1. Introduction
Grapes are the fifth most widely produced fruit, with approximately 79.5 million tonnes being produced worldwide in 2019 [
1]. The estimation of the maturity of the berries is critical for determining the appropriate harvesting time, which in turn results in favorable quality [
2]. This is particularly important in wine production, where the optimal harvest time determined by enological parameters largely affects the produced wine quality. The exact point in time in which each grape berry attains its optimal maturity level depends, among others, on the terrain [
3], the duration of the growing season, the variety, the vine tree load, and other environmental conditions [
4,
5].
The common practice used today by the wine producers to assess the maturity of the grapes of a field is a two-step process. First, experts use sensory attributes (i.e., color and taste) to identify that a grape is entering its maturity stage. Following this, they sample some of the fruits, crush them, and use a refractometer to measure their °Brix value in situ [
6]. A similar step may be performed in the laboratory using more costly chemical analyses. The °Brix value is the total soluble solids content, i.e., the sugar content of the aqueous solution of the crushed grape. The sugar content is crucial since it determines the alcoholic level of the wine and is critical in the subsequent fermentation process [
7]. The decision about when to harvest is currently taken based on this sampling method, which relies on the destructive measurements at a given time, without considering the evolution of the associated variables. Evidently, this traditional approach cannot reliably perform selective harvesting [
2].
On the other hand, near infrared (NIR) reflectance spectroscopy is a widespread technique used in many scientific fields such as in the food quality assessment sector [
8] and soil science [
9]. It is a non-destructive technique based on measuring the electromagnetic radiation, which is reflected at different wavelengths by the target surface, and may be used for the quality evaluation of intact fruits and vegetables [
10]. In the context of grape composition monitoring during the ripening process using NIR spectroscopy, a variety of works has been published [
11,
12,
13,
14,
15,
16], but most of these were conducted under controlled conditions, such as illumination, temperature, humidity, and sample positioning, among others—i.e., in a laboratory. For example, in a recent study [
17], three ripening parameters were predicted in four table grape cultivars using a NIR sensor under laboratory conditions. Chariskou et al. [
18] used Fourier-transform near infrared reflectance spectra of intact berries to predict total soluble solids (TSS) content, but the spectra were recorded in the laboratory. Line-scan hyperspectral imaging in the NIR has also been employed in laboratory conditions to estimate sugar and pH levels in wine grape berries [
19]. Other studies (e.g., Ref. [
20]) have focused on studying the extracted berry juice, which may potentially yield better results but requires a destructive measurement process. Larrain et al. [
21] developed a portable instrument for determining the ripeness in wine grapes using NIR spectroscopy (640–1100 nm), testing it in five grape varieties in Chile, but used only a fraction of the NIR spectrum.
The use of hyperspectral data and specifically in the visible and near infrared (VNIR, 350–1000 nm) and in the short-wave infrared (SWIR, 1000–2500 nm) regions in grape production is of great interest [
22]. Due to its fine spectral resolution, hyperspectral analysis can contribute to both fruit monitoring and quality control at all stages of maturity in a simple and inexpensive way. The regions of VNIR and SWIR in grape production have piqued the interest of researchers in the past [
23]. Specifically, three comprehensive reviews show the potential and challenges of infrared spectroscopy for analyzing the chemical composition of grapes in the laboratory, the vineyard, and before or during the harvest, to provide better insights into the chemistry, nutrition, and physiology of grapes [
24,
25,
26].
Furthermore, machine learning has been applied in the wine sector across various domains and the entire production chain. In addition to providing estimations of grape maturity indicators, a plethora of other applications has been reported in the literature. For example, machine learning approaches can assist in determining how consumers perceive wine quality, thus constituting an effective tool for understanding the complex nature of wine datasets and conveying useful information related to wine quality [
27]. Machine learning coupled with various spectroscopic approaches has also been employed to guarantee wine authenticity [
28]. Moreover, wine grape yield was estimated at the regional level in Portugal using as inputs a combination of space-borne imagery and climate data in a deep learning framework [
29]. Another interesting application involves the segmentation of the grapevines and the vineyard classification, which are key to optimize the management of vineyard plots; this was achieved through the use of aerial imagery obtained from unmanned aerial vehicles [
30]. A machine learning method has also been developed to predict which municipalities will obtain geographical Indications in the future, showcasing which main features (e.g., territorial conditions, socio-economic factors, etc.) are more relevant in predicting their success [
31]. These works, although not presenting exhaustively all possible applications of machine learning in the wine sector, demonstrate the merits of the data-driven approaches, which can improve the performance on some tasks or provide essential tools for various stakeholders.
The main goals of the current work were to (i) create a local grape spectral library and (ii) estimate the wine grape ripeness in a simple, inexpensive, and non-destructive way, taking advantage of the synergistic use of ground truth °Brix measurements, in situ point spectroscopy data, and machine learning algorithms coupled with several pre-processing techniques.
3. Results
3.1. Dataset
An overall description of the dataset descriptive statistics obtained by conventional techniques for grape sugar content for all the varieties is presented in
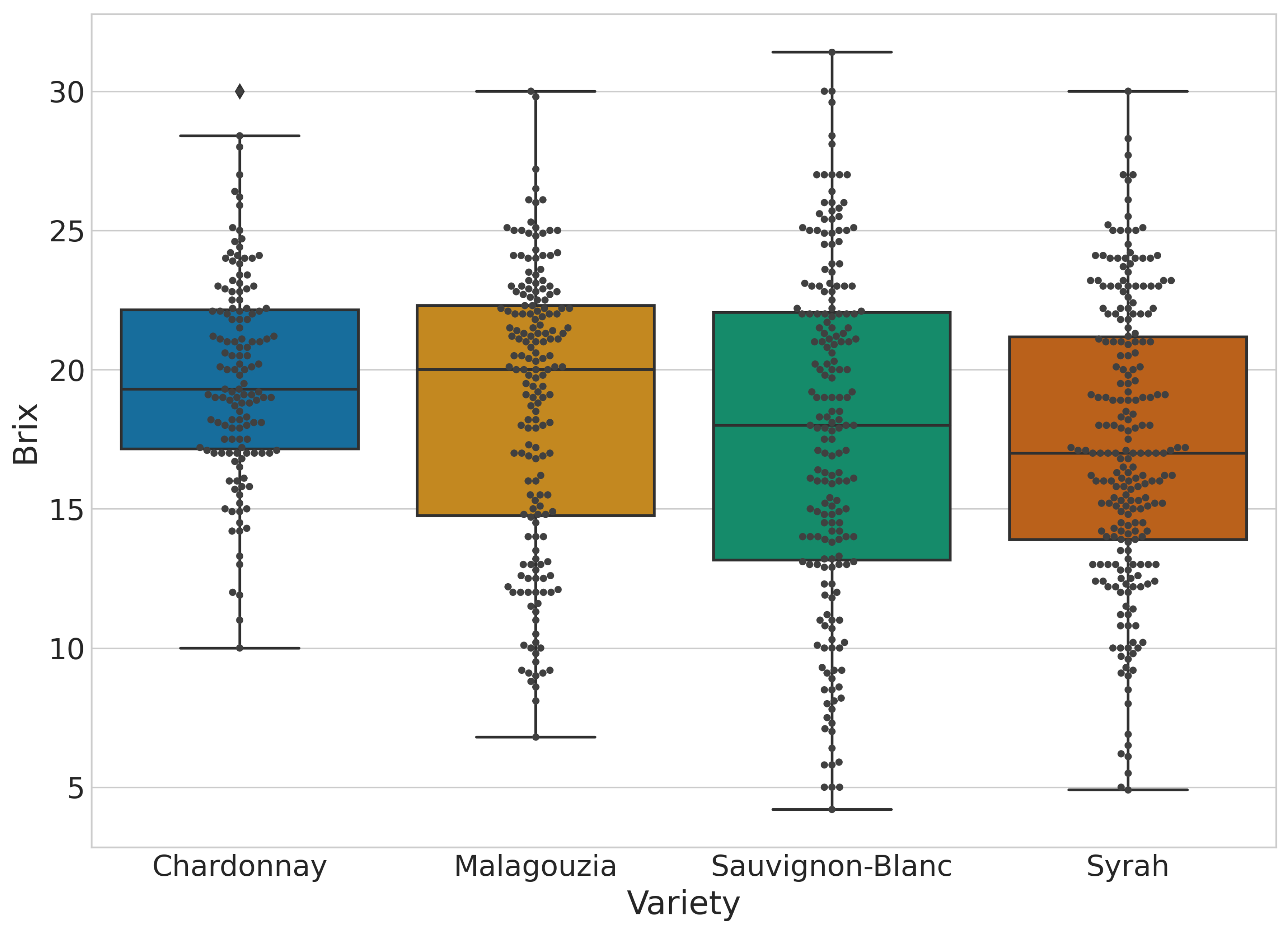
Table 2. These values were used as ground truth data to test the machine learning prediction models. Based on the table it is possible to observe differences between varieties. Furthermore, the minimum and maximum values for all varieties have significant ranges due to the measurements that took place from the early ripening stage of the grapes in July until just before their harvest time in August. Overall, within the varieties, values range from 4.2 up to 31.4 °Brix, where both the extreme values are found in the Sauvignon-Blanc variety. Regarding the mean standard deviation and the quartiles, it should be noted that they vary widely among the varieties. In addition, for more information about the statistics of the grape dataset, the box plot of
Figure 5 for the sugar content ground truth values is provided.
