


Text Summarization Method Based on Gated Attention Graph Neural Network


Abstract
:1. Introduction
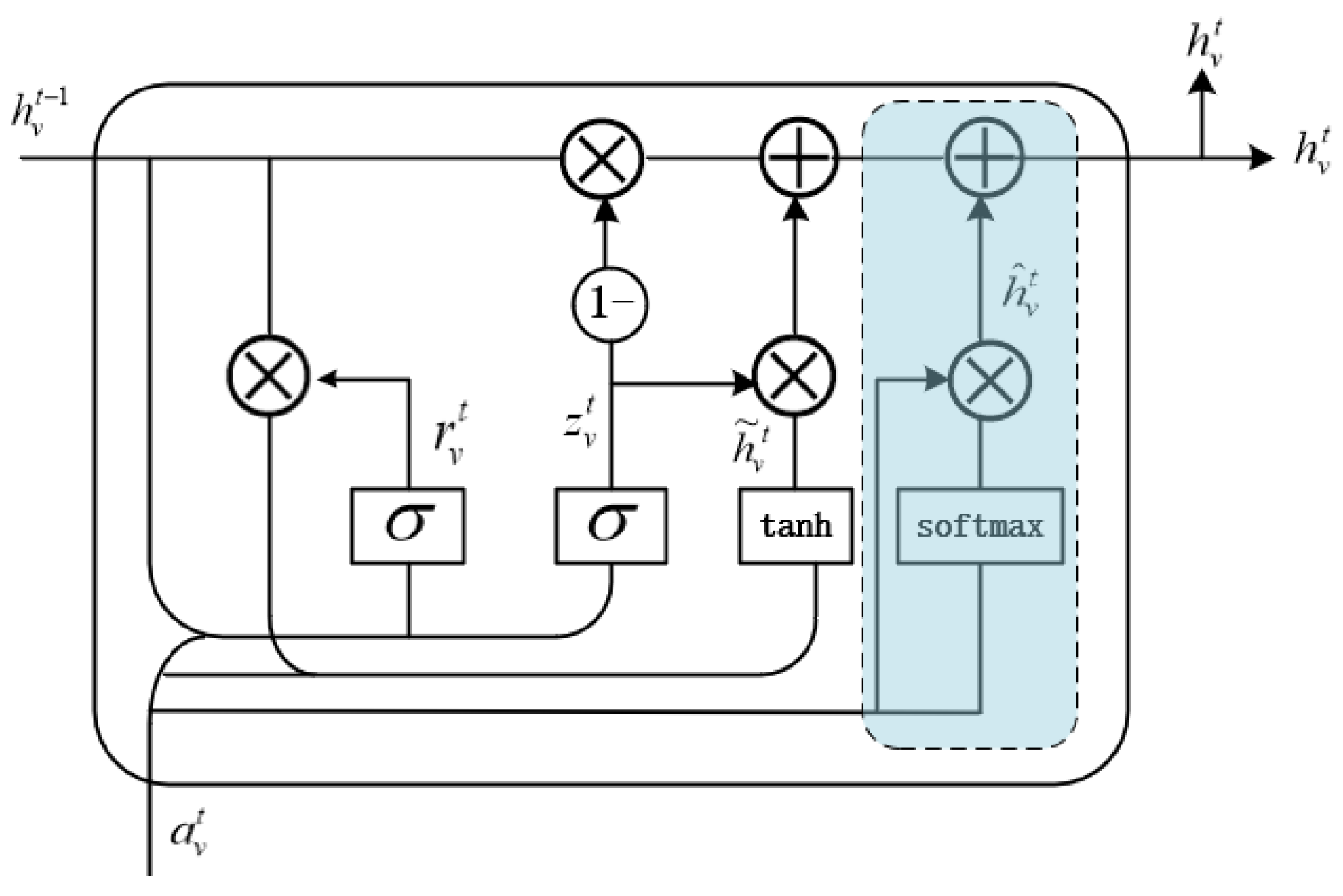
- To adequately exclude irrelevant information, an attention gate is added to the gate control unit GRU.In the iterative process of the existing Gated Graph Neural Network (GGNN), irrelevant information will also be accumulated and amplified, resulting in redundant information in the decoding phase which cannot be eliminated, making the text abstract distorted. Therefore, an Attention Gate (GA) is added to the gating unit GRU to form a Gate Attention Graph Neural Network (GA-GNN) model.
- Use of parallelism in the coding phase to mitigate inadequate coding and high time complexity.If a single coder is used in the sentence encoding stage, the local information and the global information cannot be concerned at the same time, which easily leads to insufficient semantic information encoding. Tandem encoding can solve the problem of global local semantic encoding, but the time complexity is high. In this paper, parallel sentence coding mode is used to encode both local and global information of the text, which enriches vector information and shortens training time.
