Abstract
This paper is dedicated to video coding based on a compressive sensing (CS) framework. In CS, it is assumed that if a video sequence is sparse in some transform domain, then it could be reconstructed from a much lower number of samples (called measurements) than the Nyquist–Shannon theorem requires. Here, the performance of such a codec depends on how the measurements are acquired (or sensed) and compressed and how the video is reconstructed from the decoded measurements. Here, such a codec potentially could provide significantly faster encoding compared with traditional block-based intra-frame encoding via Motion JPEG (MJPEG), H.264/AVC or H.265/HEVC standards. However, existing video codecs based on CS are inferior to the traditional codecs in rate distortion performance, which makes them useless in practical scenarios. In this paper, we present a video codec based on CS called CS-JPEG. To the author’s knowledge, CS-JPEG is the first codec based on CS, combining fast encoding and high rate distortion results. Our performance evaluation shows that, compared with the optimized software implementations of MJPEG, H.264/AVC, and H.265/HEVC, the proposed CS-JPEG encoding is 2.2, 1.9, and 30.5 times faster, providing 2.33, 0.79, and 1.45 dB improvements in the peak signal-to-noise ratio, respectively. Therefore, it could be more attractive for video applications having critical limitations in computational resources or a battery lifetime of an upstreaming device.
1. Introduction
In recent years, more and more applications where a video upstreaming device is limited by its resources, such as the battery lifetime and the platform performance, have been developed. Examples include deep space missions [1], wireless endoscopy [2], wireless multimedia sensors [3,4], the Internet of Underwater Things [5], and high-speed video capturing [6]. The basic solution for these applications is traditional block-based intra-frame video coding, such as x264 [7], which is an open-source implementation of video encoding according to the H.264/AVC [8] standard. Video encoding through x264 includes several complexity profiles from veryslow to ultrafast. The veryslow profile corresponds to the maximum possible optimization of the codec parameters such that the compression performance is the highest while the encoding speed is the lowest. In contrast, the ultrafast profile corresponds to the maximum possible encoding speed. In [9], it was shown that x264 provides close to optimum rate distortion performance for the H.264/AVC standard when computational complexity is significantly restricted. The main goal of this paper is to answer the following question: Is it possible to compress faster than the traditional block-based intra-frame video coding, such as with x264 in an ultrafast profile, while having better compression performance?
One of the promising video coding concepts that can potentially provide lower encoding complexity is distributed video coding (DVC), where the coding complexity is shifted from the encoder to the decoder [10]. There are two main DVC implementations which are still under development:
- 1.
- DVC based on syndrome coding [11,12] or overlapped arithmetic coding [13];
- 2.
- DVC based on compressive sensing (CS) [3].
In the first implementation (e.g., DISCOVER [11]), some frames (called key frames) are intra-encoded via conventional video coding based on H.264/AVC in Intra mode. The remaining frames (called Wyner–Ziv (WZ) frames) are divided into non-overlapped blocks for which a 2D discrete cosine transform (DCT) is performed. The resulting DCT coefficients are converted into several binary vectors. Then, a syndrome of an error-correcting code is computed for each vector and transmitted to the decoder. At the decoder side, already-reconstructed frames are used in order to obtain the interpolated version of the decoded frame (called side information). Then, the received syndromes and the side information are used for syndrome decoding, considering the binary vectors extracted from the side information as a sum of the vectors obtained at the encoder and some errors in a virtual channel. Several works [11,12,13] reported that this approach outperforms H.264/AVC (Intra) in compression performance. However, the utilization of H.264/AVC makes the whole architecture more sophisticated, since it requires having two different encoders at the same upstreaming device. Moreover, since WZ frame encoding includes block-based DCT, binarization, and syndrome coding, it is very unlikely that it would be significantly less complex than the frame encoding via existing fast software implementations of H.264/AVC (Intra), such as via the x264 [7] encoder in an ultrafast profile.
This paper is dedicated to DVC based on CS, which potentially could provide lower encoding complexity compared with x264 in an ultrafast profile. In CS, it is assumed that if a video sequence is sparse in some transform domain, then it could be reconstructed from a much lower number of samples (called measurements) than the Nyquist–Shannon theorem requires [14,15]. The measurements could be quantized and entropy-encoded. As a result, the complexity and rate distortion (RD) performance of such a codec depend on how the measurements are acquired, quantized, and compressed and how the video is reconstructed from the decoded measurements. In [16], we proposed the CS-JPEG video codec, which outperformed other codecs based on CS such as DISCOS [17], DCVS [18], MH-BCS [19], and MC-BCS [20]. However, CS-JPEG from [16] has the following drawbacks. First, in [16], a video was recovered via the iterative shrinkage-thresholding Algorithm (ISTA), where VBM3D was used as the thresholding operator. Since VBM3D was originally developed for video denoising, it performs a lot of redundant operations at each iteration of ISTA, such as hard thresholding (which is used in order to obtain an initial estimation of a video signal before the empirical Wiener shrinkage) and block matching (which does not use motion vectors obtained at previous iterations). As a result, the decoding speed in [16] is too slow, even for low-frame resolutions. In [21], a fast thresholding algorithm was proposed. However, it does not take into account the motion between neighbor frames. Therefore, there is still room for the ISTA improving from both the complexity and performance points of view. Second, the encoders in [16,21] as well as in DISCOS, DCVS, MH-BCS, and MC-BCS allow only setting the number of measurements and corresponding quantization levels for all frames. As a result, the output bit rate depends on the statistical properties of an input video sequence. However, in order to fit the channel capacity, the upstreaming applications should have a rate control algorithm which provides a target bit rate by adaptive selection of the number of measurements and the quantization level for each frame. Therefore, the rate control for the CS-JPEG codec is needed.
In this paper, we address the issues described above and evaluate the performance of the resulting video codec. The main contributions of this paper are the following:
- 1.
