
Exploring Prosodic Features Modelling for Secondary Emotions Needed for Empathetic Speech Synthesis

Abstract
:1. Introduction
2. Past Studies on Emotional Speech Synthesis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Speech Synthesis Method | Emotional Speech Synthesis Method | Features Modelled | Resources Needed | Naturalness | Emotions Modelled |
|---|---|---|---|---|---|
| 1993 [13] Diphone synthesis | Rule-based | Duration and | All possible diphones in a language have to be recorded for neutral TTS , e.g., 2431 diphones in British English. An emotional speech database (312 sentences) to frame rules is needed | Average | Neutral, joy, boredom, anger, sadness, fear and indignation |
| 1995 [9] Formant synthesis | Rule-based | Prosody features such as pitch, duration, voice quality features | DECtalk synthesiser was used containing approximately 160,000 lines of C code. Emotion rules framed from past research | Average | Anger, happiness, sadness, fear, disgust and grief |
| 2004 [14] Parametric speech synthesis | Style control vector associated with the target style transforms the mean vectors of the neutral HMM models | , mel cepstrum | 504 phonetically balanced sentences for average voice, and at least 10 sentences of each of the styles | Good | Three styles: rough, joyful and sad |
| 2006 [10] Recorded neutral speech used as it is | Rule-based using GMM and CART | , duration | Corpus with 1500 sentences | Average | Neutral, happiness, sadness, fear and anger |
| 2006 [15] Parametric speech synthesis | Corpus-based using decision trees | contours, timing | 11 h (excluding silence) of neutral sentences + 1 h emotional speech | Good | Conveying bad news, yes-no questions |
| 2007 [16] Parametric speech synthesis | Model adaptation on average voice | Mel cepstrum, log | 503 phonetically balanced sentences for average voice, and at least 10 sentences of a particular style | Good | Speaking styles of speakers in the database |
| 2010 [17] Neutral voice not created | HMM-based parametric speech synthesis | Spectral envelope, , duration | Spanish expressive voices corpus-100 min per emotion | Good | Happiness, sadness, anger, surprise, fear and disgust |
| 2017 [12] Parametric speech synthesis using recurrent neural networks with long short-term memory units | Emotion-dependent modelling and unified modelling with emotion codes | Spectrogram | 5.5 h emotional speech data + speaker-independent model from 100 h speech data | Reported to be better than HMM-based synthesis | Neutral, happiness, anger and sadness |
| 2018 [11] Tacotron-based end-to-end synthesis using DNN (Deep neural network-Tacotron model learning a latent embedding space) | Prosody transfer | Spectrogram | English dataset of audiobook recordings-147 h | Reported to be better than HMM-based synthesis | Speaking styles of speakers in the database |
| 2019 [18] Deep Convolutional TTS | Emotion adaptation from neutral TTS to emotional TTS | Spectrogram | Large dataset (24 h) of neutral speech + 7000 emotional speech sentences (5 emotions) | Reported to be better than HMM-based synthesis | Anger, happiness, sadness and neutral |
Emotional Speech Corpus
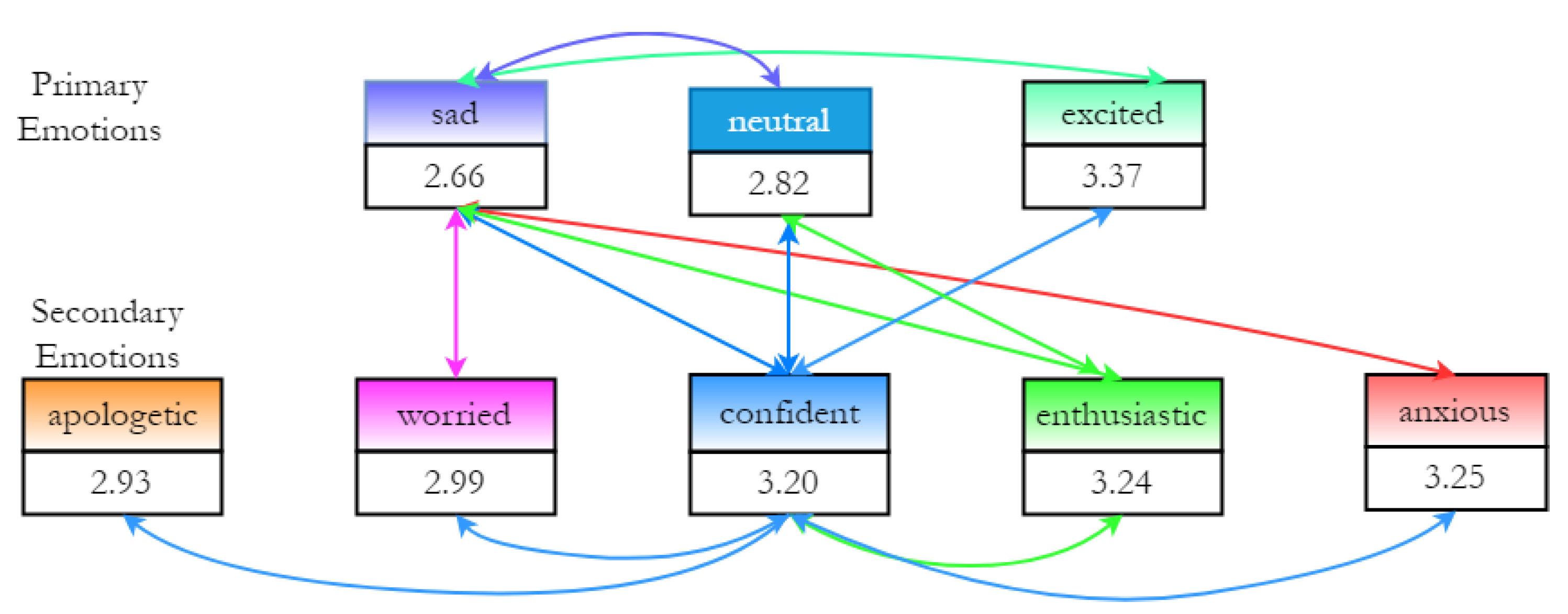
- Research question 1: Can prosody features be used to model secondary emotions?
- Research question 2: How can a low-resource emotional text-to-speech synthesis system be developed for secondary emotions?