3.2. Spectra Analysis
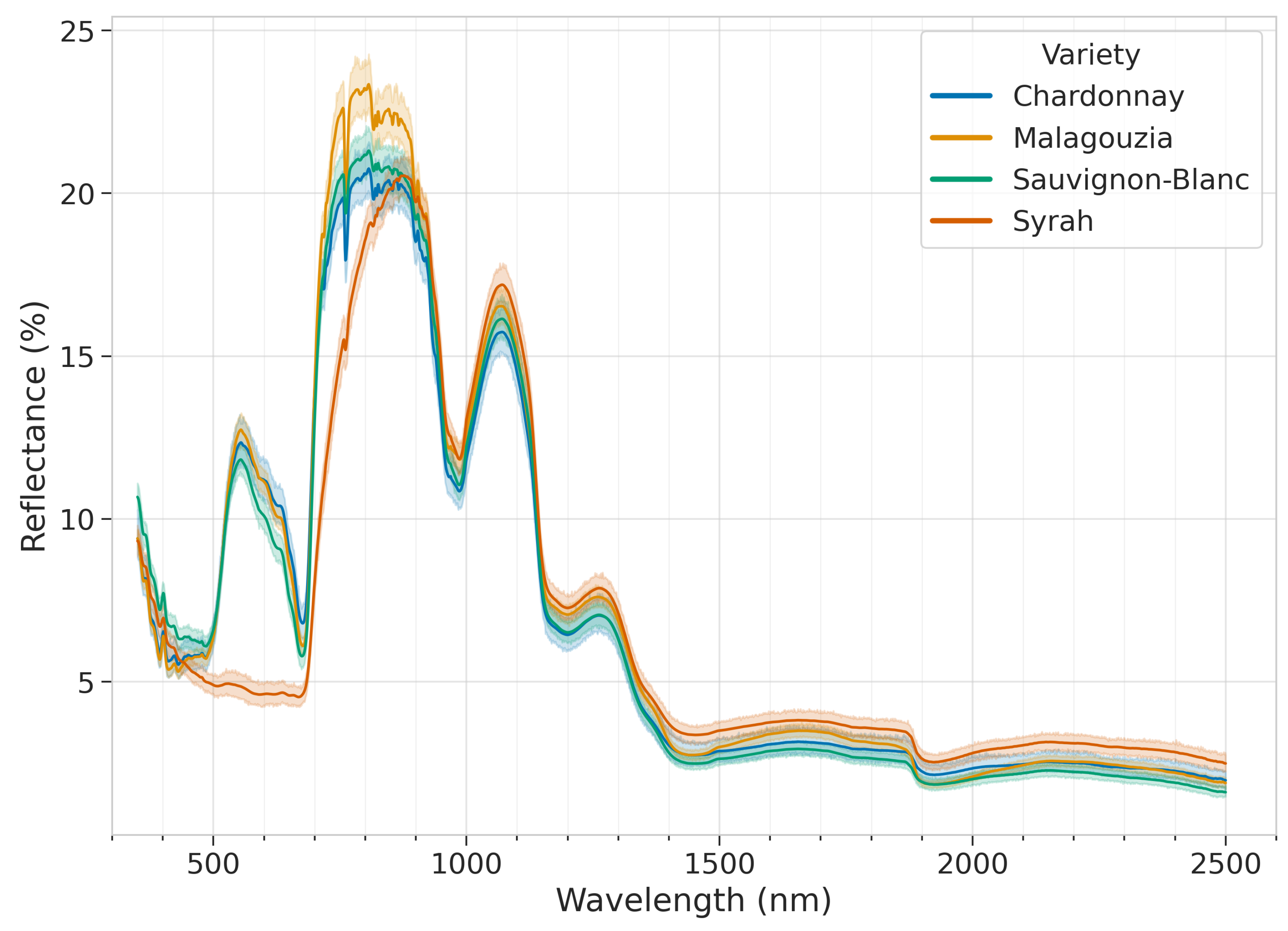
Figure 6 illustrates the reflectance spectra of the grape spectra library for the four varieties. The x axis defines the wavelength (350 to 2500 nm) and the y axis the reflectance. The continuous line is the mean spectrum, while the shaded area indicates the confidence interval calculated at a 95% confidence level. Looking carefully in the graph it is obvious that the white grape varieties (Chardonnay, Malagouzia, Sauvignon-Blanc) present the same variations in contrast to the red variety (Syrah), which presents certain differences, especially in the range of 450 to 700 nm.
