




Design and Validation of Vision-Based Exercise Biofeedback for Tele-Rehabilitation




Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
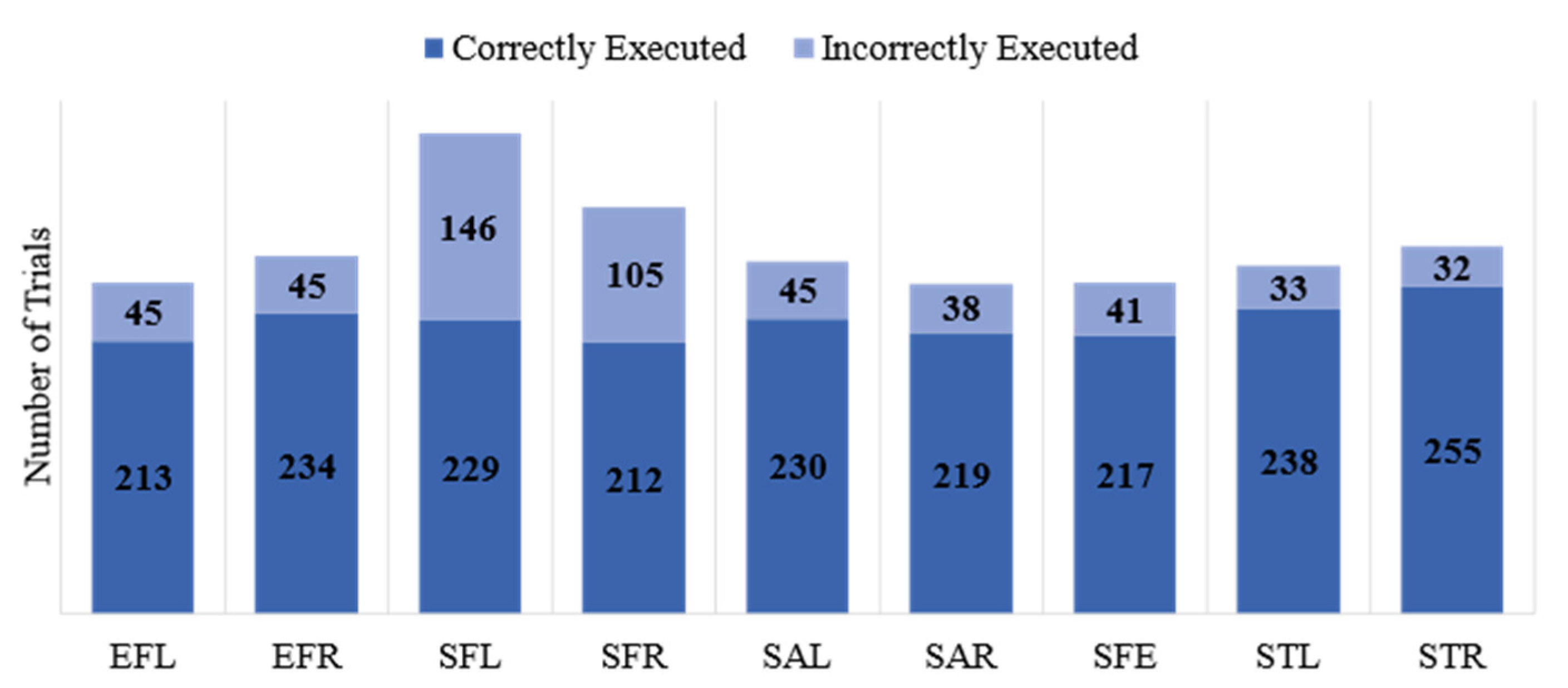
3.1. Dataset
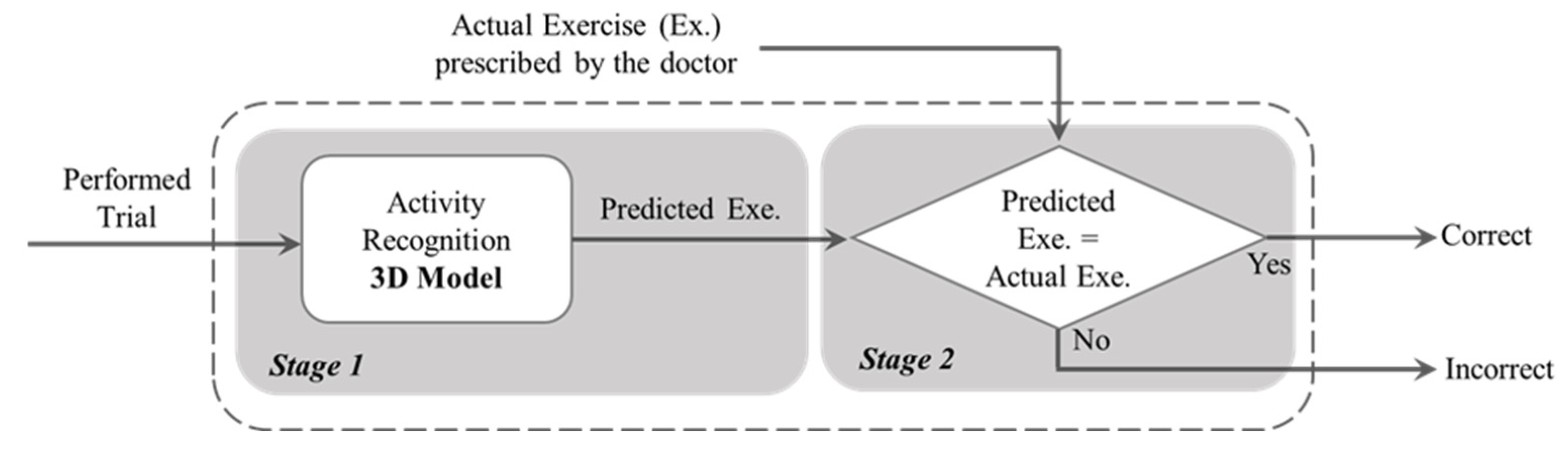
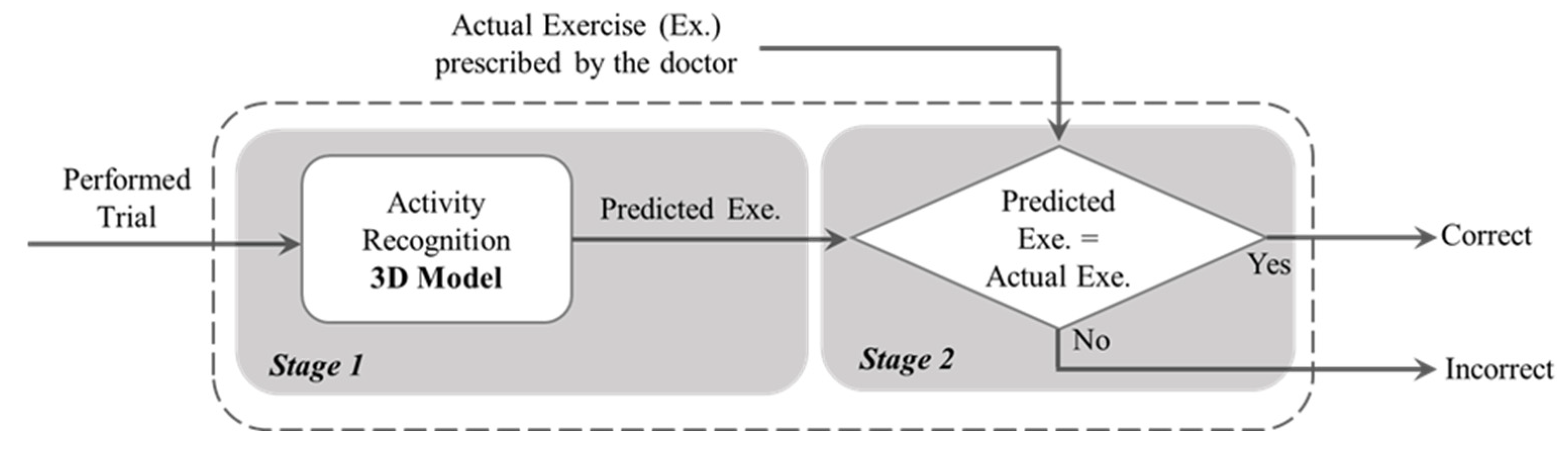
3.2. Methodology
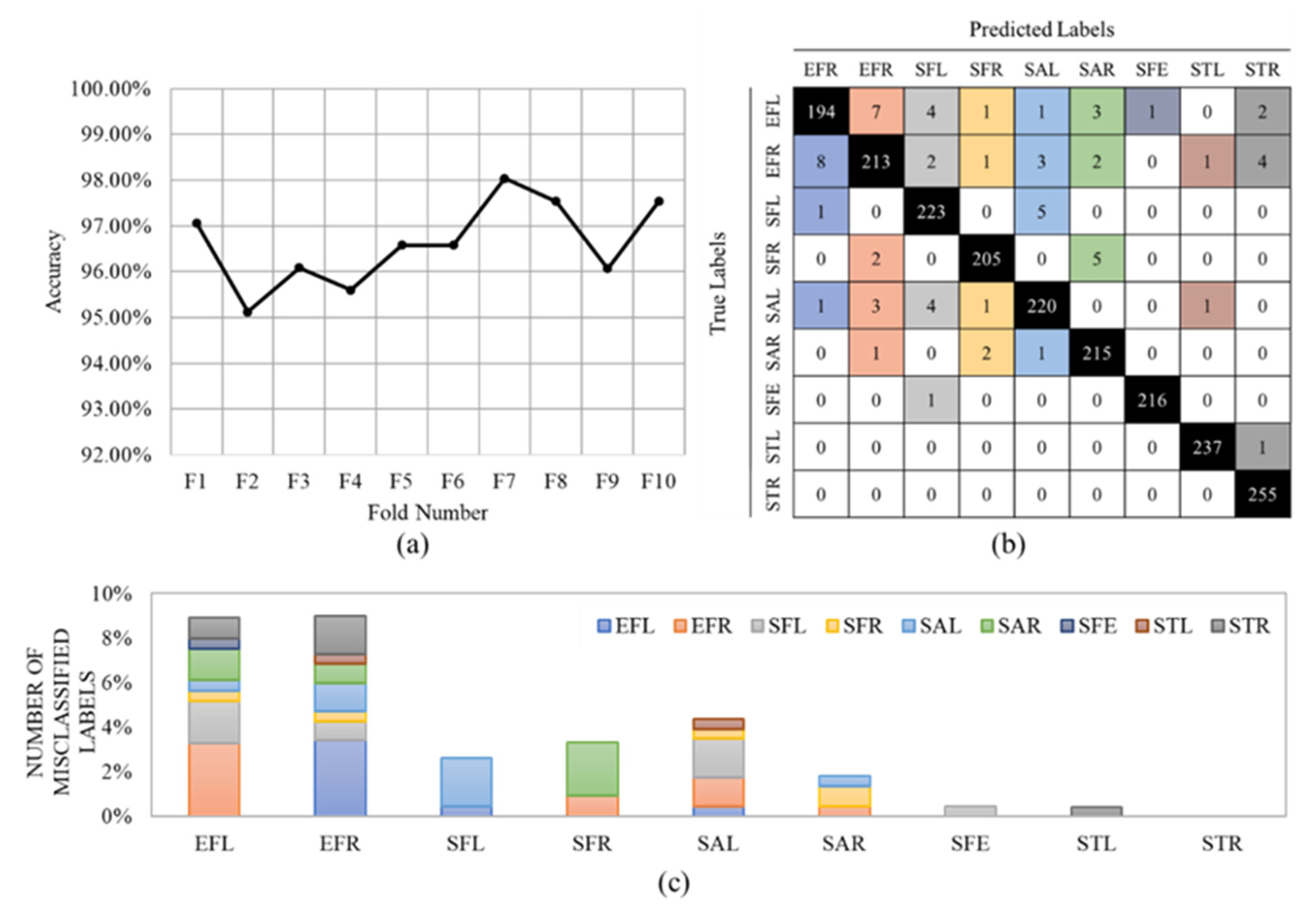