3. Emotional Speech Corpus Analysis
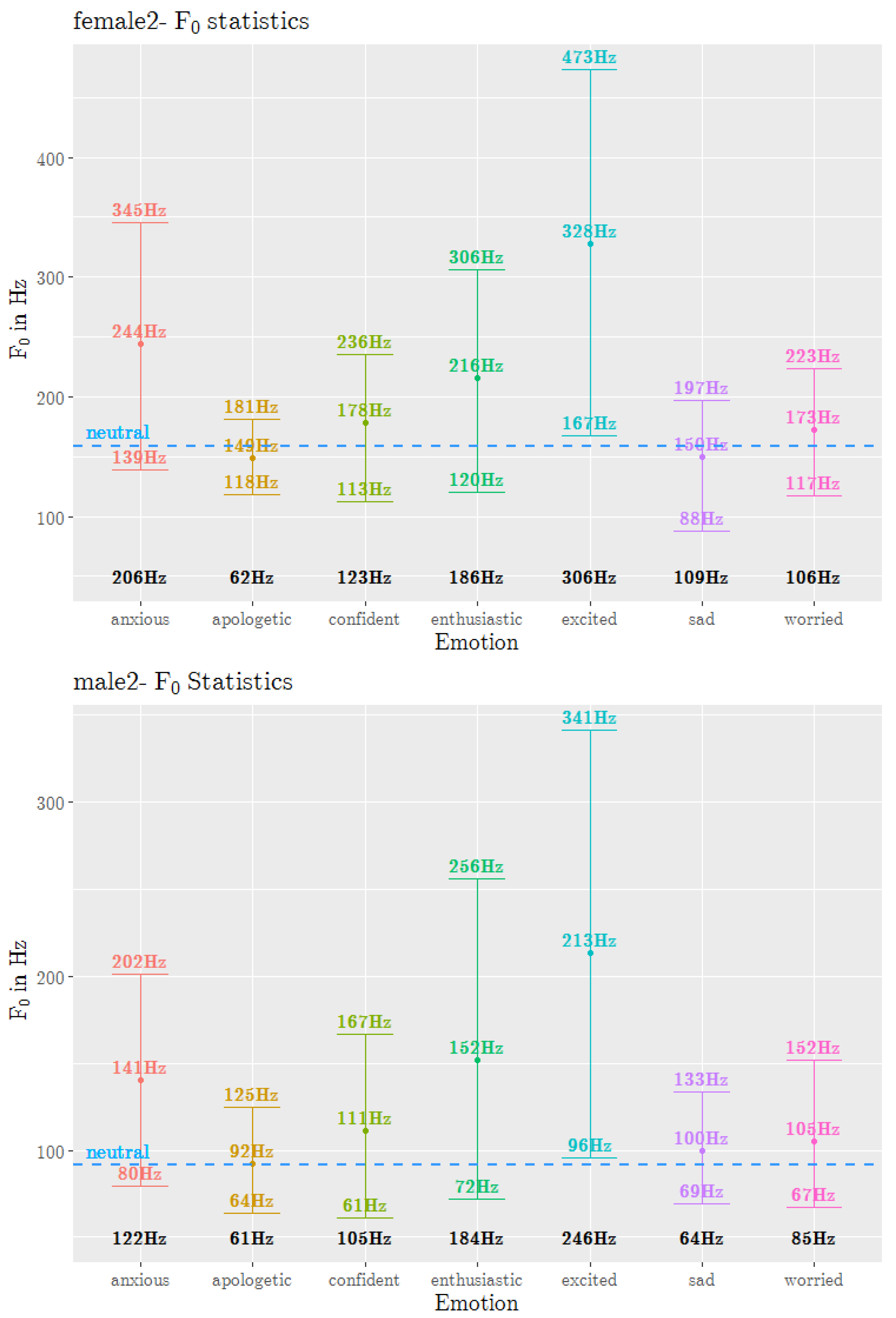
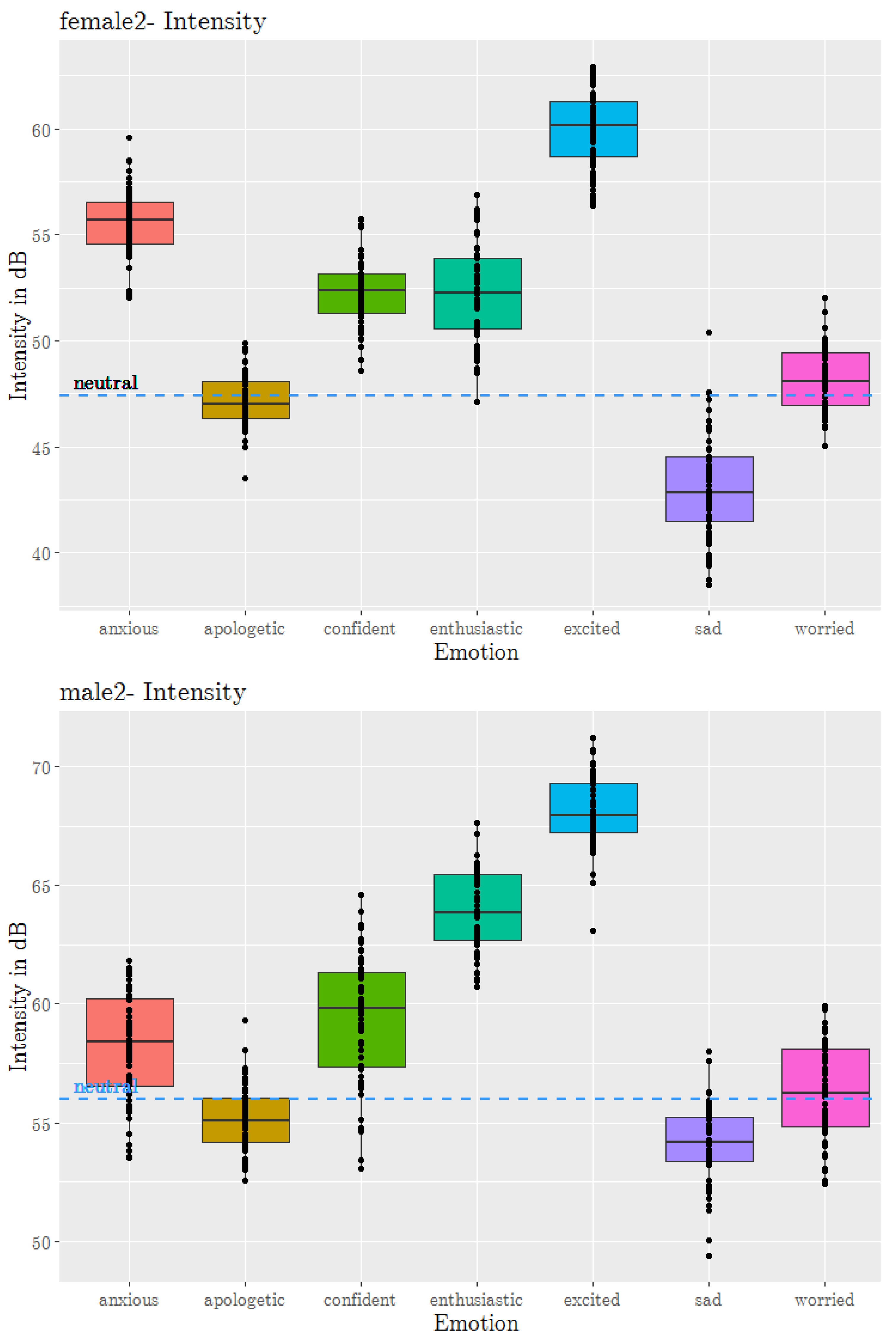
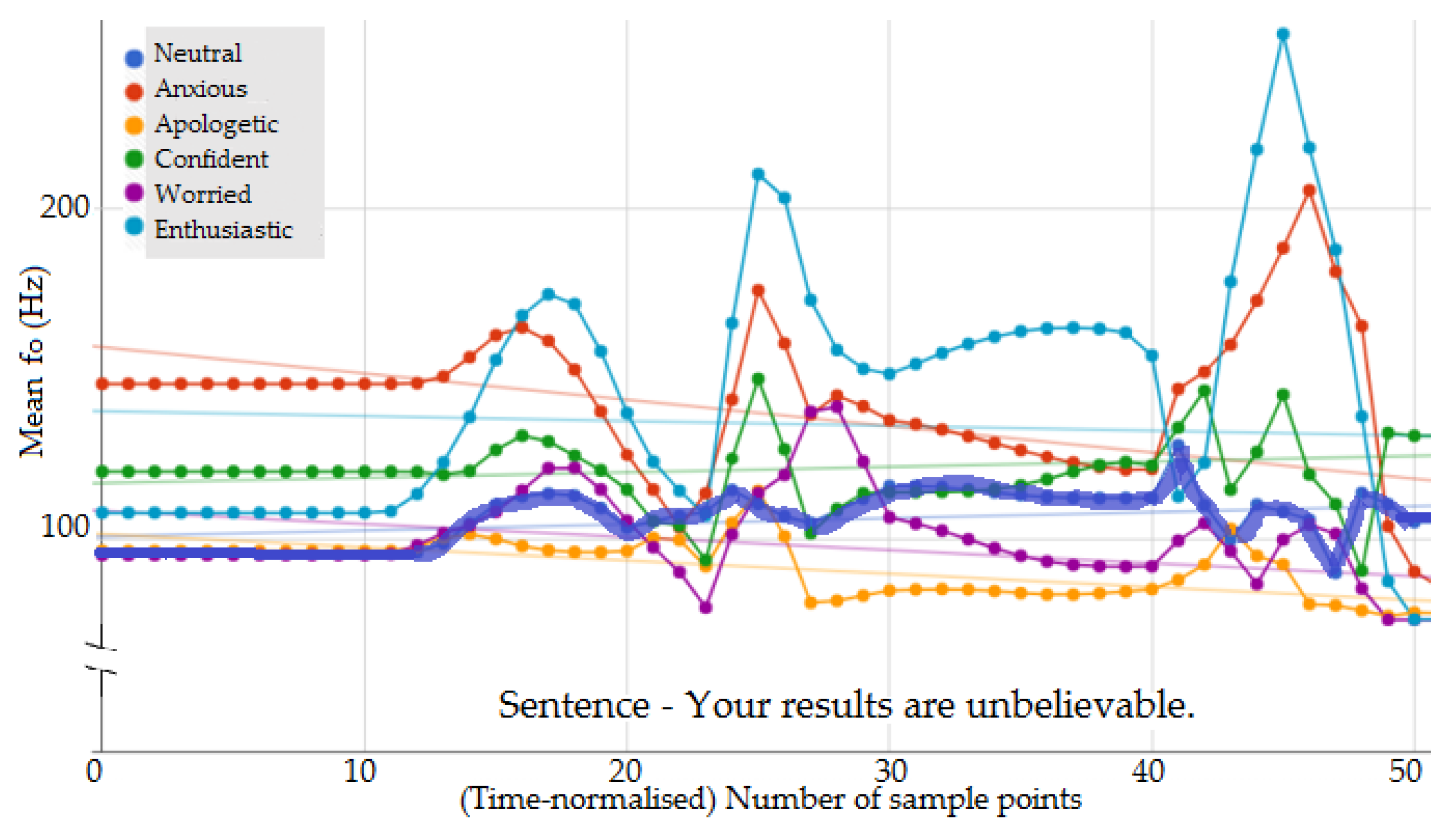
3.1. Prosody Feature Analysis
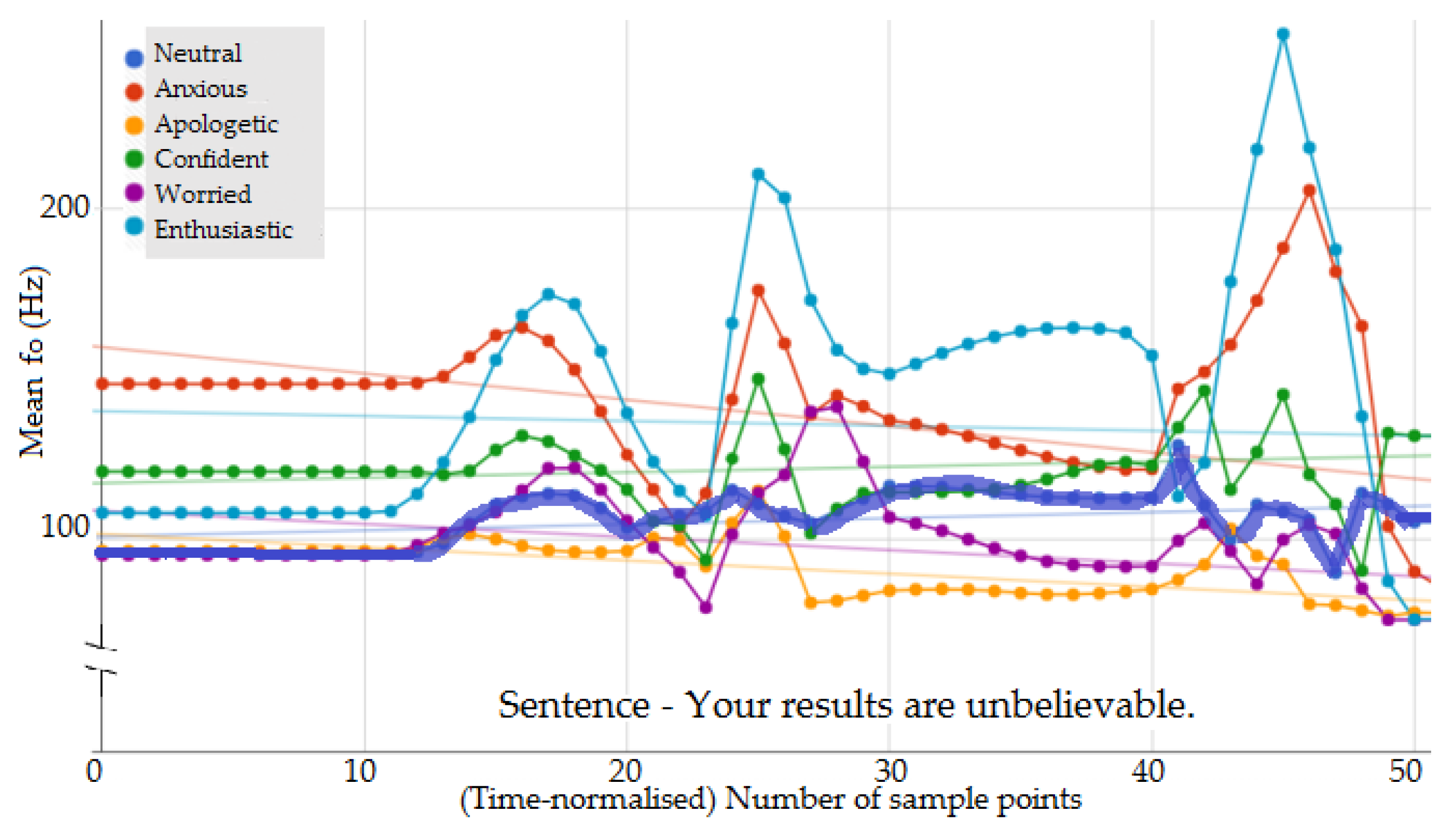
3.2. Contour Analysis
- 1.
- Phrase command onset time (): Onset time of the phrasal contour, typically before the segmental onset of the phrase of the ensuing prosodic phrase. Phrase command duration Dur_phr= End of phrase time-.
- 2.
- Phrase command amplitude (): magnitude of the phrase command that precedes each new prosodic phrase, quantifying the reset of the declining phrase component.
- 3.
- Accent command amplitude (): amplitude of the accent command associated with every pitch accent.
- 4.
- Accent command onset time () and offset time (): The timing of the accent command can be related to the timing of the underlying segments. Accent command duration Dur_acc = −.

- -Bias level upon which all the phrase and accent components are superposed to form an contour.
- -Natural angular frequency of the jth accent command.
- -Natural angular frequency of the jth phrase command.
- I-Number of phrase commands.
- J-Number of accent commands.
- -Magnitude of the ith phrase command.
- -Magnitude of the jth accent command.
- -Instant of occurrence of the ith phrase command.
- -Onset of the jth accent command.
- -Offset of the jth accent command.
- -Ceiling level of the accent component for the jth accent command.