- A joint loss function optimization model is proposed.Decoding based on graph-extracted features not only ignores the connections between sentence levels, but also diminishes the accuracy of generated summaries due to the lack of multiple sample guidance. In this paper, the loss function is optimized by weights based on contrast learning, graphic feature extraction and confidence calculation of important sentences, and all the key information is effectively incorporated into the decoder.
2. Related Technologies
2.1. Codec Framework
2.2. Graph Neural Network (GNN)
2.3. Contrastive Learning
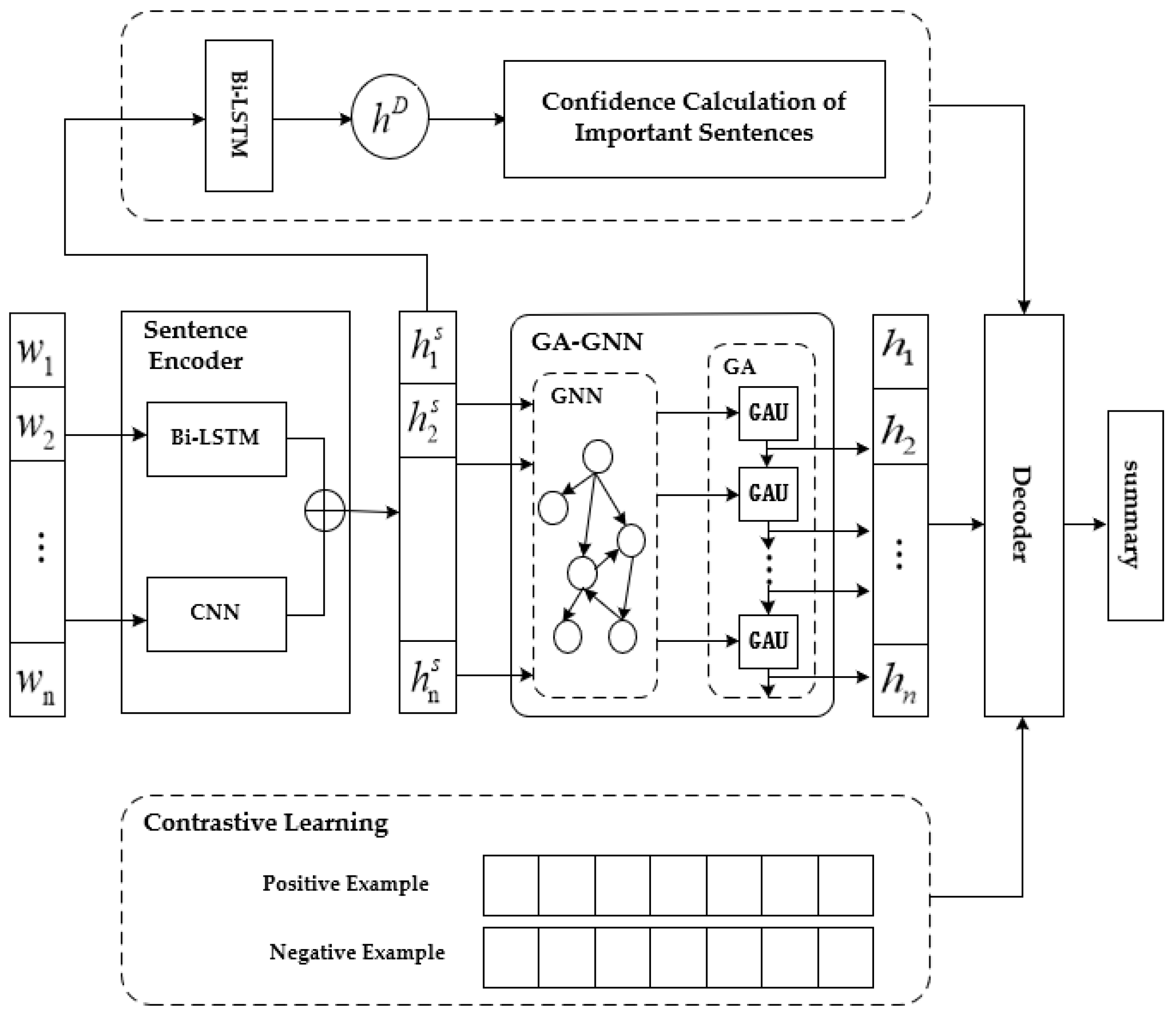
3. Model
3.1. The Hierarchical Encoder
