1. Introduction
Currently there is a large amount of data generated by the massification of various information systems, where many of them are based on sensors [
1]. These data typically need to be channelled and processed in order to be transformed into useful information for the people involved in data analysis. In general, they are enormous and also poorly structured, making difficult their manual analysis. A recent alternative to deal with them is to use the machine learning methods, which consist of learning to automatically recognise patterns from data [
2].
In particular, the sensors are applied in the vehicle telemetry sector in cities, which provide large volumes of data generated by the continuous monitoring of vehicles through installed GPS devices [
3]. During a measurement, each vehicle sends its temporal and spatial information, as well as sensor values, where such data are normally stored in the cloud. Vehicle monitoring allows companies to make better routing decisions for drivers and detect slow traffic zones; from a governance point of view, this information can allow the creation of localized traffic policies [
4]. Moreover, the detection of outlier trajectories monitored by the authorities can be important for people’s urban safety [
5].
In the context of vehicle telemetry considering GPS sensors, there is the possibility that there are errors in the GPS measurements provided by the satellites. The sources of ranging/positioning errors of GPS sensors in cities are mainly due to atmospheric interference caused by possible signal delays in the ionosphere, to correction and rounding errors caused by spatial events affecting the correction models based on altered GPS signals, to satellite data errors due to changes in the position of the satellites in relation to the measurement time, and to multi-path errors caused by signal reflection from surfaces close to the receiver, which is a common event in urban environments (see, for example, [
6,
7,
8,
9], among others). These errors may generate anomalous data.
In terms of GPS sensor data, three types of anomalies are described in [
10]: distance-based, velocity-based, and acceleration-based. Each of them refers to abrupt changes in patterns in each of the measures considered. Note that all these anomalies can be caused by errors in the ranging or GPS positioning. On the other hand, these anomalies can also be caused by the loss of the GPS signal due to various factors in the urban context such as entering a tunnel, proximity to buildings, or the malfunction of the GPS device itself [
11], which can be reflected in abrupt measurement changes. Note that manual labeling of these anomalies can be tedious due to the noisy nature of GPS data.
Detection of sudden and sharp increasing errors can be performed by means of models based on minimum and maximum velocity constraints. However this scheme may fail to detect errors where speed errors cause out of bounds values such as one meter deviations from the value measured by the GPS [
12]. Furthermore, by adding the sequence of measurements, the errors can accumulate, increasing the total error of the GPS device [
13].
Detection of slowly increasing positioning errors may therefore be less obvious to perform than abrupt errors. An alternative is to use models based on space-time graphs that consider the geometrical and topological characteristics of the streets as well as the temporary restrictions on vehicle speeds [
14]. Unfortunately this method requires several steps as well as non-trivial parameters. There are many other approaches that can be applied to detect this type of error, like those based on statistical [
15], logical [
16], data outliers [
17] and clustering methods [
18].
Although there is a wide variety of applicable methods [
12], they usually consider several non-trivial parameters that may not necessarily lead to capturing the non-linear patterns of the sequence of GPS measurements since they are based on linear statistical assumptions. Therefore, an alternative is the use of deep neural networks for the detection of outliers in GPS trajectories, since they are models that allow the capture of the non-linear and complex relationships between the variables measured by GPS devices.
In particular, the identification of anomalous values in GPS trajectories can use methods for the detection of time series outliers, since GPS normally provides measurements at regular intervals over time. In the last decade, many methods have been proposed in various fields to detect anomalies in time series.
