
A Survey on Deep Reinforcement Learning Algorithms for Robotic Manipulation


Abstract
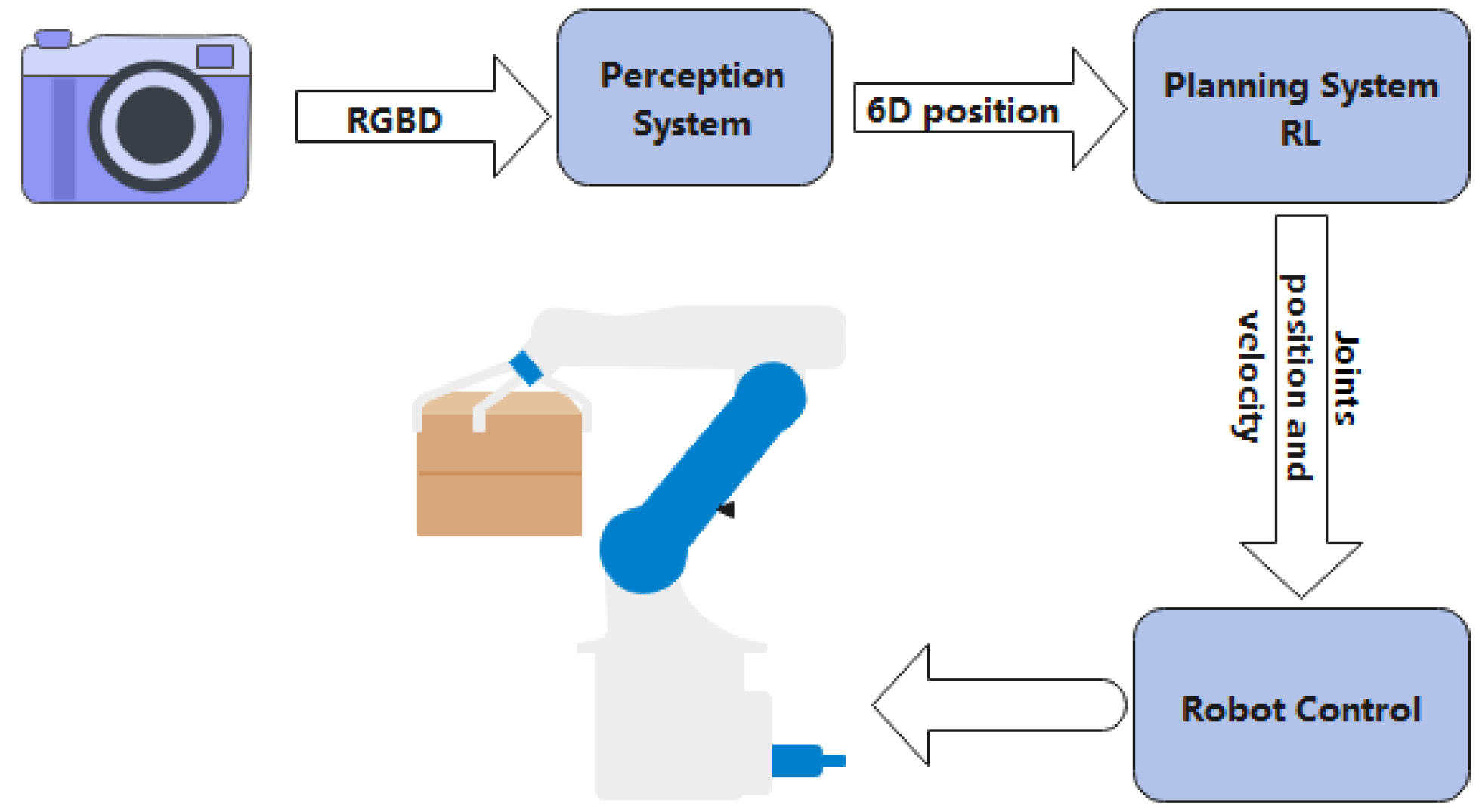
:1. Introduction
- A tutorial of the current RL algorithms and reward engineering methods used in robotic manipulation.
- An analysis of the current status and application of RL in robotic manipulation in the past seven years.
- An overview of the current main trends and directions in the use of RL in robotic manipulation tasks.
2. Search Methodology
3. Key Concepts and Algorithms of Reinforcement Learning
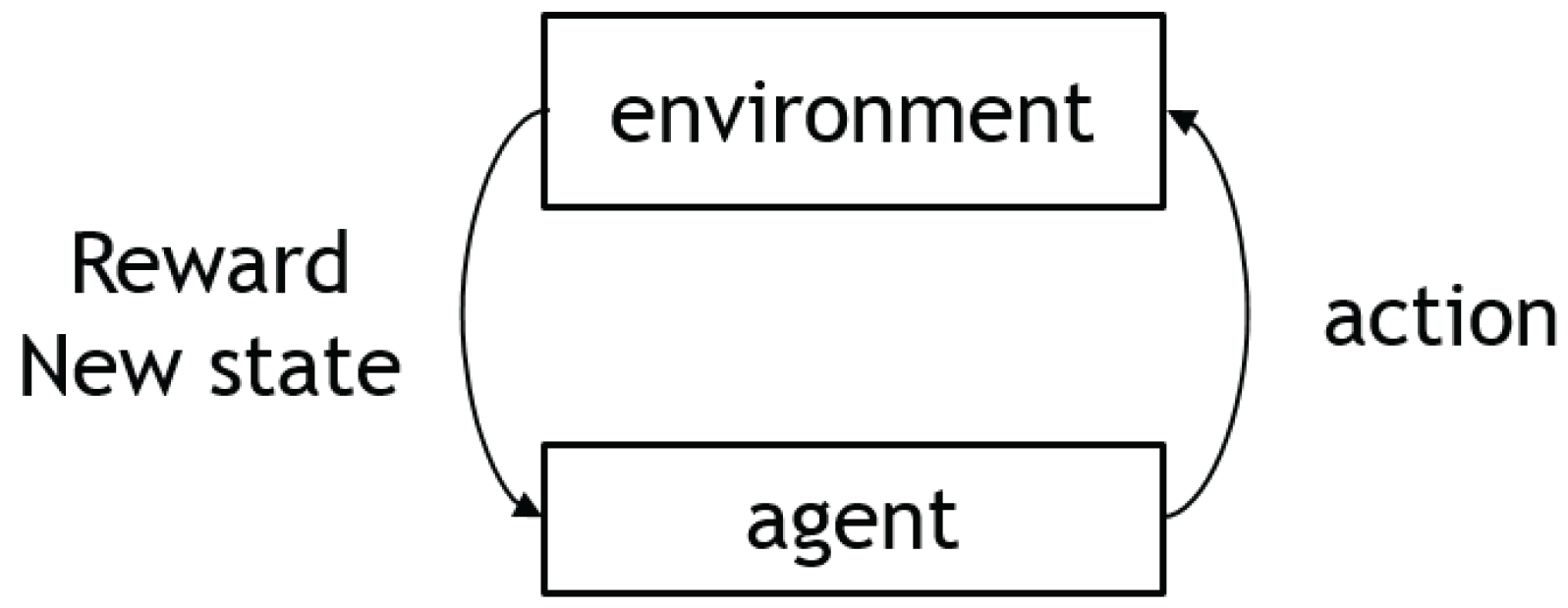
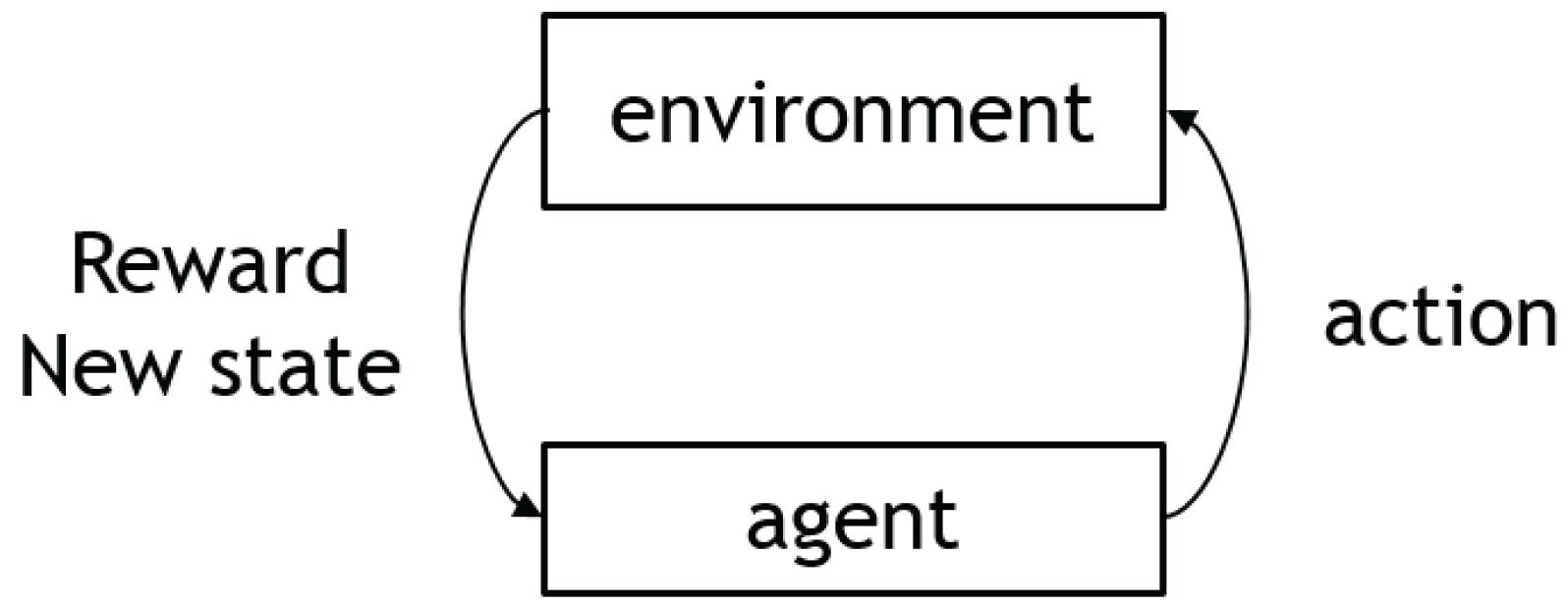
3.1. Markov Decision Process and RL
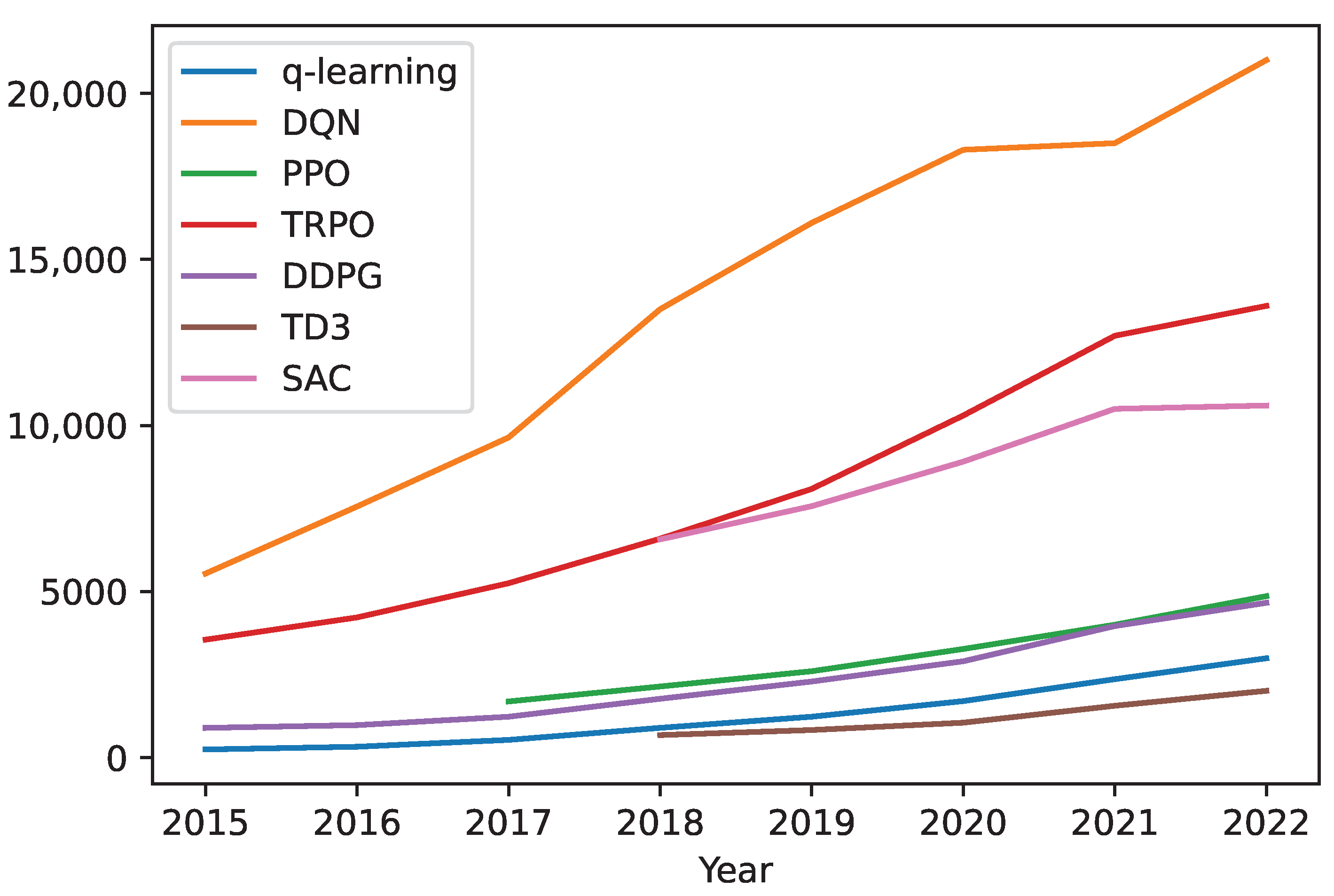
3.2. Value-Based RL
3.2.1. Q-Learning
3.2.2. SARSA
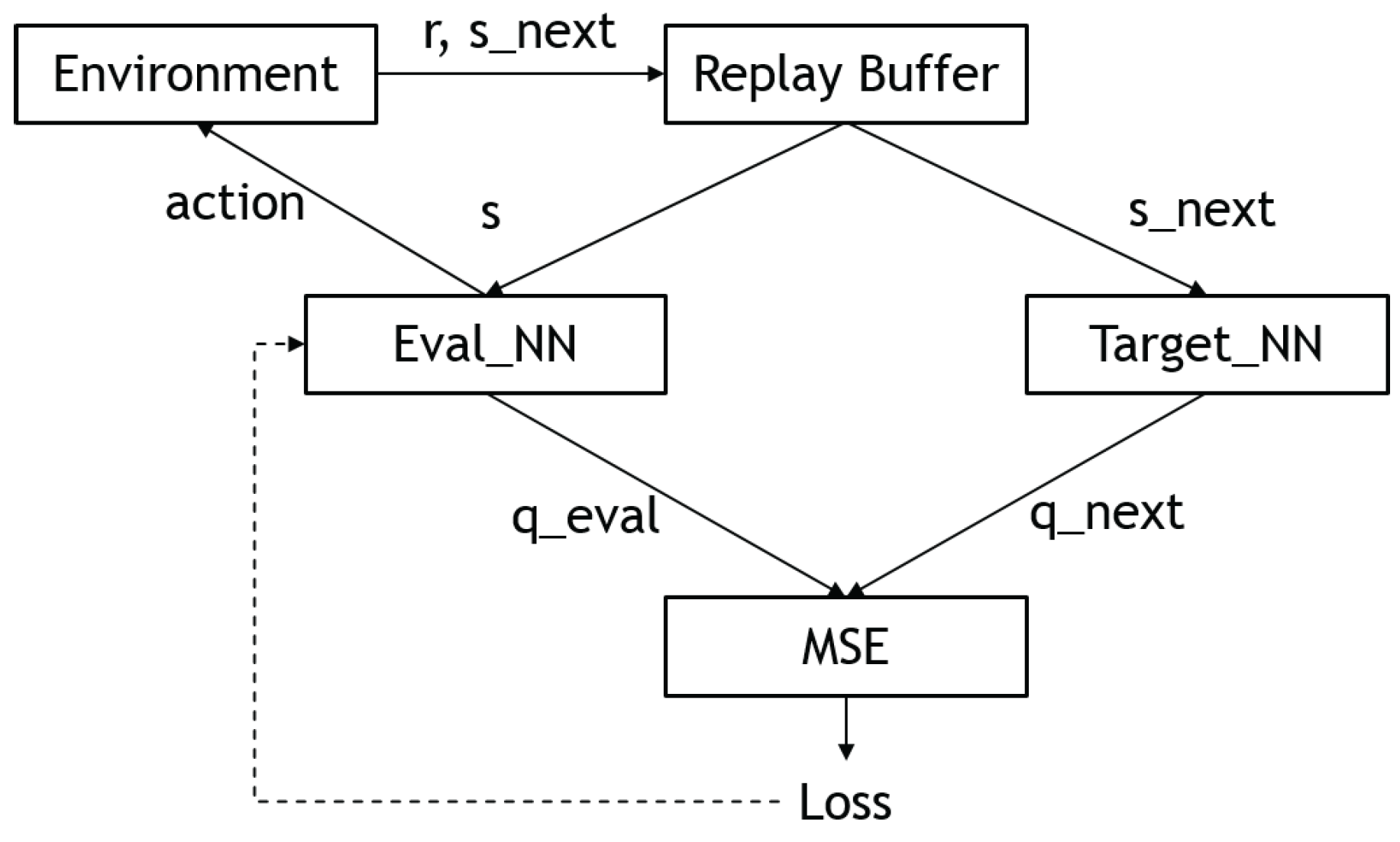
3.2.3. Deep Q-Learning (DQN)
3.2.4. Double Deep Q-Learning (Double DQN)
3.2.5. Dueling Deep Q-Learning (Dueling DQN)
3.3. Policy-Based RL
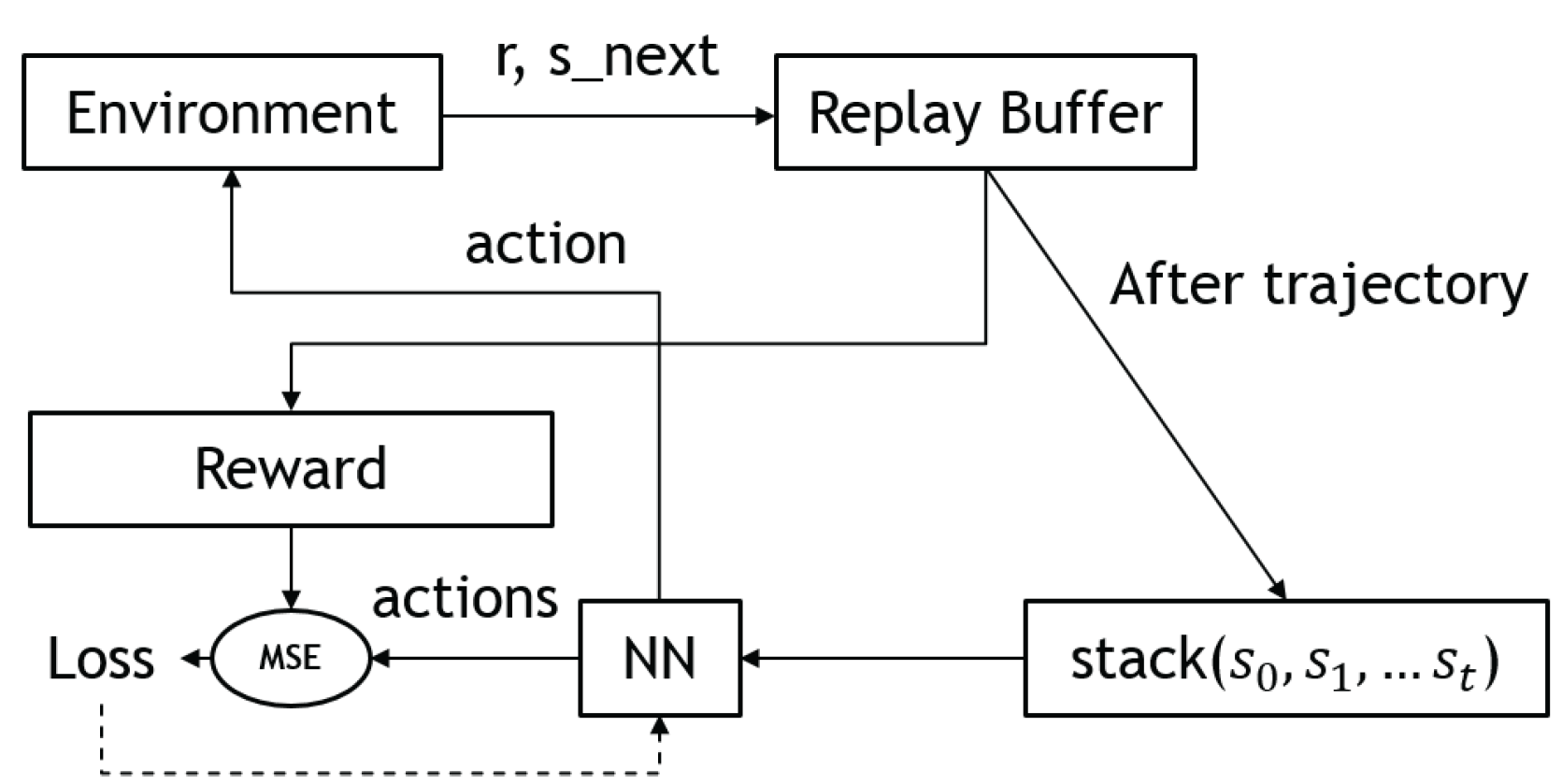
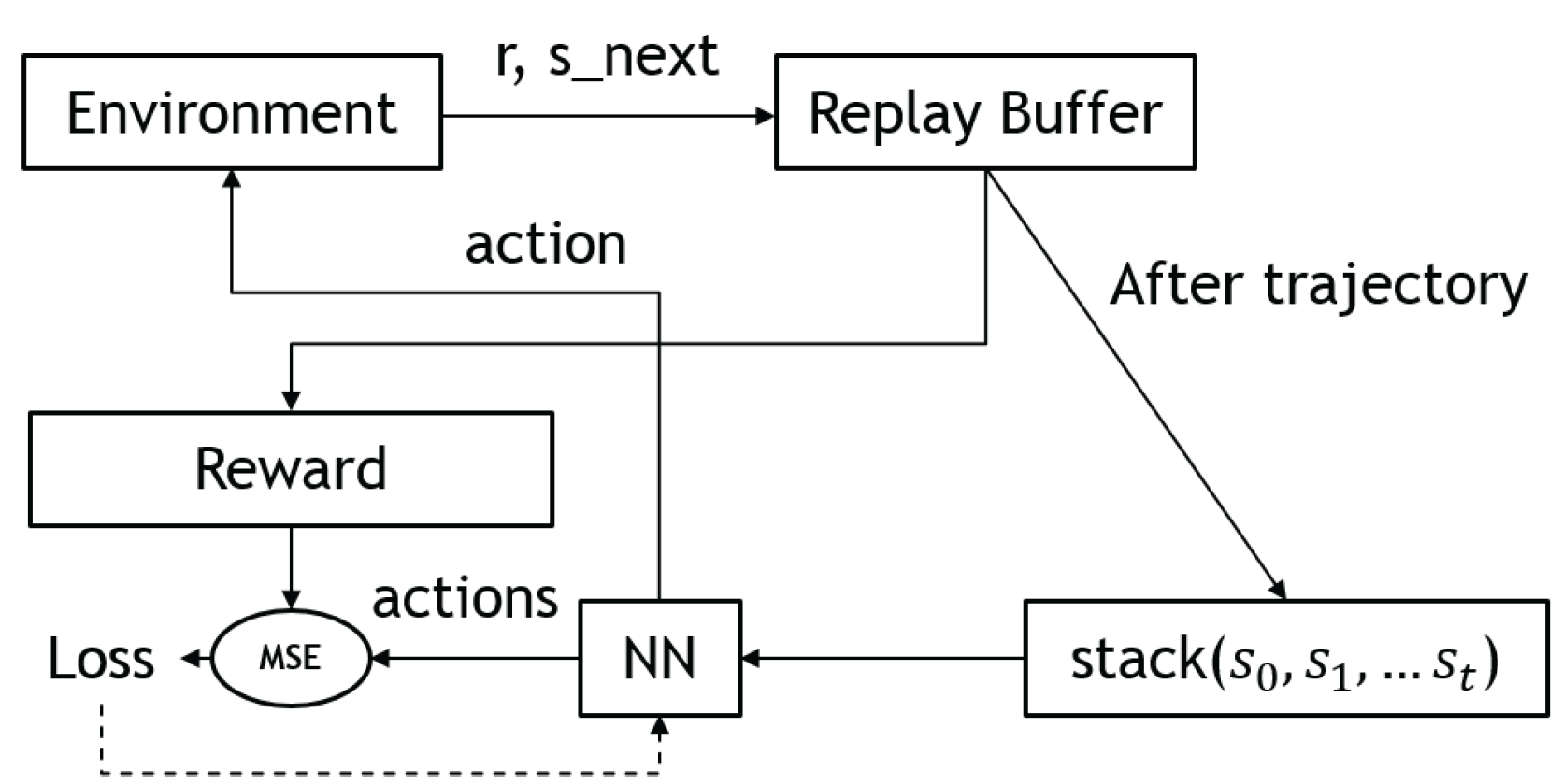
3.3.1. Vanilla Policy Gradient (VPG)
3.3.2. Trust Region Policy Optimization (TRPO)
3.3.3. Proximal Policy Optimization (PPO)
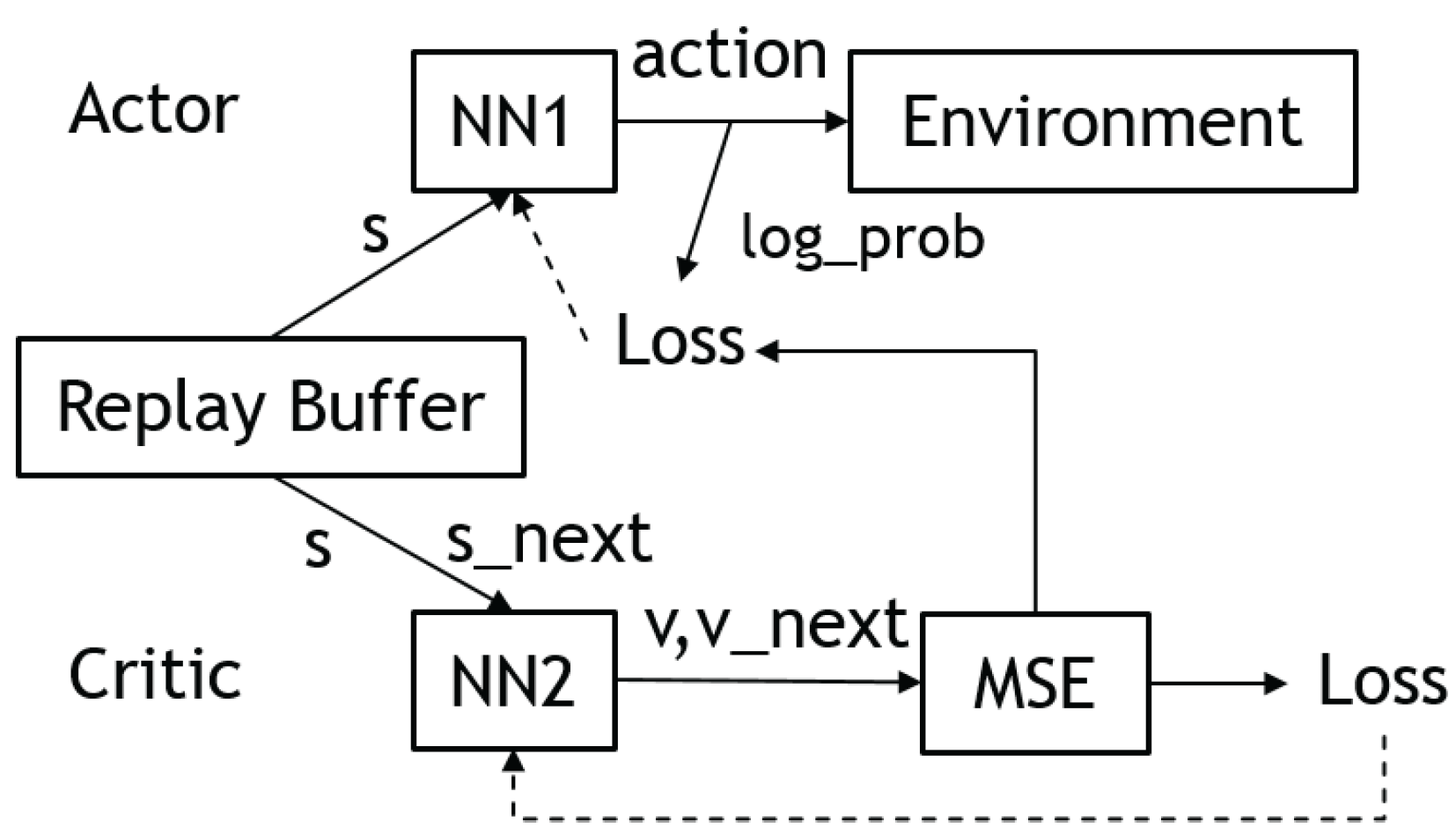
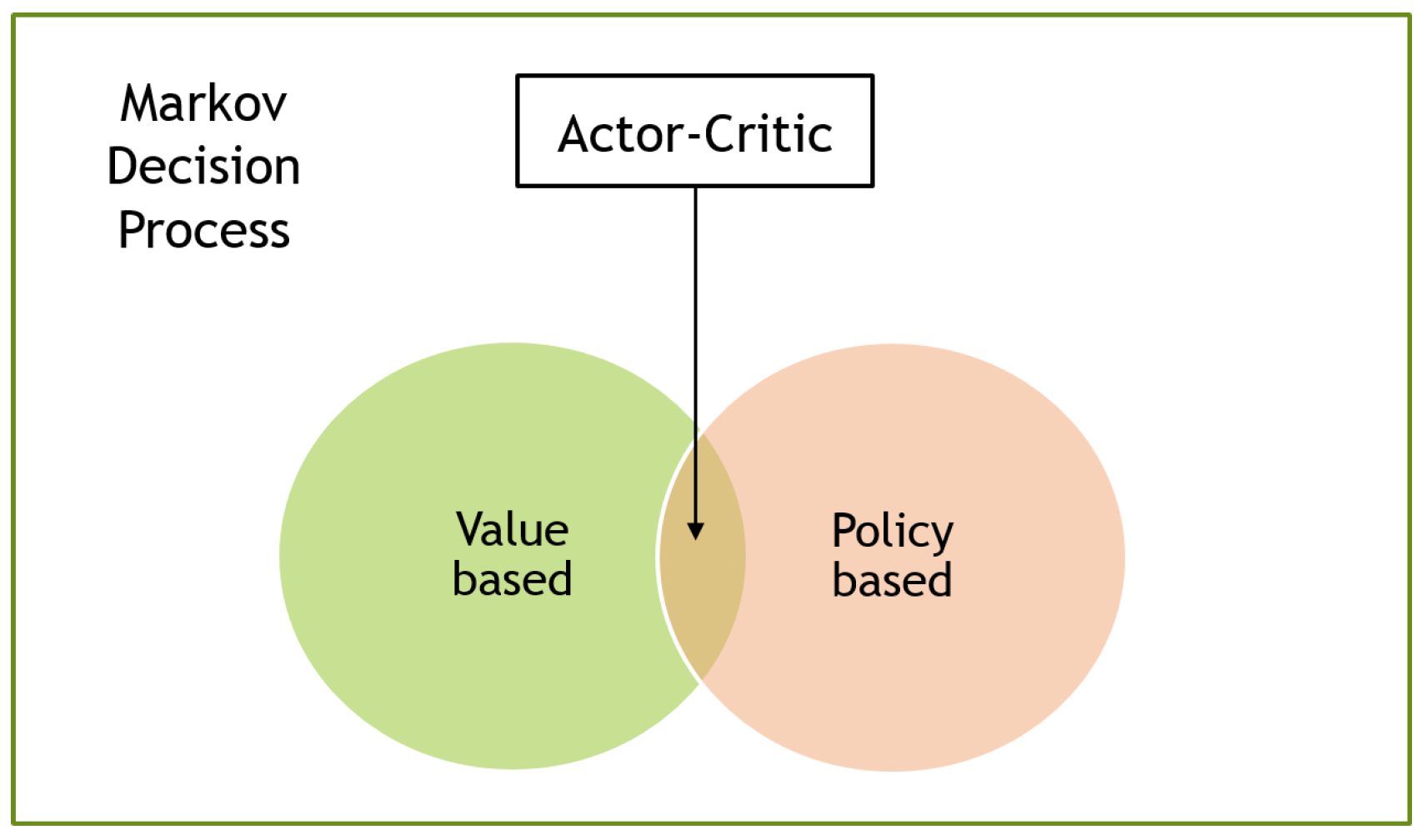
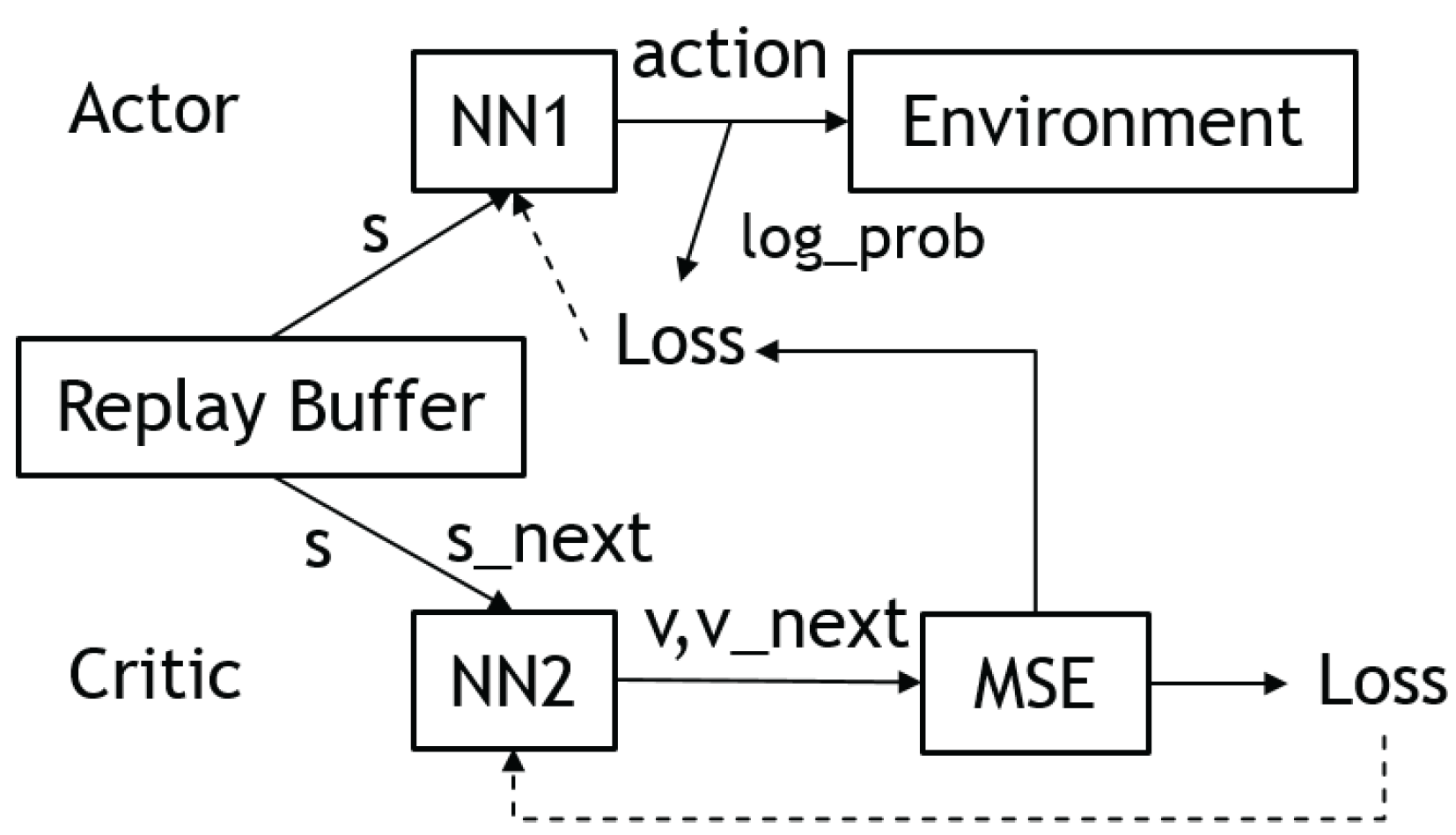
3.4. Actor–Critic
3.4.1. Advantage Actor–Critic (A2C)
3.4.2. Asynchronous Advantage Actor–Critic (A3C)
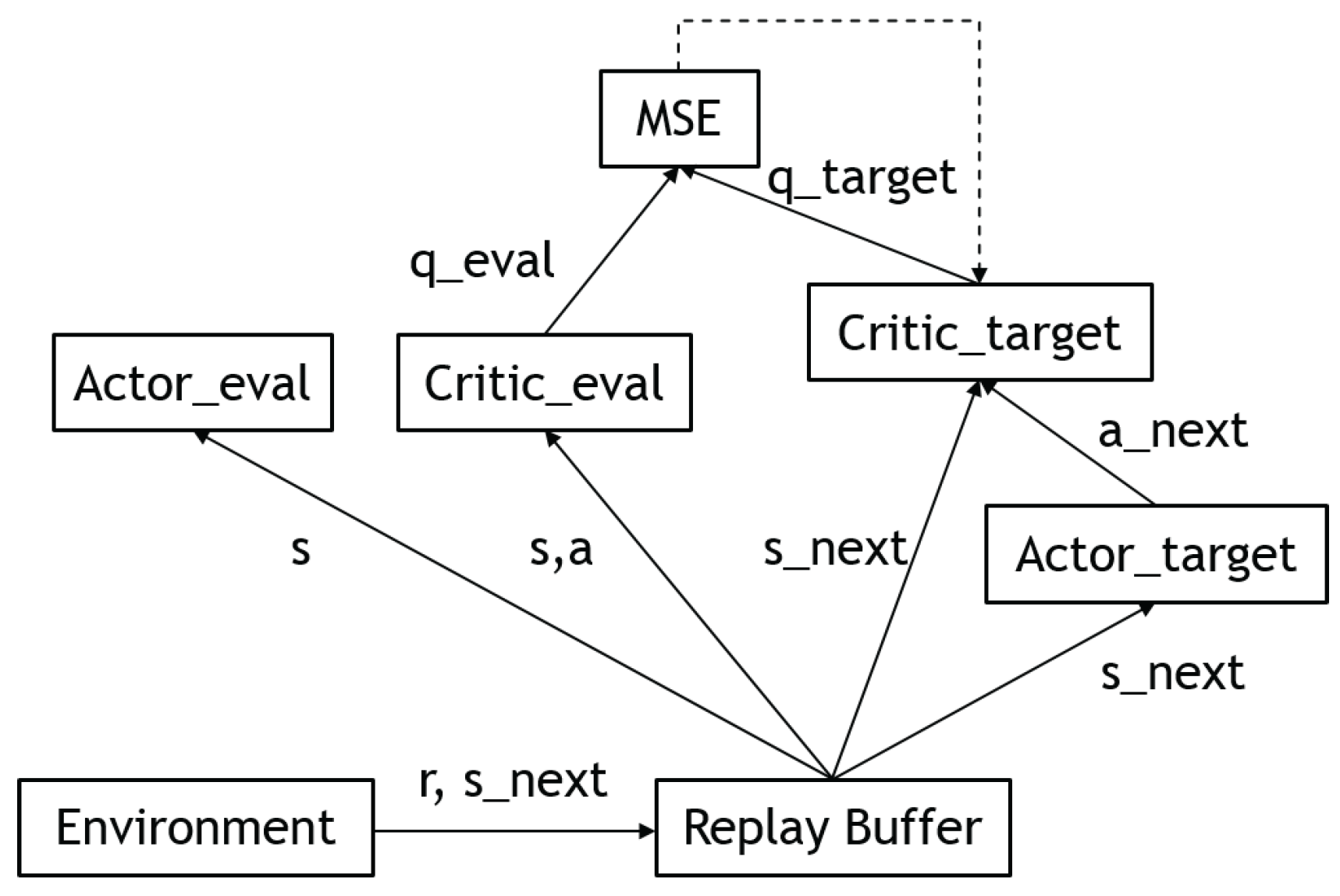
3.4.3. Deep Deterministic Policy Gradient (DDPG)
3.4.4. Twin Delayed Deep Deterministic Policy Gradients (TD3)
3.4.5. Soft Actor–Critic (SAC)
4. Reward Engineering
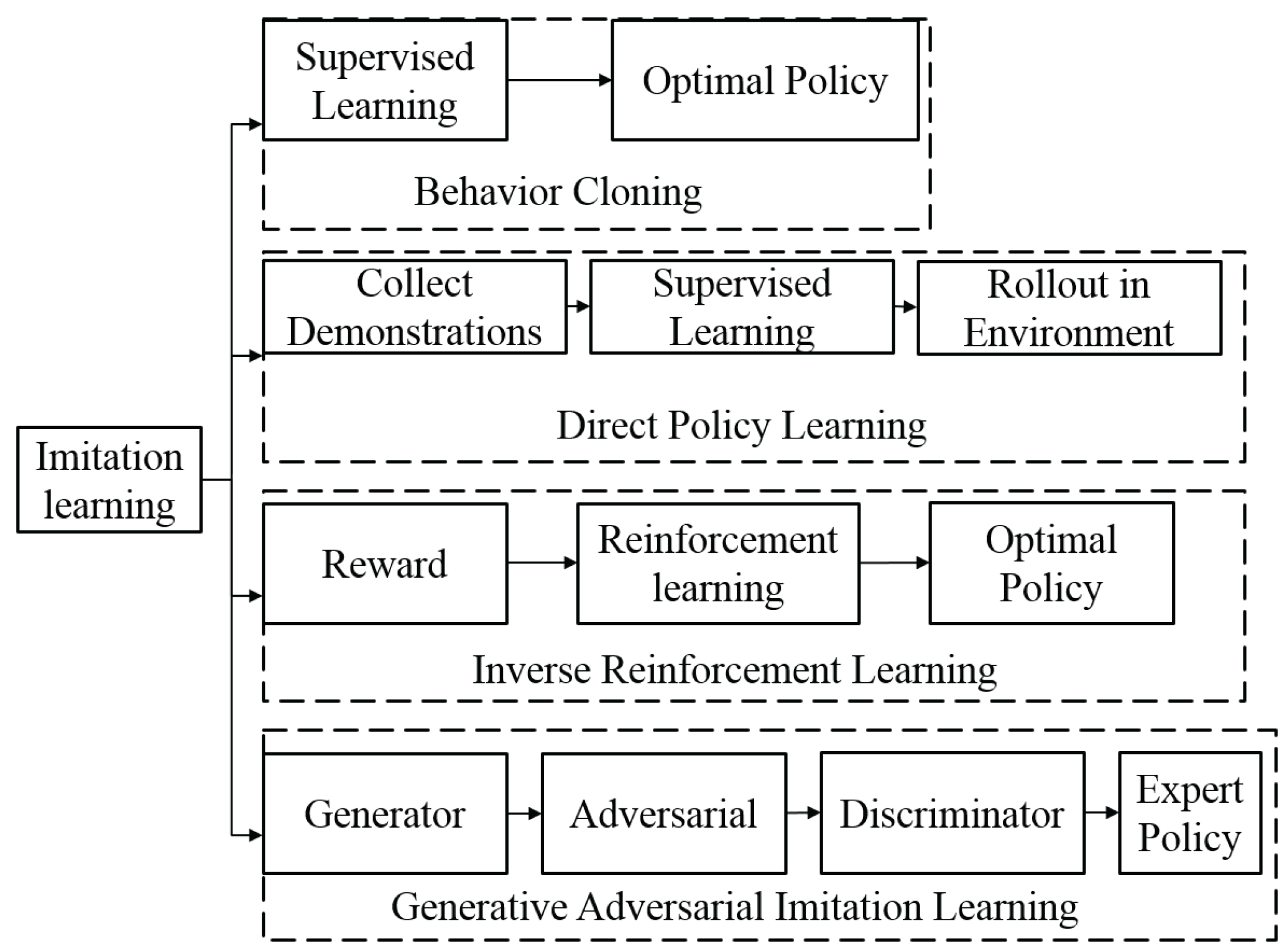
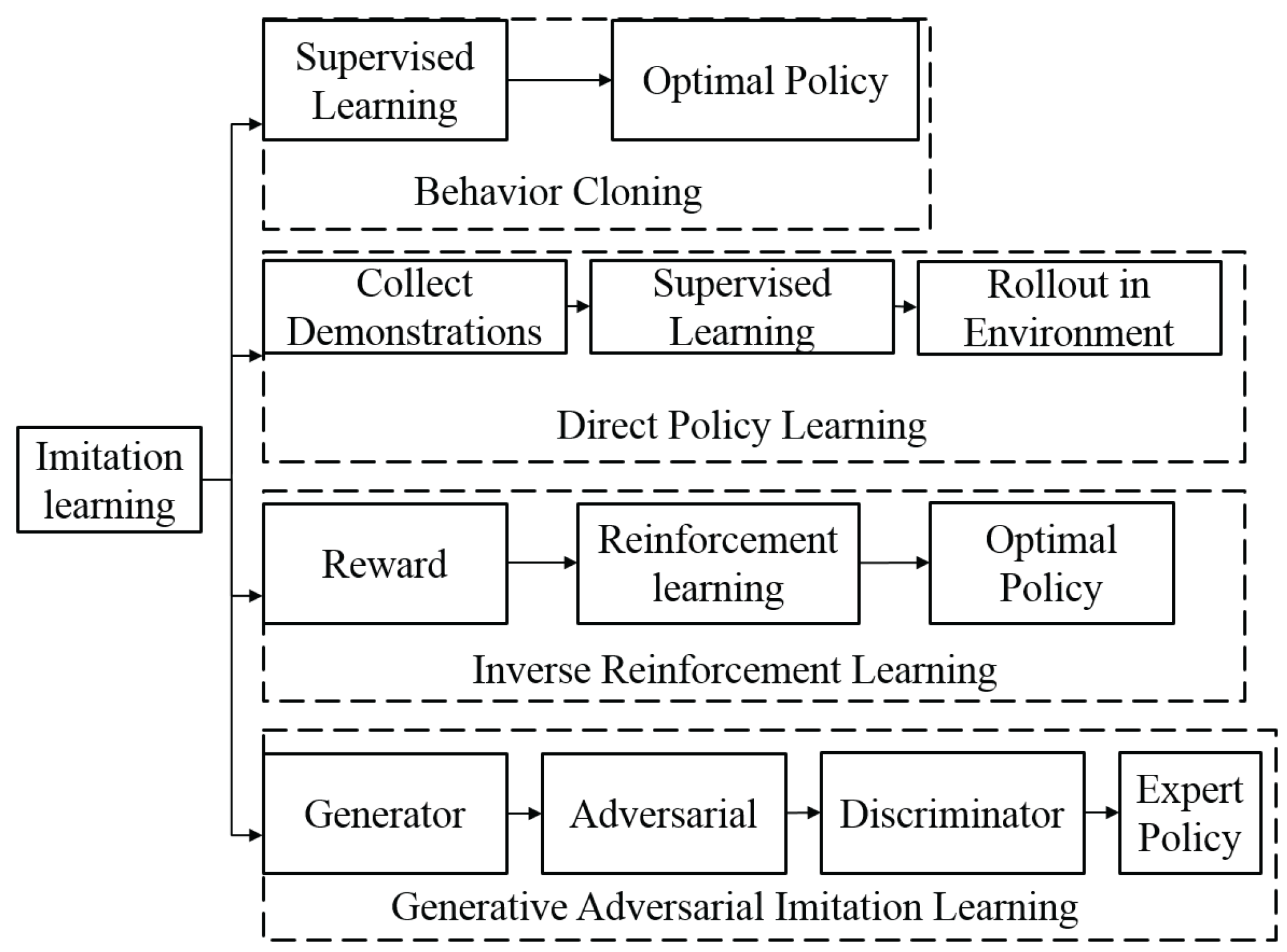
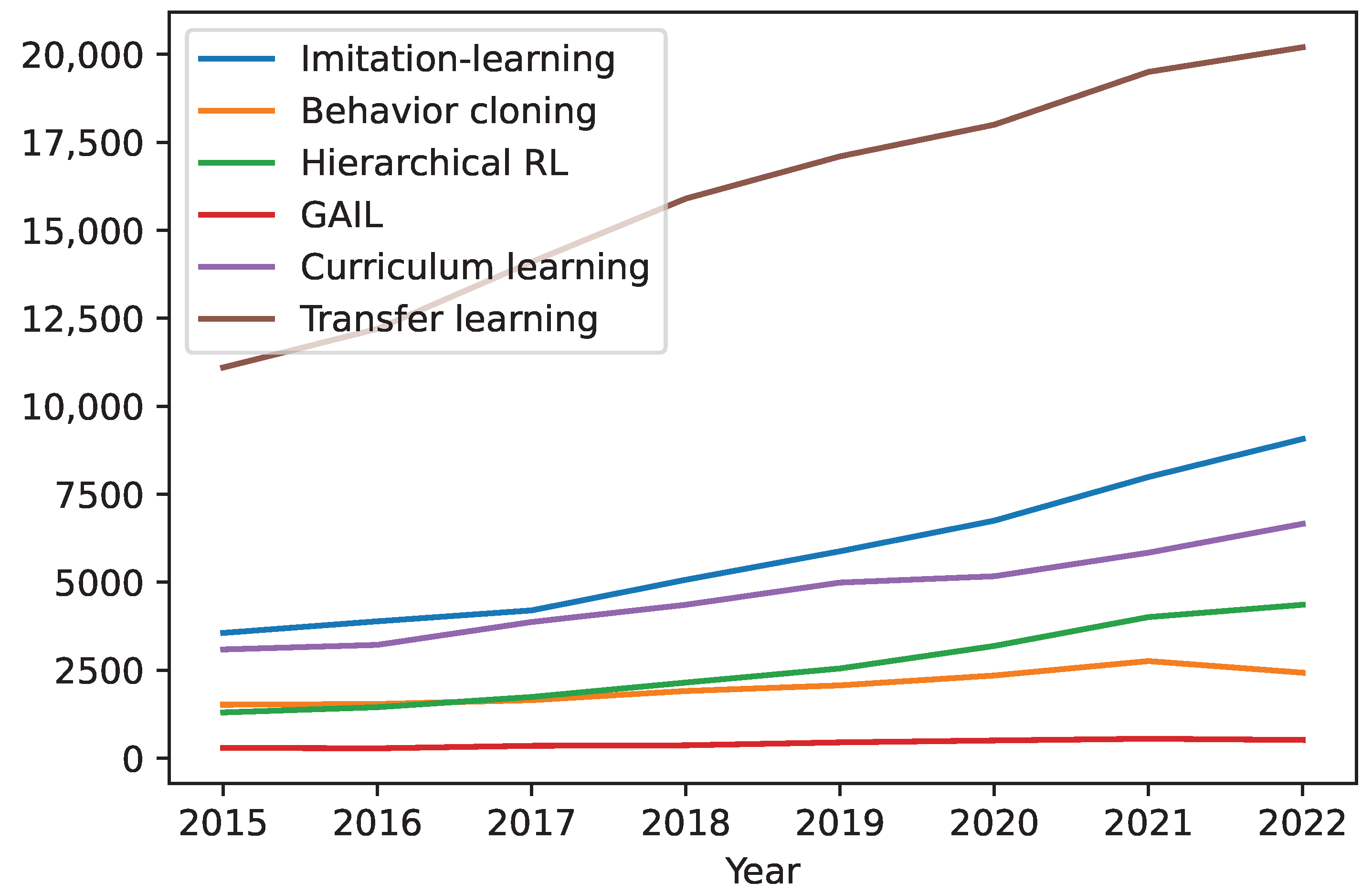
4.1. Imitation Learning
4.1.1. Behavior Cloning
4.1.2. Direct Policy Learning
4.1.3. Inverse Reinforcement Learning
4.1.4. Generative Adversarial Imitation Learning (GAIL)
4.1.5. Goal-Conditioned Imitation Learning (GCIL)
4.2. Curriculum Learning
4.3. Hierarchical Reinforcement Learning
5. Network Architecture
5.1. Convolutional Neural Network
5.2. Recurrent Neural Network
5.3. Graph Neural Network
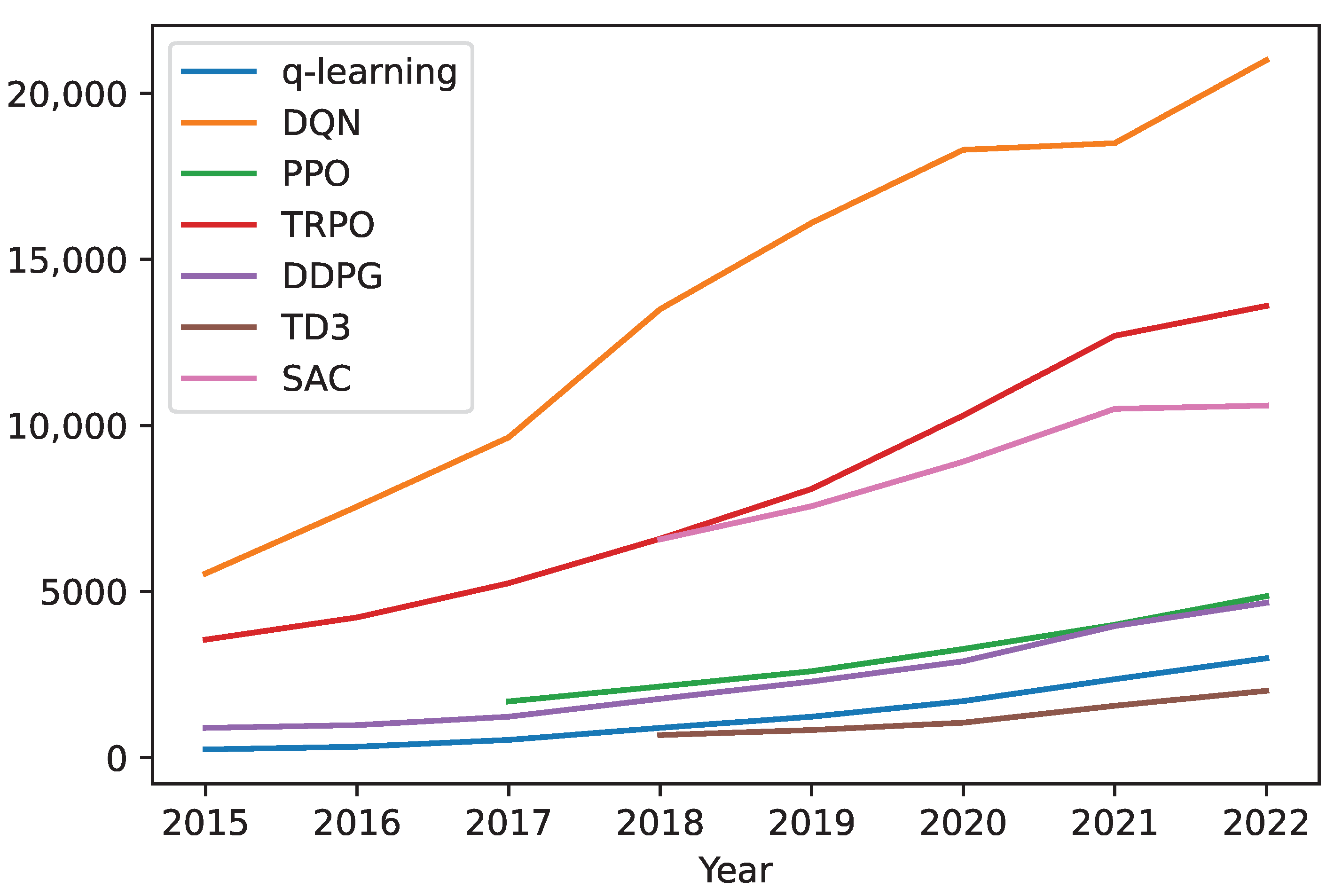
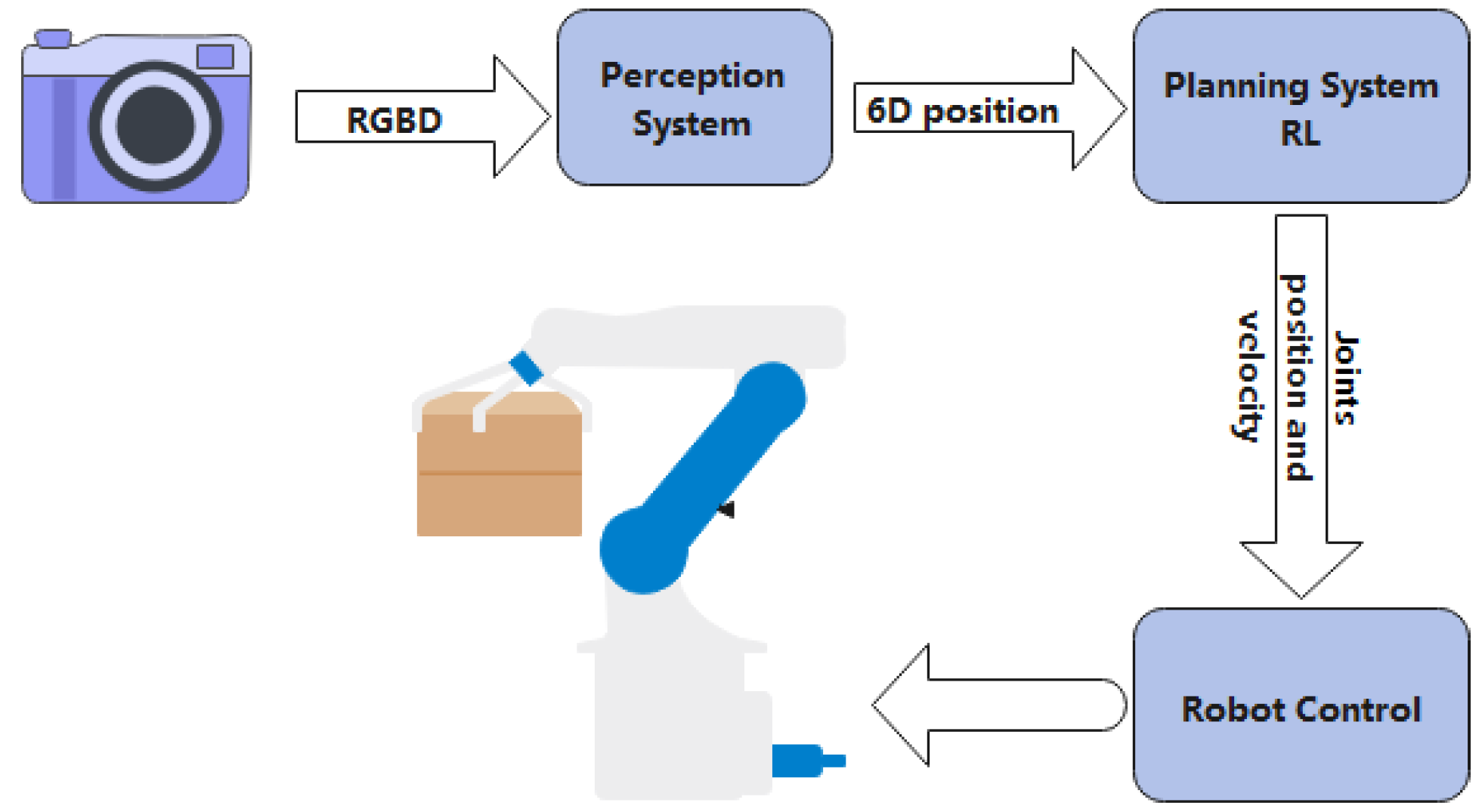
6. Deep RL for Robotic Manipulation
6.1. Sim-to-Real
6.2. Reward Engineering
6.2.1. Imitation Learning
6.2.2. Behavior Cloning
6.2.3. Hierarchical RL
6.2.4. Generative Adversarial Imitation Learning (GAIL)
6.2.5. Curriculum Learning
6.2.6. Transfer Learning
6.3. RL Techniques
6.3.1. Q-Learning
6.3.2. Deep Q-Network
6.3.3. Proximal Policy Optimization
6.3.4. Trust Region Policy Optimization
6.3.5. Deep Deterministic Policy Gradient
6.3.6. Twin Delayed Deep Deterministic Policy Gradients
6.3.7. Soft Actor–Critic
6.3.8. GNN
6.4. Future Directions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lasi, H.; Fettke, P.; Kemper, H.G.; Feld, T.; Hoffmann, M. Industry 4.0. Bus. Inf. Syst. Eng. 2014, 6, 239–242. [Google Scholar] [CrossRef]
- Sigov, A.; Ratkin, L.; Ivanov, L.A.; Xu, L.D. Emerging enabling technologies for Industry 4.0 and beyond. Inf. Syst. Front. 2022, 1–11. [Google Scholar] [CrossRef]
- Hua, J.; Zeng, L.; Li, G.; Ju, Z. Learning for a robot: Deep reinforcement learning, imitation learning, transfer learning. Sensors 2021, 21, 1278. [Google Scholar] [CrossRef] [PubMed]
- Mason, M.T. Toward Robotic Manipulation. Annu. Rev. Control. Robot. Auton. Syst. 2018, 1, 1–28. [Google Scholar] [CrossRef]
- Hafiz, A.; Hassaballah, M.A.H. Reinforcement Learning with an Ensemble of Binary Action Deep Q-Networks. Comput. Syst. Sci. Eng. 2023, 46, 2651–2666. [Google Scholar] [CrossRef]
- Hafiz, A.M.; Hassaballah, M.; Binbusayyis, A. Formula-Driven Supervised Learning in Computer Vision: A Literature Survey. Appl. Sci. 2023, 13, 723. [Google Scholar] [CrossRef]
- Morales, E.F.; Murrieta-Cid, R.; Becerra, I.; Esquivel-Basaldua, M.A. A survey on deep learning and deep reinforcement learning in robotics with a tutorial on deep reinforcement learning. Intell. Serv. Robot. 2021, 14, 773–805. [Google Scholar] [CrossRef]
- Rubagotti, M.; Sangiovanni, B.; Nurbayeva, A.; Incremona, G.P.; Ferrara, A.; Shintemirov, A. Shared Control of Robot Manipulators With Obstacle Avoidance: A Deep Reinforcement Learning Approach. IEEE Control. Syst. Mag. 2023, 43, 44–63. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–503. [Google Scholar] [CrossRef]
- Zejnullahu, F.; Moser, M.; Osterrieder, J. Applications of Reinforcement Learning in Finance—Trading with a Double Deep Q-Network. arXiv 2022, arXiv:2206.14267. [Google Scholar]
- Ramamurthy, R.; Ammanabrolu, P.; Brantley, K.; Hessel, J.; Sifa, R.; Bauckhage, C.; Hajishirzi, H.; Choi, Y. Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization. arXiv 2023, arXiv:2210.01241. [Google Scholar]
