
Learning-Based Motion-Intention Prediction for End-Point Control of Upper-Limb-Assistive Robots

 , , ,
, , , 
Abstract
:1. Introduction
2. Background
2.1. Control Based on Physiological Signals
2.2. IMU Control Interfaces
2.3. Multi-Modal Sensing Interfaces
3. Methods
3.1. Participants
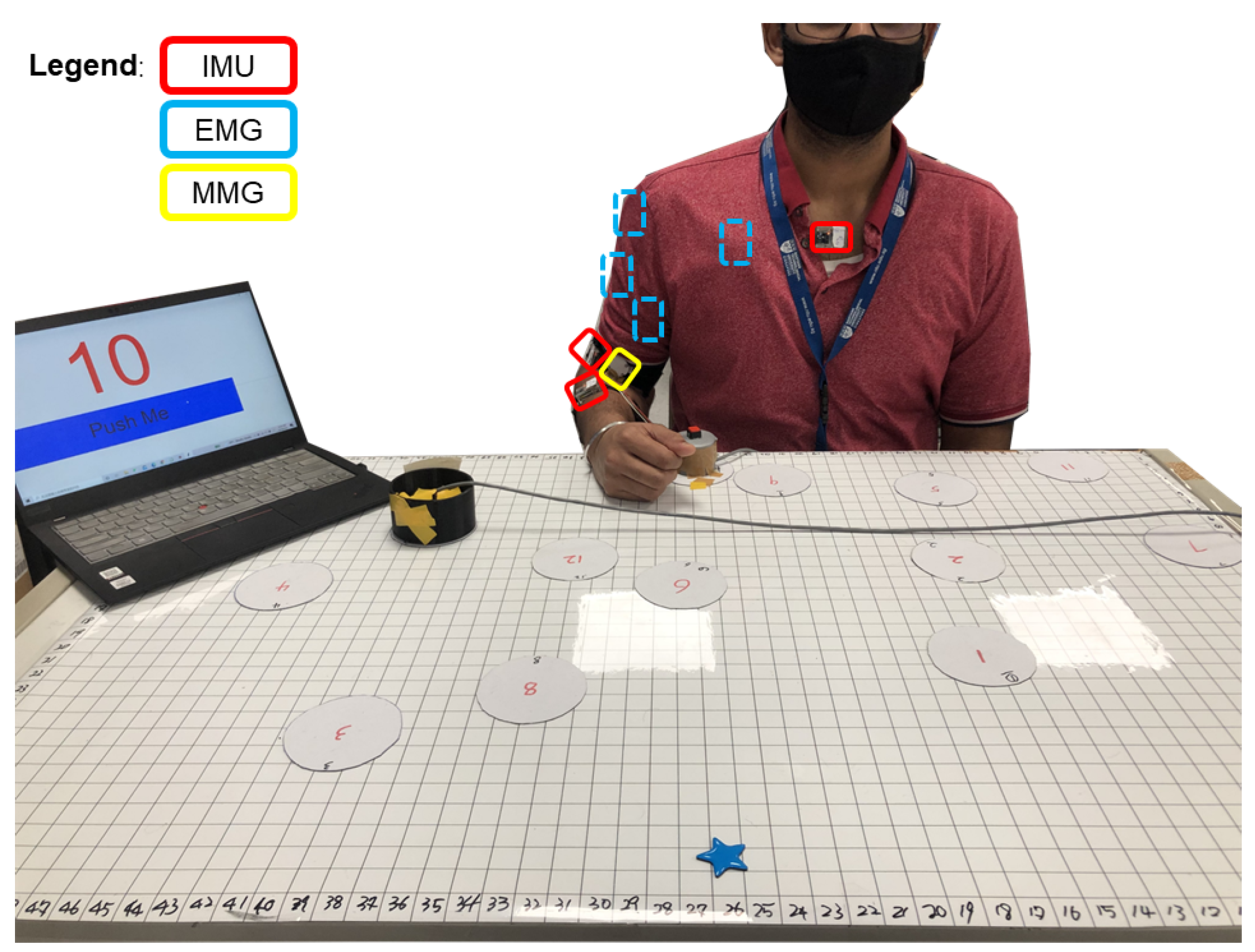
3.2. Experimental Setup and Protocol
3.3. Data Collection
3.4. Data Processing
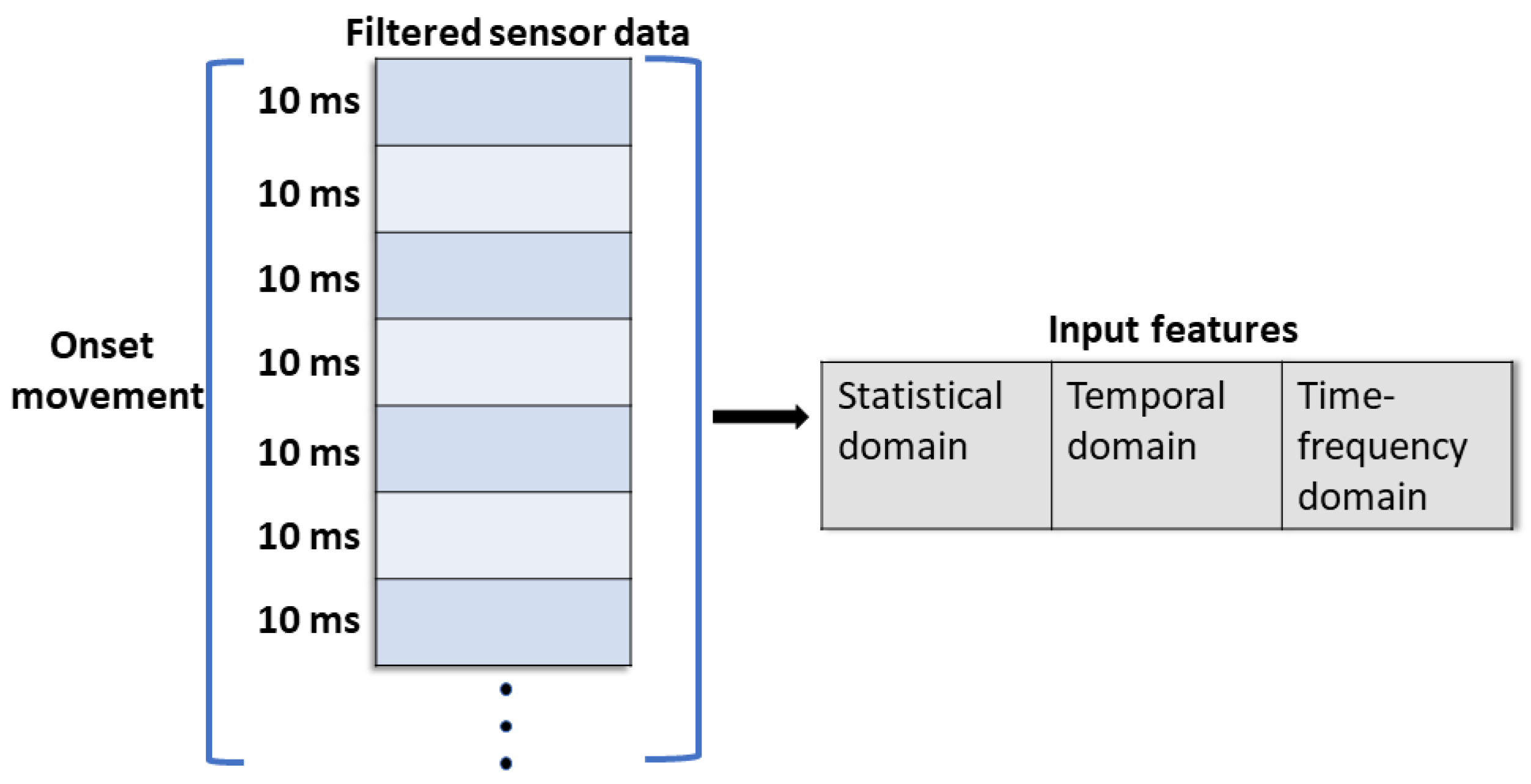
3.4.1. Segmentation
3.4.2. Feature Extraction
3.4.3. Standardization
3.5. Models
3.5.1. Tree-Based Models
3.5.2. Support Vector Regression
3.5.3. Feedforward Neural Networks
3.5.4. Recurrent Neural Networks
3.6. Output
3.7. Cross-Validation
3.8. Evaluation Metric
4. Results
4.1. Reaching Task
4.2. Placing Task
5. Discussion
6. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADL | Activities of daily living |
| AD | Anterior Deltoid |
| BB | Biceps Brachii |
| EEG | Electroencefalography |
| sEMG | Surface Electromyography |
| HMI | Human–machine interface |
| IMU | Inertial measurement unit |
| MAE | Mean absolute error |
| RMS | Root mean square |
| RMSE | Root mean square error |
| VAR | Variance |
| WL | Wavelength |
| OTW | Onset motion time window |
| MI | Mutual information |
| MID | Motion intention detection |
| MLP | Multiple Layer Perceptron |
| RNN | Recurrent neural network |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| MMG | Mechanomyographic |
| PM | Pectoralis Major |
| SVR | Support Vector Regression |
| TB | Triceps Brachii |
References
- Mayo, N.E.; Wood-Dauphinee, S.; Côte, R.; Durcan, L.; Carlton, J. Activity, participation, and quality of life 6 months poststroke. Arch. Phys. Med. Rehabil. 2002, 83, 1035–1042. [Google Scholar] [CrossRef] [PubMed]
- Bos, R.A.; Haarman, C.J.; Stortelder, T.; Nizamis, K.; Herder, J.L.; Stienen, A.H.; Plettenburg, D.H. A structured overview of trends and technologies used in dynamic hand orthoses. J. Neuroeng. Rehabil. 2016, 13, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Perry, J.C.; Rosen, J.; Burns, S. Upper-limb powered exoskeleton design. IEEE/ASME Trans. Mechatron. 2007, 12, 408–417. [Google Scholar] [CrossRef]
- Johannes, M.S.; Bigelow, J.D.; Burck, J.M.; Harshbarger, S.D.; Kozlowski, M.V.; Van Doren, T. An overview of the developmental process for the modular prosthetic limb. Johns Hopkins APL Tech. Dig. 2011, 30, 207–216. [Google Scholar]