Yan et al. [
19] propose an anomaly detection design with the unsupervised learning approach for multivariate observations, using a
stacked denoising autoencoders (SDAE) network, which learns more robust features for the input noise. The learned features of the SDAE are taken as input to an extreme learning machine (ELM) to classify whether an observation is anomalous or not. An ELM has connections between input and hidden neurons that are randomly generated and arranged. Singh [
20] proposes an unsupervised approach for univariate time series anomaly detection by combining a long- and short-term memory (LSTM) network and a recurrent neural network (RNN). The LSTM-RNN model is trained only with normal data and without anomalies; in this way the model learns the normal behavior of the time series; thus when the model is used for predictions of new data, it will give a higher prediction error in regions with anomalies compared to normal regions. An outlier detection method for univariate observations is also proposed by Ma et al. [
21]. In [
21], the time series is divided into subsequences using a sliding window, then an autoregressive (AR) prediction model is applied to each subsequence to predict the value of the next point. Finally, they calculate a prediction confidence interval (PCI) based on the nearest neighbor’s historical data, where, if the predicted value falls outside the PCI, it will be considered an outlier value. Lu et al. [
22] face the issue of the detection of multivariate outlier time series with an unsupervised approach using deep learning. Their model integrates a denoising autoencoder network (DAE) that is used to automatically extract features from raw data and a recurrent network (RNN) which is used to model the temporal structure. The goal of the DAE network is to capture the intrinsic difference in densities between outlier and normal instances, while the RNN network seeks to obtain contextual information and, therefore, improve the construction of the features. For the identification of outliers they use the reconstruction error so that, if the time series has a high reconstruction error, then it is considered an outlier. Cao et al. [
23] introduce a neighborhood-based time stream outlier detection algorithm. This method is based on the estimation of the neighborhood of trajectories in a database considering the estimation of an outlier factor, which is based on the number of data outliers in the trajectory. On the other hand, outlier data are based on the distance of each point from its neighborhoods.To speed up the calculations consider a data tree representation. Eldawy et al. [
24] present the FraudMove model for online detection of abnormal trajectories in taxis. In this work, anomalies are detected by comparing the time traveled with respect to the estimated time according to the proposed model. The time estimate is based on the application of the Viterbi algorithm to infer the most probable route according to the route followed at the moment, and then dynamically estimate the time needed to reach the route.
Recently, Han et al. [
25] propose DeepTEA (deep-probabilistic-based time-dependent anomaly detection algorithm) which is a hybrid model of neural networks and probabilistic models for detecting anomalous trajectories. In this work, the average speeds of vehicles are spatially represented on grids to model the traffic condition at each time, then a convolutional network is used at the spatial level, and later a LSTM network at the temporal level. This method allows to obtain time-dependent outliers from a huge volume of trajectories and detect them accurately.
In the context of GPS detection anomalies, Kieu et al. [
26] present two models for the detection of anomalous time series for multivariate observations using an autoencoder-based convolutional neural network (2DCNN-AE) and an autoencoder-based Long Short Term Memory network (LSTM-AE). Furthermore, they propose a method to enrich multidimensional time series to capture different aspects of the temporal changes in the time series and transform them into matrices so that they can be processed by 2DCNN-AE. For the LSTM-AE network, the matrices are taken and the rows are concatenated in a one-dimensional vector. As in [
22] reconstruction error is used for the identification of outliers. A variant of this work is presented by Kieu et al. [
27] As the main difference, they propose the use of sparse variants of recurrent networks grouped into ensembles to reduce overtraining in outlier detection, leading them to outperform the compared models.
In this work, we propose a method based on stacked autoencoder neural networks for the identification of anomalous values in the trajectory of vehicles measured by GPS. These neural networks do not require labels, so they can be adapted to this problem. To evaluate the performance of the method, we apply it to GPS measurements collected in the city of Santiago de Chile by a private company. The data set includes 13 million measurements considering 15,000 sensors. In summary, the contributions of this research can be summarized in
Proposal of a stacked autoencoder neural network model for detecting anomalous sequences of GPS measurements in urban vehicles considering fully connected and convolutional architectures.
Comparison of fully connected and convolutional autoencoder architectures.
Evaluation of model results regarding anomalies detected by human users.
