1. Introduction
Face masks are a well-established preventive tool to limit the spread of viruses through droplets and aerosols in the population [
1]. With the COVID-19 global pandemic, many countries and regions stipulate that people must wear masks in public places, especially indoor areas and vehicles. In most cases, some staff are assigned to enforce the rule. Nevertheless, the manual monitoring method not only wastes manpower but also can easily cause infection. Contactless mask recognition can avoid the waste of human resources and the risk of exposure, which has been highly valued by many researchers [
2,
3,
4].
It is important to quickly and accurately identify masks in daily life, especially in areas with a large flow of people. Some researchers have developed integrated systems for rapid screening. Hussain et al. [
5] designed an intelligent disinfection screening door that can simultaneously measure the pedestrian’s temperature, identify if a mask is worn, and perform the disinfection. The 2D data captured by the camera was first input to the mask recognition module. Then, the neural network was used for classification. In addition to the comprehensive screening system, which can monitor the temperature and detect the mask, there is also a lot of work focused on improving the accuracy of mask recognition. Most mask recognition methods are based on object recognition technology, which automatically identifies whether a person is wearing a mask by combining the camera’s input with a computer algorithm. Conventional solutions of object recognition are mainly based on two-dimensional (2D) images, including detecting regions of interest, extracting features, and performing classification [
6]. At present, numerous emerging machine learning methods are being used more and more in object recognition. In [
7,
8,
9,
10,
11,
12], ResNet, Yolo, MobileNet, and other machine learning models are used to recognize face masks. The identification accuracy can exceed 90%. However, the performance of these methods begins to decline significantly in some situations, such as occlusion or variable illumination conditions [
13]. In addition, Cao et al. [
14] considered night situations and proposed the MaskHunter model, but the accuracy dropped to 71.6%. Even when the additional training module was designed to improve accuracy, the results were not satisfactory. Hence, breaking the trade-offs between accuracy and the adaptability of mask identification is a difficult problem to solve.
In recent years, with the enrichment of information acquisition methods and the development of sensing technology, many three-dimensional (3D) sensors have emerged [
15,
16], which can not only obtain the shape information of the object but also determine the distance between the object and the camera. Among them, the depth camera, based on the principle of active ranging, has many advantages, such as being insensitive to illumination and unaffected by the contrast of the target. As the popular depth sensors that are commercially available [
17,
18,
19], the structured light cameras and the time-of-flight (ToF) cameras have different advantages and application scenarios [
20]. In most cases, the ToF camera has low complexity and advantages in practical application [
21]. Therefore, the ToF camera is more commonly used as a data acquisition device. Since the depth cameras work well in low light and even in dark conditions, object recognition based on obtained 3D images has been used in many scenes, such as human detection, industrial assembly, gesture recognition, and others [
22,
23,
24,
25,
26,
27,
28]. Luna et al. [
29] presented a new method for detecting people only using depth images, and the data was captured by a depth camera in a frontal position. This method ran in real-time using a low-cost CPU platform with high accuracy. Various tasks based on the depth information require different features to be extracted. The introduction of 3D information also increases the computational cost of machine learning models. Moreover, the universal parameters of feature extraction based on 3D information need to be further investigated.
