



A Reinforcement Learning Handover Parameter Adaptation Method Based on LSTM-Aided Digital Twin for UDN


Abstract
:1. Introduction
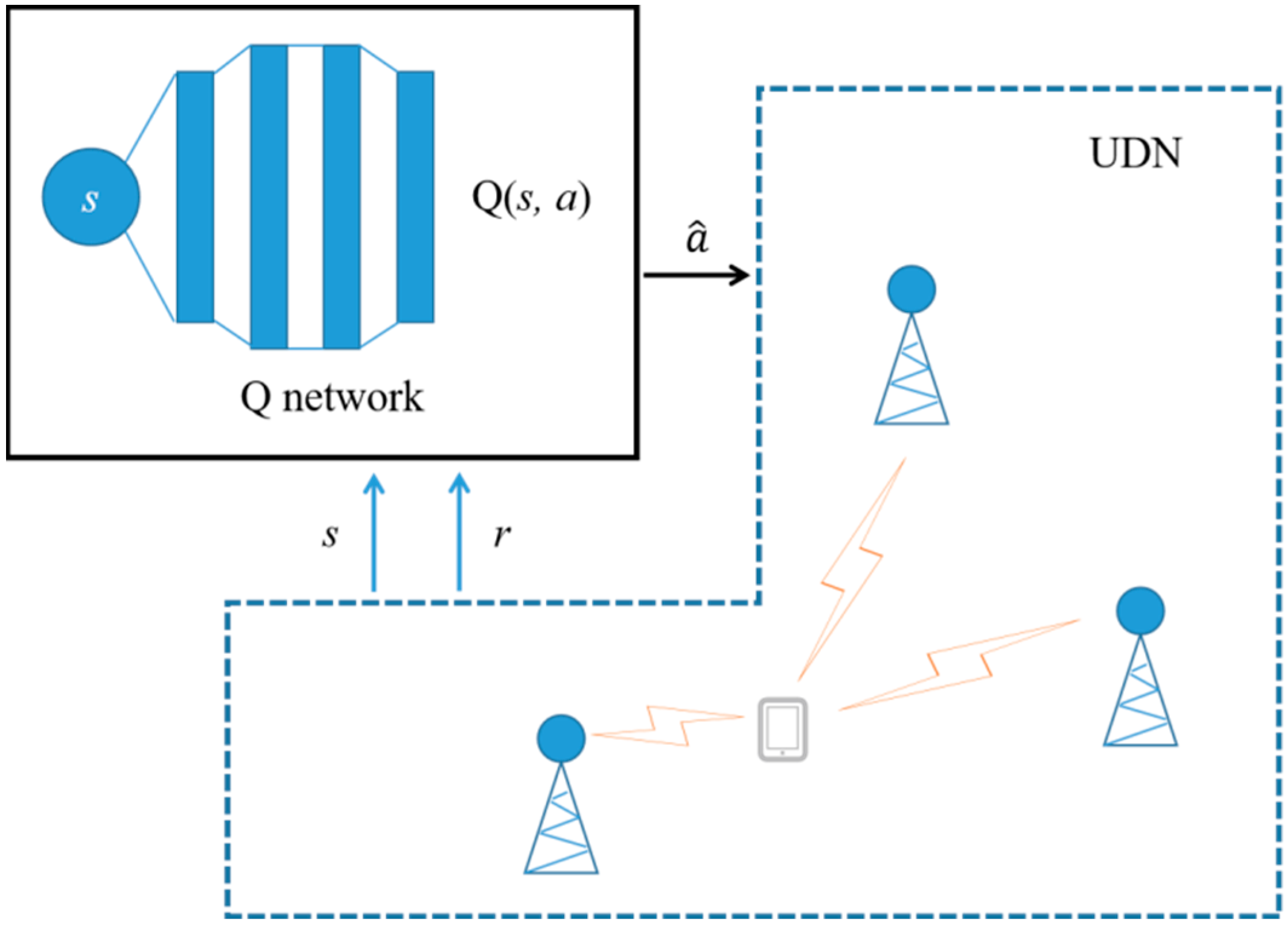
- Considering different conditions of signal fading, a real-time handover parameter selection method using a DQN is proposed. The method can be added to the actual communication system as an additional module without