1. Introduction
In recent years, the detection and recognition of human activities through machine learning algorithms have become a field of significant interest to the scientific community. As most human beings live in highly social environments, the interest arises because such research can be used in applications such as personal security and safety, healthcare, assistance to the elderly, sports, and so on.
Many of the approaches for the recognition of human activities presented in the literature have proposed the use of body sensors such as gyroscopes, accelerometers, barometers, life sign measuring devices, etc. These types of sensors are often integrated into cell phones, necklaces, or smartwatches that can detect sudden changes in a person’s movement when they fall or perform a certain movement [
1]. The main disadvantage of such approaches is that subjects must wear or place these devices on them. As such, they can be uncomfortable and clearly do not scale up for their use in open spaces and for multiple subjects [
2]. More recent proposals that use video images from RGB cameras to detect human activity free subjects from having to carry on-body devices and can be extended to the analysis of human activity in public areas and involving interactions among different people [
3,
4,
5,
6].
In other recent cases, instead of using RGB images directly, they are used to extract poses represented by a set of body joints and their interconnection (i.e., human skeleton representation) [
5,
7,
8,
9,
10], which are then used as features for further analysis. Such skeleton representations have been found powerful to differentiate between different types of activities such as walking, sitting, jumping, running, falling down, etc. Modern posture extraction from RGB images is not limited to images with single individuals, which is an important advantage compared to other works [
4]. Indeed, we have used this approach in a previous paper [
11], which uses skeleton features with well-known machine learning (ML) methods, demonstrating state-of-the-art performance for public reference datasets. That work also presented tests with an LSTM (Long Short-Term Memory) recurrent neural network that resulted in low performance due to the imbalanced dataset.
The use of deep learning applied to Human Activity Recognition has recently grown. The most popular architectures are Convolutional Neural Networks (CNNs) for their capacity to learn special features from images [
12] and Recurrent Neural Networks (RNNs) which are able to learn long-term temporal patterns present in the data [
13]. Yadav et al. [
14] present an activity recognition and fall detection network (ARFDNet) where the videos are passed to a pose estimation network to extract skeleton features, which are processed and inputted to a CNN followed by gated recurrent units (GRUs) to learn spatiotemporal dynamics, obtaining an accuracy of
. Song et al. [
15] propose a model using different levels of attention with an LSTM to learn discriminative skeleton joints. The work presented in [
16] develops a hybrid model by incorporating CNN and LSTM for activity recognition and tests it on a generated dataset, obtaining an accuracy of 90.89%, which shows that the proposed model is suitable for human activity recognition applications. In [
17], the visual attention mechanism is used and an end-to-end, two-stream, attention-based LSTM architecture is proposed for action recognition in videos, which can learn detailed spatiotemporal attention features and also can explicitly allocate content and temporal-dependent attention to the output of each deep feature in the video sequence. This method obtained an accuracy of 94.1% on UFC11, 96% on UFC sports, and 69.8% on jHMDB datasets. Other works such as [
18] propose a framework that employs deep learning and swarm-intelligence-based optimization techniques with 3D skeleton data for action classification; they extract features such as distance, distance velocity, angle, and angle velocity on encoded images that were fed into a CNN model, which is a modified version of Inception-ResNet, and were evaluated on public datasets achieving an accuracy of 98.13% on UTD-MHAD, 90.67% on HDM05, and 85.45% on NTU RGB+D60. Finally, [
19] introduces a soft attention mechanism in Temporal Segment Networks (TSN), which improves the ability to learn long-term information, enables the network to adaptively focus on key features in space and time, and verify the effectiveness on their model in four public datasets achieving an accuracy of 93.3% on UCF101, 67.9% on HMDB51, and 78.4% on JHMDB.
A characteristic of public datasets such as UP-Fall [
20] and UR-Fall is that both were created by simulating controlled activities in laboratory conditions and the human activity classes tend to be unbalanced, especially for activities such as falling down. It is well-known that the performance of deep classification algorithms can deteriorate when the data are not balanced—that is, when the available data are not evenly distributed among the different classes. The traditional and best-known approach to mitigate this problem is to increase the dataset by introducing instances corresponding to the classes with minority data, applying geometric transformations to the original instances. For example, in images for this, such transformation translates into rotations or reflections of the pixels. The main disadvantage of this augmentation approach is that it can corrupt relevant orientation-related features. In this sense, the inclusion of synthetic data generation algorithms based on deep learning has had greater importance as an approach to reducing the lack of balance. Generative Adversarial Neural Networks (GANs) have been proposed as a tool to artificially generate realistic data [
21,
22,
23].
The main contributions of the proposed work are as follows:
The use of novel deep neural networks such as BERT transformer networks for the recognition of activities using data of skeleton poses extracted from video images. As far as we know, our approach is the first activity recognition model that uses BERT networks directly with numerical data instead of text. Our proposal suggests that it is possible to use the characteristics of the pose (skeleton) of a person in video images as if it were a sentence (text)—this is how BERT interprets it. The way in which we approach this challenge is described in
Section 3.2.
The development of a direct comparison between the use of machine learning and deep learning models for the recognition of activities using the same methodology and the same dataset.
The use of data augmentation of the activities corresponding to the unbalanced classes demonstrating the hypothesis that it is possible to increase the performance of the BERT model by increasing the data of the unbalanced classes of the UP-Fall set using generative networks. The generation of these artificial data is achieved using GANs, which lead to better activity recognition performance. Performance is then compared with our previously published results for the UP-Fall dataset.
The paper is organized as follows.
Section 2 presents the description of the UP-Fall database.
Section 3 introduces the activity recognition approach and describes AlphaPose, the feature extraction method, the model to use, and the data augmentation system.
Section 4 shows the experimental results and the comparison with previous results. Finally,
Section 5 presents the conclusions and the proposed future work.
2. Datasets
The present work uses the UP-Fall dataset for the recognition of activities. The experimental results are compared with the results obtained in [
11] using the same dataset.
As described in Martínez-Villaseñor et al. [
20]—for completeness, outlined also here—UP-Fall includes 12 human activities of daily living performed by 17 subjects in a controlled environment, each subject making three repetitions of each activity. The first five activities correspond to fall activities, such as falling forward using hands, falling forward using knees, falling backward, falling sideways, and falling sitting on a flat chair. The other seven activities include more normal activities such as walking, standing, sitting, picking up an object, jumping, lying down, and kneeling. The twelve activities are shown in
Table 1. UP-Fall has a total of 816 videos, of which 255 correspond to falls and 561 to daily activities. The images are located at (
https://sites.google.com/up.edu.mx/har-up/ accessed on 20 January 2023). The files are organized into 17 folders, one for each subject. Within each folder, there are 11 sub-folders, one for each activity. Within these sub-folders, there are three other sub-folders, one for each repetition. In each sub-folder, there is a CSV file that points to a ZIP file with the recorded images. The complete dataset has
samples (
), where 49,544 samples (
) are labeled with fall activities and
samples (
) are labeled with daily activities.
