
SLAM and 3D Semantic Reconstruction Based on the Fusion of Lidar and Monocular Vision

Abstract
:1. Introduction
- (1)
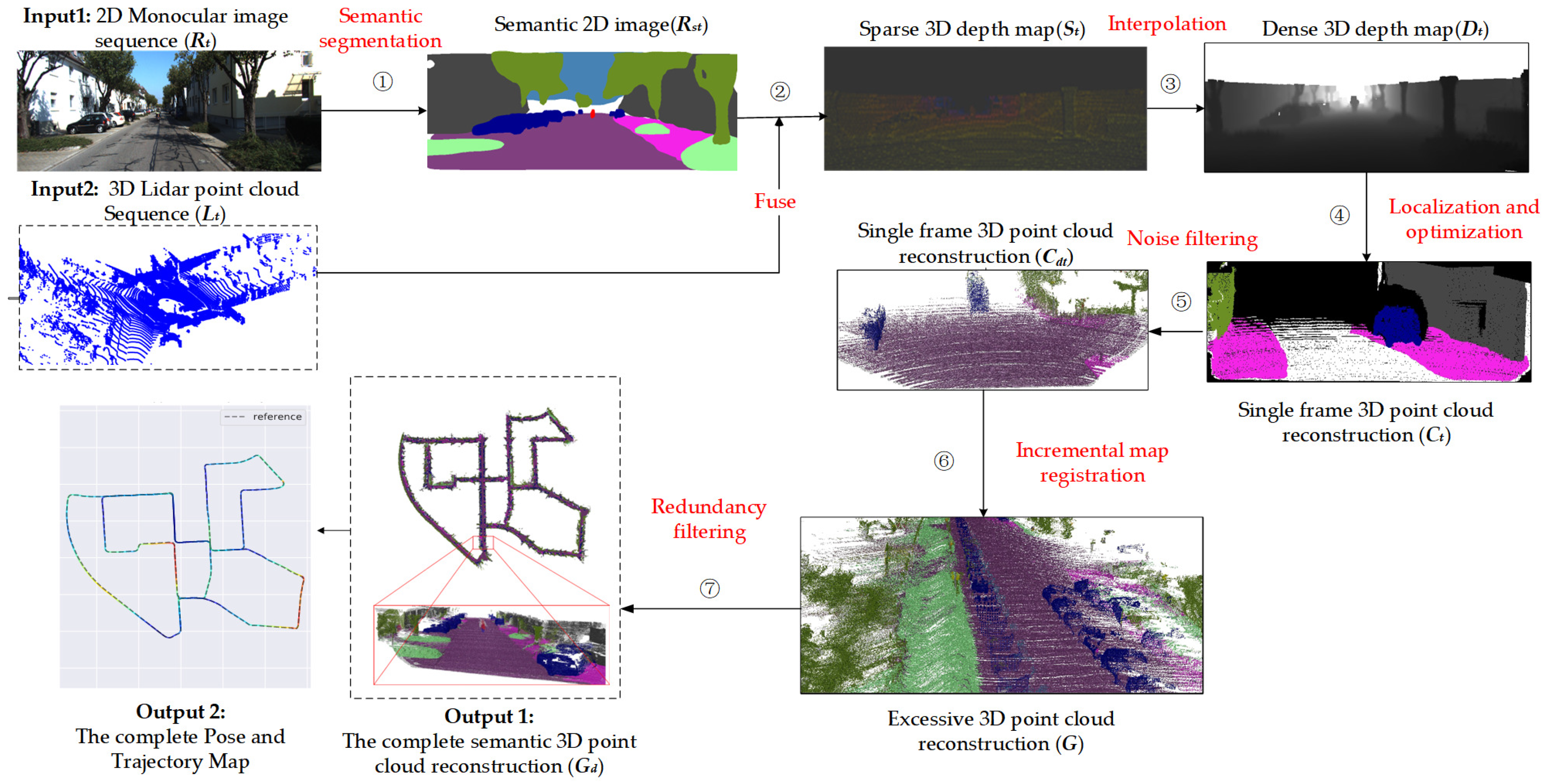
- We propose a projection and interpolation method to fuse low-density Lidar point clouds with semantically segmented images, and semanticize the point clouds corresponding to the semantic images.