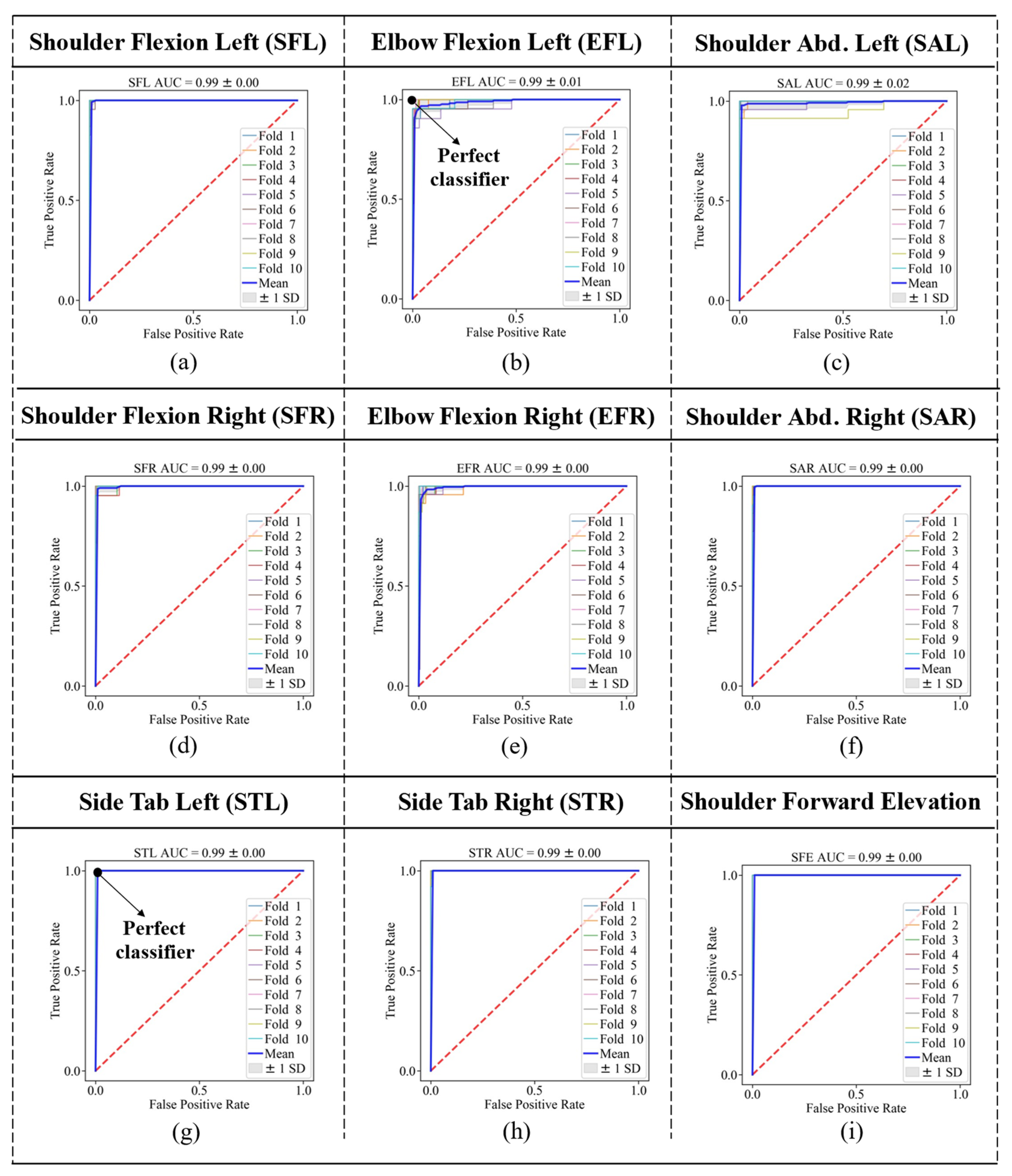
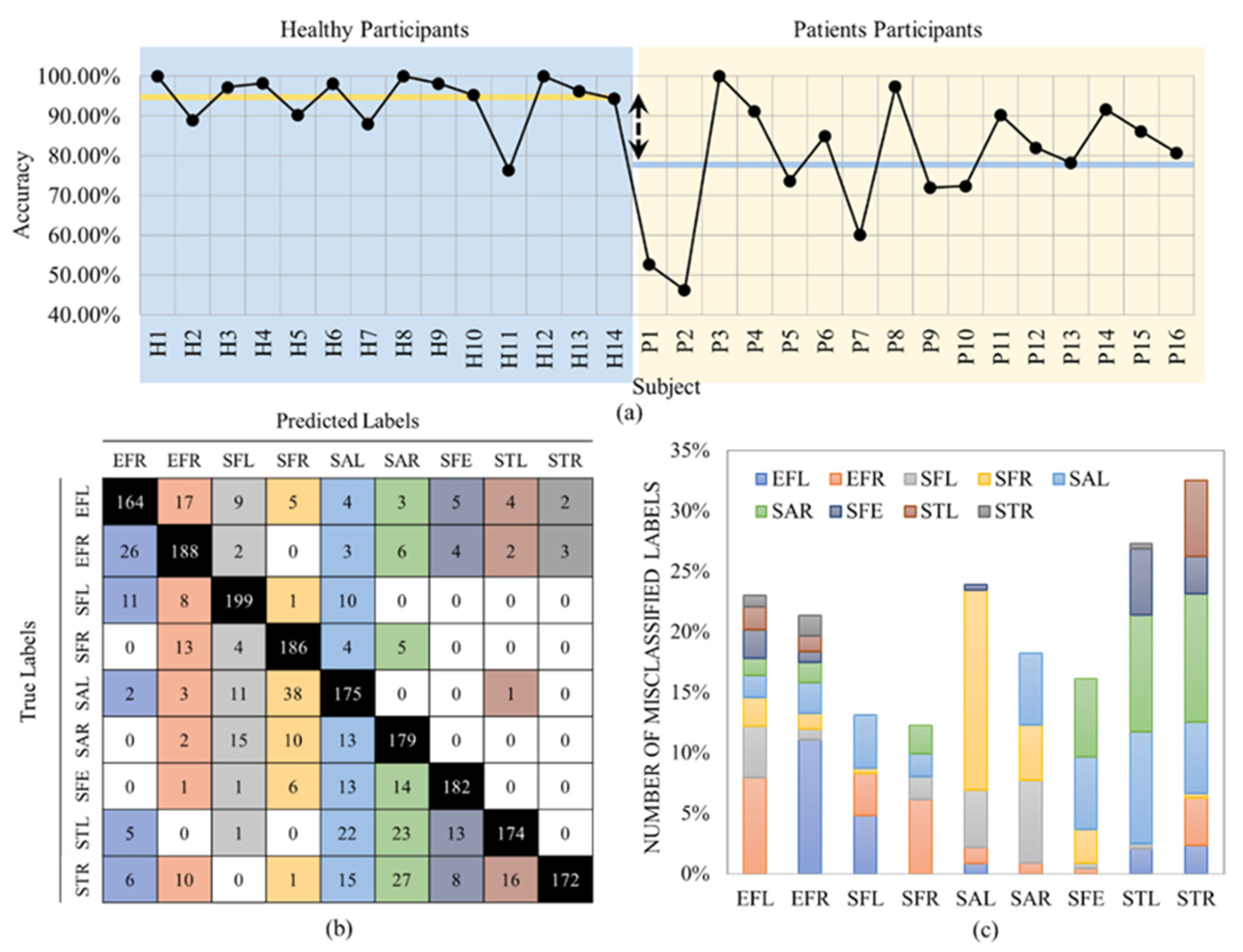
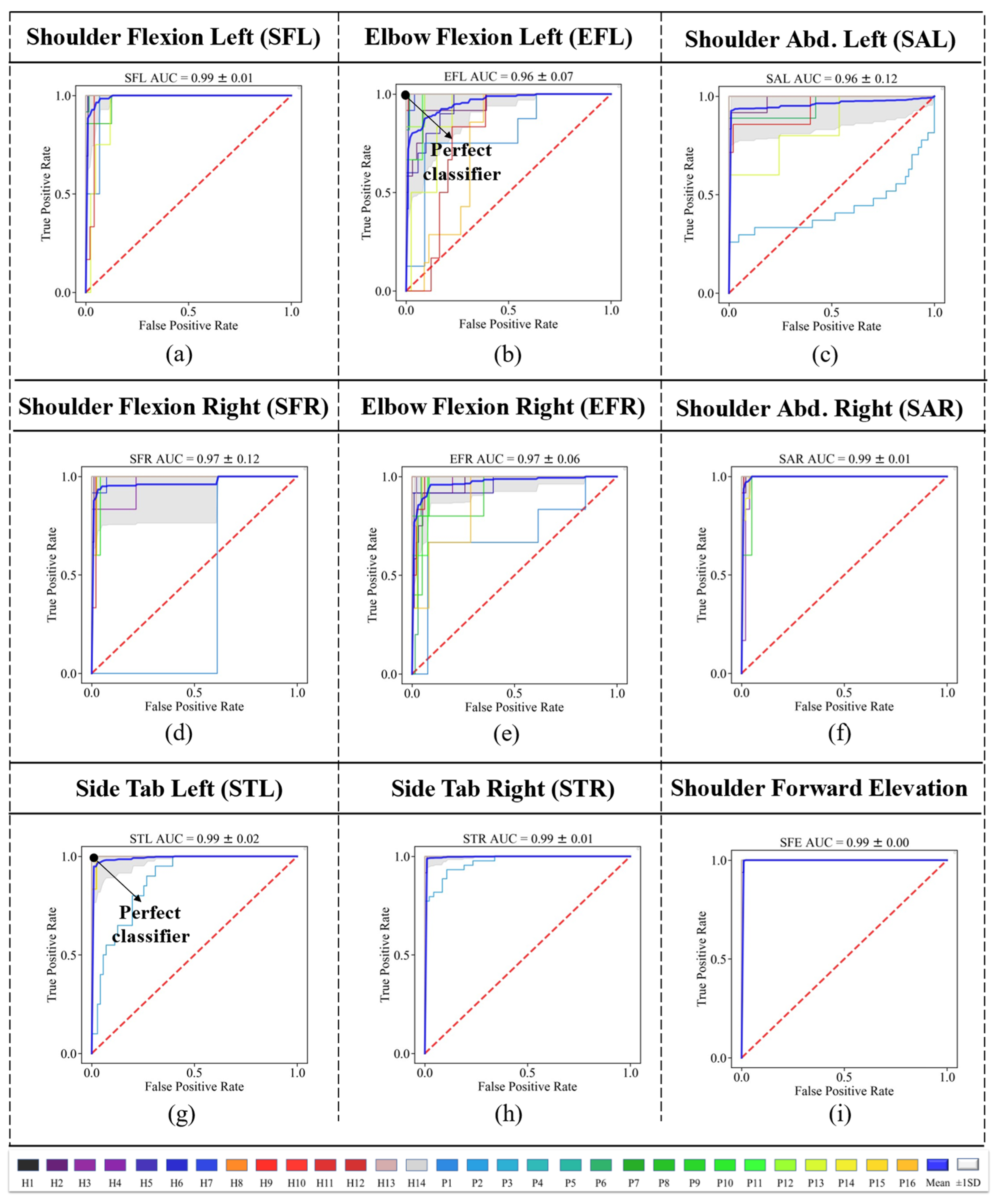
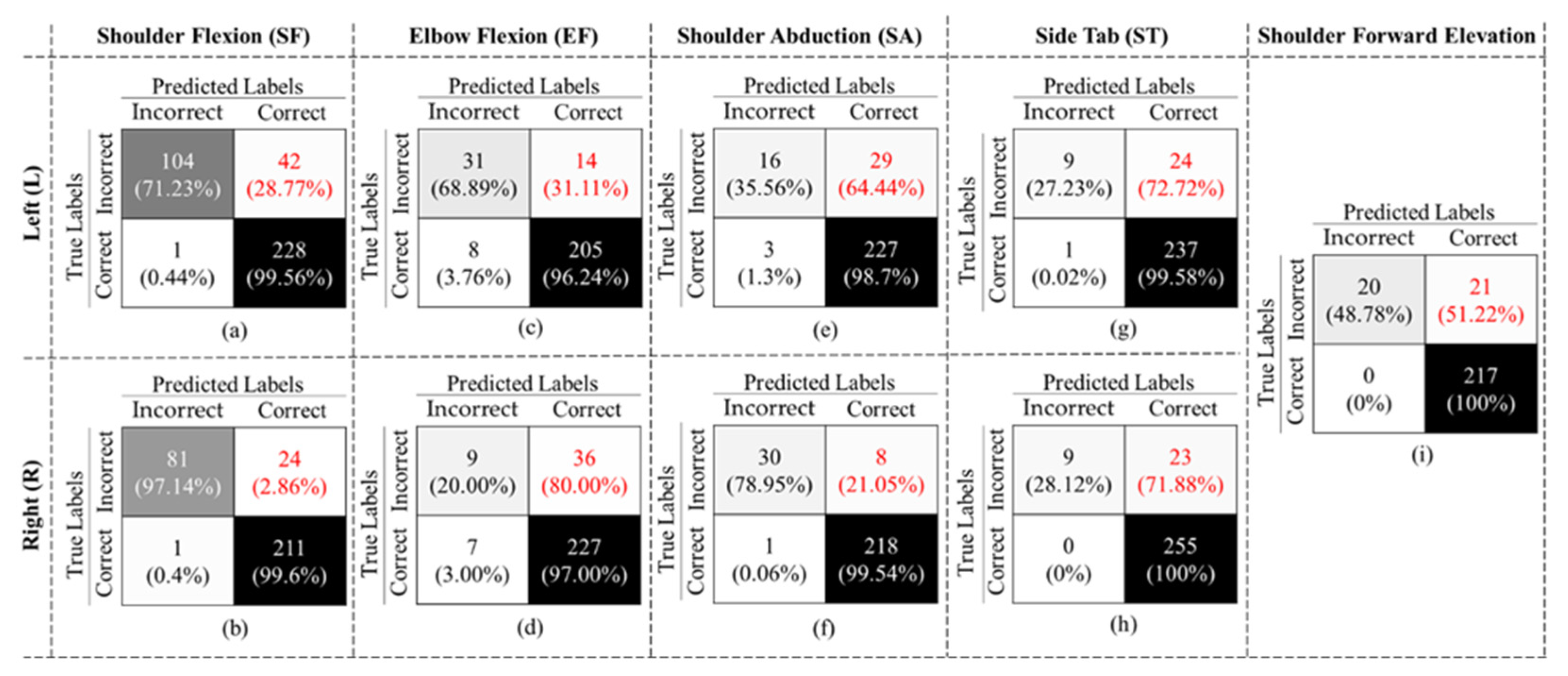
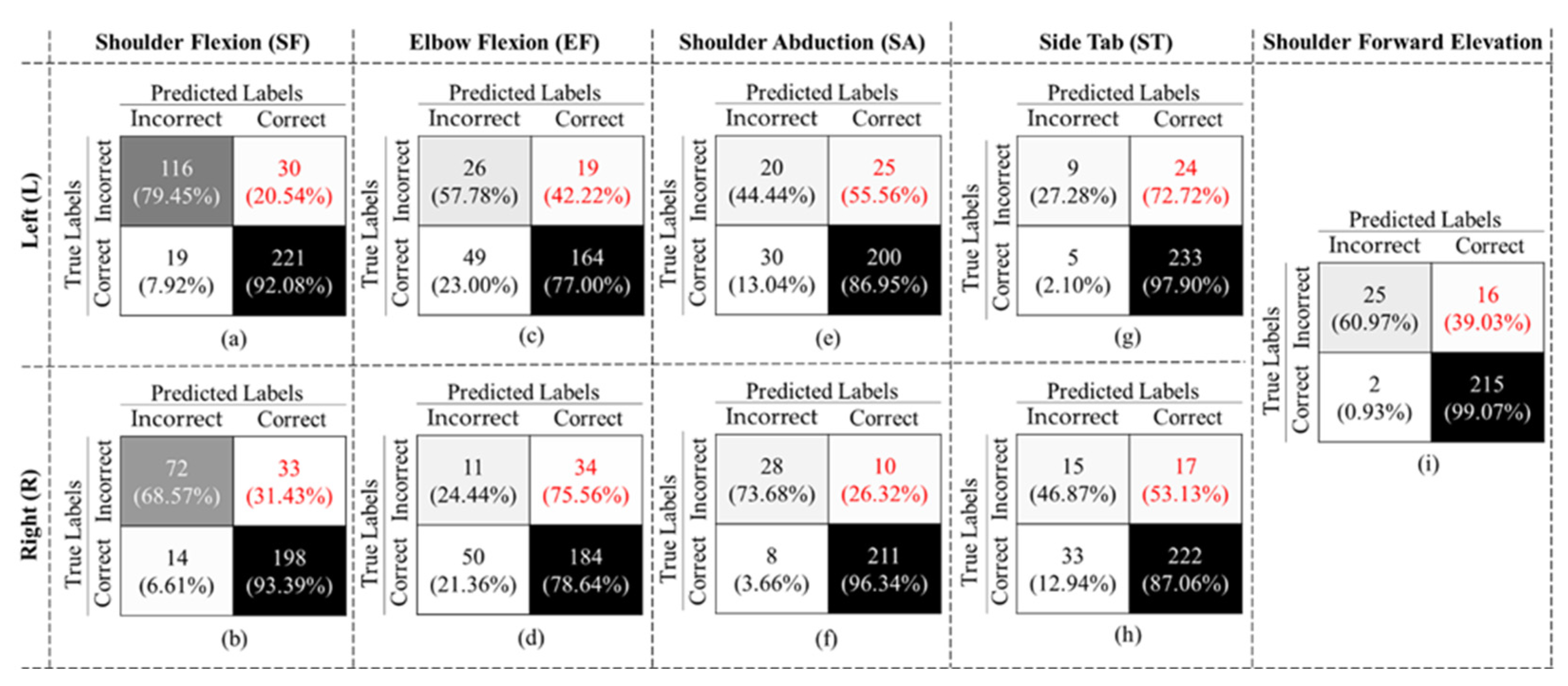
4. Results
5. Limitations of the Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kulik, C.T.; Ryan, S.; Harper, S.; George, G. Aging populations and management. Acad. Manag. J. 2014, 57, 929–935. [Google Scholar] [CrossRef]
- Lee, A.C.W.; Billings, M. Telehealth implementation in a skilled nursing facility: Case report for physical therapist practice in Washington. Phys. Ther. 2016, 96, 252–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Covert, L.T.; Slevin, J.T.; Hatterman, J. The effect of telerehabilitation on missed appointment rates. Int. J. Telerehabilitation 2018, 10, 65. [Google Scholar] [CrossRef]
- Ontario Physiotherapy Association. Telerehabilitation In Physiotherapy During the Covid-19 Pandemic, Survey Report. Available online: https://www.google.com/search?q=“telerehabilitation+in+physiotherapy+during+the+covid-19+pandemic”%2c+survey+report%2c+ontario+physiotherapy+association%2c+august+2020&rlz=1c1sqjl_enir917ir917&oq=“telerehabilitation+in+physiotherapy+during+the+covid-19+pandemic”%2c+survey+report%2c+ontario+physiotherapy+association%2c+august+2020&aqs=chrome..69i57.559j0j4&sourceid=chrome&ie=utf-8 (accessed on 3 August 2021).