3. Methodology
This work focuses on the recognition of human activities using only video data since, in practical applications such as assisted living and public space monitoring, the use of wearable devices and other sensor modalities is not realistic or convenient. The main hypothesis is that the performance of the methodology provided in our previous work [
11] can be verified using articulated bodies (skeletons) extracted from the video, even when modern deep learning techniques are used. Therefore, the goal is to implement an activity recognition method using the UP-Fall dataset and the sliding window methodology described in [
11]. The results are obtained when using a Transformers BERT network. After this, GAN networks are tested for data augmentation and the BERT model is re-evaluated with more balanced data.
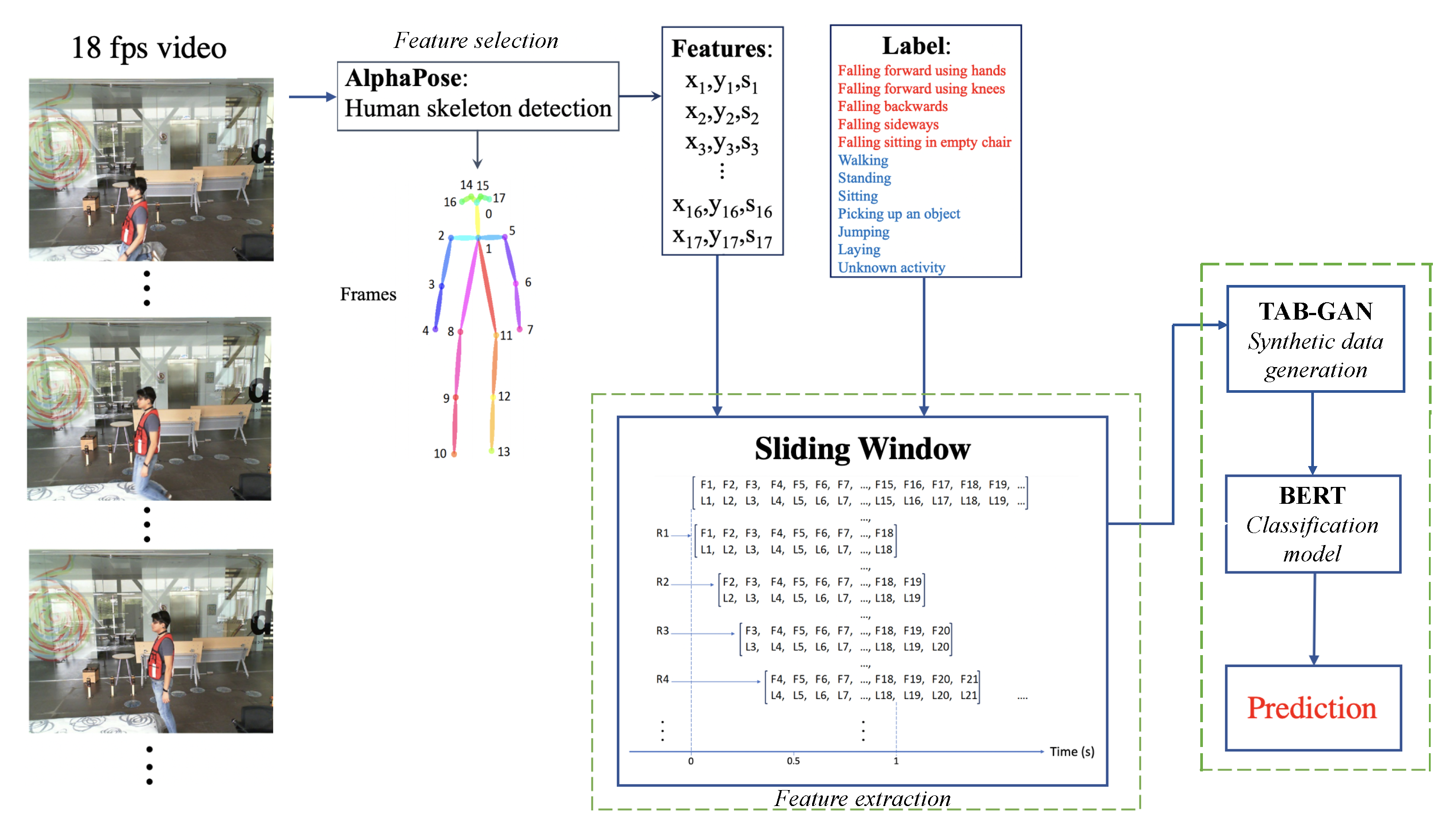
The method developed for this study is illustrated in
Figure 1. It consists of data collection; feature extraction using human skeleton estimation; skeleton filtering; creation of sliding windows (each window with a size of 2 seconds and 3 frames per window); and finally, a neural network classification for recognition activities. All steps are implemented using Python 3.6.
3.1. Feature Selection and Extraction
As mentioned in
Section 2, the UP-Fall dataset is used to carry out the experiments of this work. This dataset is selected to make a more direct comparison with the work carried out in Ramirez et al. [
11]. Once all the UP-Fall images are downloaded, the skeletonization is performed as explained below.
3.1.1. Skeleton Detection
AlphaPose is an open-access method for estimating the postures of multiple people [
24], available at (
https://www.mvig.org/research/alphapose.html accessed on 20 January 2023). It uses RGB images as input and performs posture detection with a pre-trained model (with the COCO database), obtaining as output the positions
of 17 key points or joints with coordinates
, together with the detection confidence score of each one, forming a skeleton with the posture of the person or persons of interest. For each person, there are
attributes per frame. Time sequences containing these skeleton attributes are generated in this way for UP-Fall.
3.1.2. Sliding Windows
For a direct comparison with [
11], sliding windows with the same characteristics and the same dataset are used. Each window has a size of 2 seconds, with 36 frames for each window, of which only 3 frames (the first, the middle, and the last) are selected to reduce the size of each vector of features and to decrease processing time. Therefore, each feature vector with length 153 (51 skeleton attributes * 3 frames) serves as input to the classification model.