Our proposal mainly differs from the works by [
20,
22] since they use RNN and LSTM networks, while we propose fully connected and convolutional models additional to relative spatial relationships that can recognize outlier trajectories. Also, [
21,
23] models are based on autoregressive and neighborhood-based models that do not necessarily capture non-linear relationships between sequence measurements. The complex model presented in [
25] considers maps with multiple trajectories, while we consider single trajectories. Unlike our proposal, the methods introduced in [
26,
27] consider aggregate features generated in a two-step process given by obtaining features based on time series differences and obtaining statistical features. Also, when performing the reconstruction of the time series, they consider the added features as new variables to be reconstructed, generating a 2D input matrix. In this way, the authors use typical operators of convolutional networks applied to images such as 2D convolution and max pooling. Instead, our proposed model is simpler since it considers 1D convolutions, which facilitate its implementation, reconstructing the original data given by the GPS measurement sequences. In general, the cited methods, including [
26,
27], are evaluated in labeled databases where the outliers correspond to the less frequent classes and in [
25] outliers are artificially generated, while our proposed method is applied to a real unlabeled database during both training and testing.
2. Proposed Model for Detection of Outlier Trajectories
An alternative to detect outlier trajectories is by using classical outlier detection techniques. There are numerous alternatives to detect outliers such as models based on convex hull [
28], clustering [
29], k-nearest neighbours [
30], among others. A classic density-based outlier detection model is given by LOF (Local Outlier Factor) [
31]. This model is based on calculating the density of regions in the data using k-neighborhoods and declaring the objects in low-density regions as outlier values. The techniques mentioned above explore outlier values in their original data spaces and have been shown to work well on linearly separable distributions; however they tend to perform less well than nonlinear structures, according to [
32]. An alternative to model non linear outlier patterns is by using autoencoder neuronal networks.
An autoencoder is an artificial neural network that tries to copy its input to its output, and internally compresses the input data into a hidden layer
h, called
latent space, with which it reconstructs the input data (see [
33] for theoretical concepts and mathematical details). This data compression is based on reducing the number of neurons in the hidden layer, and, in this way, the network is forced to learn a representation of the main patterns of the input data. Since outliers often correspond to non-representative features, it is likely that the autoencoder network will not be able to reconstruct the outliers using the latent space, and this reconstruction allows us to flag as outliers those data that are not well explained using the latent space.
Autoencoders can be stacked to form a deep network. This neural network is called a stacked autoencoder and is typically made up of two interconnected subnets: the encoder and decoder networks. In general, the more layers there are in the encoder and decoder subnetworks, the more complex encodings this network will be able to learn.
Encoder network: It is formed by the input layer and a set of hidden layers: this subnet compresses the input data
x to a latent space and the training of said network is done one layer at a time. Each layer is trained as an encoder by reducing the number of neurons and it receives as input the latent representation of the previous layer until reaching the hidden layer
h that describes the latent space of the network. The encoder network is represented by the Equation (
1).
Decoder network: It is formed by a set of hidden layers and the output layer: this subnet reconstructs the original input
based on the latent space
h and the training of said network is done one layer at a time. Each layer is trained as a decoder by increasing the number of neurons and it receives as input the reconstruction of the previous layer until reaching the output layer, which has the number of neurons equal to that of the input layer. The network decoder is represented by the Equation (
2).
The stacked autoencoder can be represented by the Equation (
3).
The implementation of autoencoder networks requires that they are not very complex because they can learn to memorize the input without obtaining a useful data representation [
34]. In this work we implement the densely connected and convolutional neural networks for the encoder and decoder pair of the autoencoder network applied to the detection of outlier trajectories.
