
AI-Driven Validation of Digital Agriculture Models


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Look at predictions made by the ML model and then go to the location of said prediction and evaluate its accuracy. This requires an understanding of how many images need to be observed to have a representative idea of model behavior, which in turn requires an understanding of how well a set of images covers all possible inputs in a field. Ideally, the images to be observed would be representative of the whole field while being as few as possible.
- Assess how representative a test set is of a whole field. This is particularly important for identifying biases in a dataset. For instance, if all images on a field were taken at a certain time of day, maybe the model can learn to focus on a specific side of the image. A test set with the same bias would lead to high performance while the model would be likely to under-perform in practice. Results using a test set in which all features of the input are relevant are more likely to be representative of in-practice performance. Thus, measuring feature coverage can be an indication of the quality of a test set. Feature coverage also may be adjusted depending on the rigor needed by the farmer. A farmer could consider unnecessary that all features of a dataset are relevant and instead focus on the relevance of different regions of adjustable size. A model providing this representation assessment should adapt to different levels of quantization.
- Add images to the test set, if necessary, so that the test set is more representative. This requires quantification of how representative is a dataset and how much one input contributes to the overall representation.
- Evaluate the type of features of the input that make the model predict a certain result. While a perfect understanding might not be possible, an approximation is still useful for the farmer when making a decision. Using a separate interpretable model that learns from the original might lead to some additional knowledge on the original model.
2. Overview of System Proposed
3. Materials and Methods
3.1. Dataset
3.2. Neural Network Model
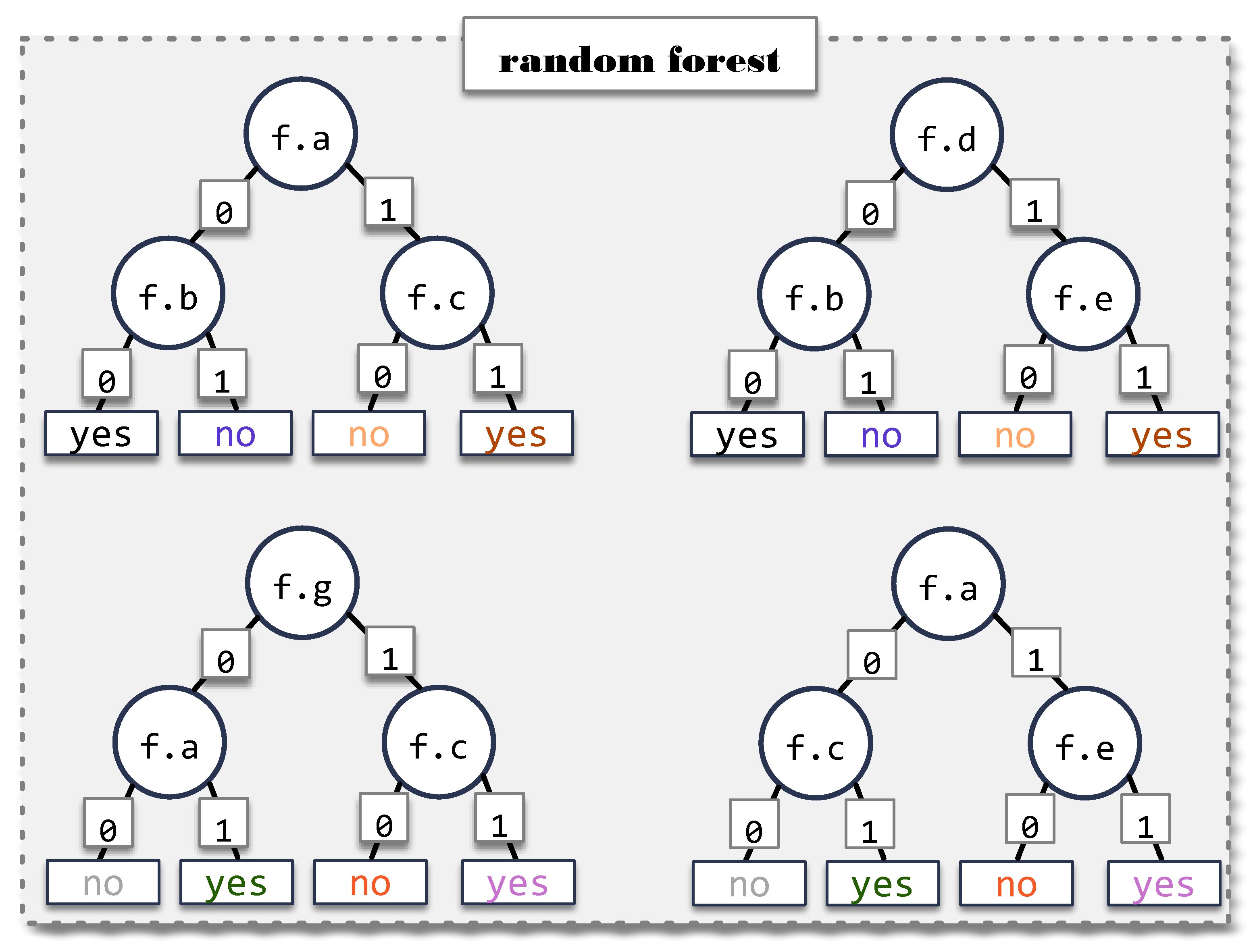
3.3. Random Forest Training
3.4. Characterization of a Neural Model through Random Forests
3.5. Quantification of Feature Coverage
3.5.1. Boundaries
3.5.2. Application
3.6. Producing a Minimal Observation Set
4. Results
5. Discussion
6. Conclusions
- Spot check specific locations in the field and compare to model prediction;
- Evaluate the coverage of a dataset (test set) in a field;
- Modify the dataset by adding images if coverage is not complete;
- Understand why the model makes the predictions that it does.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tetila, E.C.; Machado, B.B.; Astolfi, G.; de Souza Belete, N.A.; Amorim, W.P.; Roel, A.R.; Pistori, H. Detection and classification of soybean pests using deep learning with UAV images. Comput. Electron. Agric. 2020, 179, 105836. [Google Scholar] [CrossRef]