- We introduce an accurate rate control algorithm based on packet dropping which does not lead to a noticeable increase in encoding complexity.
- 2.
- We propose fast randomized thresholding for the ISTA, which pseudo-randomly selects the shrinkage parameters at each iteration and shows that compared with the ISTA with VBM3D [22,23], it is significantly less complex and provides better recovery performance.
- 3.
- We show detailed comparisons of the proposed CS-JPEG codec with conventional optimized competitors, such as MJPEG, x264 (Intra), and x265 (Intra) [24] (fast software implementation of H.265/HEVC [25]) in ultrafast profiles. The comparisons demonstrate that the CS-JPEG codec provides much faster encoding and more accurate rate control. Moreover, it shows better compression performance for video sequences with low and medium motion levels.
The rest of this paper is organized as follows. Section 2 overviews the work related to the CS-JPEG codec which was previously performed by the authors in [16,21,23]. Section 3 describes the proposed rate control. Section 4 introduces the proposed fast randomized thresholding for the ISTA. Section 5 provides a comparison with the conventional intra codecs. Section 6 concludes the presented results.
2. Overview of CS-JPEG Video Codec Based on Compressive Sensing
2.1. Research Problem Statement
The CS task for a video sequence can be formulated in the following way. Let us define a frame with an index i as a 2D signal of a size pixels (We use the following notation. The column vectors and matrices are denoted by boldfaced lowercase and uppercase letters, respectively, (e.g., and ), and vec concatenates columns of into a vector). First, linear measurements for are acquired as , where vec, and denotes the measurement (or sensing) matrix for the ith frame. As was shown in [23], the task of reconstruction of the frame from measurements can be efficiently solved with the ISTA, where the frames at iteration k are estimated as
where is a soft thresholding operator with a threshold
where is an initial threshold, K is the number of iterations, and
where is the step size [23] (usually ).
In order to provide an efficient video coding based on the CS framework, we should answer the following questions:
- 1.
- Which measurement matrix is the most efficient?
- 2.
- How do we efficiently transmit to the decoder?
- 3.
- How do we quantize and compress the measurements ?
- 4.
- How do we choose the best combination of the quantization level and the sensing rate ?
- 5.
- How do we choose the soft thresholding operator ?
- 6.
- How do we choose the best combination of parameters for the ISTA?
The rest of this section is dedicated to these questions.
2.2. Measurement (or Sensing) Matrix Selection and Quantization
In several video CS works [26,27], the block-based random measurements based on a Gaussian random projection matrix is used. In this approach, each video frame is divided into non-overlapping blocks of a size . Then, each block is acquired by utilizing the Gaussian random projection measurement matrix of a size . As a result, the measurement (or sensing) matrix for each frame is equal to
First, the block-based sensing approach allows calculating the measurements separately for each block (i.e., it can be performed in parallel). Second, for the same reason, the recovery process can be performed in parallel as well. However, this approach has the following disadvantages:
- 1.
- As was shown in [23], the block-based measurements provide a much lower reconstruction quality compared with the global measurements which are acquired for a whole frame.
- 2.
- From an implementation point of view, the block-based sensing requires matrix multiplication with floating-point coefficients (i.e., it is not efficient from the encoding computational complexity point of view [28]).
In order to overcome the disadvantages mentioned above, in [23], we introduced the following global measurement (or sensing) matrix:
where is a downsampling matrix of the L-level Haar transform, which is needed to compute low-resolution images of a size , and is random rows of an orthogonal real-valued dragon noiselet transform (DNT) matrix [29]. The operation with DNT is presented in Algorithm 1.
| Algorithm 1: Forward (inverse) DNT |
Input:
|
First, the DNT can be applied only for a 1D vector of a power of two samples. Therefore, in [16], we proposed extending the input vector by additional zero samples, where . Second, after forward and inverse DNT, each sample should be divided by . In order to avoid square root calculation and division, in [16], we proposed combining this operation with quantization in the following way. At the encoder side, we compute the quantized measurement as follows:
where is the quantization step, and at the decoder side, we dequantize the measurement as follows:
One can see that the DNT combined with quantization is performed for integer numbers and does not require division and multiplication. Since the downsampling matrix of the L-level Haar transform can be also performed without division and multiplication, the considered measurements matrix in Equation (5) is very attractive for low-complexity encoding.
2.3. Measurement Matrix Transmission
According to the CS framework, after DNT, we need to take out of coefficients located at pseudo-random positions. Here, from the reconstruction quality point of view, these positions should be different for the neighboring frames. In [16], we proposed generating only 8 different pseudo-random vectors of a size of 10, corresponding to sensing rates , where each vector element defines a distance between two coefficients to be included in the output bit stream. For example, for , the following vectors are used:
If we use vector , then the quantized measurements will be included in the output bit stream. Here, both the encoder and the decoder use vector for the frame with an index i.
2.4. Measurements of Compression and Packetization
The measurement matrix in Equation (5) produces two types of measurements which are compressed as in [16] (see Figure 1).
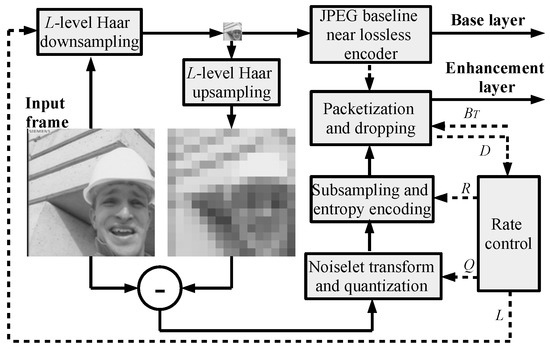
Figure 1.
CS-JPEG intra-frame encoder.