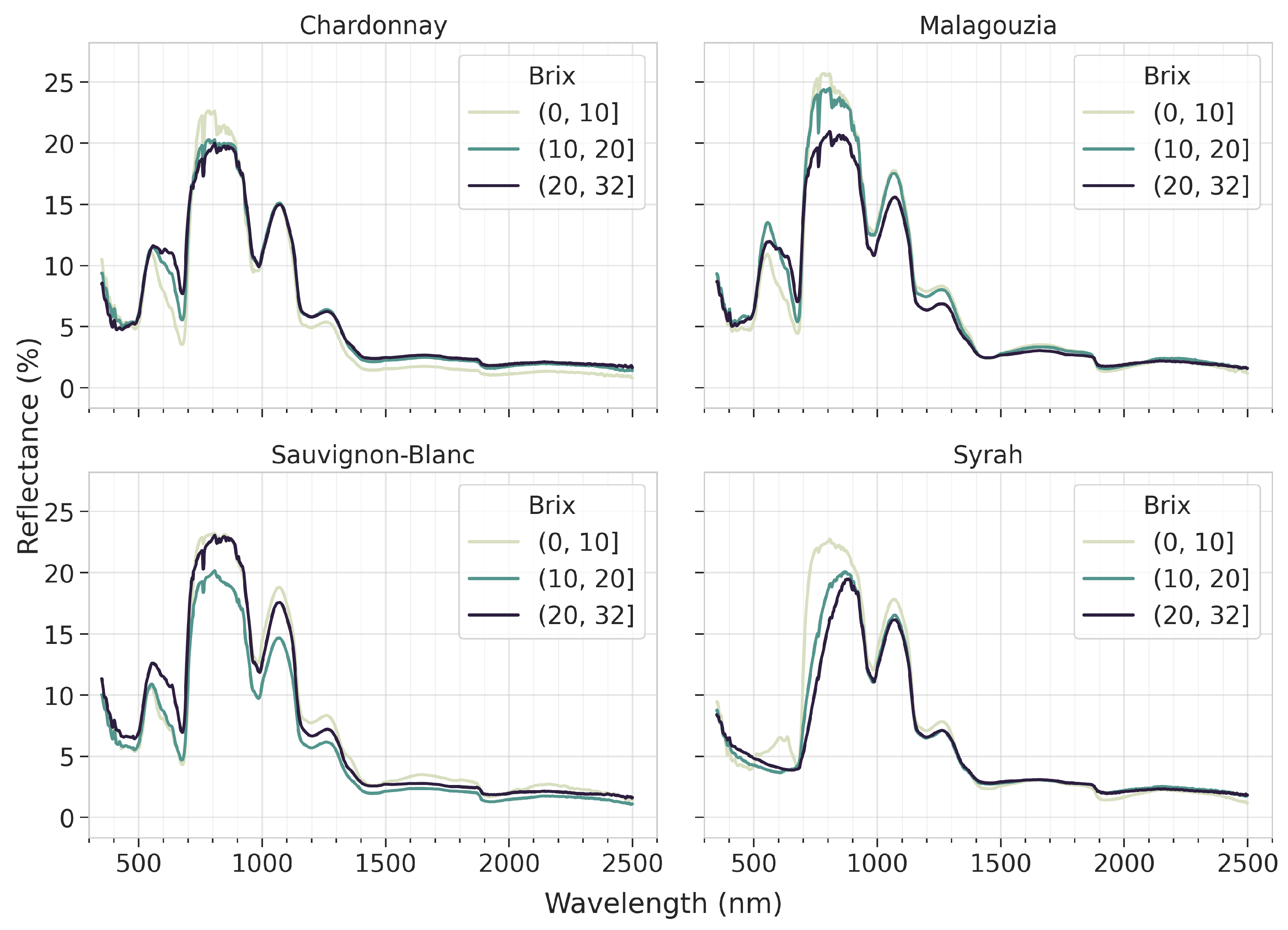
How the grapes’ spectral signatures are affected as they grow more mature (i.e., with higher °Brix content) is shown in
Figure 7. An important point that arises from this figure is that the valuable information pertaining to the maturity of the grapes according to all spectral signatures focuses on the range from 550 to 1300 nm, whereas most of the SWIR appears to provide limited information in terms of absorption bands. At least in terms of the mean spectra, it is possible to visually identify some patterns that indicate a transition from low to higher sugar content; e.g., for Chardonnay and Malagouzia at 680 nm and for Syrah from 700 to 900 nm. Things are more convoluted for Sauvignon-Blanc, where the mean reflectance curve for the higher sugar content is found in between the respective curves for low and medium content. Yet even in this case, there is a visible absorption band at approximately 750 nm that increases for higher sugar content values. This indicates that by using spectral pre-processing techniques it may be possible for an apt learning algorithm to discern a more robust pattern and infer the sugar content from the spectral data.
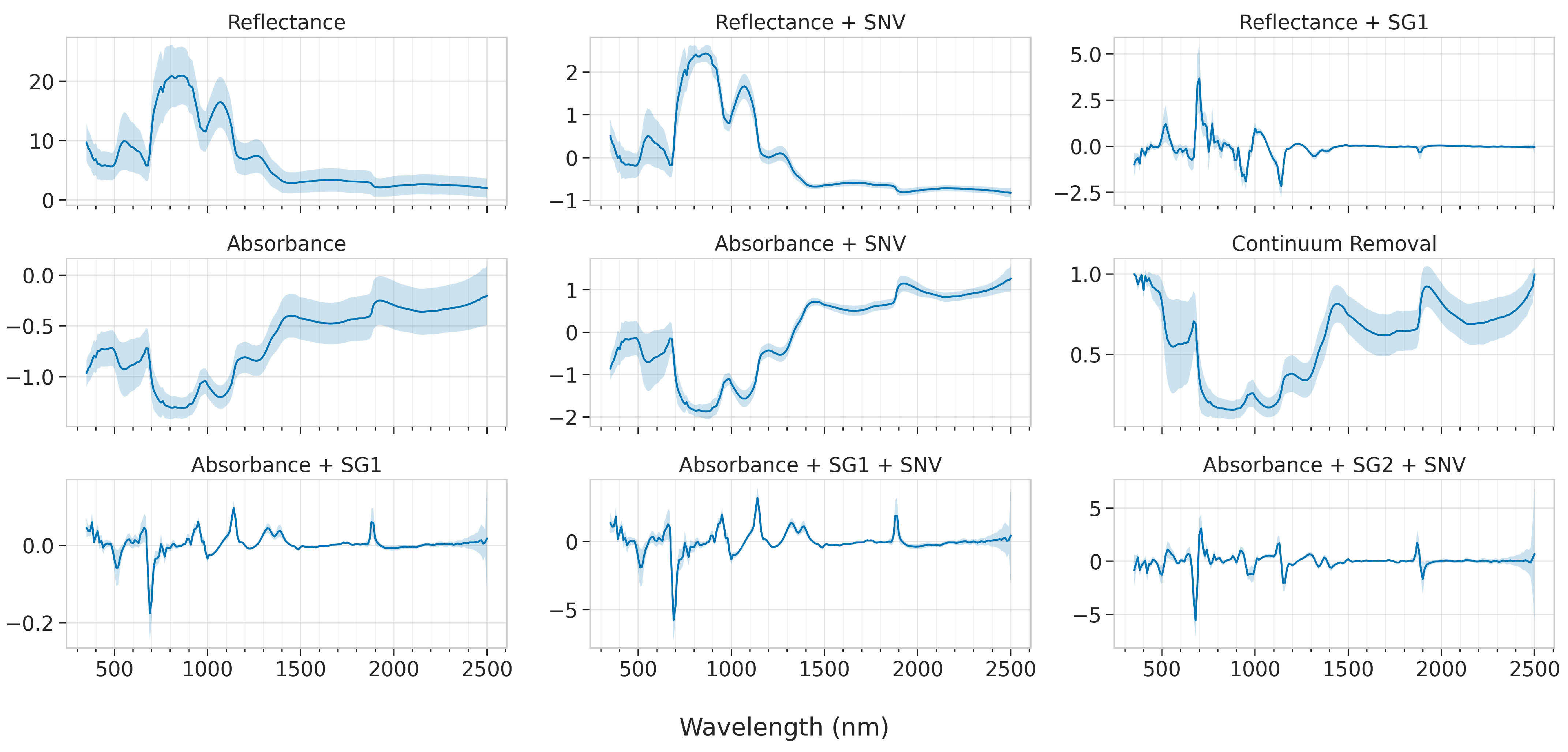
The effect of the various spectral pre-treatments is presented in
Figure 8. The absorbance and continuum removal transformations highlight five main absorbance regions, namely at around 680, 970, 1200, 1440, and 1920 nm, which are dominant throughout all grape varieties and irrespective of the grapes’ sugar content. The SNV transformation, which is a scatter-correction technique, also adjusts for baseline shifts between samples. As expected, the effect on the mean spectra is not profound, however, when comparing, e.g., the Ref and Ref+SNV spectra, the standard deviation indicates that the largest deviations are to be found in the VNIR. On the other hand, the first-derivative transformations indicate the same sharp peaks, albeit with a small offset, which is expected due to the mathematical calculation of the first-derivative; it is zero exactly at the peak and attains its largest positive and negative value at each side. Therefore, care should be taken when reading into the exact wavelengths from the first-derivative transformation. For similar reasons, the second-derivative transformation does not have the same problem and its peaks indicate more precisely the exact location of the absorption bands.