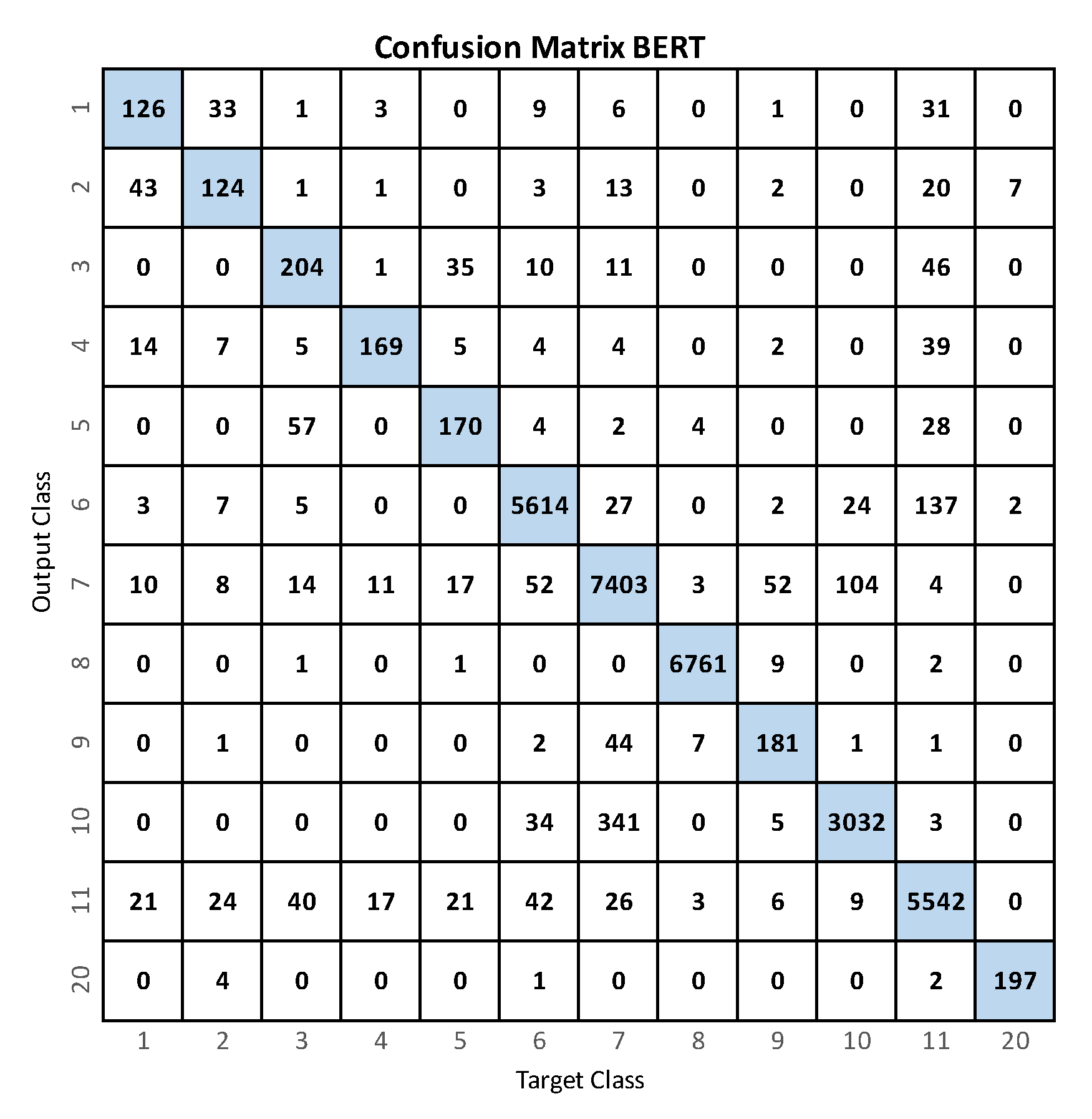
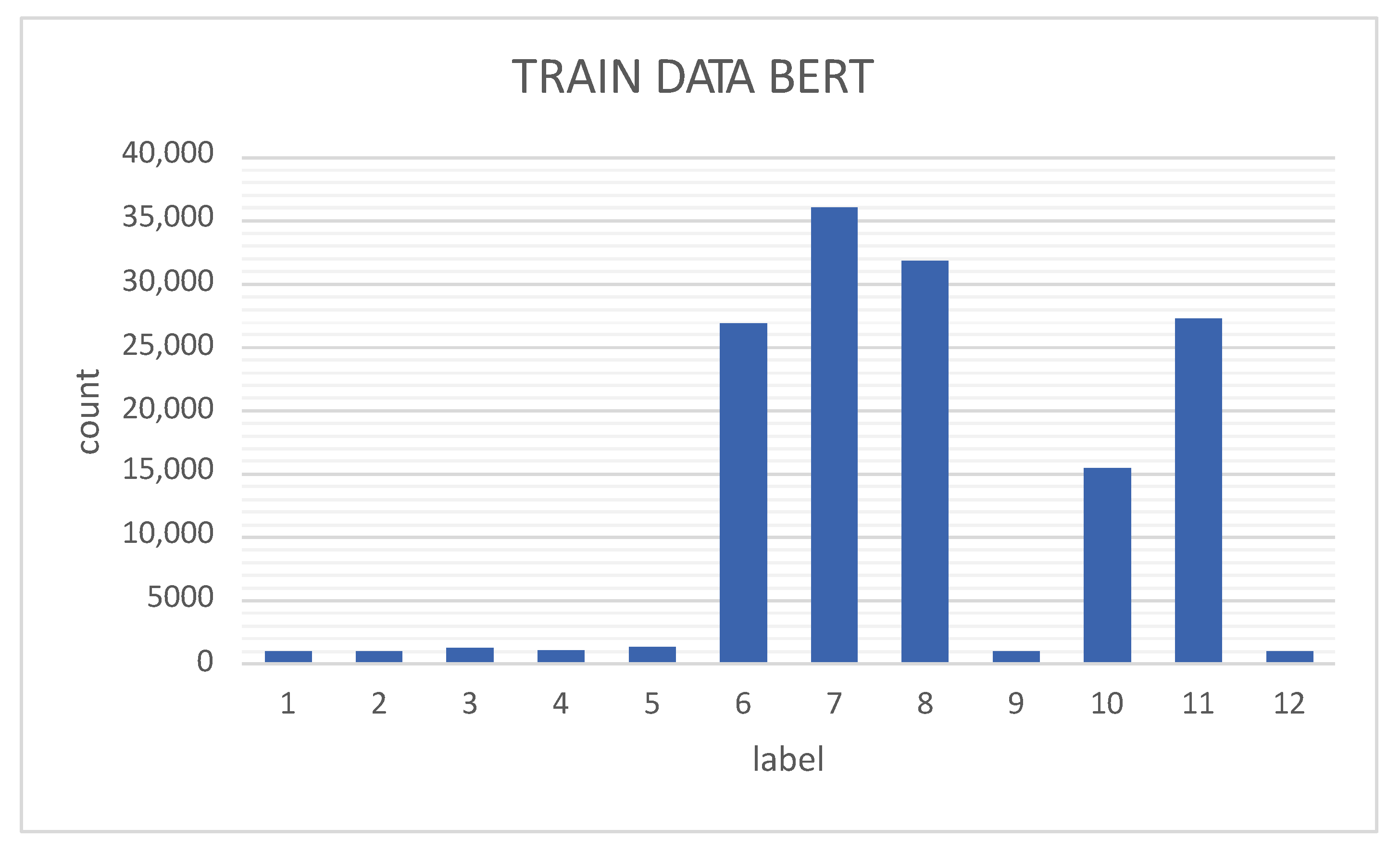
Activity recognition is performed using multi-class classifiers. Each sliding window contains one of twelve UP-Fall activities. Of the sliding windows, 1473 () correspond to the activity of falling forward using hands; 1473 () to falling forward using knees; 1858 () to falling backward; 1560 () to falling sideways; 1863 () to falling sitting in an empty chair; 38,570 () to walking; 51,573 () to standing up; 45,439 () to sitting; 1456 () to picking up an object; 22,067 () to jumping; 38,771 () to laying; and 1394 () to unknown activity.
