



A Multi-Stage Deep-Learning-Based Vehicle and License Plate Recognition System with Real-Time Edge Inference



Abstract
:1. Introduction
- This study proposes a novel multi-stage system for real-time vehicle identification based on deep learning models. Two different techniques (single-character and double-character detection) are presented and assessed. To the best of our knowledge, the matching post-processing procedure for the single character detection and the double character detection approach are both introduced for the first time in the literature.
- New dedicated datasets of vehicles, license plates, and license characters are carefully collected and manually labeled.
- A set of carefully designed algorithms efficiently integrate two object detectors, an image classifier, and a customized version of the DeepSort tracker, so that the system processes video streams in real-time and sends unique information about cars and license plates to a cloud server while maximizing the accuracy by taking advantage of redundancies.
- Extensive experiments are carried out on images and videos recorded under realistic conditions to evaluate the performance of the proposed system. The results show a promising performance both in terms of accuracy and inference speed, after optimizing the detection and classification models using TensorRT to run them on edge devices.
2. Related Works
3. Materials and Methods
3.1. Car and License Plate Detection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Validation Set | Total | |
|---|---|---|---|
| Number of images | 183 | 20 | 203 |
| Number of car instances | 740 | 79 | 819 |
| Number of LP instances | 227 | 19 | 246 |
3.2. Car Model Recognition
| Training Set | Validation Set | Testing Set | Total | |
|---|---|---|---|---|
| Number of images | 36,953 | 2284 | 2284 | 41,521 |
| Percentage | 89% | 5.5% | 5.5% | 100% |
| Training Hyperparameter | Value |
|---|---|
| Image input size | 224 × 224 |
| Batch size | 1024 |
| Learning rate | |
| Optimizer | Adam |
| Loss function | Categorical cross entropy |
| Nb epochs | 800 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Macro average | 97.5% | 97.3% | 97.3% |
| Weighted average | 97.5% | 97.3% | 97.3% |
| Accuracy | 97.3% |


3.3. License Character Recognition
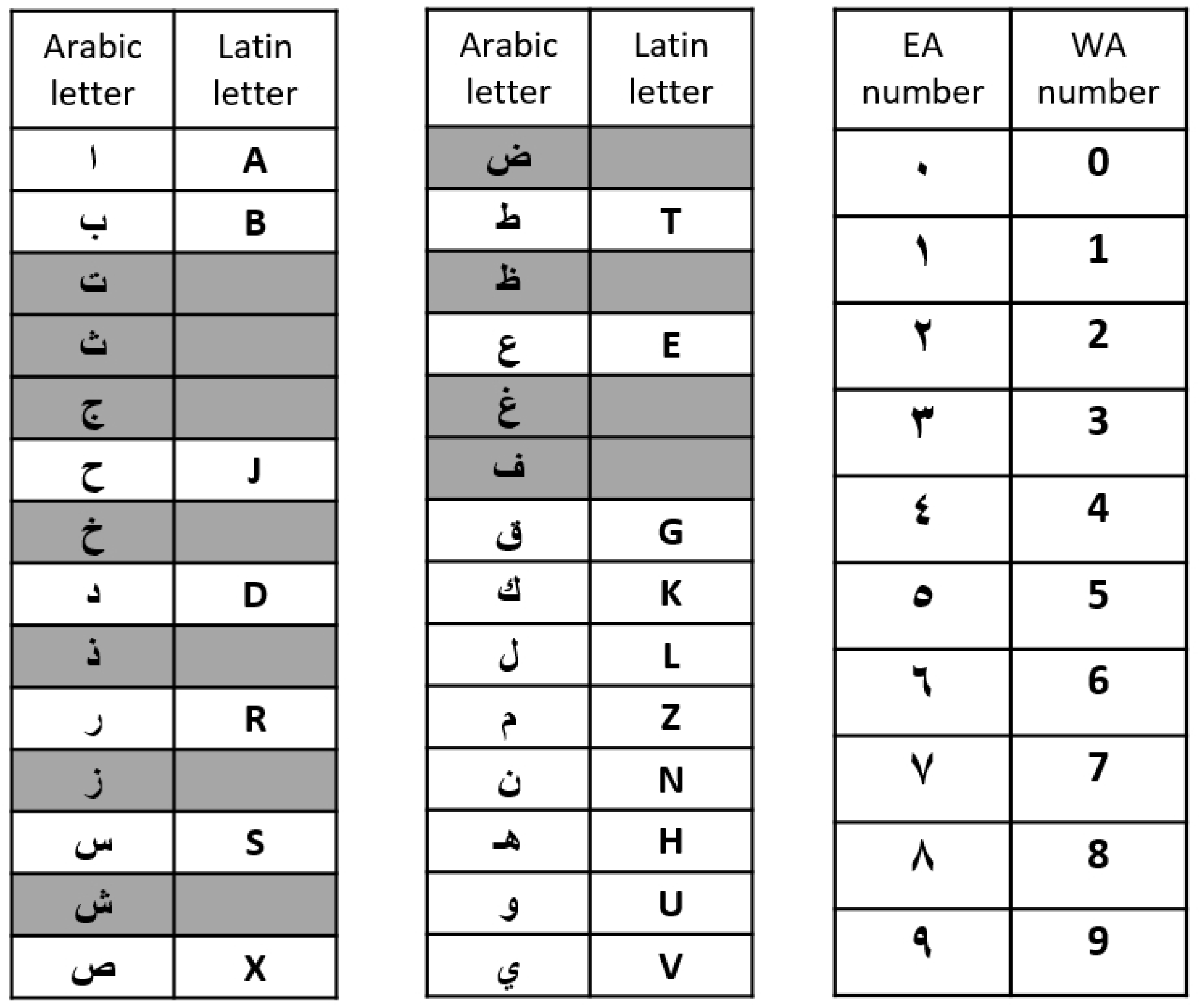
3.3.1. Characteristics of Saudi License Plates
3.3.2. First Approach: Single-Character Detection

