonAssist-Net [28]. The model infers the poses of a drill and of the surgeon’s hand from RGB images of 224 × 224 pixels. The ONNX model, pre-trained on the Colibrì dataset [58], is available in the official GitHub repository of the paper [28]. The model version “PyTorch_1.4” was used in this study.
- Yolov4-Tiny [34,36]. The model performs object detection in RGB images of 416 × 416 pixels. For our study, we utilized a pre-trained version of the model on the Pascal Visual Object Classes (VOC) dataset [60], which is available in a public GitHub repository [61]. The model was trained to detect 20 different classes.
- Unet model. The pre-trained ONNX model was obtained from a public GitHub repository [64]. The model performs semantic segmentation of RGB images (256 × 256 pixels). The model version “u2netp.onnx” was used in this study.
3.3.3. Software and Library Versions
4. Results
4.1. Impact of Model Complexity on Inference Time: Results
4.2. Windows Machine Learning vs. Unity Barracuda
4.3. Feasibility of SOTA Models Integration: Results
- SurgeonAssist-Net. Our results show higher inference times with WinML on GPU than the original authors reported for WinML on CPU, which they reported as 219 ms in the paper and estimated between 200 and 350 ms in their GitHub repository.
- HMD-EgoPose. We recorded inference times of around 1 s when using WinML on GPU, similar to the inference times reported by the author in CPU. However, when executed with Barracuda, the recorded inference times were notably shorter at 384 ms.
5. Discussion
Limitations and Future Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moawad, G.N.; Elkhalil, J.; Klebanoff, J.S.; Rahman, S.; Habib, N.; Alkatout, I. Augmented realities, artificial intelligence, and machine learning: Clinical implications and how technology is shaping the future of medicine. J. Clin. Med. 2020, 9, 3811. [Google Scholar] [CrossRef]
- Gumbs, A.A.; Grasso, V.; Bourdel, N.; Croner, R.; Spolverato, G.; Frigerio, I.; Illanes, A.; Abu Hilal, M.; Park, A.; Elyan, E. The Advances in Computer Vision That Are Enabling More Autonomous Actions in Surgery: A Systematic Review of the Literature. Sensors 2022, 22, 4918. [Google Scholar] [CrossRef]
- Oufqir, Z.; Binan, L.; el Abderrahmani, A.; Satori, K. Deep Learning for the Improvement of Object Detection in Augmented Reality. Int. J. Adv. Soft Comput. Its Appl. 2021, 13, 130–143. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Guo, Y.C.; Weng, T.H.; Fischer, R.; Fu, L.C. 3D semantic segmentation based on spatial-aware convolution and shape completion for augmented reality applications. Comput. Vis. Image Underst. 2022, 224, 103550. [Google Scholar] [CrossRef]
- Khurshid, A.; Grunitzki, R.; Estrada Leyva, R.G.; Marinho, F.; Matthaus Maia Souto Orlando, B. Hand Gesture Recognition for User Interaction in Augmented Reality (AR) Experience. In Virtual, Augmented and Mixed Reality: Design and Development; Springer International Publishing: Cham, Switzerland, 2022; pp. 306–316. [Google Scholar] [CrossRef]
- Jain, R.; Karsh, R.; Barbhuiya, A. Literature review of vision-based dynamic gesture recognition using deep learning techniques. Concurr. Comput. Pract. Exp. 2022, 34, e7159. [Google Scholar] [CrossRef]
- Zhou, H.; Huang, W.; Xiao, Z.; Zhang, S.; Li, W.; Hu, J.; Feng, T.; Wu, J.; Zhu, P.; Mao, Y. Deep-Learning-Assisted Noncontact Gesture-Recognition System for Touchless Human-Machine Interfaces. Adv. Funct. Mater. 2022, 32, 2208271. [Google Scholar] [CrossRef]
