

Feature Attribution Analysis to Quantify the Impact of Oceanographic and Maneuverability Factors on Vessel Shaft Power Using Explainable Tree-Based Model


Abstract
1. Introduction
- The vessel sails against sea resistance by adjusting its engine operation which generates the shaft power to drive the propeller. Is it possible to predict the vessel shaft power considering the influence of uncontrollable variables such as the oceanographic factors and also the controllable variables such as the maneuverability factors?
- Among the uncontrollable and controllable variables affecting the generation of vessel shaft power, what factors deploy the significant influence and how?
- Does a different vessel voyage (trip) change the important factors affecting the vessel shaft power?
2. Data Description
3. Research Methodologies
3.1. Machine Learning Prediction
3.1.1. Tree-Based Regressor Comparative Study
3.1.2. Performance Evaluation
- Mean Absolute Error (MAE)
- 2.
- Root Mean Squared Error (RMSE)
- 3.
- Mean Absolute Percentage Error (MAPE)
- 4.
- R2 or R-squared (Coefficient of Determination)
3.2. Explainable Artificial Intelligence
3.3. Experimental Framework
4. Experimental Results and Discussion
4.1. Data Preprocessing
- Features selection
- 2.
- Data filtering
- 3.
- Features transformation
4.2. Prediction Results
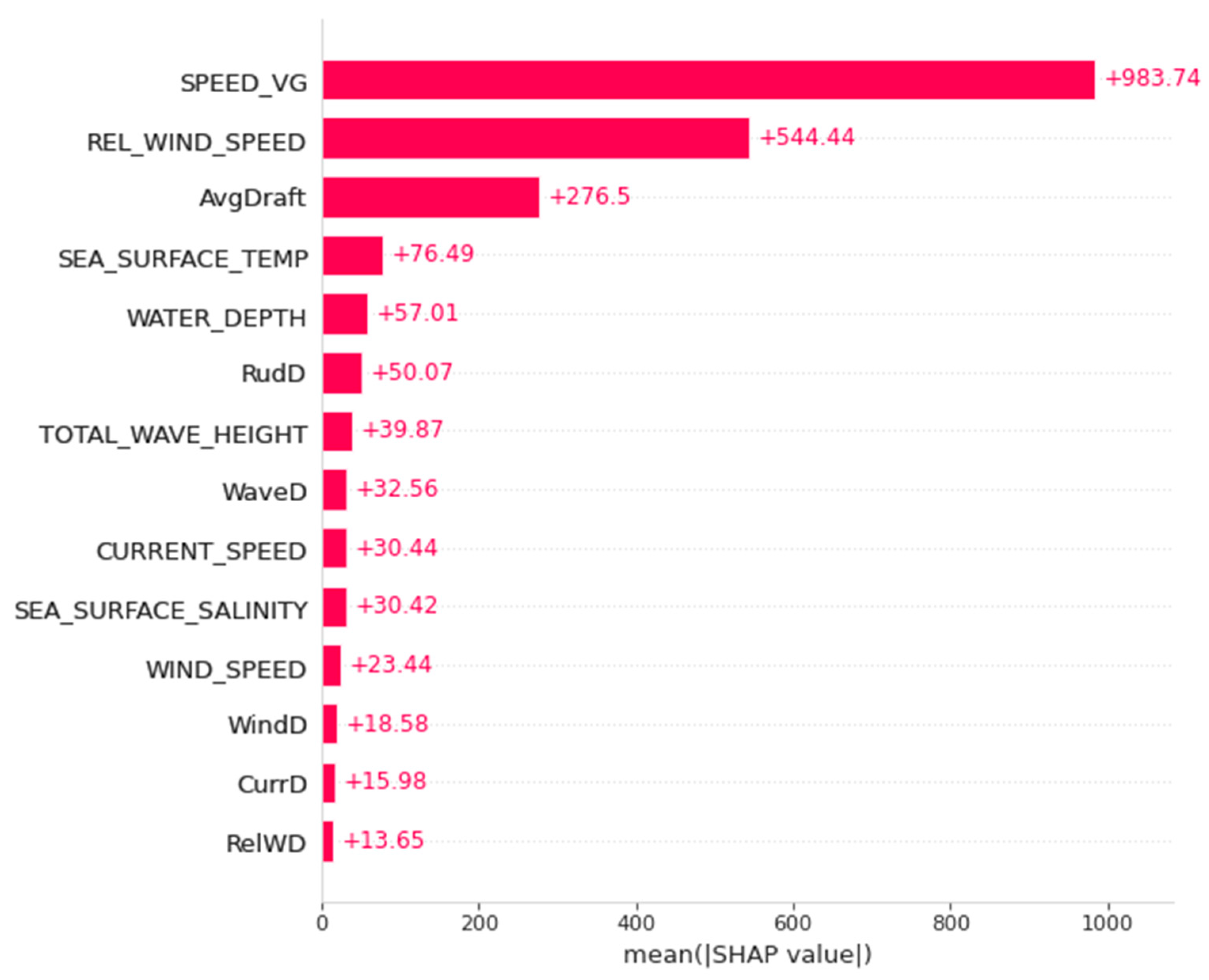
4.3. Explainable Machine Learning with SHAP
5. Conclusions
- Is it possible to predict the vessel shaft power considering the influence of uncontrollable variables such as the oceanographic factors and also the controllable variables such as the maneuverability factors?
- Among the uncontrollable and controllable variables affecting the generation of vessel shaft power, what factors deploy the significant influence and how?
- Does a different vessel voyage (trip) change the important factors affecting the vessel shaft power?
Author Contributions
Funding
Conflicts of Interest
References
- Cullinane, K.; Cullinane, S. Atmospheric Emissions from Shipping: The Need for Regulation and Approaches to Compliance. Transp. Rev. 2013, 33, 377–401. [Google Scholar] [CrossRef]
- International Maritime Organization. Fourth IMO Greenhouse Gas Study 2020; International Maritime Organization: London, UK, 2020. [Google Scholar]
- Zheng, W.; Makhloufi, A.; Chen, Y.; Tang, J. Decarbonizing the International Shipping Industry: Solutions and Policy Recommendations. Mar. Pollut. Bull. 2018, 126, 428–435. [Google Scholar]
- Soultatis, C. Systems Modeling for Electric Ship Design; Massachusetts Institute of Technology: Cambridge, MA, USA, 2004. [Google Scholar]
- Zhang, C.; Bin, J.; Wang, W.; Peng, X.; Wang, R.; Halldearn, R.; Liu, Z. AIS Data Driven General Vessel Destination Prediction: A Random Forest Based Approach. Transp. Res. Part C Emerg. Technol. 2020, 118, 102729. [Google Scholar] [CrossRef]