- Bini, S.A.; Mahajan, J. Clinical outcomes of remote asynchronous telerehabilitation are equivalent to traditional therapy following total knee arthroplasty: A randomized control study. J. Telemed. Telecare 2017, 23, 239–247. [Google Scholar] [CrossRef]
- World Health Organization. Global Estimates of The Need for Rehabilitation. Available online: https://www.who.int/teams/noncommunicable-diseases/sensory-functions-disability-and-rehabilitation/global-estimates-of-the-need-for-rehabilitation (accessed on 5 October 2022).
- Peretti, A.; Amenta, F.; Tayebati, S.K.; Nittari, G.; Mahdi, S.S. Telerehabilitation: Review of the State-of-the-Art and Areas of Application. JMIR Rehabil. Assist. Technol. 2017, 4, e7511. [Google Scholar] [CrossRef] [PubMed]
- Jones, L.; Lee, M.; Castle, C.L.; Heinze, N.; Gomes, R.S.M. Scoping review of remote rehabilitation (telerehabilitation) services to support people with vision impairment. BMJ Open 2022, 12, e059985. [Google Scholar] [CrossRef]
- Shem, K.; Irgens, I.; Alexander, M. Getting Started: Mechanisms of Telerehabilitation. In Telerehabilitation; Elsevier: Amsterdam, The Netherlands, 2022; pp. 5–20. [Google Scholar] [CrossRef]
- Condino, S.; Turini, G.; Viglialoro, R.; Gesi, M.; Ferrari, V. Wearable Augmented Reality Application for Shoulder Rehabilitation. Electronics 2019, 8, 1178. [Google Scholar] [CrossRef] [Green Version]
- Naeemabadi, M.R.; Dinesen, B.I.; Andersen, O.K.; Najafi, S.; Hansen, J. Evaluating accuracy and usability of Microsoft Kinect sensors and wearable sensor for tele knee rehabilitation after knee operation. In Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies, Biostec 2018, Madeira, Portugal, 19–21 January 2018; pp. 128–135. [Google Scholar] [CrossRef]
- Argent, R.; Drummond, S.; Remus, A.; O’Reilly, M.; Caulfield, B. Evaluating the use of machine learning in the assessment of joint angle using a single inertial sensor. J. Rehabil. Assist. Technol. Eng. 2019, 6, 205566831986854. [Google Scholar] [CrossRef]
- Kim, J.Y.; Park, G.; Lee, S.A.; Nam, Y. Analysis of Machine Learning-Based Assessment for Elbow Spasticity Using Inertial Sensors. Sensors 2020, 20, 1622. [Google Scholar] [CrossRef] [Green Version]
- Burns, D.M.; Leung, N.; Hardisty, M.; Whyne, C.M.; Henry, P.; McLachlin, S. Shoulder physiotherapy exercise recognition: Machine learning the inertial signals from a smartwatch. Physiol. Meas. 2018, 39, 075007. [Google Scholar] [CrossRef] [Green Version]
- Fekr, A.R.; Janidarmian, M.; Radecka, K.; Zilic, Z. Multi-sensor blind recalibration in mHealth applications. In Proceedings of the 2014 IEEE Canada International Humanitarian Technology Conference–(IHTC), Montreal, QC, Canada, 1–4 June 2014. [Google Scholar] [CrossRef]
- Groves, P.D. Navigation using inertial sensors. IEEE Aerosp. Electron. Syst. Mag. 2015, 30, 42–69. [Google Scholar] [CrossRef]
- Ma, J. Innovative Intelligent Sensors to Objectively Understand Exercise Interventions for Older Adults. Ph.D. Thesis, Loughborough University, Loughborough, UK, 2019. Available online: https://www.google.com/search?q=%5B14%5D+Jianjia+Ma%2C+Ph.D.+Thesis%2C+“Innovative+Intelligent+Sensors+to+Objectively+Understand+Exercise+Interventions+for+Older+Adults”%2C+May+2019.&rlz=1C1SQJL_enIR917IR917&oq=%5B14%5D%09Jianjia+Ma%2C+Ph.D.+Thesis%2C+“Innovative+Intelligent+Sensors+to+Objectively+Understand+Exercise+Interventions+for+Older+Adults”%2C+May+2019.&aqs=chrome..69i57.573j0j9&sourceid=chrome&ie=UTF-8 (accessed on 3 August 2021).