The low-resolution image is compressed by a JPEG baseline with a quality factor of 100 (near lossless mode). The quantized and subsampled DNT coefficients are binarized and compressed via a context-adaptive binary range coder (CABRC) [30], which is up to faster than conventional adaptive binary arithmetic coders with bit renormalization [31]. Here, one binary context is used for the sign of a DNT coefficient, while its amplitude is unarily binarized and compressed using 64 binary contexts. The compressed DNT coefficients are packetized so that each packet also includes the frame index, the packet index, the sensing rate index, an absolute position of the first DNT coefficient within the packet, and other information needed for decoding. Moreover, CABRC is reinitialized for each new packet so that each packet can be decoded separately and used for reconstruction. All packets with DNT coefficients are embedded into an application part of the JPEG header. As a result, any JPEG-compatible software can decode the low-resolution part of a frame. The CS-JPEG decoder is used in order to find the full frame resolution. Let us also note that any other potential image coding, such as JPEG2000, H.264/AVC (Intra), or H.265/HEVC (Intra), can be used for low-resolution image compression. CS-JPEG uses JPEG due to its low complexity and simplicity.
2.5. The Soft Thresholding Operator Selection
In [16], we proposed using randomized VBM3D from [23] as a soft thresholding operator in the CS-JPEG decoder. VBM3D originally was developed as a video denoising filter. However, as was shown in [32], such denoising filters can be considered as thresholding operators as well. VBM3D assumes that a video sequence has temporal similarity between blocks in different frames and similarity between blocks at different spatial locations within the same frame. Under this assumption, it performs denoising in two stages. At the first stage, for each reference block, several of the most similar blocks in the current frame and neighbor frames are grouped into a 3D block. Then, the hard thresholding operator is applied:
- 1.
- A sparsifying transform with a matrix is applied for a 3D block as .
- 2.
- The hard threshold transform coefficients are calculated as follows:
- 3.
- A hard threshold block is calculated as .
Since each pixel can be estimated by the hard thresholding of different 3D blocks, operator also computes a weight coefficient for all pixels estimates corresponding to the 3D block as , where is -norm (number of non-zero coefficients) of . Thereafter, the final estimate of each pixel is calulated as a weighted sum of the all estimates.
Video frames obtained at the first stage are used at the second stage as estimates of the noise-free frames in order to find similar blocks more precisely. Then, instead of the hard thesholding, an empirical Wiener shrinkage operator is performed:
- 1.
- A sparsifying transform with matrix is applied for a 3D block as .
- 2.
- A shrinkage coefficients are calculated as , where .
- 3.
- A resulting block is calculated as .
Here, the final estimate of each pixel is calculated as a weighted sum of all the estimates as well, where a weight coefficient for each estimate is computed as .
As was shown in [16], the resulting CS-JPEG video codec with ISTA based on VBM3D significantly outperformed the other codecs based on CS, such as DISCOS [17], DCVS [18], MH-BCS [19], and MC-BCS [20]. However, the computational complexity of the VBM3D is very high. Therefore, in [21], we proposed a low-complexity ISTA based on simple spatial transforms (, , and DCT) and temporal transforms (1-D DCT of sizes 4, 8, and 16) which were randomly selected at each iteration, and we showed that it reduced the recovery time by around 300 times compared with the one with VBM3D. However, the low-complexity ISTA did not take into account the motion between neighbor frames. Therefore, its reconstruction performance was much worse than that of ISTA with VBM3D. As a result, a reconstruction algorithm combining a high recovery performance and low computational complexity should be developed.
2.6. Parameter Selection for the CS-JPEG Codec
There are three parameters in the CS-JPEG encoder: the number of levels for the Haar transform L, sensing rate R, and quantization step Q for DNT coefficients. At the decoder side, there are only two parameters: an initial threshold value and the number of iterations K. In general, the problem of the codec parameter selection can be formulated as follows. For a given bit rate, we need to choose a triple at the encoder and a corresponding pair at the decoder which provide the maximum reconstruction quality. This task could be solved by a brute force algorithm which includes encoding and decoding with all possible combinations of the parameters. However, such an approach requires too many computations. Therefore, in [21], we proposed a heuristic separate optimization within three stages. At the first stage, we set the parameters , and K and performed encoding and decoding for all pairs , where and . Then, for the selected pairs , we obtained the best , shown in Table 1.

Table 1.
CS-JPEG coding parameters.
Finally, for the selected triples , we performed the reconstruction with and and found that and provided the best rate distortion results on average. However, the problem of parameter selection for a given target bit rate was not covered in [21], (i.e., a rate control algorithm should be developed).
3. Proposed Rate Control for the CS-JPEG Encoder
According to Table 1, the CS-JPEG encoder supports five basic sets of coding parameters . As a result, five basic RD points are provided. Since the measurements in different packets are compressed independently and assumed to have equal contributions to the decoded quality, the remaining RD points could be achieved by dropping the corresponding number of packets before transmission or storage. Figure 2 illustrates this idea. First, we built the basic RD curve. Second, we chose a bit stream corresponding to a sensing rate , removed of the packets from it, and performed the decoding. Then, we removed packets from the resulting bit stream, and so on. One can see that the proposed codec provides a high level of quality scalability (i.e., a wide range of bit rates can be achieved by extraction or dropping the corresponding number of packets from the initial bit stream).
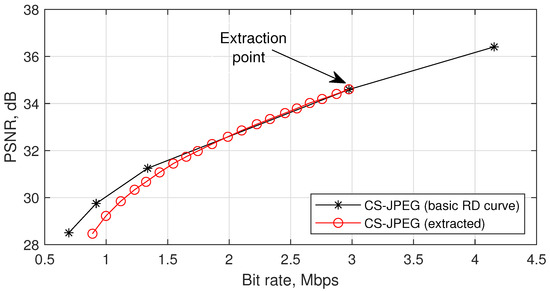
Figure 2.
Illustration of the codec scalability for `Foreman’.
In this paper we propose using quality scalability in order to introduce the following rate control algorithm in the form of a state machine with five states , presented at Figure 3.