- Popova, M.; Isayev, O.; Tropsha, A. Deep reinforcement learning for de novo drug design. Sci. Adv. 2018, 4, eaap7885. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. arXiv 2021, arXiv:2002.00444. [Google Scholar] [CrossRef]
- Elguea-Aguinaco, Í.; Serrano-Muñoz, A.; Chrysostomou, D.; Inziarte-Hidalgo, I.; Bøgh, S.; Arana-Arexolaleiba, N. A review on reinforcement learning for contact-rich robotic manipulation tasks. Robot. Comput. Integr. Manuf. 2023, 81, 102517. [Google Scholar] [CrossRef]
- Wang, F.Y.; Zhang, J.J.; Zheng, X.; Wang, X.; Yuan, Y.; Dai, X.; Zhang, J.; Yang, L. Where does AlphaGo go: From church-turing thesis to AlphaGo thesis and beyond. IEEE/CAA J. Autom. Sin. 2016, 3, 113–120. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; University of Cambridge, Department of Engineering: Cambridge, UK, 1994; Volume 37. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, the, Phoenix Convention Center, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 28–30 November 2000; pp. 1057–1063. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Konda, V.R.; Tsitsiklis, J.N. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 28–30 November 2000; pp. 1008–1014. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Uhlenbeck, G.E.; Ornstein, L.S. On the theory of the Brownian motion. Phys. Rev. 1930, 36, 823. [Google Scholar] [CrossRef]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Haarnoja, T.; Tang, H.; Abbeel, P.; Levine, S. Reinforcement learning with deep energy-based policies. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1352–1361. [Google Scholar]
- Pomerleau, D.A. Alvinn: An Autonomous Land Vehicle in a Neural Network. In Artificial Intelligence and Psychology; Technical Report; Carnegie-Mellon University: Pittsburgh, PA, USA, 1989. [Google Scholar]
- Christiano, P.; Leike, J.; Brown, T.B.; Martic, M.; Legg, S.; Amodei, D. Deep reinforcement learning from human preferences. arXiv 2017, arXiv:1706.03741. [Google Scholar]
- Ng, A.Y.; Russell, S.J. Algorithms for inverse reinforcement learning. In Proceedings of the International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; Volume 1, p. 2. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum entropy inverse reinforcement learning. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI) Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 1433–1438. [Google Scholar]
- Ramachandran, D.; Amir, E. Bayesian Inverse Reinforcement Learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; Volume 7, pp. 2586–2591. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. Adv. Neural Inf. Process. Syst. 2016, 29, 4565–4573. [Google Scholar]
- Ding, Y.; Florensa, C.; Phielipp, M.; Abbeel, P. Goal-conditioned imitation learning. arXiv 2019, arXiv:1906.05838. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, P.; Zaremba, W. Hindsight experience replay. arXiv 2017, arXiv:1707.01495. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Matiisen, T.; Oliver, A.; Cohen, T.; Schulman, J. Teacher–Student curriculum learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3732–3740. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sukhbaatar, S.; Lin, Z.; Kostrikov, I.; Synnaeve, G.; Szlam, A.; Fergus, R. Intrinsic motivation and automatic curricula via asymmetric self-play. arXiv 2017, arXiv:1703.05407. [Google Scholar]
- Sutton, R.S.; Precup, D.; Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif. Intell. 1999, 112, 181–211. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; Technical Report; Institute for Cognitive Science, California University of San Diego: La Jolla, CA, USA, 1985. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sperduti, A.; Starita, A. Supervised neural networks for the classification of structures. IEEE Trans. Neural Netw. 1997, 8, 714–735. [Google Scholar] [CrossRef] [Green Version]
- Morris, C.; Ritzert, M.; Fey, M.; Hamilton, W.L.; Lenssen, J.E.; Rattan, G.; Grohe, M. Weisfeiler and leman go neural: Higher-order graph neural networks. In Proceedings of the the Association for the Advancement of Artificial Intelligence (AAAI) Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4602–4609. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Peng, X.B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Sim-to-real transfer of robotic control with dynamics randomization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 3803–3810. [Google Scholar]
- Andrychowicz, O.M.; Baker, B.; Chociej, M.; Jozefowicz, R.; McGrew, B.; Pachocki, J.; Petron, A.; Plappert, M.; Powell, G.; Ray, A.; et al. Learning dexterous in-hand manipulation. Int. J. Robot. Res. 2020, 39, 3–20. [Google Scholar] [CrossRef] [Green Version]
