Abstract
Alzheimer’s disease (AD), a neuropsychiatric disorder, continually arises in the elderly. To date, no targeted medications have been developed for AD. Early and fast diagnosis of AD plays a pivotal role in identifying potential AD patients, enabling timely medical interventions, and mitigating disease progression. Computer-aided diagnosis (CAD) becomes possible with the burgeoning of deep learning. However, the existing CAD models for processing 3D Alzheimer’s disease images usually have the problems of slow convergence, disappearance of gradient, and falling into local optimum. This makes the training of 3D diagnosis models need a lot of time, and the accuracy is often poor. In this paper, a novel 3D aggregated residual network with accelerated mirror descent optimization is proposed for diagnosing AD. First, a novel unbiased subgradient accelerated mirror descent (SAMD) optimization algorithm is proposed to speed up diagnosis network training. By optimizing the nonlinear projection process, our proposed algorithm can avoid the occurrence of the local optimum in the non-Euclidean distance metric. The most notable aspect is that, to the best of our knowledge, this is the pioneering attempt to optimize the AD diagnosis training process by improving the optimization algorithm. Then, we provide a rigorous proof of the SAMD’s convergence, and the convergence of SAMD is better than any existing gradient descent algorithms. Finally, we use our proposed SAMD algorithm to train our proposed 3D aggregated residual network architecture (ARCNN). We employed the ADNI dataset to train ARCNN diagnostic models separately for the AD vs. NC task and the sMCI vs. pMCI task, followed by testing to evaluate the disease diagnostic outcomes. The results reveal that the accuracy can be improved in diagnosing AD, and the training speed can be accelerated. Our proposed method achieves 95.4% accuracy in AD diagnosis and 79.9% accuracy in MCI diagnosis; the best results contrasted with several state-of-the-art diagnosis methods. In addition, our proposed SAMD algorithm can save about 19% of the convergence time on average in the AD diagnosis model compared with the gradient descent algorithms, which is very momentous in clinic.
1. Introduction
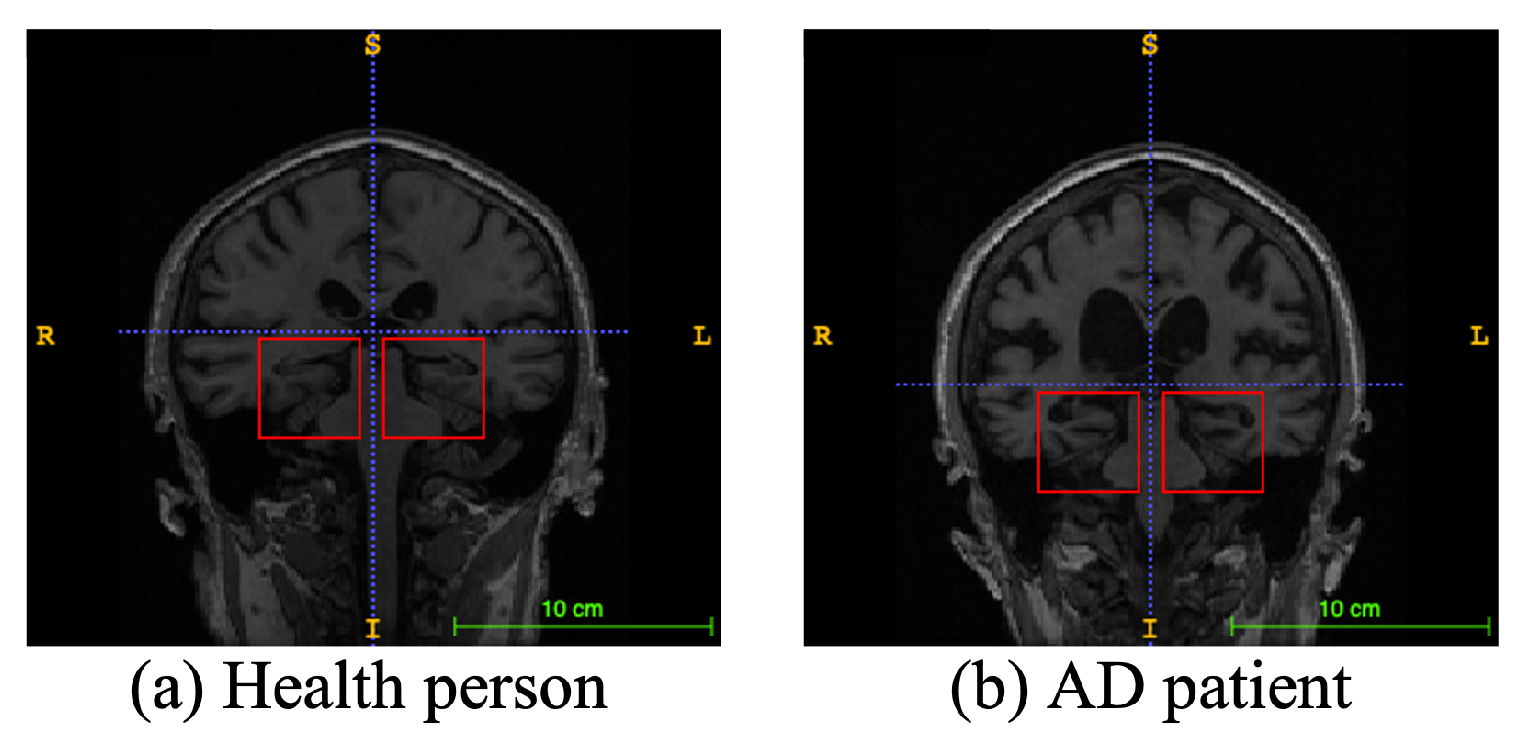
Alzheimer’s disease (AD), a progressive neurodegenerative disease, is the most typical condition of dementia, mainly in the elderly. It affects people’s memory function, thinking ability, and behavior capability. With the growth of modern life expectancy, the aging phenomenon is aggravating [1]. So, the prevalence of AD is further rising. According to the latest research, patients suffering from AD will reach 74.7 million by 2030 [2], with an average of one person who has AD every three seconds. At present, the etiology of AD is still unclear in medicine, and there is no effective therapeutic method to prevent the incidence and development of AD. Most of the new cases are in low- and middle-income countries. The substantial medical and nursing costs will cause a significant burden to society [3]. Patients with AD usually have organic brain changes, such as narrowing of the gyrus and widening of the sulcus, and especially atrophy of brain tissue, such as the hippocampus and many lobes [4]. Early diagnosis of AD usually used neuroimaging data [5]. Many imaging studies [6] have demonstrated that Alzheimer’s patients have different degrees of hippocampal volume atrophy, the corresponding lateral ventricle enlargement, and temporal angle enlargement phenomena, which gradually extend to the cingulate gyrus and neocortical junction with time. Figure 1 shows an example of different types of magnetic resonance images. In this figure, the left side is the hippocampus of a normal human brain, and the right side is the pathological hippocampus of an AD patient. We can see the atrophy of the hippocampus clearly. These abnormalities, easily obtained by craniocerebral MRI (magnetic resonance imaging), supply essential information for clinicians to diagnose AD.
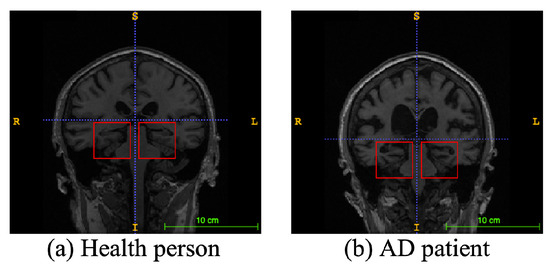
Figure 1.
An example of different types of magnetic resonance images. The left image is a healthy person, and the right one is an Alzheimer’s disease patient. The red boxes represent hippocampi.
Moreover, MCI (mild cognitive impairment), a cognitive impairment state between the change in average random cognitive ability and dementia state, has a high probability of eventually becoming AD. MCI is split into two subtypes: sMCI (stable MCI) and pMCI (progress MCI). Patients with sMCI can prevent the development of the disease through drugs and medical intervention. However, patients with pMCI have a high probability of it turning into AD within three years [7]. If AD can be diagnosed early, clinicians can find the probable dementia of patients as soon as possible, carry out drug and medical intervention, and prevent the deterioration of the disease.
The rapid development of neural network technology makes computer-aided AD diagnosis possible. More and more researchers [8,9,10] think about how to use the MRI data of patients for AD diagnosis. The human brain has many functional areas, so the structure of MRI is very complex. When neural networks extract features from complex images, the optimization process is prone to the problems of vanishing gradient [11] and local optimization [12]. Moreover, the craniocerebral MRI data are three-dimensional matrix data. In the process of feature extraction of 3D MRI using neural network models, the training speed of the models is slow, and the accuracy of the diagnosis models is low.
When constructing the 3D MRI CAD model of AD, because data are highly complex, the neural network model often has slow speed in the feature extraction process. At the same time, due to the problems of vanishing gradient [11] and local optimal solutions [12] in the existing optimization algorithms when dealing with complex medical image data, the accuracy of prediction is often not satisfactory. Thus, accelerating the training speed, avoiding the disappearance of partial derivatives in the network training process, and improving accuracy have become challenges of diagnosing AD.
A novel 3D aggregated residual network with subgradient accelerated mirror descent optimization is proposed to tackle the aforementioned challenges. The main contributions are as follows:
- •
- We propose SAMD, an unbiased subgradient accelerated mirror descent optimization algorithm, designed to expedite the training of diagnostic networks. By optimizing and improving the mirror descent algorithm [13], SAMD avoids the optimization problem falling into local optimum under the non-Euclidean distance metric. SAMD achieves accelerated convergence by introducing the step factor and the deviation correction factor to the mirror descent algorithm. Furthermore, the incorporation of a subgradient unbiased estimation mechanism effectively mitigates the issue of vanishing gradient.
- •
- We propose a 3D aggregated residual network (ARCNN) for feature extraction from craniocerebral MRI scans to diagnose AD. The ARCNN leverages our proposed aggregation residual blocks (ARBs) to capture global information within the input data, enhancing its capability to recognize complex patterns and features while improving model stability. Experimental results on the ADNI dataset highlight the superior performance of the diagnostic model trained using the SAMD algorithm in terms of accuracy and efficiency compared to other state-of-the-art methods.