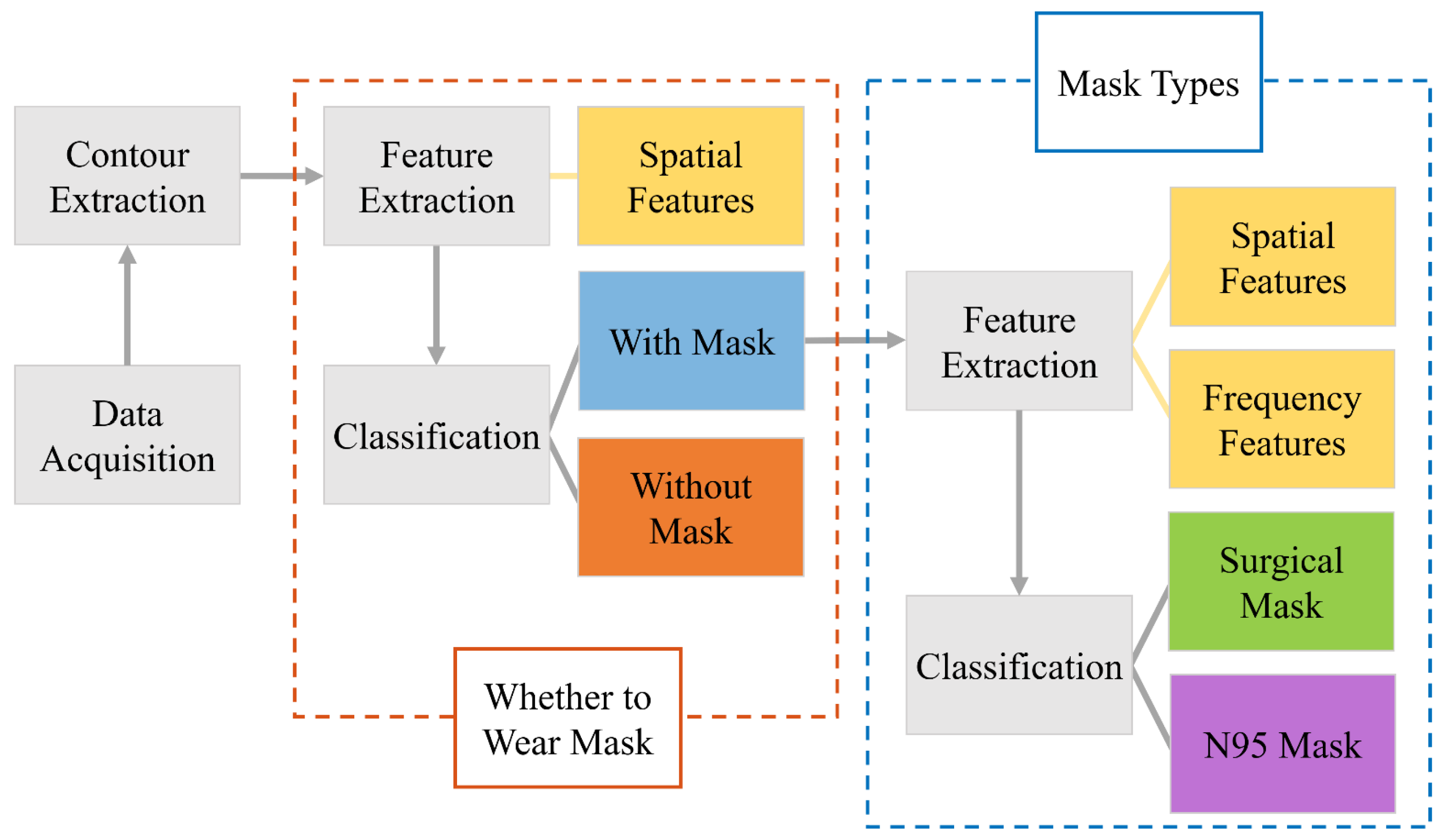
In this paper, we propose and demonstrate a method based on a ToF depth camera to determine whether a person is wearing a mask. The results are divided into three classifications: wearing no mask, wearing a surgical mask, and wearing an N95 mask. The three situations can be easily discriminated by the optimized spatial and frequency features on the facial depth contour. The experimental results show that these characteristics not only can distinguish whether people wear masks but also can determine the types of masks. Unlike the 2D image from the RGB camera, which is easily affected by the environmental illumination, our developed mask identification system based on the ToF camera runs robustly under variable external conditions, especially in the dark environment. Compared with the other 3D imaging sensors, the ToF camera also has the advantage of fast imaging. Through the sampling and dimension reduction of the depth image to obtain the facial contour curve, our method could potentially achieve quick and accurate identification, which is suitable for scenes with illumination variation and rapid identification, such as entrances and exits of the building. In addition, our method can also provide statistical data for epidemiological analysis by monitoring the mask types.
3. Results
To evaluate the proposed recognition algorithm, a ToF depth camera was used to capture the depth data. The PicoFlexx camera from pmdtechnologies was used for data collection. The PicoFlexx camera is equipped with an IRS1145C Infineon
® REAL3™ 3D image sensor based on the principle of ToF. The camera uses an 850-nm Vertical-Cavity Surface-Emitting Laser (VCSEL) as the light source, and the detection range is from 0.1 m to 4 m. We used this camera to collect the front-face image under the indoor environment. For the acquired images, the corresponding resolution is 945 × 722 pixels, which is expanded from the 244 × 172 resolution of the IRS1145C sensor by the Software Development Kit (SDK) Royale 3.20.0.62 as a color-coded depth map. These depth images can be divided into three categories: not wearing a mask, wearing a surgical mask, and wearing an N95 mask. The bottom half of the face is obtained by distance filtering and clipping. The 3D view of three situations is shown in
Figure 8. The pixel value of the data is normalized to the range from 0 to 1 by the SDK of the ToF camera, where 0 represents the closest distance to the camera and 1 represents the farthest distance detected by the camera. In
Figure 8, we flip the meaning of the values for better visualization.