- Holtrop, J. A Statistical Analysis of Performance Test Results. Int. Shipbuild. Prog. 1977, 24, 23–28. [Google Scholar] [CrossRef]
- Holtrop, J. A Statistical Re-analysis of Resistance and Propulsion Data. Int. Shipbuild. Prog. 1984, 31, 272–276. [Google Scholar]
- Holtrop, J.; Mennen, G. A Statistical Power Prediction Method. Int. Shipbuild. Prog. 1978, 25, 253–256. [Google Scholar] [CrossRef]
- Holtrop, J.; Mennen, G. An Approximate Power Prediction Method. Int. Shipbuild. Prog. 1982, 29, 166–170. [Google Scholar] [CrossRef]
- Petersen, J.P.; Jacobsen, D.J.; Winther, O. Statistical Modeling for Ship Propulsion Efficiency. J. Mar. Sci. Technol. 2012, 17, 20–39. [Google Scholar] [CrossRef]
- Petersen, J.P.; Winther, O.; Jacobsen, D.J. A Machine-Learning Approach to Predict Main Energy Consumption under Realistic Operational Conditions. Ship Technol. Res. 2012, 59, 64–72. [Google Scholar] [CrossRef]
- Radonjic, A.; Vukadinovic, K. Application of Ensemble Neural Networks to Pediction of Towboat Shaft Power. J. Mar. Sci. Technol. 2014, 20, 64–80. [Google Scholar] [CrossRef]
- Coraddu, A.; Oneto, L.; Baldi, F.; Anguita, D. Vessel Fuel Consumption Forecast and Trim Optimisation: A Data Analytics Perspective. Ocean Eng. 2017, 130, 351–370. [Google Scholar] [CrossRef]
- Kim, D.-H.; Han, S.-J.; Jung, B.-K.; Han, S.-H.; Lee, S.-B. A Machine Learning-Based Method to Predict Engine Power. J. Korean Soc. Mar. Environ. Saf. 2019, 25, 851–857. [Google Scholar] [CrossRef]
- Kim, D.-H.; Lee, S.-B.; Lee, J.-H. Data-Driven Prediction of Vessel Propulsion Power Using Support Vector Regression with Onboard Measurement and Ocean Data. Sensors 2020, 20, 1588. [Google Scholar] [CrossRef] [PubMed]
- Lang, X.; Wu, D.; Mao, W. Benchmark Study of Supervised Machine Learning Methods for a Ship Speed-Power Prediction at Sea. In Proceedings of the ASME 40th International Conference on Ocean, Offshore, and Arctic Engineering, Virtual, 21–30 June 2021. [Google Scholar]
- Laurie, A.; Anderlini, E.; Dietz, J.; Thomas, G. Machine learning for shaft power prediction and analysis of fouling related performance deterioration. Ocean Eng. 2021, 234, 108886. [Google Scholar] [CrossRef]
- Khosravi, H.; Shum, S.B.; Chen, G.; Conati, C.; Tsai, Y.-S.; Kay, J.; Knight, S.; Martinez-Maldonado, R.; Sadiq, S.; Gašević, D. Explainable Artificial Intelligence in education. Comput. Educ. Artif. Intell. 2022, 3, 100074. [Google Scholar] [CrossRef]
- Jacinto, M.; Silva, M.; Medeiros, G.; Oliveira, L.; Montalvão, L.; de Almeida, R.V.; Ninci, B. Explainable Artificial Intelligence for O&G Machine Learning Solutions: An Application to Lithology Prediction. In Proceedings of the 83rd EAGE Annual Conference & Exhibition, Madrid, Spain, 6–9 June 2022. [Google Scholar]