- Riedmiller, M.; Hafner, R.; Lampe, T.; Neunert, M.; Degrave, J.; Wiele, T.; Mnih, V.; Heess, N.; Springenberg, J.T. Learning by playing solving sparse reward tasks from scratch. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4344–4353. [Google Scholar]
- Vecerik, M.; Hester, T.; Scholz, J.; Wang, F.; Pietquin, O.; Piot, B.; Heess, N.; Rothörl, T.; Lampe, T.; Riedmiller, M. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards. arXiv 2017, arXiv:1707.08817. [Google Scholar]
- Kilinc, O.; Hu, Y.; Montana, G. Reinforcement learning for robotic manipulation using simulated locomotion demonstrations. arXiv 2019, arXiv:1910.07294. [Google Scholar] [CrossRef]
- Chen, H. Robotic Manipulation with Reinforcement Learning, State Representation Learning, and Imitation Learning (Student Abstract). In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI) Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 15769–15770. [Google Scholar]
- Zhang, M.; Jian, P.; Wu, Y.; Xu, H.; Wang, X. DAIR: Disentangled Attention Intrinsic Regularization for Safe and Efficient Bimanual Manipulation. arXiv 2021, arXiv:2106.05907. [Google Scholar]
- Yamada, J.; Lee, Y.; Salhotra, G.; Pertsch, K.; Pflueger, M.; Sukhatme, G.S.; Lim, J.J.; Englert, P. Motion planner augmented reinforcement learning for robot manipulation in obstructed environments. arXiv 2020, arXiv:2010.11940. [Google Scholar]
- Yang, X.; Ji, Z.; Wu, J.; Lai, Y.K. An Open-Source Multi-Goal Reinforcement Learning Environment for Robotic Manipulation with Pybullet. arXiv 2021, arXiv:2105.05985. [Google Scholar]
- Vulin, N.; Christen, S.; Stevšić, S.; Hilliges, O. Improved learning of robot manipulation tasks via tactile intrinsic motivation. IEEE Robot. Autom. Lett. 2021, 6, 2194–2201. [Google Scholar] [CrossRef]
- Silver, T.; Allen, K.; Tenenbaum, J.; Kaelbling, L. Residual policy learning. arXiv 2018, arXiv:1812.06298. [Google Scholar]
- Deisenroth, M.P.; Rasmussen, C.E.; Fox, D. Learning to control a low-cost manipulator using data-efficient reinforcement learning. In Robotics: Science and Systems VII; MIT Press: Cambridge, MA, USA, 2011; Volume 7, pp. 57–64. [Google Scholar]
- Li, R.; Jabri, A.; Darrell, T.; Agrawal, P. Towards practical multi-object manipulation using relational reinforcement learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Online, 31 May–31 August 2020; pp. 4051–4058. [Google Scholar]
- Popov, I.; Heess, N.; Lillicrap, T.; Hafner, R.; Barth-Maron, G.; Vecerik, M.; Lampe, T.; Tassa, Y.; Erez, T.; Riedmiller, M. Data-efficient deep reinforcement learning for dexterous manipulation. arXiv 2017, arXiv:1704.03073. [Google Scholar]
- Rusu, A.A.; Večerík, M.; Rothörl, T.; Heess, N.; Pascanu, R.; Hadsell, R. Sim-to-real robot learning from pixels with progressive nets. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 262–270. [Google Scholar]
- Nair, A.; McGrew, B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Overcoming exploration in reinforcement learning with demonstrations. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 6292–6299. [Google Scholar]
- OpenAI; Plappert, M.; Sampedro, R.; Xu, T.; Akkaya, I.; Kosaraju, V.; Welinder, P.; D’Sa, R.; Petron, A.; Pinto, H.P.d.O.; et al. Asymmetric self-play for automatic goal discovery in robotic manipulation. arXiv 2021, arXiv:2101.04882. [Google Scholar]
- Zhan, A.; Zhao, P.; Pinto, L.; Abbeel, P.; Laskin, M. A Framework for Efficient Robotic Manipulation. arXiv 2020, arXiv:2012.07975. [Google Scholar]
- Franceschetti, A.; Tosello, E.; Castaman, N.; Ghidoni, S. Robotic arm control and task training through deep reinforcement learning. In Intelligent Autonomous Systems 16, Proceedings of the 16th International Conference IAS-16, Singapore, 29–31 July 2020; Springer: Berlin/Heidelberg, Germany, 2022; pp. 532–550. [Google Scholar]
- Lu, L.; Zhang, M.; He, D.; Gu, Q.; Gong, D.; Fu, L. A Method of Robot Grasping Based on Reinforcement Learning. J. Phys. Conf. Ser. 2022, 2216, 012026. [Google Scholar] [CrossRef]
- Davchev, T.; Luck, K.S.; Burke, M.; Meier, F.; Schaal, S.; Ramamoorthy, S. Residual learning from demonstration: Adapting dmps for contact-rich manipulation. IEEE Robot. Autom. Lett. 2022, 7, 4488–4495. [Google Scholar] [CrossRef]
- Zhang, X.; Jin, S.; Wang, C.; Zhu, X.; Tomizuka, M. Learning insertion primitives with discrete-continuous hybrid action space for robotic assembly tasks. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 9881–9887. [Google Scholar]
- Zhao, T.Z.; Luo, J.; Sushkov, O.; Pevceviciute, R.; Heess, N.; Scholz, J.; Schaal, S.; Levine, S. Offline meta-reinforcement learning for industrial insertion. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 6386–6393. [Google Scholar]