changing the handover process and has better backward compatibility. Good convergence performance is obtained through the validation of simulation platform.
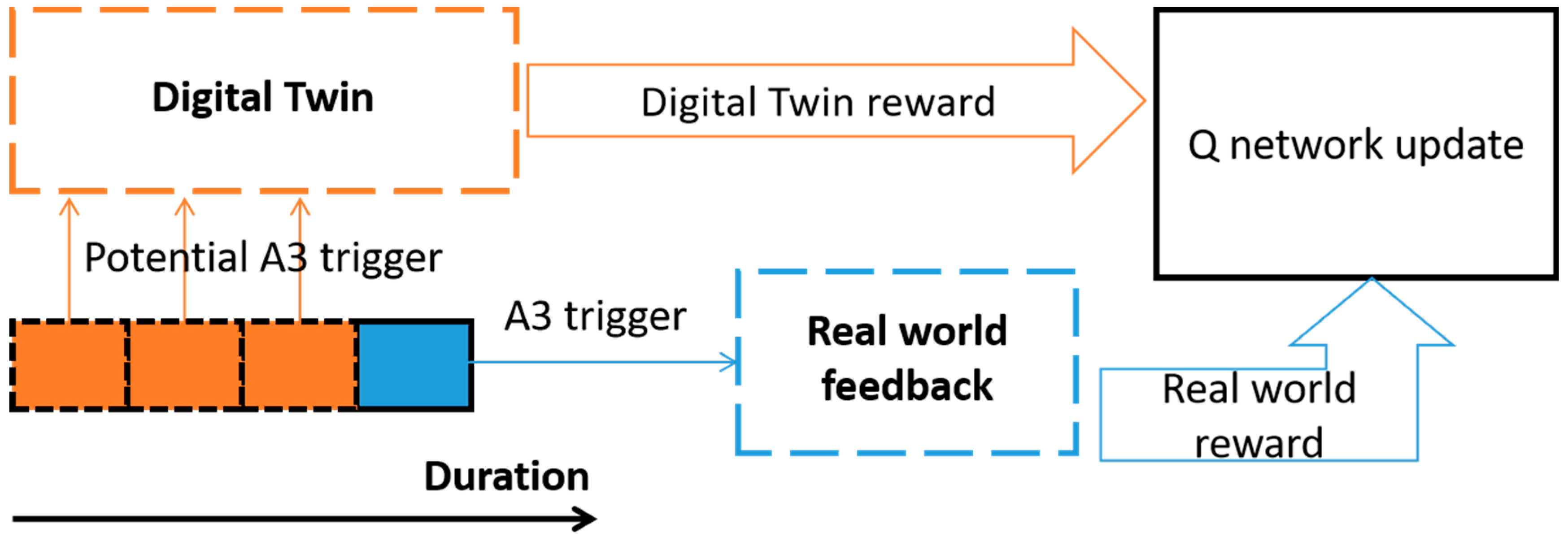
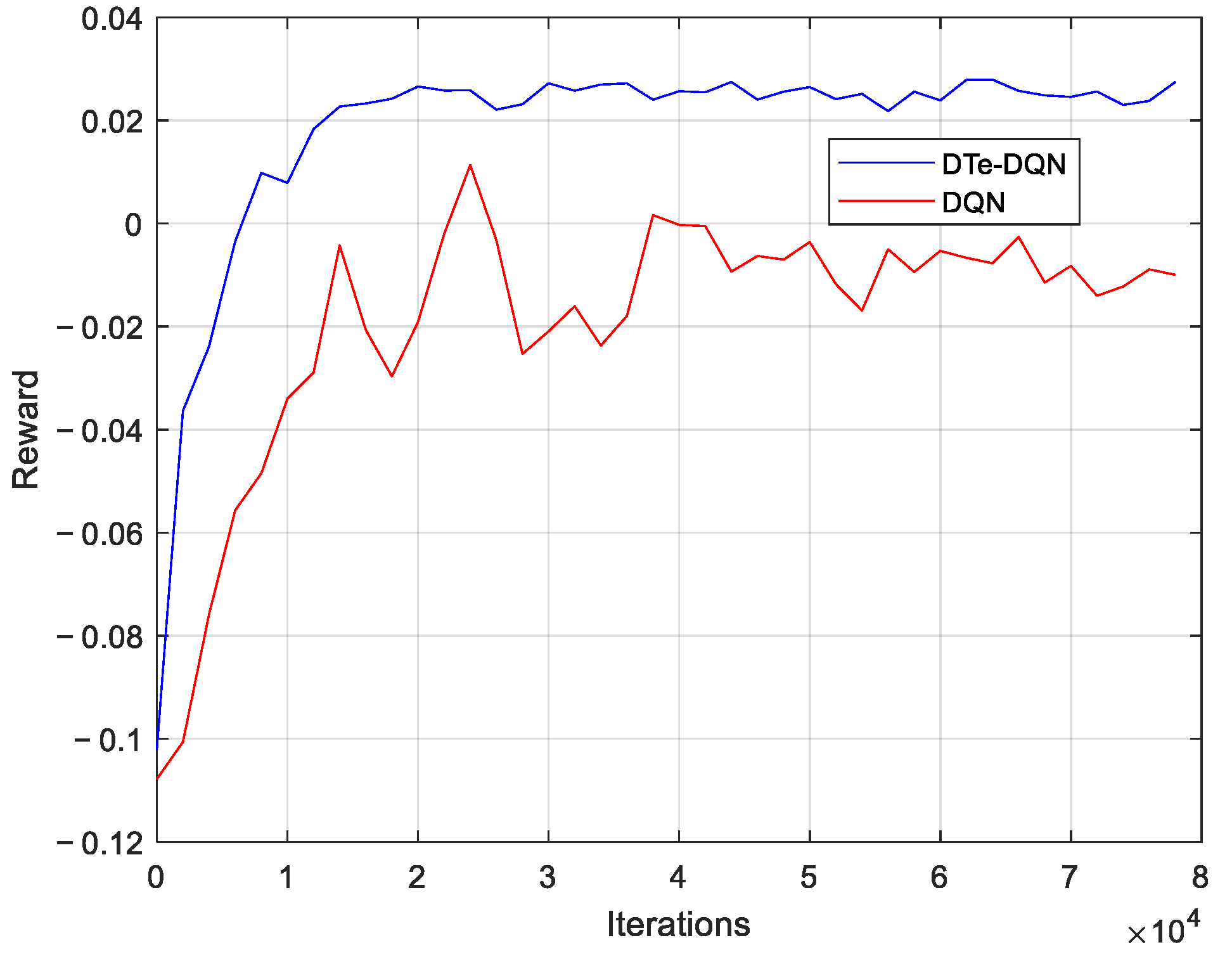
- An enhanced DQN method based on digital twin is proposed. RSRP data that can trigger different TTT parameters in the actual system are collected, and