- Devagiri, J.S.; Paheding, S.; Niyaz, Q.; Yang, X.; Smith, S. Augmented Reality and Artificial Intelligence in industry: Trends, tools, and future challenges. Expert Syst. Appl. 2022, 207, 118002. [Google Scholar] [CrossRef]
- Seibold, M.; Spirig, J.M.; Esfandiari, H.; Farshad, M.; Fürnstahl, P. Translation of Medical AR Research into Clinical Practice. J. Imaging 2023, 9, 44. [Google Scholar] [CrossRef]
- Baashar, Y.; Alkawsi, G.; Wan Ahmad, W.N.; Alomari, M.A.; Alhussian, H.; Tiong, S.K. Towards Wearable Augmented Reality in Healthcare: A Comparative Survey and Analysis of Head-Mounted Displays. Int. J. Environ. Res. Public Health 2023, 20, 3940. [Google Scholar] [CrossRef]
- Park, S.; Bokijonov, S.; Choi, Y. Review of Microsoft HoloLens Applications over the Past Five Years. Appl. Sci. 2021, 11, 7259. [Google Scholar] [CrossRef]
- Palumbo, A. Microsoft Hololens 2 in medical and healthcare context: State of the art and future prospects. Sensors 2022, 22, 7709. [Google Scholar] [CrossRef] [PubMed]
- Collins, T.; Pizarro, D.; Gasparini, S.; Bourdel, N.; Chauvet, P.; Canis, M.; Calvet, L.; Bartoli, A. Augmented Reality Guided Laparoscopic Surgery of the Uterus. IEEE Trans. Med. Imaging 2021, 40, 371–380. [Google Scholar] [CrossRef]
- Zorzal, E.R.; Campos Gomes, J.M.; Sousa, M.; Belchior, P.; da Silva, P.G.; Figueiredo, N.; Lopes, D.S.; Jorge, J. Laparoscopy with augmented reality adaptations. J. Biomed. Inform. 2020, 107, 103463. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Wang, T.; Xuquan, J.; Shen, Y.; Sun, Z.; Zhang, X. A markerless automatic deformable registration framework for augmented reality navigation of laparoscopy partial nephrectomy. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 1285–1294. [Google Scholar] [CrossRef] [PubMed]
- Jarmula, J.; de Andrade, E.J.; Kshettry, V.R.; Recinos, P.F. The Current State of Visualization Techniques in Endoscopic Skull Base Surgery. Brain Sci. 2022, 12, 1337. [Google Scholar] [CrossRef] [PubMed]
- Thavarajasingam, S.G.; Vardanyan, R.; Rad, A.A.; Thavarajasingam, A.; Khachikyan, A.; Mendoza, N.; Nair, R.; Vajkoczy, P. The use of augmented reality in transsphenoidal surgery: A systematic review. Br. J. Neurosurg. 2022, 36, 457–471. [Google Scholar] [CrossRef]
- Hale, A.; Fischer, M.; Schütz, L.; Fuchs, H.; Leuze, C. Remote Training for Medical Staff in Low-Resource Environments Using Augmented Reality. J. Imaging 2022, 8, 319. [Google Scholar] [CrossRef]
- Garg, R.; Aggarwal, K.; Arora, A. Applications of Augmented Reality in Medical Training. In Mathematical Modeling, Computational Intelligence Techniques and Renewable Energy; Springer Nature: Singapore, 2023; pp. 215–228. [Google Scholar] [CrossRef]
- Logeswaran, A.; Munsch, C.; Chong, Y.J.; Ralph, N.; McCrossnan, J. The role of extended reality technology in healthcare education: Towards a learner-centred approach. Future Healthc. J. 2021, 8, 79–84. [Google Scholar] [CrossRef]
- Birlo, M.; Edwards, P.J.E.; Yoo, S.; Dromey, B.; Vasconcelos, F.; Clarkson, M.J.; Stoyanov, D. CAL-Tutor: A HoloLens 2 Application for Training in Obstetric Sonography and User Motion Data Recording. J. Imaging 2023, 9, 6. [Google Scholar] [CrossRef]
- Dinh, A.; Yin, A.L.; Estrin, D.; Greenwald, P.; Fortenko, A. Augmented Reality in Real-time Telemedicine and Telementoring: Scoping Review. JMIR Mhealth Uhealth 2023, 11, e45464. [Google Scholar] [CrossRef]
- Microsoft. Microsoft HoloLens. 2023. Available online: https://learn.microsoft.com/en-us/hololens/hololens2-hardware (accessed on 3 June 2023).
- Apple. Apple Vision Pro. 2023. Available online: https://www.apple.com/apple-vision-pro (accessed on 17 October 2023).