- Mottaghi, E.; Akbarzadeh-T, M.-R. Automatic Evaluation of Motor Rehabilitation Exercises Based on Deep Mixture Density Neural Networks. J. Biomed. Inform. 2022, 130, 104077. [Google Scholar] [CrossRef] [PubMed]
- Houglum, P.; Bertoti, D. Brunnstrom’s Clinical Kinesiology; FA Davis: Philadelphia, PA, USA, 2011. [Google Scholar]
- Esfahlani, S.S.; Shirvani, H.; Butt, J.; Mirzaee, I.; Esfahlani, K.S. Machine Learning role in clinical decision-making: Neuro-rehabilitation video game. Expert Syst. Appl. 2022, 201, 117165. [Google Scholar] [CrossRef]
- Wei, W.; McElroy, C.; Dey, S. Towards on-demand virtual physical therapist: Machine learning-based patient action understanding, assessment and task recommendation. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1824–1835. [Google Scholar] [CrossRef]
- Pham, Q.T.; Nguyen, V.A.; Nguyen, T.T.; Nguyen, D.A.; Nguyen, D.G.; Pham, D.T.; Le, T.L. Automatic recognition and assessment of physical exercises from RGB images. In Proceedings of the 2022 IEEE Ninth International Conference on Communications and Electronics (ICCE), Nha Trang, Vietnam, 27–29 July 2022; pp. 349–354. [Google Scholar] [CrossRef]
- Cao, W.; Zhong, J.; Cao, G.; He, Z. Physiological Function Assessment Based on Kinect V2. IEEE Access 2019, 7, 105638–105651. [Google Scholar] [CrossRef]
- Yang, F.; Wu, Y.; Sakti, S.; Nakamura, S. Make Skeleton-based Action Recognition Model Smaller, Faster and Better. In Proceedings of the ACM Multimedia Asia, New York, NY, USA, 10 January 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Yan, H.; Hu, B.; Chen, G.; Zhengyuan, E. Real-Time Continuous Human Rehabilitation Action Recognition using OpenPose and FCN. In Proceedings of the 2020 3rd International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), Shenzhen, China, 24–26 April 2020; pp. 239–242. [Google Scholar] [CrossRef]
- Barriga, A.; Conejero, J.M.; Hernández, J.; Jurado, E.; Moguel, E.; Sánchez-Figueroa, F. A Vision-Based Approach for Building Telecare and Telerehabilitation Services. Sensors 2016, 16, 1724. [Google Scholar] [CrossRef] [Green Version]
- Rahman, Z.U.; Ullah, S.I.; Salam, A.; Rahman, T.; Khan, I.; Niazi, B. Automated Detection of Rehabilitation Exercise by Stroke Patients Using 3-Layer CNN-LSTM Model. J. Healthc. Eng. 2020, 2022, 1563707. [Google Scholar] [CrossRef]
- Yahya, M.; Shah, J.; Kadir, K.; Warsi, A.; Khan, S.; Nasir, H. Accurate shoulder joint angle estimation using single RGB camera for rehabilitation. In Proceedings of the 2019 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Auckland, New Zealand, 20–23 May 2019. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, Z.; Lu, J.; Feng, J.; Zhou, J. Multi-Stream Deep Neural Networks for RGB-D Egocentric Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3001–3015. [Google Scholar] [CrossRef]
- Cao, L.; Fan, C.; Wang, H.; Zhang, G. A Novel Combination Model of Convolutional Neural Network and Long Short-Term Memory Network for Upper Limb Evaluation Using Kinect-Based System. IEEE Access 2019, 7, 145227–145234. [Google Scholar] [CrossRef]
- Miron, A.; Sadawi, N.; Ismail, W.; Hussain, H.; Grosan, C. Intellirehabds (Irds)—A dataset of physical rehabilitation movements. Data 2021, 6, 46. [Google Scholar] [CrossRef]
- “IntelliRehabDS–A Dataset of Physical Rehabilitation Movements | Zenodo.”. Available online: https://zenodo.org/record/4610859 (accessed on 28 April 2022).
- Climent-Pérez, P.; Florez-Revuelta, F. Protection of visual privacy in videos acquired with RGB cameras for active and assisted living applications. Multimed. Tools Appl. 2021, 80, 23649–23664. [Google Scholar] [CrossRef]
- Zhang, C.; Tian, Y.; Capezuti, E. Privacy preserving automatic fall detection for elderly using RGBD cameras. In Computers Helping People with Special Needs; Springer: Berlin/Heidelberg, Germany, 2012; pp. 625–633. [Google Scholar] [CrossRef]
- Stone, E.E.; Skubic, M. Evaluation of an inexpensive depth camera for passive in-home fall risk assessment. In Proceedings of the 2011 5th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth) and Workshops, Dublin, Ireland, 23–26 May 2011; pp. 71–77. [Google Scholar] [CrossRef]
- Momin, M.S.; Sufian, A.; Barman, D.; Dutta, P.; Dong, M.; Leo, M. In-Home Older Adults’ Activity Pattern Monitoring Using Depth Sensors: A Review. Sensors 2022, 22, 9067. [Google Scholar] [CrossRef] [PubMed]
- Carreira, J.; Zisserman, A. Quo Vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef] [Green Version]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes from Videos in The Wild. 2012. Available online: https://arxiv.org/abs/1212.0402 (accessed on 28 April 2022).
