
DualDiscWaveGAN-Based Data Augmentation Scheme for Animal Sound Classification


Abstract
:1. Introduction
- In a multi-class environment, the GAN should be constructed for each animal sound class to be generated. This requires a huge amount of time and storage space as the number of target classes increase. Further, for classes with insufficient training data, such as rare animal sounds, the quality of the generated data can be very poor.
- Animal sounds have complex patterns made up of multiple acoustic components such as frequency, duration and tempo. In order to generate realistic animal sound data, a GAN should consider not only the waveforms that represent the signal intensity over time, but also the spectrograms that contain the frequency-time features of the sound to capture periodic patterns. However, existing GAN-based augmentation methods only consider either waveforms or spectrograms to generate sound data [9,10].
- Although GANs show good generative performance, their results are closely influenced by the quantity and quality of the real animal sound data used for training. In particular, as animal sounds are usually collected in an outdoor environment, the collected sounds may contain significant background noise, such as wind and rain, despite noise reduction operations. Because of these noises, GANs cannot effectively learn the characteristics of real animal sounds, resulting in virtual sounds that lack semantic information representing distinct animal sounds.
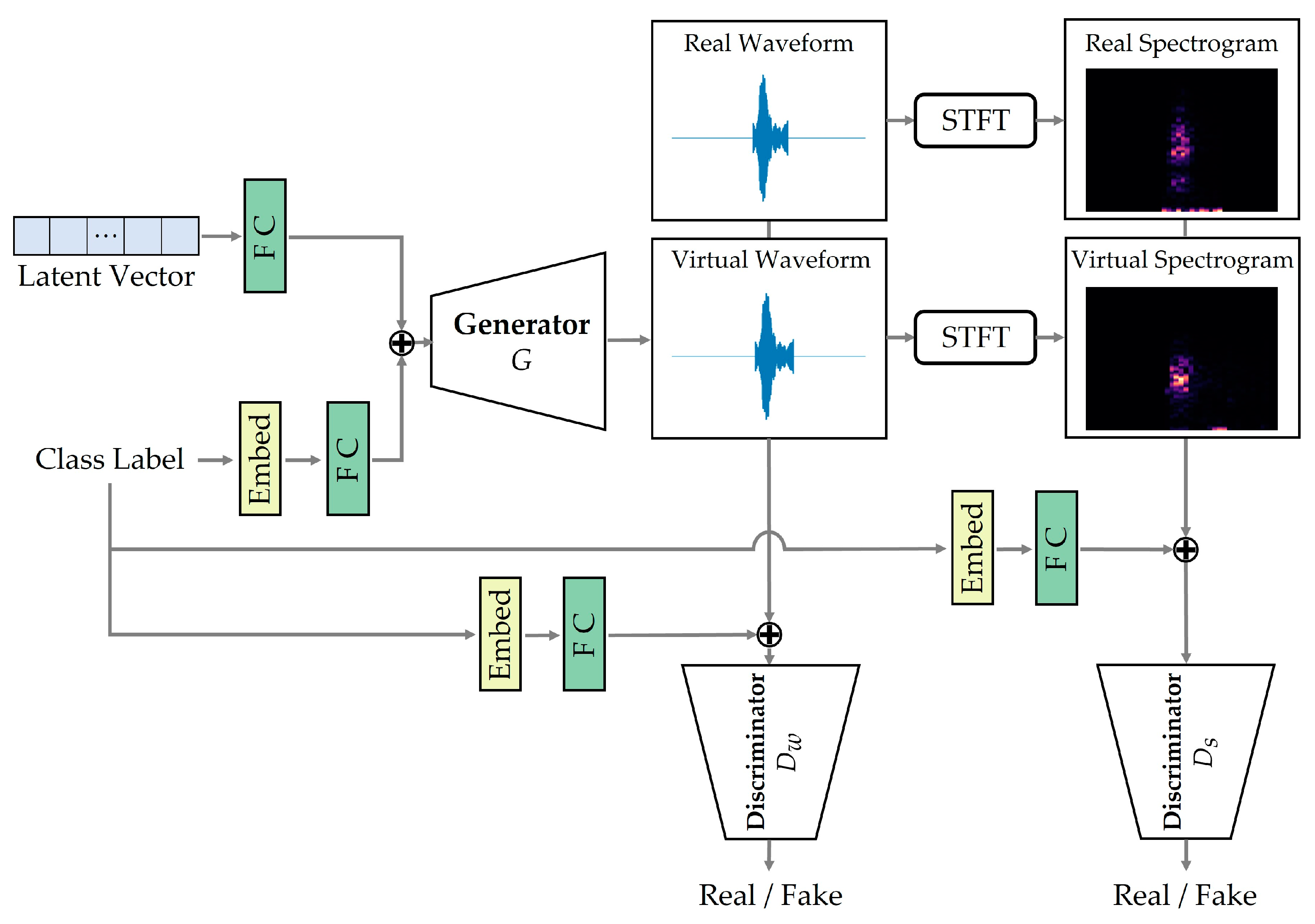
- We propose a novel two-stage sound data augmentation scheme using a class-conditional GAN to solve the data shortage problem in ASC.
- We present an effective way to consider both the waveform and the spectrogram of sound to plausibly generate animal sound data. In addition, we propose a data selection method for augmentation from the generated data to improve ASC performance.