2.1. Densely Connected Stacked Autoencoder Network
The first model uses densely connected layers, that is, all the neurons of a layer
L are connected with all the neurons of the next layer
. Therefore the input of a neuron of the layer
is the correlation of all the outputs of the neurons of layer
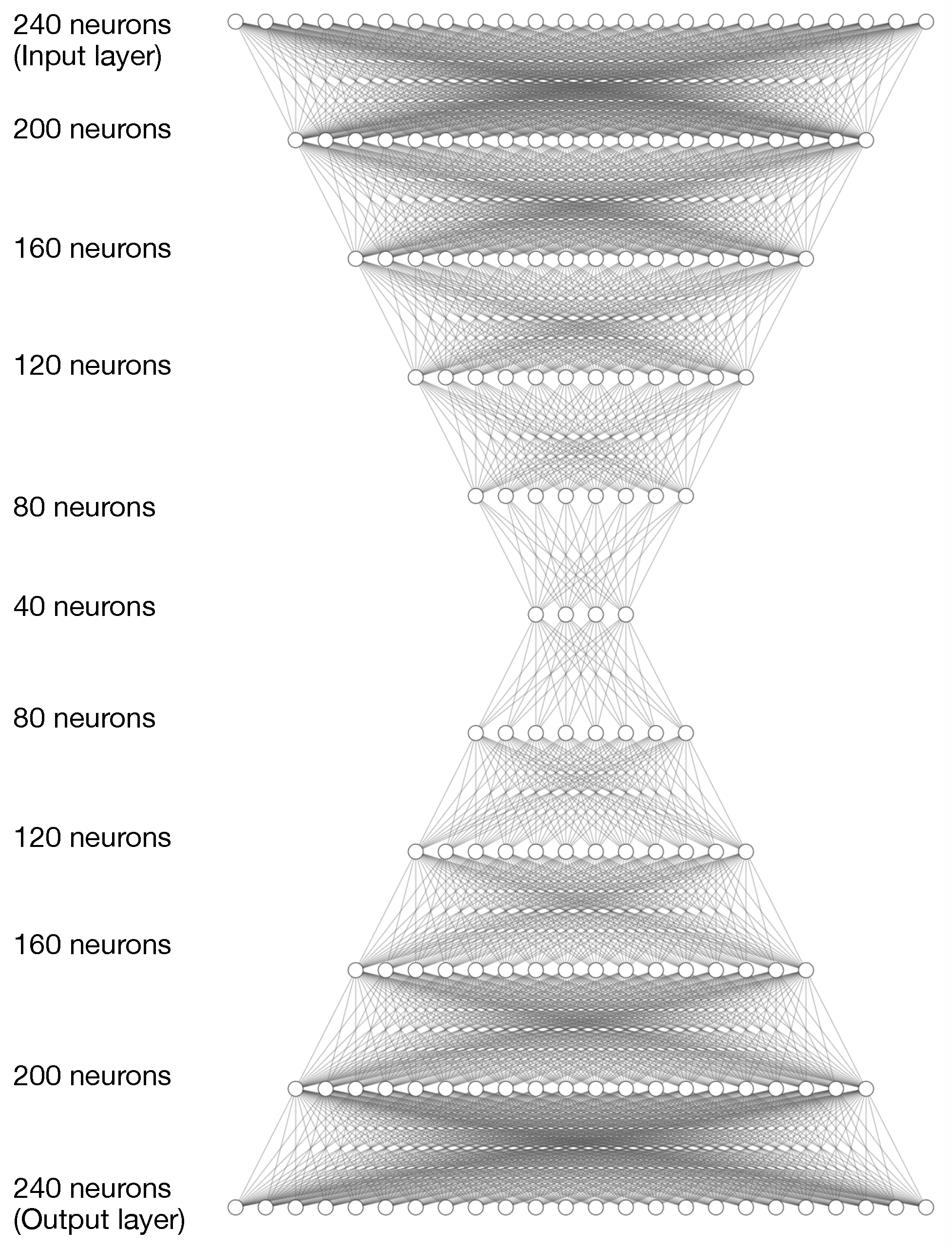
L. The model receives as input a time series that has a set of multivariate observations and correlates all the observations which have six variables each, making the number of connections dependent on the number of observations and variables. To detect if a time series is an outlier, the model correlates the context of the time series, that is, all the variables of all the observations are associated. An example of an architecture used in experiments (
Section 4) is shown in
Figure 1. In this case, the neural network has five layers for the autoencoder and decoder subnetworks made up of 240, 200, 160, 120, 80 and 40 neurons, forming a typical symmetric structure in stacked autoencoder networks.