- Ding, Y.; Zhao, J.; Min, X. Impedance control and parameter optimization of surface polishing robot based on reinforcement learning. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2023, 237, 216–228. [Google Scholar] [CrossRef]
- Belousov, B.; Wibranek, B.; Schneider, J.; Schneider, T.; Chalvatzaki, G.; Peters, J.; Tessmann, O. Robotic architectural assembly with tactile skills: Simulation and optimization. Autom. Constr. 2022, 133, 104006. [Google Scholar] [CrossRef]
- Lin, N.; Li, Y.; Tang, K.; Zhu, Y.; Zhang, X.; Wang, R.; Ji, J.; Chen, X.; Zhang, X. Manipulation planning from demonstration via goal-conditioned prior action primitive decomposition and alignment. IEEE Robot. Autom. Lett. 2022, 7, 1387–1394. [Google Scholar] [CrossRef]
- Cong, L.; Liang, H.; Ruppel, P.; Shi, Y.; Görner, M.; Hendrich, N.; Zhang, J. Reinforcement learning with vision-proprioception model for robot planar pushing. Front. Neurorobot. 2022, 16, 829437. [Google Scholar] [CrossRef]
- Kim, S.; Jo, H.; Song, J.B. Object manipulation system based on image-based reinforcement learning. Intell. Serv. Robot. 2022, 15, 171–177. [Google Scholar] [CrossRef]
- Nasiriany, S.; Liu, H.; Zhu, Y. Augmenting reinforcement learning with behavior primitives for diverse manipulation tasks. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 7477–7484. [Google Scholar]
- Anand, A.S.; Myrestrand, M.H.; Gravdahl, J.T. Evaluation of variable impedance-and hybrid force/motioncontrollers for learning force tracking skills. In Proceedings of the 2022 IEEE/SICE International Symposium on System Integration (SII), Online, 9–12 January 2022; pp. 83–89. [Google Scholar]
- Deisenroth, M.; Rasmussen, C.E. PILCO: A model-based and data-efficient approach to policy search. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 465–472. [Google Scholar]
- Ben-Iwhiwhu, E.; Dick, J.; Ketz, N.A.; Pilly, P.K.; Soltoggio, A. Context meta-reinforcement learning via neuromodulation. Neural Netw. 2022, 152, 70–79. [Google Scholar] [CrossRef]
- Brunke, L.; Greeff, M.; Hall, A.W.; Yuan, Z.; Zhou, S.; Panerati, J.; Schoellig, A.P. Safe learning in robotics: From learning-based control to safe reinforcement learning. Annu. Rev. Control. Robot. Auton. Syst. 2022, 5, 411–444. [Google Scholar] [CrossRef]
- Wabersich, K.P.; Zeilinger, M.N. Linear model predictive safety certification for learning-based control. In Proceedings of the 2018 IEEE Conference on Decision and Control (CDC), Miami Beach, FL, USA, 17–19 December 2018; pp. 7130–7135. [Google Scholar]
- Beyene, S.W.; Han, J.H. Prioritized Hindsight with Dual Buffer for Meta-Reinforcement Learning. Electronics 2022, 11, 4192. [Google Scholar] [CrossRef]
- Shao, Q.; Qi, J.; Ma, J.; Fang, Y.; Wang, W.; Hu, J. Object detection-based one-shot imitation learning with an RGB-D camera. Appl. Sci. 2020, 10, 803. [Google Scholar] [CrossRef] [Green Version]
- Ho, D.; Rao, K.; Xu, Z.; Jang, E.; Khansari, M.; Bai, Y. Retinagan: An object-aware approach to sim-to-real transfer. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 10920–10926. [Google Scholar]
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; Hadsell, R. Progressive neural networks. arXiv 2016, arXiv:1606.04671. [Google Scholar]
- Sadeghi, F.; Toshev, A.; Jang, E.; Levine, S. Sim2real view invariant visual servoing by recurrent control. arXiv 2017, arXiv:1712.07642. [Google Scholar]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Sun, C.; Orbik, J.; Devin, C.; Yang, B.; Gupta, A.; Berseth, G.; Levine, S. Fully Autonomous Real-World Reinforcement Learning for Mobile Manipulation. arXiv 2021, arXiv:2107.13545. [Google Scholar]
- Ding, Z.; Tsai, Y.Y.; Lee, W.W.; Huang, B. Sim-to-Real Transfer for Robotic Manipulation with Tactile Sensory. arXiv 2021, arXiv:2103.00410. [Google Scholar]
- Duan, Y.; Andrychowicz, M.; Stadie, B.C.; Ho, J.; Schneider, J.; Sutskever, I.; Abbeel, P.; Zaremba, W. One-shot imitation learning. arXiv 2017, arXiv:1703.07326. [Google Scholar]
- Finn, C.; Yu, T.; Zhang, T.; Abbeel, P.; Levine, S. One-shot visual imitation learning via meta-learning. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 357–368. [Google Scholar]
- Yu, T.; Finn, C.; Xie, A.; Dasari, S.; Zhang, T.; Abbeel, P.; Levine, S. One-shot imitation from observing humans via domain-adaptive meta-learning. arXiv 2018, arXiv:1802.01557. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Wang, Z.; Merel, J.; Reed, S.; Wayne, G.; de Freitas, N.; Heess, N. Robust imitation of diverse behaviors. arXiv 2017, arXiv:1707.02747. [Google Scholar]
- Zhou, A.; Kim, M.J.; Wang, L.; Florence, P.; Finn, C. NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics via Novel-View Synthesis. arXiv 2023, arXiv:2301.08556. [Google Scholar]