- Fiorini, L.; De Mul, M.; Fabbricotti, I.; Limosani, R.; Vitanza, A.; D’Onofrio, G.; Tsui, M.; Sancarlo, D.; Giuliani, F.; Greco, A.; et al. Assistive robots to improve the independent living of older persons: Results from a needs study. Disabil. Rehabil. Assist. Technol. 2021, 16, 92–102. [Google Scholar] [CrossRef]
- Novak, D.; Riener, R. A survey of sensor fusion methods in wearable robotics. Robot. Auton. Syst. 2015, 73, 155–170. [Google Scholar] [CrossRef]
- Liu, H.; Gamboa, H.; Schultz, T. Sensor-Based Human Activity and Behavior Research: Where Advanced Sensing and Recognition Technologies Meet. Sensors 2023, 23, 125. [Google Scholar] [CrossRef] [PubMed]
- Ren, J.L.; Chien, Y.H.; Chia, E.Y.; Fu, L.C.; Lai, J.S. Deep learning based motion prediction for exoskeleton robot control in upper limb rehabilitation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5076–5082. [Google Scholar]
- Callens, T.; van der Have, T.; Van Rossom, S.; De Schutter, J.; Aertbeliën, E. A framework for recognition and prediction of human motions in human–robot collaboration using probabilistic motion models. IEEE Robot. Autom. Lett. 2020, 5, 5151–5158. [Google Scholar] [CrossRef]
- Krausz, N.E.; Lamotte, D.; Batzianoulis, I.; Hargrove, L.J.; Micera, S.; Billard, A. Intent prediction based on biomechanical coordination of EMG and vision-filtered gaze for end-point control of an arm prosthesis. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1471–1480. [Google Scholar] [CrossRef]
- Li, Z.; Wang, B.; Sun, F.; Yang, C.; Xie, Q.; Zhang, W. sEMG-based joint force control for an upper-limb power-assist exoskeleton robot. IEEE J. Biomed. Health Inform. 2013, 18, 1043–1050. [Google Scholar]
- Guo, W.; Sheng, X.; Liu, H.; Zhu, X. Mechanomyography assisted myoeletric sensing for upper-extremity prostheses: A hybrid approach. IEEE Sens. J. 2017, 17, 3100–3108. [Google Scholar] [CrossRef]
- Fougner, A.; Stavdahl, Ø.; Kyberd, P.J.; Losier, Y.G.; Parker, P.A. Control of upper limb prostheses: Terminology and proportional myoelectric control—A review. IEEE Trans. Neural Syst. Rehabil. Eng. 2012, 20, 663–677. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Islam, M.A.; Sundaraj, K.; Ahmad, R.B.; Ahamed, N.U. Mechanomyogram for muscle function assessment: A review. PLoS ONE 2013, 8, e58902. [Google Scholar] [CrossRef] [PubMed]
- Lenzi, T.; De Rossi, S.M.M.; Vitiello, N.; Carrozza, M.C. Intention-based EMG control for powered exoskeletons. IEEE Trans. Biomed. Eng. 2012, 59, 2180–2190. [Google Scholar] [CrossRef] [PubMed]
- Tigrini, A.; Pettinari, L.A.; Verdini, F.; Fioretti, S.; Mengarelli, A. Shoulder Motion Intention Detection Through Myoelectric Pattern Recognition. IEEE Sens. Lett. 2021, 5, 1–4. [Google Scholar] [CrossRef]