| Training Set | Validation Set | Total | |
|---|---|---|---|
| Number of images | 336 | 37 | 373 |
| Number of character instances | 4678 | 515 | 5193 |

3.3.3. Second Approach: Double-Character Detection

| Training Set | Validation Set | Total | |
|---|---|---|---|
| Number of images | 561 | 32 | 593 |
| Number of character instances | 3628 | 199 | 3827 |
3.4. Tracking
- : a list containing the detected LP bounding box coordinates on the image.
- : a dictionary containing a list of selected characters for each license plate position. The length of the list corresponds to the number of frames in which the character was detected.
- : surface of the detected license plate, in pixels ().
- : a list containing the car model yielded by the classifier for each frame in which the car was detected.
- : a list containing the car model’s confidence score for each frame in which the car was detected.
- : name of the currently selected car model, after voting on the series of frames in which the car was detected. This name is visualized in real-time, but the definitive name will only be sent to the server with the conditions defined in Figure 11.
- : Boolean variable indicating whether the information of the track was already sent to the server or not.
- : number of detected characters in the license plate for the current frame.
- : license plate image saved as a Numpy array. When the same license plate (same ) is detected in a series of frames, only the image having the maximum surface is saved.
- : car image saved as a Numpy array. When the same car is detected in a series of frames, only the image having the maximum surface is saved.

3.5. Model Optimization
3.6. Edge-Cloud Communication
- The car quits the camera field of view for a predefined number of successive frames ();
- The car has been tracked for a predefined number of successive frames ().
- The car cropped image (in base 64).
- The license plate cropped image (in base 64).
- The predicted car model.
- The car model confidence (averaged on a series of frames).
- The predicted license plate.
- The license plate confidence (averaged on a series of frames).
- The timestamp.
- The camera ID and location.
3.7. Description of the Complete Multi-Stage Process


4. Results and Discussion
4.1. Evaluation Approach
4.2. Car Model Recognition
4.3. License Plate Recognition

| Video 1 | Video 2 | Total | |
|---|---|---|---|
| Duration | 11 mn:18 s | 21 mn:28 s | 32 mn:46 s |
| Original FPS | 25 | 30 | – |
| Number of unique cars | 58 | 61 | 119 |
| Number of character pairs | 403 | 420 | 823 |
| Missed LP detections | 5% | 0% | 2.5% |
| Correctly predicted characters | 81.9% | 95% | 88.6% |
| Correctly predicted LPs | 67% | 80% | 74% |
| Missed car detections | 3% | 0% | 1.7% |
| Nonexistent car models (not included in the training dataset) | 24% | 28% | 26% |
| Misclassified car models | 41% | 23% | 32% |
| Misclassified car models and generations | 43% | 32% | 38% |
| Correctly classified car models | 33% | 49% | 43% |
| Correctly classified car models and generations | 31% | 45% | 37% |
| Average processing speed (in FPS) | 14.4 | 18.4 | 17.1 |

