

Global Context Attention for Robust Visual Tracking

Abstract
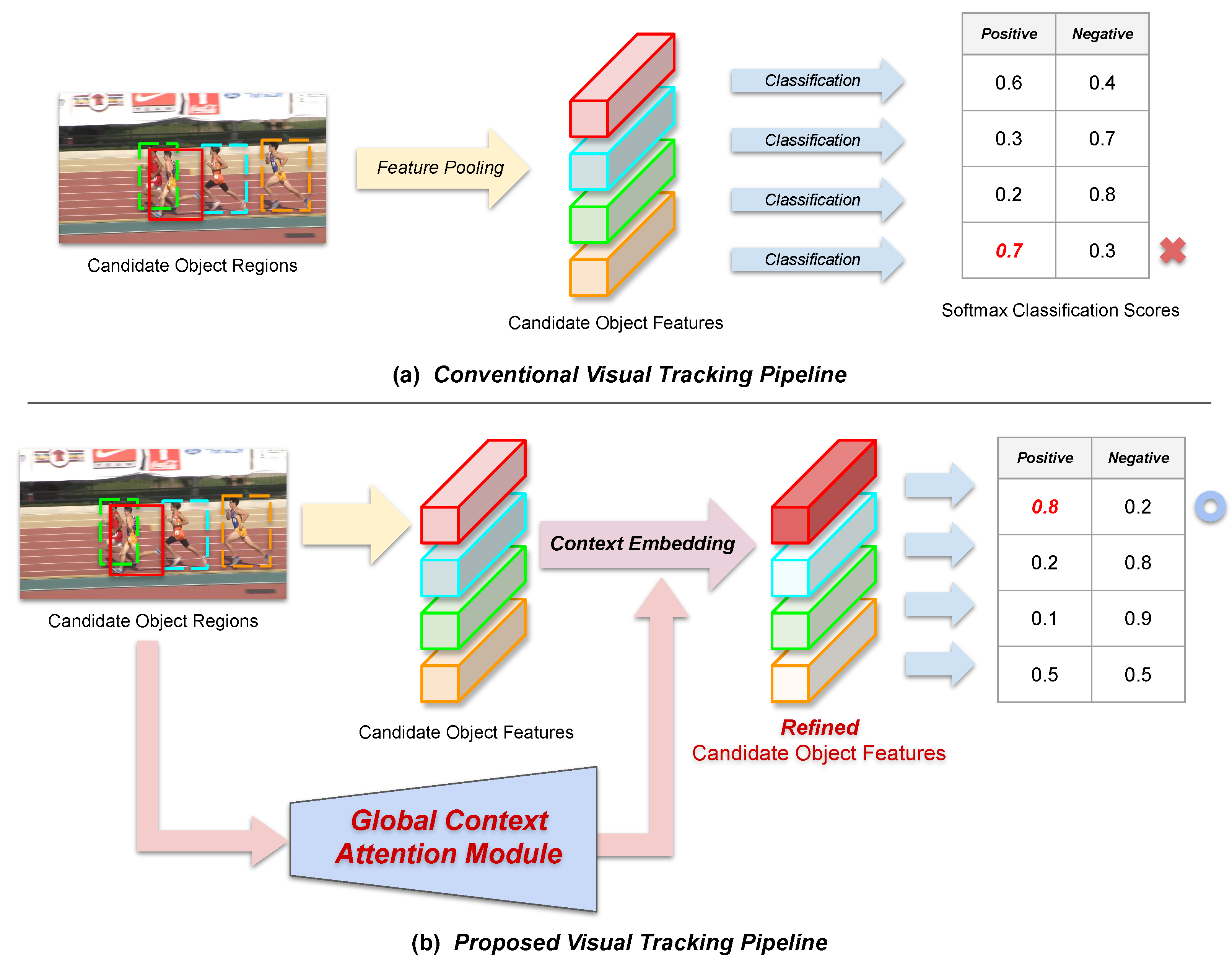
1. Introduction
2. Related Work
3. Proposed Method
3.1. Operation of the Baseline Tracker
3.2. Incorporating the Global Context Attention Module
| Algorithm 1: Visual tracking with global context attention |
 |
3.3. Training the Overall Tracking Framework
3.4. Implementation Details
3.4.1. Architectural Details and Parameter Settings
3.4.2. Training Data
3.4.3. Training Details and Hyperparameters
4. Experiments
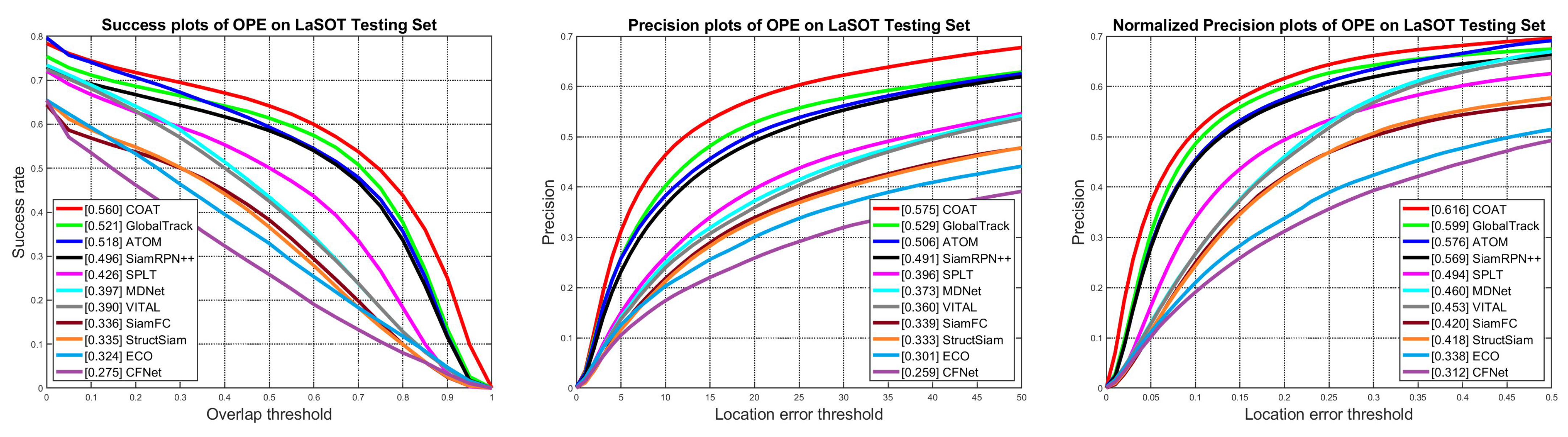
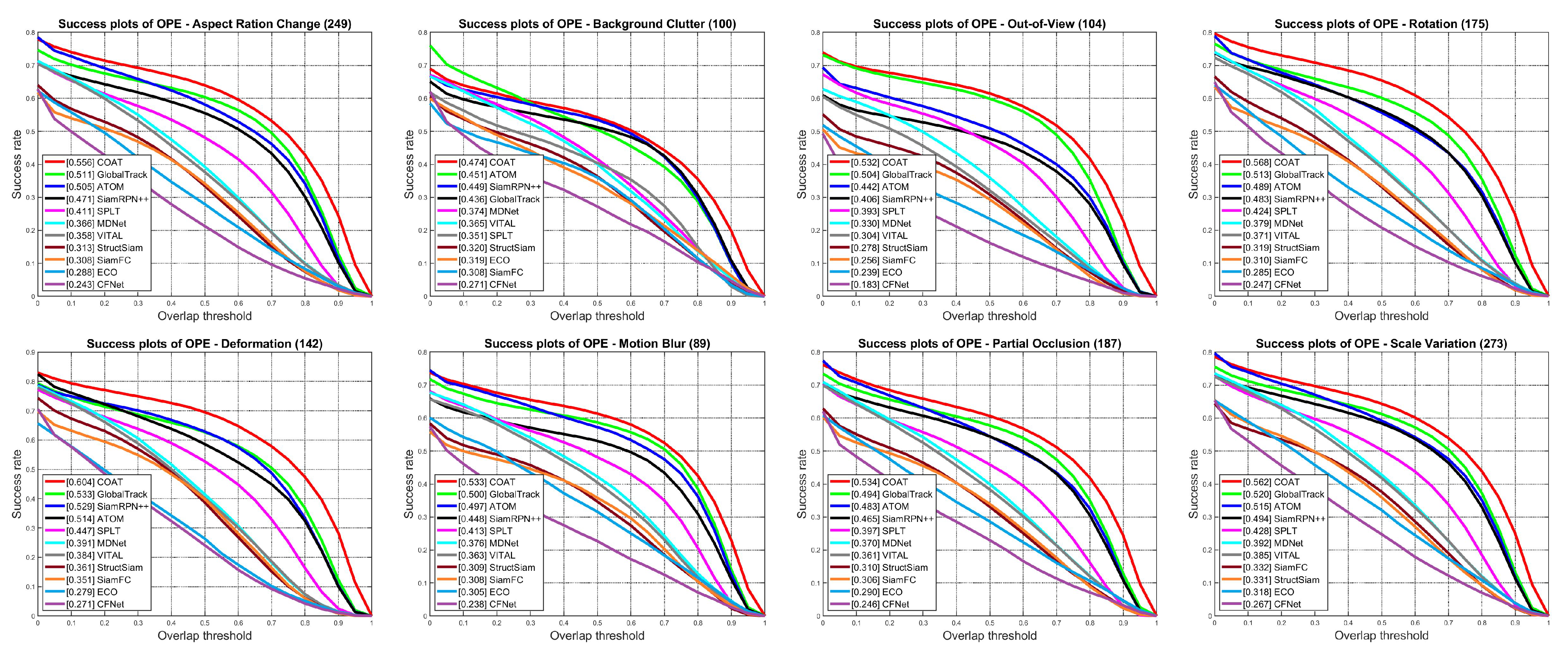
4.1. Quantitative Evaluation
4.2. Ablation Experiments
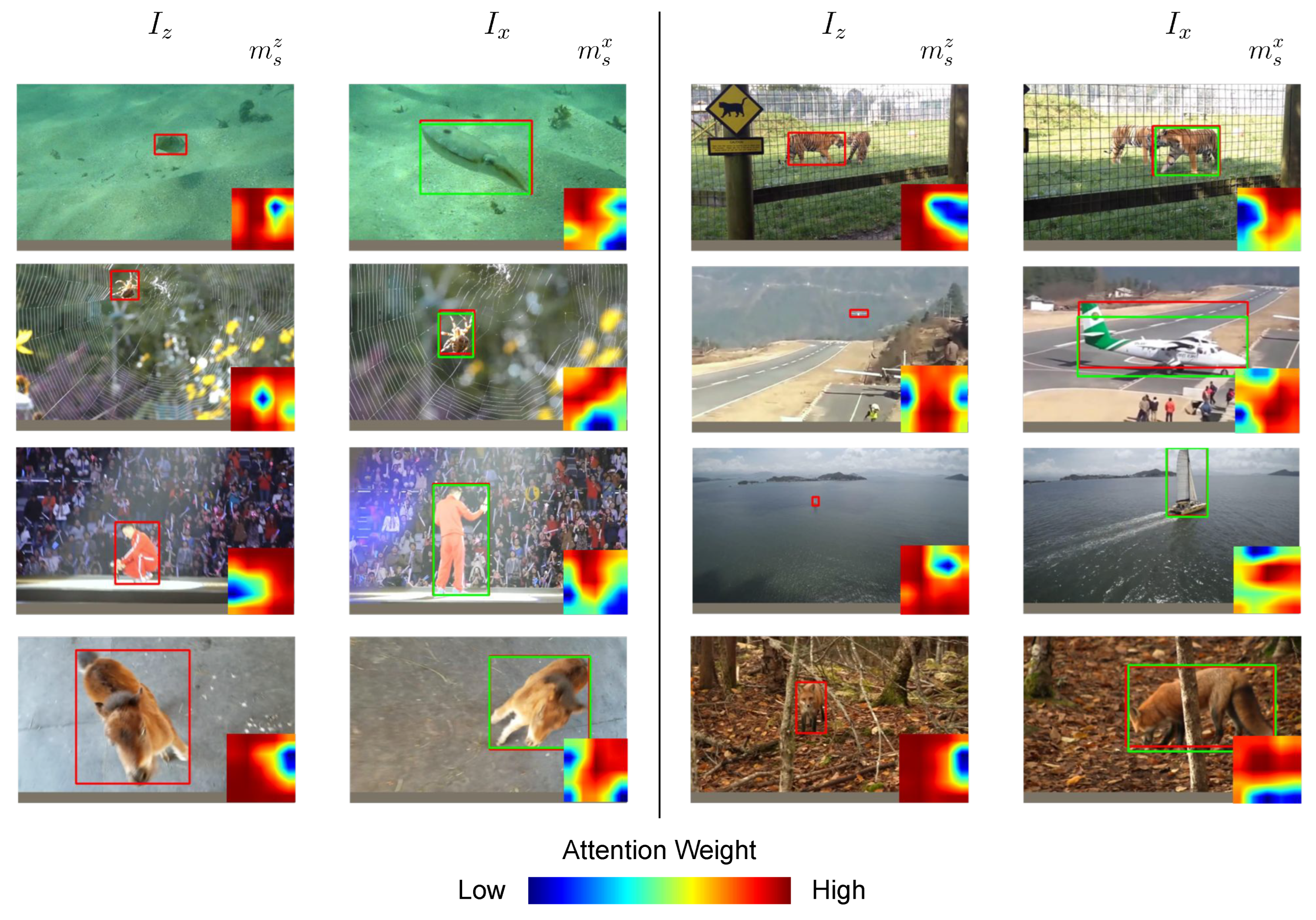
4.3. Qualitative Evaluation
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-Convolutional Siamese Networks for Object Tracking. arXiv 2016, arXiv:1606.09549. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the NIPS, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking With Siamese Region Proposal Network. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ma, H.; Acton, S.T.; Lin, Z. CAT: Centerness-Aware Anchor-Free Tracker. Sensors 2022, 22, 354. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese Box Adaptive Network for Visual Tracking. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. SiamFC++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE TPAMI 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Čehovin, L.; Leonardis, A.; Kristan, M. Visual object tracking performance measures revisited. IEEE TIP 2016, 25, 1261–1274. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.F.; Tao, R.; Vedaldi, A.; Smeulders, A.W.; Torr, P.H.; Gavves, E. Long-term tracking in the wild: A benchmark. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. GlobalTrack: A Simple and Strong Baseline for Long-term Tracking. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.H.; Leibe, B. Siam r-cnn: Visual tracking by re-detection. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, N.; Yeung, D.Y. Learning a deep compact image representation for visual tracking. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Nam, H.; Han, B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Jung, I.; Son, J.; Baek, M.; Han, B. Real-time mdnet. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bhat, G.; Johnander, J.; Danelljan, M.; Shahbaz Khan, F.; Felsberg, M. Unveiling the power of deep tracking. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xu, T.; Feng, Z.H.; Wu, X.J.; Kittler, J. Joint group feature selection and discriminative filter learning for robust visual object tracking. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-Aware Siamese Networks for Visual Object Tracking. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Cheng, L.; Zheng, X.; Zhao, M.; Dou, R.; Yu, S.; Wu, N.; Liu, L. SiamMixer: A Lightweight and Hardware-Friendly Visual Object-Tracking Network. Sensors 2022, 22, 1585. [Google Scholar] [CrossRef] [PubMed]
- Yan, B.; Peng, H.; Wu, K.; Wang, D.; Fu, J.; Lu, H. LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search. In Proceedings of the CVPR, Virtual, 19–25 June 2021; pp. 15180–15189. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the CVPR, Virtual, 19–25 June 2021; pp. 8126–8135. [Google Scholar]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning Spatio-Temporal Transformer for Visual Tracking. In Proceedings of the ICCV, Montreal, QC, Canada, 10–17 October 2021; pp. 10448–10457. [Google Scholar]
- Yu, B.; Tang, M.; Zheng, L.; Zhu, G.; Wang, J.; Feng, H.; Feng, X.; Lu, H. High-Performance Discriminative Tracking With Transformers. In Proceedings of the ICCV, Montreal, QC, Canada, 10–17 October 2021; pp. 9856–9865. [Google Scholar]
- Yang, C.; Zhang, X.; Song, Z. CTT: CNN Meets Transformer for Tracking. Sensors 2022, 22, 3210. [Google Scholar] [CrossRef] [PubMed]
- Mayer, C.; Danelljan, M.; Bhat, G.; Paul, M.; Paudel, D.P.; Yu, F.; Van Gool, L. Transforming Model Prediction for Tracking. In Proceedings of the CVPR, New Orleans, LA, USA, 19–24 June 2022; pp. 8731–8740. [Google Scholar]
- Zhou, X.; Yin, T.; Koltun, V.; Krähenbühl, P. Global Tracking Transformers. In Proceedings of the CVPR, New Orleans, LA, USA, 19–24 June 2022; pp. 8771–8780. [Google Scholar]
- Ma, F.; Shou, M.Z.; Zhu, L.; Fan, H.; Xu, Y.; Yang, Y.; Yan, Z. Unified Transformer Tracker for Object Tracking. In Proceedings of the CVPR, New Orleans, LA, USA, 19–24 June 2022; pp. 8781–8790. [Google Scholar]