3.2. Classification Model
This work seeks to improve the results of the best Machine Learning model (RF, Random Forest) reported in [
11] with the CAM (camera) modality and the sliding windows methodology using skeletons. Therefore, a deep learning model is chosen to investigate whether that methodology also works with more modern techniques.
Considering the poor results reported in [
11] when using an LSTM network, it is decided to test a transformers network with the hypothesis that activity recognition is possible when using recurrent neural networks using the same methodology and the same dataset.
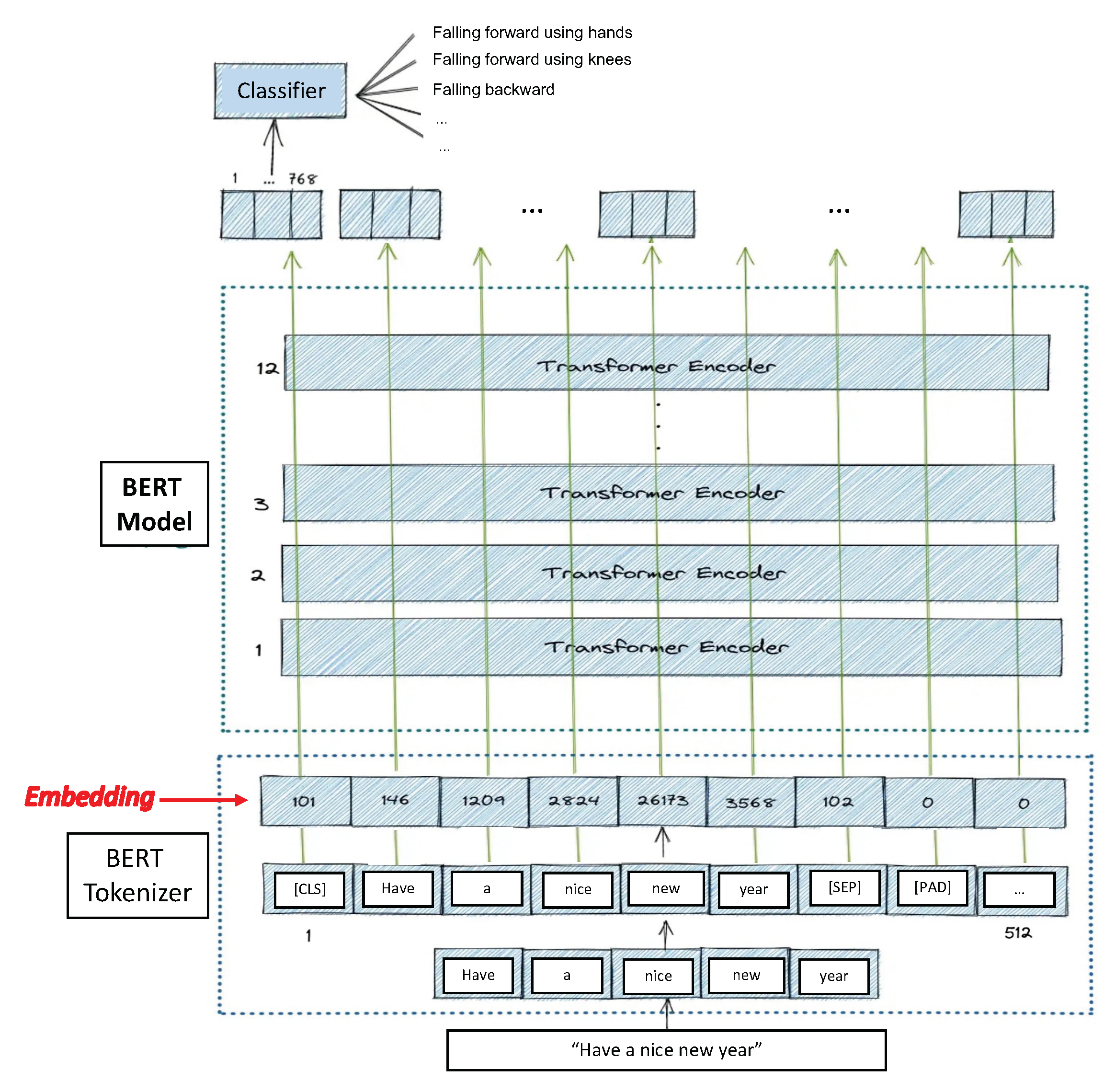
Taking into account that the feature can be represented by one dimension, a Bidirectional Encoder Representation of Transformers (BERT) is used to classify the activities. BERT is a cutting-edge, attention-based natural language processing (NLP) technique [
25] created and published by Google in 2018. Bidirectional means that it looks at the left and right context to understand a text. It can be used for prediction, answering questions, language inference, and more. Here, BERT is used for activity classification using the Hugging Face library of transformers. All tests are implemented using Pytorch.
BERT is basically an Encoder stack of transformer architecture. A transformer architecture is an encoder–decoder network that uses self-attention on the encoder side and attention on the decoder side. BERT has 12 layers in the Encoder stack. The BERT architecture has large feedforward networks (768 hidden units). It contains 512 hidden units and 8 attention heads. BERT contains 110 M parameters.
BERT can take sentences as input. The [CLS] token always appears at the start of the text and is specific to classification tasks. The [SEP] token always appears at the end. It is also important to note that the maximum size of tokens that can be fed into the BERT model is 512. If the tokens in a sequence are less than 512, padding is used to fill the unused token slots with [PAD] tokens.
