1. Introduction
The ability to open doors is important for robots designed for use in household environments, as it allows them to reach places behind doors, which is necessary for solving many tasks. Doors are a common feature in most homes, and robots designed to perform tasks or provide assistance in a home environment must be able to navigate through doors to get from one room to another. Similarly, the ability of robots to open cabinets and drawers can also be important in a home. Cabinets and drawers are commonly used to store food, cleaning supplies, tools, and other household items. A robot that is designed to perform tasks such as retrieving items, replenishing supplies, or organizing items may need to be able to open cabinets to access these items and perform its tasks. For example, a robot designed to assist with cooking may need to be able to open cabinets to pick ingredients or cooking utensils. Similarly, a robot designed to help with cleaning might be able to open cabinets to access cleaning supplies or tools.
Traditionally, cabinets and drawers are opened by grabbing and pulling the handle that is attached to the front of this furniture. Therefore, many researchers have already developed various algorithms for handle detection and grasp planning. However, in modern homes, it has become increasingly common to see cabinet and drawer doors without visible handles on their outer surface. These types of doors are usually opened by pressing on the outer surface near a spring mechanism located inside the door, as shown in
Figure 1b. When this spring, shown in
Figure 1a, is pressed, it stretches and pushes the door from the inside, allowing it to be opened. On the other hand, there are also cabinet doors that are opened by grasping the edges of the front surface of the door, as shown in
Figure 1c, which are referred to in this paper as hidden handle doors.
These opening types can present a potential problem for autonomous robots that are programmed to open doors, as these algorithms typically expect to find a visible handle suitable for grasping. Cabinet doors without visible handles or with hidden handles may be more difficult for these robots to open, as they do not have a traditional handle to grasp and use to initiate the opening process. To the best of our knowledge, there is no recent research considering opening doors without regular handles.
In this research paper, we focus on the first step of the process of opening doors and drawers with regular and alternative handles: the classification of the opening type. To conduct our study, we collected and labeled a