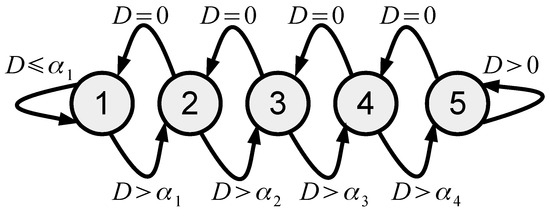
Figure 3.
The proposed rate control state machine.
Each state defines the coding parameters for frame i as shown in Table 1. Let us define as the target number of bits for each frame and as the number of bits after compression of frame i, with the encoding parameters defined by the state . The encoder uses the packet dropping mechanism, which allows it to store or transmit bits and compute the frame dropping level as
The dropping level indicates that the encoder should generate more bits; in other words, we have
Otherwise, indicates that the encoder generates bits. However, if is too high, then the encoder wastes a lot of computational resources in order to acquire and compress a lot of measurements which are dropped. Moreover, from the RD performance point of view, it could be more efficient to use a lower sensing rate with different Q and L values (see Figure 2). Therefore, if
where , then the lower sensing rate is selected; in other words, we have
It could be noticed that the proposed rate control algorithm has relatively low computational complexity, since it computes only the dropping level , which is compared with zero and in order to define the triple for the next frame.
4. Proposed Fast Randomized Thresholding ISTA in the CS-JPEG Decoder
4.1. Basic Soft Thresholding for the ISTA
Let us introduce the following basic soft thresholding, presented in Algorithm 2. First, for a current reference block of a size with the left-top corner coordinates in frame , we apply hierarchical motion estimation (HME) [33]. HME returns the most similar blocks with the corresponding motion vectors such that block belongs to frame . Second, these blocks are grouped into a 3D block of a size , and then the 3D discrete cosine transform (DCT) coefficients for it are calculated. Then, empirical Wiener shrinkage [22] is performed for each coefficient as , where , a weight coefficient for the 3D block is calculated as , and then inverse 3D DCT for the coefficients is performed in order to obtain the thresholded blocks . Third, the operator creates two zero frames and and inserts a block into frame and a block of the same size containing only ones into frame according to motion vector . Finally, the sum of the weighted pixel values and the corresponding sum of weights are accumulated in buffers and , respectively, and the resulting output frame is computed as , where the division is performed in an element-by-element manner.
| Algorithm 2: Basic soft thresholding operator (Version 1) |
Input:
|
In contrast to VBM3D, Algorithm 2 does not have the first stage, where the frames are hard thresholded in order to obtain better estimations for the motion estimation in the second stage. In our case, we assume that the frame estimations at iteration are good enough to use for motion estimation at iteration k. Moreover, in the motion estimation, we are not searching for the most similar blocks within the same frame. Both of these approaches allow reducing the computational complexity. Table 2 shows an average recovery time for and , where the basic thresholding is called Version 1. One can see that the complexity is still too high and should be reduced.
Table 2.
Recovery time for frame of size for thresholding with DCT on 2.8 GHz CPU.
4.2. Proposed Modifications of the Basic Soft Thresholding with DCT
In this paper, we propose the following four modifications of the basic soft thresholding:
- 1.
- Let us approximate the basic thresholding results by reducing the number of considered reference blocks. In the original VBM3D [22] only, we havewhere is used, while in [23], s is randomly selected from a set at each iteration. Both approaches consider a significantly lower number of reference blocks, while the second one uses four times more combinations, which allows obtaining better performance. However, both of these approaches consider a limited number of different reference blocks used during the whole recovery process. Therefore, in Version 2, we propose usingwhere both and are randomly selected from a set at each iteration. From one side, in contrast to [22,23], this approach uses a lower number of reference blocks at each iteration. As a result, it is more than 11 times faster than basic thresholding (see Table 2) and 3–5 times faster than VBM3D (see Table 3). From the other side, if K is high enough, this allows us to use almost all combinations of the reference blocks during the whole recovery process, providing the closest approximation to Version 1 (see Figure 4).
Table 3. An average frame recovery time for VBM3D and the proposed algorithm on a 2.8 GHz CPU.
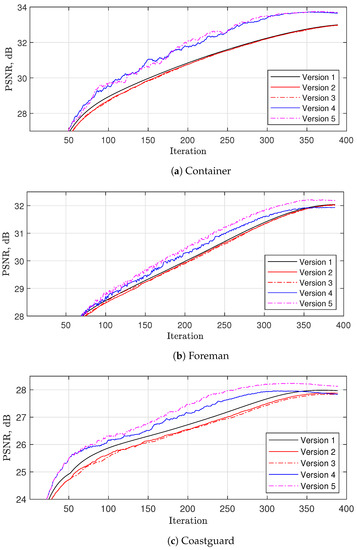 Figure 4. Comparison of different versions of thresholding with DCT for . Here, Version 1 is the thresholdig according to Algorithm 2, Version 2 is Version 1 with random selection of shifts from set , Version 3 is Version 2, in which hierarchical motion estimation (HME) is used once per 30 iterations, while for the remaining iterations, only motion vector refinement via fast gradient motion vector searching is used, Version 4 is Version 3, in which any motion estimation is performed at each iteration with a probability of while zero-motion vectors are used with a probability of , and Version 5 is Version 4, in which motion searching within the same frame is enabled.
Figure 4. Comparison of different versions of thresholding with DCT for . Here, Version 1 is the thresholdig according to Algorithm 2, Version 2 is Version 1 with random selection of shifts from set , Version 3 is Version 2, in which hierarchical motion estimation (HME) is used once per 30 iterations, while for the remaining iterations, only motion vector refinement via fast gradient motion vector searching is used, Version 4 is Version 3, in which any motion estimation is performed at each iteration with a probability of while zero-motion vectors are used with a probability of , and Version 5 is Version 4, in which motion searching within the same frame is enabled. - 2.