The BERT then passes the input to the above layers. Each layer applies self-attention, passes the result through a feedforward network, and then hands off to the next encoder. For the text classification task, we focus our attention on the embedding vector output from the special [CLS] token. This means that we are going to use the embedding vector of size 768 from the [CLS] token as an input for the classifier, which will then output a vector of the size of the number of classes in the classification task.
In order to convert the words into numerical representations, we first take the sentence and tokenize it. After that, we convert the sentence from a list of strings into a list of numerical indices (word embedding). Thus, the original word is split into smaller subwords and characters. This is because the BERT vocabulary is fixed to a size of 30,000 tokens.
Finally, we need to convert our data to tensors (the input format for the model) and call the BERT model. Thus, this trained vector can be used to perform different kind of tasks such as classification.
Having outlined how BERT works and what it expects at the input, we give way to the novelty of our proposal. Taking into account that our feature vector, which has a size of 153 skeleton features for each sliding window, is made up of numerical data and not of words, our proposal is to eliminate the stage in which BERT tokenizes the sentence (text) and immediately skip to the embedding stage (see
Figure 2).
BERT is trained with 30,000 natural language words; so, each word of the linear vector will be represented by a number between 0 and 30,000. Taking that into account, we process our 153 × 1 size features vector as if it were text; thus, all vector data are normalized so that each numeric datum can only have an integer value between 0 and 30,000. Considering that the features of the skeleton’s pose are presented as numerical data (
x and
y coordinates in the image plane and a number indicating the score), each feature value maps one of the 30,000 BERT Tokens. To this end, we have used the Min–Max scaling algorithm, which is summarized by the following equation:
where
F is a feature’s value, and
and
are the minimum and maximum numeric values of the entire dataset, respectively. Note that we only consider the integer part of
.
For this work, the has four dimensions in the following order:
The layer number (13 layers): 13 because the first element is the input embedding; the rest are the outputs of each of BERT’s 12 layers.
The batch number: 1 vector (for each sliding window).
The word/token number (153 tokens in our vector).
The hidden unit/feature number (768 features, BERT’s default).
Table 2 summarizes the hyperparameter settings for the classifier model. The proposed approach uses a pre-trained BERT neural network, which is invoked with the BertModel from _pretrained instruction of PyTorch without modifying any default parameters; these parameters are as follows:
input_ids: typing.Optional[torch.Tensor] = None.
attention_mask: typing.Optional[torch.Tensor] = None.
token_type_ids: typing.Optional[torch.Tensor] = None.
position_ids: typing.Optional[torch.Tensor] = None.
head_mask: typing.Optional[torch.Tensor] = None.
inputs_embeds: typing.Optional[torch.Tensor] = None.
labels: typing.Optional[torch.Tensor] = None.
next_sentence_label: typing.Optional[torch.Tensor ] = None.
output_attentions: typing.Optional[bool] = None.
output_hidden_states: typing.Optional[bool] = None.
return_dict: typing.Optional[bool] = None.
In addition, it is set with the following options:
self.drop = nn.Dropout(p = 0.1),
self.out = nn.Linear(self.bert.config.hidden_size, n_classes),
where n_classes = 12.
Our previous work [
11] mentioned that an LSTM resulted in low performance due to the notable data imbalance between the 12 UP-Fall classes. That is why in this work it is decided to investigate a data augmentation method to try to balance the classes and to compare the performance between a BERT model with unbalanced data versus a BERT model with balanced data.
3.3. Synthetic Data Generation
Generative adversarial networks (GANs) are composed of two deep neural networks: the generator and the discriminator. The goal of the generator is to generate false (artificial) instances that cannot be easily distinguished from true instances by the discriminator [
26]. These two networks are trained simultaneously with adverse targets. The discriminator tries to maximize its classification accuracy (by correctly identifying which images came from the generator), while the generator tries to get the discriminator wrong. Recent architectures such as StyleGAN are capable of producing images that are not far from reality [
27]. However, most datasets used in the industry are tabular in nature. In this particular approach, the data available to train the model consist of instances composed of vectors of 153 features (
frames); so, a generation system that is compatible with this type of data is required. Tabular generative models allow the production of artificial data with a distribution similar to the training data, taking into account that these data correspond to a table where each row or instance is sampled independently and each column can contain continuous or discrete values. While in the literature there are several methods to perform this task [
28,
29], in this work, TABGAN [
30] will be used since the model is readily available as a library.
TABGAN contains a continuous data normalization phase in which a variational Gaussian mixture model (VGM) is used to create a vector that encodes each of the continuous instances. Further, the generative network includes a conditional vector, which forces the generator to produce an instance of a specific category. The conditional vector contains all the coded discrete columns with value 0, except the one that we want to satisfy with the generated instance. The training is performed by sampling. In each iteration, a column is randomly selected; from this column, a category is selected based on a probability function built from the frequency of each category in that discrete column. Finally, this category is transformed into the conditional vector that is the input of the generator. This training mode allows the generated distributions to match the distributions of the discrete variables in the training data.