- (2)
- We propose a SLAM method based on the fusion of Lidar and monocular vision, which uses the upsampled point cloud to provide depth information for image feature points and improve localization accuracy.
- (3)
- To solve the sparsity problem of mapping, we propose a 3D dense reconstruction method, which uses fused data to reconstruct dense semantic maps of the outdoor environment while localizing.
2. Related Work
2.1. Single-Sensor SLAM
2.2. Multi-Sensor Fusion SLAM
2.3. Semantic SLAM
3. Methods
3.1. Data Fusion and Depth Interpolation
3.2. Location and BA Optimization
3.3. 3D Semantic Reconstruction
| Algorithm 1: SLAM and 3D semantic reconstruction based on the fusion of Lidar and monocular vision. |
| 1 input: time stamps , 2D monocular image sequence , 3D Lidar scans |
| 2 output: unmanned vehicle pose and trajectory , complete 3D point cloud reconstruction |
| 3 begin |
| 4 for do |
| 5 Semantic segments with BiseNetV2, get semantic image |
| 6 Use Equation (1) to generate sparse-depth map with semantic information |
| 7 Use Equation (2)~(4) to upsampling to generate semantic dense 3D depth map |
| 8 Combine and to extract ORB feature point with depth |
| 9 if the depth of the feature point is valid do |
| 10 Use Equation (5)~(13) to localizaion and potimize |
| 11 Use Equation (14)~(15) to reconstruct semantic 3D point cloud of |
| 12 Use Equation (16) to filter noise in to get |
| 13 Incremental stitching , get complete semantic 3D point cloud reconstruction |
| 14 end if |
| 15 end for |
| 16 Use Equation (17) to filter the redundancy in , get |
| 17 End |
4. Experiment and Analysis
4.1. Semantic Segmentation
4.2. Data Fusion and Depth Interpolation
4.3. Positioning Accuracy Based on the Fusion of Lidar and Monocular Vision
4.4. 3D Reconstruction
4.4.1. Quantitative Evaluation of Reconstruction
4.4.2. Qualitative Evaluation of Reconstruction
5. Conclusions
- (1)
- Based on projection and interpolation methods, we implement upsampling of sparse Lidar point clouds and fusion with high-resolution 2D images. Semantic segmentation images are used to provide semantic information. The experimental results show that the fusion data has high resolution and visibility, and can be used as an input to realize the operation and experimental verification of subsequent algorithms.
- (2)
- Our method is compared with vision-based SLAM methods and Lidar vision-fusion SLAM methods, and the experiments were conducted on the KITTI Visual Odometry datasets. Results show that the positioning errors of our method in all 11 sequences are greatly reduced compared to ORB-SLAM2 and DynaSLAM. Compared with DEMO and DVL-SLAM, based on Lidar-vision fusion, the positioning accuracy of our method is also improved.