- Khanal, S.; Fulton, J.; Shearer, S. An overview of current and potential applications of thermal remote sensing in precision agriculture. Comput. Electron. Agric. 2017, 139, 22–32. [Google Scholar] [CrossRef]
- Zhang, Z.; Boubin, J.; Stewart, C.; Khanal, S. Whole-Field Reinforcement Learning: A Fully Autonomous Aerial Scouting Method for Precision Agriculture. Sensors 2020, 20, 6585. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.C. Artificial neural network. In Interdisciplinary Computing in Java Programming; Springer: Berlin/Heidelberg, Germany, 2003; pp. 81–100. [Google Scholar]
- Zhang, Z.; Khanal, S.; Raudenbush, A.; Tilmon, K.; Stewart, C. Assessing the efficacy of machine learning techniques to characterize soybean defoliation from unmanned aerial vehicles. Comput. Electron. Agric. 2022, 193, 106682. [Google Scholar] [CrossRef]
- Patil, S.; Pardeshi, S.; Patange, A.; Jegadeeshwaran, R. Deep learning algorithms for tool condition monitoring in milling: A review. J. Phys. Conf. Ser. IOP Publ. 2021, 1969, 012039. [Google Scholar] [CrossRef]
- Quinlan, J.R. Learning decision tree classifiers. ACM Comput. Surv. (CSUR) 1996, 28, 71–72. [Google Scholar] [CrossRef]
- Deo, T.Y.; Patange, A.D.; Pardeshi, S.S.; Jegadeeshwaran, R.; Khairnar, A.N.; Khade, H.S. A white-box SVM framework and its swarm-based optimization for supervision of toothed milling cutter through characterization of spindle vibrations. arXiv 2021, arXiv:2112.08421. [Google Scholar]
- Khade, H.; Patange, A.; Pardeshi, S.; Jegadeeshwaran, R. Design of bagged tree ensemble for carbide coated inserts fault diagnosis. Mater. Today Proc. 2021, 46, 1283–1289. [Google Scholar] [CrossRef]
- Khairnar, A.; Patange, A.; Pardeshi, S.; Jegadeeshwaran, R. Supervision of Carbide Tool Condition by Training of Vibration-based Statistical Model using Boosted Trees Ensemble. Int. J. Perform. Eng. 2021, 17, 229–240. [Google Scholar] [CrossRef]
- Tambake, N.R.; Deshmukh, B.B.; Patange, A.D. Data Driven Cutting Tool Fault Diagnosis System Using Machine Learning Approach: A Review. J. Phys. Conf. Ser. IOP Publ. 2021, 1969, 012049. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Neal, P. The Generalised Coupon Collector Problem. J. Appl. Probab. 2008, 45, 621–629. [Google Scholar] [CrossRef]
- Marchese Robinson, R.L.; Palczewska, A.; Palczewski, J.; Kidley, N. Comparison of the predictive performance and interpretability of random forest and linear models on benchmark data sets. J. Chem. Inf. Model. 2017, 57, 1773–1792. [Google Scholar] [CrossRef]
- Romero-Gainza, E.; Stewart, C.; Li, A.; Hale, K.; Morris, N. Memory Mapping and Parallelizing Random Forests for Speed and Cache Efficiency. In Proceedings of the 50th International Conference on Parallel Processing Workshop, Lemont, IL, USA, 9–12 August 2021; Association for Computing Machinery: New York, NY, USA, 2021. ICPP Workshops ’21. [Google Scholar] [CrossRef]