3.2.1. Fujisaki Parameterisation of Contour
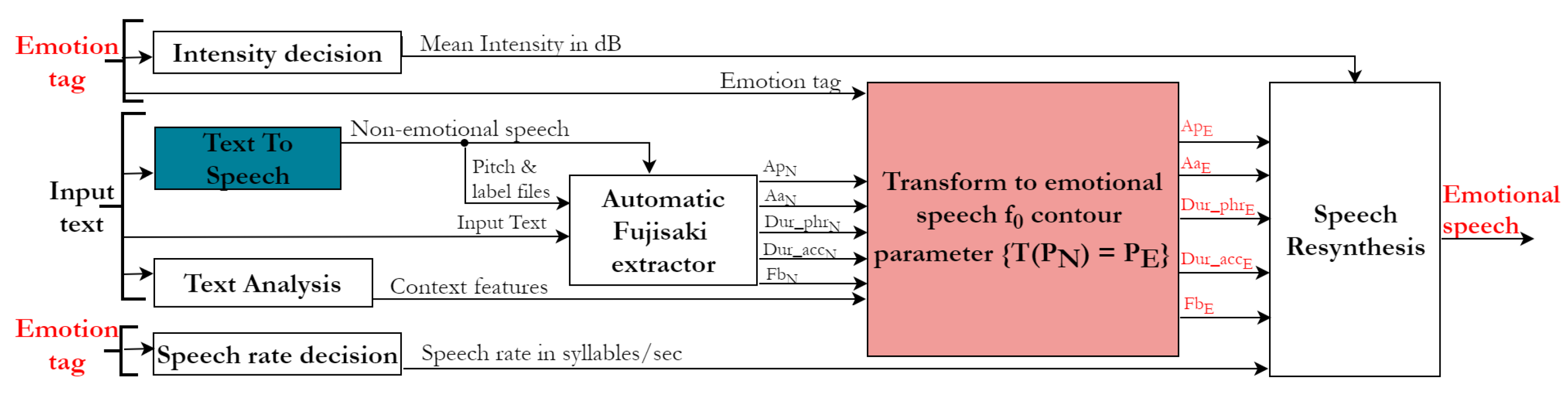
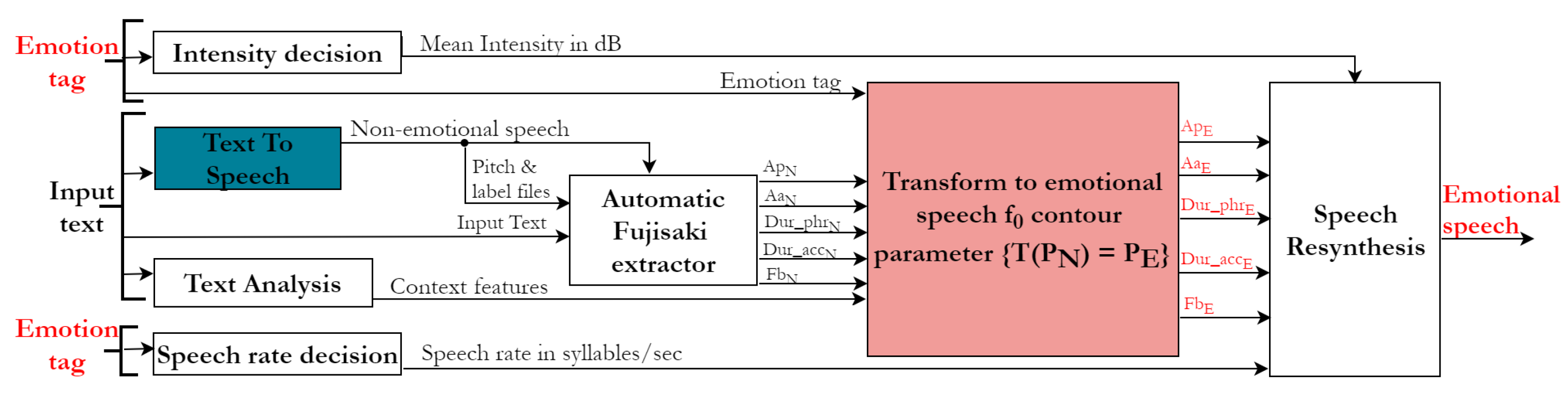
4. Emotional TTS Synthesis System Development
4.1. Text-to-Speech Module
4.2. Automatic Fujisaki Extractor
4.3. Transformation to Emotional Speech Parameters
4.3.1. Features for the Regression Model
4.3.2. Contour Transformation Model
4.3.3. Using the Transformation Model
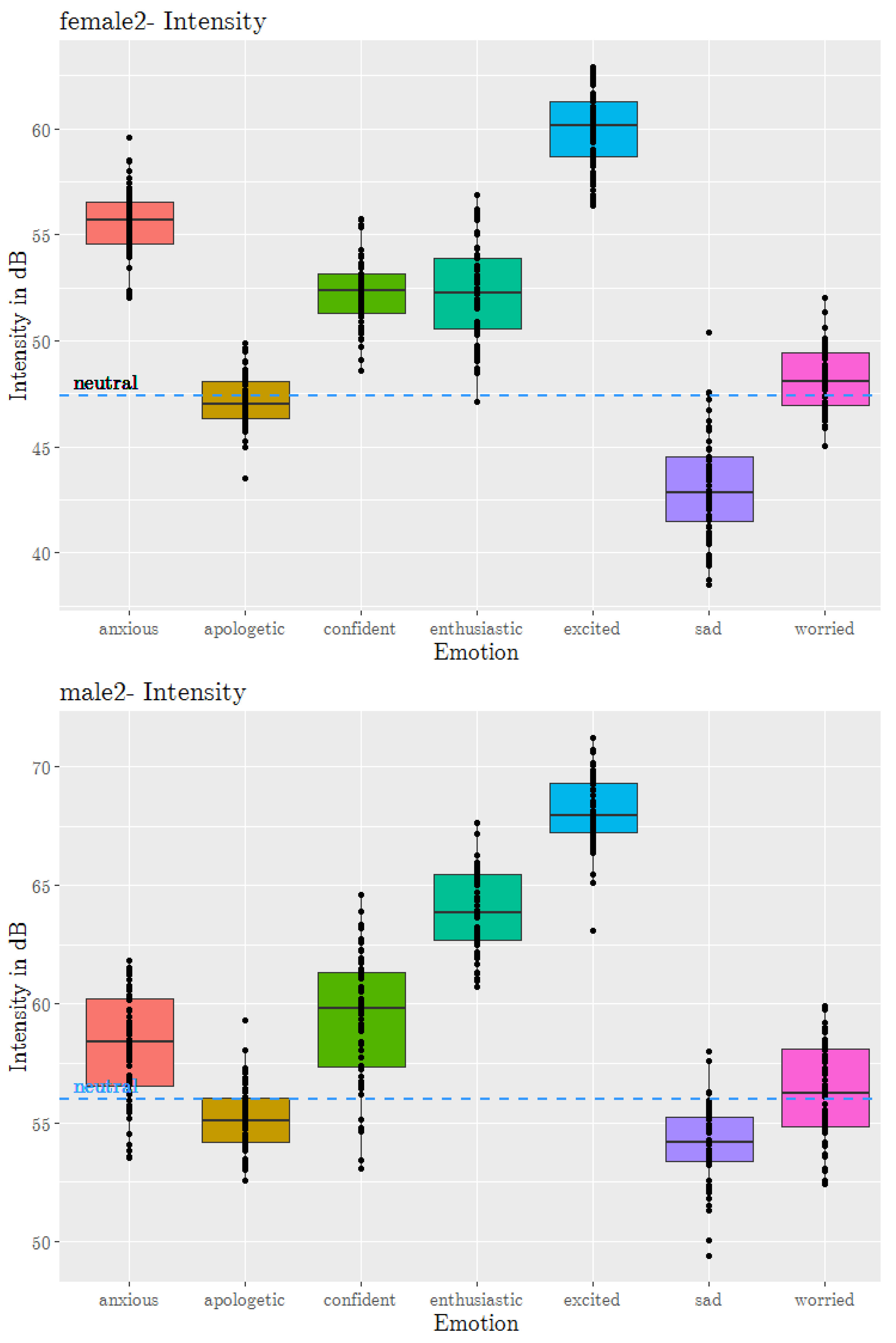
4.4. Speech Rate and Mean Intensity Modelling
4.5. Resynthesis
5. Performance Analysis and Results
5.1. Task I-Pairwise Forced-Response Test for Five Secondary Emotions
5.2. Task II-Free-Response Test for Five Secondary Emotions
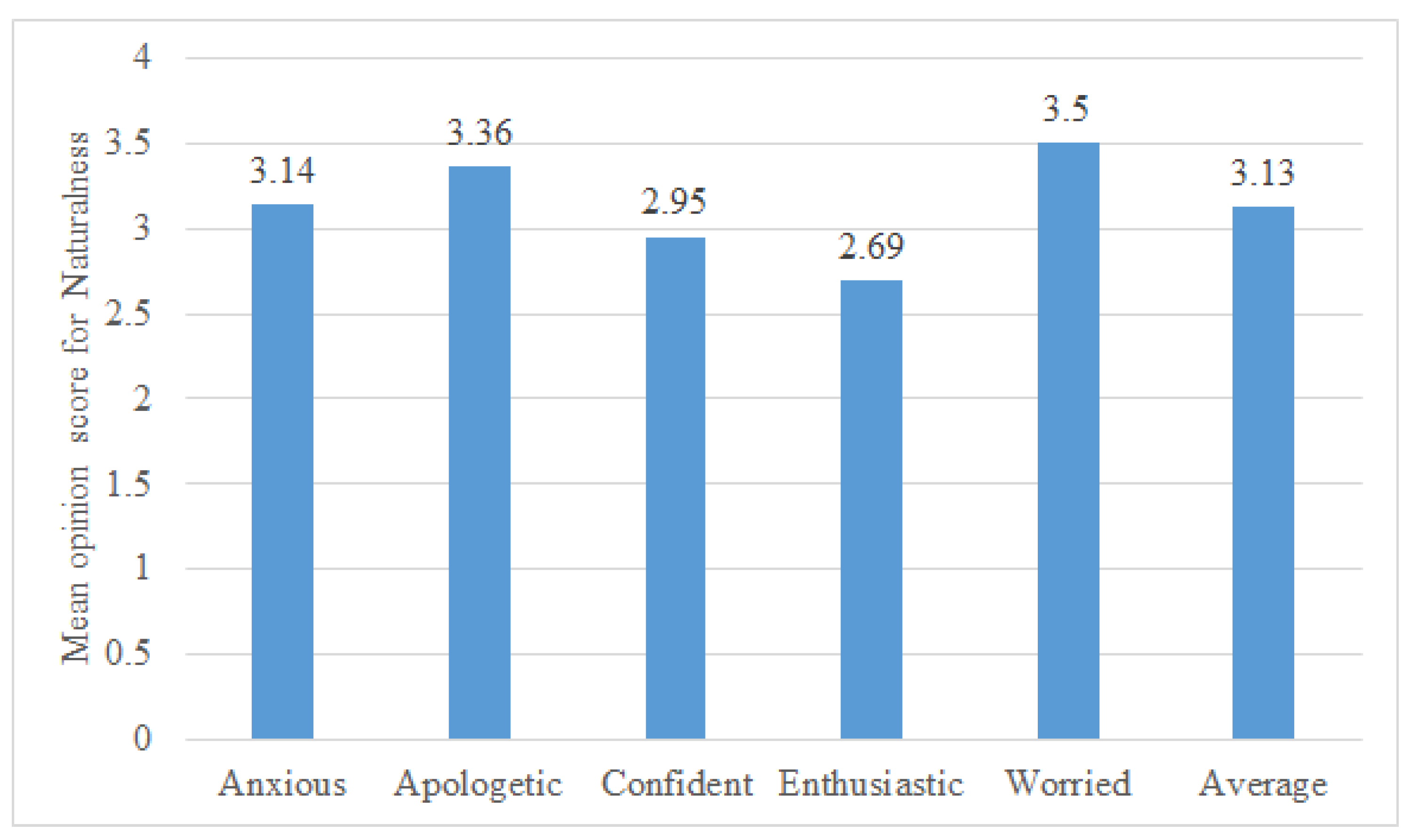
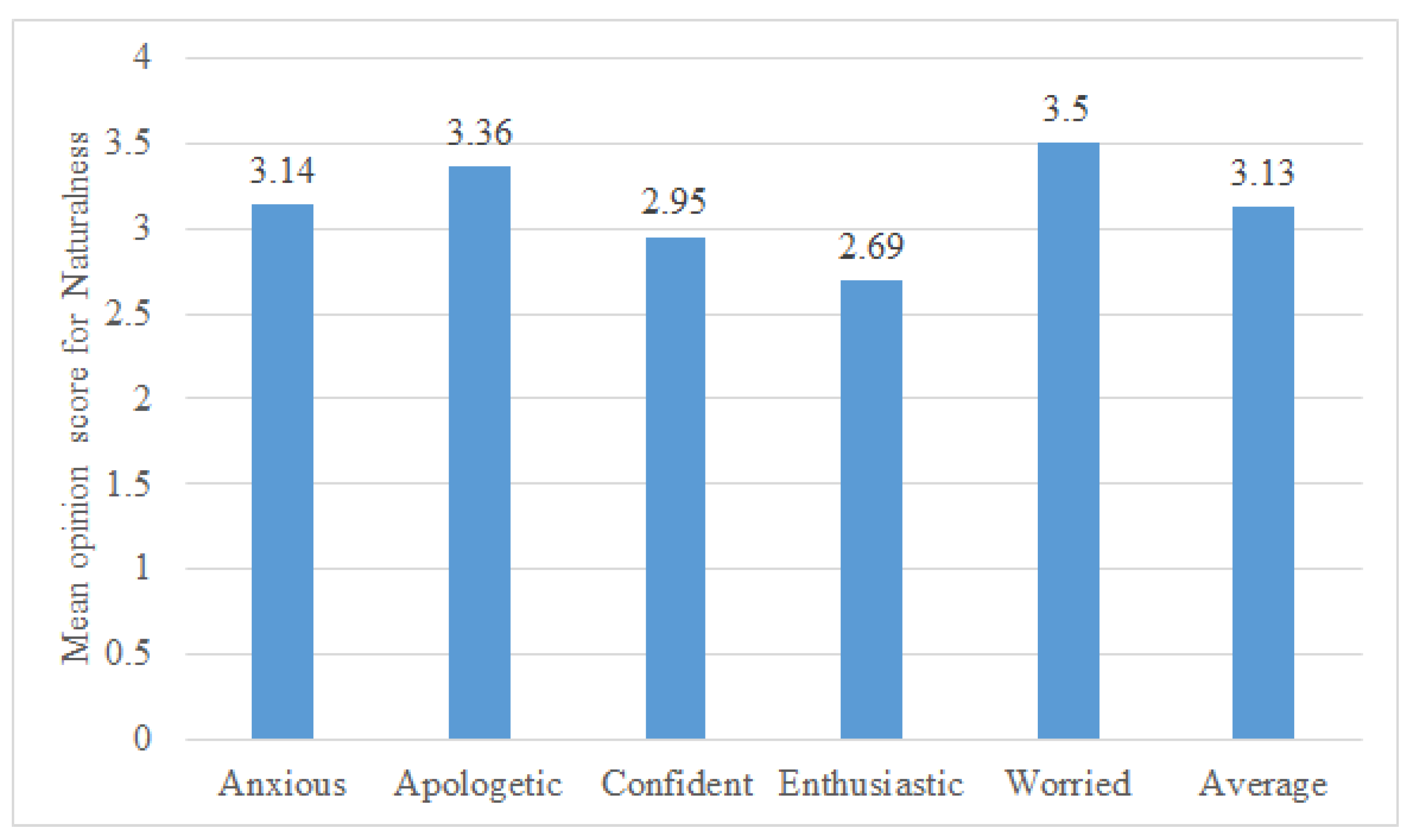
5.3. Task III-Naturalness Rating on Five-Point Scale
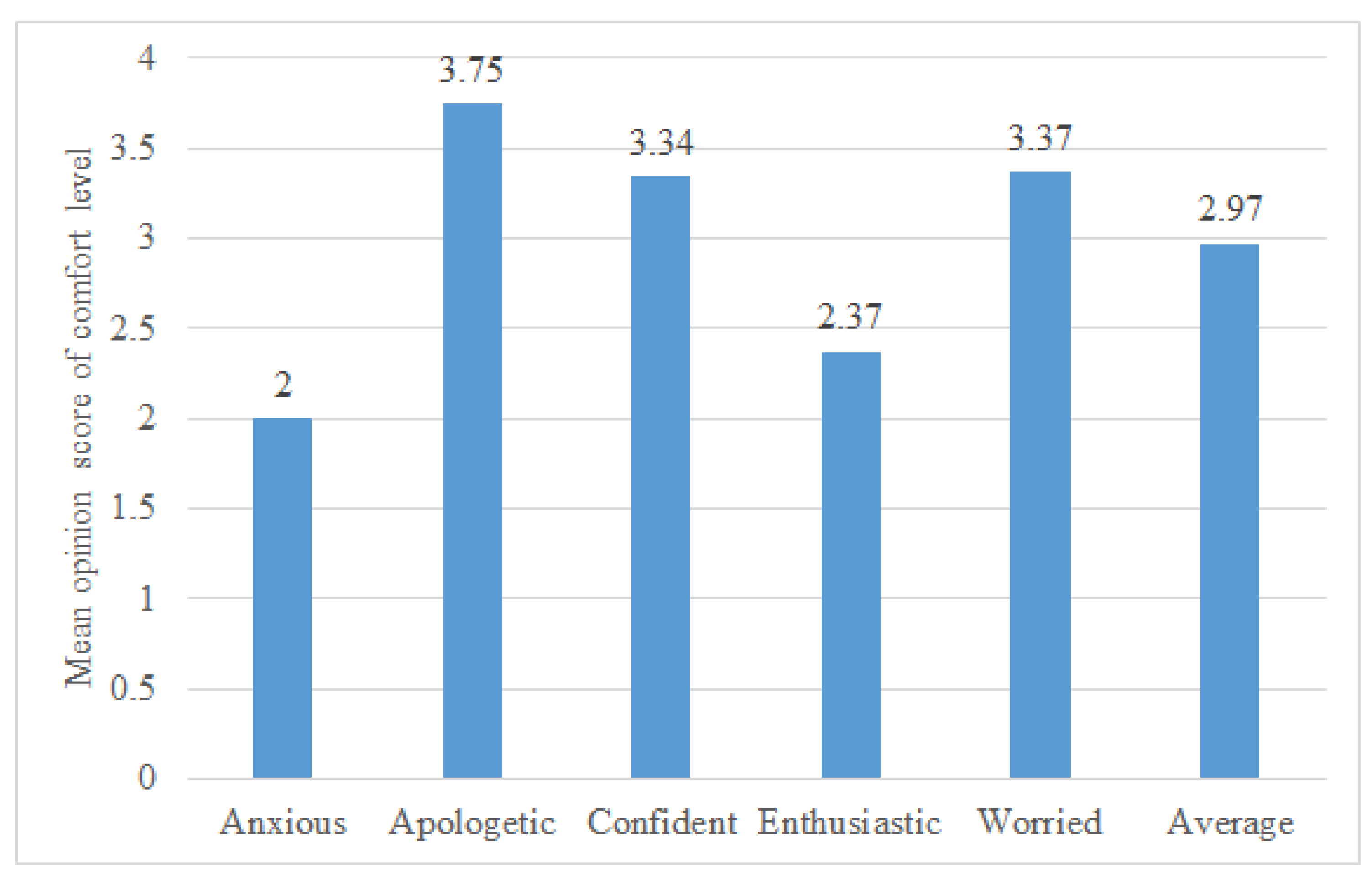
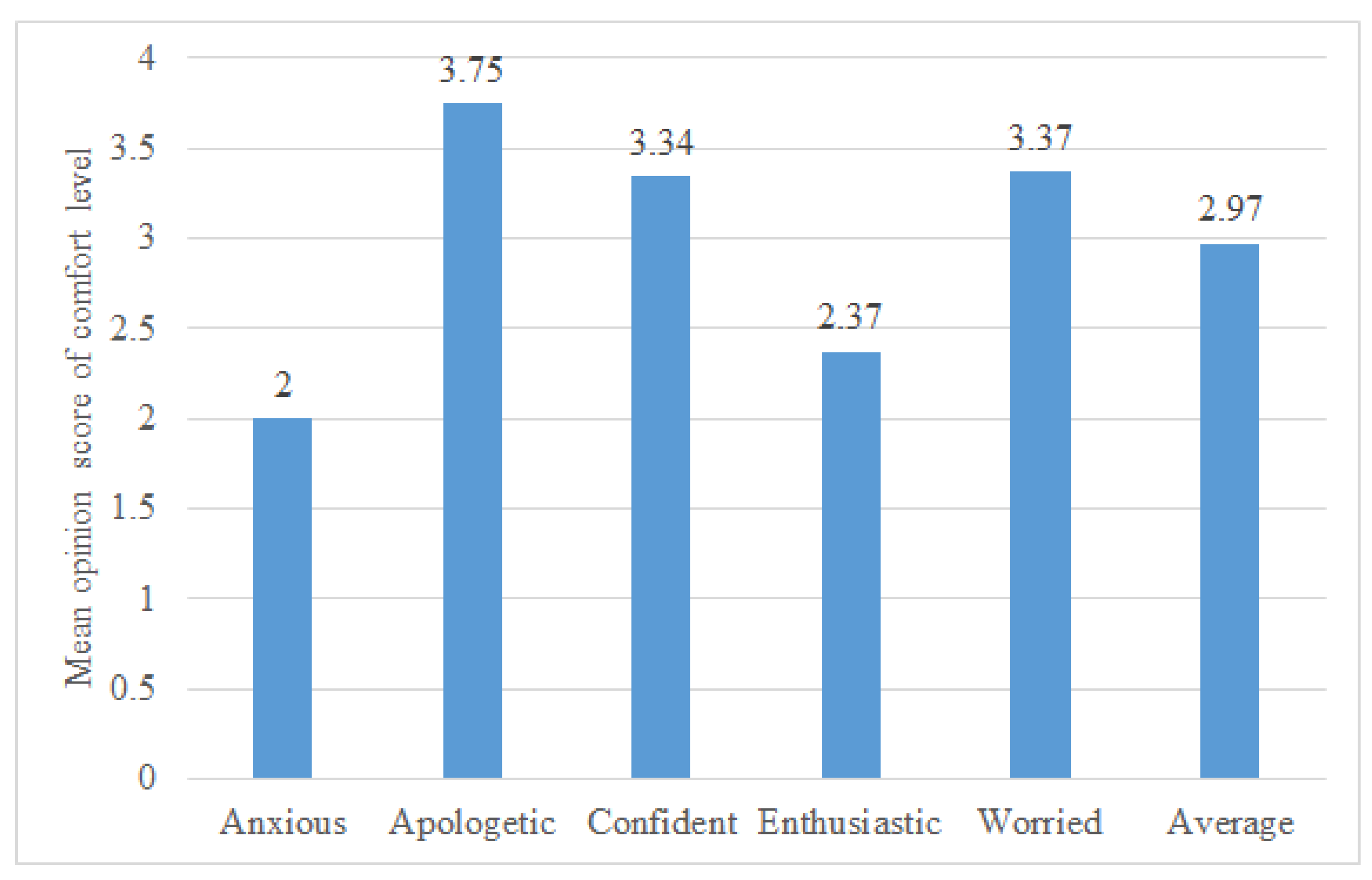
5.4. Task IV-Comfort Level Rating on Five-Point Scale
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eyssel, F.; Ruiter, L.D.; Kuchenbrandt, D.; Bobinger, S.; Hegel, F. ‘If you sound like me, you must be more human’: On the interplay of robot and user features on human-robot acceptance and anthropomorphism. In Proceedings of the International Conference on Human-Robot Interaction, Boston, MA, USA, 5–8 March 2012; pp. 125–126. [Google Scholar]
- James, J.; Watson, C.I.; MacDonald, B. Artificial empathy in social robots: An analysis of emotions in speech. In Proceedings of the IEEE International Symposium on Robot & Human Interactive Communication, Nanjing, China, 27–31 August 2018; pp. 632–637. [Google Scholar]
- James, J.; Balamurali, B.; Watson, C.I.; MacDonald, B. Empathetic Speech Synthesis and Testing for Healthcare Robots. Int. J. Soc. Robot. 2020, 13, 2119–2137. [Google Scholar] [CrossRef]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Schröder, M. Emotional Speech Synthesis: A Review. In Proceedings of the Eurospeech, Alborg, Denmark, 3–7 September 2001; pp. 561–564. [Google Scholar]
- Becker-Asano, C.; Wachsmuth, I. Affect Simulation with Primary and Secondary Emotions. In Proceedings of the Intelligent Virtual Agents, Tokyo, Japan, 1–3 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5208, pp. 15–28. [Google Scholar]