- •
- Our proposed SAMD algorithm achieves a convergence rate that is a square order faster than gradient descent algorithms such as Adam and SGD. Experimental results further validate the efficiency of the SAMD algorithm, showcasing an average time-saving of approximately 19% compared to gradient descent algorithms in the training phase. The SAMD algorithm accelerates AD diagnosis model training, overcoming real-world healthcare computational constraints, ensuring local data security, enabling continuous updates, and enhancing diagnosis efficiency while complying with privacy regulations and evolving medical knowledge.
2. Related Work
The vital technology of computer-aided AD diagnosis is to extract neuroimaging features from patients’ MRIs. Generally, the existing AD diagnosis models are separated into four types of feature extraction techniques (i.e., voxel, patch, ROI, and whole-image).
Methods based on voxels [14] attempt to recognize AD-related classification microstructure. Usually, the feature dimension can reach the order of millions, and the number of images used for model training is relatively small (such as dozens). Those make the method face the risk of overfitting.
Comparatively, methods based on the region [15] obtained quantitative features by region segmentation algorithm and then constructed a classifier used to identify patients in a normal control group. Intuitively, these methods only attended to craniocerebral regions defined by experience. Therefore, they may not contain all the possible pathological parts in the cerebrum. Ju et al. [16] used fMRI data to diagnose AD. A brain was divided into 90 regions. According to the Pearson correlation coefficient, the connection of 90 regions is calculated to form a relation matrix, which is input to the network for diagnosis.
In order to obtain the changes of local brain regions, a patch-based method [17] used the intermediate scale of feature representation (between the voxel level and region level) to construct a classifier. However, a key question is determining the number, place, and proportions of patches in MR images. Therefore, Lian et al. [10] proposed a CNN (convolutional neural network) to find the voxels with high contrast through statistical analysis and comparison of ordinary images and AD images, and then extracted patches to improve the diagnosis effect.
Wang et al. [18] firstly input 3D MRI into DenseNet and then applied ensemble learning for diagnosis. Cui et al. [19] proposed a diagnostic framework based on CNN and RNN. This method can use the imaging data of different time points. Fang et al. [20] designed a neural network framework, taking advantage of 3D CNN and FSBI-LSTM. It was regarded as a feature extraction to extract the hidden spatial features to promote performance further. Ordinary diagnosis networks used convolutional layers to extract features (such as Resnet [21], Unet [22], etc.), followed by fully connected layers for diagnosis. Because the fully connected layer only processes the one-dimensional information, it resulted in information loss. Fang et al. [20] used bidirectional LSTM instead of fully connected layers to capture spatial information and improve the diagnosis effect. Pan et al. [23] used GAN to generate missing multimodal data for diagnosis. Precisely, the traditional multimodal diagnostic methods discard the subjects without PET (position emission computed tomography) data to solve the problem of modal missing. However, this strategy may significantly reduce training data, thus diminishing the diagnostic performance.
Ji et al. [24] used a deep CNN to diagnose AD, and an effective method was used to train the model using an unbalanced small dataset. Recently, Zhang et al. [25] proposed a diagnostic model with embedding feature selection and feature fusion. They proposed a norm regularization-based optimization algorithm and theoretically demonstrated that it can converge to a global optimum. Their proposed method achieved 84% accuracy in diagnosing AD.
In the existing Alzheimer’s diagnosis models, no matter which feature extraction methods are used for modeling, the optimization algorithms based on gradient descent are used for model training. These training algorithms have some problems, such as local optimization, vanishing gradient, and slow training speed. Therefore, we propose a novel unbiased subgradient accelerated mirror descent optimization algorithm and apply it to our 3D aggregated residual network diagnosis model. The best we can tell is that it is the first time to improve the optimization algorithm of the model in Alzheimer’s diagnosis, which improves the training speed and diagnostic accuracy of the model.
3. Materials and Methods
3.1. Datasets
The data used in our paper were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI). Parameters of these MR images are listed in Table 1. 348 subjects are separated into 4 categories, including AD, NC (normal control), sMCI, and pMCI. In total, the ADNI dataset contains 78 AD, 100 NC, 117 sMCI, and 53 pMCI subjects.

Table 1.
Parameters of our acquired dataset.
3.2. Proposed Method
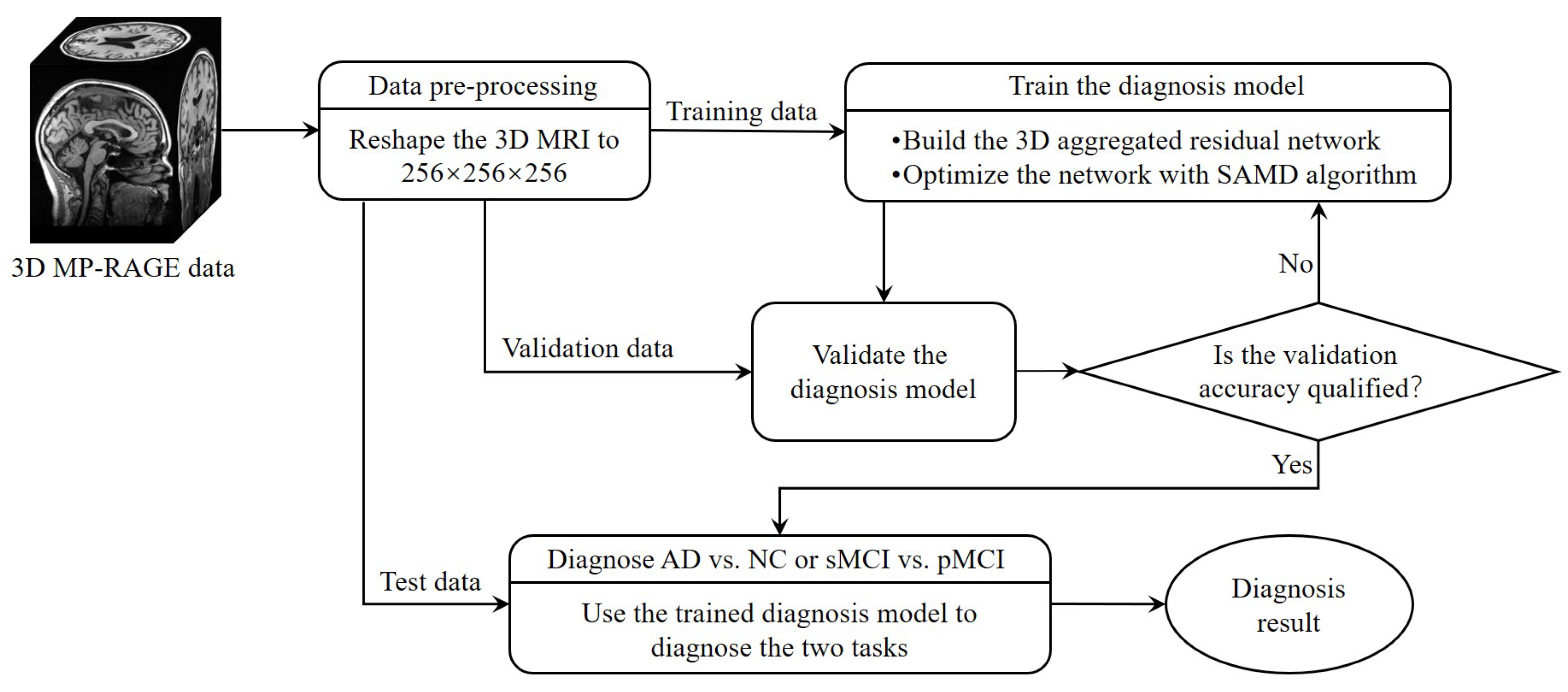
The whole framework of our proposed diagnostic model is shown in Figure 2. Before training the diagnosis network, data preprocessing (Section 3.2.1) was performed before training. Then, we proposed a 3D aggregated residual diagnosis network (Section 3.2.2) for feature extracting. Our proposed unbiased subgradient accelerated mirror descent optimization algorithm was used in the training process to obtain a faster training speed (Section 3.2.3). Our method addresses two binary classification tasks: diagnosing AD vs. NC and distinguishing sMCI from pMCI. We chose this approach due to clinical relevance; the AD vs. NC task aids early AD diagnosis, while sMCI vs. pMCI classifies cognitive impairment degree. It aligns with disease progression trends, avoiding inconsistencies in a combined model and ensuring meaningful diagnostic insights.
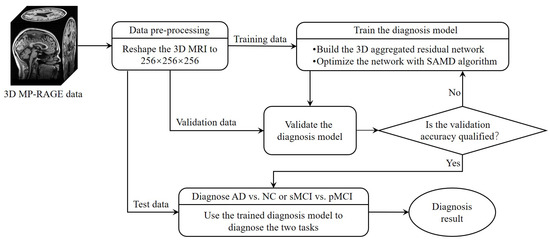
Figure 2.
The framework of our proposed diagnostic model.
3.2.1. Data Preprocessing
Our dataset comprises numerous subjects, each of which encompasses multiple MR images captured at various time points. We divide the data classified by subjects into MR images one by one and complete all the information of MR images at the same time. In this way, our dataset becomes image-based. The ADNI dataset contains 220 AD, 478 NC, 448 sMCI, and 328 pMCI. By interpolating the original data, every 3D MR image is reshaped into a data cube, which is suitable as an input of our proposed 3D aggregated residual network.