- Ding, Q.; Han, J.; Zhao, X. Continuous estimation of human multi-joint angles from sEMG using a state-space model. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 25, 1518–1528. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, Z.; Li, Z.; Yang, Z.; Dehghani-Sanij, A.A.; Xie, S. An EMG-driven musculoskeletal model for estimating continuous wrist motion. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 3113–3120. [Google Scholar] [CrossRef]
- Formstone, L.; Huo, W.; Wilson, S.; McGregor, A.; Bentley, P.; Vaidyanathan, R. Quantification of Motor Function Post-stroke using Novel Combination of Wearable Inertial and Mechanomyographic Sensors. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 1158–1167. [Google Scholar] [CrossRef]
- Wilson, S.; Eberle, H.; Hayashi, Y.; Madgwick, S.O.; McGregor, A.; Jing, X.; Vaidyanathan, R. Formulation of a new gradient descent MARG orientation algorithm: Case study on robot teleoperation. Mech. Syst. Signal Process. 2019, 130, 183–200. [Google Scholar] [CrossRef]
- Castillo, C.S.M.; Wilson, S.; Vaidyanathan, R.; Atashzar, S.F. Wearable MMG-Plus-One Armband: Evaluation of Normal Force on Mechanomyography (MMG) to Enhance Human–Machine Interfacing. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 29, 196–205. [Google Scholar] [CrossRef]
- Gardner, M.; Mancero Castillo, C.S.; Wilson, S.; Farina, D.; Burdet, E.; Khoo, B.C.; Atashzar, S.F.; Vaidyanathan, R. A multimodal intention detection sensor suite for shared autonomy of upper-limb robotic prostheses. Sensors 2020, 20, 6097. [Google Scholar] [CrossRef] [PubMed]
- Ai, Q.; Liu, Z.; Meng, W.; Liu, Q.; Xie, S.Q. Machine Learning in Robot Assisted Upper Limb Rehabilitation: A Focused Review. IEEE Trans. Cogn. Dev. Syst. 2021. [Google Scholar] [CrossRef]
- Van Ommeren, A.; Sawaryn, B.; Prange-Lasonder, G.; Buurke, J.; Rietman, J.; Veltink, P. Detection of the intention to grasp during reaching in stroke using inertial sensing. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 2128–2134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, Y.; He, Z.; Liu, Y.; Yang, R.; Zhang, X.; Cheng, G.; Yi, J.; Ferreira, J.P.; Liu, T. Real-time intended knee joint motion prediction by deep-recurrent neural networks. IEEE Sens. J. 2019, 19, 11503–11509. [Google Scholar] [CrossRef]
- Trick, S.; Koert, D.; Peters, J.; Rothkopf, C.A. Multimodal uncertainty reduction for intention recognition in human–robot interaction. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 7009–7016. [Google Scholar]