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Bouckaert, R.R. Efficient AUC learning curve calculation. Lect. Notes Comput. Sci. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinforma 2006, 4304, 181–191. [Google Scholar] [CrossRef] [Green Version]
- Rybarczyk, Y.; Pérez Medina, J.L.; Leconte, L.; Jimenes, K.; González, M.; Esparza, D. Implementation and Assessment of an Intelligent Motor Tele-Rehabilitation Platform. Electronics 2019, 8, 58. [Google Scholar] [CrossRef] [Green Version]
- García-de-Villa, S.; Casillas-Pérez, D.; Jiménez-Martín, A.; García-Domínguez, J.J. Simultaneous exercise recognition and evaluation in prescribed routines: Approach to virtual coaches. Expert Syst. Appl. 2022, 199, 116990. [Google Scholar] [CrossRef]
- Choi, J. Range Sensors: Ultrasonic Sensors, Kinect, and LiDAR. In Humanoid Robotics: A Reference; Goswami, A., Vadakkepat, P., Eds.; Springer: Dordrecht, The Netherlands, 2019. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Sub.# | Problem | Method | Performance/Results | |
|---|---|---|---|---|---|
| [18] | 78 | Designing an automatic assessment in tele-rehab | DMDN | RMSE 1: 11.99% | |
| [20] | 52 | Predicting the rehabilitation outcome and classifying healthy and MS participants | KNN SVM | RMSE: 6.1% | |
| Classification: | |||||
| Acc. 2: 91.7% Acc.: 88.0% | AUC 3: 96% AUC: 93% | ||||
| [30] | 23 | Estimating the Brunnstrom scale | RF SVM Hybrid model | Acc.: 58.8% Acc.: 55.7% Acc.: 84.1% | |
| [21] | 35 | A two-phase human action understanding algorithm | Hidden Markov SVM | Acc. for feedback: 93.5% Acc. for task recommendation: 90.47% | |
| [26] | 1 | Detecting static posture and falls | NN | Acc.: 96%, Pre. 4: 95%, Rec. 5: 97% and F1-Score: 96% | |
| [27] | 20 | Rehabilitation exercise recognition | 3-layer CNN-LSTM | Acc.: 91.3% | |
| [28] | 2 | Shoulder angle estimation | NN | Acc.: 67.04% | |
| [29] | 8 | Rehabilitation exercise recognition | MDNN | Acc.: 67.04% | |
| Index | Gesture Name | Description |
|---|---|---|
| 0 | Elbow Flexion Left (EFL) | Flexion and extension of the left elbow joint |
| 1 | Elbow Flexion Right (EFR) | Flexion and extension of the right elbow joint |
| 2 | Shoulder Flexion Left (SFL) | Flexion and extension of the left shoulder while the arm is kept straight in front of the body |
| 3 | Shoulder Flexion Right (SFR) | Flexion and extension of the right shoulder while the arm is kept straight in front of the body |
| 4 | Shoulder Abduction Left (SAL) | Maintaining the arm straight, the left arm is raised away from the side of the body |
| 5 | Shoulder Abduction Right (SAR) | Maintaining the arm straight, the right arm is raised away from the side of the body |
| 6 | Shoulder Forward Elevation (SFE) | Holding hands clasped together in front of the body, maintaining the arms in a straight position, raise the arms above the head while keeping elbows straight |
| 7 | Side Tap Left (STL) | Moving the left leg to the left side and back while maintaining balance |
| 8 | Side Tap Right (STR) | Moving the right leg to the right side and back while maintaining balance |
| Gesture | Accuracy (%) | Precision (%) | F1-Score (%) | Specificity (%) | Recall (%) |
|---|---|---|---|---|---|
| EFL | 73.64 ± 34.38 | 34.67 ± 42.99 | 43.33 ± 43.49 | 77.00 ± 33.75 | 57.78 ± 27.59 |
| EFR | 69.89 ± 32.25 | 18.03 ± 46.76 | 20.75 ± 45.23 | 78.63 ± 29.25 | 24.44 ± 39.53 |
| SFL | 86.93 ± 19.66 | 85.93 ± 38.43 | 82.56 ± 38.15 | 91.70 ± 18.42 | 79.45 ± 26.96 |
| SFR | 85.17 ± 19.54 | 68.57 ± 40.54 | 75.39 ± 41.57 | 85.71 ± 23.86 | 83.72 ± 23.01 |
| SAL | 80.00 ± 24.65 | 40.00 ± 35.95 | 42.11 ± 43.29 | 86.96 ± 16.61 | 44.44 ± 40.00 |
| SAR | 93.00 ± 25.82 | 77.78 ± 34.55 | 75.68 ± 37.24 | 96.35 ± 18.85 | 73.68 ± 22.64 |
| SFE | 93.02 ± 16.87 | 92.59 ± 19.79 | 73.53 ± 29.18 | 99.08 ± 2.25 | 60.98 ± 27.19 |
| STL | 89.30 ± 23.72 | 64.29 ± 24.94 | 38.30 ± 24.97 | 97.90 ± 4.59 | 27.27 ± 34.91 |
| STR | 82.58 ± 25.32 | 31.25 ± 33.12 | 37.50 ± 41.82 | 87.06 ± 17.87 | 46.88 ± 32.96 |
| Overall | 83.78 ± 7.63 | 60.53 ± 25.14 | 60.64 ± 21.3 | 89.74 ± 7.53 | 60.75 ± 20.25 |
| Accuracy (%) | Precision (%) | F1-Score (%) | Specificity (%) | Recall (%) | |||||
|---|---|---|---|---|---|---|---|---|---|
| 10-Fold | LOSO | 10-Fold | LOSO | 10-Fold | LOSO | 10-Fold | LOSO | 10-Fold | LOSO |
| 90.57% | 83.78% | 93.35% | 60.53% | 71.78% | 60.64% | 98.93% | 89.74% | 58.30% | 60.75% |
| Ref. # | ER 1 Accuracy | EA 2 Accuracy | EA F1-Score | Device | Activities | Feedback | |||
|---|---|---|---|---|---|---|---|---|---|
| LOSO | Other | LOSO | Other | LOSO | Other | ||||
| [27] | - | 91.3% | - | - | - | - | RGB | 7 | NA |
| [18] | - | - | - | RMSE:0.12 | - | - | Kinect | 5 | 10 Level Numerical |
| [21] | - | 98.13% | - | 93.5% | - | - | Kinect | 3 | Binary |
| [43] | - | - | - | 92.33% | - | - | Kinect | 4 | Numerical into Binary |
| Proposed | 86.04% | 96.62% | 83.78% | 90.57% | 60.64% | 71.78% | Kinect | 9 | Binary |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barzegar Khanghah, A.; Fernie, G.; Roshan Fekr, A. Design and Validation of Vision-Based Exercise Biofeedback for Tele-Rehabilitation. Sensors 2023, 23, 1206. https://doi.org/10.3390/s23031206
Barzegar Khanghah A, Fernie G, Roshan Fekr A. Design and Validation of Vision-Based Exercise Biofeedback for Tele-Rehabilitation. Sensors. 2023; 23(3):1206. https://doi.org/10.3390/s23031206
Chicago/Turabian StyleBarzegar Khanghah, Ali, Geoff Fernie, and Atena Roshan Fekr. 2023. "Design and Validation of Vision-Based Exercise Biofeedback for Tele-Rehabilitation" Sensors 23, no. 3: 1206. https://doi.org/10.3390/s23031206
APA StyleBarzegar Khanghah, A., Fernie, G., & Roshan Fekr, A. (2023). Design and Validation of Vision-Based Exercise Biofeedback for Tele-Rehabilitation. Sensors, 23(3), 1206. https://doi.org/10.3390/s23031206