| Resolution | 1920 × 1080 | 1280 × 720 | 720 × 480 |
|---|---|---|---|
| Missed LP detections | 0% | 2% | 20% |
| Correctly predicted characters | 95% | 91.2% | 79.3% |
| Correctly predicted LPs | 80% | 72% | 23% |
| Average processing speed (in FPS) | 18.4 | 19.5 | 21.2 |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- AI Surveillance Camera Market 2022. Available online: https://southeast.newschannelnebraska.com/story/45571414/ai-surveillance-camera%C2%A0 (accessed on 6 June 2022).
- ANPR System Market (2022–2027). Available online: https://www.marketsandmarkets.com/Market-Reports/anpr-system-market-140920103.html (accessed on 6 June 2022).
- The Winners of the KAUST Challenge—Ideas & Solutions For Hajj & Umrah 2020. Available online: https://challenge.kaust.edu.sa/assets/pdfs/WINNER%20EN.pdf (accessed on 6 June 2022).
- Oyoon Wins Best AI Product Award at the Saudi International Artificial Intelligence & Cloud Expo 2022. Available online: https://www.riotu-lab.org/newsDetails.php?id=12 (accessed on 6 June 2022).
- Wang, H.; Hou, J.; Chen, N. A survey of vehicle re-identification based on deep learning. IEEE Access 2019, 7, 172443–172469. [Google Scholar] [CrossRef]
- Boukerche, A.; Ma, X. Vision-based Autonomous Vehicle Recognition: A New Challenge for Deep Learning-based Systems. ACM Comput. Surv. (CSUR) 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Llorca, D.F.; Colás, D.; Daza, I.G.; Parra, I.; Sotelo, M.A. Vehicle model recognition using geometry and appearance of car emblems from rear view images. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 3094–3099. [Google Scholar] [CrossRef]
- Lee, H.J.; Ullah, I.; Wan, W.; Gao, Y.; Fang, Z. Real-time vehicle make and model recognition with the residual SqueezeNet architecture. Sensors 2019, 19, 982. [Google Scholar] [CrossRef]
- Manzoor, M.A.; Morgan, Y.; Bais, A. Real-time vehicle make and model recognition system. Mach. Learn. Knowl. Extr. 2019, 1, 611–629. [Google Scholar] [CrossRef]
- Shashirangana, J.; Padmasiri, H.; Meedeniya, D.; Perera, C. Automated license plate recognition: A survey on methods and techniques. IEEE Access 2020, 9, 11203–11225. [Google Scholar] [CrossRef]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. A deep learning-based approach to progressive vehicle re-identification for urban surveillance. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 869–884. [Google Scholar]
- Selmi, Z.; Halima, M.B.; Alimi, A.M. Deep learning system for automatic license plate detection and recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1132–1138. [Google Scholar]
- Kessentini, Y.; Besbes, M.D.; Ammar, S.; Chabbouh, A. A two-stage deep neural network for multi-norm license plate detection and recognition. Expert Syst. Appl. 2019, 136, 159–170. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Hendry; Chen, R.-C. Automatic License Plate Recognition via sliding-window darknet-YOLO deep learning. Image Vis. Comput. 2019, 87, 47–56. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Sarfraz, M.; Ahmed, M.; Ghazi, S. Saudi Arabian license plate recognition system. In Proceedings of the 2003 International Conference on Geometric Modeling and Graphics, London, UK, 16–18 July 2003; pp. 36–41. [Google Scholar] [CrossRef]
- Ahmed, M.J.; Sarfraz, M.; Zidouri, A.; Al-Khatib, W.G. License plate recognition system. In Proceedings of the 10th IEEE International Conference on Electronics, Circuits and Systems, 2003 (ICECS 2003), Sharjah, United Arab Emirates, 14–17 December 2003; Volume 2, pp. 898–901. [Google Scholar]