3.3. Prediction Accuracy
The mean prediction of accuracy across the five-folds in the independent test set is given in
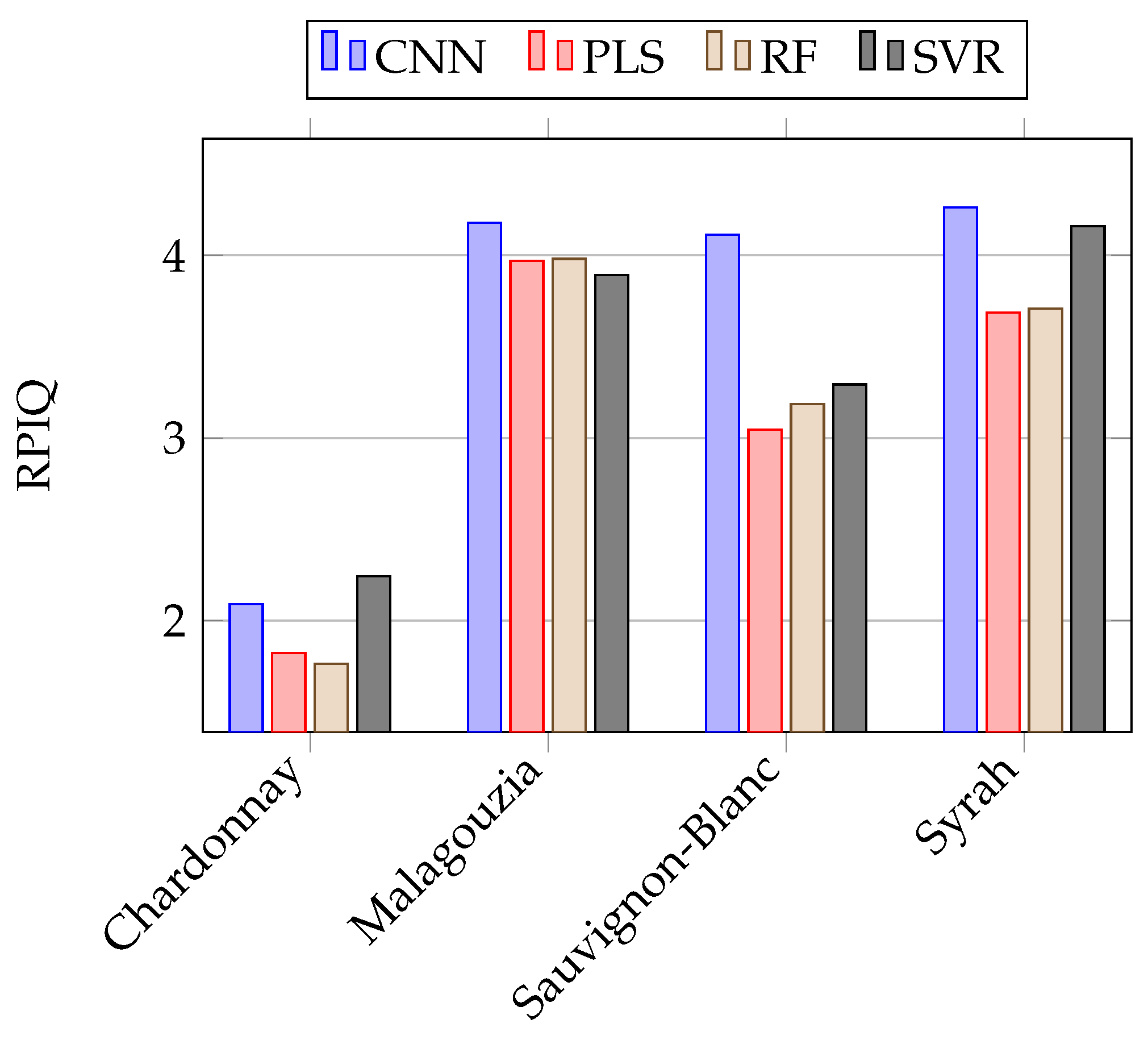
Table 3. Therein we present for each model the best spectral pre-treatment, which was determined as the one that minimized the mean RMSE in the internal validation sets. To aid the reader in the comparison,
Figure 9 provides a visual comparison of the RPIQ values. The optimal set of hyperparameters corresponding to those results is provided in
Table A1. Additionally provided in
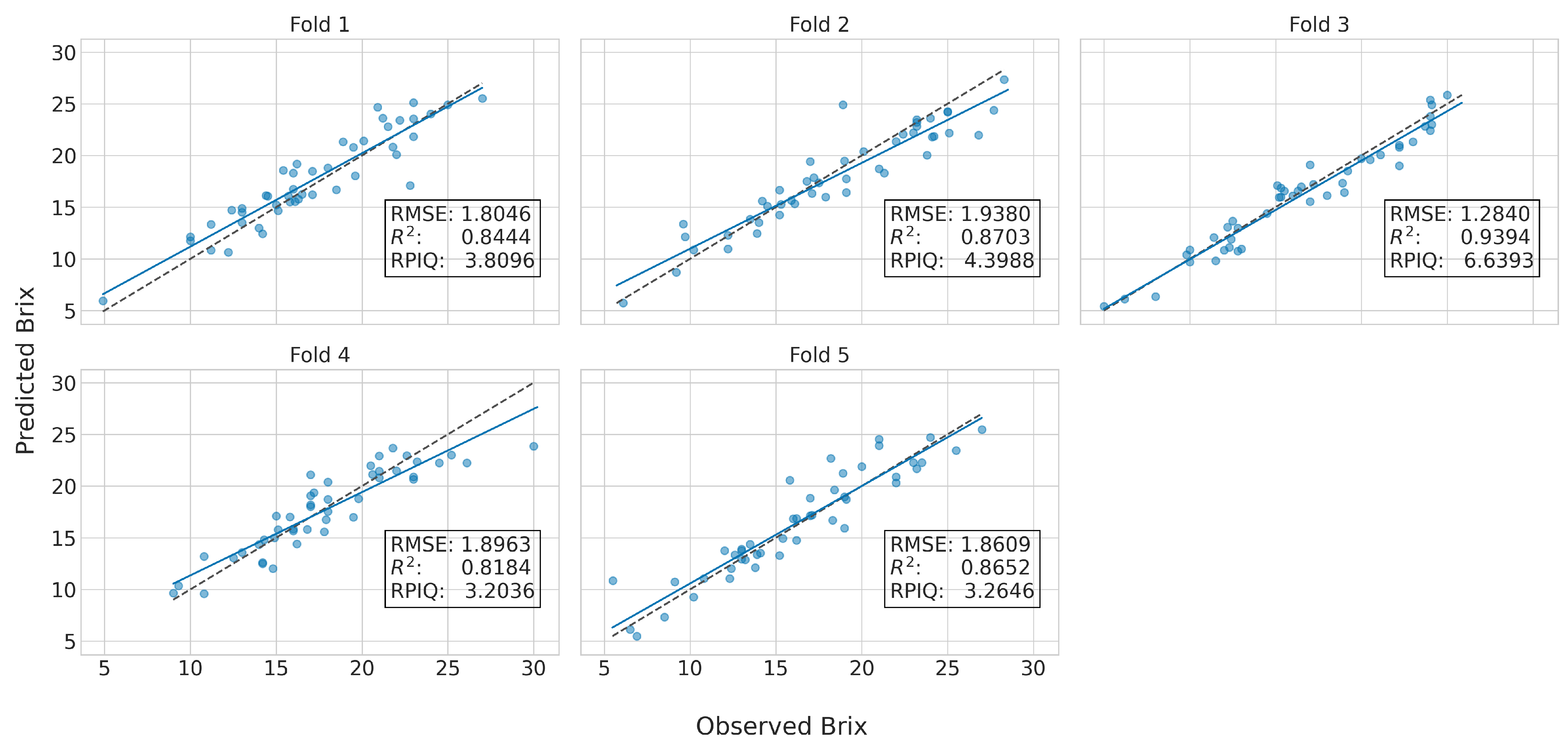
Figure 10 are the predictions of the CNN model using the Ref+SG1 spectra for the Syrah variety in the independent test set (i.e., the best model); the respective results of
Table 3 are the mean metrics calculated across the five-folds. It is thus visible that there are some slight variations across the folds, which justifies our selection to use a five-fold cross-validation strategy to provide more robust comparisons.
The Chardonnay variety yielded the worst results across all four different models, and only the CNN and SVR models attained a performance of mean RPIQ > 2 and mean >= 0.6, which indicates a good fit. In the other three varieties, namely Malagouzia, Sauvignon-Blanc, and Syrah, the CNN model attained the best results when compared with the other models. It should be noted that in these varieties the mean RPIQ was greater than 4 while the metric was greater than 0.8, suggesting that the prediction accuracy was very good.
When the different learning algorithms are compared, it is evident that the CNN model achieved the second best performance in the Chardonnay variety (behind SVR) and the best results in the remaining three out of four varieties. In particular, for Chardonnay, the relative difference in terms of RMSE is about 4.6%, which expressed in °Brix is about 0.1. The greatest difference is observed for Sauvignon-Blanc, where the CNN model compared to the second best (namely, SVR), has a relative difference in terms of RMSE