3.2.2. Three-Dimensional Aggregated Residual Diagnosis Network
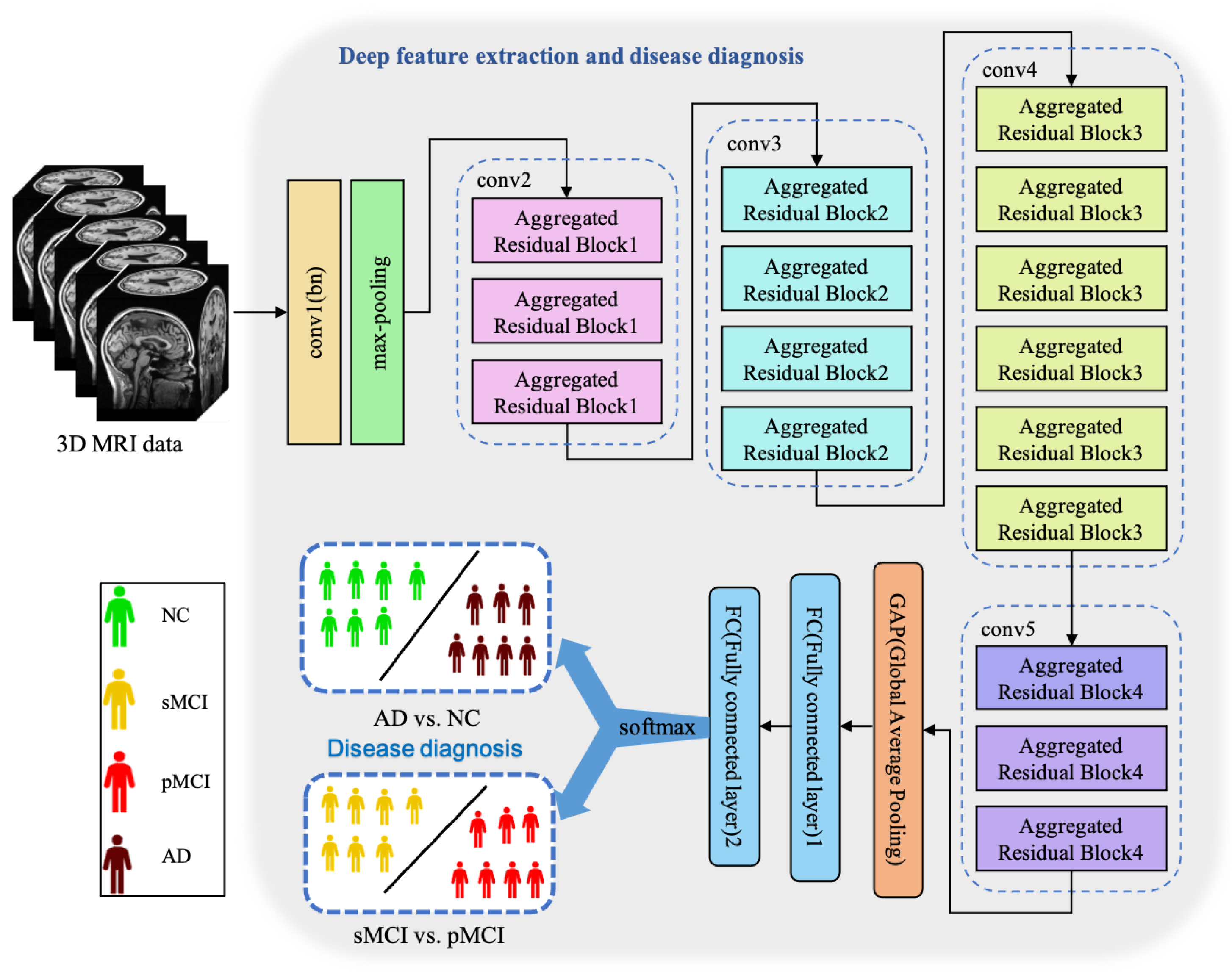
Essentially, CNN is a feature extractor of layer-by-layer learning mode, which can mine different features from input images. Due to the specific structure of MRI data, specific neural network architectures are required to adequately capture spatial dependencies and features in healthy and ill brains. Because the 3D MRI data of AD patients have large amounts of information, they are often used to deepen or widen the network to enhance the accuracy of feature extraction. The design is conducive to extracting deeper features from MRI, to obtain higher accuracy. However, with the increase in hyperparameters (such as channels, filter size, etc.), the network training cost and design difficulty will greatly increase. We propose a 3D aggregated residual network architecture to extract features from MR images, shown in Figure 3.
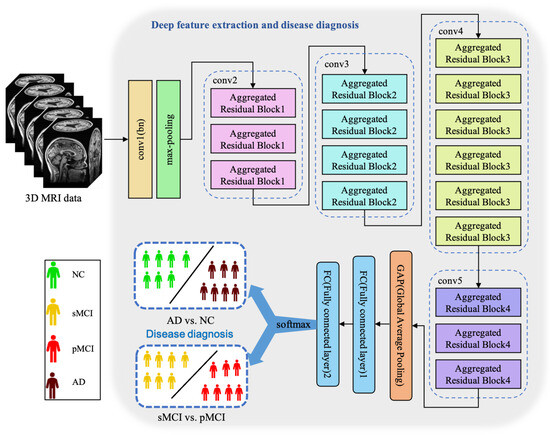
Figure 3.
The architecture of our proposed ARCNN. This model achieves two diagnosis tasks so that it needs to be trained respectively.
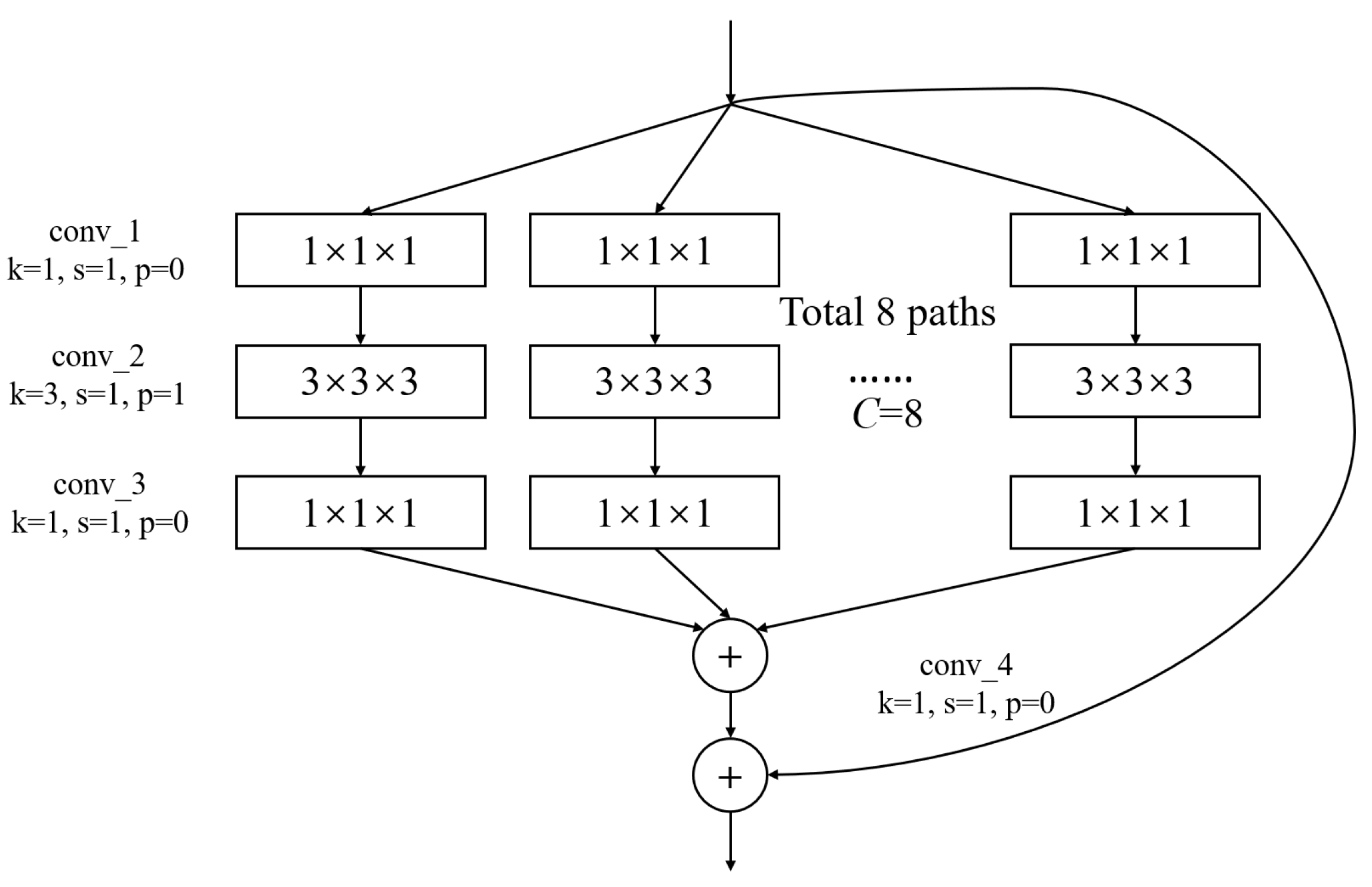
In Figure 3, conv1(bn) denotes a convolutional layer with batch normalization applied. Conv2-conv5 are aggregated residual blocks (ARBs) with a unique cardinality mechanism to realize the sharing of parameters in the network model, shown in Figure 4. ARBs are designed to aggregate features from multiple preceding layers. This helps the network capture both low-level and high-level information effectively, enabling the model to learn intricate patterns and representations. Using ARB structures can increase the model’s accuracy without significantly increasing the magnitude of parameters. The hyperparameter C represents the number of branches in the aggregated feature extraction convolutional layers. In accordance with the data characteristics and experimental conditions, we set C to 8. GAP stands for global average pooling, which calculates the average of feature maps, reducing them to scalar values. This reduces data dimensionality, leading to fewer parameters in subsequent fully connected layers and lower computational overhead. As GAP computes the average over all positions, it is spatially invariant, enhancing the model’s ability to handle features at different positions. FC represents the fully connected layer. Table 2 displays details of the diagnostic network structure, including kernels, number of neurons, size of input, and output vectors at each layer. ARCNN is designed to extract neuroimaging features from MRIs, and the network can acquire subtle changes of AD patients’ brain organs to give better diagnosis results.
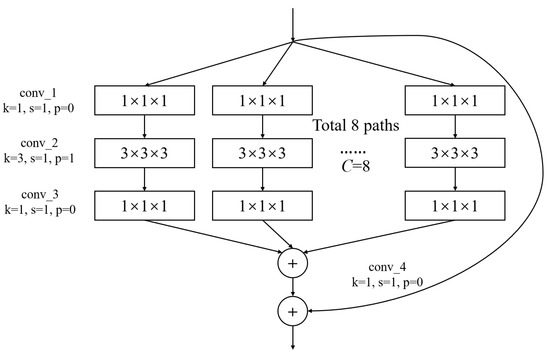
Figure 4.