- As in [23], Version 2 performs HME at each iteration, which is computationally expensive. Therefore, in Version 3, we assume that the estimated frames do not change significantly from iteration to iteration. Therefore, we can, for instance, perform HME only once per 30 iterations, while for the remaining iterations, we apply only the motion vector refinement performing fast gradient motion vector searching [33], utilizing the motion vectors estimated at the previous iteration as the initial vectors. As a result, the overall complexity is reduced by around four times compared with Version 2, keeping the same reconstruction performance (see Figure 4).
- 3.
- A further reduction in complexity can be achieved by avoiding motion estimation at all for some iterations (i.e., when zero motion vectors are used). In Version 4, we propose disabling motion estimation for the first iterations, while for , the motion estimation is performed with a probability of . This allows reducing the thresholding complexity by 1.75 times compared with Version 4 (see Table 2). Figure 4 shows that this approach has minor PSNR degradation for video sequences with fast and medium motion (see `Foreman’ and `Coastguard’) and noticeable PSNR improvement when the motion level is low (see `Container’). This can be explained in the following way. At initial iterations, the current estimates look noisy such that the motion estimation is not able to obtain zero-motion vectors even for completely static videos. In contrast, the proposed solution allows using zero-motion vectors, which improves the reconstruction quality compared with both Version 3 and VBM3D.
- 4.
- Since some videos have a high level of non-local similarities between the blocks within a frame, following VBM3D in Version 5, we propose collecting F blocks from F frames, which have the maximum similarity, so that more than one block for a given frame can be selected in the thresholding. This allows us to achieve a noticeable improvement in PSNR but with almost double the complexity compared with Version 4.
4.3. Proposed Thresholding Based on 3D DCT with Randomized Block Sizes
The sparsity level, achieved through 3D DCT for a block of size of , depends on the video properties. From the spatial sparsity point of view, a larger N is better for a flat area, while the smaller ones are better for areas with many details. From the temporal sparsity point of view, smaller N and F values allow finding more similar blocks in the neighbor frames when the motion level is medium or high, while for a low-motion area, a larger F value is better. Figure 5 shows PSNR improvements related to the recovery algorithm from [21] for different 3D DCT block sizes in case of compression of the first 16 frames of the test video sequences with a sensing rate .
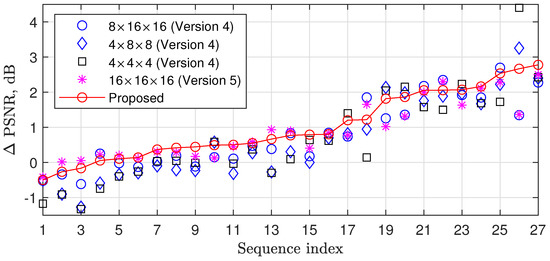
Figure 5.
PSNR improvements related to [21] for the thresholding with 3D DCT block sizes , , and and the proposed thresholding in which the block size is selected from a set , and at each iteration with a probability of .
As could be expected, different block sizes provide different results for different videos. In this paper, we propose exploiting the advantages of different transform sizes in the following way. At each iteration, we randomly select the transform size using equal probabilities. This approach does not increase the complexity. At the same time, Figure 5 shows that it provides an average improvement in PSNR from 0.13 to 0.36 dB compared with a case when one fixed transform size is used for all iterations and up to 3 dB compared with [21].
Following the reasoning described above, Figure 6 shows the proposed fast randomized ISTA as a part of the CS-JPEG decoder. At each iteration , we first randomly select the mode with a distribution . If , then we randomly select mode with a distribution . If , then we perform motion estimation for the blocks and the thresholding with DCT. For , we perform motion estimation for the , , and blocks, respectively, and the thresholding with DCT, DCT, and DCT, respectively. If or , then we disable the motion estimation, set all the motion vectors to zero, and perform the thresholding.
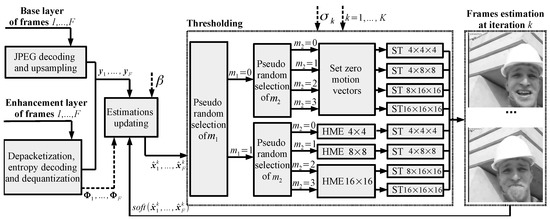
Figure 6.
Proposed fast randomized ISTA for CS-JPEG decoder.
Figure 7 and Table 3 show a comparison of the proposed fast randomized ISTA and the ISTA with the original VBM3D [22] in a high profile (VBM3D-HI) and VBM3D from [23] with random selection of parameters as well (VBM3D-RND). One can see that, on average, the proposed ISTA outperformed VBM3D-HI and VBM3D-RND by 0.76 dB and 0.26 dB, having 20 and 32 times lower complexity, respectively.
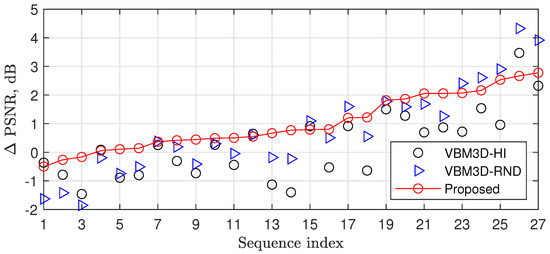
Figure 7.
PSNR improvements related to [21] for thresholding using VBM3D-HI, VBM3D-RND, and the proposed randomized thresholding.
5. Performance Evaluation
5.1. Test Video Sequences
The performance evaluation was obtained for 27 test video sequences available in [34]. All the sequences had a frame resolution of . In all cases, only the luminance (Y) component was considered. The test sequences were selected so that they had very different motion levels. In order to measure this numerically, let us introduce the following temporal similarity level S:
where is the maximum possible value of the pixels in original video sequence and
where and are the values of the pixels with coordinates in the original frame with a number f and the motion-compensated frame relative to frame f, respectively.