- Bao, T.; Xie, S.Q.; Yang, P.; Zhou, P.; Zhang, Z. Towards Robust, Adaptive and Reliable Upper-limb Motion Estimation Using Machine Learning and Deep Learning–A Survey in Myoelectric Control. IEEE J. Biomed. Health Inform. 2022, 26, 3822–3835. [Google Scholar] [CrossRef]
- Lalitharatne, T.D.; Teramoto, K.; Hayashi, Y.; Kiguchi, K. Towards hybrid EEG-EMG-based control approaches to be used in bio-robotics applications: Current status, challenges and future directions. Paladyn. J. Behav. Robot. 2013, 4, 147–154. [Google Scholar] [CrossRef]
- Leeb, R.; Sagha, H.; Chavarriaga, R.; del R Millán, J. A hybrid brain–computer interface based on the fusion of electroencephalographic and electromyographic activities. J. Neural Eng. 2011, 8, 025011. [Google Scholar] [CrossRef] [Green Version]
- Little, K.; K Pappachan, B.; Yang, S.; Noronha, B.; Campolo, D.; Accoto, D. Elbow Motion Trajectory Prediction Using a Multi-Modal Wearable System: A Comparative Analysis of Machine Learning Techniques. Sensors 2021, 21, 498. [Google Scholar] [CrossRef]
- Williams, H.E.; Shehata, A.W.; Dawson, M.R.; Scheme, E.; Hebert, J.S.; Pilarksi, P. Recurrent Convolutional Neural Networks as an Approach to Position-Aware Myoelectric Prosthesis Control. IEEE Trans. Biomed. Eng. 2022, 69, 2243–2255. [Google Scholar] [CrossRef]
- Siu, H.C.; Arenas, A.M.; Sun, T.; Stirling, L.A. Implementation of a surface electromyography-based upper extremity exoskeleton controller using learning from demonstration. Sensors 2018, 18, 467. [Google Scholar] [CrossRef] [Green Version]
- Hermens, H.J.; Freriks, B.; Disselhorst-Klug, C.; Rau, G. Development of recommendations for SEMG sensors and sensor placement procedures. J. Electromyogr. Kinesiol. 2000, 10, 361–374. [Google Scholar] [CrossRef] [PubMed]
- Posatskiy, A.; Chau, T. Design and evaluation of a novel microphone-based mechanomyography sensor with cylindrical and conical acoustic chambers. Med. Eng. Phys. 2012, 34, 1184–1190. [Google Scholar] [CrossRef] [PubMed]
- Russell, J.; Bergmann, J. A Systematic Literature Review of Intent Sensing for Control of Medical Devices. IEEE Trans. Med. Robot. Bionics 2021, 4, 118–129. [Google Scholar] [CrossRef]
- Barandas, M.; Folgado, D.; Fernandes, L.; Santos, S.; Abreu, M.; Bota, P.; Liu, H.; Schultz, T.; Gamboa, H. TSFEL: Time series feature extraction library. SoftwareX 2020, 11, 100456. [Google Scholar] [CrossRef]
- Bi, L.; Guan, C. A review on EMG-based motor intention prediction of continuous human upper limb motion for human–robot collaboration. Biomed. Signal Process. Control 2019, 51, 113–127. [Google Scholar] [CrossRef]