The architecture of ARB. k represents the convolutional kernel size, which is a small matrix used for feature extraction in convolutional operations. p represents the padding size, which is the technique of adding extra pixels around the input image before convolution to control the output size. s represents the stride, which determines the step size at which the kernel moves across the input data.
Table 2.
The topology of our diagnosis network.
3.2.3. Accelerated Mirror Descent Optimization
Most diagnostic models of AD are usually 2D, and the extracted brain spatial structure information is insufficient. Therefore, researchers consider using a 3D model for feature extraction. Three-dimensional MRI data contain more features of brain organs, so the training speed of the 3D neural network model is slow. Moreover, training time is still a problem that confines the development of neural network models, and more efficient methods are always sought after. Aiming to accelerate the training speed of the 3D Alzheimer’s disease diagnostic model, a novel accelerated mirror descent algorithm is proposed to decrease training time. This subsection will introduce the proposed unbiased subgradient accelerated mirror descent algorithm (SAMD). Before introducing our proposed algorithm, a table is listed to contain the symbolic representations and definitions used in this subsection, as shown in Table 3.
Table 3.
A notation of symbols and definitions.
Preliminary
Mathematically, Bregman divergence [26] is defined as a method similar to distance measurement, which extends the square of Euclidean distance to a kind of distance. The distance has no trigonometric inequality and symmetry. Bregman divergence , with regard to the function , is defined as follows:
where is the scalar product of a and b. is a distance generation function.
Assume that is a strong convex function. Then we have the following inequality [27]:
where is a strong convex coefficient.
According to the knowledge of convex optimization, the Bregman divergence has the following property:
SAMD Optimization Algorithm
The traditional gradient descent algorithm is slow when training data are complex. In the process of optimizing an objective function, the gradient descent algorithm is apt to converge to the local minimum [28]. Moreover, the gradient depends on derivatives, which is imprecise due to the nonsmoothness of the objective function. In addition, numerical schemes need to be used to solve them due to nonsmooth and unknown gradient flows. These gradient flows must have higher-order derivatives than the second-order derivatives. Meanwhile, implementing gradient flow is not easy because numerical artifacts will occur when the derivative is higher than second-order, but the gradient is usually like this.
The optimization objective of the mirror descent algorithm using Bregman divergence as the mirror map is [13]:
where L is a Lipschitz constant. x indicates the parameters to be trained and is the search space of x.
However, for the two items and , there is only one parameter L in the projection calculation. In the original mirror descent algorithm (see Equation (4)), constant L (called Lipschitz constant) is put forward to regulate the proportion of and . L is preset as a hyperparameter when the mirror descent iteration is performed. In the iterative change process, the algorithm cannot dynamically adjust the influence of and on the iterative results according to the iterative steps. This makes the mirror descent algorithm look a little inflexible. Moreover, the single parameter will make the algorithm oscillate in the iterative process, resulting in the poor effect of the optimization algorithm. So, we use the idea of momentum, which introduces the step factor and the deviation correction factor to dynamically adjust the change speed in the iterative process of the algorithm so that the change of the process tends to be more stable. In this paper, the optimization objective is changed as:
Among them, is used to control the change of , and is used to control the change of . According to the projection calculation process of the mirror descent algorithm, with iterations, the weights of and change, which can accelerate the speed of the optimization algorithm to the optimal solution to a certain extent. In consideration of the above trends and related knowledge, we set and . changes with the number of iterations, and the change rate is greater than .
The mirror descent algorithm is effective when can be calculated by a numerical calculation algorithm. However, when the objective function is nonsmooth or the derivative does not exist, can not be calculated. At this point, the gradient descent algorithms will not work. Therefore, we use the subgradient instead of traditional gradient in this paper. The subgradient has good performance in solving nondifferentiable convex optimization problems. The subgradients of function can be regarded as a cluster of supported hyperplanes, represented by . Furthermore, the unbiased estimation of the subgradients is used to replace the gradient so that the results of the numerical analysis are unique, unbiased, and bounded. To prove this point, we give Theorem 1.
Theorem 1.
Given an objective function , for any , there exists a real number subject to .
Proof.
is a finite function in a finite set. That is, it is uniformly bounded. Therefore, the unbiased estimation of subgradients is also bounded. The mathematical expectation of a bounded function is bounded. Obviously, is a bounded function. So, , and there exists a real number subject to . □
Based on some knowledge of mathematical analysis, we can prove Theorem 1. Theorem 1 shows that when we calculate the unbiased estimate of the subgradient of , the result is bounded. Hence, can avoid the vanishing gradient problem. can be calculated by the following equation:
where is the sampling of the subgradient hyperplane by at . By the following equation, the gradient of can be replaced by . This can avoid the vanishing gradient problem.
Finally, the iterative weighted average method is used to control the objective function change further so that the algorithm can achieve the optimal solution faster. We define as the weighted average value in the iterative step. It can be calculated by the following equation:
where is the weighted average value in the previous step and is calculated by Equation (5). is a dynamically adjusted parameter, which used to adjust the weight between and in different iteration steps. is determined by accumulating the reciprocal of inner product term weight of the current step and the previous step. The accumulation of the reciprocal of inner product term weight at step t is represented by , and the calculation method [29] is:
This setting can make the iteration step span of each step of the algorithm less large, and can achieve the optimal solution more accurately.
The approach is summarized in Algorithm 1.
Algorithm 1 shows our proposed stochastic unbiased subgradient accelerated mirror descent algorithm. Line 1 gives the initial of the whole algorithm. Lines 3–4 calculate and , which are put forward to dynamically regulate the impact of and on the iterative equation (see Line 6). Line 5 calculates our proposed unbiased subgradient method. Lines 7–8 show our proposed iterative weighted average method. By using this method, our proposed SAMD algorithm can converge faster and avoid the error caused by too large a step size. Lines 9–12 are used to evaluate whether the SAMD algorithm fulfills the convergence situation. Through iterations, our proposed SAMD algorithm can train the diagnostic network until it reaches the optimal condition. Then, the convergence of our proposed SAMD will be analyzed below.
| Algorithm 1 A stochastic unbiased subgradient accelerated mirror descent algorithm |
| Input: Loss function |
| Output: The optimization result |
| 1: Initial: , obtain by grid search |
| 2: while do |
| 3: Calculate |
| 4: Calculate |
| 5: Calculate |
| 6: Set by |
| 7: Calculate , and |
| 8: Set by |
| 9: if then |
| 10: Let |
| 11: break |
| 12: end if |
| 13: end while |
| 14: return . |
Convergence of SAMD
The following lemma can be obtained according to the properties of strongly convex functions and Bregman divergence constructed by Bregman function.
Lemma 1.
, we have:
where constrained set Ω is a closed convex set.
Proof.
According to the definition of Bregman divergence (see in Equation (1)), the following three equations can be deduced:
So, we have . □
This lemma is proved by the property of Bregman divergence and is used to obtain the convergence of the SAMD algorithm. Based on some knowledge of mathematical analysis, we can obtain Lemma 2.
To prove the convergence of the unbiased subgradient accelerated mirror descent algorithm, the following lemma can be deduced:
Lemma 2.
When , for any , we have the follwing inequality:
where is a sigma-field, i.e., , . Especially, .
Proof.
From the first-order necessary condition, we can obtain
Then, it can be acquired that
From Lemma 1, it can be concluded that
The above inequalities are sorted out:
By using the Fenchel inequality, Equation (23) is transformed to
The above equation is transformed:
According to Algorithm 1, there has , so the value range of is . Then, we take conditional expectations on :
□
From Lemma 2, we can deduce the following theorem to converge our proposed unbiased subgradient accelerated mirror descent algorithm.
Theorem 2.
For an optimization question , where is a strong convex function, is the optimal solution obtained by the iterative algorithm, and is the optimal solution, we have
Proof.
In Lemma 2, let , and we can obtain
By the strong convexity of , we can obtain
Take Equation (30) into Equation (29). Divide both sides of the inequality by and calculate the total expectation:
Then, we have
When the algorithm iterates to , we can come to the following conclusion:
□
According to Theorem 2, our proposed SAMD algorithm can converge at , a square order faster than the gradient descent algorithms (such as Adam and SGD (stochastic gradient descent), which have convergence). It is proved theoretically that the SAMD algorithm proposed in our paper can accelerate the convergence of the training process of the diagnostic network. At the same time, through the relevant description and theorem-proof of the algorithm, it can be obtained that the SAMD algorithm can avoid the problems of vanishing gradient and local optimal solution.
4. Experiments and Discussion
We validate our proposed model on the ADNI dataset. In Section 4.1, we describe some settings and performance measures. Section 4.2, Section 4.3, Section 4.4 and Section 4.5 verify the performance of our proposed model.
4.1. Experimental Settings
Our proposed model is verified on both AD vs. NC task and sMCI vs. pMCI task. The hardware we utilized consisted of an Intel(R) Core(R) i9-9900K CPU, operating at 3.60 GHz with 16 cores, 16 GB of RAM, a storage setup comprising a 256 GB SSD and a 2 TB SATA drive, along with an NVIDIA RTX 2080 Ti GPU equipped with 11 GB of dedicated memory. This configuration provided the essential computational resources for our experiments.
To assess the performance of our proposed model, we divided the dataset into training, validation, and testing sets. For each class of data, we employed a split ratio of 7:2:1 for these three sets. The training set, comprising 70% of the data, was used for model training, during which the model learned to diagnose diseases by recognizing the features and labels of the data. The validation set, consisting of 20% of the data, played a crucial role in monitoring the model’s performance during training and tuning hyperparameters, aiding in preventing overfitting. The remaining 10% of the data served as the testing set, used to evaluate the model’s ultimate performance. Importantly, the testing set contained data that the model had not previously encountered, ensuring the objectivity of the evaluation. Furthermore, to enhance the evaluation of the model’s performance and generalization capabilities, we ensured that images of the same subject do not appear in more than one of the training, validation, and test sets during the dataset partitioning process.