- We compare the ASC performance of the proposed scheme with other popular data augmentation methods through various experiments on real-world audio datasets of bird and frog species. Furthermore, we validate the class-specific and aggregate generative capability of the proposed scheme.
2. Related Work
2.1. Overview of GAN
2.2. Data Augmentation for Sound Classification
3. Method
3.1. DualDiscWaveGAN
3.2. Adversarial Loss
3.3. Confidence-Based Data Selection
4. Experiments Setup
4.1. Datasets
- North American Bird Species (NA birds): This audio dataset, introduced by Zhao et al. [27], contains audio recordings of eleven bird species commonly observed in North America. The species are Cyanocitta cristata, Melospiza melodia, Cistothorus palustris, Geothlypis trichas, Spizella passerine, Setophaga aestiva, Ardea herodias, Corvus brachyrhynchos, Bombycilla cedrorum, Haemorhous mexicanus, and Passerina cyanea. All the recordings were collected from the Xeno-canto archive (https://xeno-canto.org/, accessed on 10 September 2022) and split into segments representing short songs or calls. The sounds are as varied as the mixed tones and partly contain background noise. In our experiments, we used 2515 segments from 10 birds, excluding Ardea herodias, which are classified in a different order in the biological classification.
- South Korean Frog Species (SK frogs): This dataset contains 16,245 audio segments collected from five species of anuran living in South Korea. The species are Kaloula borealis, Bombina orientalis, Hyla suweonensis, Pelophylax nigromaculatus, and Hyla japonica. All the anuran sounds were recorded in their habitats under the following conditions: sample rate of 44.1 kHz, single channel, and 16-bit resolution. Because many recorded sounds substantially overlap with other animal sounds and background noises, we divided all the recordings into multiple segments by using the end-point detection method [28], and removed the segments that were heavily intermingled with sounds from other species or loud noises.