- Damasio, A. Descartes’ Error, Emotion Reason and the Human Brain; Avon Books: New York, NY, USA, 1994. [Google Scholar]
- James, J.; Watson, C.; Stoakes, H. Influence of Prosodic features and semantics on secondary emotion production and perception. In Proceedings of the International Congress of Phonetic Sciences, Melbourne, Australia, 5–9 August 2019; pp. 1779–1782. [Google Scholar]
- Murray, I.R.; Arnott, J.L. Implementation and testing of a system for producing emotion-by-rule in synthetic speech. Speech Commun. 1995, 16, 369–390. [Google Scholar] [CrossRef]
- Tao, J.; Kang, Y.; Li, A. Prosody conversion from neutral speech to emotional speech. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1145–1154. [Google Scholar]
- Skerry-Ryan, R.; Battenberg, E.; Xiao, Y.; Wang, Y.; Stanton, D.; Shor, J.; Weiss, R.J.; Clark, R.; Saurous, R.A. Towards end-to-end prosody transfer for expressive speech synthesis with tacotron. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4693–4702. [Google Scholar]
- An, S.; Ling, Z.; Dai, L. Emotional statistical parametric speech synthesis using LSTM-RNNs. In Proceedings of the APSIPA Conference, Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1613–1616. [Google Scholar]
- Vroomen, J.; Collier, R.; Mozziconacci, S. Duration and intonation in emotional speech. In Proceedings of the Third European Conference on Speech Communication and Technology, Berlin, Germany, 19–23 September 1993. [Google Scholar]
- Masuko, T.; Kobayashi, T.; Miyanaga, K. A style control technique for HMM-based speech synthesis. In Proceedings of the International Conference on Spoken Language Processing, Jeju, Republic of Korea, 8 October 2004; pp. 1437–1440. [Google Scholar]
- Pitrelli, J.F.; Bakis, R.; Eide, E.M.; Fernandez, R.; Hamza, W.; Picheny, M.A. The IBM expressive text-to-speech synthesis system for American English. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1099–1108. [Google Scholar] [CrossRef]