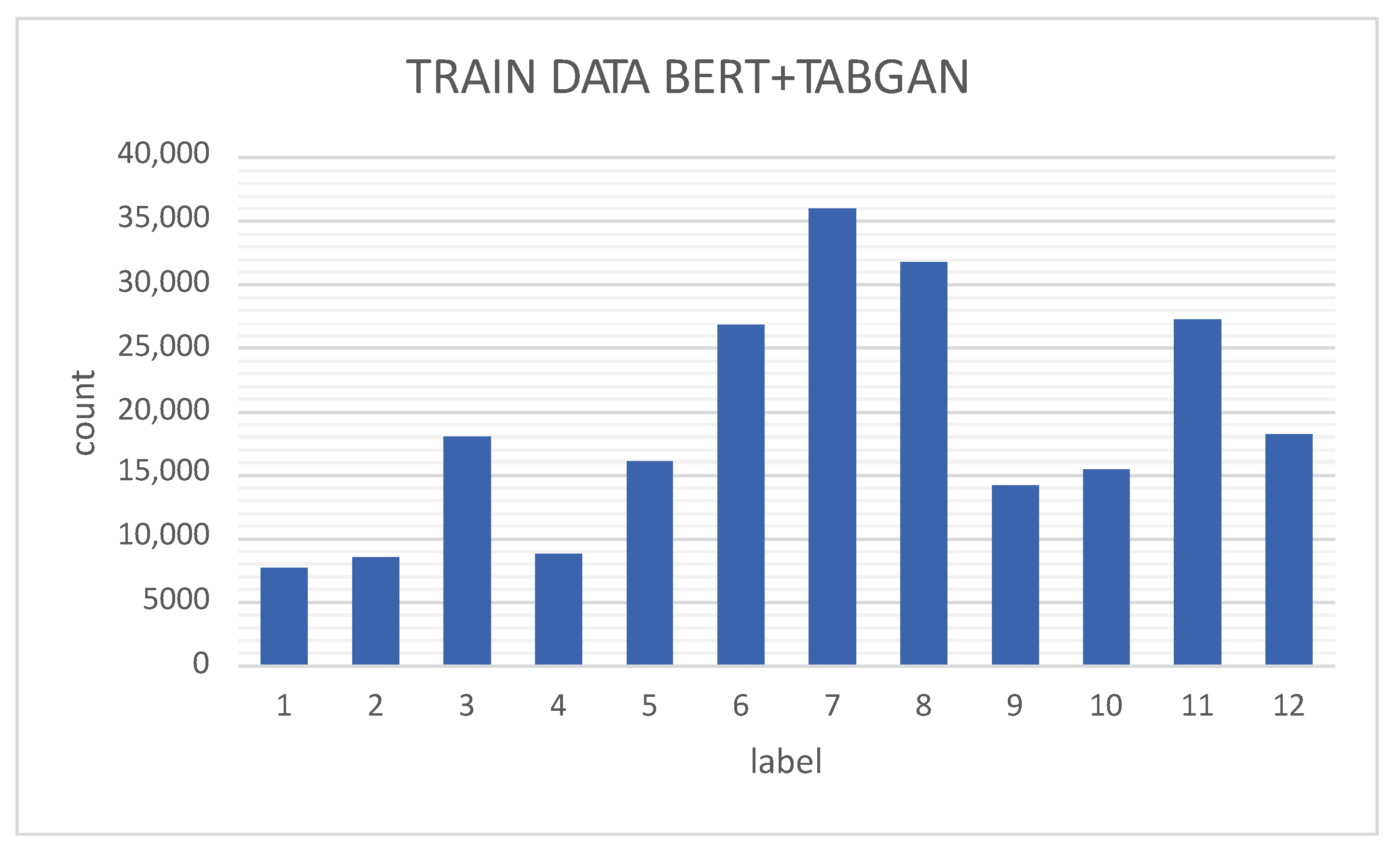
The 207,497 samples were obtained from the UP-Fall dataset, each containing 153 features, with
Table 3 showing the data distribution by class. The second and third columns show the number of actual data per class and the equivalent percentage, respectively. It can be seen that classes 6, 7, 8, 10, and 11 contain more than
of the data and that the rest of the classes each contain less than
of the total. Consequently, models trained on these data may be limited to mostly recognize the majority classes correctly. The fourth column shows the number of artificially generated data for the minority classes, where the number of data is increased by about
. It can be seen in the sixth column that the percentages of each class are more similar than before; therefore, the dataset is now more balanced.
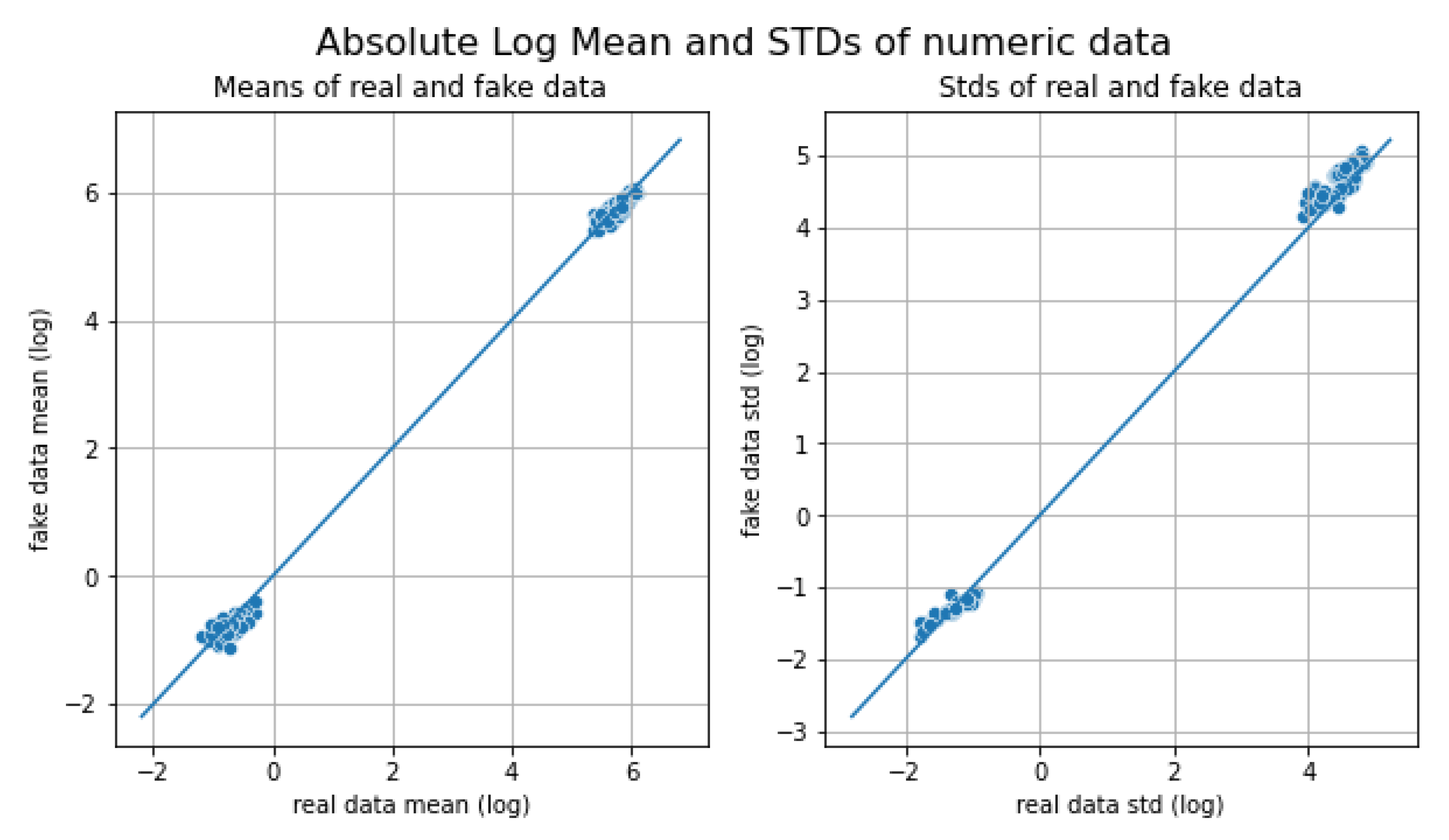
Figure 3 shows how the real data are correlated with the false ones. The mean is on the left, the standard deviation is on the right, and the diagonal lines mean equality between real and false data. Each point represents an instance, and it can be seen that they are grouped at two extremes of the graphs. However, they are close to the diagonal line of equality, so it can be said that the data generated are correct. For each feature, it can be seen how similar the real data are to the generated data.