- Ali, A.; Aliyuda, K.; Elmitwally, N.; Bello, A.M. Towards more accurate and explainable supervised learning-based prediction of deliverability for underground natural gas storage. Appl. Energy 2022, 327, 120098. [Google Scholar] [CrossRef]
- Cohausz, L. Towards Real Interpretability of Student Success Prediction Combining Methods of XAI and Social Science. In Proceedings of the International Conference on Educational Data Mining (EDM), Durham, UK, 24–27 July 2022. [Google Scholar]
- Abioye, S.O.; Oyedele, L.O.; Akanbi, L.; Ajayi, A.; Delgado, J.M.D.; Bilal, M.; Akinade, O.O.; Ahmed, A. Artificial intelligence in the construction industry: A review of present status, opportunities and future challenges. J. Build. Eng. 2021, 44, 103299. [Google Scholar] [CrossRef]
- Love, P.E.; Fang, W.; Matthews, J.; Porter, S.; Luo, H.; Ding, L. Explainable Artificial Intelligence (XAI): Precepts, Methods, and Opportunities for Research in Construction. arXiv 2022, arXiv:2211.06579. [Google Scholar]
- Gaur, L.; Sahoo, B.M. Introduction to Explainable AI and Intelligent Transportation. In Explainable Artificial Intelligence for Intelligent Transportation Systems; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Procopiou, A.; Chen, T.M. Explainable AI in Machine/Deep Learning for Intrusion Detection in Intelligent Transportation Systems for Smart Cities. In Explainable Artificial Intelligence for Smart Cities; CRC Press: Boca Raton, FL, USA, 2021; pp. 297–321. [Google Scholar]
- Chaddad, A.; Peng, J.; Xu, J.; Bouridane, A. Survey of Explainable AI Techniques in Healthcare. Sensors 2023, 23, 634. [Google Scholar] [CrossRef]
- Sheu, R.-K.; Pardeshi, M.S. A Survey on Medical Explainable AI (XAI): Recent Progress, Explainability Approach, Human Interaction and Scoring System. Sensors 2022, 22, 8068. [Google Scholar] [CrossRef]
- Shin, D. The effects of explainability and causability on perception, trust, and acceptance: Implications for explainable AI. Int. J. Hum. Comput. Stud. 2021, 146, 102551. [Google Scholar] [CrossRef]
- Limna, P. Artificial Intelligence (AI) in the Hospitality Industry: A Review Article. Int. J. Comput. Sci. Res. 2022, 6, 1–12. [Google Scholar]
- Hrnjica, A.; Softic, S. Explainable AI in Manufacturing: A Predictive Maintenance Case Study. In Proceedings of the IFIP International Conference on Advances in Production Management Systems, Novi Sad, Serbia, 30 August–3 September 2020. [Google Scholar]
- Hore, S.; Bhattacharya, T. A Smart System for the Assessment of Genuineness or Trustworthiness of the Tip-Off Using Audio Signals: An Explainable AI Approach. In Explainable AI: Foundations, Methodologies and Applications. Intelligent Systems Reference Library; Springer: Cham, Switzerland, 2022; pp. 185–209. [Google Scholar]
