

Highway Visibility Estimation in Foggy Weather via Multi-Scale Fusion Network

 , and
, and
Abstract
:1. Introduction
- (1)
- We propose a CNN-based method for highway visibility estimation from a single surveillance image. This method can provide low-cost and efficient support for intelligent highway management.
- (2)
- A multi-scale fusion network model is developed to estimate visibility from the input highway surveillance image. We are more concerned with the efficient transfer of low-level features to high-level features than with the design of complex network structures. Multiple image feature extraction methods are utilized to extract low-level visual features of fog, which can provide valuable information for subsequent model learning. The multi-scale fusion module is designed to extract the important high-level multi-scale features for the final visibility estimation, which can effectively improve the accuracy of the estimation.
- (3)
- We create a dataset of real-world highway surveillance images for model learning and performance evaluation. Each image in the dataset was labeled by professional traffic meteorology practitioners.
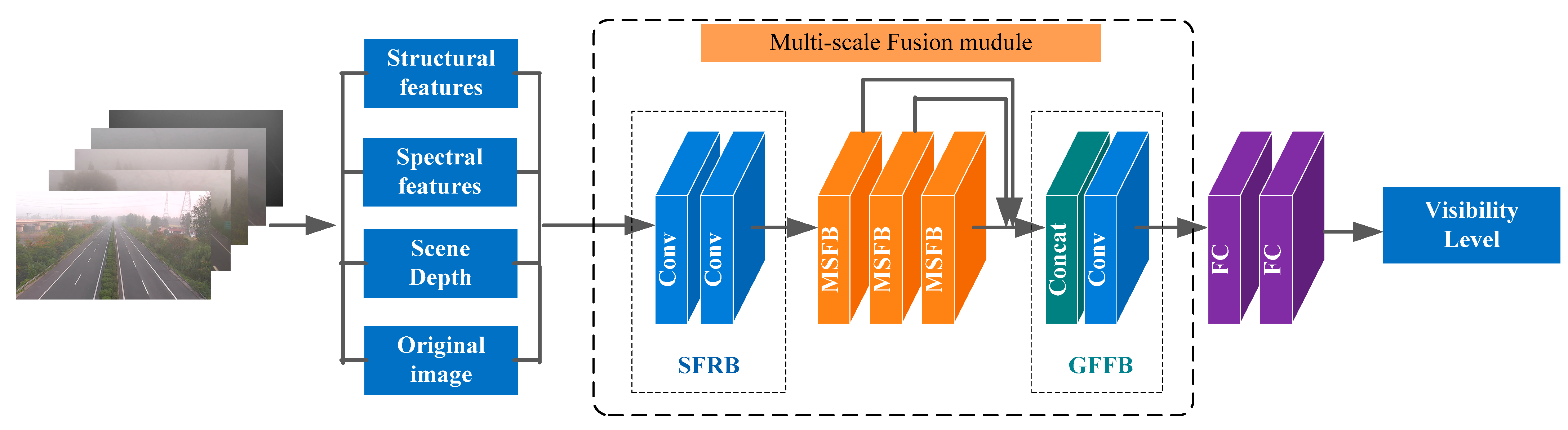
2. Proposed Method