used as the input of digital twins to predict the reward value under the assumed handover parameters. The virtual rewards from digital twin act on the DQN together with the actual system reward values. Compared with the ordinary DQN, it has faster convergence speed, and the final convergence effect is also better and more stable.
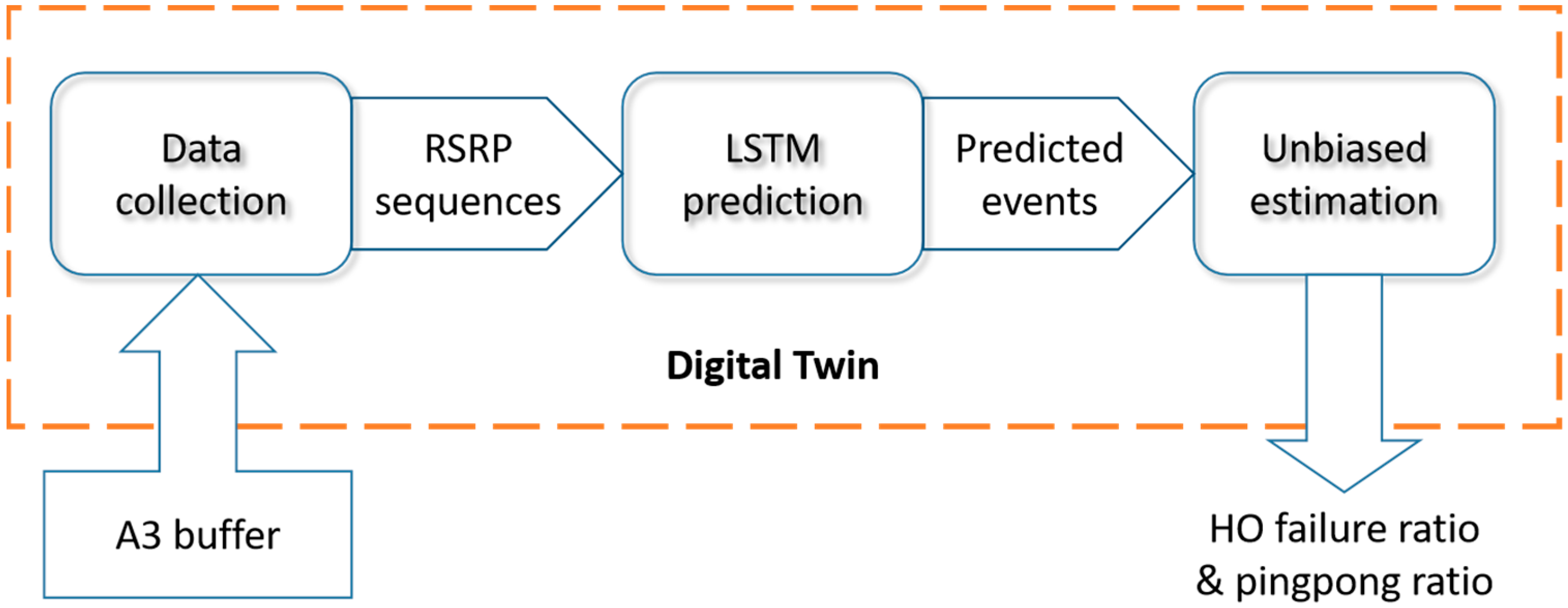