- Atkinson, K.; Bench-Capon, T.; Bollegala, D. Explanation in AI and law: Past, present, and future. Artif. Intell. 2020, 289, 103387. [Google Scholar] [CrossRef]
- Giudici, P.; Raffinetti, E. Explainable AI methods in cyber risk management. Qual. Reliab. Eng. Int. 2022, 38, 1318–1326. [Google Scholar] [CrossRef]
- Sachan, S.; Yang, J.-B.; Xu, D.-l.; Benavides, D.E.; Li, Y. An explainable AI decision-support-system to automate loan underwriting. Expert Syst. Appl. 2020, 144, 113100. [Google Scholar] [CrossRef]
- Misheva, H.; Osterrieder, J.; Hirsa, A.; Kulkarni, O.; Lin, S.F. Explainable AI in Credit Risk Management. arXiv 2021, arXiv:2103.00949. [Google Scholar]
- Kim, D.; Antariksa, G.; Handayani, M.P.; Lee, S.; Lee, J. Explainable Anomaly Detection Framework for Maritime Main Engine Sensor Data. Sensors 2021, 21, 5200. [Google Scholar] [CrossRef] [PubMed]
- Opitz, A.; Maclin, R. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Ke, A.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A Comparative Analysis of Gradient Boosting Algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Sammut, A.; Webb, G.I.W. Encyclopedia of Machine Learning; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Hancock, R.; Freeman, M.J. Power and Sample Size for the Root Mean Square Error of Approximation Test of not Close Fit in Structural Equation Modeling. Educ. Psychol. Meas. 2001, 61, 741–758. [Google Scholar] [CrossRef]
- de Myttenaere, A.; Golden, B.; Grand, B.L.; Rossi, F. Mean Absolute Percentage Error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef] [PubMed]
- Wright, S. Correlation and causation. J. Agric. Res. USDA 1921, 557–585. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the KDD ‘16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI Conference of Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Shapley, L. A Value for n-person Games. In Contribution to the Theory of Games II; Kuhn, H., Tucker, A., Eds.; Princeton University Press: Princeton, NJ, USA, 1953; pp. 307–317. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From Local Explanations to Global Understanding with Explainable AI for Trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. Explainable AI for Trees: From Local Explanations to Global Understanding. arXiv 2019, arXiv:1905.04610. [Google Scholar] [CrossRef]
- Li, Z. Extracting spatial effects from machine learning model using local interpretation method: An example of SHAP and XGBoost. Comput. Environ. Urban Syst. 2022, 96, 101845. [Google Scholar] [CrossRef]
- Lundberg, S. SHAP. 2018. Available online: https://shap.readthedocs.io/ (accessed on 28 November 2022).