- Zidouri, A.; Deriche, M. Recognition of Arabic license plates using NN. In Proceedings of the 2008 First Workshops on Image Processing Theory, Tools and Applications, Sousse, Tunisia, 23–26 November 2008; pp. 1–4. [Google Scholar]
- Khan, I.R.; Ali, S.T.A.; Siddiq, A.; Khan, M.M.; Ilyas, M.U.; Alshomrani, S.; Rahardja, S. Automatic License Plate Recognition in Real-World Traffic Videos Captured in Unconstrained Environment by a Mobile Camera. Electronics 2022, 11, 1408. [Google Scholar] [CrossRef]
- Driss, M.; Almomani, I.; Al-Suhaimi, R.; Al-Harbi, H. Automatic Saudi Arabian License Plate Detection and Recognition Using Deep Convolutional Neural Networks. In International Conference of Reliable Information and Communication Technology; Springer: Cham, Switzerland, 2022; pp. 3–15. [Google Scholar]
- Tote, A.S.; Pardeshi, S.S.; Patange, A.D. Automatic number plate detection using TensorFlow in Indian scenario: An optical character recognition approach. Mater. Today Proc. 2023, 72, 1073–1078. [Google Scholar] [CrossRef]
- Khan, M.A.; Sharif, M.; Javed, M.Y.; Akram, T.; Yasmin, M.; Saba, T. License number plate recognition system using entropy-based features selection approach with SVM. IET Image Process. 2018, 12, 200–209. [Google Scholar] [CrossRef]
- Alginahi, Y.M. Automatic arabic license plate recognition. Int. J. Comput. Electr. Eng. 2011, 3, 454–460. [Google Scholar] [CrossRef]
- Basalamah, S. Saudi license plate recognition. Int. J. Comput. Electr. Eng. 2013, 5, 1. [Google Scholar] [CrossRef]
- Perwej, Y.; Akhtar, N.; Parwej, F. The Kingdom of Saudi Arabia Vehicle License Plate Recognition using Learning Vector Quantization Artificial Neural Network. Int. J. Comput. Appl. 2014, 98, 32–38. [Google Scholar] [CrossRef]
- Alyahya, H.M.; Alharthi, M.K.; Alattas, A.M.; Thayananthan, V. Saudi license plate recognition system using artificial neural network classifier. In Proceedings of the 2017 International Conference on Computer and Applications (ICCA), Doha, Qatar, 6–7 September 2017; pp. 220–226. [Google Scholar]
- Alzubaidi, L.; Latif, G.; Alghazo, J. Affordable and portable realtime saudi license plate recognition using SoC. In Proceedings of the 2019 2nd International Conference on New Trends in Computing Sciences (ICTCS), Amman, Jordan, 9–11 October 2019; pp. 1–5. [Google Scholar]
- Antar, R.; Alghamdi, S.; Alotaibi, J.; Alghamdi, M. Automatic Number Plate Recognition of Saudi License Car Plates. Eng. Technol. Appl. Sci. Res. 2022, 12, 8266–8272. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ammar, A.; Koubaa, A.; Benjdira, B. Deep-Learning-based Automated Palm Tree Counting and Geolocation in Large Farms from Aerial Geotagged Images. Agronomy 2021, 11, 1458. [Google Scholar] [CrossRef]
- Ammar, A.; Koubaa, A.; Ahmed, M.; Saad, A.; Benjdira, B. Vehicle detection from aerial images using deep learning: A comparative study. Electronics 2021, 10, 820. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, Montreal, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Yadav, S.; Shukla, S. Analysis of k-Fold Cross-Validation over Hold-Out Validation on Colossal Datasets for Quality Classification. In Proceedings of the 2016 IEEE 6th International Conference on Advanced Computing (IACC), Bhimavaram, India, 27–28 February 2016; pp. 78–83. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Koubaa, A.; Ammar, A.; Kanhouch, A.; AlHabashi, Y. Cloud Versus Edge Deployment Strategies of Real-Time Face Recognition Inference. IEEE Trans. Netw. Sci. Eng. 2022, 9, 143–160. [Google Scholar] [CrossRef]