- Yamagishi, J.; Kobayashi, T.; Tachibana, M.; Ogata, K.; Nakano, Y. Model adaptation approach to speech synthesis with diverse voices and styles. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 16–20 April 2007; p. 1236. [Google Scholar]
- Barra-Chicote, R.; Yamagishi, J.; King, S.; Montero, J.M.; Macias-Guarasa, J. Analysis of statistical parametric and unit selection speech synthesis systems applied to emotional speech. Speech Commun. 2010, 52, 394–404. [Google Scholar] [CrossRef] [Green Version]
- Tits, N. A Methodology for Controlling the Emotional Expressiveness in Synthetic Speech-a Deep Learning approach. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Cambridge, UK, 3–6 September 2019; pp. 1–5. [Google Scholar]
- Zhang, M.; Tao, J.; Jia, H.; Wang, X. Improving HMM based speech synthesis by reducing over-smoothing problems. In Proceedings of the International Symposium on Chinese Spoken Language Processing, Singapore, 11–14 September 2008; pp. 1–4. [Google Scholar]
- Murray, I.; Arnott, J.L. Toward the simulation of emotion in synthetic speech: A review of the literature on human vocal emotion. J. Acoust. Soc. Am. 1993, 93, 1097–1108. [Google Scholar] [CrossRef] [PubMed]
- James, J.; Tian, L.; Watson, C. An open source emotional speech corpus for human robot interaction applications. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2768–2772. [Google Scholar]
- Scherer, K. What are emotions? And how can they be measured? Soc. Sci. Inf. 2005, 44, 695–729. [Google Scholar] [CrossRef]
- Paltoglou, G.; Thelwall, M. Seeing Stars of Valence and Arousal in Blog Posts. IEEE Trans. Affect. Comput. 2013, 4, 116–123. [Google Scholar] [CrossRef]
- Sitaula, C.; He, J.; Priyadarshi, A.; Tracy, M.; Kavehei, O.; Hinder, M.; Withana, A.; McEwan, A.; Marzbanrad, F. Neonatal Bowel Sound Detection Using Convolutional Neural Network and Laplace Hidden Semi-Markov Model. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1853–1864. [Google Scholar] [CrossRef]