More specifically, four metrics, namely accuracy (ACC), sensitivity (SEN), specificity (SPE), and area under the curve (AUC, obtained by summing the area under the ROC curve), are used to evaluate our proposed model’s diagnostic performance, which are the most commonly occurring in bioinformatics literature [30,31].
4.2. Compared with Other Optimizers
To evaluate the performance of the SAMD optimizer, we train our model and then test on ADNI in the two tasks of diagnosis. The results of SAMD are compared with other mainstream optimization methods by using the same diagnostic networks. Hence, Adam and SGD are chosen as two baselines. Adam, a widely used method in training neural networks, has proved to be better than many gradient methods. SGD is a well-known convex optimization method. Table 4 presents the diagnostic performance of our algorithm in two diagnostic tasks, as compared to other methods, on the testing datasets.
Table 4.
Diagnostic performance of two tasks in ADNI dataset.
Table 4 shows that the proposed SAMD method has achieved excellent performance in most evaluation indicators. Primarily, our model can diagnose AD with 95.4% accuracy. This better performance is due to the proposed SAMD method being an optimizer based on mirror descent. The proposed method avoids the local optimization and the smoothness limitation of the cost function by constructing the optimization problem in the dual space. Therefore, it can reach the optimal value of the model more accurately. These experimental results also indicate that this model is still effective when the MRI to be diagnosed has different parameters (such as TE, TR) or the distribution of patients is inhomogeneous.
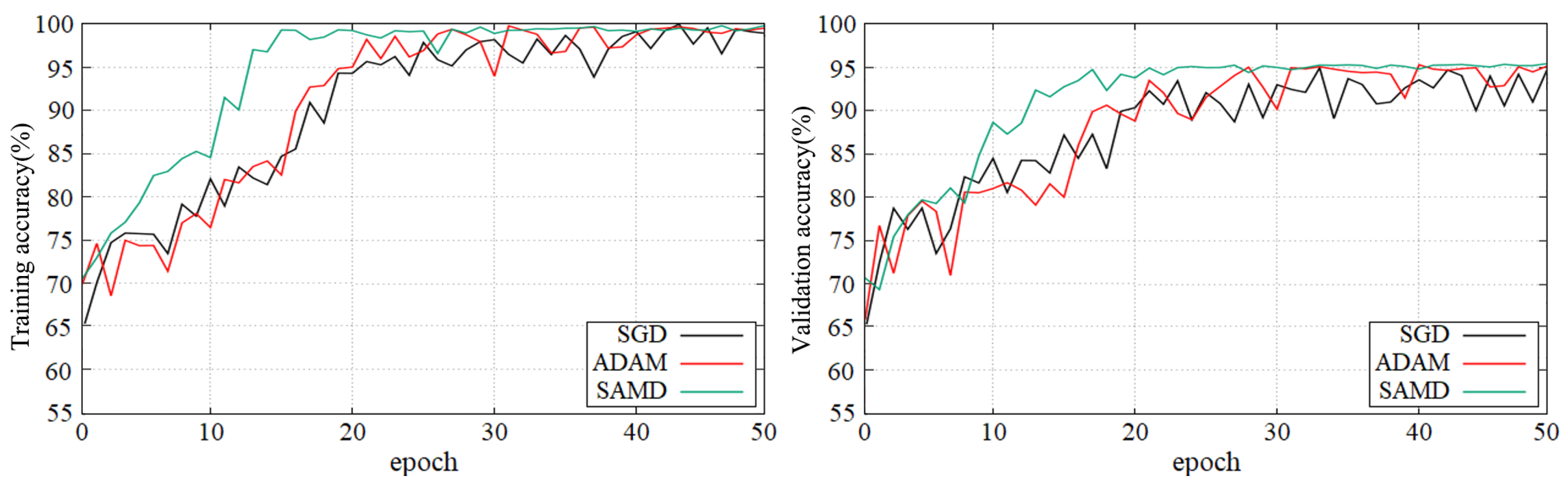
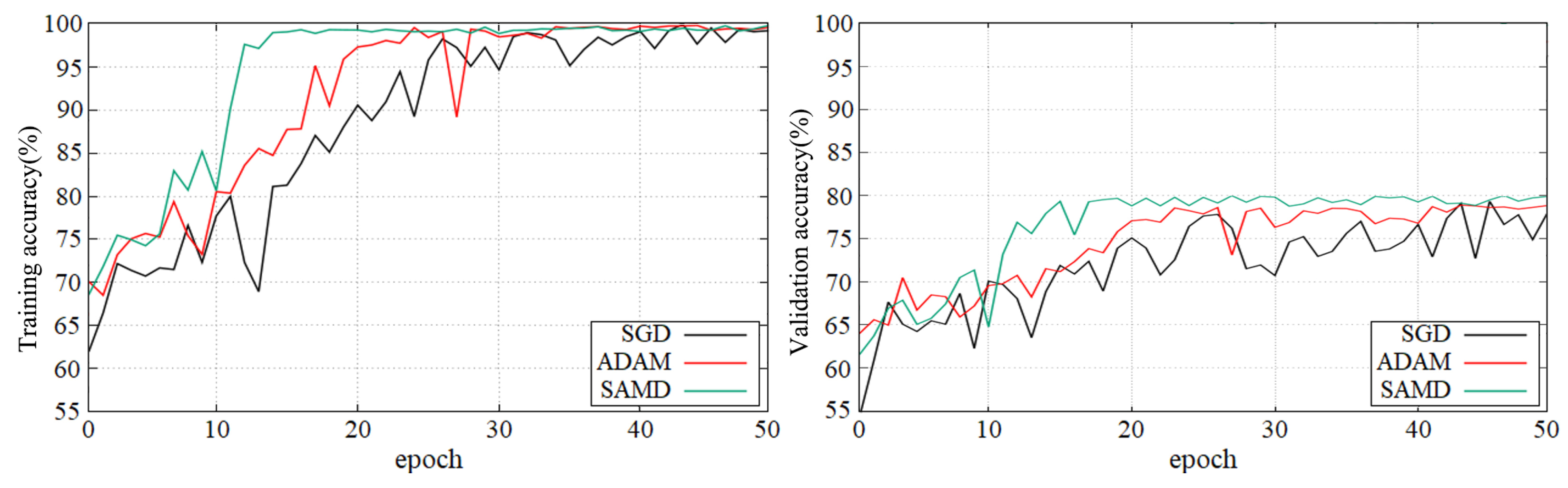
Figure 5 and Figure 6 show the training and validation accuracy of different epochs in two diagnostic tasks. We can obtain that all models are trained to the optimal state from these figures. It is worth noting that the network architecture which used our proposed SAMD optimizer can achieve the optimal state in fewer epochs. That is, our proposed method has a faster convergence speed.
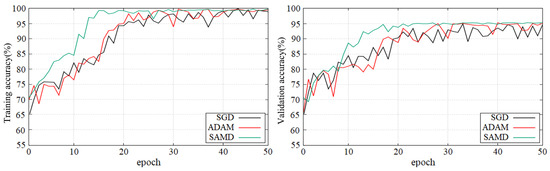
Figure 5.
Training and validation accuracy with epochs in AD vs. NC diagnostic task by using ADNI dataset.
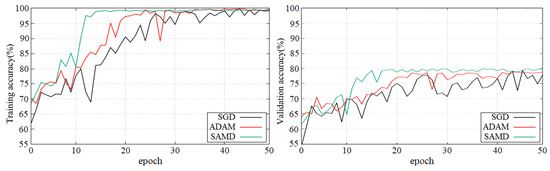
Figure 6.
Training and validation accuracy with epochs in sMCI vs. pMCI diagnostic task by using ADNI dataset.
As shown in these two plots, our proposed SAMD method can achieve higher accuracy in a shorter time. Our proposed method, SAMD, can converge faster than other algorithms. Moreover, the model trained by SAMD can achieve higher accuracy eventually. According to the experimental results, we can believe that our proposed SAMD algorithm is effective and efficient in optimizing our proposed AD diagnostic network.
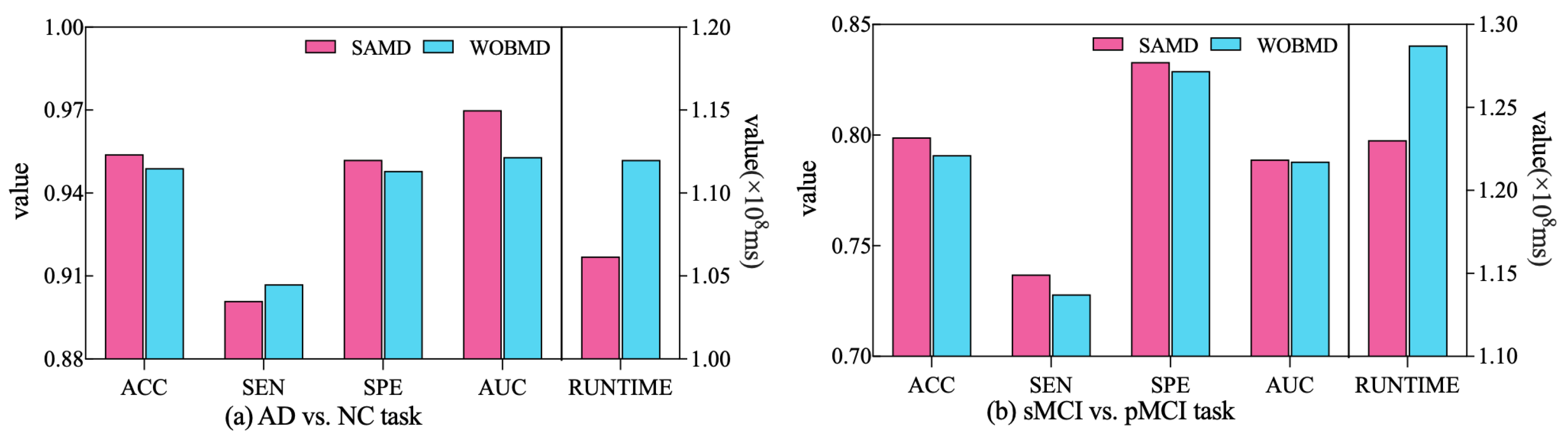
In order to better demonstrate the efficacy of the proposed adjustment factors in our study, we conducted a comparative experiment. Specifically, we established a control group (referred to as WOBMD) where we set in SAMD to 1 (i.e., without considering ). We applied WOBMD to train and optimize our diagnostic model ARCNN, and subsequently compared the diagnostic outcomes and runtime on both tasks with the results obtained using SAMD, as illustrated in Figure 7. The experimental results reveal that our SAMD algorithm, featuring two adjustment factors, outperforms the WOBMD algorithm, which utilizes only a single adjustment factor. This observation underscores the superiority and innovativeness of our proposed algorithm.