- Romero, E.; Stewart, C.; Li, A.; Hale, K.; Morris, N. Bolt: Fast Inference for Random Forests. In Proceedings of the 23rd ACM/IFIP International Middleware Conference, Quebec, QC, Canada, 7–11 November 2022; pp. 94–106. [Google Scholar]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Almeida, J.S. Predictive non-linear modeling of complex data by artificial neural networks. Curr. Opin. Biotechnol. 2002, 13, 72–76. [Google Scholar] [CrossRef]
- Lee, J.; Xiao, L.; Schoenholz, S.; Bahri, Y.; Novak, R.; Sohl-Dickstein, J.; Pennington, J. Wide neural networks of any depth evolve as linear models under gradient descent. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Dumitrescu, E.; Hué, S.; Hurlin, C.; Tokpavi, S. Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects. Eur. J. Oper. Res. 2022, 297, 1178–1192. [Google Scholar] [CrossRef]
- Yin, C.; Cao, J.; Sun, B. Examining non-linear associations between population density and waist-hip ratio: An application of gradient boosting decision trees. Cities 2020, 107, 102899. [Google Scholar] [CrossRef]
- Paez, A.; López, F.; Ruiz, M.; Camacho, M. Inducing non-orthogonal and non-linear decision boundaries in decision trees via interactive basis functions. Expert Syst. Appl. 2019, 122, 183–206. [Google Scholar] [CrossRef]
- Sealey, V. Definite integrals, Riemann sums, and area under a curve: What is necessary and sufficient. In Proceedings of the 28th Annual Meeting of the North American Chapter of the International Group for the Psychology of Mathematics Education; Universidad Pedagógica Nacional Mérida: Mérida, Mexico, 2006; Volume 2, pp. 46–53. [Google Scholar]
- Krishnan, R.; Sivakumar, G.; Bhattacharya, P. Extracting decision trees from trained neural networks. Pattern Recognit. 1999, 32, 1999–2009. [Google Scholar] [CrossRef]
- Craven, M.W.; Shavlik, J.W. Extracting Tree-Structured Representations of Trained Networks. In Proceedings of the NIPS, Denver, CO, USA, 27–30 November 1995. [Google Scholar]
- Johansson, U.; Niklasson, L. Evolving Decision Trees Using Oracle Guides. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; pp. 238–244. [Google Scholar] [CrossRef] [Green Version]
- Rudin, C. Please stop explaining black box models for high stakes decisions. Stat 2018, 1050, 26. [Google Scholar]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; Volume 37, pp. 597–606. Available online: https://proceedings.mlr.press/v37/hong15.html (accessed on 1 November 2022).








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romero-Gainza, E.; Stewart, C. AI-Driven Validation of Digital Agriculture Models. Sensors 2023, 23, 1187. https://doi.org/10.3390/s23031187
Romero-Gainza E, Stewart C. AI-Driven Validation of Digital Agriculture Models. Sensors. 2023; 23(3):1187. https://doi.org/10.3390/s23031187
Chicago/Turabian StyleRomero-Gainza, Eduardo, and Christopher Stewart. 2023. "AI-Driven Validation of Digital Agriculture Models" Sensors 23, no. 3: 1187. https://doi.org/10.3390/s23031187
APA StyleRomero-Gainza, E., & Stewart, C. (2023). AI-Driven Validation of Digital Agriculture Models. Sensors, 23(3), 1187. https://doi.org/10.3390/s23031187