4.2. Evaluation Metrics
4.2.1. Quality Evaluation Metrics
4.2.2. Diversity Evaluation Metrics
4.3. Implementation Details
4.4. Comparative Data Augmentation Methods
5. Results and Discussion
5.1. Quality and Diversity Evaluation
5.2. Comparsion with Different Data Augmentation Methods
5.2.1. ASC Experiment on the Random Separation Protocol
5.2.2. ASC Experiment on the Regional Separation Protocol
5.3. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Potamitis, I.; Ntalampiras, S.; Jahn, O.; Riede, K. Automatic bird sound detection in long real-field recordings: Applications and tools. Appl. Acoust. 2014, 80, 1–9. [Google Scholar] [CrossRef]
- Xie, J.; Zhu, M. Handcrafted features and late fusion with deep learning for bird sound classification. Ecol. Inform. 2019, 52, 74–81. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, L.; Chen, H.; Xie, J. Bird Species Identification Using Spectrogram Based on Multi-Channel Fusion of DCNNs. Entropy 2021, 23, 1507. [Google Scholar] [CrossRef]
- Moon, J.; Jung, S.; Park, S.; Hwang, E. Conditional tabular GAN-based two-stage data generation scheme for short-term load forecasting. IEEE Access 2020, 8, 205327–205339. [Google Scholar] [CrossRef]
- Nanni, L.; Maguolo, G.; Paci, M. Data augmentation approaches for improving animal audio classification. Ecol. Inform. 2020, 57, 101084. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–26 August 2021; pp. 4653–4660. [Google Scholar] [CrossRef]
- Ma, S.; Cui, J.; Xiao, W.; Liu, L. Deep Learning-Based Data Augmentation and Model Fusion for Automatic Arrhythmia Identification and Classification Algorithms. Comput. Intell. Neurosci. 2022, 2022, 1577778. [Google Scholar] [CrossRef]
- Bahmei, B.; Birmingham, E.; Arzanpour, S. CNN-RNN and Data Augmentation Using Deep Convolutional Generative Adversarial Network for Environmental Sound Classification. IEEE Signal Process. Lett. 2022, 29, 682–686. [Google Scholar] [CrossRef]
- Nanni, L.; Costa, Y.M.; Aguiar, R.L.; Mangolin, R.B.; Brahnam, S.; Silla, C.N. Ensemble of convolutional neural networks to improve animal audio classification. EURASIP J. Audio Speech Music Process. 2020, 2020, 8. [Google Scholar] [CrossRef]
- Wu, Y.; Zhu, L.; Yan, Y.; Yang, Y. Dual attention matching for audio-visual event localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 29 October 2019–1 November 2019; pp. 6292–6300. [Google Scholar] [CrossRef]
- Xie, J.; Hu, K.; Guo, Y.; Zhu, Q.; Yu, J. On loss functions and CNNs for improved bioacoustic signal classification. Ecol. Inform. 2021, 64, 101331. [Google Scholar] [CrossRef]
- Abayomi-Alli, O.O.; Damaševičius, R.; Qazi, A.; Adedoyin-Olowe, M.; Misra, S. Data Augmentation and Deep Learning Methods in Sound Classification: A Systematic Review. Electronics 2022, 11, 3795. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Su, S.-F. Environmental sound classification using a regularized deep convolutional neural network with data augmentation. Appl. Acoust. 2020, 167, 107389. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar] [CrossRef]
- Esmaeilpour, M.; Cardinal, P.; Koerich, A.L. Unsupervised feature learning for environmental sound classification using weighted cycle-consistent generative adversarial network. Appl. Soft Comput. 2020, 86, 105912. [Google Scholar] [CrossRef]