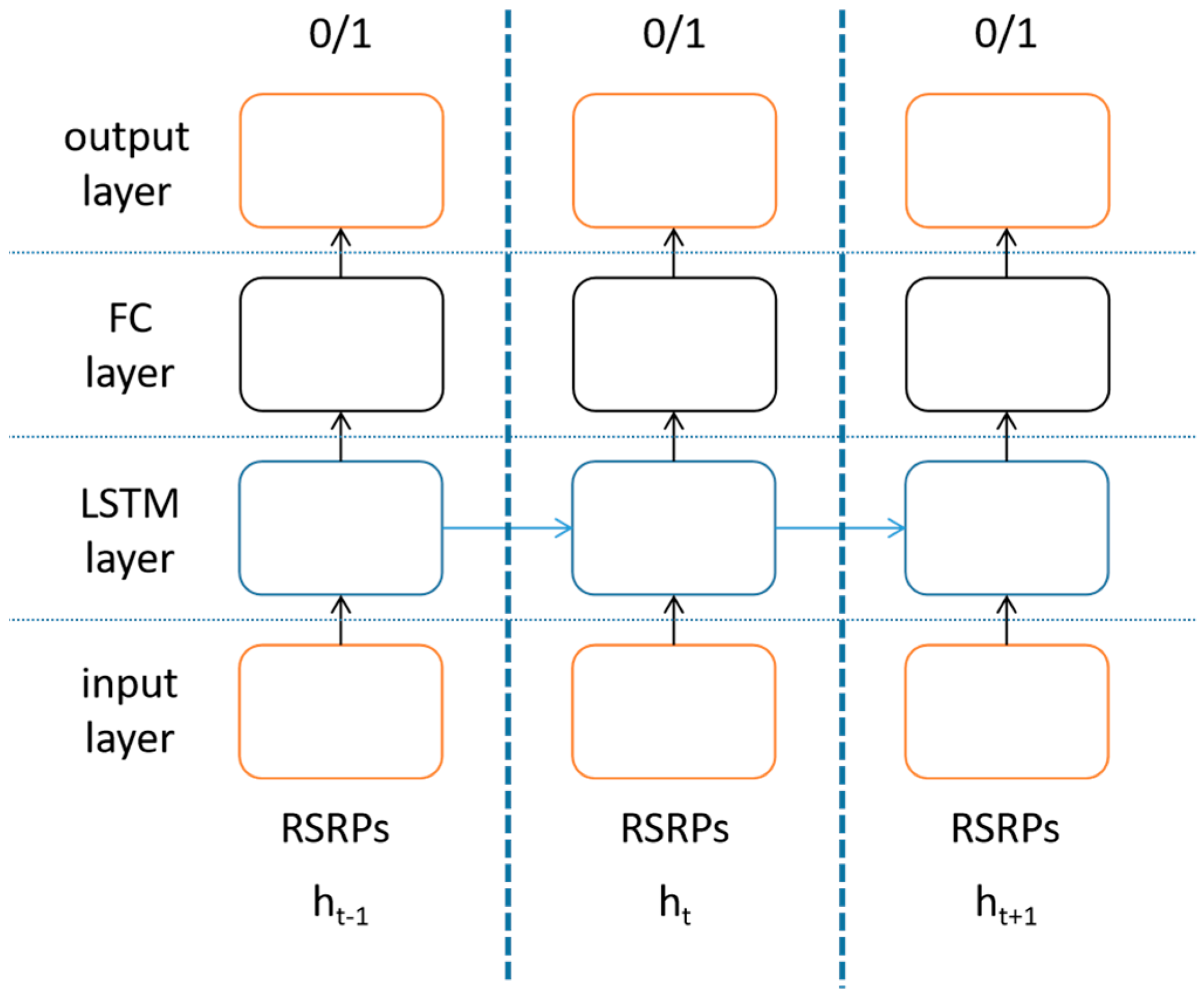
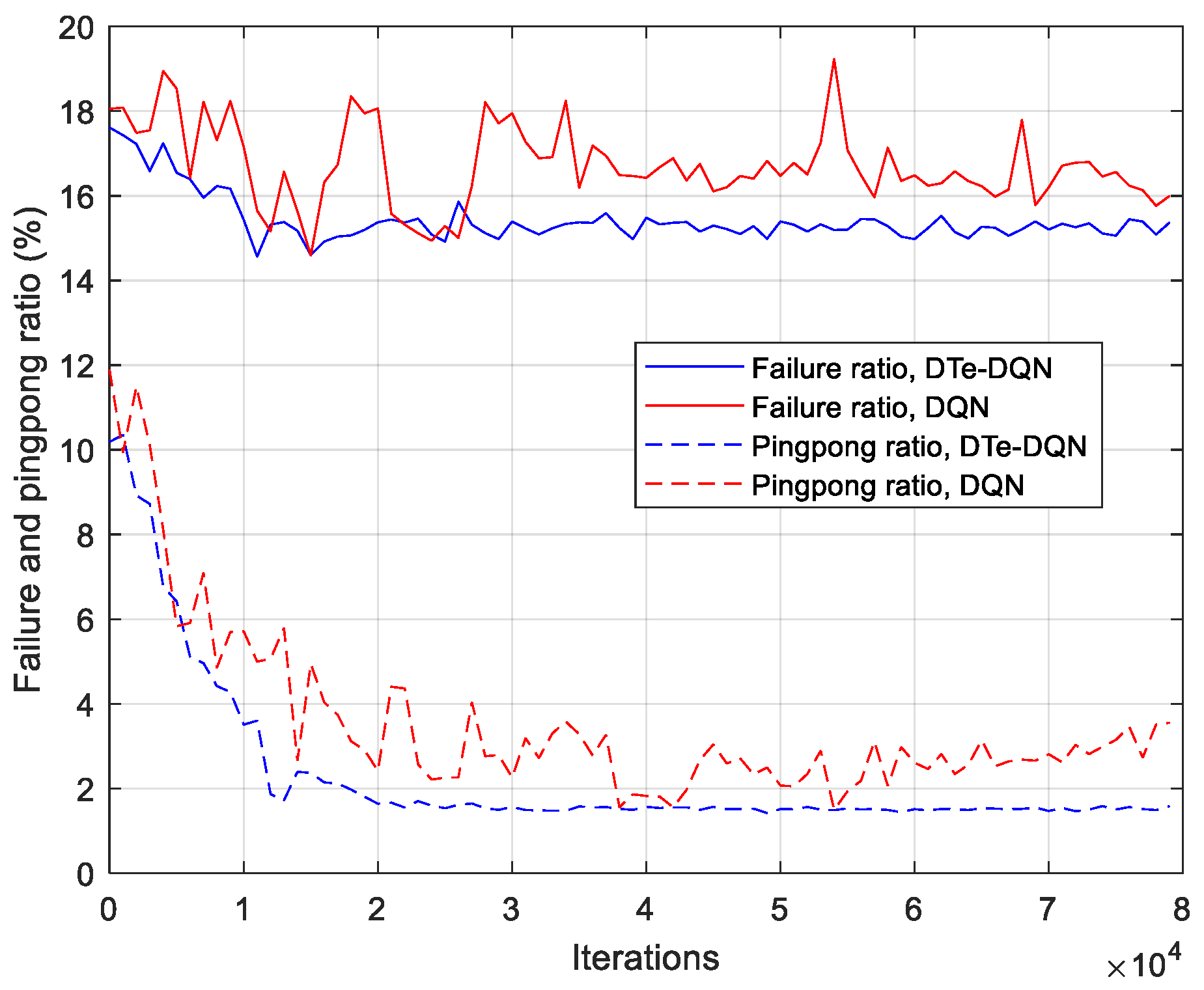
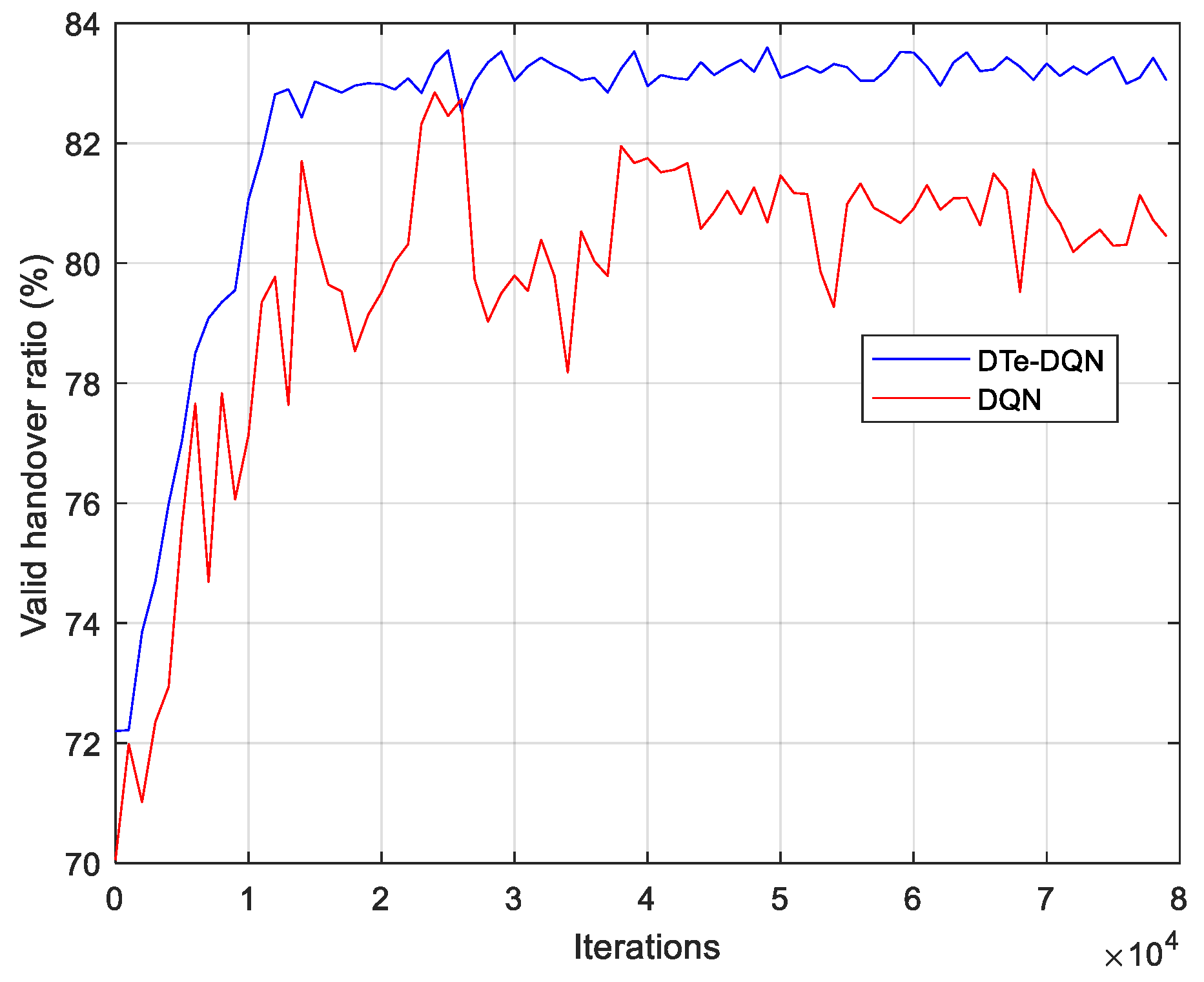
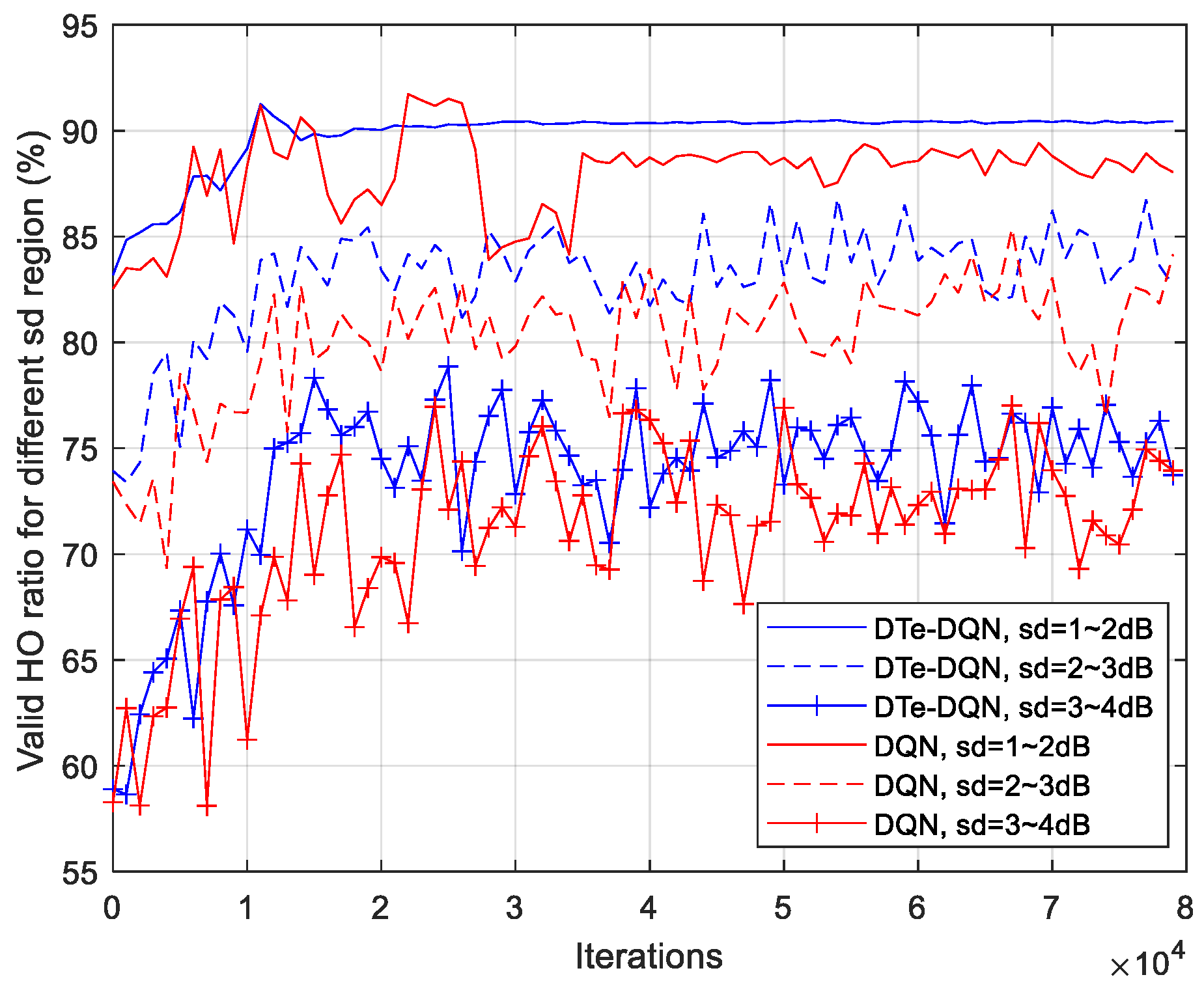
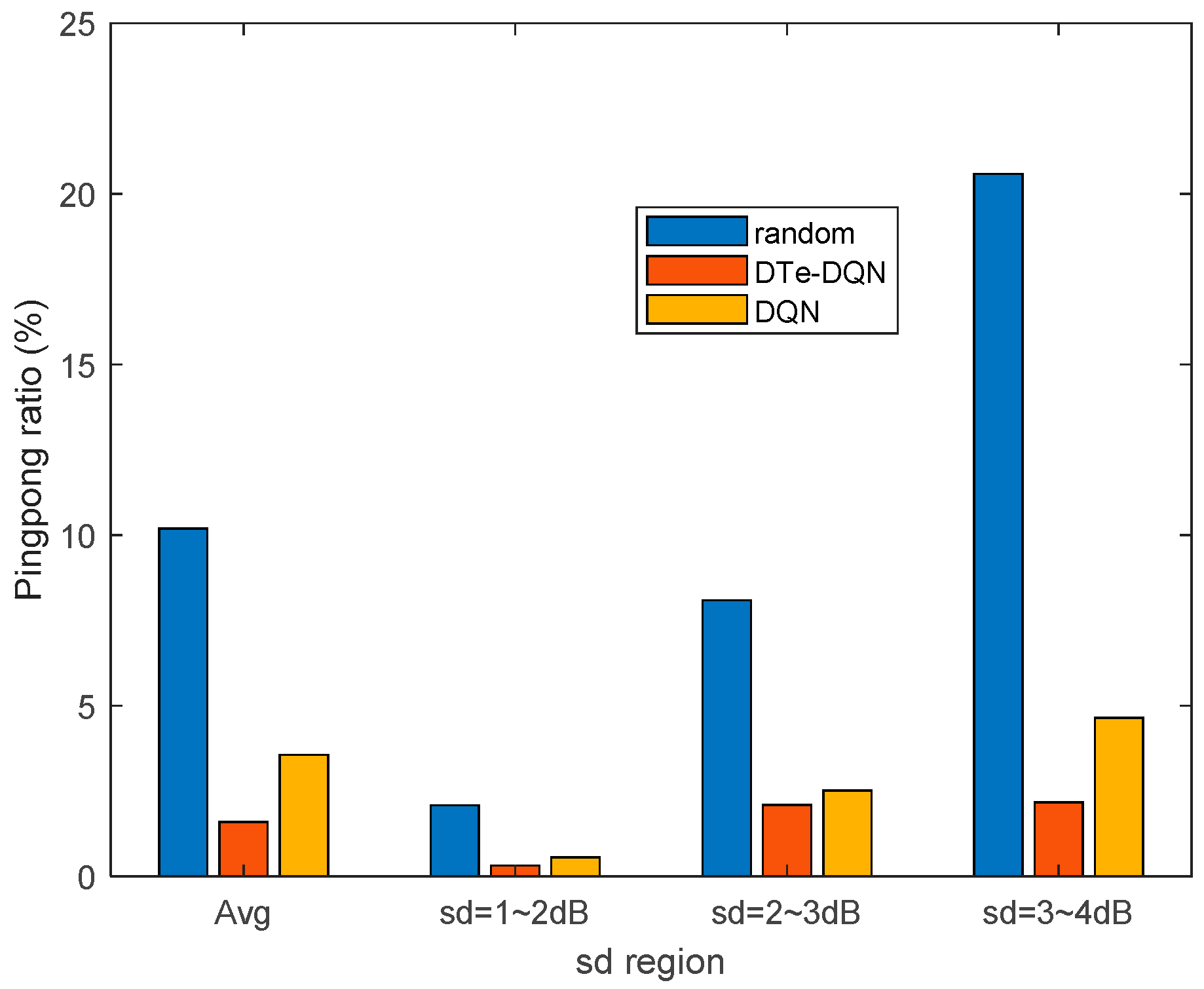
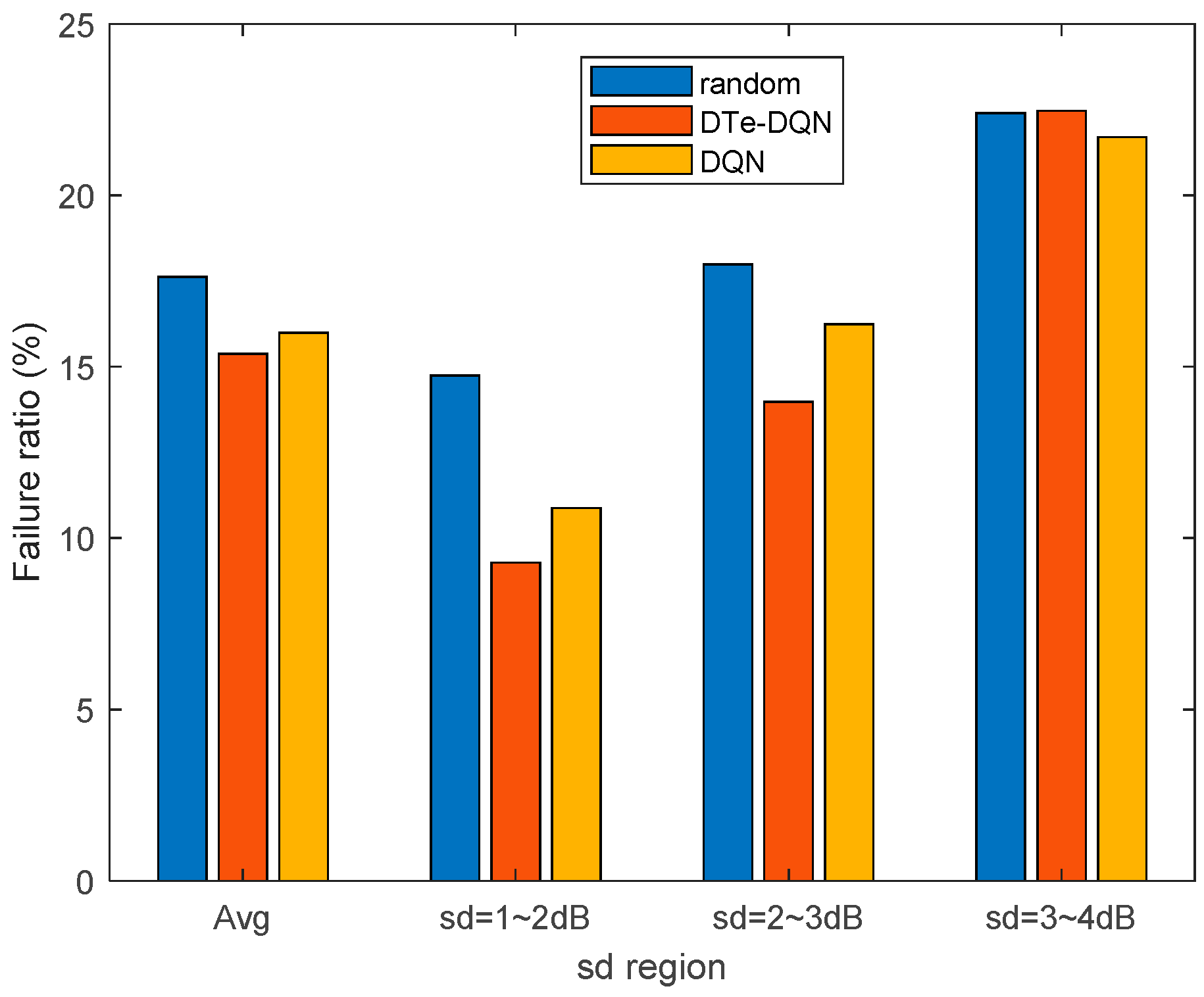
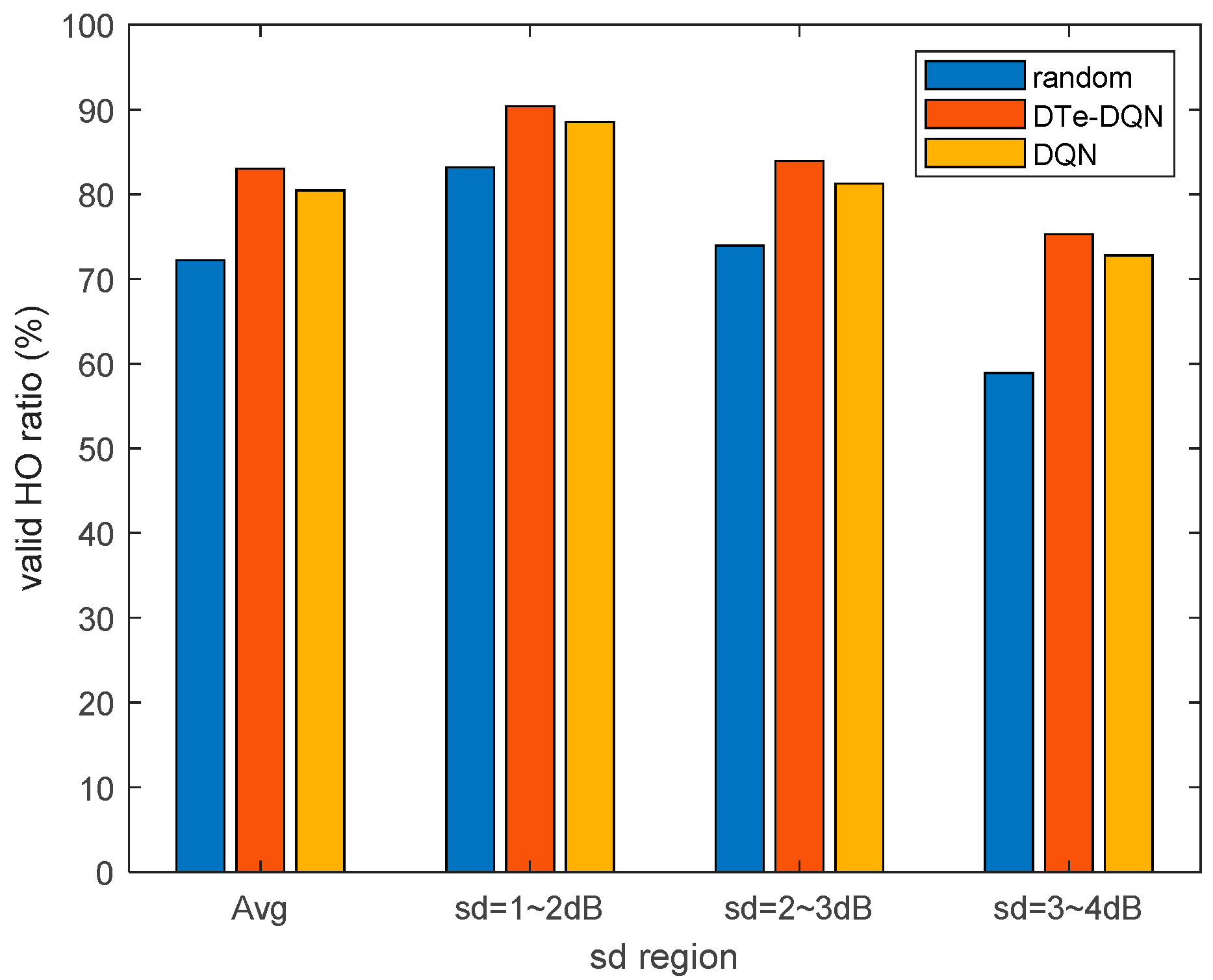
- Digital twin with LSTM network as the core is established. The RSRP temporal series between UE and each base station before triggering the handover event is used as LSTM input to predict whether the handover failure and ping-pong occur. Unbiased estimation of handover failure rate and ping-pong rate based on this method is proposed. With the aid of LSTM-based digital twin, the enhanced DQN achieves 2.7% higher effective handover rate than the ordinary DQN, and 10.9% higher than random parameter strategy.