From the 3D view of the bottom face, the face without a mask has more obvious undulations with multiple peaks, and the nose part is conspicuous. The 3D contour of the surgical mask is much smoother in general, but there are more small fluctuations. The shape of the 3D contour for the N95 mask has only one obvious peak.
With the depth image of the bottom face, the facial contour curve is extracted and normalized. In our research, the length of all the contour curves is unified at 300, and the relative distance of the global minimum point is set to zero.
Figure 9 shows the 3 types of facial contour curves, and 10 contour curves of each type are selected for overlapping display. When all the contours are normalized, contour curves of the same type show good repeatability and similar geometric features, but different kinds of contour curves have different geometric features. In particular, the mask covers the shape of the human face, so the contour curve with a mask is gentler, while the contour curve without a mask fluctuates more obviously. We can clearly see the characteristics of the bottom face in
Figure 9, including the nose, the top lip, and the bottom lip, while they cannot be distinguished from the contour curve with a mask. The contour curves of different mask types are also different. In general, the contour curve of a surgical mask is relatively gentle. However, there are many wrinkle-caused fluctuations in the curve. The N95 mask is made of thicker material, and its depth contour curve is closer to a trapezoidal shape. Depending on the different shapes of the contour curves, the features can be extracted for classification and recognition.
After obtaining the contour curve, the features
N,
SSD, and a
1 are calculated to determine whether to wear a mask. A total of 15 images of each type are selected to calculate the three features, which are shown in
Figure 10. The black curve represents the feature values of the contour curve without a mask, while the red and blue curves represent the feature values of the contour curve with a surgical mask and an N95 mask, respectively. The minimum number of points is displayed in
Figure 10a. One can see that due to the shape of the nose and lips, the number of the minimum points of the contour curve without a mask is always more than three. With the regular shape, the
N value of the contour curve with an N95 mask is typically one. However, due to the influence of the folds, the
N value of the contour curve with a surgical mask shows great fluctuation, ranging from 1 to 3. Although most
N values of the contour curve without mask are greater than those of the contour curves with a mask, there are still overlapping parts. Therefore, a single feature cannot classify the mask wearing condition accurately. The value of
N is also not suitable for distinguishing the mask types.
Figure 10b shows the standard deviation between the two farthest minimum points. The
SSD values of the contour curve without a mask are far greater than those of the contour curve with a mask because of the shape of the human face. The folds of the surgical mask lead to the oscillation of the contour curve with the mask, causing a smaller but unpredictable fluctuation in
SSD value. The contour curve with the N95 mask usually has only 1 minimum point, and its
SSD is set to 0. However, because the
SSD curves of two types of masks also overlap, the
SSD value cannot distinguish the mask types well.
Figure 10c demonstrates the quadratic coefficient
a1 of the partial fitting curve. As one can see, the a
1 value of the contour curve without a mask are far greater than those of the contour curve with a mask. For the quadratic function, the value of |
a1| is larger and the opening of the parabola is smaller. The global minimum point is the vertex of the quadratic function. For the contour curve without a mask, the fitting curve represents the nose. For the contour curve with a mask, the fitting curve describes a part of the mask. Therefore, the
a1 value of the contour curve without a mask is greater than that with a mask, which is consistent with the theory. The
a1 values of different mask types also have differentiation, which will be further explained.
In summary, the above three features can distinguish whether or not to wear a mask by setting the thresholds appropriately. The effect of a single feature is limited, while the combination of the three features can achieve better results. The decision conditions are N > N’, SSD > SSD’, a1 > a1’, where N’, SSD’, and a1’ are the thresholds. In our work, N’ is 2, SSD’ is 0.05, and a1’ is 5. To improve the robustness, the voting method is used for the classification. When more than two evaluation conditions are satisfied, it is considered as without a mask. Otherwise, it is determined to be wearing a mask.
In the identification process of two mask types, the surgical mask and the N95 mask, three features are extracted from the spatial and frequency curves.
Figure 8 shows the features to distinguish the mask types from 15 images. The red and blue curves represent the feature values of the contour curve with the surgical mask and the N95 mask, respectively. The opening angle values of these images are illustrated in
Figure 11a. It clearly shows that the opening angle of the contour curve with the N95 mask is greater than that with the surgical mask. However, the opening angle values of two types still have overlapping parts and other features are required to be leveraged together.