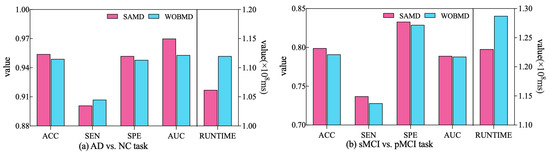
Figure 7.
Comparative performance of SAMD and WOBMD.
4.3. Performance of Diagnostic Network
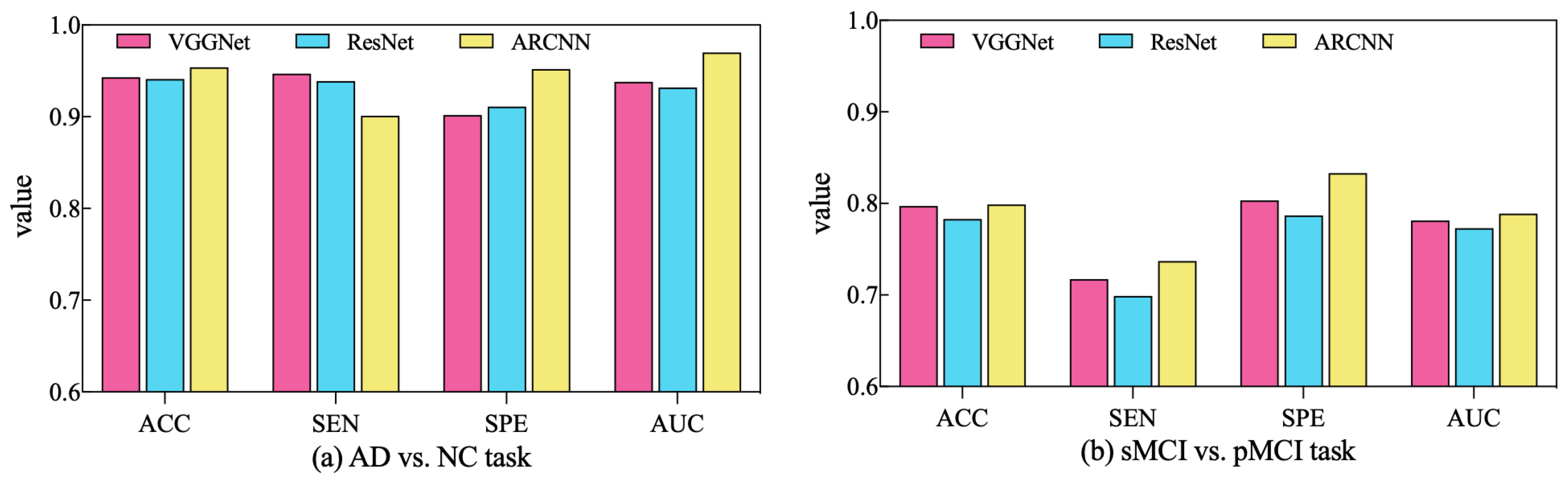
In order to assess the performance of the SAMD algorithm when optimizing different diagnostic networks, a series of comparative experiments were conducted. Specifically, two widely employed CNN-based networks in the AD diagnosis field, VGGNet [32] and ResNet [33], were selected for evaluation. SAMD was employed as the optimizer for training and optimizing these two networks on two different diagnostic tasks. The resulting diagnostic outcomes are presented in Figure 8.
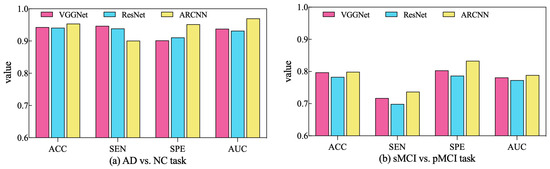
Figure 8.
Comparison of diagnostic performance across different diagnostic networks using SAMD as the optimizer in two diagnostic tasks.
As illustrated in Figure 8, SAMD consistently demonstrated good performance across three diagnostic models (including VGGNet, ResNet, and our proposed ARCNN), with particularly superior results observed in the ARCNN model. This observation underscores the adaptability and effectiveness of the SAMD algorithm in optimizing AD diagnostic networks. Furthermore, the experimental results revealed that, in comparison to the two commonly used CNN network architectures, our proposed ARCNN architecture consistently yielded superior diagnostic performance. This demonstrates the advanced and superior characteristics of our model. The experiments confirm the efficacy of the SAMD algorithm in optimizing different diagnostic networks, highlighting its adaptability and effectiveness in the field of medical image analysis, especially for AD diagnosis. Additionally, it is evident that our proposed ARCNN model, with its unique ARB structure, outperforms both ResNet with residual blocks and VGGNet without any special network structure in both diagnostic tasks. This indicates that our proposed ARCNN diagnostic network, featuring ARBs, exhibits advanced performance.
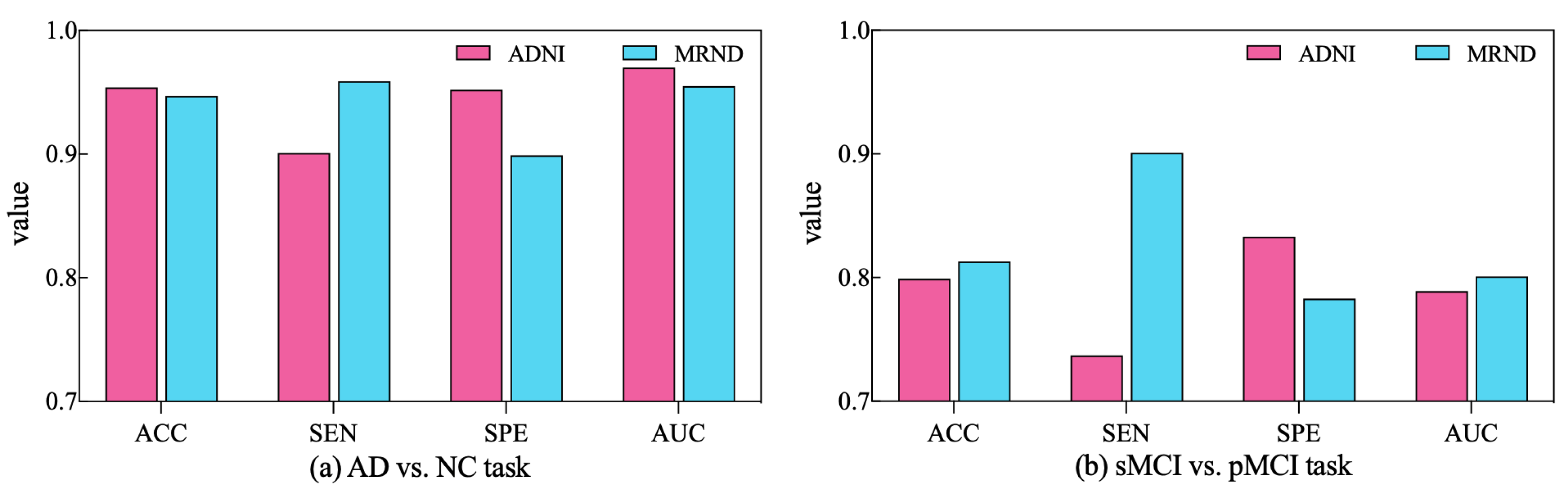
To further validate the diagnostic performance of our ARCNN model optimized using SAMD, we gathered an additional dataset (represented as MRND), including 67 AD, 89 sMCI, 48 pMCI, and 75 NC. Using the model previously trained on ADNI data, we conducted a performance evaluation with this new MRI dataset, and the results are depicted in Figure 9.
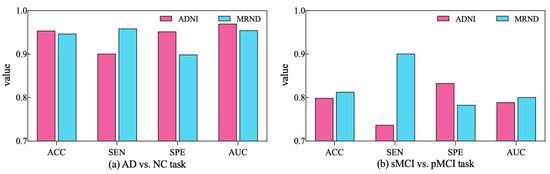
Figure 9.
The performance of ARCNN trained with SAMD on MRND.
As observed in the figure, our model continues to exhibit superior performance on the new MRI data, indicating the robustness and generalizability of our proposed approach. This outcome underscores the versatility of our method in effectively diagnosing AD across different datasets and highlights its potential for broader clinical applications. The results obtained from the evaluation on the new dataset reaffirm the effectiveness of our SAMD-optimized ARCNN model and its potential for widespread application in AD diagnosis.