dataset of RGB-D images of various cabinet and drawer doors in their natural environment, such as kitchens, living rooms, and bedrooms. These images were taken in complex scenes to more accurately represent the real-world situations in which these doors are typically encountered.
One of the challenges we identified when attempting to classify the opening type of these doors is that when the regular handle is not present on the door surface, it can be difficult to determine the correct method for opening the door. In some cases, doors with hidden handles may resemble those with a push mechanism, making it difficult to distinguish between the two. As a result, we decided to train an algorithm to distinguish between these opening types based on human demonstration. When a human opens a door with a push mechanism, they typically press the door surface with their spread palm. On the other hand, when a human opens a door with a hidden handle, their fingers usually bend to grip the edge of the surface. By using these human demonstration patterns as examples, we develop an algorithm that can classify the opening type of these doors.
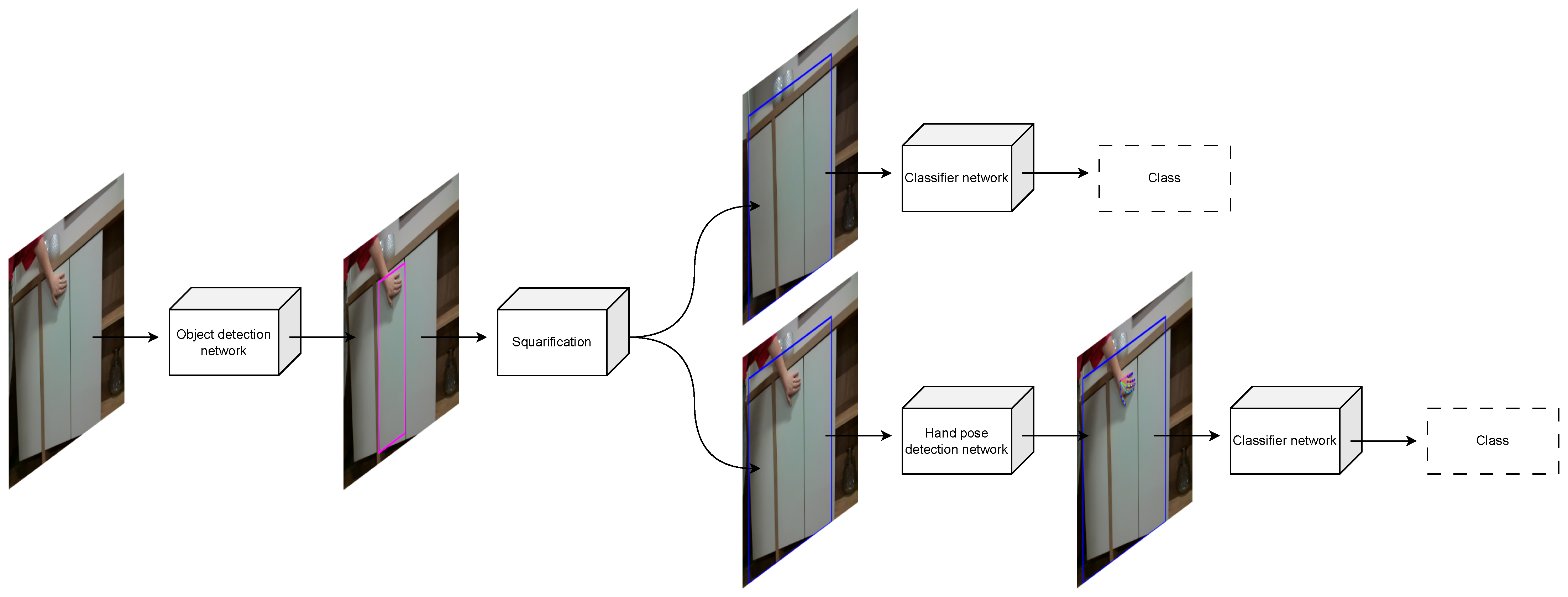