The quadratic coefficient
a1 of the partial fitting curve is shown in
Figure 11b. Although the opening angle of the contour curve with an N95 mask is larger than that with a surgical mask, the quadratic coefficient of the partial fitting curve of an N95 mask is smaller, because the chosen part of the N95 mask is sharper together with a more stable shape.
The frequency curve is obtained by the Fourier transform after the quadratic fitting of the contour curve. The area of the frequency curve of the N95 mask is larger than that of the surgical mask in
Figure 11c.
The above three features can distinguish whether or not to wear a mask by setting the thresholds appropriately. Due to different wearing habits and soft mask materials, the feature values have fluctuations, and the effect of a single feature is limited. The combination of these three features can achieve better results, and the voting method is also used to classify the mask types. The decision conditions are α < α’, a1 < a1’, FS < FS’, where α’, a1’, and FS’ are thresholds. In our work, α’ is 70, a1’ is 2.5, and FS’ is 85. When two or more threshold conditions are satisfied, it is determined that the person is wearing a surgical mask. Otherwise, it is judged as an N95 mask.
The algorithm is evaluated from many aspects based on our data. The results can be classified into three categories:
TP (true positive) means that the results are the same as the real conditions;
FP (false positive) means samples in the detected category are inconsistent with the real category; and
FN (false negative) means that the object is detected as the opposite category. Precision is used to measure the proportion of the real cases (
TP) among all the positive cases (
TP +
FP) detected by the algorithm, as shown in Equation (6).
Recall is the proportion of detected real cases in all positive cases, which represents the ability of the algorithm to detect the real cases, calculated as follows:
Due to the trade-off between the precision and recall, the
F1 score combines them into a single indicator, defined by the harmonic average, as shown in Equation (8).
where
P and
R represent precision and recall, respectively. If the
F1 score is higher, the test of the algorithm will be more effective.
A total of 369 depth images were captured, including evenly distributed categories: without masks, with surgical masks, and with N95 masks, to test the algorithm. These images were taken by 3 women aged from 23 to 25 over a 1-week timeframe. In order to enrich the sample diversity, the images were taken for people with and without glasses. In addition, it also includes different hairstyles, such as long, straight hair and a ponytail. In the proposed algorithm, there are two classifications: one is whether or not to wear mask and the other is the mask types. The precision, recall, and
F1 score are calculated for the two cases, respectively. For the classification of whether or not to wear mask, the results are listed in
Table 1.
Although the recall of those without a mask is larger than the recall of those with a mask, the precision and
F1 score of with a mask are larger than that of without a mask. As displayed in
Table 1, most images without a mask can be detected correctly. Because of the soft material, surgical masks are more likely to produce wrinkles or reflect the undulation of the face. Therefore, most of the images incorrectly identified as without a mask are actually images with surgical masks.
To evaluate the confusion between the surgical mask and the N95 mask, the classification results on the mask types are shown in
Table 2. Since the step is performed after detecting whether or not to wear a mask, the classification of mask types relies on the image detected as with a mask. These two kinds of masks have similar contour curves and feature values, which leads to the drop in accuracy. In addition, the precision and recall of the two types are in a restrictive relation, respectively, and have close
F1 scores.
The system runs on a regular laptop (Intel Core AMD Ryzen 7 6800H CPU running at 3.2 GHz, and 16 GB of RAM) and MATLAB is used for image processing. The average processing time of the algorithm is 32 ms, which corresponds to 31.55 FPS.
Table 3 presents a comparison of this proposal with the other works. The accuracy of our work is expressed by the average precision. At present, there is less related work to recognize the face mask based on the depth image; most works are based on the RGB images. However, compared with the method based on the RGB image, the depth image captured from the low-cost ToF camera can be less affected by the environment light. Therefore, our accuracy has certain advantages compared with those works. The work [
14] considered the RGB data under dark condition; they introduced additional resources to train the network, and the improved accuracy rate in the dark condition was 77.9%. Compared with this work, our proposed method is unaffected by light and the average accuracy can reach 96.9%. In addition, we have also classified the mask types, which are not involved in some works. It can be seen from Jiang et al. [
12] that the introduction of more classification situations will affect the accuracy of the method. In the case of sufficient lighting and good image quality, our ToF-camera-based method has close accuracy with the other works of mask recognition based on the RGB images. Most RGB-camera-based works with high identification accuracy are based on mature deep-learning methods. However, compared with most network-based works, our method is more interpretable and with lower computational costs.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}