2.1. Image Feature Extraction
2.1.1. Detailed Structural Feature Extraction
2.1.2. Spectral Feature Extraction
2.1.3. Scene Depth Feature Extraction
2.2. Multi-Scale Fusion Module
3. Experiments
3.1. Dataset
3.2. Implementation and Training Details
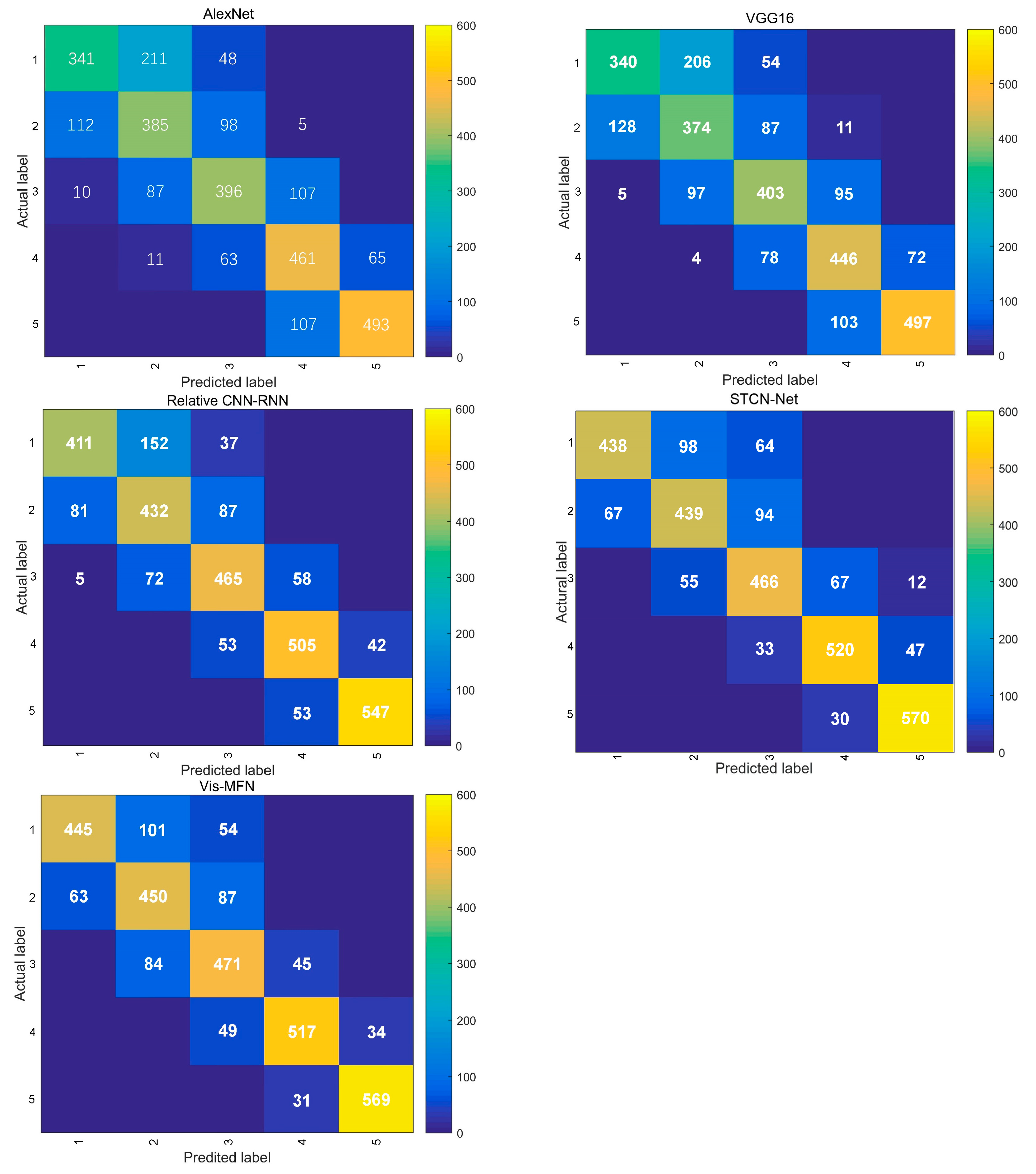
3.3. Comparison Experiments
3.4. Ablation Experiments
- (1)
- Vis-MFN-NF: No image feature extraction algorithm was used in the model.
- (2)
- Vis-MFN-NM: The multi-scale fusion blocks were replaced by multiple convolutions in series. Meanwhile, the receptive field of the new network remained unchanged.
- (3)
- Vis-MFN-M2: Only two multi-scale blocks were used in the network.
- (4)
- Vis-MFN-M4: Four multi-scale blocks were used in the network.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fabbian, D.; Dear, R.D.; Lellyett, S. Application of artificial neural network forecasts to predict fog at Canberra International Airport. Weather Forecast. 2007, 22, 372–381. [Google Scholar] [CrossRef]
- Kwon, T.M. Atmospheric Visibility Measurements Using Video Cameras: Relative Visibility. Retrieved from the University of Minnesota Digital Conservancy. 2004. Available online: https://hdl.handle.net/11299/1027 (accessed on 1 July 2004).