The proposed approach consists of image preprocessing, classification training, and evaluation. Since the images are acquired in complex scenes, the first step consists of detecting the region of interest (ROI) on the image represented by the considered bounding box of the door. Using this ROI as input to the OpenPose [
1] and ResNet [
2] algorithms, we obtained door opening classes. This training was done with images containing human hands to demonstrate opening and with images without hands. The idea was to find out if the human demonstration could help to identify the type of door opening. This can be useful in cases where a robot deployed in a work environment cannot correctly determine the opening type of a particular door. A human could then show the robot how to open that door by demonstration.
We propose the following contributions in this paper:
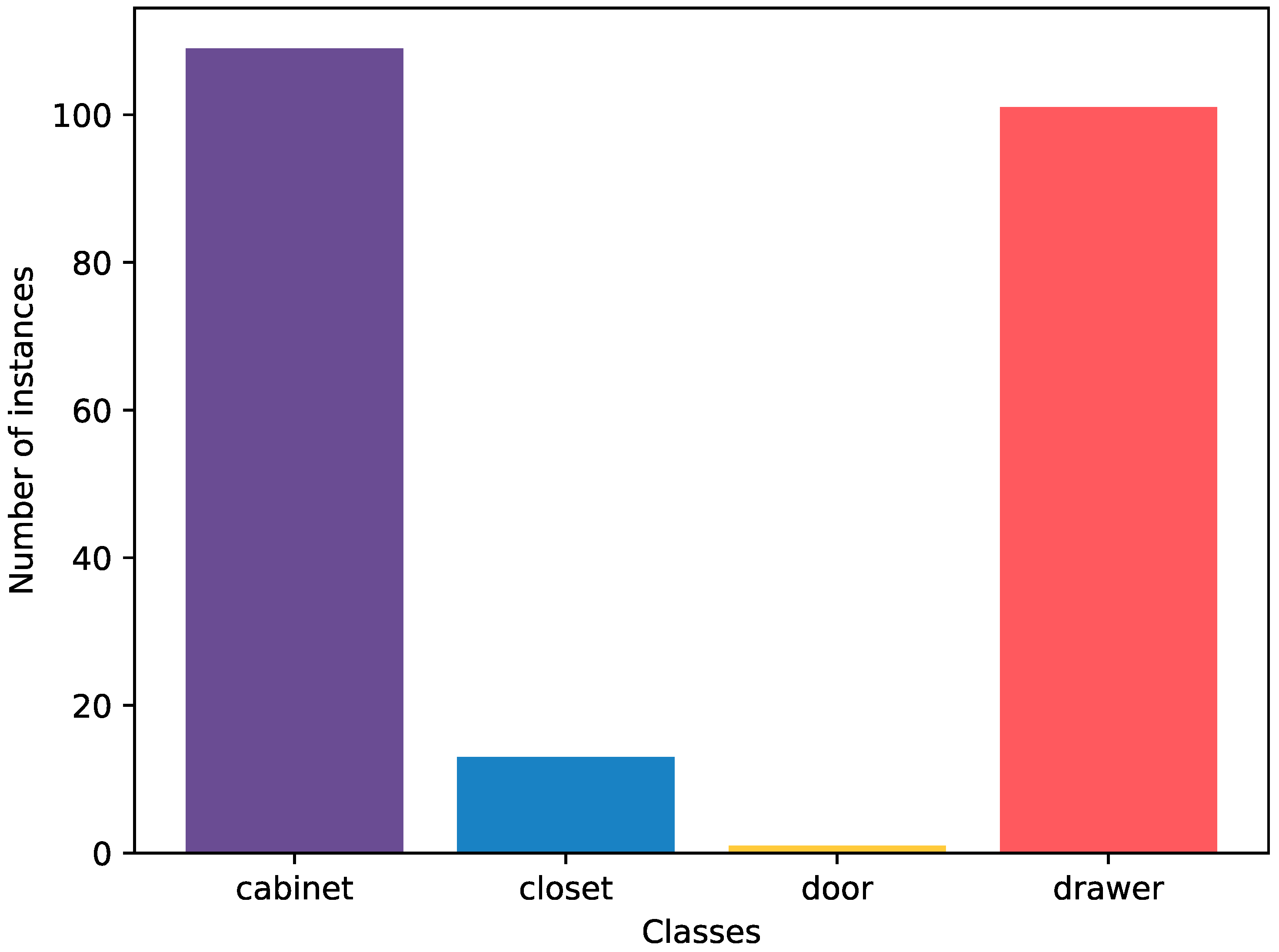
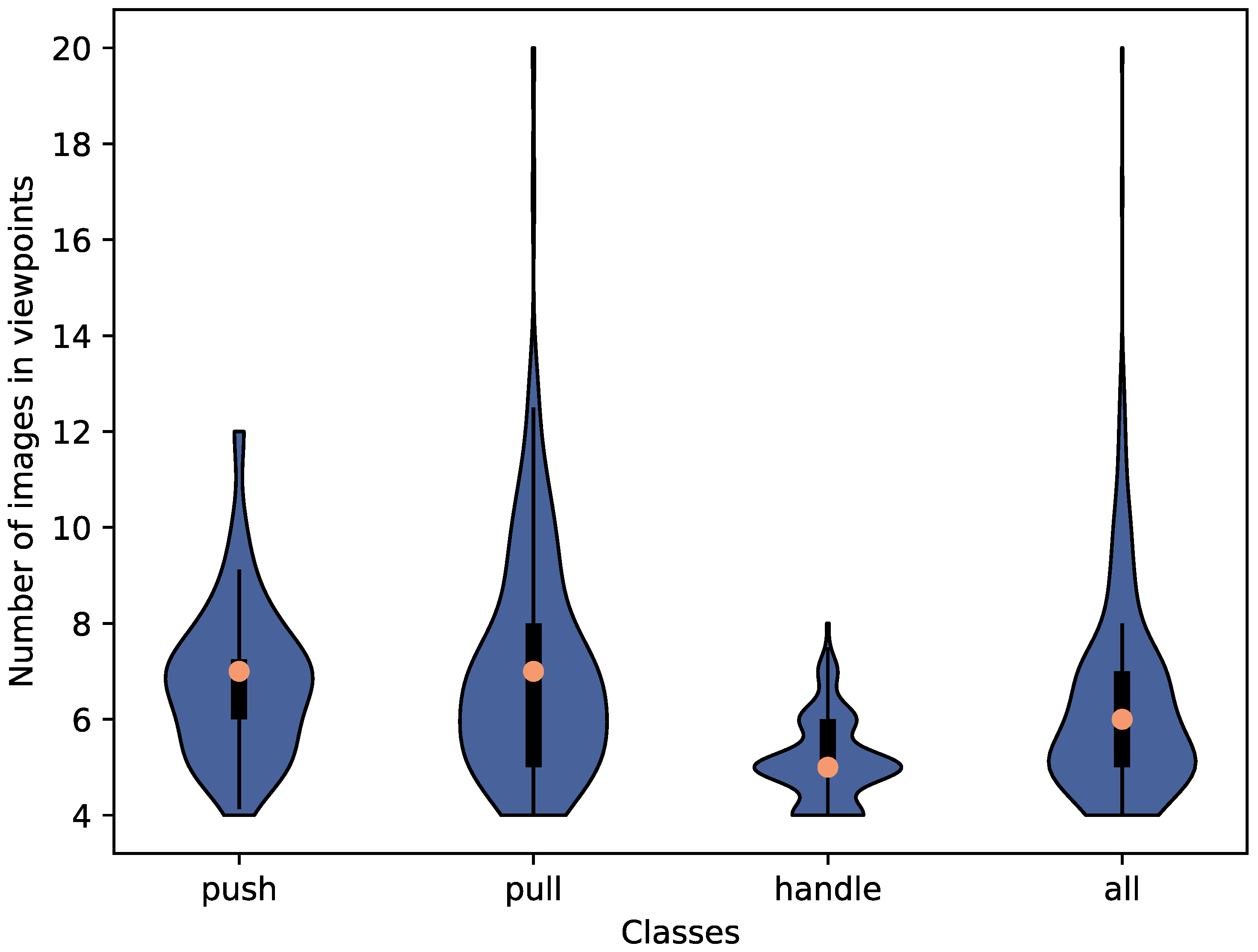
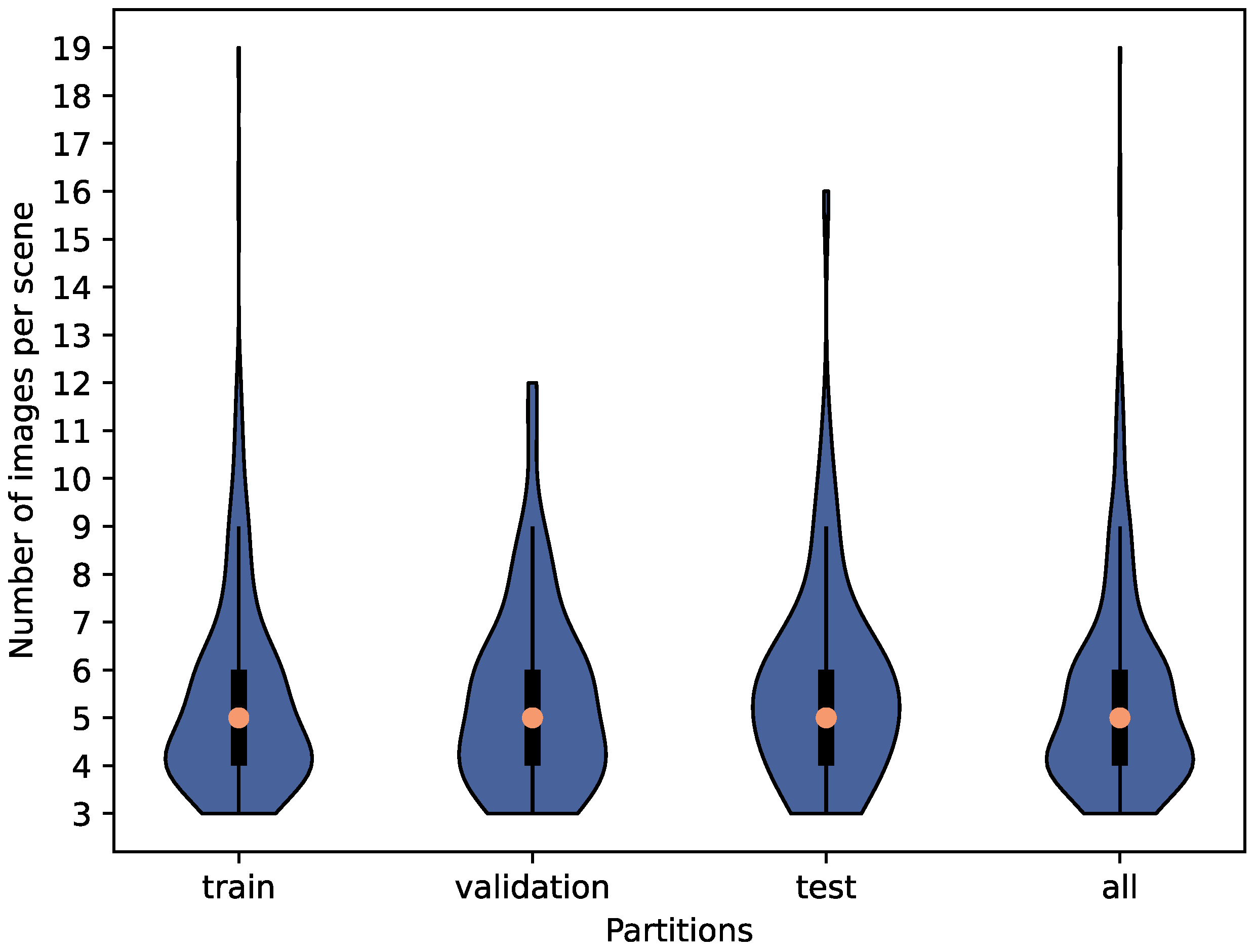
HoDoor: An RGB-D dataset of cabinets and drawers in complex scenes with labeled bounding boxes and ground truth information about the type of door opening. Images are provided from the same viewpoint with and without a human hand to demonstrate opening.
A neural network-based approach to classify three door opening types: with a regular handle, with a hidden handle, and with a push mechanism.
The paper consists of the following sections. In
Section 2, the related research is presented. We researched the state of the art in the field of different detection methods that could be used for door and handle detection. Furthermore, we explored hand pose estimation and hand gesture recognition in images, since our method is based on human door opening demonstrations.
Section 3 provides information about the HoDoor dataset and proposed methodology of door opening type classifications. Results are given in
Section 4, and they are discussed in
Section 5.
5. Discussion
Complex scenes can sometimes make some objects without regular handles difficult to classify, particularly when no hands are visible in the scene. The lighting in the scene can also affect the classification, as it may change the visibility of some visual features of the object.
Figure 15 shows several images from the dataset that have proven difficult to classify for both humans and detectors. All of the objects in these images belong to the pull class but are often misclassified as push. The objects that are easily misclassified are usually captured from a perspective that does not show some important features of the object that would be critical for correct classification. In some cases, the objects do not even have visual features that distinguish them from another class.