- Riurean, S.; Antipova, T.; Rocha, Á.; Leba, M.; Ionica, A. VLC, OCC, IR and LiFi Reliable Optical Wireless Technologies to be Embedded in Medical Facilities and Medical Devices. J. Med. Syst. 2019, 43, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Lazar, L. Neural Networks on Microsoft HoloLens 2. Bachelor’s Thesis, University of Stuttgart, Stuttgart, Germany, 2021. [Google Scholar]
- Doughty, M.; Singh, K.; Ghugre, N.R. Surgeon-assist-net: Towards context-aware head-mounted display-based augmented reality for surgical guidance. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021: 24th International Conference, Part IV 24, Strasbourg, France, 27 September–1 October 2021; Springer: Cham, Switzerland, 2021; pp. 667–677. [Google Scholar] [CrossRef]
- Doughty, M.; Ghugre, N.R. HMD-EgoPose: Head-mounted display-based egocentric marker-less tool and hand pose estimation for augmented surgical guidance. Int. J. Comput. Assist. Radiol. Surg. 2022, 14, 2253–2262. [Google Scholar] [CrossRef]
- Kim, A.; Kamalinejad, E.; Madal-Hellmuth, K.; Zhong, F. Deep Learning Based Face Recognition Application with Augmented Reality Devices. In Advances in Information and Communication; Springer International Publishing: Cham, Switzerland, 2020; Volume 21, pp. 836–841. [Google Scholar] [CrossRef]
- Bahri, H.; Krčmařík, D.; Kočí, J. Accurate object detection system on hololens using yolo algorithm. In Proceedings of the 2019 International Conference on Control, Artificial Intelligence, Robotics & Optimization (ICCAIRO), Athens, Greece, 8–10 December 2019; pp. 219–224. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, S.; Zhang, Q.; Cheng, Y.; Huang, J.; He, W. Assembly training system on HoloLens using embedded algorithm. In Proceedings of the Third International Symposium on Computer Engineering and Intelligent Communications (ISCEIC 2022), Xi’an, China, 16–18 September 2023; Ben, X., Ed.; International Society for Optics and Photonics. SPIE: Bellingham, WA, USA, 2023; Volume 12462. [Google Scholar] [CrossRef]
- Zhao, G.; Feng, P.; Zhang, J.; Yu, C.; Wang, J. Rapid offline detection and 3D annotation of assembly elements in the augmented assembly. Expert Syst. Appl. 2023, 222, 119839. [Google Scholar] [CrossRef]
- von Atzigen, M.; Liebmann, F.; Hoch, A.; Bauer, D.E.; Snedeker, J.G.; Farshad, M.; Fürnstahl, P. HoloYolo: A proof-of-concept study for marker-less surgical navigation of spinal rod implants with augmented reality and on-device machine learning. Int. J. Med Robot. Comput. Assist. Surg. 2021, 17, 1–10. [Google Scholar] [CrossRef]
- Zakaria, M.; Karaaslan, E.; Catbas, F.N. Advanced bridge visual inspection using real-time machine learning in edge devices. Adv. Bridge Eng. 2022, 3, 1–18. [Google Scholar] [CrossRef]
- Hamilton, M.A.; Beug, A.P.; Hamilton, H.J.; Norton, W.J. Augmented Reality Technology for People Living with Dementia and their Care Partners. In Proceedings of the ICVARS 2021: The 5th International Conference on Virtual and Augmented Reality Simulations, Melbourne, Australia, 20–22 March 2021; pp. 21–30. [Google Scholar] [CrossRef]
- Bohné, T.; Brokop, L.T.; Engel, J.N.; Pumplun, L. Subjective Decisions in Developing Augmented Intelligence. In Judgment in Predictive Analytics; Seifert, M., Ed.; Springer International Publishing: Cham, Switzerland, 2023; pp. 27–52. [Google Scholar] [CrossRef]
- Microsoft. Microsoft HoloLens vs Microsoft HoloLens 2. 2023. Available online: https://versus.com/en/microsoft-hololens-vs-microsoft-hololens-2#group_features (accessed on 3 June 2023).
- Pose-Díez-de-la Lastra, A.; Moreta-Martinez, R.; García-Sevilla, M.; García-Mato, D.; Calvo-Haro, J.A.; Mediavilla-Santos, L.; Pérez-Mañanes, R.; von Haxthausen, F.; Pascau, J. HoloLens 1 vs. HoloLens 2: Improvements in the New Model for Orthopedic Oncological Interventions. Sensors 2022, 22, 4915. [Google Scholar] [CrossRef]
- Microsoft. Windows Device Portal Overview. 2023. Available online: https://learn.microsoft.com/en-us/windows/uwp/debug-test-perf/device-portal (accessed on 3 June 2023).