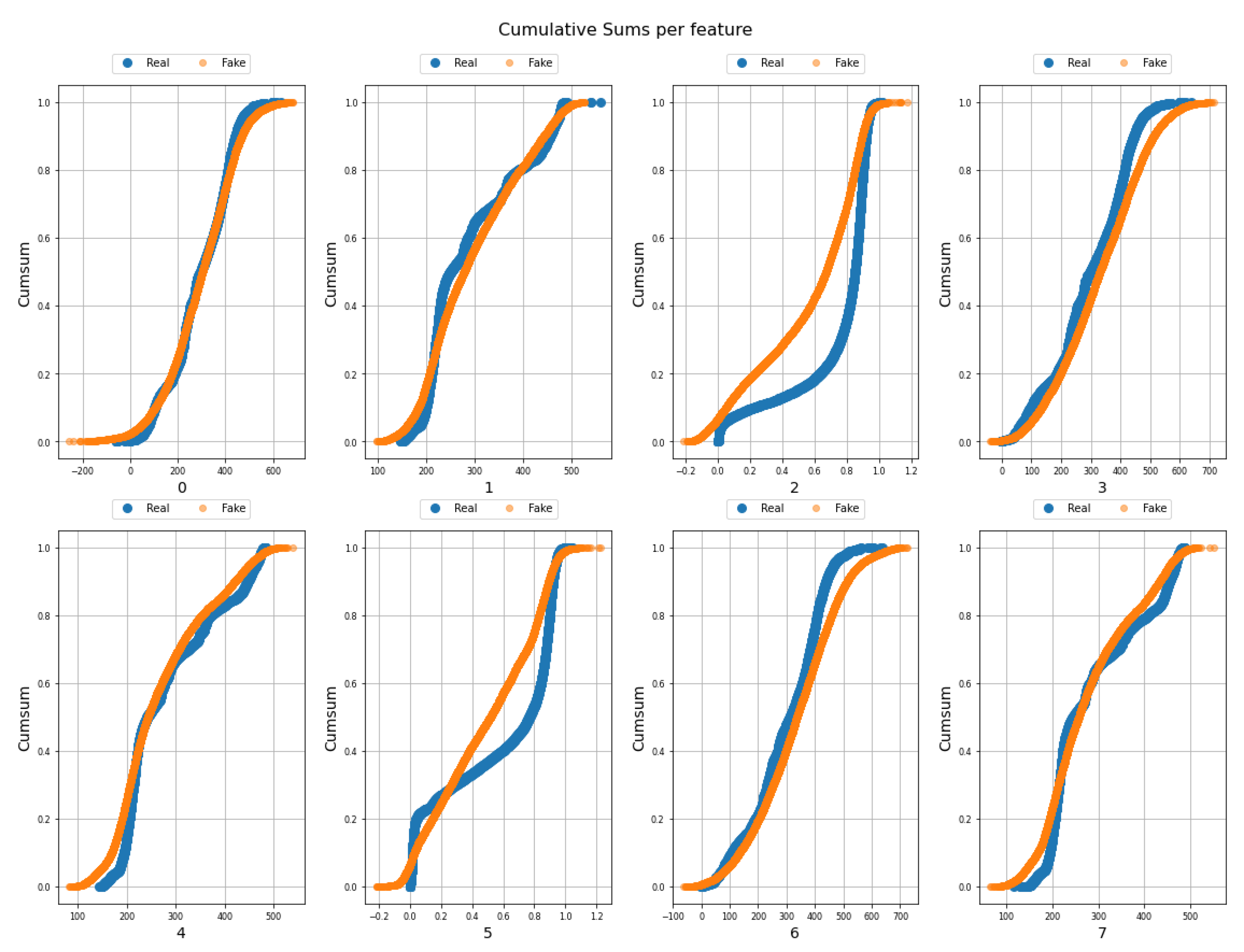
Figure 4 shows the cumulative sum of all real and synthetic or fake instances per feature. For clarity, only the first 8 features of the 153 features are shown. It can be seen that characteristics 2 and 5 are the ones that present the most complexity when generated due to their distribution. The graphs are not identical but there are characteristics such as 1, 3, 4, 6, and 7 whose accumulated sums are quite similar for the case of real and fake data.
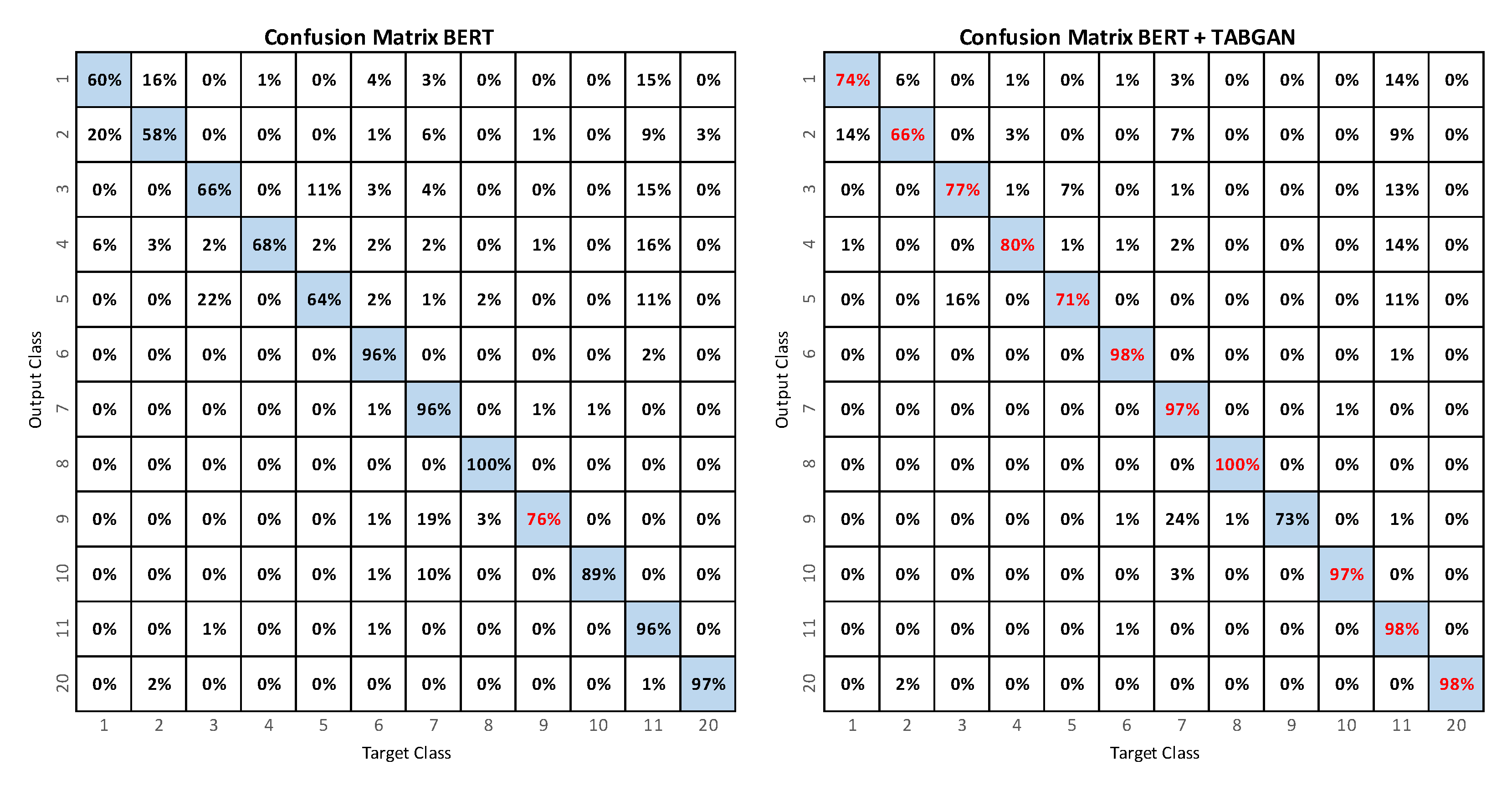
5. Conclusions
This paper presented an activity recognition approach using video data with a classifier model based on transformers using human skeleton poses as inputs and tested using the public dataset UP-Fall to provide a direct comparison with previous work reported in [
11]. The presented BERT model outperforms the results obtained by the LSTM, SVM, and MLP models.