3.2. Gated Attention Feature Extraction
3.3. Contrastive Loss Function
3.4. Confidence Calculation of Important Sentences
3.5. Decoders and Loss Functions
4. Experimental Results and Analysis
4.1. Dataset
4.2. Parameter Setting and Evaluation Index
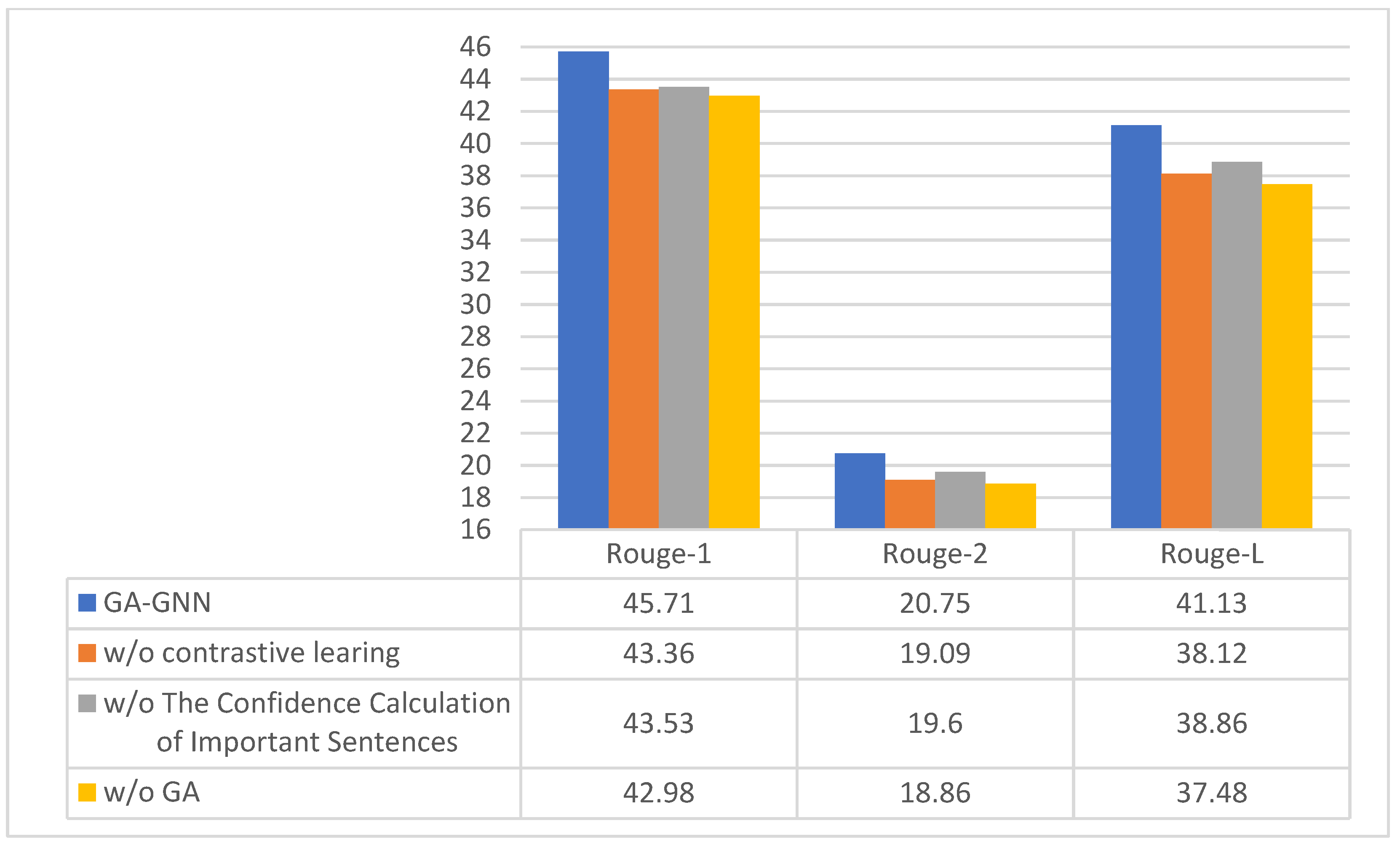
4.3. Ablation Experiments
4.4. Baseline Model Comparison Experiment
- Seq2Seq + Joint Attention (2018): Hou Liwei et al. [32] proposed to incorporate a joint attention mechanism into the decoder to reduce redundant repetitive information in the decoding process by the decoder.
- DAPT (2022): Li et al. [33] proposed a dual-attention pointer fusion network fusing contextual and critical information.