- Li, K.; Chappell, D.; Rojas, N. Immersive Demonstrations are the Key to Imitation Learning. arXiv 2023, arXiv:2301.09157. [Google Scholar]
- Tong, D.; Choi, A.; Terzopoulos, D.; Joo, J.; Jawed, M.K. Deep Learning of Force Manifolds from the Simulated Physics of Robotic Paper Folding. arXiv 2023, arXiv:2301.01968. [Google Scholar]
- Zhang, D.; Fan, W.; Lloyd, J.; Yang, C.; Lepora, N.F. One-Shot Domain-Adaptive Imitation Learning via Progressive Learning Applied to Robotic Pouring. arXiv 2022, arXiv:2204.11251. [Google Scholar] [CrossRef]
- Yi, J.B.; Kim, J.; Kang, T.; Song, D.; Park, J.; Yi, S.J. Anthropomorphic Grasping of Complex-Shaped Objects Using Imitation Learning. Appl. Sci. 2022, 12, 12861. [Google Scholar] [CrossRef]
- Wang, Y.; Beltran-Hernandez, C.C.; Wan, W.; Harada, K. An adaptive imitation learning framework for robotic complex contact-rich insertion tasks. Front. Robot. 2022, 8, 414. [Google Scholar] [CrossRef]
- von Hartz, J.O.; Chisari, E.; Welschehold, T.; Valada, A. Self-Supervised Learning of Multi-Object Keypoints for Robotic Manipulation. arXiv 2022, arXiv:2205.08316. [Google Scholar]
- Zhou, Y.; Aytar, Y.; Bousmalis, K. Manipulator-independent representations for visual imitation. arXiv 2021, arXiv:2103.09016. [Google Scholar]
- Jung, E.; Kim, I. Hybrid imitation learning framework for robotic manipulation tasks. Sensors 2021, 21, 3409. [Google Scholar] [CrossRef] [PubMed]
- Bong, J.H.; Jung, S.; Kim, J.; Park, S. Standing Balance Control of a Bipedal Robot Based on Behavior Cloning. Biomimetics 2022, 7, 232. [Google Scholar] [CrossRef]
- Shafiullah, N.M.M.; Cui, Z.J.; Altanzaya, A.; Pinto, L. Behavior Transformers: Cloning k modes with one stone. arXiv 2022, arXiv:2206.11251. [Google Scholar]
- Piche, A.; Pardinas, R.; Vazquez, D.; Mordatch, I.; Pal, C. Implicit Offline Reinforcement Learning via Supervised Learning. arXiv 2022, arXiv:2210.12272. [Google Scholar]
- Shridhar, M.; Manuelli, L.; Fox, D. Perceiver-actor: A multi-task transformer for robotic manipulation. arXiv 2022, arXiv:2209.05451. [Google Scholar]
- Wang, Q.; McCarthy, R.; Bulens, D.C.; Redmond, S.J. Winning Solution of Real Robot Challenge III. arXiv 2023, arXiv:2301.13019. [Google Scholar]
- Finn, C.; Levine, S.; Abbeel, P. Guided cost learning: Deep inverse optimal control via policy optimization. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 49–58. [Google Scholar]
- Zhao, X.; Xia, L.; Zhang, L.; Ding, Z.; Yin, D.; Tang, J. Deep reinforcement learning for page-wise recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; pp. 95–103. [Google Scholar]
- Li, X.; Ma, Y.; Belta, C. Automata guided reinforcement learning with demonstrations. arXiv 2018, arXiv:1809.06305. [Google Scholar]
- Osa, T.; Peters, J.; Neumann, G. Hierarchical reinforcement learning of multiple grasping strategies with human instructions. Adv. Robot. 2018, 32, 955–968. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Yu, H.; Xu, W. Hierarchical reinforcement learning by discovering intrinsic options. arXiv 2021, arXiv:2101.06521. [Google Scholar]
- Baram, N.; Anschel, O.; Caspi, I.; Mannor, S. End-to-end differentiable adversarial imitation learning. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 390–399. [Google Scholar]
- Merel, J.; Tassa, Y.; TB, D.; Srinivasan, S.; Lemmon, J.; Wang, Z.; Wayne, G.; Heess, N. Learning human behaviors from motion capture by adversarial imitation. arXiv 2017, arXiv:1707.02201. [Google Scholar]
- Tsurumine, Y.; Matsubara, T. Goal-aware generative adversarial imitation learning from imperfect demonstration for robotic cloth manipulation. Robot. Auton. Syst. 2022, 158, 104264. [Google Scholar] [CrossRef]
- Zolna, K.; Reed, S.; Novikov, A.; Colmenarejo, S.G.; Budden, D.; Cabi, S.; Denil, M.; de Freitas, N.; Wang, Z. Task-relevant adversarial imitation learning. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 247–263. [Google Scholar]
- Yang, X.; Ji, Z.; Wu, J.; Lai, Y.K. Abstract demonstrations and adaptive exploration for efficient and stable multi-step sparse reward reinforcement learning. In Proceedings of the 2022 27th International Conference on Automation and Computing (ICAC), Bristol, UK, 1–3 September 2022; pp. 1–6. [Google Scholar]
- Li, Y.; Kong, T.; Li, L.; Li, Y.; Wu, Y. Learning to Design and Construct Bridge without Blueprint. arXiv 2021, arXiv:2108.02439. [Google Scholar]
- Puang, E.Y.; Tee, K.P.; Jing, W. Kovis: Keypoint-based visual servoing with zero-shot sim-to-real transfer for robotics manipulation. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Online, 25 October–24 December 2020; pp. 7527–7533. [Google Scholar]