of about 20%, or 0.5 °Brix. It should also be noted that the differences in Malagouzia across all models are quite small, and all four algorithms attained a very similar performance. Finally, the smallest prediction error was to be found in the only red wine variety in our study, namely Syrah, where the CNN model had an RMSE of 1.76 °Brix.
With respect to the best pre-treatment, it must be highlighted that even though it was not universal across all learning algorithms and varieties, nevertheless there was a strong preference for the use of the 1st derivative spectra, with variations including it producing the best results in 14 out of 16 cases. This attests to the fact that by accentuating the absorption bands it is possible to yield lower prediction errors. Most notably, in both cases where the 1st derivative spectra were not the most favorable approach, the PLS algorithm was the model used. In the first one (i.e., PLS in Chardonnay) the model had a poor fit and used the 2nd derivative spectra, while in the second case (i.e., PLS in Malagouzia) the absorbance spectra case were utilized with a noteworthy performance, very close to the CNN model.
3.4. Important Wavelengths
3.4.1. Pre-Hoc Analysis
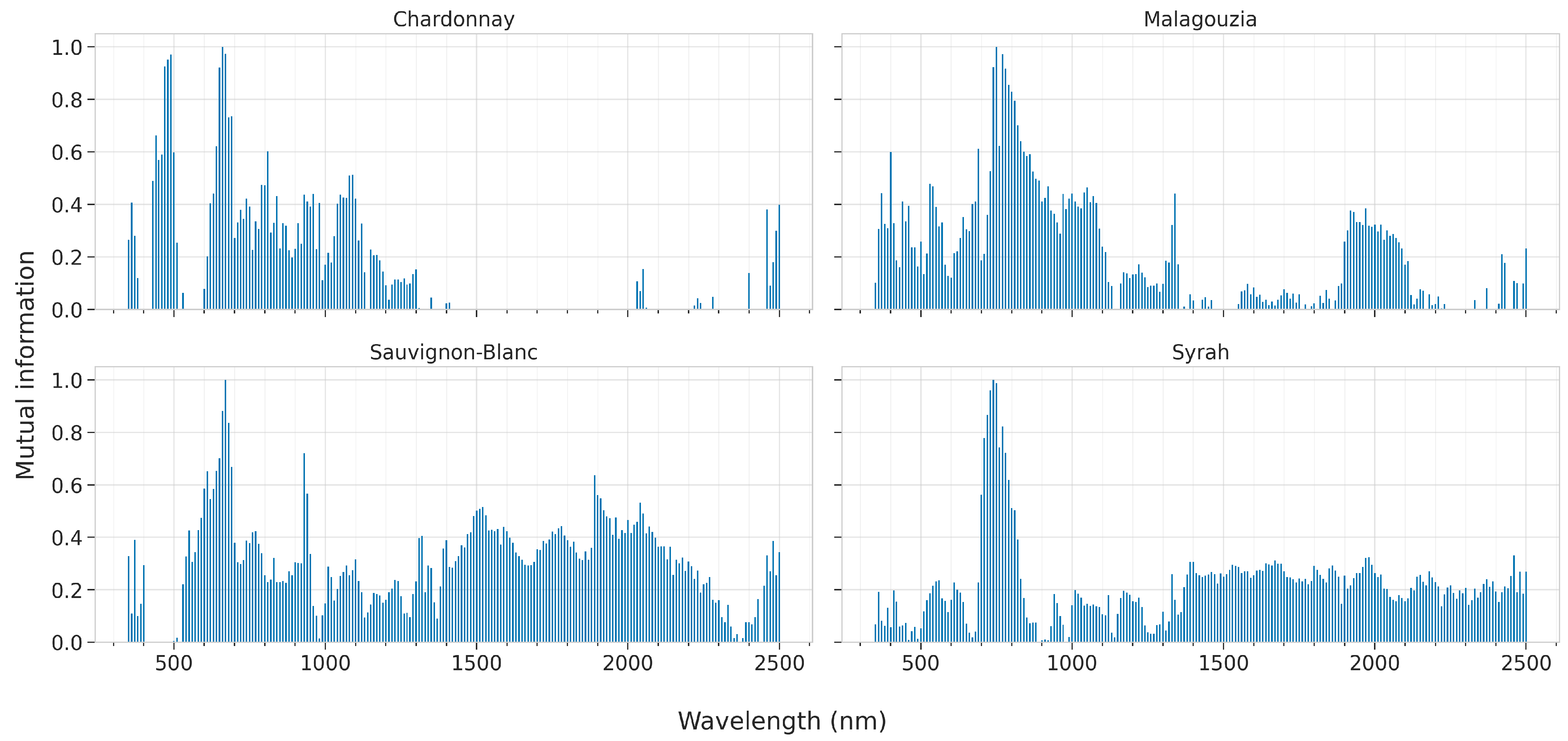
The results of the mutual information criterion, which is calculated before any model fit, are presented in
Figure 11. This figure suggests that the exact peaks which indicate the most informative wavelengths are not unique across all spectral varieties. Indeed, for Malagouzia, the most important spectral region appears to be centered around 730 nm. For Chardonnay, two distinct spectral regions are at about 490 and 660 nm. The results from Sauvignon-Blanc also indicate the spectral region of 670 nm to be important, while two more peaks at 930 and 1890 nm also suggest that there are some regions in the upper NIR and SWIR that could be relevant. Finally, for the only red-grape variety, namely Syrah, the most important region is also at about 730 nm (like for the Malagouzia variety).