- Ungureanu, D.; Bogo, F.; Galliani, S.; Sama, P.; Duan, X.; Meekhof, C.; Stühmer, J.; Cashman, T.J.; Tekina, B.; Schönberger, J.L.; et al. Hololens 2 research mode as a tool for computer vision research. arXiv 2020, arXiv:2008.11239. [Google Scholar]
- Guo, H.J.; Prabhakaran, B. HoloLens 2 Technical Evaluation as Mixed Reality Guide. arXiv 2022, arXiv:2207.09554. [Google Scholar]
- Hübner, P.; Clintworth, K.; Liu, Q.; Weinmann, M.; Wursthorn, S. Evaluation of HoloLens tracking and depth sensing for indoor mapping applications. Sensors 2020, 20, 1021. [Google Scholar] [CrossRef] [PubMed]
- Koop, M.M.; Rosenfeldt, A.B.; Owen, K.; Penko, A.L.; Streicher, M.C.; Albright, A.; Alberts, J.L. The Microsoft HoloLens 2 Provides Accurate Measures of Gait, Turning, and Functional Mobility in Healthy Adults. Sensors 2022, 22, 2009. [Google Scholar] [CrossRef] [PubMed]
- Linux. Onnx. 2019. Available online: https://lfaidata.foundation/projects/onnx/ (accessed on 3 July 2023).
- Microsoft. ONNX Concepts. Available online: https://onnx.ai/onnx/intro/concepts.html (accessed on 3 June 2023).
- Microsoft. ONNX Versions and Windows Builds. 2022. Available online: https://learn.microsoft.com/en-us/windows/ai/windows-ml/onnx-versions (accessed on 3 June 2023).
- Unity. Introduction to Barracuda. Available online: https://docs.unity3d.com/Packages/[email protected]/manual/index.html (accessed on 3 June 2023).
- Unity. Build and Deploy to the HoloLens. Available online: https://learn.microsoft.com/en-us/windows/mixed-reality/develop/unity/build-and-deploy-to-hololens (accessed on 3 June 2023).
- Unity. Supported Neural Architectures and Models. Available online: https://docs.unity.cn/Packages/[email protected]/manual/SupportedArchitectures.html (accessed on 3 June 2023).
- Unity. IWorker Interface: Core of the Engine. Available online: https://docs.unity3d.com/Packages/[email protected]/manual/Worker.html (accessed on 3 June 2023).
- Microsoft. Tutorial: Create a Windows Machine Learning UWP Application (C#). 2021. Available online: https://learn.microsoft.com/en-us/windows/ai/windows-ml/get-started-uwp (accessed on 3 June 2023).
- Microsoft. Using Visual Studio to Deploy and Debug. 2022. Available online: https://learn.microsoft.com/en-us/windows/mixed-reality/develop/advanced-concepts/using-visual-studio? (accessed on 3 June 2023).
- Microsoft. Select an Execution Device. 2021. Available online: https://learn.microsoft.com/en-us/windows/ai/windows-ml/tutorials/advanced-tutorial-execution-device (accessed on 3 June 2023).
- Microsoft. Stopwatch Class. Available online: https://learn.microsoft.com/en-us/dotnet/api/system.diagnostics.stopwatch?view=net-7.0 (accessed on 6 June 2023).
- Kapoor, S. LeNet-5. 2020. Available online: https://github.com/activatedgeek/LeNet-5 (accessed on 3 June 2023).
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Tong, H.; Papadimitriou, S.; Sun, J.; Yu, P.S.; Faloutsos, C. Colibri: Fast Mining of Large Static and Dynamic Graphs. In Proceedings of the KDD ’08: 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 686–694. [Google Scholar] [CrossRef]
- Twinanda, A.P.; Shehata, S.; Mutter, D.; Marescaux, J.; de Mathelin, M.; Padoy, N. EndoNet: A Deep Architecture for Recognition Tasks on Laparoscopic Videos. IEEE Trans. Med. Imaging 2017, 36, 86–97. [Google Scholar] [CrossRef] [PubMed]
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Chen, C.W. Tiny YOLOv2. 2021. Available online: https://github.com/onnx/models/tree/main/vision/object_detection_segmentation/tiny-yolov2 (accessed on 3 June 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Mills, C.J. Barracuda PoseNet Tutorial 2nd Edition. 2023. Available online: https://github.com/cj-mills/Barracuda-PoseNet-Tutorial (accessed on 3 June 2023).
- Ribard, A. Barracuda-U-2-NetTest. 2021. Available online: https://github.com/AlexRibard/Barracuda-U-2-NetTest (accessed on 3 June 2023).
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- D’Agostino, R.B. An omnibus test of normality for moderate and large sample sizes. Biometrika 1971, 58, 1–348. [Google Scholar] [CrossRef]
- Unity. Unity’s Beta Program for Creating Spatial Experiences. 2023. Available online: https://create.unity.com/spatial (accessed on 10 October 2023).