- Yuan, C.; Shi, Y.; Feng, Q.; Chang, C.; Liu, M.; Chen, Z.; Knoll, A.C.; Zhang, J. Sim-to-Real Transfer of Robotic Assembly with Visual Inputs Using CycleGAN and Force Control. In Proceedings of the 2022 IEEE International Conference on Robotics and Biomimetics (ROBIO), Xishuangbanna, China, 5–9 December 2022; pp. 1426–1432. [Google Scholar]
- Tiboni, G.; Arndt, K.; Kyrki, V. DROPO: Sim-to-Real Transfer with Offline Domain Randomization. arXiv 2022, arXiv:2201.08434. [Google Scholar]
- Yamanokuchi, T.; Kwon, Y.; Tsurumine, Y.; Uchibe, E.; Morimoto, J.; Matsubara, T. Randomized-to-Canonical Model Predictive Control for Real-World Visual Robotic Manipulation. IEEE Robot. Autom. Lett. 2022, 7, 8964–8971. [Google Scholar] [CrossRef]
- Julian, R.; Swanson, B.; Sukhatme, G.S.; Levine, S.; Finn, C.; Hausman, K. Efficient adaptation for end-to-end vision-based robotic manipulation. In Proceedings of the 4th Lifelong Machine Learning Workshop at ICML, Online, 13–18 July 2020. [Google Scholar]
- Rammohan, S.; Yu, S.; He, B.; Hsiung, E.; Rosen, E.; Tellex, S.; Konidaris, G. Value-Based Reinforcement Learning for Continuous Control Robotic Manipulation in Multi-Task Sparse Reward Settings. arXiv 2021, arXiv:2107.13356. [Google Scholar]
- Wang, D.; Walters, R. So (2) equivariant reinforcement learning. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Deng, Y.; Guo, D.; Guo, X.; Zhang, N.; Liu, H.; Sun, F. MQA: Answering the question via robotic manipulation. arXiv 2020, arXiv:2003.04641. [Google Scholar]
- Imtiaz, M.B.; Qiao, Y.; Lee, B. Prehensile and Non-Prehensile Robotic Pick-and-Place of Objects in Clutter Using Deep Reinforcement Learning. Sensors 2023, 23, 1513. [Google Scholar] [CrossRef]
- Sarantopoulos, I.; Kiatos, M.; Doulgeri, Z.; Malassiotis, S. Split deep q-learning for robust object singulation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Online, 31 May–31 August 2020; pp. 6225–6231. [Google Scholar]
- Hsu, H.L.; Huang, Q.; Ha, S. Improving safety in deep reinforcement learning using unsupervised action planning. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 5567–5573. [Google Scholar]
- Iriondo, A.; Lazkano, E.; Susperregi, L.; Urain, J.; Fernandez, A.; Molina, J. Pick and place operations in logistics using a mobile manipulator controlled with deep reinforcement learning. Appl. Sci. 2019, 9, 348. [Google Scholar] [CrossRef] [Green Version]
- Hwangbo, J.; Lee, J.; Dosovitskiy, A.; Bellicoso, D.; Tsounis, V.; Koltun, V.; Hutter, M. Learning agile and dynamic motor skills for legged robots. Sci. Robot. 2019, 4, eaau5872. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clegg, A.; Yu, W.; Tan, J.; Kemp, C.C.; Turk, G.; Liu, C.K. Learning human behaviors for robot-assisted dressing. arXiv 2017, arXiv:1709.07033. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Wang, Q.; Sanchez, F.R.; McCarthy, R.; Bulens, D.C.; McGuinness, K.; O’Connor, N.; Wüthrich, M.; Widmaier, F.; Bauer, S.; Redmond, S.J. Dexterous robotic manipulation using deep reinforcement learning and knowledge transfer for complex sparse reward-based tasks. Expert Syst. 2022, e13205. [Google Scholar] [CrossRef]
- Luu, T.M.; Yoo, C.D. Hindsight Goal Ranking on Replay Buffer for Sparse Reward Environment. IEEE Access 2021, 9, 51996–52007. [Google Scholar] [CrossRef]
- Eppe, M.; Magg, S.; Wermter, S. Curriculum goal masking for continuous deep reinforcement learning. In Proceedings of the 2019 Joint IEEE 9th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Norway, 19–22 August 2019; pp. 183–188. [Google Scholar]
- Sehgal, A.; La, H.; Louis, S.; Nguyen, H. Deep reinforcement learning using genetic algorithm for parameter optimization. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 596–601. [Google Scholar]
- Sehgal, A.; Ward, N.; La, H.; Louis, S. Automatic parameter optimization using genetic algorithm in deep reinforcement learning for robotic manipulation tasks. arXiv 2022, arXiv:2204.03656. [Google Scholar]
- Nair, A.V.; Pong, V.; Dalal, M.; Bahl, S.; Lin, S.; Levine, S. Visual reinforcement learning with imagined goals. arXiv 2018, arXiv:1807.04742. [Google Scholar] [CrossRef]
- Meng, Z.; She, C.; Zhao, G.; De Martini, D. Sampling, communication, and prediction co-design for synchronizing the real-world device and digital model in metaverse. IEEE J. Sel. Areas Commun. 2022, 41, 288–300. [Google Scholar] [CrossRef]
- Li, H.; Zhou, X.H.; Xie, X.L.; Liu, S.Q.; Gui, M.J.; Xiang, T.Y.; Wang, J.L.; Hou, Z.G. Discrete soft actor-critic with auto-encoder on vascular robotic system. Robotica 2022, 41, 1115–1126. [Google Scholar] [CrossRef]
- Wang, D.; Jia, M.; Zhu, X.; Walters, R.; Platt, R. On-robot learning with equivariant models. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022. [Google Scholar]