3.4.2. Post-Hoc Analysis
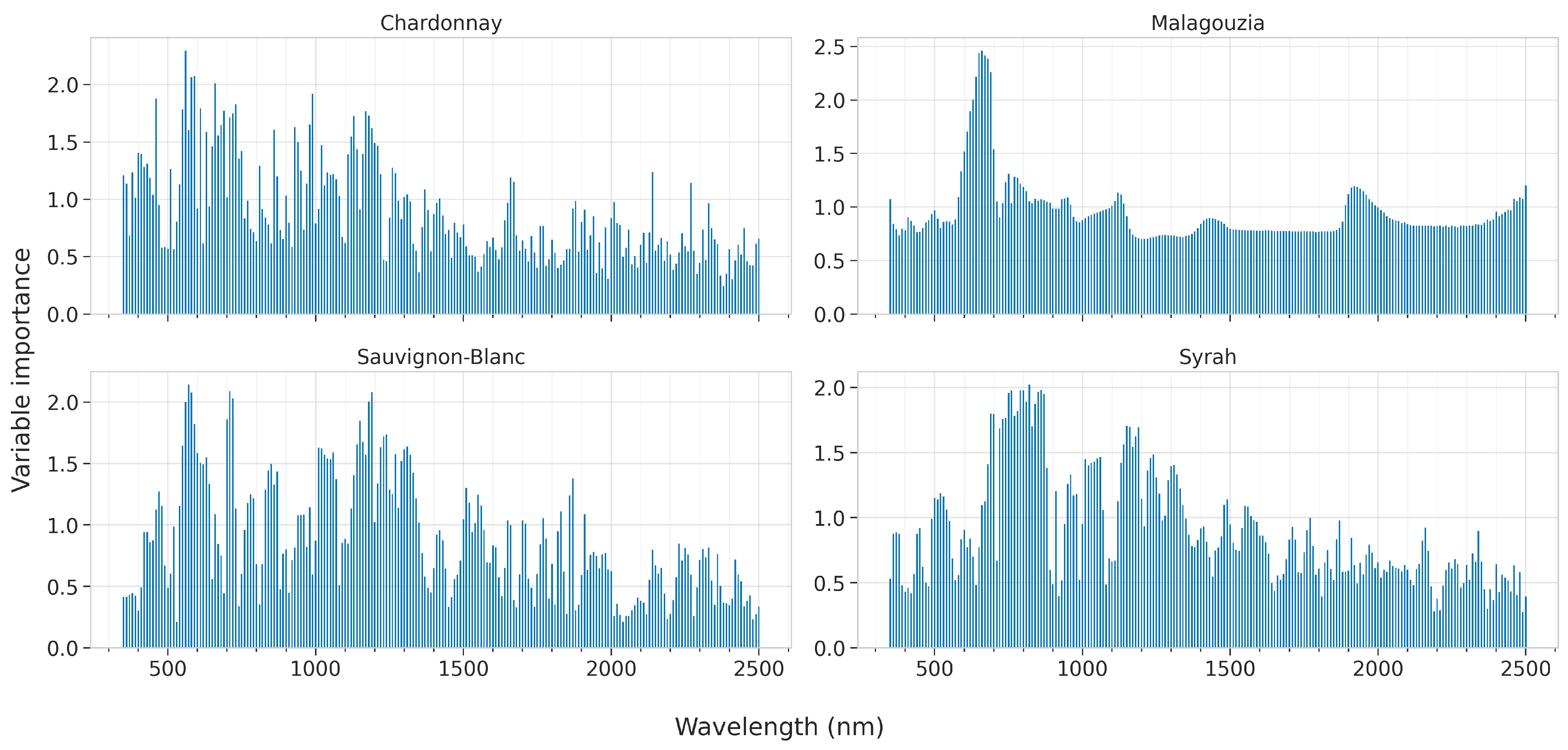
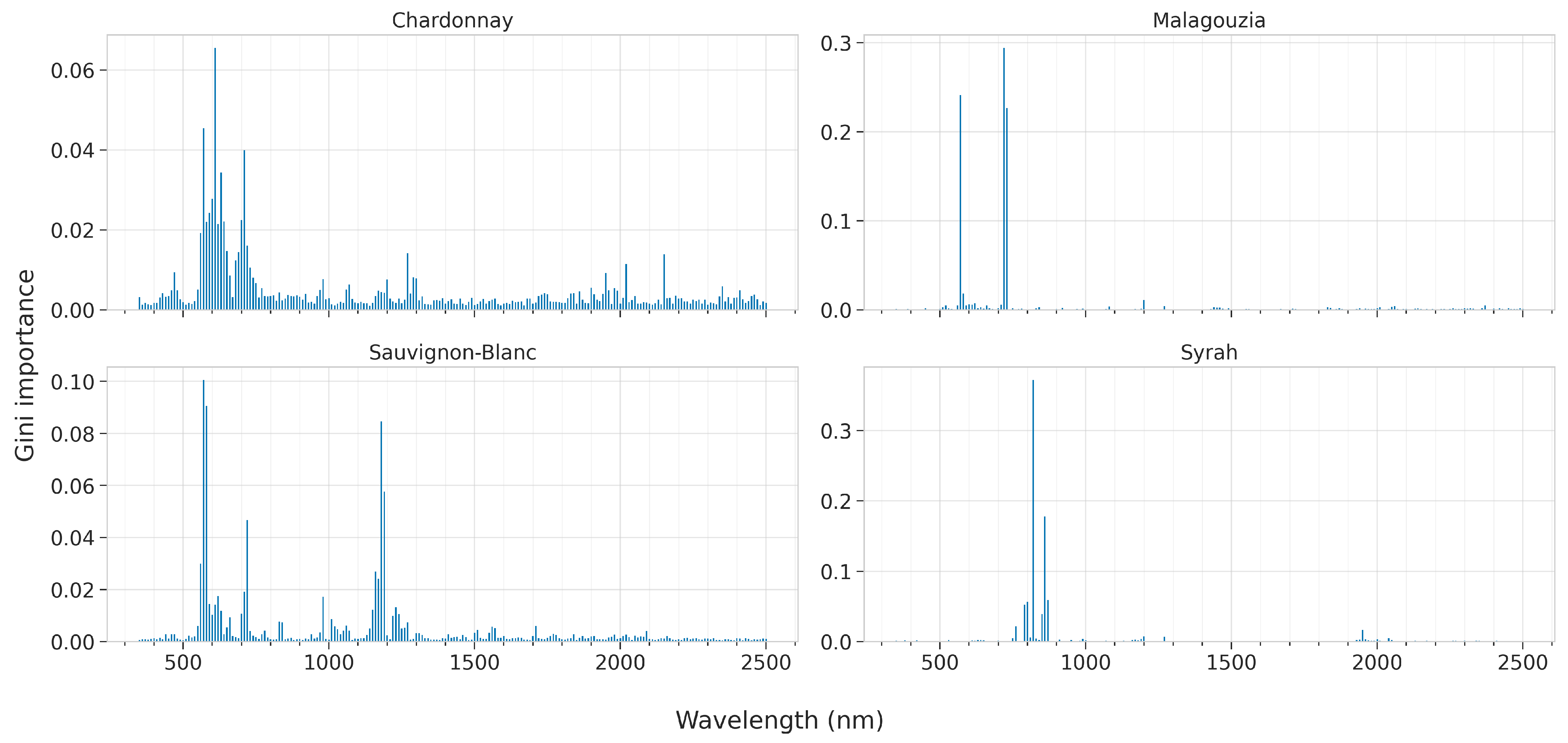
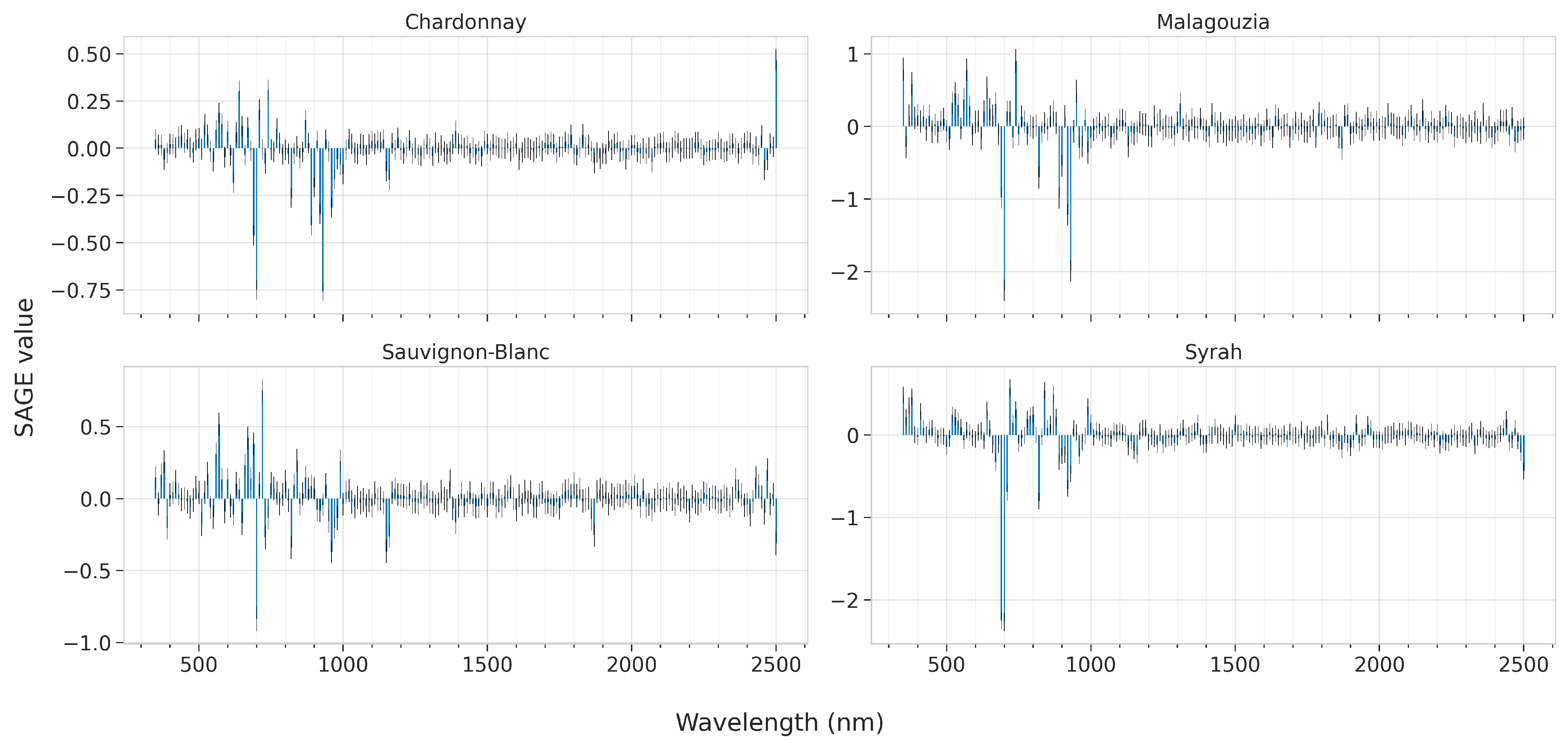
In this section we present the results of the feature importances as ascribed by the best models for each learning algorithm, across all four grape varieties. These are presented in
Figure 12 for PLS by plotting the VIP scores,
Figure 13 for RF by visualizing the Gini score, and
Figure 14 and
Figure 15 for SVR and CNN, respectively, by plotting the SAGE values.
It is evident that PLS has produced feature rankings that are not entirely sparse, although some feature ranges and peaks may be identified even in this case. For Chardonnay, the VIP scores indicate that there are many areas which the model uses, and coupled with its low accuracy we can conclude that the model does not successfully model the relationship between spectrum and sugar content. With respect to Malagouzia, the most important appear to be centered around 670 nm, with lower importance given to 750, 1210, and 1920 nm. In regard to Sauvignon-Blanc, important peaks may be identified almost throughout the entire spectrum. The most significant of those are at 570, 710, 850, 1010, 1190, and 1870 nm. Similarly, in Syrah, there are multiple peaks with the areas centered around 800 and 1150 nm deemed to be the most significant.
For RF, the feature ranking produces much clearer results as there is greater sparsity and there are dominant peaks (