- Blatter, P.; Kanakis, M.; Danelljan, M.; Van Gool, L. Efficient Visual Tracking With Exemplar Transformers. In Proceedings of the WACV, Waikoloa, HA, USA, 3–7 January 2023; pp. 1571–1581. [Google Scholar]
- Moudgil, A.; Gandhi, V. Long-term Visual Object Tracking Benchmark. In Proceedings of the ACCV, Perth, Australia, 2–6 December 2018. [Google Scholar]
- Dai, K.; Zhang, Y.; Wang, D.; Li, J.; Lu, H.; Yang, X. High-performance long-term tracking with meta-updater. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. IJCV 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. arXiv 2019, arXiv:1810.11981. [Google Scholar] [CrossRef] [PubMed]
- Real, E.; Shlens, J.; Mazzocchi, S.; Pan, X.; Vanhoucke, V. Youtube-boundingboxes: A large high-precision human-annotated data set for object detection in video. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yan, B.; Zhao, H.; Wang, D.; Lu, H.; Yang, X. ‘Skimming-Perusal’Tracking: A Framework for Real-Time and Robust Long-term Tracking. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware Anchor-free Tracking. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-To-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical convolutional features for visual tracking. In Proceedings of the ICCV, Santiago, Chile, 7–13 December 2015. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| COAT | GlobalTrack [16] | ATOM [50] | DiMP-50 [51] | SiamRPN++ [4] | DASiam [26] | SPLT [52] | MDNet [19] | Ocean [53] | SiamFC [3] | CFNet [54] | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | 0.556 | 0.521 | 0.518 | 0.569 | 0.496 | 0.448 | 0.426 | 0.397 | 0.560 | 0.336 | 0.275 |