- Wolpert, D.H. The lack of a priori distinctions between learning algorithms. Neural Comput. 1996, 8, 1341–1390. [Google Scholar] [CrossRef]
- Hsu, H.K.; Yao, C.H.; Tsai, Y.H.; Hung, W.C.; Tseng, H.Y.; Singh, M.; Yang, M.H. Progressive domain adaptation for object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, Colorado, 2–5 March 2020; pp. 749–757. [Google Scholar]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef]
- Benjdira, B.; Ammar, A.; Koubaa, A.; Ouni, K. Data-efficient domain adaptation for semantic segmentation of aerial imagery using generative adversarial networks. Appl. Sci. 2020, 10, 1092. [Google Scholar] [CrossRef]
- Ayoub, A.; Naeem, E.A.; El-Shafai, W.; Sultan, E.A.; Zahran, O.; Abd El-Samie, F.E.; EL-Rabaie, E.S.M. Video quality enhancement using recursive deep residual learning network. Signal Image Video Process. 2022, 17, 257–265. [Google Scholar] [CrossRef]
- Lee, C.; Cho, S.; Choe, J.; Jeong, T.; Ahn, W.; Lee, E. Objective video quality assessment. Opt. Eng. 2006, 45, 017004. [Google Scholar] [CrossRef]
- Chikkerur, S.; Sundaram, V.; Reisslein, M.; Karam, L.J. Objective video quality assessment methods: A classification, review, and performance comparison. IEEE Trans. Broadcast. 2011, 57, 165–182. [Google Scholar] [CrossRef]
- Janowski, L.; Kozłowski, P.; Baran, R.; Romaniak, P.; Glowacz, A.; Rusc, T. Quality assessment for a visual and automatic license plate recognition. Multimed. Tools Appl. 2014, 68, 23–40. [Google Scholar] [CrossRef]
- Leszczuk, M.; Janowski, L.; Nawała, J.; Boev, A. Method for Assessing Objective Video Quality for Automatic License Plate Recognition Tasks. In Proceedings of the Multimedia Communications, Services and Security: 11th International Conference, MCSS 2022, Kraków, Poland, 3–4 November 2022; pp. 153–166. [Google Scholar]
- Ukhanova, A.; Støttrup-Andersen, J.; Forchhammer, S.; Madsen, J. Quality assessment of compressed video for automatic license plate recognition. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 3, pp. 306–313. [Google Scholar]
- Łubkowski, P.; Laskowski, D. Assessment of Quality of Identification of Data in Systems of Automatic Licence Plate Recognition. In Smart Solutions in Today’s Transport: 17th International Conference on Transport Systems Telematics, TST 2017, Katowice, Poland, 5–8 April 2017; Selected Papers 17; Springer: Cham, Switzerland, 2017; pp. 482–493. [Google Scholar]
- Boulila, B.; Khlifi, M.; Ammar, A.; Koubaa, A.; Benjdira, B.; Farah, I.F. A Hybrid Privacy-Preserving Deep Learning Approach for Object Classification in Very High-Resolution Satellite Images. Remote Sens. 2022, 14, 4631. [Google Scholar] [CrossRef]
- Boulila, B.; Ammar, A.; Benjdira, B.; Koubaa, A. Securing the classification of covid-19 in chest x-ray images: A privacy-preserving deep learning approach. In Proceedings of the 2022 International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 9–11 May 2022; pp. 220–225. [Google Scholar]
- Rehman, M.; Shafique, A.; Ghadi, Y.Y.; Boulila, W.; Jan, S.U.; Gadekallu, T.R.; Driss, M.; Ahmad, J. A Novel Chaos-Based Privacy-Preserving Deep Learning Model for Cancer Diagnosis. IEEE Trans. Netw. Sci. Eng. 2022, 9, 4322–4337. [Google Scholar] [CrossRef]