Table 4 shows the considered video sequences with the corresponding number of frames and the temporal similarity level S. Here, the sequences `Bridge-close’, `Container’, and `Bridge-far’ had the highest S values (i.e., the neighboring frames were almost the same), while `Football’, `Mobile’, and `Flower’ had very low similarity due to heavy motion of the camera and the objects.
Table 4.
Test video sequences.
5.2. Rate Control Precision Comparison
In this paper, we compare the proposed rate control for the CS-JPEG codec (The CS-JPEG codec can be found at https://github.com/eabelyaev/csjpeg, accessed on 3 December 2022) with the corresponding algorithms in the most famous intra-frame encoders such as MJPEG [35] (MATLAB implementation), Motion JPEG2000 (MJPEG2000) [36], x264 [7], and x265 [24], which are fast software implementations of H.264/AVC [8] and H.265/HEVC [25] encoders, respectively. All the codecs were run without any software optimization tools, such as assembler optimization or threads. Here, ultrafast means that the x264 or x265 encoder is used in its fastest preset, while veryslow corresponds to the full RD optimization. Since MJPEG does not contain any rate control, we implement the following rate control based on a virtual buffer. For frame i, we select the JPEG quality factor as follows:
where is the size of the virtual buffer, is the frame rate, is the buffering delay, is the virtual channel rate, and is the virtual buffer fullness after encoding frame , which is calculated as follows:
where is the number of bits after compression of frame with a quality factor . The rate control (Equation (18)) selects , depending on the virtual buffer fullness , so that a decrease in leads to an increase in the quality factor and vice versa. As a result, a bit rate close to the target one is provided. Similar rate controls are used in both x264 and x265. However, as can be seen in Figure 8, in many cases, the virtual buffer cannot guarantee a bit rate close enough to the target value . MJPEG, x264, and x265 can provide a bit rate which is up to , , and higher than , respectively. This can be very critical for some video streaming applications. In contrast, both MJPEG2000 and the proposed rate control for CS-JPEG provided almost exact for all the considered test video sequences. Here, the proposed rate control had a higher precision than that in MJPEG2000.
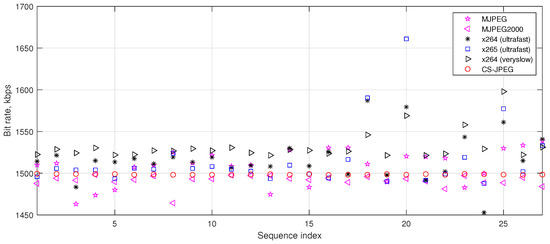
Figure 8.
Bit rate provided by the considered codecs for kbps.
5.3. Encoding Speed Comparison
Table 5 shows an encoding speed comparison for the considered codecs, measured in terms of the number of frames which could be compressed in one second by a 2.8 GHz CPU. Let us notice that both x264 and x265 were developed and optimized for many years by professional software engineers, while CS-JPEG was implemented in C-language by the author of the paper, who is not an expert in software development. Nevertheless, one can see that, on average, the CS-JPEG encoder was 2.2, 39.8, 1.9, 26.2, and 30.5 times faster than MJPEG, MJPEG2000, x264-ultrafast, x264-veryslow, and x265-ultrafast, respectively. These results practically prove that video coding based on CS has a much lower encoding complexity than the traditional block-based or wavelet-based intra codecs (i.e., it could be attractive for video applications having significant limitations in computational resources or the battery lifetime of an upstreaming device).
Table 5.
Encoding speed in frames per second for `Foreman’ with resolution and 300 frames on 2.8 GHz CPU.
5.4. Rate Distortion Comparison via the PSNR Metric
Let us compare the rate distortion performance of the considered codecs using the peak signal-to-noise ratio (PSNR) as an objective visual quality metric. The PSNR is defined as
where
where and are the values of the pixels with coordinates in the original and reconstructed frames with a number f, respectively.
Figure 9 shows a rate distortion performance comparison for the test video sequences `Container’, `Hall’, `Foreman’, and `Soccer’. One can see that for `Container’ and `Hall’, the proposed CS-JPEG codec outperformed all the block-based codecs, while for `Foreman’ and `Soccer’, it provided similar or even worse results. This could be explained in the following way. The recovery performance of CS-JPEG highly depends on the statistical properties of a video sequence. On one hand, CS-JPEG exploits the temporal similarity between neighboring frames (i.e., higher similarity means better reconstruction). On the other hand, if the temporal similarity is low, then the traditional block-based intra codecs could provide better performance, since they exploit the spatial similarity of the pixels within a frame more efficiently.
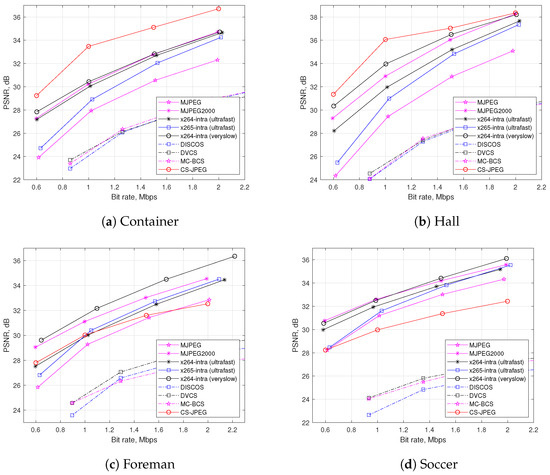
Figure 9.
Rate distortion comparison using PSNR metric.
As a reference, Figure 9 also shows the rate distortion performance for other codecs based on CS such as DISCOS, DCVS, and MC-BCS. One can see that the proposed CS-JPEG provided significantly better results. Therefore, we further compared CS-JPEG only with the block-based codecs, such as x264, x265, MJPEG, and wavelet-based MJPEG2000. Finally, x265-intra (ultrafast) provided surprisingly worse compression performance than x264-ultrafast. This could be explained by H.265/HEVC originally being oriented for video sequences with higher frame resolutions. In order to demonstrate this, Figure 10 presents comparisons for two test video sequences [21] with a frame resolution of . For such a resolution, x265-intra (ultrafast) provided much better performance than both x264-intra (ultrafast) and x264-intra (veryslow).