2. System Model and the Optimization Problem
3. Handover Parameter Decision DQN Based on Signal Fading
| Algorithm 1: DQN Algorithm |
| Initialize Q-network; Initialize ; for (i = 1; i < ; i++) do Update standard deviation of signal strength sd; if () do ; end if if () do Select an action randomly; else do Predict an action with Q-network forward propagation; end if Set A3 parameters by the selected/predicted action; Collect HO failure rate pfailure and HO pingpong rate ppingpong; Calculate reward r as in (9); Update Q-network with loss calculated as in (10); end for |
4. Enhanced DQN Based on Digital Twin
4.1. Digital Twin Enhancement Mechanism
| Algorithm 2: DTe-DQN Algorithm |
| Initialize Q-network; Initialize ; for (i = 1; i ; i++) do Update standard deviation of signal strength sd; if () do ; end if if () do Select an action randomly; else do Predict an action with the Q-network forward propagation; end if Set A3 parameters by the selected/predicted action; Update digital twin A3 parameter set Collect HO failure rate pfailure and HO pingpong rate ppingpong; Calculate reward r as in (9); Update Q-network as in (10); for (j = 1; j ; j++) do Collect RSRP sequential values triggered by A3 parameter ; Predict HO failure rate pfailure and HO pingpong rate ppingpong via LSTM-based digital twin; Calculate reward r as in (9); Update Q-network with loss calculated as in (10); end for end for |
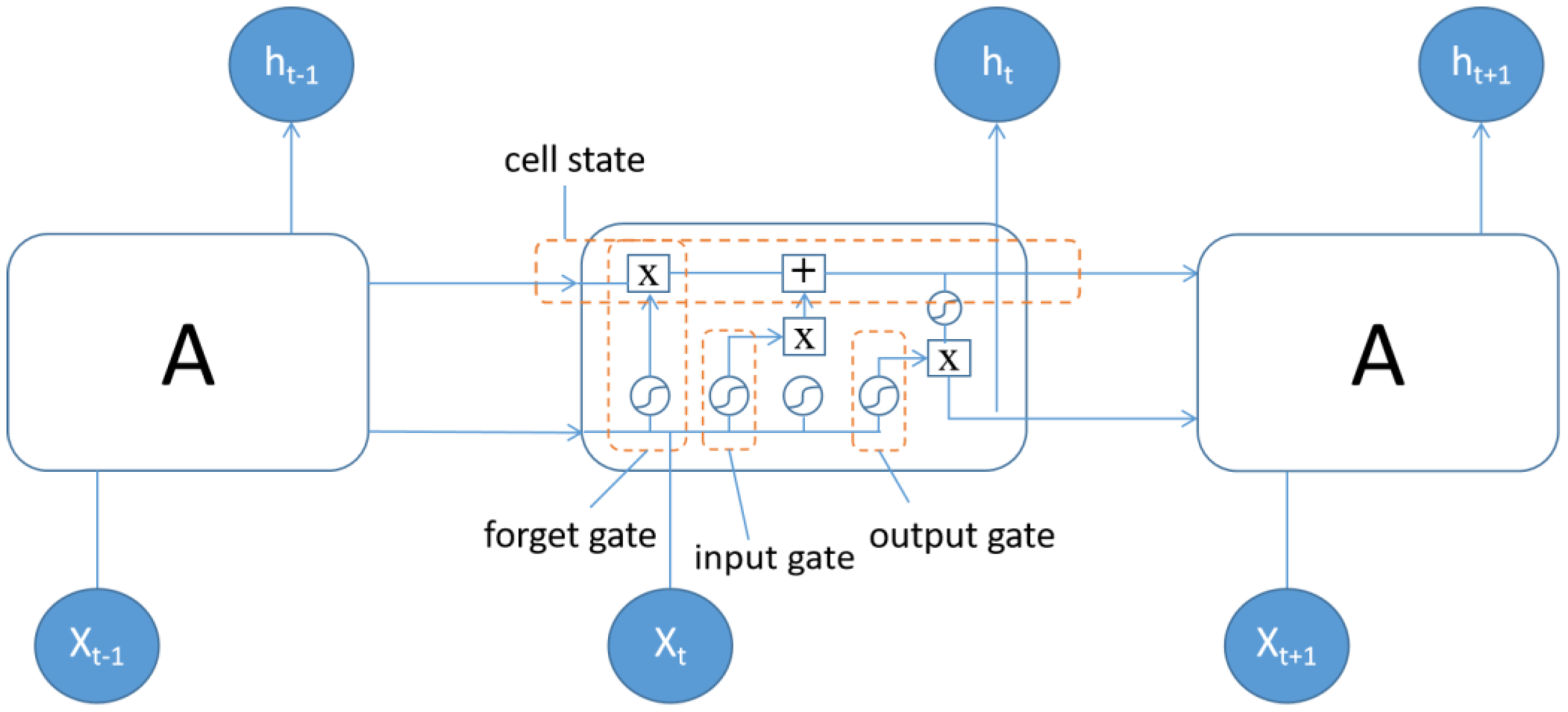
4.2. Digital Twin Based on LSTM
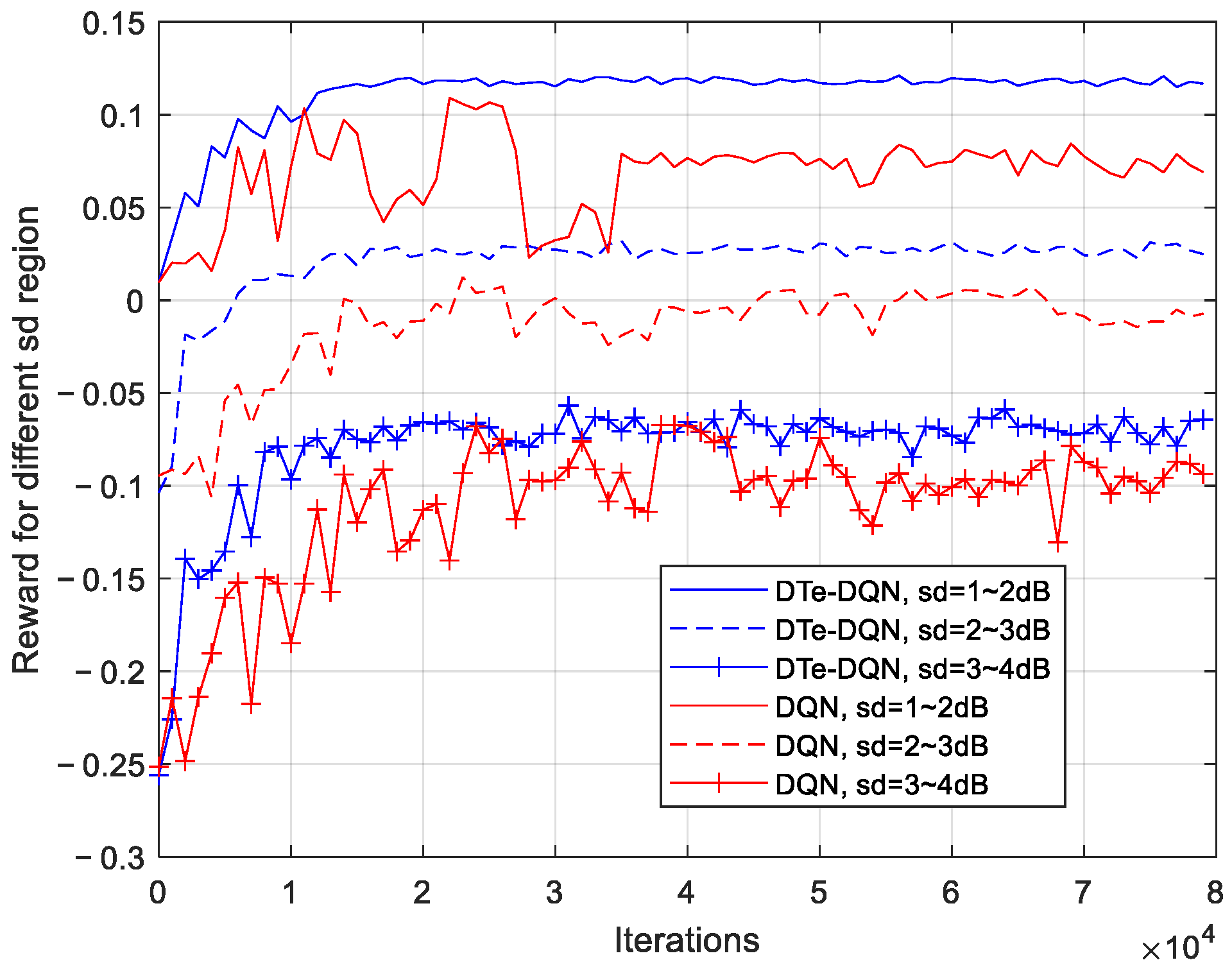
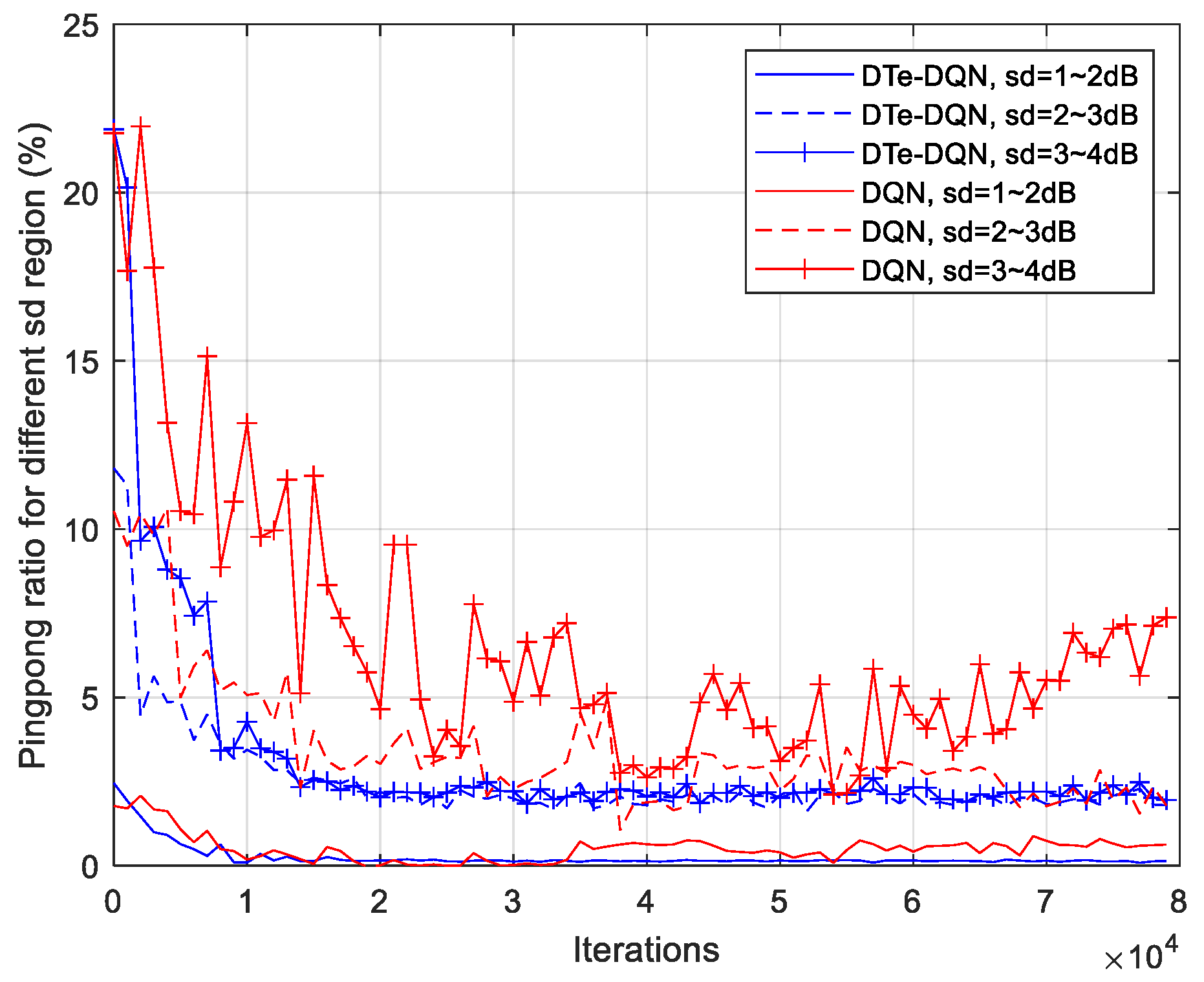
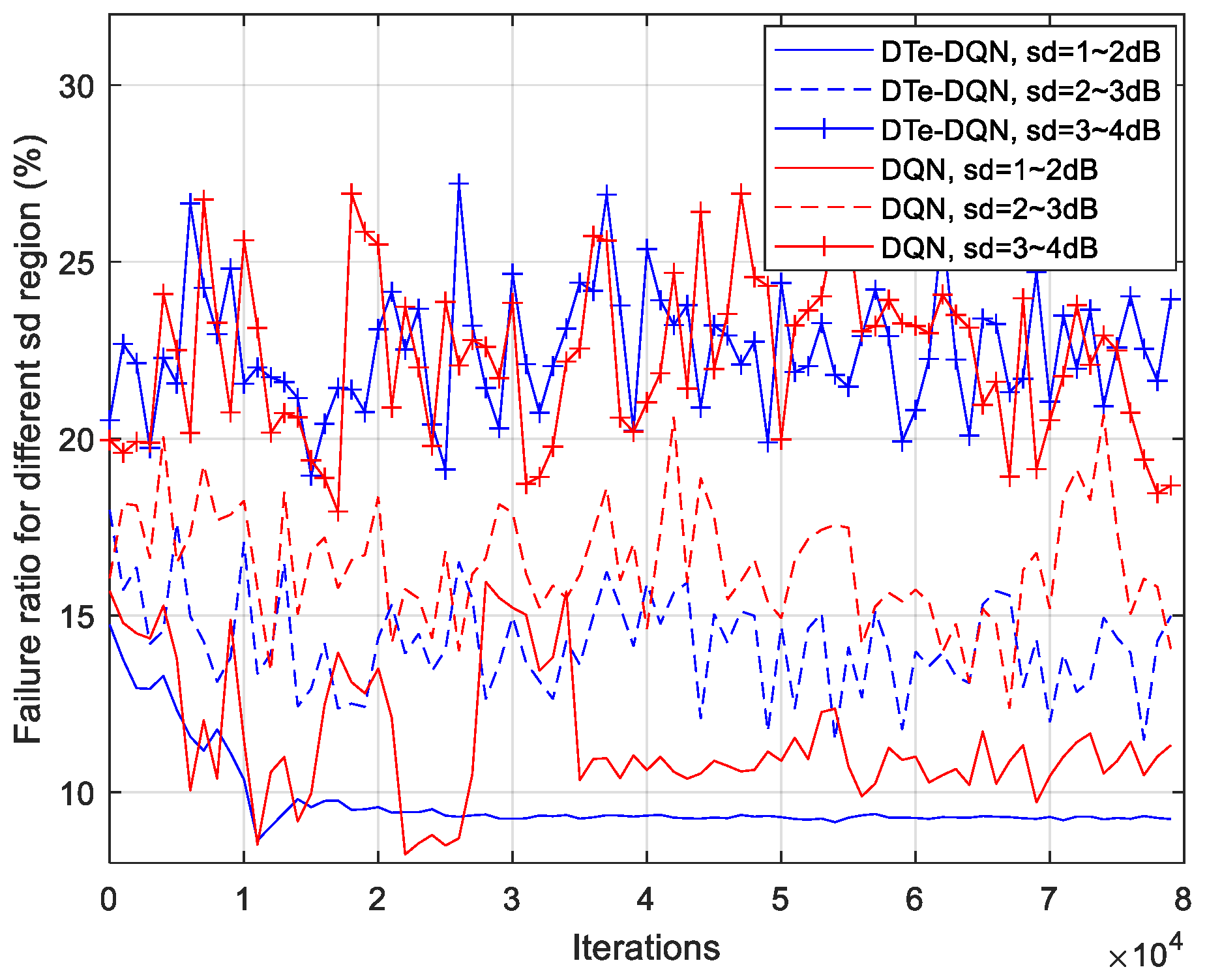
5. Experiment Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, T.; Bang, I.; Dan, K.S. Design criteria on a mmWave-based small cell with directional antennas. In Proceedings of the IEEE 25th Annual International Symposium on Personal, Indoor, and Mobile Radio Communication, Washington, DC, USA, 2–5 September 2014. [Google Scholar]
- Hao, P.; Yan, X.; Ruyue, Y.N.; Yuan, Y. Ultra Dense Network: Challenges, Enabling Technologies and New Trends. China Commun. 2016, 13, 30–40. [Google Scholar] [CrossRef]
- Sun, K.; Yu, J.; Huang, W.; Zhang, H.; Leung, V.C.M. A Multi-Attribute Handover Algorithm for QoS Enhancement in Ultra Dense Network. IEEE Trans. Veh. Technol. 2021, 70, 4557–4568. [Google Scholar] [CrossRef]
- Li, Q.; Xu, Y.; Tian, X. Overview of CoMP Clustering in UDN. Oalib 2018, 5, 4557–4568. [Google Scholar] [CrossRef]
- Kanwal, K.; Safdar, G.A. Energy Efficiency and Superlative TTT for Equitable RLF and Ping Pong in LTE Networks. Mob. Netw. 2018, 23, 1682–1692. [Google Scholar] [CrossRef]
- Bilen, T.; Canberk, B.; Chowdhury, K.R. Handover Management in Software-Defined Ultra-Dense 5G Networks. IEEE Netw. 2017, 31, 49–55. [Google Scholar] [CrossRef]
- Wu, M.; Huang, W.; Sun, K.; Zhang, H. A DQN-Based Handover Management for SDN-Enabled Ultra-Dense Networks. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), Victoria, BC, Canada, 4–7 October 2020. [Google Scholar]