- Jian, P.; Yang, C.; Guo, D.; Liu, H.; Sun, F. Adversarial Skill Learning for Robust Manipulation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 2555–2561. [Google Scholar]
- Janisch, J.; Pevnỳ, T.; Lisỳ, V. Symbolic Relational Deep Reinforcement Learning based on Graph Neural Networks. arXiv 2020, arXiv:2009.12462. [Google Scholar]
- Almasan, P.; Suárez-Varela, J.; Badia-Sampera, A.; Rusek, K.; Barlet-Ros, P.; Cabellos-Aparicio, A. Deep reinforcement learning meets graph neural networks: Exploring a routing optimization use case. arXiv 2019, arXiv:1910.07421. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, A.S.; Undersander, E.; Rai, A. Efficient and interpretable robot manipulation with graph neural networks. arXiv 2021, arXiv:2102.13177. [Google Scholar] [CrossRef]
- Sieb, M.; Xian, Z.; Huang, A.; Kroemer, O.; Fragkiadaki, K. Graph-structured visual imitation. In Proceedings of the Conference on Robot Learning, Online, 16–18 November 2020; pp. 979–989. [Google Scholar]
- Xie, F.; Chowdhury, A.; De Paolis Kaluza, M.; Zhao, L.; Wong, L.; Yu, R. Deep imitation learning for bimanual robotic manipulation. Adv. Neural Inf. Process. Syst. 2020, 33, 2327–2337. [Google Scholar]
- Liang, J.; Boularias, A. Learning Category-Level Manipulation Tasks from Point Clouds with Dynamic Graph CNNs. arXiv 2022, arXiv:2209.06331. [Google Scholar]
- Oliva, M.; Banik, S.; Josifovski, J.; Knoll, A. Graph Neural Networks for Relational Inductive Bias in Vision-based Deep Reinforcement Learning of Robot Control. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–9. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Description |
|---|---|
| Keywords | “reinforcement learning” AND “robotic manipulation” AND “manipulation tasks” AND “control policies” |
| Search engine | Google Scholar, IEEE Xplore, or ArXiv |
| Time period | Between 2015 and the present |
| Publication type | Academic conference paper and journal articles |
| Relevance | Exclude studies that are not appropriate for the scope of the review |
| Outdated | Exclude old papers that are no longer relevant to the current state of the field |
| Quality | Exclude poorly written or methodologically flawed papers |
| Methods | Value-Based | Policy-Based | Actor–Critic |
|---|---|---|---|
| On-Policy | Monte Carlo Learning/ SARSA | REINFORCE(PG) | A2C/ A3C/ TRPO/ PPO |
| Off-Policy | Q-learning/ DQN Double/ Dueling | DDPG/ TD3/ SAC |
| RL Algorithm | Strengths | Limitations |
|---|---|---|
| Q-Learning | Straightforward and easy to use, capable of handling discrete state and action spaces, eventually converges to the best possible policy | Suffers from slow convergence, difficulty using in continuous action spaces |
| SARSA | Manages stochastic environments and policies | Slow convergence and difficulty using in continuous action areas |
| Deep Q-Networks (DQN) | Handle high-dimensional state spaces, directly learns from sensory data | Difficulty using in continuous action spaces, overestimation of Q-values |
| Policy Gradient | Handles continuous action spaces, learns stochastic policies, optimizes non-differentiable objective functions | High variance in gradients, sensitive to hyperparameters |
| Actor–Critic | Combines the advantages of policy gradient and value-based approaches, handles continuous and discrete action spaces, concurrently updates policy and value function | Difficult to balance exploration and exploitation, high variance in gradients |
| DDPG | Handles continuous action spaces and high-dimensional state spaces, learns deterministic policies, | Instability, overestimation bias |
| TD3 | Same as DDPG and solves overestimation bias | Instability, careful tuning of hyperparameters |
| SAC | Same as TD3 and optimizes entropy-regularized objectives | Computationally expensive, careful tuning of hyperparameters |
| Methods | RL Algorithms | Learning Techniques |
|---|---|---|
| Learning by playing and solving sparse reward tasks from scratch [56] | Q-learning and DDPG | Scheduled auxiliary control and hierarchical RL |
| Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards [57] | DDPG | Demonstration and reward shaping |
| Reinforcement learning for robotic manipulation using simulated locomotion demonstrations [58] | DDPG and HER | Simulated demonstrations and behavior cloning |
| Robotic manipulation with reinforcement learning, state representation learning, and imitation learning [59] | PPO and DQN | State representation learning (SRL) |
| Disentangled attention intrinsic regularization for safe and efficient bimanual manipulation [60] | SAC | Attention mechanism |
| Motion planner augmented reinforcement learning for robot manipulation in obstructed environments [61] | SAC | Motion planning augment action space re-scaling |