- Madhu, A.; Suresh, K. EnvGAN: A GAN-based augmentation to improve environmental sound classification. Artif. Intell. Rev. 2022, 55, 6301–6320. [Google Scholar] [CrossRef]
- Donahue, C.; McAuley, J.; Puckette, M. Adversarial audio synthesis. arXiv 2018, arXiv:1802.04208. [Google Scholar]
- Jayalakshmy, S.; Sudha, G.F. Conditional GAN based augmentation for predictive modeling of respiratory signals. Comput. Biol. Med. 2021, 138, 104930. [Google Scholar] [CrossRef] [PubMed]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Seibold, M.; Hoch, A.; Farshad, M.; Navab, N.; Fürnstahl, P. Conditional Generative Data Augmentation for Clinical Audio Datasets. arXiv 2022, arXiv:2203.11570. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of Wasserstein GANs. Adv. Neural Inf. Process. Syst. 2017, 30, 5769–5779. [Google Scholar]
- Shao, S.; Wang, P.; Yan, R. Generative adversarial networks for data augmentation in machine fault diagnosis. Comput. Ind. 2019, 106, 85–93. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier GANs. In Proceedings of the 34th International Conference on Machine Learning, International Convention Centre, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Zhao, Z.; Zhang, S.-H.; Xu, Z.-Y.; Bellisario, K.; Dai, N.-H.; Omrani, H.; Pijanowski, B.C. Automated bird acoustic event detection and robust species classification. Ecol. Inform. 2017, 39, 99–108. [Google Scholar] [CrossRef]
- Park, J.; Kim, W.; Han, D.K.; Ko, H. Voice activity detection in noisy environments based on double-combined Fourier transform and line fitting. Sci. World J. 2014, 2014, 146040. [Google Scholar] [CrossRef] [PubMed]
- Okamoto, Y.; Imoto, K.; Komatsu, T.; Takamichi, S.; Yagyu, T.; Yamanishi, R.; Yamashita, Y. Overview of tasks and investigation of subjective evaluation methods in environmental sound synthesis and conversion. arXiv 2019, arXiv:1908.10055. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6629–6640. [Google Scholar]
- Engel, J.; Agrawal, K.K.; Chen, S.; Gulrajani, I.; Donahue, C.; Roberts, A. Gansynth: Adversarial neural audio synthesis. arXiv 2019, arXiv:1902.08710. [Google Scholar] [CrossRef]
- Miyato, T.; Koyama, M. cGANs with projection discriminator. arXiv 2018, arXiv:1802.05637. [Google Scholar] [CrossRef]
- Richardson, E.; Weiss, Y. On GANs and GMMs. Adv. Neural Inf. Process. Syst. 2018, 31, 5852–5863. [Google Scholar]
- Liu, X.; Iqbal, T.; Zhao, J.; Huang, Q.; Plumbley, M.D.; Wang, W. Conditional sound generation using neural discrete time-frequency representation learning. In Proceedings of the IEEE 31st International Workshop on Machine Learning for Signal Processing, Gold Coast, Australia, 25–28 October 2021; pp. 1–6. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2020, 17, 168–192. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. NIPS Autodiff Workshop. 2017. Available online: https://openreview.net/pdf?id=BJJsrmfCZ (accessed on 11 November 2022).
- Borji, A. Pros and cons of gan evaluation measures. Comput. Vis. Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Method | Data Type | Augmentation Setting |
|---|---|---|
| Time stretching | Waveform | Speed scaling by a random value [0.8, 1.2] |
| Pitch shifting | Waveform | Pitch shifting by a random value [−2, 2] |
| Background noise addition | Waveform | Background noises from Freesound web DB |