- AGGNN (2022): Deng et al. [24] proposed an attention-based gated graph neural network that effectively exploits the semantic features of words.
- GRETEL (2022): Qianqian Xie et al. [29] introduced a graphical contrast topic augmented language model in the model, and combined the graphical contrast topic model with the training model to fully capture the global semantic information.
- CNN/Daily Mail Dataset
- MR Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mingtuo, S.; Chen, H. Progress and trends in text summarization research. Chin. J. Netw. Inf. Secur. 2018, 4, 1–10. [Google Scholar]
- Zhu, Y.; Zhao, P.; Zhao, F.; Mu, X.; Bai, K.; You, X. Survey on Abstractive Text Summarization Technologies Based on Deep Learning. Comput. Eng. 2021, 47, 11–21+28. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, T.; Zhou, W. Text classification method based on abstracted text summarization. J. Chang. Univ. Technol. 2021, 42, 558–564. [Google Scholar] [CrossRef]
- Wei, L.; Xiao, Y.; Xiao, X. An Improved TextRank for Tibetan Summarization. J. Chin. Inf. Process. 2020, 34, 36–43. [Google Scholar]
- Li, X.; Zhou, A. Abstractive Summarization Model Based on Mixed Attention Mechanism. Mod. Comput. 2022, 28, 50–54+59. [Google Scholar]
- Fu, S. Research on Automatic Text Summarization Based on Deep Neural Network; University of Science and Technology of China: Hefei, China, 2021. [Google Scholar] [CrossRef]
- Shi, T.; Keneshloo, Y.; Ramakrishnan, N.; Reddy, C.K. Neural Abstractive Text Summarization with Sequence-to-Sequence Models. ACM Trans. Data Sci. 2021, 1, 1–37. [Google Scholar] [CrossRef]
- Wang, B. Research and Implementation of Automatic Text Summarization Technology Based on Seq2Seq Model; Huazhong University of Science and Technology: Wuhan, China, 2019. [Google Scholar] [CrossRef]
- Qi, T.; Jiang, H. Exploring stock price trend using Seq2Seq based automatic text summarization and sentiment mining. Manag. Rev. 2021, 33, 257–269. [Google Scholar] [CrossRef]
- Hofstätter, S.; Zamani, H.; Mitra, B.; Craswell, N.; Hanbury, A. Local Self-Attention over Long Text for Efficient Document Retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020. [Google Scholar] [CrossRef]
- Liao, Y. Research and Implementation of Text Summarization Based on Attention Mechanism; Huazhong University of Science and Technology: Wuhan, China, 2019. [Google Scholar] [CrossRef]
- Zhang, S. Research on Text Summary Generation Technology Based on Deep Learning; Xinjiang University: Ürümqi, China, 2019. [Google Scholar]
- Dong, P. Improved Seq2Seq Text Summarization Generation Method; Guangdong University of Technology: Guangzhou, China, 2021. [Google Scholar] [CrossRef]
- Lan, Y.; Hao, Y.; Xia, K.; Qian, B.; Li, C. Stacked Residual Recurrent Neural Networks with Cross-Layer Attention for Text Classification. IEEE Access 2020, 8, 70401. [Google Scholar] [CrossRef]
- Jia, R.; Cao, Y.; Tang, H.; Fang, F.; Cao, C.; Wang, S. Neural Extractive Summarization with Hierarchical Attentive Heterogeneous Graph Network. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 19–20 November 2020; pp. 3622–3631. [Google Scholar]
- Vaibhav, V.; Mandyam, R.; Hovy, E. Do Sentence Interactions Matter? Leveraging Sentence Level Representations for Fake News Classification; Association for Computational Linguistics: Hong Kong, China, 2019. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ma, S.; Sun, X.; Xu, J.; Wang, H.; Li, W.; Su, Q. Improving Semantic Relevance for Sequence-to-Sequence Learning of Chinese Social Media Text Summarization. arXiv 2017, arXiv:1706.02459. [Google Scholar]
- Lin, J.; Sun, X.; Ma, S.; Su, Q. Global Encoding for Abstractive Summarization; Association for Computational Linguistics: Melbourne, Australia, 2018. [Google Scholar] [CrossRef]
- Shi, J.; Li, Z.; Lai, W.; Li, F.; Shi, R.; Feng, Y.; Zhang, S. Two End-to-End Quantum-inspired Deep Neural Networks for Text Classification. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Lu, M.; Tan, D.; Xiong, N.; Chen, Z.; Li, H. Program Classification Based on Gated Graph Attention Neural Network. Comput. Eng. Appl. 2020, 56, 176–183. [Google Scholar]
- Yang, Y.; Wang, L.; Wang, H. Rumor Detection Based on Source Information and Gating Graph Neural Network. J. Comput. Res. Dev. 2021, 58, 1412–1424. [Google Scholar]
- Deng, C.; Zhong, G.; Dong, W. Text Classification Based on Attention Gated Graph Neural Network. Comput. Sci. 2022, 49, 326–334. [Google Scholar]
- Cheng, Z.; Liang, M.; Yiyan, Z.; Suhang, Z. Text Classification Method Based on Bidirectional Attention Mechanism and Gated Graph Convolution Network [J/OL]. Computer Science: 1–12 [2022-11-21]. Available online: http://kns.cnki.net/kcms/detail/50.1075.tp.20220927.1002.002.html (accessed on 13 December 2022).