- Liaw, J.J.; Lian, S.B.; Huang, Y.F.; Chen, R.C. Atmospheric visibility monitoring using digital image analysis techniques. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Münster, Germany, 2–4 September 2009; pp. 1204–1211. [Google Scholar]
- Luo, C.H.; Wen, C.Y.; Yuan, C.S.; Liaw, J.J.; Lo, C.C.; Chiu, S.H. Investigation of urban atmospheric visibility by high-frequency extraction: Model development and field test. Atmos. Environ. 2005, 39, 2545–2552. [Google Scholar] [CrossRef]
- Babari, R.; Hautière, N.; Dumont, E.; Papelard, J.P.; Paparoditis, N. Computer vision for the remote sensing of atmospheric visibility. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 219–226. [Google Scholar]
- Varjo, S.; Hannuksela, J. Image based visibility estimation during day and night. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 277–289. [Google Scholar]
- Lee, Z.; Shang, S. Visibility: How applicable is the century-old Koschmieder model? J. Atmos. Sci. 2016, 73, 4573–4581. [Google Scholar] [CrossRef]
- Hautiére, N.; Babari, R.; Dumont, E.; Brémond, R.; Paparoditis, N. Estimating meteorological visibility using cameras: A probabilistic model-driven approach. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; pp. 243–254. [Google Scholar]
- Gallen, R.; Cord, A.; Hautière, N.; Aubert, D. Towards night fog detection through use of in-vehicle multipurpose cameras. In Proceedings of the IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 399–404. [Google Scholar]
- Babari, R.; Hautiere, N.; Dumont, E.; Brémond, R.; Paparoditis, N. A model-driven approach to estimate atmospheric visibility with ordinary cameras. Atmos. Environ. 2011, 45, 5316–5324. [Google Scholar] [CrossRef]
- Hautiere, N.; Tarel, J.P.; Lavenant, J.; Aubert, D. Automatic fog detection and estimation of visibility distance through use of an onboard camera. Mach. Vis. Appl. 2006, 17, 8–20. [Google Scholar] [CrossRef]
- Hautière, N.; Labayrade, R.; Aubert, D. Estimation of the visibility distance by stereovision: A generic approach. IEICE Trans. Inf. Syst. 2006, 89, 2084–2091. [Google Scholar] [CrossRef]
- Negru, M.; Nedevschi, S. Image based fog detection and visibility estimation for driving assistance systems. In Proceedings of the IEEE 9th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 5–7 September 2013; pp. 163–168. [Google Scholar]
- You, Y.; Lu, C.; Wang, W.; Tang, C.K. Relative CNN-RNN: Learning relative atmospheric visibility from images. IEEE Trans. Image Process. 2018, 28, 45–55. [Google Scholar] [CrossRef] [PubMed]
- Palvanov, A.; Cho, Y.I. VisNet: Deep Convolutional Neural Networks for Forecasting Atmospheric Visibility. Sensors 2019, 19, 1343. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Shen, K.; Yu, P.; Shi, Q.; Ko, H. Multimodal Deep Fusion Network for Visibility Assessment With a Small Training Dataset. IEEE Access 2020, 8, 217057–217067. [Google Scholar] [CrossRef]
- He, K.; Sun, J. Fast guided filter. arXiv 2015, arXiv:1505.00996. [Google Scholar]
- Liu, J.; Li, Q.; Cao, R.; Tang, W.; Qiu, G. MiniNet: An extremely lightweight convolutional neural network for real-time unsupervised monocular depth estimation. ISPRS J. Photogramm. Remote Sens. 2020, 166, 255–267. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, J.; Chang, X.; Li, Y.; Li, Y.; Ji, Y.; Fu, J.; Zhong, J. STCN-Net: A novel multi-feature stream fusion visibility estimation approach. IEEE Access 2022, 10, 120329–120342. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Visibility Level | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Visibility distance | 0–50 m | 50–100 m | 100–200 m | 200–500 m | 500+ m |
| AlexNet | VGG16 | Relative CNN-RNN | STCN-Net | Vis-MFN | |
|---|---|---|---|---|---|
| Accuracy | 69.21% | 68.72% | 78.58% | 81.10% | 81.76% |
| Setting | Vis-MFN-NM | Vis-MFN-NF | Vis-MFN-M2 | Vis-MFN-M4 |
|---|---|---|---|---|
| Image feature extraction methods | ✓ | × | ✓ | ✓ |
| Multi-scale fusion module | × | ✓ | ✓ | ✓ |
| The number of MSFBs | 2 | 2 | 2 | 4 |
| Accuracy | 75.36% | 72.85% | 81.76% | 82.49% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, P.; Zhang, Z.; Luo, X.; Sun, J.; Zhou, X.; Yang, X.; Huang, L. Highway Visibility Estimation in Foggy Weather via Multi-Scale Fusion Network. Sensors 2023, 23, 9739. https://doi.org/10.3390/s23249739
Xiao P, Zhang Z, Luo X, Sun J, Zhou X, Yang X, Huang L. Highway Visibility Estimation in Foggy Weather via Multi-Scale Fusion Network. Sensors. 2023; 23(24):9739. https://doi.org/10.3390/s23249739
Chicago/Turabian StyleXiao, Pengfei, Zhendong Zhang, Xiaochun Luo, Jiaqing Sun, Xuecheng Zhou, Xixi Yang, and Liang Huang. 2023. "Highway Visibility Estimation in Foggy Weather via Multi-Scale Fusion Network" Sensors 23, no. 24: 9739. https://doi.org/10.3390/s23249739
APA StyleXiao, P., Zhang, Z., Luo, X., Sun, J., Zhou, X., Yang, X., & Huang, L. (2023). Highway Visibility Estimation in Foggy Weather via Multi-Scale Fusion Network. Sensors, 23(24), 9739. https://doi.org/10.3390/s23249739