2.2. Stacked Convolutional Autoencoder Network
The reason for using convolutional models is based on the idea that, if an observation has an anomalous behavior with respect to the adjacent observations, then it is not necessary to correlate all the observations. This second proposed model associates the set of neighboring observations, which reduces the number of connections. The model uses a filter or sliding window to correlate the neighboring observations, and for this it uses the convolutional layers that use filters that correlate the observations; this procedure is applied to the following layers. With this method, the model is not forced to look for correlations between all the observations; on the contrary, it allows us to correlate the observations that we want.
Figure 2 shows the design of the stacked convolutional neural network.
This stacked convolutional autoencoder network receives as input a time series in the form of a two-dimensional grid. Next we will indicate the steps followed for the construction of the same in our proposal.
2.2.1. Step 1
Given a time series , where , , is a multidimensional observation , first the correlation between the observation variables is sought so that the size of the first filter is d, then the filter is applied to each observation obtaining a transformed time series , where is the correlation of the variables of and is also one-dimensional, i.e., .
2.2.2. Step 2
Given the transformed time series , we look for the correlation for each row of the transformed series, which is made up of a pair of observations. Since is one-dimensional, the size of the filter is two. The filter is applied to each row and a new transformed time series is obtained: , where is one-dimensional.
2.2.3. Step 3
Unlike the previous steps where the size of the filters is always the same, in this step the correlation between observations with different filter sizes is sought. Specifically in this step the size of the filters and the displacements to move the filter can be defined. Then, given the transformed time series , a filter is applied and a new transformed time series is obtained: . This step is repeated until a latent space is obtained.
2.3. Models Implementation
For the two proposed models, the hyperbolic tangent activation function and stochastic gradient descent were used as the optimization algorithm. Regarding the evaluation metrics, the coefficient of determination and explained variance were used. Since it is a regression problem, the optimization function was the mean square error cost function. The demo source code of this work can be found at
https://github.com/sagagk/Autoencoder_Outliers (accessed on 1 October 2022).
4. Experiments
For the experiments, the Hold-Out method was used to train and evaluate the model, considering 70% for training and 30% for testing. Since this problem corresponds to a regression, the mean square error was used as the cost function. The mean square error (MSE) given by
provides an average error between the difference of the original data and reconstructed data, where
x is the time series of the variables GPS, given in
Table 1,
is the time series of GPS variables reconstructed by the model and
n is the number of observations. The GPS variables correspond to the measurements obtained by the GPS sensor in the trajectory of a vehicle.
For the quantitative evaluation, the validation metrics used in this project are the coefficient of determination (
) and the explained variance (
). The coefficient of determination measures the goodness of the fit made by the model and allows deciding whether the linear fit is sufficient, while the explained variance measures the proportion to which a model explains the variation (dispersion) of a given dataset. In the case of the subjective evaluation, the opinion of an expert was considered to establish whether a time series is an outlier or not based on the reconstruction error. Therefore, those time series with greater reconstruction error are labeled as outliers, while those with less reconstruction are considered as normal. In this case, we opted to consider the 100 time series with the highest reconstruction error as outliers. This is a number that experimentally appears reasonable in this dataset since the expected anomalies appear; on the other hand, with this method we avoid looking for a threshold which is not trivial to find. The experts in the field will evaluate each time series, giving an assessment of whether the time series is an outlier, a dubious one or not an outlier. The assessment used is shown in
Table 4. The scale that appears in this table is based on the subjective criteria of the human expert. The
Outlier tag is given when one is absolutely sure that a path is outlier,
No outlier if the opposite is the case, and
Dubious in case one is not sure if the path is outlier.
4.1. Quantitative Results
An architecture of a neural network is the way the neurons inside it are organized. Three different architectures were trained for each dataset, maintaining the mentioned configurations but varying the number of layers and number of neurons for each architecture. All architectures were trained with the same number of epochs (300) to maintain the same learning conditions. To specify each architecture, we will use the following notation that denotes the layer types that were used:
In the experiments for the four databases, the three best results are shown for each database considering the error in the training set in both the full-connected and convolutional autoencoders. The former are denoted by AFC-A, AFC-B and AFC-C, while the latter by ACONV-A, ACONV-B and ACONV-C. The detail of the main architectures is shown in the text that accompanies each table of results.