| White noise addition | Waveform | Random noises with uniform intensity |
| Frequency masking | Spectrogram | Random mask size (max. 50% of frequency range) and index |
| Time masking | Spectrogram | Random mask size (max. 50% of time range) and index |
| Conditional Generative Model | FID | NDBall-classes (K = 100) |
|---|---|---|
| cGAN | 31.73 | 33 |
| ACGAN | 37.96 | 22 |
| Projection-cGAN | 35.94 | 21 |
| DualDiscWaveGAN | 26.45 | 4 |
| Class | Intra-FID/NDBclass-wise (K = 20) | |||
|---|---|---|---|---|
| cGAN | ACGAN | Projection-cGAN | DualDiscWaveGAN | |
| Cyanocitta cristata | 74.30/2 | 73.89/3 | 64.41/1 | 60.59/1 |
| Melospiza melodia | 44.26/4 | 52.20/9 | 26.38/3 | 28.05/3 |
| Cistothorus palustris | 18.35/4 | 17.07/0 | 16.94/1 | 18.15/1 |
| Geothlypis trichas | 76.60/6 | 63.83/10 | 63.15/4 | 29.67/3 |
| Spizella passerine | 87.85/6 | 101.52/7 | 128.06/9 | 35.32/0 |
| Setophaga aestiva | 96.70/5 | 116.30/7 | 126.61/6 | 94.08/2 |
| Corvus brachyrhynchos | 17.33/3 | 14.22/4 | 26.01/2 | 11.98/2 |
| Bombycilla cedrorum | 118.12/2 | 156.83/8 | 125.73/4 | 116.30/1 |
| Haemorhous mexicanus | 30.73/4 | 48.77/11 | 55.53/7 | 18.31/1 |
| Passerina cyanea | 45.06/5 | 123.38/4 | 62.40/5 | 25.72/2 |
| Average | 60.93/4.1 | 76.80/6.3 | 69.52/4.2 | 43.82/1.6 |
| Method | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| ResNet | 95.4 | 95.5 | 95.3 | 95.4 |
| Time stretching | 97.2 | 97.2 | 97.2 | 97.2 |
| Pitch shifting | 97.6 | 97.6 | 97.6 | 97.6 |
| White noise addition | 96.8 | 96.8 | 96.8 | 96.8 |
| Background noise addition | - | - | - | - |
| Frequency masking | 97.0 | 97.0 | 97.0 | 97.0 |
| Time masking | 94.4 | 94.5 | 94.4 | 94.4 |
| Proposed scheme w/o DS | 97.8 | 97.8 | 97.9 | 97.8 |
| Proposed scheme | 98.4 | 98.4 | 98.5 | 98.4 |
| Method | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| ResNet | 65.8 | 77.0 | 73.8 | 69.5 |
| Time stretching | 62.8 | 78.4 | 69.9 | 65.7 |
| Pitch shifting | 53.8 | 66.2 | 61.2 | 56.1 |
| Background noise addition | 68.9 | 76.2 | 75.8 | 69.8 |
| White noise addition | 70.7 | 78.4 | 79.1 | 75.1 |
| Frequency masking | 65.2 | 68.7 | 72.4 | 61.9 |
| Time masking | 67.6 | 74.9 | 74.4 | 68.3 |
| Proposed scheme w/o DS | 83.7 | 82.0 | 76.0 | 76.6 |
| Proposed scheme | 84.1 | 82.5 | 76.3 | 76.9 |
| Method | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| ResNet (No augmentation) | 65.8 | 77.0 | 73.8 | 69.5 |
| cGAN | 74.6 | 77.9 | 75.8 | 74.1 |
| cGAN with SD | 83.7 | 82.0 | 76.0 | 76.6 |
| cGAN with SD & DS (Proposed) | 84.1 | 82.5 | 76.3 | 76.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, E.; Moon, J.; Shim, J.; Hwang, E. DualDiscWaveGAN-Based Data Augmentation Scheme for Animal Sound Classification. Sensors 2023, 23, 2024. https://doi.org/10.3390/s23042024
Kim E, Moon J, Shim J, Hwang E. DualDiscWaveGAN-Based Data Augmentation Scheme for Animal Sound Classification. Sensors. 2023; 23(4):2024. https://doi.org/10.3390/s23042024
Chicago/Turabian StyleKim, Eunbeen, Jaeuk Moon, Jonghwa Shim, and Eenjun Hwang. 2023. "DualDiscWaveGAN-Based Data Augmentation Scheme for Animal Sound Classification" Sensors 23, no. 4: 2024. https://doi.org/10.3390/s23042024
APA StyleKim, E., Moon, J., Shim, J., & Hwang, E. (2023). DualDiscWaveGAN-Based Data Augmentation Scheme for Animal Sound Classification. Sensors, 23(4), 2024. https://doi.org/10.3390/s23042024