| Precision | 0.575 | 0.529 | 0.506 | - | 0.491 | 0.427 | 0.396 | 0.373 | 0.566 | 0.339 | 0.259 |
| Norm. Precision | 0.616 | 0.599 | 0.576 | 0.650 | 0.569 | - | 0.494 | 0.460 | - | 0.420 | 0.312 |
| FPS | 57 | 6 | 30 | 43 | 35 | 110 | 25.7 | 0.9 | 25 | 58 | 43 |
| (%) | COAT | ATOM [50] | DiMP-50 [51] | SiamMask [11] | Ocean [53] | CFNet [54] | SiamFC [3] | GOTURN [55] | CCOT [22] | ECO [23] | CF2 [56] | MDNet [19] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 64.3 | 63.4 | 71.7 | 58.7 | 72.1 | 40.4 | 35.3 | 37.5 | 32.8 | 30.9 | 29.7 | 30.3 | |
| 49.1 | 40.2 | 49.2 | 36.6 | - | 14.4 | 9.8 | 12.4 | 10.7 | 11.1 | 8.8 | 9.9 | |
| 57.2 | 55.6 | 61.1 | 51.4 | 61.1 | 37.4 | 34.8 | 34.7 | 32.5 | 31.6 | 31.5 | 29.9 |
| COAT | COAT w/o GCAM | GlobalTrack [16] | |
|---|---|---|---|
| AUC | 0.556 | 0.532 | 0.521 |
| Precision | 0.575 | 0.541 | 0.529 |
| Norm. Precision | 0.616 | 0.605 | 0.599 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J. Global Context Attention for Robust Visual Tracking. Sensors 2023, 23, 2695. https://doi.org/10.3390/s23052695
Choi J. Global Context Attention for Robust Visual Tracking. Sensors. 2023; 23(5):2695. https://doi.org/10.3390/s23052695
Chicago/Turabian StyleChoi, Janghoon. 2023. "Global Context Attention for Robust Visual Tracking" Sensors 23, no. 5: 2695. https://doi.org/10.3390/s23052695
APA StyleChoi, J. (2023). Global Context Attention for Robust Visual Tracking. Sensors, 23(5), 2695. https://doi.org/10.3390/s23052695