- Burne, L.; Sitaula, C.; Priyadarshi, A.; Tracy, M.; Kavehei, O.; Hinder, M.; Withana, A.; McEwan, A.; Marzbanrad, F. Ensemble Approach on Deep and Handcrafted Features for Neonatal Bowel Sound Detection. IEEE J. Biomed. Health Inform. 2022, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Winkelmann, R.; Harrington, J.J.K. EMU-SDMS: Advanced speech database management and analysis in R. Comput. Speech Lang. 2017, 45, 392–410. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- James, J.; Mixdorff, H.; Watson, C. Quantitative model-based analysis of F0 contours of emotional speech. In Proceedings of the International Congress of Phonetic Sciences, Melbourne, Australia, 5–9 August 2019; pp. 72–76. [Google Scholar]
- Hui, C.T.J.; Chin, T.J.; Watson, C. Automatic detection of speech truncation and speech rate. In Proceedings of the SST, Christchurch, New Zealand, 2–5 December 2014; pp. 150–153. [Google Scholar]
- Hirose, K.; Fujisaki, H.; Yamaguchi, M. Synthesis by rule of voice fundamental frequency contours of spoken Japanese from linguistic information. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Calgary, AB, Canada, 15–20 April 1984; Volume 9, pp. 597–600. [Google Scholar]
- Nguyen, D.T.; Luong, M.C.; Vu, B.K.; Mixdorff, H.; Ngo, H.H. Fujisaki Model based f0 contours in Vietnamese TTS. In Proceedings of the International Conference on Spoken Language Processing, Jeju, Republic of Korea, 8 October 2004; pp. 1429–1432. [Google Scholar]
- Gu, W.; Lee, T. Quantitative analysis of f0 contours of emotional speech of Mandarin. In Proceedings of the 8th ISCA Spee Synthesis Workshop, Barselona, Spain, 31 August–2 September 2007; pp. 228–233. [Google Scholar]
- Amir, N.; Mixdorff, H.; Amir, O.; Rochman, D.; Diamond, G.M.; Pfitzinger, H.R.; Levi-Isserlish, T.; Abramson, S. Unresolved anger: Prosodic analysis and classification of speech from a therapeutic setting. In Proceedings of the Speech Prosody, Chicago, IL, USA, 10–14 May 2010; p. 824. [Google Scholar]
- Mixdorff, H.; Cossio-Mercado, C.; Hönemann, A.; Gurlekian, J.; Evin, D.; Torres, H. Acoustic correlates of perceived syllable prominence in German. In Proceedings of the Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 51–55. [Google Scholar]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer [Computer Program]. Version 6.0.46. 2019. Available online: https://www.fon.hum.uva.nl/praat/ (accessed on 1 February 2022).