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specification | Measurement |
|---|---|
| Length (m) | 172.07 |
| Beam (m) | 27.4 |
| Gross Tonnage | 18,085 |
| Deadweight (t) | 22,317 |
| TEU | 1809 |
| Year Build | 2020 |
| Feature Name | Description |
|---|---|
| ME1_SHAFT_POWER | Propeller shaft power of the vessel |
| SPEED_VG | Speed over ground |
| DRAFT_FORE | Vertical distance between the waterline and the bottom of the hull measured at the perpendicular of the bow |
| DRAFT_AFT | Vertical distance between the waterline and the bottom of the hull measured at the perpendicular of the stern |
| SHIP_HEADING | Direction of which the vessel is sailing |
| TOTAL_WAVE_HEIGHT | Vertical distance between the crest (peak) and the trough of a wave |
| TOTAL_WAVE_DIRECTION | Direction of which the wave is moving |
| CURRENT_SPEED | Directional movement of seawater driven by gravity, wind (Coriolis Effect), and water density |
| CURRENT_DIRECTION | Direction of seawater |
| WIND_SPEED | Speed of the geographic or ground wind, assuming no tidal flow |
| WIND_DIRECTION | Direction of the geographic or ground wind |
| REL_WIND_SPEED | Speed of the apparent wind |
| REL_WIND_DIR | Direction of the apparent wind |
| RUDDER_ANGLE | The angle of the vessel rudder |
| WATER_DEPTH | The depth of water where the ship sails |
| SEA_SURFACE_SALINITY | Amount of salt on the body of the seawater |
| SEA_SURFACE_TEMP | Temperature on the seawater |
| Feature Name | Min | Mean | Max | Standard Deviation |
|---|---|---|---|---|
| ME1_SHAFT_POWER | 0 | 4072.26 | 9681.59 | 2920.40 |
| SPEED_VG | −9999.00 | 11.4821 | 22.4 | 47.9097 |
| REL_WIND_SPEED | −9999.00 | 7.4492 | 29.524 | 111.215 |
| REL_WIND_DIR | −9999.00 | 184.9379 | 360 | 181.6887 |
| DRAFT_FORE | 2.633 | 7.5792 | 10.297 | 1.4717 |
| DRAFT_AFT | 5.707 | 8.1147 | 10.071 | 0.8196 |
| SHIP_HEADING | −9999.00 | 144.976 | 359.998 | 135.9825 |
| TOTAL_WAVE_HEIGHT | −9999.00 | −141.738 | 8889.15 | 1188.97 |
| TOTAL_WAVE_DIRECTION | −9999.00 | 5.8528 | 360 | 1208.92 |
| CURRENT_SPEED | −9999.00 | −142.8992 | 1.89 | 1187.64 |
| CURRENT_DIRECTION | −9999.00 | 30.8615 | 360 | 1212.59 |
| WIND_SPEED | −9999.00 | −136.9188 | 27.25 | 1188.37 |
| WIND_DIRECTION | −9999.00 | 5.4583 | 360 | 1209.35 |
| RUDDER_ANGLE | −9999.00 | −24.8728 | 36.8 | 512.351 |
| WATER_DEPTH | −9999.00 | −1341.97 | 834.6 | 3469.26 |
| SEA_SURFACE_SALINITY | −9999.00 | −111.0224 | 34.68 | 1191.48 |
| SEA_SURFACE_TEMP | −9999.00 | −120.9845 | 32.93 | 1190.31 |