Figure 13). In particular, for the Chardonnay variety, the most important wavelengths are 570, 610, 630, and 710 nm. It should be noted though, that for this variety, RF did not attain high accuracy. For Malagouzia, 570, 610, and 620 nm are ranked the highest, while for Sauvginon-Blanc 570, 720 and 1180 nm are the more pronounced. Finally, for Syrah, the most important wavelengths are 820 and 860 nm. Taking into consideration that RF attains the best results using the first derivative, the actual absorption bands may be slightly shifted in either direction of these identified bands.
The SAGE values for SVR are also quite sparse (
Figure 14). For Chardonnay, the top-ranked features are at 570, 690, and at 2500 nm. This latter finding is interesting given that it lies at the very edge of the spectrum. Indeed, if
Figure 7 is observed, there is a distinct difference in the spectral albedo starting from approximately 1100 nm until the edge of the spectrum, where it appears to be slightly more pronounced. As far as the Malagouzia variety is concerned, SVR regards as important the 570, 710, 960, 1000, and 1150 nm. A small (yet not essential) importance is ascribed also at 2470 nm. For Sauvignon-Blanc, SAGE indicates that 570, 710 and 2470 nm are the most significant; i.e., also using a band in SWIR to better model the input–output association. Finally, for Syrah, the most essential features are at 690 and 760 nm, while also the 2480 nm are noted, albeit with lower emphasis.