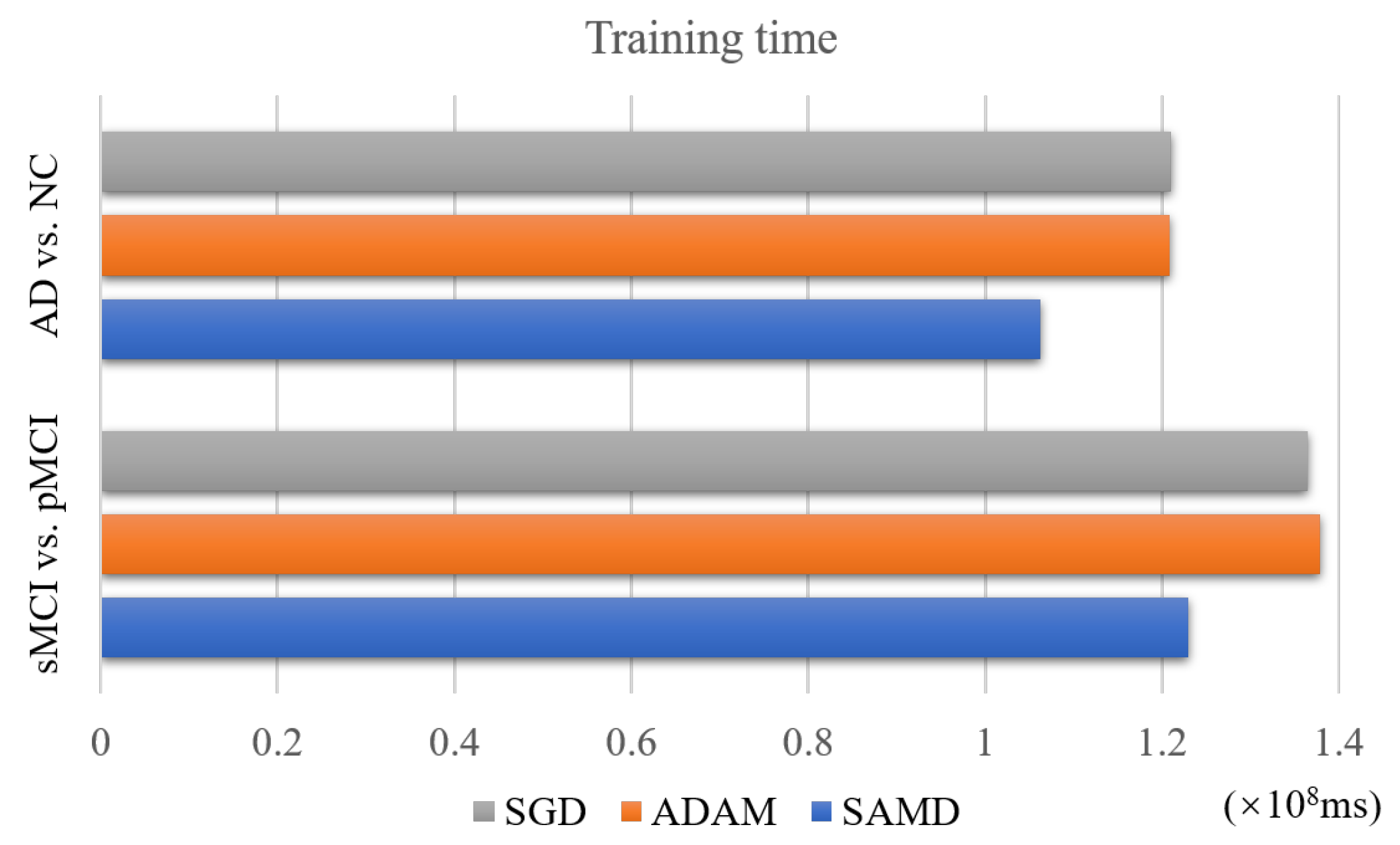
4.4. Performance of Training Time
The SAMD algorithm is proposed to accelerate the training speed of neural networks. The training time of two diagnosis tasks is recorded to verify this point. We applied SAMD, SGD, and Adam optimization to the ARCNN diagnostic model separately and recorded the training times for both diagnostic tasks, as shown in Figure 10. To ensure experimental fairness, we maintained identical datasets and experimental settings across the three different optimization algorithms for ARCNN. In a holistic perspective, the ARCNN model optimized using our proposed SAMD algorithm exhibited an average reduction of approximately 19% in training time compared to models optimized using SGD and Adam when training was completed. The experimental results demonstrate that our proposed SAMD optimization algorithm is capable of accelerating the training process of the ARCNN diagnostic network in different diagnostic tasks.
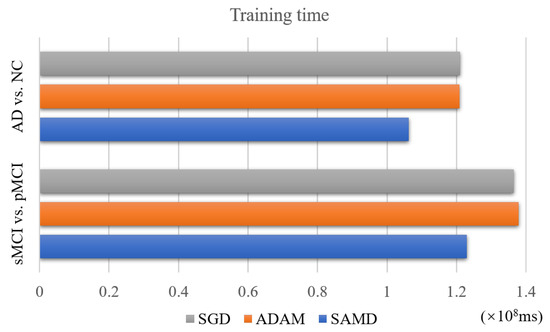
Figure 10.
Training time of different optimization algorithms on various tasks.
Furthermore, we present the average inference times for two diagnostic tasks conducted using our proposed diagnostic network. For the AD vs. NC task, the average inference time is 79.5216 ms, while for the sMCI vs. pMCI task, it is 81.3423 ms. It is worth noting that for a well-trained diagnostic model, the process of disease diagnosis is typically instantaneous, requiring minimal waiting time. Consequently, when deploying this system in clinical settings, real-time disease diagnosis can be achieved, facilitating prompt medical interventions and decisions.
4.5. Comparison with Previous Work
In Table 5, several SOTA results reported in the literature for AD vs. NC diagnosis and sMCI vs. pMCI diagnosis using structure MRI data of ADNI have been summarized. The underlined values are the optimal values in the baseline methods. From this table, we can see that our proposed method has a more powerful diagnosis capability than the existing machine learning-based AD diagnostic methods. It is worth noting that although many baselines use more data for training than us, our proposed model still achieves the highest accuracy in the two classification tasks. These results demonstrate that our model effectively diagnoses different parametric nuclear magnetic scannings. The 3D aggregated residual diagnosis network has excellent feature extraction ability. The SAMD algorithm can train the neural network model accurately and efficiently, so our proposed architecture can obtain great diagnosis results.
Table 5.
Comparison with previous work.
4.6. Future Research Directions
In this subsection, we discuss future research directions for AD diagnosis models. Emerging avenues encompass the integration of cutting-edge imaging modalities, such as the fusion of fMRI and PET with MRI images, to bolster early detection capabilities. Furthermore, the development of interpretable AI models is poised to enhance diagnostic transparency, fostering trust within clinical contexts. Additionally, the adoption of early detection strategies, including biomarker discovery and digital health technologies, holds the potential to identify AD in its incipient stages.
The future of AD diagnosis hinges on the amalgamation of advanced imaging, the advancement of interpretable AI models, the realization of early detection, and the prediction of disease progression. Through continuous research endeavors, achieving more efficient and accurate AD diagnosis becomes attainable, enabling timely clinical interventions and treatments, ultimately alleviating societal burdens and enhancing the overall wellbeing of patients.
5. Conclusions
Computer-aided diagnosis of AD plays a vital role in helping doctors diagnose disease and find potential patients. We present a novel 3D aggregated residual network with accelerated mirror descent optimization for diagnosing AD. An unbiased subgradient accelerated mirror descent optimization algorithm is proposed to accelerate the training speed of our diagnostic model. The best we can tell is that it is the first work to accelerate the Alzheimer’s diagnosis process by improving the optimization algorithm of the diagnostic model. Theoretically, our proposed SAMD optimization algorithm can converge at an rate. A 3D aggregated residual network is proposed to extract features from 3D MRI data. The experimental results on the ADNI dataset indicate that our proposed method can improve diagnosing AD and achieve 95.4% accuracy in AD diagnosis and 79.9% accuracy in MCI diagnosis. Compared with several SOTA diagnosis models, our proposed model shows excellent performance. In addition, our proposed SAMD algorithm can save about 19% of the convergence time on average compared with several gradient descent algorithms.
We will explore further to improve the disease diagnosis’s efficiency in the future. Moreover, MRI scans are not performed in many hospitals during AD diagnosis. We may consider different kinds of medical images for the diagnosis of AD and make the diagnosis network adaptable for multimodal data.
Author Contributions
All authors contributed to the study conception and design. Y.T.: conceptualization, methodology, software, investigation, formal analysis, writing—original draft. S.L.: resources, supervision, writing—review and Editing. J.Q.: resources, supervision. P.Z.: software, validation. K.H.: software. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Science and Technology Development Project of Liaoning Province of China under Grant number 2021JH6/10500127 and Science Research Project of Liaoning Department of Education of China under Grant number LJKZ0008.
Institutional Review Board Statement
A benchmark dataset, Alzheimer’s Disease Neuroimaging Initiative (ADNI), was used in our proposed work where the terms of use are declared in the following link: http://adni.loni.usc.edu/terms-of-use/ (accessed on 19 March 2022).
Informed Consent Statement
A benchmark dataset, Alzheimer’s Disease Neuroimaging Initiative (ADNI), which was used in our work, has obtained informed consent from the participants. More information can be found in the following link: http://adni.loni.usc.edu/study-design/ (accessed on 19 March 2022).
Data Availability Statement
The dataset used in this study was obtained from Alzheimer’s Disease Neuroimaging Initiative (ADNI). More information regarding ADNI can be obtained from the following link: http://adni.loni.usc.edu/ (accessed on 19 March 2022).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Holtzman, D.M.; Morris, J.C.; Goate, A.M. Alzheimer’s disease: The challenge of the second century. Sci. Transl. Med. 2011, 3, 77sr1. [Google Scholar] [CrossRef]
- Alzheimer’s Disease International. World Alzheimer Report 2022. Available online: https://www.alzint.org/resource/world-alzheimer-report-2022/ (accessed on 10 July 2023).