| Feature | Error Instances Count | Error Ratio (%) |
|---|---|---|
| ME1_SHAFT_POWER | 0 | 0.00 |
| SPEED_VG | 2 | 0.00 |
| DRAFT_FORE | 0 | 0.00 |
| DRAFT_AFT | 0 | 0.00 |
| SHIP_HEADING | 7 | 0.01 |
| TOTAL_WAVE_HEIGHT | 1278 | 1.43 |
| TOTAL_WAVE_DIRECTION | 1278 | 1.43 |
| CURRENT_SPEED | 1278 | 1.43 |
| CURRENT_DIRECTION | 1278 | 1.43 |
| WIND_SPEED | 1278 | 1.43 |
| WIND_DIRECTION | 1278 | 1.43 |
| RUDDER_ANGLE | 235 | 0.26 |
| SEA_SURFACE_SALINITY | 1278 | 1.43 |
| SEA_SURFACE_TEMP | 1278 | 1.43 |
| REL_WIND_SPEED | 11 | 0.01 |
| REL_WIND_DIR | 11 | 0.01 |
| WATER_DEPTH | 12,352 | 13.83 |
| Feature Name | Min | Mean | Max | Standard Deviation |
|---|---|---|---|---|
| ME1_SHAFT_POWER | 0 | 3810.3591 | 9681.594 | 2939.5802 |
| SPEED_VG | 0 | 11.0992 | 22.4 | 7.2974 |
| REL_WIND_SPEED | 0 | 8.5606 | 29.524 | 5.7281 |
| REL_WIND_DIR | 0 | 187.1479 | 360 | 141.6656 |
| DRAFT_FORE | 2.633 | 7.4488 | 10.297 | 1.4857 |
| DRAFT_AFT | 5.707 | 8.0631 | 10.071 | 0.8459 |
| SHIP_HEADING | 0 | 148.0478 | 359.998 | 102.9816 |
| TOTAL_WAVE_HEIGHT | 0.01 | 0.9648 | 5.97 | 0.8011 |
| TOTAL_WAVE_DIRECTION | 0.01 | 158.9932 | 360 | 91.5081 |
| CURRENT_SPEED | 0 | 0.184 | 1.89 | 0.1725 |
| CURRENT_DIRECTION | 0 | 176.6547 | 360 | 99.3439 |
| WIND_SPEED | 0.03 | 6.1868 | 27.25 | 3.6007 |
| WIND_DIRECTION | 0 | 156.57 | 360.00 | 97.79 |
| RUDDER_ANGLE | −34.7 | 1.4153 | 36.8 | 1.8461 |
| WATER_DEPTH | 0.7 | 48.3948 | 834.6 | 75.1042 |
| SEA_SURFACE_SALINITY | 17.57 | 32.3563 | 34.68 | 2.3481 |
| SEA_SURFACE_TEMP | −1.72 | 21.6276 | 32.62 | 8.2854 |
| Feature Name | Description |
|---|---|
| ME1_SHAFT_POWER | Propeller shaft power of the vessel |
| SPEED_VG | Speed over ground |
| TOTAL_WAVE_HEIGHT | Vertical distance between the crest (peak) and the trough of a wave |
| CURRENT_SPEED | Directional movement of seawater driven by gravity, wind (Coriolis Effect), and water density |
| WIND_SPEED | Speed of the geographic or ground wind, assuming no tidal flow |
| REL_WIND_SPEED | Speed of the apparent wind |
| WATER_DEPTH | The depth of water where the ship sails |
| SEA_SURFACE_SALINITY | Amount of salt on the body of the seawater |
| SEA_SURFACE_TEMP | Temperature on the seawater |
| AvgDraft 1 | Averaged value of DRAFT_FORE and DRAFT_AFT |
| CurrD 1 | Angular difference between SHIP_HEADING and CURRENT_DIRECTION |
| WaveD 1 | Angular difference between SHIP_HEADING and TOTAL_WAVE_DIRECTION |