- Lu, Y.; Zhang, C.; Chen, D.; Zhang, W.; Xiong, K. Handover Enhancement in High-Speed Railway 5G Networks: A LSTM-based Prediction Method. In Proceedings of the 2022 13th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 18–23 September 2022. [Google Scholar]
- Hasan, M.M.; Kwon, S.; Oh, S. Frequent-Handover Mitigation in Ultra-Dense Heterogeneous Networks. IEEE Trans. Veh. Technol. 2019, 68, 1035–1040. [Google Scholar] [CrossRef]
- Muñoz, P.; Barco, R.; de la Bandera, I. On the Potential of Handover Parameter Optimization for Self-Organizing Networks. IEEE Trans. Veh. Technol. 2013, 62, 1895–1905. [Google Scholar] [CrossRef]
- Kitagawa, K.; Komine, T.; Yamamoto, T.; Konishi, S. A handover optimization algorithm with mobility robustness for LTE systems. In Proceedings of the 2011 IEEE 22nd International Symposium on Personal, Indoor and Mobile Radio Communications, Toronto, ON, Canada, 11–14 September 2011. [Google Scholar]
- Achhab, T.A.; Abboud, F.; Assalem, A. A Robust Self-Optimization Algorithm Based on Idiosyncratic Adaptation of Handover Parameters for Mobility Management in LTE-A Heterogeneous Networks. IEEE Access 2021, 9, 154237–154264. [Google Scholar] [CrossRef]
- Saad, W.; Shayea, I.; Hamza, B.; Mohamad, H.; Daradkeh, Y.; Jabbar, W. Handover Parameters Optimisation Techniques in 5G Networks. Sensors 2021, 21, 5202. [Google Scholar] [CrossRef]
- Abdelmohsen, A.; Abdelwahab, M.; Adel, M.; Darweesh, M.S.; Mostafa, H. LTE Handover Parameters Optimization Using Q-Learning Technique. In Proceedings of the 2018 IEEE 61st International Midwest Symposium on Circuits and Systems (MWSCAS), Windsor, ON, Canada, 5–8 August 2018. [Google Scholar]
- Wu, C.; Cai, X.; Sheng, J.; Tang, Z.; Ai, B.; Wang, Y. Parameter Adaptation and Situation Awareness of LTE-R Handover for High-Speed Railway Communication. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1767–1781. [Google Scholar] [CrossRef]
- Shayea, I.; Ergen, M.; Azizan, A.; Ismail, M.; Daradkeh, Y.I. Individualistic Dynamic Handover Parameter Self-Optimization Algorithm for 5G Networks Based on Automatic Weight Function. IEEE Access 2020, 8, 214392–214412. [Google Scholar] [CrossRef]
- Huang, W.; Wu, M.; Yang, Z.; Sun, K.; Zhang, H.; Nallanathan, A. Self-Adapting Handover Parameters Optimization for SDN-Enabled UDN. IEEE Trans. Wirel. Commun. 2022, 21, 6434–6447. [Google Scholar] [CrossRef]
- Technical Specifification Group Radio Access Network; Evolved Universal Terrestrial Radio Access (E-UTRA); Radio Resource Control (RRC); Protocol Specifification (R13), 3GPP, Document 36.331 (V13.7.1). Available online: https://www.3gpp.org/ftp/Specs/archive/36_series/36.331 (accessed on 1 February 2023).
- Park, H.-S.; Lee, Y.; Kim, T.-J.; Kim, B.-C.; Lee, J.-Y. Handover Mechanism in NR for Ultra-Reliable Low-Latency Communications. IEEE Netw. 2018, 32, 41–47. [Google Scholar] [CrossRef]
- Dassanayake, P. Spatial correlation of shadow fading and its impact on handover algorithm parameter settings. In Proceedings of the IEEE Singapore International Conference on Networks and International Conference on Information Engineering ‘95, Singapore, 3–7 July 1995. [Google Scholar]