- Phinyomark, A.; Phukpattaranont, P.; Limsakul, C. Feature reduction and selection for EMG signal classification. Expert Syst. Appl. 2012, 39, 7420–7431. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Bruinsma, J.; Carloni, R. IMU-Based Deep Neural Networks: Prediction of Locomotor and Transition Intentions of an Osseointegrated Transfemoral Amputee. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 1079–1088. [Google Scholar] [CrossRef]
- Bragança, H.; Colonna, J.G.; Oliveira, H.A.; Souto, E. How validation methodology influences human activity recognition mobile systems. Sensors 2022, 22, 2360. [Google Scholar] [CrossRef]
- Tilley, A.R. Henry Dreyfuss Associates. The Measure of Man and Woman: Human Factors in Design; John Wiley & Sons: Hoboken, NJ, USA, 2001. [Google Scholar]
- Tealab, A. Time series forecasting using artificial neural networks methodologies: A systematic review. Future Comput. Inform. J. 2018, 3, 334–340. [Google Scholar] [CrossRef]
- Xue, T.; Liu, H. Hidden Markov Model and its application in human activity recognition and fall detection: A review. In Proceedings of the Communications, Signal Processing, and Systems: Proceedings of the 10th International Conference on Communications, Signal Processing, and Systems, Changbaishan, China, 24–25 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; Volume 1, pp. 863–869. [Google Scholar]
- Hartmann, Y.; Liu, H.; Schultz, T. Interactive and Interpretable Online Human Activity Recognition. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops), Pisa, Italy, 21–25 March 2022; pp. 109–111. [Google Scholar]
- Folgado, D.; Barandas, M.; Antunes, M.; Nunes, M.L.; Liu, H.; Hartmann, Y.; Schultz, T.; Gamboa, H. Tssearch: Time series subsequence search library. SoftwareX 2022, 18, 101049. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Distance [cm] | OTW [ms] | Model | |||||||
|---|---|---|---|---|---|---|---|---|---|
| SVR | DecisionTree | AdaBoost | ExtraTrees | MLP | RNN | GRU | LSTM | ||
| 50 | 3% | 28% | 57% | 5% | 14% | 80% | 80% | 81% | |
| 100 | 4% | 21% | 62% | 6% | 17% | 71% | 75% | 76% | |
| 150 | 4% | 29% | 65% | 7% | 18% | 75% | 75% | 75% | |
| 200 | 11% | 30% | 71% | 6% | 24% | 72% | 73% | 75% | |
| 50 | 7% | 31% | 61% | 16% | 38% | 80% | 81% | 81% | |
| 100 | 14% | 26% | 66% | 15% | 46% | 76% | 75% | 76% | |
| 150 | 21% | 34% | 71% | 20% | 44% | 75% | 75% | 76% | |
| 200 | 26% | 33% | 74% | 26% | 52% | 77% | 76% | 76% | |