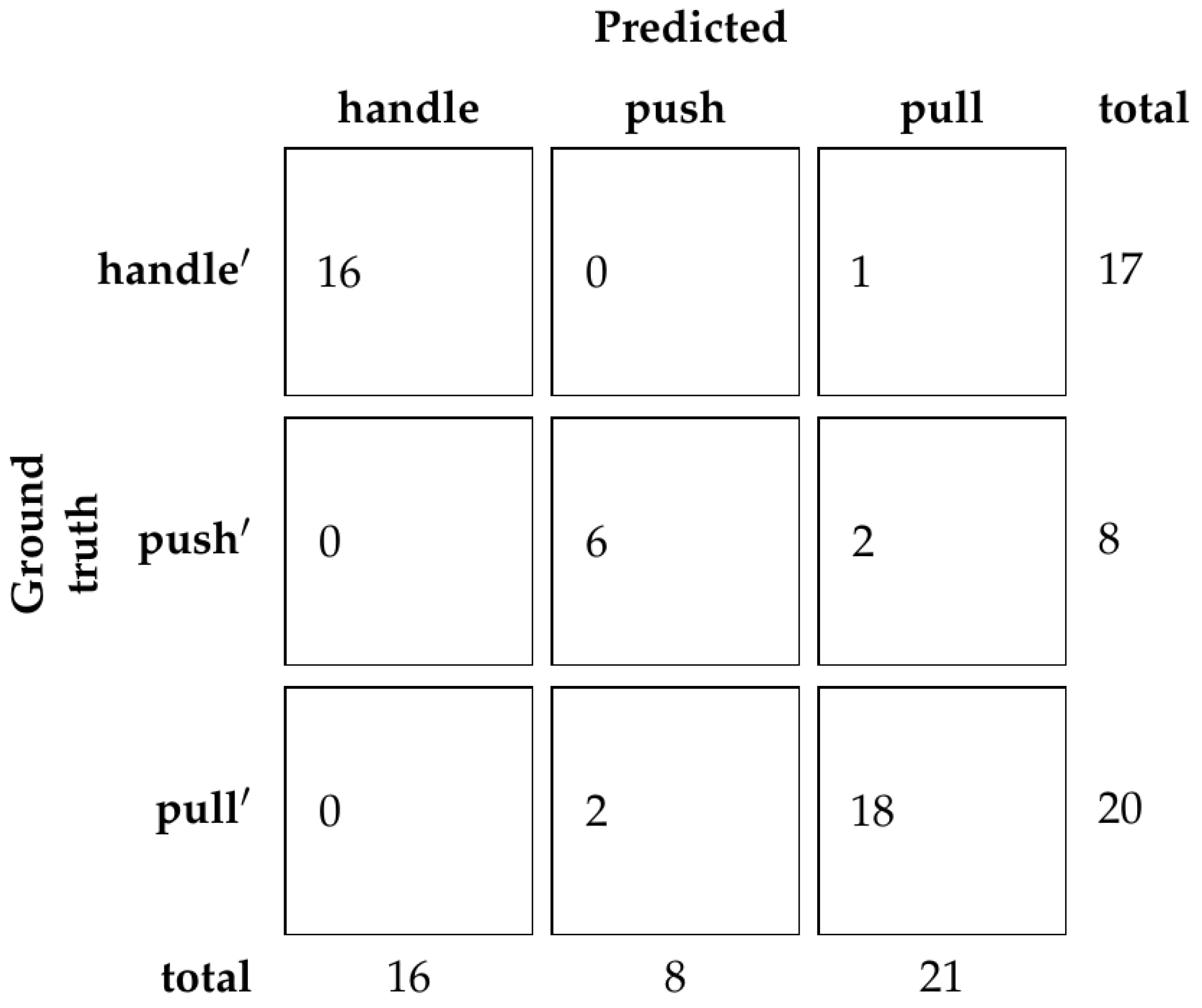
Using our dataset with human demonstration, we show that a reliable classifier that relies exclusively on hand pose can be trained. The classifier’s performance depends on the underlying hand pose detection method [
1], which brings additional uncertainty to the predictions. However,
Figure 11 shows that most mistakes come from mistaking furniture doors with regular handles and furniture doors with hidden handles, which is to be expected since the hand gesture for opening those types of doors is somewhat similar. Furthermore, we show that the depth of the ResNet does not influence the results consistently, which is also to be expected, considering there are only three classes. What does consistently influence the results is the
parameter, which controls how much context is included in the input for the hand pose detection. It can be seen that both too little context and too much context negatively influence the prediction.