| Open-source multi-goal reinforcement learning environment for robotic manipulation [62] | DDPG and HER | Human-prior-based curriculum learning |
| Improved learning of robot manipulation tasks via tactile intrinsic motivation [63] | DDPG and CPER | Intrinsic motivation and tactile feedback |
| Residual policy learning [64] | DDPG and HER | Residual policy learning |
| Learning to control a low-cost manipulator using data-efficient reinforcement learning [65] | Model-based approach | Transfer learning |
| Towards practical multi-object manipulation using relational reinforcement learning [66] | SAC and HER | Sequential curriculum learning |
| Data-efficient deep reinforcement learning for dexterous manipulation [67] | DDPG and A3C | Reward shaping |
| Sim-to-real robot learning from pixels with progressive nets [68] | A3C | Transfer learning |
| Overcoming exploration in reinforcement learning with demonstrations [69] | DDPG and HER | Imitation learning |
| Asymmetric self-play for automatic goal discovery in robotic manipulation [70] | PPO | Asymmetric self-play |
| A framework for efficient robotic manipulation [71] | SAC | Imitation learning |
| Robotic arm control and task training through deep reinforcement learning [72] | DQN and TRPO | Curriculum learning |
| Method of robot grasping based on reinforcement learning [73] | DQN | Priority experience replay |
| Residual learning from demonstration: adapting dmps for contact-rich manipulation [74] | PPO | Behavior cloning |
| Learning insertion primitives with discrete-continuous hybrid action space for robotic assembly tasks [75] | Multi-pass DQN | Transfer learning |
| Offline meta-reinforcement learning for industrial insertion [76] | A2C | Demonstration |
| Impedance control and parameter optimization of surface polishing robot based on reinforcement learning [77] | PG | Dynamic matching and linearization |
| Robotic architectural assembly with tactile skills: Simulation and optimization [78] | TD3 | Transfer learning |
| Manipulation planning from demonstration via goal-conditioned prior action primitive decomposition and alignment [79] | DAPG | Imitation learning and hierarchical RL |
| Reinforcement learning with vision-proprioception model for robot planar pushing [80] | SAC | Variational autoencoder |
| Object manipulation system based on image-based reinforcement learning [81] | SAC | Transfer learning |
| Augmenting reinforcement learning with behavior primitives for diverse manipulation tasks [82] | MAPLE | Hierarchical RL |
| Evaluation of variable impedance and hybrid force/motion controllers for learning force tracking skills [83] | Model-based PILCO [84] | Hybrid force/motion control |
| Context meta-reinforcement learning via neuromodulation [85] | SAC | Meta-RL |
| Safe learning in robotics: from learning-based control to safe reinforcement learning [86] | PPO | Model predictive safety certification [87] |
| Prioritized hindsight with dual buffer for meta-reinforcement learning [88] | SAC | Prioritized hindsight with dual experience replay |
| Object detection-based one-shot imitation learning with an RGB-D camera [89] | PG | Auto-encoder and object detection network |
| Retinagan: an object-aware approach to sim-to-real transfer [90] | Q2-OPT | GAN and imitation learning |
| Reference Papers | RL Algorithms | Learning Techniques |
|---|---|---|
| [152] | DQN and GNN | Evaluate on OTN routing map |
| [125] | Blueprint policy and PPG | Curriculum learning |
| [151] | GNN and A2C | Behavior cloning |
| [153] | PPO | Imitation learning |
| [66] | GNN and SAC | Sequential curriculum learning |
| [154] | Model-based method | Imitation learning |
| [155] | MDP and GAT | Hierarchical imitation learning |
| [156] | PG and GCN | GAIL |
| [157] | PPO and GCN | Relational Inductive Bias |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, D.; Mulyana, B.; Stankovic, V.; Cheng, S. A Survey on Deep Reinforcement Learning Algorithms for Robotic Manipulation. Sensors 2023, 23, 3762. https://doi.org/10.3390/s23073762
Han D, Mulyana B, Stankovic V, Cheng S. A Survey on Deep Reinforcement Learning Algorithms for Robotic Manipulation. Sensors. 2023; 23(7):3762. https://doi.org/10.3390/s23073762
Chicago/Turabian StyleHan, Dong, Beni Mulyana, Vladimir Stankovic, and Samuel Cheng. 2023. "A Survey on Deep Reinforcement Learning Algorithms for Robotic Manipulation" Sensors 23, no. 7: 3762. https://doi.org/10.3390/s23073762
APA StyleHan, D., Mulyana, B., Stankovic, V., & Cheng, S. (2023). A Survey on Deep Reinforcement Learning Algorithms for Robotic Manipulation. Sensors, 23(7), 3762. https://doi.org/10.3390/s23073762