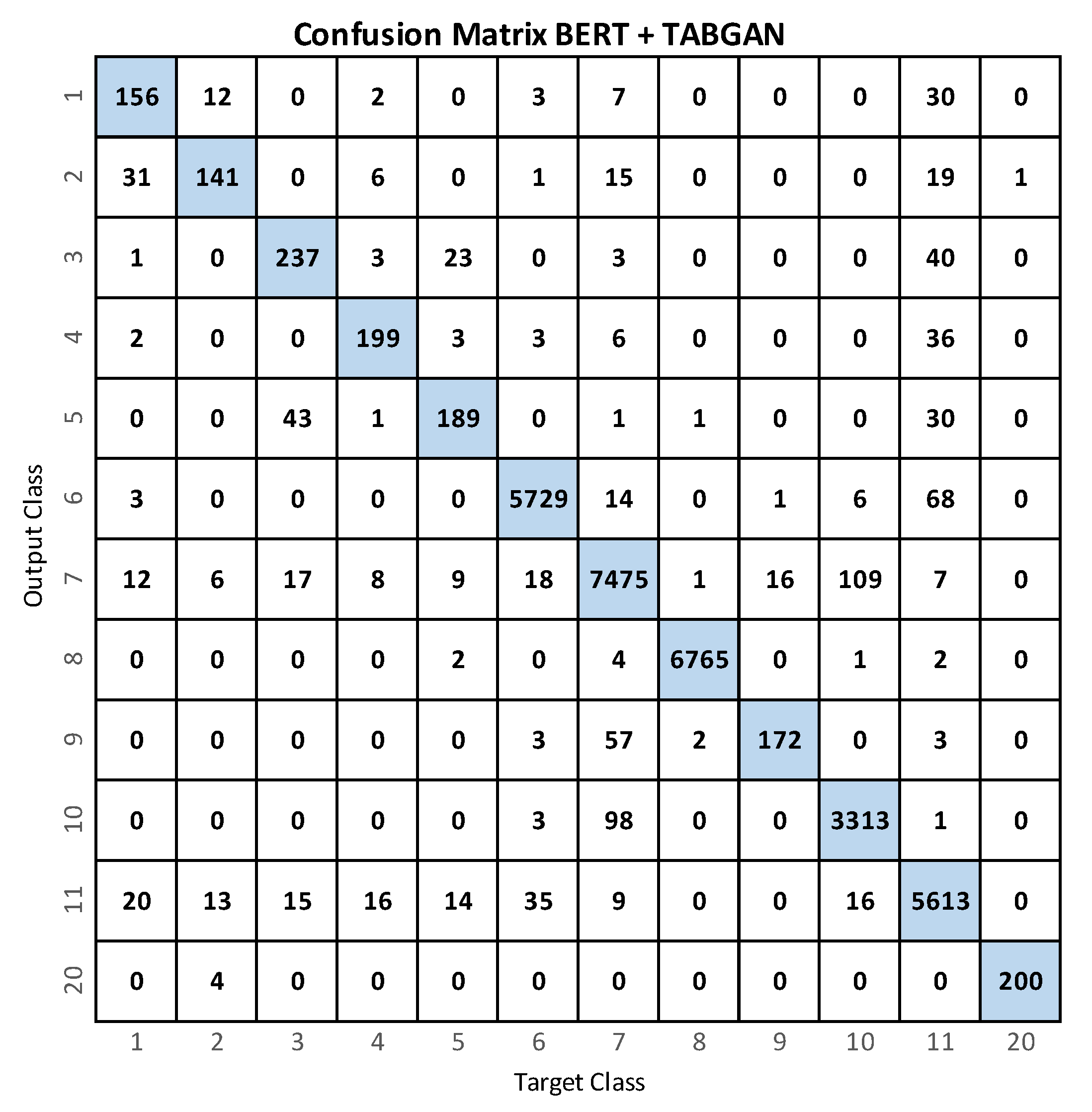
The proposed method demonstrated that data augmentation using GAN to generate synthetic data improved model performance since a balanced database adds generalization capability to the classifier. Using an optimization method, it is possible to find the proportion of artificial data that allows obtaining the best performance for the BERT classifier.
Although
Table 6 shows that the [
11] RF model is still better than our TABGAN, it is important to highlight some advantages of our model over the models delivered in previous works. Thanks to the use of GAN networks combined with BERT, it is possible to use datasets for the recognition of activities, even when the classes are unbalanced or when the amount of data is scarce. On the other hand, the use of BERT networks in vision applications opens up many possibilities, such as combining the use of words and skeletons with the pose information of a person in an image to create new images or videos from only a sentence or to tell stories from images.
Future work is expected to validate with other pre-trained models based on transformers and different GAN architectures to increase detection rates and verify the proposed methodology’s operation with other datasets of multiple people in open spaces.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}