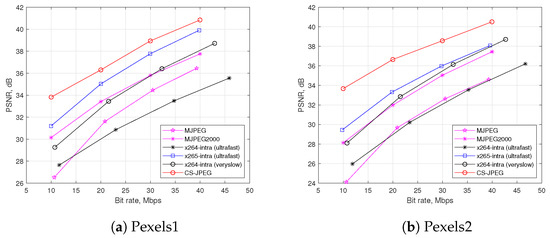
Figure 10.
Rate distortion comparison using PSNR metric for Full HD videos.
Table 6 shows the BD-PSNR [37] provided by the CS-JPEG codec in comparison with the intra codecs mentioned above. Here, the positive values mean that CS-JPEG provided better performance. One can see that if the temporal similarity level dB, then in the most of the cases, CS-JPEG outperformed the competitors, including x264-veryslow and MJPEG2000. If dB, then the temporal similarity was too low, so the traditional block-based or wavelet-based intra-coding had more advantages. Using this observation, we can conclude that CS-JPEG is more attractive for applications with low and medium motion levels between neighboring frames.
Table 6.
BD-PSNR provided by CS-JPEG compared with different intra-frame codecs.
5.5. Rate Distortion Comparison via the SSIM Metric
For objective visual quality evaluation, we also used the Structural Similarity Index (SSIM) [38], which measures the similarity between two images and ranges from 0 to 1. Table 7 shows the BD-SSIM provided by the CS-JPEG codec in comparison with the intra codecs. One can see that, as in the previous case, CS-JPEG provided better performance for dB.
Table 7.
BD-SSIM provided by CS-JPEG compared with different intra-frame codecs.
5.6. Comparison via Flickering Level
The objective PSNR and SSIM metrics are calculated for only a single frame. Therefore, these metrics are not always good enough for quality assessment of a video sequence. Let us also evaluate inter-frame flickering, which is a commonly seen video coding artifact. It is perceived mainly because of the increased inter-frame difference between neighboring frames after compression compared with the corresponding difference in the original video. As a result, flicker is more easily seen in static areas. Table 8 shows the flickering level [39] for the considered codecs. One can see that for a similarity level dB, the proposed CS-JPEG codec provided a much lower flickering level (except for `Bridge-far’) compared with the other block-based codecs, while in some cases, wavelet-based MJPEG2000 had the lowest flickering level.
Table 8.
Flickering level at kbps.
5.7. Subjective Comparison
Figure 11, Figure 12, Figure 13 and Figure 14 show frame 150 for `Container’, `Hall’, `Foreman’, and `Soccer’ at a target bit rate kbps. It could be noticed that MJPEG, x264, and x265 produced very strong blocking artifacts, while CS-JPEG was free of them.

Figure 11.
Frame with index 150 at kbps for `Container’.

Figure 12.
Frame with index 150 at kbps for `Hall’.

Figure 13.
Frame with index 150 at kbps for `Foreman’.

Figure 14.
Frame with index 150 at kbps for `Soccer’.
6. Conclusions
In this paper we summarized the CS-JPEG codec with intra-frame encoding and inter-frame decoding inspired by compressive sensing. We demonstrated that when compared with the traditional block-based intra codecs, it is significantly less complex and provides a higher level of scalability. Moreover, for video sequences with low and medium motion levels, it also provided better rate distortion performance. This makes CS-JPEG more attractive for video applications having significant limitations in computational resources or battery lifetime for an upstreaming device.
Funding
This research was funded by the Analytical Center for the Government of the Russian Federation (IGK 000000D730321P5Q0002), Agreement No. 70-2021-00141.
Data Availability Statement
The CS-JPEG codec as well as additional visual comparisons can be found at https://github.com/eabelyaev/csjpeg, accessed on 3 December 2022.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Karishma, S.N.; Srinivasarao, B.K.N.; Chakrabarti, I. Compressive sensing based scalable video coding for space applications. In Proceedings of the 2016 Twenty Second National Conference on Communication (NCC), Guwahati, India, 4–6 March 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Saputra, O.D.; Murti, F.W.; Irfan, M.; Putri, N.N.; Shin, S.Y. Reducing Power Consumption of Wireless Capsule Endoscopy Utilizing Compressive Sensing Under Channel Constraint. J. Inf. Commun. Converg. Eng. 2018, 16, 130–134. [Google Scholar]
- Pudlewski, S.; Melodia, T. Compressive Video Streaming: Design and Rate-Energy-Distortion Analysis. IEEE Trans. Multimed. 2013, 15, 2072–2086. [Google Scholar] [CrossRef]
- Liu, X.; Zhai, D.; Zhou, J.; Zhang, X.; Zhao, D.; Gao, W. Compressive Sampling-Based Image Coding for Resource-Deficient Visual Communication. IEEE Trans. Image Process. 2016, 25, 2844–2855. [Google Scholar] [CrossRef] [PubMed]
- Monika, R.; Samiappan, D.; Kumar, R. Underwater image compression using energy based adaptive block compressive sensing for IoUT applications. Vis. Comput. 2021, 37, 1499–1515. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, H.; Cheng, Z.; Chen, B.; Yuan, X. MetaSCI: Scalable and Adaptive Reconstruction for Video Compressive Sensing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2083–2092. [Google Scholar]
- x264 AVC Encoder/H.264 Video Codec. Available online: https://www.videolan.org/developers/x264.html (accessed on 10 June 2021).