| WindD 1 | Angular difference between SHIP_HEADING and WIND_DIRECTION |
| RelWD 1 | Angular difference between SHIP_HEADING and REL_WIND_DIR |
| RudD 1 | Angular difference between SHIP_HEADING and RUDDER_ANGLE |
| Model | Parameters | ||
|---|---|---|---|
| Grid Parameters | Grid Values | Tuned Values | |
| Random Forest Regressor | n_estimators max_depth min_samples_split min_samples_leaf | : [10,25,50,75,100] : [10,25,50,75,100] : [2,4,6,8,10] : [1,2,3,4,5] | {n_estimators: 100}, {max_depth: 25}, {min_samples_split: 2}, {min_samples_leaf: 1} |
| CatBoost Regressor | depth learning_rate iterations | : [10,25,50] : [0.1,0.5,1] : [50,100,250] | {depth: 10}, {learning_rate: 0.1}, {iterations: 250} |
| Extreme Gradient Boosting (XGB) Regressor | n_estimators max_depth learning_rate | : [50,100,150,200,250] : [5,10,25,50] : [0,0.5,1] | {n_estimators: 250}, {max_depth: 7}, {learning_rate: 0.01} |
| Light Gradient Boosting Machine (LightGBM) Regressor) | n_estimators max_depth learning_rate | : [50,75,100] : [10,50,100] : [0.05,0.1,0.5,1] | {n_estimators: 100}, {max_depth: 10}, {learning_rate: 0.5} |
| Model | R-Squared Score | RMSE | MAE | MAPE | ||||
|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | |
| Random Forest Regressor | 0.99 | 0.95 | 156.95 | 414.88 | 82.76 | 221.00 | 0.02 | 0.05 |
| CatBoost Regressor | 0.98 | 0.95 | 237.69 | 393.73 | 164.66 | 248.59 | 0.04 | 0.06 |
| Extreme Gradient Boosting (XGB) Regressor | 1.00 | 0.94 | 2.84 | 446.56 | 1.88 | 263.60 | 0.00 | 0.06 |
| Light Gradient Boosting Machine (LightGBM) Regressor) | 0.98 | 0.94 | 221.95 | 449.48 | 159.27 | 289.12 | 0.03 | 0.07 |
| Average Scoring | 0.99 | 0.95 | 154.86 | 426.16 | 102.14 | 255.58 | 0.02 | 0.06 |
| VOY.NO | #Instances | R-Squared Score | RMSE | MAE | MAPE | ||||
|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | ||
| 1 | 522 | 0.98 | 0.93 | 105.85 | 210.44 | 37.70 | 77.92 | 0.02 | 0.03 |
| 2 | 1852 | 0.99 | 0.95 | 115.49 | 302.66 | 58.23 | 146.60 | 0.02 | 0.04 |
| 3 | 2391 | 0.99 | 0.92 | 157.32 | 502.26 | 77.55 | 228.38 | 0.02 | 0.06 |
| 4 | 2367 | 0.99 | 0.92 | 158.76 | 432.59 | 75.43 | 201.87 | 0.02 | 0.05 |
| 5 | 2192 | 0.99 | 0.93 | 163.04 | 384.86 | 67.86 | 166.49 | 0.02 | 0.04 |
| 6 | 2258 | 0.99 | 0.92 | 131.93 | 351.80 | 58.13 | 155.41 | 0.02 | 0.04 |
| 7 | 2260 | 0.98 | 0.90 | 164.63 | 313.51 | 65.74 | 138.47 | 0.02 | 0.05 |
| 8 | 2458 | 0.97 | 0.79 | 156.69 | 391.22 | 62.43 | 160.65 | 0.02 | 0.05 |
| 9 | 1796 | 0.98 | 0.85 | 147.04 | 420.97 | 58.71 | 164.66 | 0.02 | 0.05 |