- (3)
- In terms of 3D reconstructions, our reconstructed objects’ widths differ by less than 0.5% compared to the data measured in Google Earth. Compared to DynSLAM for 3D reconstruction of outdoor environments, our reconstructions are of a higher quality and require 76% less storage space. The map representation can be continuously updated over time. At the same time, the generated semantic reconstruction has labels that can be understood by humans. It can better support the practical application of autonomous driving technology in the future.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, G.; Li, X.; Zhang, D.; Xu, W.; Lv, H.; Shi, Y.; Cai, M. Visual-SLAM Classical framework and key Techniques: A review. Sensors 2022, 22, 4582. [Google Scholar] [CrossRef] [PubMed]
- Huang, B.; Zhao, J.; Liu, J. A survey of simultaneous localization and mapping. arXiv 2019, arXiv:1909.05214. [Google Scholar]
- Debeunne, C.; Vivet, D. A review of visual-LiDAR fusion based simultaneous localization and mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiao, J. Machine learning assisted high-definition map creation. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 1, pp. 367–373. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Cui, L.; Ma, C. SDF-SLAM: Semantic depth filter SLAM for dynamic environments. IEEE Access 2020, 8, 95301–95311. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Ćwian, K.; Nowicki, M.R.; Wietrzykowski, J.; Skrzypczyński, P. Large-scale LiDAR SLAM with factor graph optimization on high-level geometric features. Sensors 2021, 21, 3445. [Google Scholar] [CrossRef] [PubMed]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Ku, J.; Harakeh, A.; Waslander, S.L. In defense of classical image processing: Fast depth completion on the cpu. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 16–22. [Google Scholar]
- Graeter, J.; Wilczynski, A.; Lauer, M. Limo: Lidar-monocular visual odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7872–7879. [Google Scholar]
- De Silva, V.; Roche, J.; Kondoz, A. Robust fusion of LiDAR and wide-angle camera data for autonomous mobile robots. Sensors 2018, 18, 2730. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Kaess, M.; Singh, S. A real-time method for depth enhanced visual odometry. Auton. Robot. 2017, 41, 31–43. [Google Scholar] [CrossRef]
- Shin, Y.S.; Park, Y.S.; Kim, A. DVL-SLAM: Sparse depth enhanced direct visual-LiDAR SLAM. Auton. Robot. 2020, 44, 115–130. [Google Scholar] [CrossRef]
- McCormac, J.; Clark, R.; Bloesch, M.; Davison, A.; Leutenegger, S. Fusion++: Volumetric object-level slam. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Prague, Czech Republic, 12–16 September 2018; pp. 32–41. [Google Scholar]
- Runz, M.; Buffier, M.; Agapito, L. Maskfusion: Real-time recognition, tracking and reconstruction of multiple moving objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 16–20 October 2018; pp. 10–20. [Google Scholar]
- Bârsan, I.A.; Liu, P.; Pollefeys, M.; Geiger, A. Robust dense mapping for large-scale dynamic environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7510–7517. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. Rangenet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), The Venetian Macao, Macau, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Chen, X.; Milioto, A.; Palazzolo, E.; Giguere, P.; Behley, J.; Stachniss, C. Suma++: Efficient lidar-based semantic slam. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), The Venetian Macao, Macau, 3–8 November 2019; pp. 4530–4537. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. Epnp: An accurate o (n) solution to the pnp problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle adjustment—A modern synthesis. In Proceedings of the International Workshop on Vision Algorithms, Corfu, Greece, 21–22 September 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 298–372. [Google Scholar]