- ONNX Runtime Developers.Quantize ONNX Models. 2021. Available online: https://onnxruntime.ai/docs/performance/model-optimizations/quantization.html (accessed on 10 October 2023).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Paper | Application | Model | Model Task | API | Speed |
|---|---|---|---|---|---|
| Zakaria [35] | Infrastructure (Bridge inspection) | Yolov5 Unet | Object detection Semantic segmentation | - | - |
| Quin [32] | Manufacturing (Assembly) | Yolov5 | Object detection | WinML | 370 ms |
| Zao [33] | Manufacturing (Assembly) | Yolov4-Tiny | Object detection | - | 360 ms |
| Hamilton [36] | Medical (Daily Reminder system) | Yolov2-Tiny | Object detection | WinML | 1773 ms |
| von Atzigen [34] | Medical (Surgical navigation) | Yolov2-Tiny | Object detection | WinML | 900 ms |
| Doughty [29] | Medical (Surgical navigation) | HMD-EgoPose (EfficientNetB0 backbone) | Pose estimation | WinML | ≈1 s |
| Doughty [28] | Medical (Surgical navigation) | SurgeonAssist-Net (EfficientNet-Lite-B0 backbone) | Action recognition | WinML | 219 ms |
| Lazar [27] | Benchmark (APIs performances) | LeNet5 | Image classification | WinML TensorFlow.js Barracuda | − 3428 ms − 1035 ms − 183 ms |
| ID | Model Size (Mb) | # Params | # MACs | # Filters | Depth |
|---|---|---|---|---|---|
| 0.1 | 3024 | 212,860,928 | 112 | 1 | |
| 0.2 | 5400 | 364,380,160 | 8 | 10 | |
| 2.1 | 3618 | 263,323,648 | 8 | 100 | |
| 1.7 | 4522 | 361,627,648 | 1 | 500 |
| ID | Model Size (Mb) | # Params | # MACs | # Filters | Depth |
|---|---|---|---|---|---|
| 0.04 | 1 | 10 | |||
| 0.1 | 6 | 10 | |||
| 0.7 | 16 | 10 | |||
| 1.3 | 64 | 10 |
| Model Specifications | Inference Time (ms) | |||
|---|---|---|---|---|
| ID | # Filters | Depth | WinML | Barracuda |
| 112 | 1 | 182 ± 12 | 79 ± 8 | |
| 8 | 10 | 395 ± 9 | 192 ± 7 | |
| 8 | 100 | 1624 ± 26 | 345 ± 11 | |
| 1 | 500 | 1633 ± 60 | 1189 ± 18 | |
| Model Specifications | Inference Time (ms) | ||||
|---|---|---|---|---|---|
| ID | # Params | # MACs | # Filters | WinML | Barracuda |
| 1 | 52 ± 4 | 33 ± 4 | |||
| 6 | 305 ± 14 | 153 ± 6 | |||
| 16 | 651 ± 17 | 786 ± 9 | |||
| 64 | 9661 ± 426 | 2933 ± 52 | |||
| Model Specifications | Inference Time (ms) | ||||||
|---|---|---|---|---|---|---|---|
| ID | Size (Mb) | # Params | # MACs | Depth | WinML | Barracuda | Lit. WinML |
| Lenet-5 [27] | 0.25 | 5 | 5 ± 2 | 5 ± 8 | - | ||
| SurgeonAssist-Net [28] | 15 | 50 | 465 ± 17 | NA | 219 | ||
| EgoPose [29] | 16 | 1194 | 1164 ± 43 | 384 ± 14 | ≈1000 | ||
| Yolov2-Tiny [34,36] | 62 | 25 | 1330 ± 56 | 630 ± 32 | 900 [34] 1773 ± 34 [36] | ||
| Resnet50 [63] | 90 | 98 | 1842 ± 64 | 701 ± 14 | - | ||
| Unet [64] | 4 | 259 | 4707 ± 162 | 3023 ± 42 | - | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaccardi, S.; Frantz, T.; Beckwée, D.; Swinnen, E.; Jansen, B. On-Device Execution of Deep Learning Models on HoloLens2 for Real-Time Augmented Reality Medical Applications. Sensors 2023, 23, 8698. https://doi.org/10.3390/s23218698
Zaccardi S, Frantz T, Beckwée D, Swinnen E, Jansen B. On-Device Execution of Deep Learning Models on HoloLens2 for Real-Time Augmented Reality Medical Applications. Sensors. 2023; 23(21):8698. https://doi.org/10.3390/s23218698
Chicago/Turabian StyleZaccardi, Silvia, Taylor Frantz, David Beckwée, Eva Swinnen, and Bart Jansen. 2023. "On-Device Execution of Deep Learning Models on HoloLens2 for Real-Time Augmented Reality Medical Applications" Sensors 23, no. 21: 8698. https://doi.org/10.3390/s23218698