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- Cao, S.; Wang, L. CLIFF: Contrastive Learning for Improving Faithfulness and Factuality in Abstractive Summarization. arXiv 2021, arXiv:2109.09209. [Google Scholar]
- Yan, Y.; Li, R.; Wang, S.; Zhang, F.; Wu, W.; Xu, W. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer. arXiv 2021, arXiv:2105.11741. [Google Scholar]
- Xie, Q.; Huang, J.; Saha, T.; Ananiadou, S. GRETEL: Graph Contrastive Topic Enhanced Language Model for Long Document Extractive Summarization. arXiv 2022, arXiv:2208.09982. [Google Scholar]
- Hu, J.; Li, Z.; Chen, Z.; Li, Z.; Wan, X.; Chang, T.H. Graph Enhanced Contrastive Learning for Radiology Findings Summarization. arXiv 2022, arXiv:2204.00203. [Google Scholar]
- Li, C. Text Summarization Based on Neural Network Joint Learning; Beijing University of Posts and Telecommunications: Beijing, China, 2019. [Google Scholar]
- Hou, L.; Hu, P.; Chao, B. Abstractive Document Summarization via Neural Model with Joint Attention; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Li, Z.; Peng, Z.; Tang, S.; Zhang, C.; Ma, H. Fusing context information and key information for text summarization. J. Chin. Inf. Process. 2022, 36, 83–91. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Number | Confidence Calculation of Important Sentences | Contrastive Learning | GA | GNN | Sentence Encoder | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|---|---|---|---|---|
| 1 | × | √ | √ | √ | parallel connection | 43.53 | 19.60 | 38.86 |
| 2 | √ | × | √ | √ | parallel connection | 43.36 | 19.09 | 38.12 |
| 3 | √ | √ | × | √ | parallel connection | 42.98 | 18.86 | 37.48 |
| 4 | √ | √ | × | × | parallel connection | 42.77 | 18.28 | 37.36 |
| 5 | √ | √ | √ | √ | Single network | 44.13 | 19.68 | 39.48 |
| 6 | √ | √ | √ | √ | series connection | 44.81 | 20.48 | 39.23 |
| 7 | √ | √ | √ | √ | parallel connection | 45.14 | 20.75 | 41.13 |
| Model | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|
| Seq2Seq + Joint Attention | 27.80 | 14.25 | 25.71 |
| DAPT | 40.72 | 18.28 | 37.35 |
| AGGNN | 42.25 | 19.13 | 38.65 |
| GRETEL | 43.66 | 19.46 | 40.69 |
| Our Method | 45.14 | 20.75 | 41.13 |
| Model | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|
| Seq2Seq + Joint Attention | 38.55 | 17.36 | 36.38 |
| DAPT | 39.27 | 17.56 | 36.13 |
| AGGNN | 40.68 | 18.10 | 37.54 |
| GRETEL | 43.02 | 20.19 | 38.53 |
| Our Method | 44.71 | 20.85 | 39.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Wu, W.; Li, J.; Wang, S. Text Summarization Method Based on Gated Attention Graph Neural Network. Sensors 2023, 23, 1654. https://doi.org/10.3390/s23031654
Huang J, Wu W, Li J, Wang S. Text Summarization Method Based on Gated Attention Graph Neural Network. Sensors. 2023; 23(3):1654. https://doi.org/10.3390/s23031654
Chicago/Turabian StyleHuang, Jingui, Wenya Wu, Jingyi Li, and Shengchun Wang. 2023. "Text Summarization Method Based on Gated Attention Graph Neural Network" Sensors 23, no. 3: 1654. https://doi.org/10.3390/s23031654
APA StyleHuang, J., Wu, W., Li, J., & Wang, S. (2023). Text Summarization Method Based on Gated Attention Graph Neural Network. Sensors, 23(3), 1654. https://doi.org/10.3390/s23031654