| 10 | 2112 | 0.99 | 0.94 | 131.45 | 339.46 | 58.26 | 148.70 | 0.02 | 0.04 |
| 11 | 2183 | 0.99 | 0.93 | 199.58 | 484.96 | 90.11 | 219.33 | 0.03 | 0.06 |
| 12 | 2064 | 0.99 | 0.94 | 134.09 | 419.91 | 68.52 | 209.99 | 0.02 | 0.06 |
| 13 | 1641 | 0.99 | 0.95 | 179.03 | 353.58 | 73.79 | 169.67 | 0.02 | 0.04 |
| 14 | 2253 | 0.99 | 0.93 | 150.80 | 376.11 | 61.88 | 179.48 | 0.02 | 0.05 |
| 15 | 2418 | 0.99 | 0.95 | 177.57 | 492.00 | 88.89 | 238.77 | 0.02 | 0.05 |
| 16 | 2065 | 0.99 | 0.93 | 183.39 | 517.22 | 99.79 | 285.36 | 0.02 | 0.07 |
| 17 | 2063 | 1.00 | 0.96 | 160.98 | 421.94 | 75.34 | 213.15 | 0.02 | 0.06 |
| 18 | 1877 | 0.99 | 0.96 | 169.40 | 448.25 | 79.10 | 214.77 | 0.02 | 0.05 |
| 19 | 560 | 0.99 | 0.93 | 147.37 | 328.36 | 74.77 | 194.51 | 0.01 | 0.03 |
| 20 | 2041 | 0.99 | 0.96 | 160.51 | 459.91 | 78.96 | 213.19 | 0.02 | 0.05 |
| 21 | 1967 | 1.00 | 0.96 | 169.01 | 456.15 | 68.84 | 195.63 | 0.02 | 0.06 |
| 22 | 1969 | 0.99 | 0.94 | 162.54 | 426.96 | 76.08 | 198.78 | 0.02 | 0.05 |
| 23 | 2773 | 0.99 | 0.95 | 164.23 | 402.20 | 74.28 | 189.41 | 0.02 | 0.05 |
| 24 | 1362 | 0.99 | 0.96 | 149.60 | 391.09 | 107.18 | 216.51 | 0.03 | 0.07 |
| Average per Voyage | 1977 | 0.99 | 0.93 | 155.85 | 401.18 | 72.40 | 188.65 | 0.02 | 0.05 |
| All Data | 47,444 | 0.99 | 0.95 | 156.95 | 414.88 | 82.76 | 221.00 | 0.02 | 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.; Handayani, M.P.; Lee, S.; Lee, J. Feature Attribution Analysis to Quantify the Impact of Oceanographic and Maneuverability Factors on Vessel Shaft Power Using Explainable Tree-Based Model. Sensors 2023, 23, 1072. https://doi.org/10.3390/s23031072
Kim D, Handayani MP, Lee S, Lee J. Feature Attribution Analysis to Quantify the Impact of Oceanographic and Maneuverability Factors on Vessel Shaft Power Using Explainable Tree-Based Model. Sensors. 2023; 23(3):1072. https://doi.org/10.3390/s23031072
Chicago/Turabian StyleKim, Donghyun, Melia Putri Handayani, Sangbong Lee, and Jihwan Lee. 2023. "Feature Attribution Analysis to Quantify the Impact of Oceanographic and Maneuverability Factors on Vessel Shaft Power Using Explainable Tree-Based Model" Sensors 23, no. 3: 1072. https://doi.org/10.3390/s23031072
APA StyleKim, D., Handayani, M. P., Lee, S., & Lee, J. (2023). Feature Attribution Analysis to Quantify the Impact of Oceanographic and Maneuverability Factors on Vessel Shaft Power Using Explainable Tree-Based Model. Sensors, 23(3), 1072. https://doi.org/10.3390/s23031072