In relation to the convergence of the optimization process, we show the evolution of the cost function in dataset 4.
Figure 5 shows that the cost function during training converges gradually until iteration 300. When reviewing the validation set, the same behaviour is observed (
Figure 6). This behavior is expected because the validation and training samples come from the same dataset, and the vast majority of GPS trajectories are not outliers. In the other databases the convergence patterns appear similar.
The pattern of convergence is repeated in the other datasets, and the same is true when measuring the adjusted metric. Next we will indicate the results obtained in all the datasets.
4.1.1. Dataset 1
Table 5 shows the results of the autoencoders in dataset 1. In relation to full-connected architecture, it is observed that architecture C obtains the best result, which has 6D while architecture A and architecture B have 4D. In relation to convolutional models, it is observed that architecture B obtained the best result, which has 2C, 2D and 2TC; architecture A has 3C, 2D and 3TC and architecture C has 2C, 2D and 2TC. Architectures B and C have a smaller filter than architecture C. In comparative terms, it is observed that the smallest reconstruction error is reached in the convolutional variant.
4.1.2. Dataset 2
Table 6 shows the results of the autoencoders in dataset 2. Regarding the full-connected architecture, note that architecture B obtained the best result, which has 8D; architecture A and C have 6D. In relation to convolutional models, it is observed that architecture A obtained the best result, which has 4C, 2D and 4TC; architecture B has 3C, 2D and 3TC and architecture C has 4C, 2D and 4TC. The filter of architecture A is smaller than that of the other architectures.
4.1.3. Dataset 3
Table 7 shows the results of the autoencoders in dataset 3. In relation to the full-connected architecture, observe that architecture B obtained the best result, which has 4D; architecture A has 6D and architecture C has 4D. In relation to convolutional models, it is observed that architecture B obtained the best result, which has 3C, 2D and 3TC; architecture A has 3C, 2D and 3TC and architecture C has 2C, 2D and 2TC. The filter of architecture B is smaller than that of architectures A and C.
4.1.4. Dataset 4
Table 8 shows the results of the autoencoders in dataset 4. In relation to full-connected architecture, it is observed that architecture C obtained the best result, which has 10D; architecture A has 8D and architecture B has 6D. In relation to convolutional models, it is observed that architecture A obtained the best result, which has 4C, 2D and 4TC; architecture B has 4C, 2D and 4TC and architecture C has 3C, 2D and 3TC. The filter of architecture A is smaller than that of architectures B and C.
4.2. Qualitative Network Results
The qualitative evaluation was only applied to the best architecture of the stacked autoencoder and stacked convolutional autoencoder of each dataset. The results show that the worst qualitative result was obtained from the convolutional stacked autoencoder applied to dataset 2. Analyzing the results of the autoencoder, it was observed that the vast majority of the paths are focused on a specific region of the map. It is very likely that the autoencoder found specific geo-location patterns in that region with respect to other regions. Since this is an unsupervised learning problem, it is not known what the result will be for the proposed models. In the four datasets, abrupt changes in speed between consecutive observations greater than 100 km/h were found, which were taken as anomalous observations. The proposed models also found the spatial outliers in the four datasets. Sudden speed changes and spatial outliers were counted as detected outliers. In
Table 9 the mean and standard deviation of the percentage of detected outliers when applying a sampling techniques based on bootstrapping [
35] is reported. In particular, we considered 1000 random samples with replacement from the list of the top 100 candidates according to each algorithm. The top candidates are obtained from the test set and are based on the given ranking by maximizing the reconstruction error. Each candidate is labeled by the expert according to
Table 4. The results indicate that the most effective method is the stacked convolutional autoencoder when applied to dataset 4, obtaining an average of 82.1% accuracy, while the second most effective method is the standard stacked autoencoder with 10 layers considering the same dataset with an average of 79.5 %. On the other hand, the worst results appear in Dataset 2 where the convolutional model reaches a performance of 4% on average.