The SAGE values for the CNN model may also be characterized as sparse, with sharp peaks denoting crucial features (
Figure 15). For Chardonnay, the three most important peaks are at 690, 930, and 2500 nm. The Malagouzia variety is modeled mostly via the 350, 580, 700, and 930 nm features. In Sauvignon-Blanc, where the CNN model attains the best accuracy and has the highest RPIQ difference from the other models, the important wavelengths are at 570, 700, 720, 960, and 1150 nm. Some noteworthy peaks are also at 670, 690, 820, and 2500 nm. Finally, the most decisive results are for the Syrah variety, where the area around 700 nm is considered highly important, with lower emphasis given in the visible part (350 to 380 nm, at the edge between ultraviolet and violet) and at 820 and 920 nm.
4. Discussion and Conclusions
The present study expands existing the approaches which aim to predict the sugar content of wine grapes to assess their maturity stage by using in situ spectral measurements. The spectral data were collected in the field using the contact probe of a spectrometer covering the VNIR–SWIR range (350 to 2500 nm), while four different varieties were covered. Following this, four learning algorithms were applied to predict the sugar content from the spectra, while accordingly nine spectral sources were considered (i.e., generated via spectral pre-processing). To assess the effectiveness of the models, a cross-validation technique ensured that the accuracy results are reported more robustly. Finally, a pre-hoc and a post-hoc interpretability analysis took place to identify the wavelengths and spectral regions deemed important by the best-performing models.
The accuracy results were promising for three varieties (Malagouzia, Sauvignon-Blanc, and Syrah) with an average
and
across the five folds for the best-performing models. In the fourth variety, namely Chardonnay, the results were acceptable with an average
and
. The best results were attained using mostly first-derivative spectra (either from the raw reflectance or from the pseudo-absorbance transformation), while the best learning algorithm was the CNN for three out of four varieties with SVR slightly outperforming the CNN model for Chardonnay. The worse results of Chardonnay, when compared to the other varieties, may be attributed to the lower variance recorded in the physical sample (see, e.g.,
Figure 5), where there is a lack of samples with low sugar content.
Compared to other studies, our results are in accord with the literature in terms of accuracy of prediction. Arana et al. [
12] examined two varieties (namely, Viura and Chardonnay) in the 800–2500 nm range, with the best results being in the Chardonnay variety with
. Excellent results were reported in the work of Larrain et al. [
21], with an average
of 0.90 across six varieties—where notably the worst performance was recorded in the Chardonnay variety (
)—while the spectral region analyzed was 640–1100 nm. The study of Beghi et al. [
13] attained an
of 0.62 for the Corvina cultivar using the 400–1000 nm spectral range and intact grapes. Daniels et al. [
50] reported an
of 0.76 for Sultana (also known as Thompson Seedless) table grapes, by recording whole bunches in the 800–2500 nm range in the laboratory. Using samples from across different grape varieties and stages of maturity, González-Caballero et al. [
15] attained an
of 0.9 while recording the 380–1700 nm spectral range.
In terms of feature importance, both pre- and post-hoc interpretability analysis identified mostly distinct wavelengths in the visible and near infrared. It should be noted that the dissolved solids in the aqueous solution of the grape juice, which are measured by the degrees of Brix, are primarily composed of glucose and fructose. The absorption bands due to O–H and C–H groups in those largely influence the spectral variation [
51]. Moreover, another point that ought to be mentioned, is that the best models were developed using first-derivative spectra, therefore our identified wavelengths are located with a slight offset from the true absorption band. Coupled with the broad absorption bands even at the fundamental frequency [
51], it is evident that no exact wavelength corresponding to a specific peak may be pointed out. Nevertheless, some wider areas have been identified by the best models. More concretely, the models in the present study mainly focus on 570–630 nm and 670–730 nm. The first region corresponds to the 5th overtone of O–H, while the latter to the 5th overtone of C–H and the [
52]. On a smaller scale, the models identified the 800–860 nm region (possibly due to the second overtone of the O–H combination band [
53]), 920–960 nm (overtones of O–H and C–H stretching bands), and the 1150–1200 nm region (overtones of O–H combinations and C–H stretching). Finally, the 2470–2500 nm band region identified by our models may be ascribed to C–H stretching and C–C and C–O–C stretching combinations found in polysaccharides (which produce constituent sugars) [
52].
Compared to other studies, our findings regarding the most important wavelengths are similar. González-Caballero et al. [
15] report the 728, 948, 976, 1138, and 1384 nm as important for TSS estimation across different wine grape varieties. In Ref. [
23], it was determined that the most important wavelengths were 670, 730, and 780 nm for the Nebbiolo red wine grape variety. Kemps et al. [
54] suggest that the 700 nm are important for three varieties (namely, Cabernet Sauvignon, Merlot, and Syrah) with the model for the Syrah variety also making use of the 1190 and 1400 nm. Another study that analyzed sucrose, glucose, and fructose [
51] determined that the O–H bonds at 740, 770, 960, and 984 nm are correlated with sugar content, while C–H bonds at 910 and around 1015 are also significant. Similar results have also been reported for the sugar content determination of other fruits as well. For example, for the pomegranate fruit, the 780 and 950 nm have been identified [
55]. For strawberry, the 580, 680, and 960 nm were shown to be important for TSS [
56]. The apples’ sugar content was also determined via the 680 and 940 nm [
57,
58]. The above results are in accordance with our identified wavelengths, suggesting that our models have identified strong correlations between the input (diffuse reflectance spectra) and output (°Brix, or sugar content).
The current study is a proof of concept for crop assessment based on the exploitation of in situ spectral data and artificial intelligence methods to smartly capture information in real field conditions. Furthermore, it also takes into account the evaluation of different pre-processing and methods to estimate the feature importance, to further enhance the knowledge of the AI models’ capacity to capture different patterns in the spectral signatures, as highlighted by Silva et.al. [
59]. This is just the beginning of what is expected to be a revolution in the way the agricultural robotic industry is operated. The grape spectral library, the insights from the feature selection and the novel CNN framework presented here can be the basis for automated in situ ripeness determination and selective harvesting utilizing edge computing techniques by (i) providing improvement in production leaving unripe products in the field to mature whilst identifying the ripe ones, and (ii) enabling some human-like activities to be performed by robots [
60].
In the future, work can focus on using miniaturized NIR sensors that connect to mobile devices [
9], or on hyperspectral cameras mounted on robotic platforms [
61] having as a goal to automate the harvesting procedure [
62]. More samples may also be recorded for the Chardonnay variety, particularly when the sugar content is low, to ascertain if the spectral model can improve in terms of prediction accuracy. Another option to enhance the prediction accuracy in the Chardonnay variety would be to utilize feature selection or dimensionality reduction techniques [
63], including the simultaneous usage of multiple spectral pre-treatments and autoencoders [
64] to compress the useful spectral information. Finally, the VNIR–SWIR spectra may be used to further estimate other maturity and oenological parameters, suchas the pH content and titratable acidity, to provide more robust ripeness estimation [
17], potentially using multi-output CNNs.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