- Schwarz, H.; Marpe, D.; Wiegand, T. Overview of the Scalable Video Coding Extension of the H.264/AVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1103–1120. [Google Scholar] [CrossRef]
- Li, X.; Wien, M.; Ohm, J.R. Rate-Complexity-Distortion Optimization for Hybrid Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 957–970. [Google Scholar] [CrossRef]
- Wyner, A.; Ziv, J. The rate-distortion function for source coding with side information at the decoder. IEEE Trans. Inf. Theory 1976, 22, 1–10. [Google Scholar] [CrossRef]
- Ascenso, J.; Brites, C.; Pereira, F. Content Adaptive Wyner-ZIV Video Coding Driven by Motion Activity. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 605–608. [Google Scholar] [CrossRef]
- Deligiannis, N.; Munteanu, A.; Clerckx, T.; Cornelis, J.; Schelkens, P. Overlapped Block Motion Estimation and Probabilistic Compensation with Application in Distributed Video Coding. IEEE Signal Process. Lett. 2009, 16, 743–746. [Google Scholar] [CrossRef]
- Zhou, J.; Fu, Y.; Yang, Y.; Ho, A.T. Distributed video coding using interval overlapped arithmetic coding. Signal Process. Image Commun. 2019, 76, 118–124. [Google Scholar] [CrossRef]
- Chang, K.; Kevin Ding, P.L.; Li, B. Compressive Sensing Reconstruction of Correlated Images Using Joint Regularization. IEEE Signal Process. Lett. 2016, 23, 449–453. [Google Scholar] [CrossRef]
- Fei, X.; Wei, Z.; Xiao, L. Iterative Directional Total Variation Refinement for Compressive Sensing Image Reconstruction. IEEE Signal Process. Lett. 2013, 20, 1070–1073. [Google Scholar] [CrossRef]
- Belyaev, E. Compressive Sensed Video Coding Having Jpeg Compatibility. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1128–1132. [Google Scholar] [CrossRef]
- Do, T.T.; Chen, Y.; Nguyen, D.T.; Nguyen, N.; Gan, L.; Tran, T.D. Distributed compressed video sensing. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 1393–1396. [Google Scholar] [CrossRef]
- Kang, L.; Lu, C. Distributed compressive video sensing. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 1169–1172. [Google Scholar] [CrossRef]
- Tramel, E.W.; Fowler, J.E. Video Compressed Sensing with Multihypothesis. In Proceedings of the 2011 Data Compression Conference, Snowbird, UT, USA, 29–31 March 2011; pp. 193–202. [Google Scholar] [CrossRef]
- Mun, S.; Fowler, J. Residual Reconstruction for Block-Based Compressed Sensing of Video. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 29–31 March 2011; pp. 183–192. [Google Scholar] [CrossRef]
- Belyaev, E. Fast Decoding and Parameters Selection for CS-JPEG Video Codec. In Proceedings of the 2021 IEEE 23rd International Workshop on Multimedia Signal Processing (MMSP), Tampere, Finland, 6–8 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Egiazarian, K. Video denoising by sparse 3D transform-domain collaborative filtering. In Proceedings of the 2007 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 145–149. [Google Scholar]
- Belyaev, E.; Codreanu, M.; Juntti, M.; Egiazarian, K. Compressive Sensed Video Recovery via Iterative Thresholding with Random Transforms. IET Image Process. 2020, 14, 1187–1199. [Google Scholar] [CrossRef]
- x265 HEVC Encoder/H.265 Video Codec. Available online: http://x265.org/ (accessed on 10 June 2021).
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Fowler, J.E.; Mun, S.; Tramel, E.W. Block-Based Compressed Sensing of Images and Video. Found. Trends Signal Process. 2012, 4, 297–416. [Google Scholar] [CrossRef]
- Zhao, C.; Ma, S.; Zhang, J.; Xiong, R.; Gao, W. Video Compressive Sensing Reconstruction via Reweighted Residual Sparsity. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1182–1195. [Google Scholar] [CrossRef]
- Yuan, X.; Haimi-Cohen, R. Image Compression Based on Compressive Sensing: End-to-End Comparison With JPEG. IEEE Trans. Multimed. 2020, 22, 2889–2904. [Google Scholar] [CrossRef]
- Romberg, J. Imaging via Compressive Sampling. IEEE Signal Process. Mag. 2008, 25, 14–20. [Google Scholar] [CrossRef]
- Belyaev, E.; Liu, K.; Gabbouj, M.; Li, Y. An Efficient Adaptive Binary Range Coder and Its VLSI Architecture. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1435–1446. [Google Scholar] [CrossRef]
- Belyaev, E.; Veselov, A.; Turlikov, A.; Kai, L. Complexity Analysis of Adaptive Binary Arithmetic Coding Software Implementations. In Proceedings of the Smart Spaces and Next Generation Wired/Wireless Networking, St. Petersburg, Russia, 22–15 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 598–607. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Belyaev, E.; Turlikov, K. Motion esimation algorithms for low bit-rate video compression. Comput. Opt. 2008, 32, 69–76. [Google Scholar]
- Xiph.org Video Test Media. Available online: https://media.xiph.org/video/derf/ (accessed on 30 November 2022).
- Wallace, G.K. The JPEG still picture compression standard. IEEE Trans. Consum. Electron. 1992, 38, xviii–xxxiv. [Google Scholar] [CrossRef]
- An Open-Source JPEG 2000 CodecWritten in C. Available online: https://www.openjpeg.org/ (accessed on 13 January 2023).
- Bjøntegaard, G. Calculation of average PSNR differences between RD curves. In ITU-T Q.6/SG16 VCEG 13th Meeting, Document VCEG-M33; ITU: Austin, TX, USA, 2001. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Boyce, J.; Stein, A. Effective flicker removal from periodic intra frames and accurate flicker measurement. In Proceedings of the 2008 IEEE International Conference on Image Processing (ICIP), San Diego, CA, USA, 12–15 October 2008. [Google Scholar] [CrossRef]














Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).