4.2.1. Results of the Time Series Visualized on the Map
This section shows two visual examples of outlier time series detected by the model and two examples of time series that are not outliers but that the model detected as outliers with their respective maps and values. These visual examples are extracted from the 100 time series with the highest reconstruction error. In this case, the best neural network from each dataset that was previously evaluated is considered. Due to space optimization, we will only show examples about dataset 4. The examples show maps in Google Maps, where vehicle trajectories are marked by sequentially ordered light blue points, while the measurements that contribute the greatest error according to the neural network are marked by red dots. The anomalous GPS measurements within trajectories are obtained by considering those measurements that provide more than 90% reconstruction error in an anomalous trajectory according to the stacked autoencoder. The reason for flagging these measurements is to better understand the reason for anomalous labeling according to the neural network.
Examples of Correctly Detected Outlier Paths
Figure 7 shows a trajectory of 37 GPS measurements on a road, indicated by light blue points ordered from bottom to top, which generally presents normal continuity, except for measurements 22 and 23 that show a speed of 0, indicated by red dots which correspond to abrupt changes with respect to close measurements. In particular, the previous measurement, 21, had a speed of 95 km/h 40 s earlier, while the next measurement, 24, had a speed of 107 km/h 31 s later. On the other hand, observations 36 and 37, indicated by the red dots, show speeds of 151 km/h and 33 km/h in 30 s, which correspond to an unusual speed change according to the network. We indicate that this detection is correct, since the human expert agreed that there were anomalies in this trajectory according to the explanations given at the beginning of this paragraph. For greater clarity,
Table 10 shows the values of the GPS measurements with the greatest error of this anomalous trajectory of
Figure 7 together with the contiguous measurements.
The trajectory measurements shown in
Figure 8, taken on a rural highway, still appear to have a mostly typical behavior. However, in measurement 4 there is a speed increase of 74 km/h in 40 s compared to the previous measurement, reaching 161 km/h. In measurements 19 and 20, it is observed that the speed decreases from 150 to 5 km/h in 40 s. On the other hand, in measurement 22 a speed of 167 km/h is obtained when the speeds of the previous measurements were 5 and 143 km/h at 80 and 40 s before. The human expert found these speed changes at such times unusual, even when they correspond to rural roads, which is why it is an example of an outlier trajectory. For greater detail,
Table 11 shows the values of the GPS measurements with the greatest error of this anomalous trajectory of
Figure 8, again considering the measurements adjacent to those with the greatest error.
Example of Normal Paths Detected as Outliers
The trajectory measurements shown in
Figure 9 have a typical behavior according to experts. This trajectory corresponds to a vehicle on the road. When examining the measurements with the greatest reconstruction error, it appears that in measurements 6 and 7 there are no large changes in velocity or displacement. On the other hand, in measurements 9 and 10, a noticeable speed change appears. However, when analyzing the area, the expert indicated that it is a normal event in his opinion due to car braking and subsequent acceleration. In this case, we propose that the neural network detects abrupt changes in speed as outliers. For greater detail,
Table 12 shows the values of the GPS measurements with the greatest path error in
Figure 8, once again considering the measurements adjacent to those with the greatest error.
4.3. LOF Classical Model
To complement our study, we considered the Local Outlier Factor (LOF), a classic outlier model. For this method only dataset 4 was used, i.e., the one which contains the velocity outliers. The LOF method receives the time series as input and returns a vector with values 1 and
, where the value 1 indicates that the time series is an outlier and the value
indicates that the time series is normal. Each observation has six variables: date (
f), latitude (
), longitude (
), altitude (
), speed (
v), and number of satellites (
). For the detection of outlier observations, linear regressions were used, and each variable was taken, one at the time, as a dependent variable depending on the other ones, treated as explanatory variables. Furthermore, every dependent variable was taken as dependent also on its value at the previous time. We applied this method for each variable, and six linear regressions were obtained in the following way.
The calculated linear regressions were then applied to the observations of the time series, obtaining a prediction of the time series. To decide which observation was an outlier, the reconstruction error criterion was used. For the evaluation of the model, we only used the qualitative evaluation because this algorithm has a lazy learning, that is, it does not have a learning process.