| 50 | 14% | 34% | 64% | 30% | 59% | 81% | 82% | 82% | |
| 100 | 21% | 29% | 70% | 30% | 64% | 76% | 75% | 76% | |
| 150 | 32% | 38% | 72% | 31% | 67% | 76% | 77% | 78% | |
| 200 | 38% | 38% | 80% | 44% | 71% | 79% | 77% | 78% | |
| 50 | 20% | 42% | 71% | 42% | 76% | 81% | 82% | 84% | |
| 100 | 25% | 33% | 72% | 44% | 74% | 76% | 78% | 76% | |
| 150 | 44% | 46% | 77% | 51% | 77% | 80% | 80% | 79% | |
| 200 | 42% | 42% | 84% | 54% | 77% | 82% | 79% | 79% | |
| Error Distance [cm] | OTW [ms] | Model | |||||||
|---|---|---|---|---|---|---|---|---|---|
| SVR | DecisionTree | AdaBoost | ExtraTrees | MLP | RNN | GRU | LSTM | ||
| 50 | 2% | 23% | 48% | 4% | 8% | 80% | 80% | 80% | |
| 100 | 5% | 27% | 41% | 2% | 13% | 73% | 75% | 75% | |
| 150 | 4% | 16% | 38% | 1% | 8% | 74% | 60% | 75% | |
| 200 | 5% | 14% | 37% | 2% | 5% | 82% | 83% | 83% | |
| 50 | 6% | 26% | 52% | 14% | 28% | 80% | 80% | 80% | |
| 100 | 11% | 28% | 49% | 7% | 35% | 75% | 75% | 76% | |
| 150 | 11% | 18% | 43% | 9% | 25% | 76% | 73% | 76% | |
| 200 | 13% | 17% | 44% | 8% | 26% | 83% | 84% | 83% | |
| 50 | 9% | 30% | 55% | 25% | 43% | 80% | 81% | 81% | |
| 100 | 16% | 32% | 54% | 21% | 56% | 75% | 75% | 77% | |
| 150 | 19% | 21% | 46% | 26% | 45% | 75% | 74% | 76% | |
| 200 | 21% | 17% | 50% | 19% | 51% | 83% | 88% | 83% | |
| 50 | 16% | 38% | 64% | 40% | 58% | 80% | 81% | 82% | |
| 100 | 26% | 38% | 63% | 33% | 70% | 75% | 75% | 79% | |
| 150 | 26% | 24% | 52% | 35% | 62% | 79% | 77% | 78% | |
| 200 | 31% | 20% | 54% | 33% | 61% | 84% | 88% | 83% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Garg, N.P.; Gao, R.; Yuan, M.; Noronha, B.; Ang, W.T.; Accoto, D. Learning-Based Motion-Intention Prediction for End-Point Control of Upper-Limb-Assistive Robots. Sensors 2023, 23, 2998. https://doi.org/10.3390/s23062998
Yang S, Garg NP, Gao R, Yuan M, Noronha B, Ang WT, Accoto D. Learning-Based Motion-Intention Prediction for End-Point Control of Upper-Limb-Assistive Robots. Sensors. 2023; 23(6):2998. https://doi.org/10.3390/s23062998
Chicago/Turabian StyleYang, Sibo, Neha P. Garg, Ruobin Gao, Meng Yuan, Bernardo Noronha, Wei Tech Ang, and Dino Accoto. 2023. "Learning-Based Motion-Intention Prediction for End-Point Control of Upper-Limb-Assistive Robots" Sensors 23, no. 6: 2998. https://doi.org/10.3390/s23062998
APA StyleYang, S., Garg, N. P., Gao, R., Yuan, M., Noronha, B., Ang, W. T., & Accoto, D. (2023). Learning-Based Motion-Intention Prediction for End-Point Control of Upper-Limb-Assistive Robots. Sensors, 23(6), 2998. https://doi.org/10.3390/s23062998