- Huber, P.J. Robust statistics. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1248–1251. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Cignoni, P.; Callieri, M.; Corsini, M.; Dellepiane, M.; Ganovelli, F.; Ranzuglia, G. Meshlab: An open-source mesh processing tool. In Proceedings of the Eurographics Italian Chapter Conference, Salerno, Italy, 2–4 July 2008; Volume 2008, pp. 129–136. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote. Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Maturana, D.; Chou, P.W.; Uenoyama, M.; Scherer, S. Real-time semantic mapping for autonomous off-road navigation. In Field and Service Robotics; Springer International Publishing: Cham, Switzerland, 2018; pp. 335–350. [Google Scholar]
- Paz, D.; Zhang, H.; Li, Q.; Xiang, H.; Christensen, H.I. Probabilistic semantic mapping for urban autonomous driving applications. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 2059–2064. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Catagory | AP | AP50 | AP75 | Color |
|---|---|---|---|---|
| Sky | 31.6 | 66.3 | 25.4 |  |
| Road | 81.5 | 96.6 | 95.5 |  |
| Sidewalk | 21.6 | 42.4 | 19.2 |  |
| Plant | 18.4 | 38.6 | 15.4 |  |
| Pillar | 5.2 | 13.6 | 3.0 |  |
| House | 20.6 | 43.9 | 18.2 |  |
| Traffic signal | 15.9 | 29.4 | 15.6 |  |
| Fence | 4.0 | 10.3 | 2.2 |  |
| People | 22.9 | 43.9 | 20.9 |  |
| Car | 39.0 | 61.7 | 41.3 |  |
| Bike | 17.4 | 37.8 | 13.4 |  |
| Rider | 24.3 | 45.9 | 24.0 |  |
| Traffic light | 10.9 | 27.0 | 6.7 |  |
| Terrain | 8.6 | 21.5 | 4.8 |  |
| Truck | 24.7 | 39.3 | 26.9 |  |
| Motorcycle | 12.8 | 30.8 | 7.4 |  |
| Train | 16.3 | 36.4 | 6.9 |  |
| Bus | 34.1 | 52.7 | 38.4 |  |
| Sequence | Scene | Length (m) | ORB-SLAM2 (m) | DynaSLAM (m) | Ours (m) |
|---|---|---|---|---|---|
| 00 | Urban | 3714 | 5.33 | 7.55 | 1.10 |
| 01 | Highway | 4268 | Fail | Fail | 32.52 |
| 02 | Country + Urban | 5075 | 21.28 | 26.29 | 2.76 |
| 03 | Country | 563 | 1.51 | 1.81 | 0.40 |
| 04 | Country | 397 | 1.62 | 0.97 | 0.32 |
| 05 | Urban | 2223 | 4.85 | 4.60 | 0.65 |
| 06 | Urban | 1239 | 12.34 | 14.74 | 0.88 |
| 07 | Urban | 695 | 2.26 | 2.36 | 0.38 |
| 08 | Urban | 3225 | 46.68 | 40.28 | 5.39 |
| 09 | Country + Urban | 1717 | 6.62 | 3.32 | 1.11 |
| 10 | Country + Urban | 919 | 8.80 | 6.78 | 0.86 |
| Mean | 11.13 | 10.87 | 1.39 |
| Sequence | Scene | DEMO (%) | DVL-SLAM (%) | Ours (%) |
|---|---|---|---|---|
| 00 | Urban | 1.05 | 0.93 | 0.86 |
| 01 | Highway | 1.87 | 1.47 | 8.10 |
| 02 | Country + Urban | 0.93 | 1.11 | 1.07 |
| 03 | Country | 0.99 | 0.92 | 1.47 |
| 04 | Country | 1.23 | 0.67 | 0.68 |
| 05 | Urban | 1.04 | 0.82 | 0.62 |
| 06 | Urban | 0.96 | 0.92 | 0.72 |
| 07 | Urban | 1.16 | 1.26 | 0.52 |
| 08 | Urban | 1.24 | 1.32 | 1.30 |
| 09 | Country + Urban | 1.17 | 0.66 | 0.88 |
| 10 | Country + Urban | 1.14 | 0.70 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lou, L.; Li, Y.; Zhang, Q.; Wei, H. SLAM and 3D Semantic Reconstruction Based on the Fusion of Lidar and Monocular Vision. Sensors 2023, 23, 1502. https://doi.org/10.3390/s23031502
Lou L, Li Y, Zhang Q, Wei H. SLAM and 3D Semantic Reconstruction Based on the Fusion of Lidar and Monocular Vision. Sensors. 2023; 23(3):1502. https://doi.org/10.3390/s23031502
Chicago/Turabian StyleLou, Lu, Yitian Li, Qi Zhang, and Hanbing Wei. 2023. "SLAM and 3D Semantic Reconstruction Based on the Fusion of Lidar and Monocular Vision" Sensors 23, no. 3: 1502. https://doi.org/10.3390/s23031502