The LOF was implemented in Python using the Scikit-Learn library [
36]. Within the LOF configuration the default parameters were used [
36], except for the number of neighbours, where 20 close neighbours were considered. In the qualitative evaluation of the LOF, 0% of outlier time series were detected: this result is due to the fact that the LOF does not detect outliers in sequential data but only in independent instances. Furthermore, it does not relate the variables as a neural network does, but it detects outliers based on the density of the data.
4.4. Explainable Model
Finally, it is known that deep neural models lack simple means of explanation. In order to understand the decisions of the neural network, a decision tree is used, which generates a decision rule that helps us understand the decisions of the neural network. As the decision tree has a supervised learning, we need the labeling of the training and validation data; for this we will use the given threshold based on a percentage of 99%. That is, the time series greater than the threshold are labeled as outliers, while the time series less than the threshold are labeled as normal.
The decision tree was implemented in Python 3.7 using the Scikit-Learn library. Within the decision tree configuration the default parameters were used, except the maximum depth which was taken equal to 20 levels. The decision tree obtained a precision of 92%.
The input of the decision tree is a time series, which is formed by 40 observations. To denote the observations and the variables of each observation, the following expression will be used: date x, lat_x, lon_x, alt_x, vel_x, nsat_x, where is the latitude variable, is the longitude variable, is the altitude variable, is the velocity variable, and is the number of satellites; and x denotes the observation number that ranges from 1 to 40. To explain the decision tree, one pure sheet with an outlier time series decision and another pure sheet with a normal time series decision were taken.
Outlier example:Table 13 shows the decision rules, where the speeds of observations 6 and 8 are on average less than or equal to 41.5 km/h, unlike the speeds of observations 13 and 15, which are on average greater than or equal to 79.5 km/h, which indicate a sudden change in speed. Also the speeds of observations 17, 19, 21, 26, 29 and 31 are on average less than or equal to 29 km/h and show a sudden change in speed with respect to the speeds of observations 13 and 15.
No outlier example:Table 14 shows the decision rules, where the speeds of observations 1 to 19 are on average less than or equal to 45 km/h, which corresponds to a normal average speed with which the vehicles travel.
5. Discussion
Initially the Waypoint company identified two types of outliers in data from multivariable GPS sensors, which we call spatial outlier and speed outlier, where the first it is associated with sudden changes in GPS position, while the second is associated with sudden changes in speed. Four datasets were created where the objective of dataset 1 and dataset 2 was to detect spatial outliers in short and long paths, respectively, using the two proposed models. However, when applying dataset 2 with long paths to the stacked convolutional autoencoder network, we obtained a performance of 5% and the vast majority of paths were focused on a specific area of the map. On the other hand, the objective of dataset 3 and dataset 4 was to detect all types of outliers, including speed outliers in short and long distances respectively using the proposed models. In both datasets it was possible to detect the spatial outlier, but also the models detected abrupt or sudden changes in speed in the paths and were labeled as outliers. When analyzing the results, we observe that the outliers in short routes are better detected considering spatial variables, while the outliers in long routes are better detected considering all the variables. However, when comparing both types of routes, in general the outliers appear better detected when considering the long routes with all the available variables applying a stacked convolutional autoencoder model with an approximate improvement of 30% compared to the best model that considers only spatial variables.
Analyzing these sudden changes in speed in more detail, it was determined that this anomalous behavior may have a similarity with the abnormal behaviors of drivers. For example, when drivers encounter dangerous locations on the road and use the brakes hard to slow down or when brake due to some unforeseen event on the road that forces them to brake abruptly, such maneuvers can be called anomalous behavior of drivers and appear in the time series detected as outliers.
One aspect to improve is the interpretability of the neural model. In this work we consider the use of the decision tree to better understand the results obtained, however this model considers a univariate scheme when making a decision in each of the tree, which may be suboptimal. An important proposal to explore is the use of interpretability agnostic models of neural networks such as LIME [
37] and SHAP [
38] algorithms.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}