- Vasudeva, K.; Simsek, M.; Lopez-Perez, D.; Guvenc, I. Analysis of Handover Failures in Heterogeneous Networks With Fading. IEEE Trans. Veh. Technol. 2017, 66, 6060–6074. [Google Scholar] [CrossRef]
- Zheng, H.; Rong, C.; Yujiao, C. Theoretical analysis of handover failure rate in heterogenous networks under random shadowed model. In Proceedings of the 11th International Conference on Wireless Communications, Networking and Mobile Computing (WiCOM 2015), Shanghai, China, 21–23 September 2015. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. Comput. Sci. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mihai, S.; Yaqoob, M.; Hung, D.V.; Davis, W.; Towakel, P.; Raza, M.; Karamanoglu, M.; Barn, B.; Shetve, D.; Prasad, R.V.; et al. Digital Twins: A Survey on Enabling Technologies, Challenges, Trends and Future Prospects. IEEE Commun. Surv. Tutor. 2022, 24, 2255–2291. [Google Scholar] [CrossRef]
- Nguyen, H.X.; Trestian, R.; To, D.; Tatipamula, M. Digital Twin for 5G and Beyond. IEEE Commun. Mag. 2021, 59, 10–15. [Google Scholar] [CrossRef]
- Kuruvatti, N.P.; Habibi, M.A.; Partani, S.; Han, B.; Fellan, A.; Schotten, H.D. Empowering 6G Communication Systems With Digital Twin Technology: A Comprehensive Survey. IEEE Access 2022, 10, 112158–112186. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Feng, T.; Yang, C.; Leng, C.; Jiao, L.; Zhu, X.; Cao, L.; Li, R. HMM-LSTM for Proactive Traffic Prediction in 6G Wireless Networks. In Proceedings of the 2021 IEEE 21st International Conference on Communication Technology (ICCT), Tianjin, China, 13–16 October 2021. [Google Scholar]
- Ding, G.; Yuan, J.; Bao, J.; Yu, G. LSTM-Based Active User Number Estimation and Prediction for Cellular Systems. IEEE Wirel. Commun. Lett. 2020, 9, 1258–1262. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Configurations |
|---|---|
| 80,000 | |
| 500 | |
| 0.9 | |
| Learning rate decay | Exponential decay |
| Optimizer | Adam |
| Activation | ReLu |
| Initial learning rate | 0.001 |
| Inter-site distance | 50 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Xiang, T.; Wang, Y.; Ruan, H.; Zhang, X. A Reinforcement Learning Handover Parameter Adaptation Method Based on LSTM-Aided Digital Twin for UDN. Sensors 2023, 23, 2191. https://doi.org/10.3390/s23042191
He J, Xiang T, Wang Y, Ruan H, Zhang X. A Reinforcement Learning Handover Parameter Adaptation Method Based on LSTM-Aided Digital Twin for UDN. Sensors. 2023; 23(4):2191. https://doi.org/10.3390/s23042191
Chicago/Turabian StyleHe, Jiao, Tianqi Xiang, Yixin Wang, Huiyuan Ruan, and Xin Zhang. 2023. "A Reinforcement Learning Handover Parameter Adaptation Method Based on LSTM-Aided Digital Twin for UDN" Sensors 23, no. 4: 2191. https://doi.org/10.3390/s23042191
APA StyleHe, J., Xiang, T., Wang, Y., Ruan, H., & Zhang, X. (2023). A Reinforcement Learning Handover Parameter Adaptation Method Based on LSTM-Aided Digital Twin for UDN. Sensors, 23(4), 2191. https://doi.org/10.3390/s23042191