- Jia, J.; Wei, C.; Chen, S.; Li, F.; Tang, Y.; Qin, W.; Zhao, L.; Jin, H.; Xu, H.; Wang, F.; et al. The cost of Alzheimer’s disease in China and re-estimation of costs worldwide. Alzheimer’s Dement. 2018, 14, 483–491. [Google Scholar] [CrossRef]
- Smith, J.C.; Nielson, K.A.; Antuono, P.; Lyons, J.A.; Hanson, R.J.; Butts, A.M.; Hantke, N.C.; Verber, M.D. Semantic memory functional MRI and cognitive function after exercise intervention in mild cognitive impairment. J. Alzheimer’s Dis. 2013, 37, 197–215. [Google Scholar] [CrossRef] [PubMed]
- Altaf, F.; Islam, S.M.; Akhtar, N.; Janjua, N.K. Going deep in medical image analysis: Concepts, methods, challenges, and future directions. IEEE Access 2019, 7, 99540–99572. [Google Scholar] [CrossRef]
- Haller, S.; Zanchi, D.; Rodriguez, C.; Giannakopoulos, P. Brain structural imaging in Alzheimer’s disease. In Biomarkers for Preclinical Alzheimer’s Disease; Springer: Berlin/Heidelberg, Germany, 2018; pp. 107–117. [Google Scholar]
- Albert, M.S.; DeKosky, S.T.; Dickson, D.; Dubois, B.; Feldman, H.H.; Fox, N.C.; Gamst, A.; Holtzman, D.M.; Jagust, W.J.; Petersen, R.C.; et al. The diagnosis of mild cognitive impairment due to Alzheimer’s disease: Recommendations from the National Institute on Aging-Alzheimer’s Association workgroups on diagnostic guidelines for Alzheimer’s disease. Alzheimer’s Dement. 2011, 7, 270–279. [Google Scholar] [CrossRef]
- Poloni, K.M.; de Oliveira, I.A.D.; Tam, R.; Ferrari, R.J. Brain MR image classification for Alzheimer’s disease diagnosis using structural hippocampal asymmetrical attributes from directional 3-D log-Gabor filter responses. Neurocomputing 2021, 419, 126–135. [Google Scholar] [CrossRef]
- Alinsaif, S.; Lang, J.; Alzheimer’s Disease Neuroimaging Initiative. 3D Shearlet-Based Descriptors Combined with Deep Features for the Classification of Alzheimer’s Disease Based on MRI Data. Comput. Biol. Med. 2021, 138, 104879. [Google Scholar] [CrossRef] [PubMed]
- Lian, C.; Liu, M.; Zhang, J.; Shen, D. Hierarchical Fully Convolutional Network for Joint Atrophy Localization and Alzheimer’s Disease Diagnosis Using Structural MRI. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 880–893. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Tieleman, T.; Hinton, G. Rmsprop: Divide the gradient by a running average of its recent magnitude. coursera: Neural networks for machine learning. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Ben-Tal, A.; Margalit, T.; Nemirovski, A. The ordered subsets mirror descent optimization method with applications to tomography. SIAM J. Optim. 2001, 12, 79–108. [Google Scholar] [CrossRef]
- Baron, J.; Chetelat, G.; Desgranges, B.; Perchey, G.; Landeau, B.; De La Sayette, V.; Eustache, F. In vivo mapping of gray matter loss with voxel-based morphometry in mild Alzheimer’s disease. Neuroimage 2001, 14, 298–309. [Google Scholar] [CrossRef]
- Fan, Y.; Shen, D.; Gur, R.C.; Gur, R.E.; Davatzikos, C. COMPARE: Classification of morphological patterns using adaptive regional elements. IEEE Trans. Med. Imaging 2006, 26, 93–105. [Google Scholar] [CrossRef]
- Ju, R.; Hu, C.; Zhou, P.; Li, Q. Early diagnosis of Alzheimer’s disease based on resting-state brain networks and deep learning. IEEE/ACM Trans. Comput. Biol. Bioinform. 2017, 16, 244–257. [Google Scholar] [CrossRef]
- Coupé, P.; Eskildsen, S.F.; Manjón, J.V.; Fonov, V.S.; Pruessner, J.C.; Allard, M.; Collins, D.L.; Alzheimer’s Disease Neuroimaging Initiative. Scoring by nonlocal image patch estimator for early detection of Alzheimer’s disease. NeuroImage Clin. 2012, 1, 141–152. [Google Scholar] [CrossRef]
- Wang, H.; Shen, Y.; Wang, S.; Xiao, T.; Deng, L.; Wang, X.; Zhao, X. Ensemble of 3D densely connected convolutional network for diagnosis of mild cognitive impairment and Alzheimer’s disease. Neurocomputing 2019, 333, 145–156. [Google Scholar] [CrossRef]
- Cui, R.; Liu, M.; Alzheimer’s Disease Neuroimaging Initiative. RNN-based longitudinal analysis for diagnosis of Alzheimer’s disease. Comput. Med. Imaging Graph. 2019, 73, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Feng, C.; Elazab, A.; Yang, P.; Wang, T.; Zhou, F.; Hu, H.; Xiao, X.; Lei, B. Deep learning framework for Alzheimer’s disease diagnosis via 3D-CNN and FSBi-LSTM. IEEE Access 2019, 7, 63605–63618. [Google Scholar] [CrossRef]
- Puente-Castro, A.; Fernandez-Blanco, E.; Pazos, A.; Munteanu, C.R. Automatic assessment of Alzheimer’s disease diagnosis based on deep learning techniques. Comput. Biol. Med. 2020, 120, 103764. [Google Scholar] [CrossRef]
- Allioui, H.; Sadgal, M.; Elfazziki, A. Utilization of a convolutional method for Alzheimer disease diagnosis. Mach. Vis. Appl. 2020, 31, 1–19. [Google Scholar] [CrossRef]
- Pan, Y.; Liu, M.; Lian, C.; Zhou, T.; Xia, Y.; Shen, D. Synthesizing missing PET from MRI with cycle-consistent generative adversarial networks for Alzheimer’s disease diagnosis. In International Conference on Medical Image Computing and Computer-Assisted Intervention, Proceedings of the 21st International Conference, Granada, Spain, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 455–463. [Google Scholar]
- Ji, H.; Liu, Z.; Yan, W.Q.; Klette, R. Early diagnosis of Alzheimer’s disease using deep learning. In Proceedings of the 2nd International Conference on Control and Computer Vision, Jeju Island, Republic of Korea, 15–18 June 2019; pp. 87–91. [Google Scholar]
- Zhang, Y.; Wang, S.; Xia, K.; Jiang, Y.; Qian, P.; Alzheimer’s Disease Neuroimaging Initiative. Alzheimer’s disease multiclass diagnosis via multimodal neuroimaging embedding feature selection and fusion. Inf. Fusion 2021, 66, 170–183. [Google Scholar] [CrossRef]
- Santos-Rodríguez, R.; García-García, D.; Cid-Sueiro, J. Cost-sensitive classification based on Bregman divergences for medical diagnosis. In Proceedings of the 2009 International Conference on Machine Learning and Applications, Miami, FL, USA, 13–15 December 2009; pp. 551–556. [Google Scholar]
- Angulo, H.; Giménez, J.; Moros, A.M.; Nikodem, K. On strongly h-convex functions. Ann. Funct. Anal. 2011, 2, 85–91. [Google Scholar] [CrossRef]
- Hardt, M.; Ma, T.; Recht, B. Gradient Descent Learns Linear Dynamical Systems. J. Mach. Learn. Res. 2018, 19, 1–44. [Google Scholar]
- Nedic, A.; Lee, S. On stochastic subgradient mirror-descent algorithm with weighted averaging. SIAM J. Optim. 2014, 24, 84–107. [Google Scholar] [CrossRef]
- Xu, L.; Yao, Z.; Li, J.; Lv, C.; Zhang, H.; Hu, B. Sparse feature learning with label information for Alzheimer’s disease classification based on magnetic resonance imaging. IEEE Access 2019, 7, 26157–26167. [Google Scholar] [CrossRef]
- Cui, R.; Liu, M. Hippocampus analysis by combination of 3-D DenseNet and shapes for Alzheimer’s disease diagnosis. IEEE J. Biomed. Health Inform. 2019, 23, 2099–2107. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Janoušová, E.; Vounou, M.; Wolz, R.; Gray, K.R.; Rueckert, D.; Montana, G. Biomarker discovery for sparse classification of brain images in Alzheimer’s disease. Ann. BMVA 2012, 2012, 1–11. [Google Scholar]
- Liu, S.; Liu, S.; Cai, W.; Che, H.; Pujol, S.; Kikinis, R.; Feng, D.; Fulham, M.J.; ADNI. Multimodal neuroimaging feature learning for multiclass diagnosis of Alzheimer’s disease. IEEE Trans. Biomed. Eng. 2015, 62, 1132–1140. [Google Scholar] [CrossRef]
- Korolev, S.; Safiullin, A.; Belyaev, M.; Dodonova, Y. Residual and plain convolutional neural networks for 3D brain MRI classification. In Proceedings of the 2017 IEEE 14th international symposium on biomedical imaging (ISBI 2017), Melbourne, VIC, Australia, 18–21 April 2017; pp. 835–838. [Google Scholar]
- Karasawa, H.; Liu, C.L.; Ohwada, H. Deep 3D convolutional neural network architectures for alzheimer’s disease diagnosis. In Asian Conference on Intelligent Information and Database Systems, Proceedings of the 10th Asian Conference, ACIIDS 2018, Dong Hoi City, Vietnam, 19–21 March 2018; Springer: Cham, Switzerland, 2018; pp. 287–296. [Google Scholar]
- Khvostikov, A.; Aderghal, K.; Benois-Pineau, J.; Krylov, A.; Catheline, G. 3D CNN-based classification using sMRI and MD-DTI images for Alzheimer disease studies. arXiv 2018, arXiv:1801.05968. [Google Scholar]
- Lin, W.; Tong, T.; Gao, Q.; Guo, D.; Du, X.; Yang, Y.; Guo, G.; Xiao, M.; Du, M.; Qu, X.; et al. Convolutional neural networks-based MRI image analysis for the Alzheimer’s disease prediction from mild cognitive impairment. Front. Neurosci. 2018, 12, 777. [Google Scholar] [CrossRef]
- Zhu, T.; Cao, C.; Wang, Z.; Xu, G.; Qiao, J. Anatomical Landmarks and DAG Network Learning for Alzheimer’s Disease Diagnosis. IEEE Access 2020, 8, 206063–206073. [Google Scholar] [CrossRef]
- Lin, W.; Lin, W.; Chen, G.; Zhang, H.; Gao, Q.; Huang, Y.; Tong, T.; Du, M.; Alzheimer’s Disease Neuroimaging Initiative. Bidirectional mapping of brain MRI and PET with 3D reversible GAN for the diagnosis of Alzheimer’s disease. Front. Neurosci. 2021, 15, 646013. [Google Scholar] [CrossRef]
- Gao, X.; Shi, F.; Shen, D.; Liu, M. Task-induced pyramid and attention GAN for multimodal brain image imputation and classification in alzheimer’s disease. IEEE J. Biomed. Health Inform. 2021, 26, 36–43. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Tan, Y.; Miao, J.; Liang, P.; Gong, J.; He, H.; Jiao, Y.; Zhang, F.; Xing, Y.; Wu, D. Attention-based and micro designed EfficientNetB2 for diagnosis of Alzheimer’s disease. Biomed. Signal Process. Control 2023, 82, 104571. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).