| Ref. | Type of LP | Dataset | Technique | Accuracy | Limitations |
|---|---|---|---|---|---|
| [12] | Tunisia: Arabic characters and digits | (1) AOLP dataset: 2049 car images; (2) PKU dataset: 3977 car images; (3) Caltech dataset: 126 car images; and (4) Tunisian dataset: 740 car images | LP detection and recognition: Mask RCNN | (1) ALOP dataset: 99. 3%; (2) PKU dataset: 99.4%; (3) Caltech dataset: 98.9%; and (4) Tunisian dataset: 97.9% | (1) Working under specific lighting and weather conditions; and (2) speed of the system |
| [13] | Tunisia: Arabic characters and digits | GAP-LP: 9175 images | LP detection and recognition: YOLOv2 | (1) GAP-LP: 97.67%; and (2) Radar dataset: 91.46% | Working under specific lighting and weather conditions |
| [15] | Taiwan: Latin characters and digits | AOLP dataset: 2049 car images | Modified YOLO for LP detection and recognition | LP detection: 98.22% and LP recognition: 78% | (1) Use of a single class classifier will greatly affect computation time; and (2) working under specific lighting and weather conditions. |
| [22] | India: Latin characters and digits | 500 images | OCR | 85% | (1) Videos not considered; and (2) relatively low accuracy |
| [23] | Pakistan: Latin characters and digits | (1) Caltech car dataset; (2) Medialab LPR dataset; and (3) own dataset | HOG and geometric features + SVM | 99.3–99.8% | (1) Videos not considered; and (2) not tested on real conditions |
| [20] | Saudi Arabia | Own dataset: Static images extracted from 20 videos at 30 FPS using a mobile phone | LP detection: YOLOv5 and LP recognition: CNN | LP recognition: 92.8% | (1) Arabic characters are not considered; and (2) working under specific lighting and weather conditions. |
| [21] | Saudi Arabia | Own dataset: 1150 car images | LP detection: Faster-RCNN and LP recognition: CNN | LP detection: 92% and LP recognition: 98% | (1) Real-time videos not considered; and (2) working under specific lighting and weather conditions. |
| [24] | Saudi Arabia | Tested on 470 images captured in outdoor environment | Mahalanobis distance + MLP-NN classifier | 94.9% for character recognition, with 1.4% rejection rate | Videos not considered |
| [25] | Saudi Arabia | Tested on 173 images | Character segmentation + template matching | 81% | (1) Videos not considered; (2) low accuracy; and (3) lack of robustness |
| [26] | Saudi Arabia | 350 images | Learning Vector Quantization Neural Network | 94% | Videos not considered |
| [27] | Saudi Arabia | 22 training images | Statistical features + MLP | 92% | (1) Videos not considered; and (2) small dataset |
| [28] | Saudi Arabia | Not described | KNN | 90.6% | (1) Videos not considered; (2) dataset not described; and (3) recognition of Latin characters and Western Arabic digits only |
| [29] | Saudi Arabia | 50 images | Canny filter + OCR | 92.4–96.0% | (1) Videos not considered; and (2) small dataset |
| Criterion | Value/Percentage |
|---|---|
| Number of images | 100 |
| Nonexistent car models (not included in the training dataset) | 14% |
| Missed car detections | 15% |
| Misclassified car models and generations | 42% |
| Misclassified car models | 38% |
| Correctly classified car models | 38% |
| Correctly classified car models and generations | 34% |
| Algorithm | % Missed LPs | % Correct Characters (Single or Double) | % Correct LPs | FPS |
|---|---|---|---|---|
| Model 1: 1-char detection (YOLOv3 320 × 320, 1 class) + image classification (MobileNetV2, 54 classes) | 18% | 86.7% | 50% | 4.8 |
| Model 2a: 2-char detection (YOLOv4 320 × 320, 27 classes) | 19% | 88.3% | 44% | 9.7 |
| Model 2b: 2-char detection (YOLOv4 416 × 416, 27 classes) | 21% | 92.5% | 53% | 9.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ammar, A.; Koubaa, A.; Boulila, W.; Benjdira, B.; Alhabashi, Y. A Multi-Stage Deep-Learning-Based Vehicle and License Plate Recognition System with Real-Time Edge Inference. Sensors 2023, 23, 2120. https://doi.org/10.3390/s23042120
Ammar A, Koubaa A, Boulila W, Benjdira B, Alhabashi Y. A Multi-Stage Deep-Learning-Based Vehicle and License Plate Recognition System with Real-Time Edge Inference. Sensors. 2023; 23(4):2120. https://doi.org/10.3390/s23042120
Chicago/Turabian StyleAmmar, Adel, Anis Koubaa, Wadii Boulila, Bilel Benjdira, and Yasser Alhabashi. 2023. "A Multi-Stage Deep-Learning-Based Vehicle and License Plate Recognition System with Real-Time Edge Inference" Sensors 23, no. 4: 2120. https://doi.org/10.3390/s23042120
APA StyleAmmar, A., Koubaa, A., Boulila, W., Benjdira, B., & Alhabashi, Y. (2023). A Multi-Stage Deep-Learning-Based Vehicle and License Plate Recognition System with Real-Time Edge Inference. Sensors, 23(4), 2120. https://doi.org/10.3390/s23042120