- Mixdorff, H. A novel approach to the fully automatic extraction of Fujisaki model parameters. In Proceedings of the IEEE Int. Conf. on Acoustics, Speech, and Signal Processing, Istanbul, Turkey, 5–9 June 2000; pp. 1281–1284. [Google Scholar]
- Mixdorff, H.; Fujisaki, H. A quantitative description of German prosody offering symbolic labels as a by-product. In Proceedings of the International Conference on Spoken Language Processing, Beijing, China, 16–20 October 2000; pp. 98–101. [Google Scholar]
- Watson, C.I.; Marchi, A. Resources created for building New Zealand English voices. In Proceedings of the Australasian International Conference of Speech Science and Technology, Parramatta, New Zealand, 6–9 December 2014; pp. 92–95. [Google Scholar]
- Jain, S. Towards the Creation of Customised Synthetic Voices using Hidden Markov Models on a Healthcare Robot. Master’s Thesis, The University of Auckland, Auckland, New Zealand, 2015. [Google Scholar]
- Schröder, M.; Trouvain, J. The German text-to-speech synthesis system MARY: A tool for research, development and teaching. Int. J. Speech Technol. 2003, 6, 365–377. [Google Scholar] [CrossRef]
- Boersma, P. Accurate short-term analysis of the fundamental frequency and the harmonics-to-noise ratio of a sampled sound. Inst. Phon. Sci. 1993, 17, 97–110. [Google Scholar]
- Kisler, T.; Schiel, F.; Sloetjes, H. Signal processing via web services: The use case WebMAUS. In Proceedings of the Digital Humanities Conference, Sheffield, 16–22 July 2012; pp. 30–34. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by Random Forest. R News 2.3 2002, 23, 18–22. [Google Scholar]
- Yoav, F.; Robert E, S. Experiments with a new boosting algorithm. In Proceedings of the International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mendes-Moreira, J.; Soares, C.; Jorge, A.M.; Sousa, J.F.D. Ensemble approaches for regression: A survey. ACM Comput. Surv. 2012, 45, 1–40. [Google Scholar] [CrossRef]
- Eide, E.; Aaron, A.; Bakis, R.; Hamza, W.; Picheny, M.; Pitrelli, J. A corpus-based approach to expressive speech synthesis. In Proceedings of the ISCA ITRW on Speech Synthesis, Pittsburgh, PA, USA, 14–16 June 2004; pp. 79–84. [Google Scholar]
- Ming, H.; Huang, D.Y.; Dong, M.; Li, H.; Xie, L.; Zhang, S. Fundamental Frequency Modeling Using Wavelets for Emotional Voice Conversion. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Xi’an, China, 21–24 September 2015; pp. 804–809. [Google Scholar]
- Lu, X.; Pan, T. Research On Prosody Conversion of Affective Speech Based on LIBSVM and PAD Three Dimensional Emotion Model. In Proceedings of the Wkhp on Advanced Research & Tech in Industry Applications, Tianjin, China, 11–12 June 2016; pp. 1–7. [Google Scholar]
- Robinson, C.; Obin, N.; Roebel, A. Sequence-To-Sequence Modelling of F0 for Speech Emotion Conversion. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 6830–6834. [Google Scholar]
- Viswanathan, M.; Viswanathan, M. Measuring speech quality for text-to-speech systems: Development and assessment of a modified mean opinion score (MOS) scale. Comput. Speech Lang. 2005, 19, 55–83. [Google Scholar] [CrossRef]



| Feature | Description | Extraction Method |
|---|---|---|
| Linguistic context features | Count = 102, e.g., accented/unaccented, vowel/consonant | Text analysis at the phonetic level using MaryTTS. |
| Nonemotional contour Fujisaki model parameters | Five Fujisaki parameters-, , , , | Passing nonemotional speech to AutoFuji extractor. |
| Emotion tag | Five primary and five secondary emotions | Each emotion tag is assigned to the sentence |
| Speaker tag | Two male speakers | Speaker tag is assigned |
| Secondary Emotion | Mean Speech Rate (Syllables/s) | Mean Intensity (dB) |
|---|---|---|
| anxious | 3.25 | 58.24 |
| apologetic | 2.93 | 55.14 |
| confident | 3.20 | 59.50 |
| enthusiastic | 3.24 | 63.91 |
| worried | 2.99 | 56.34 |
| APO | ANX | APO | ENTH | ||
|---|---|---|---|---|---|
| APO | 97.9 % | 2.1% | APO | 100% | 0% |
| ANX | 0% | 100% | ENTH | 1.4% | 98.6% |
| CONF | ANX | APO | WOR | ||
| CONF | 88.3% | 11.7% | APO | 64.3% | 35.7% |
| ANX | 12.4% | 87.6% | WOR | 32.4% | 67.6% |
| ENTH | ANX | CONF | ENTH | ||
| ENTH | 78.6% | 21.4% | CONF | 69% | 31% |
| ANX | 24.8% | 75.2% | ENTH | 30.3% | 69.7% |
| WOR | ANX | CONF | WOR | ||
| WOR | 97.9% | 2.1% | CONF | 95.2% | 4.8% |
| ANX | 4.1% | 95.9% | WOR | 22.8% | 77.2% |
| APO | CONF | WOR | ENTH | ||
| APO | 94.5% | 5.5% | WOR | 97.9% | 2.1% |
| CONF | 9.7% | 90.3% | ENTH | 0.7% | 99.3% |
| Actual Emotions | Emotion Words by Participants (Count of Times Used) |
|---|---|
| Anxious | Anxious (41), enthusiastic (9), neutral (4), confident (3), energetic (1) |
| Apologetic | Apologetic (35), worried (22), worried/sad (1) |
| Confident | Confident (34), enthusiastic (9), worried (8), neutral (5), authoritative (1), demanding (1) |
| Enthusiastic | Confident (24), enthusiastic (21), neutral (4), apologetic (3), worried (5), encouraging (1) |
| Worried | Worried (38), apologetic (12), anxious (5), condescending (1), confident (1), neutral (1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
James, J.; B.T., B.; Watson, C.; Mixdorff, H. Exploring Prosodic Features Modelling for Secondary Emotions Needed for Empathetic Speech Synthesis. Sensors 2023, 23, 2999. https://doi.org/10.3390/s23062999
James J, B.T. B, Watson C, Mixdorff H. Exploring Prosodic Features Modelling for Secondary Emotions Needed for Empathetic Speech Synthesis. Sensors. 2023; 23(6):2999. https://doi.org/10.3390/s23062999
Chicago/Turabian StyleJames, Jesin, Balamurali B.T., Catherine Watson, and Hansjörg Mixdorff. 2023. "Exploring Prosodic Features Modelling for Secondary Emotions Needed for Empathetic Speech Synthesis" Sensors 23, no. 6: 2999. https://doi.org/10.3390/s23062999
APA StyleJames, J., B.T., B., Watson, C., & Mixdorff, H. (2023). Exploring Prosodic Features Modelling for Secondary Emotions Needed for Empathetic Speech Synthesis. Sensors, 23(6), 2999. https://doi.org/10.3390/s23062999