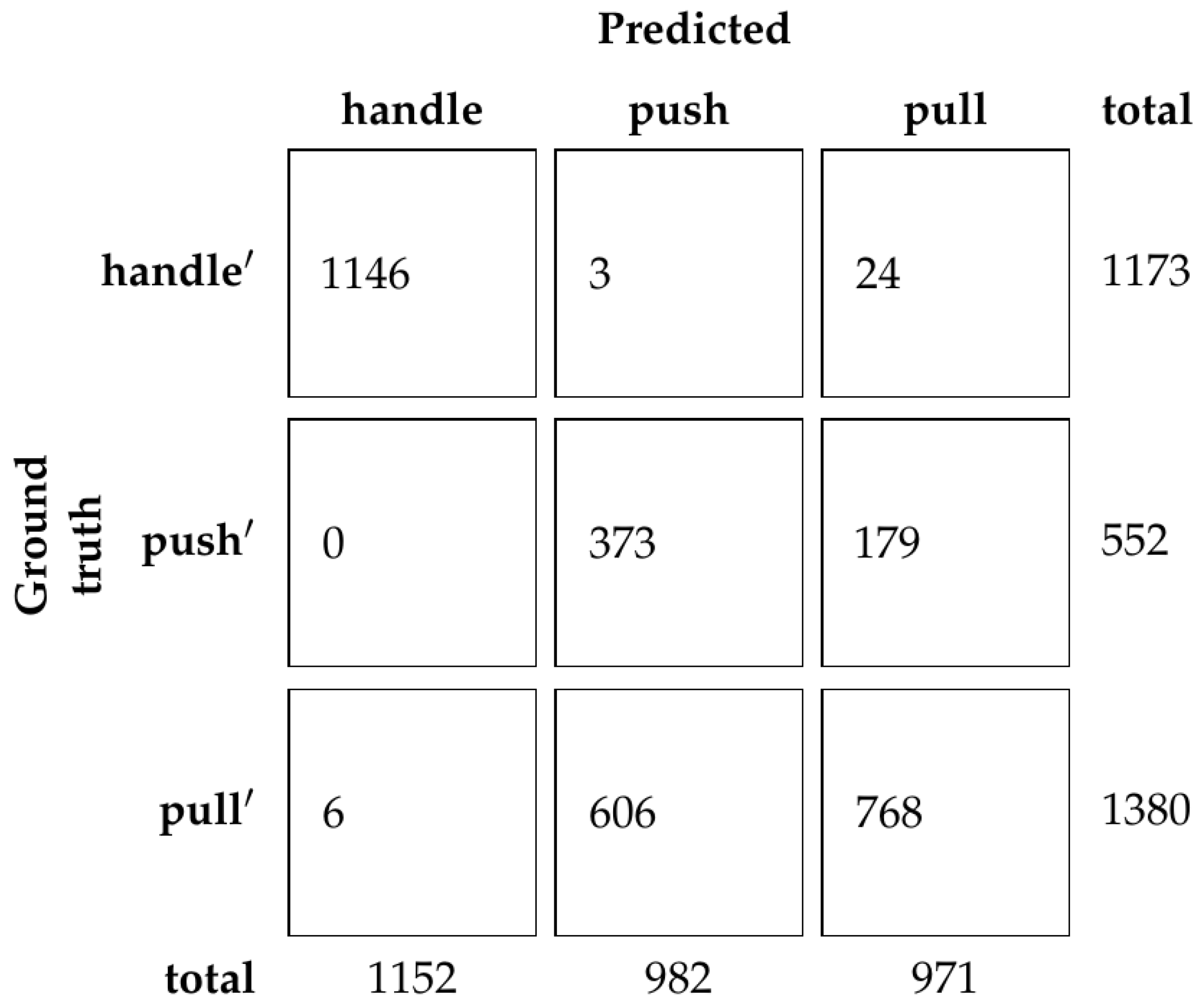
It is hard to differentiate between doors with push mechanisms and those with a hidden handle because the main differences are a hidden mechanism or a differently designed edge. The former cannot be seen on a closed furniture door, and the latter is hard to notice on an RGB image. On the contrary, the hand poses used to open these types of doors are very distinguishable. Thus, it would be expected that a classifier would achieve better results on images with human demonstration than without.
However, the results from the dataset without human demonstration are different than what we expected. Using only the RGB information, we achieve perfect classification results on the validation set. On the test set, we achieve a very high accuracy of 88.89%. Compared to the results of the human survey (73.66%), this is suspiciously high. This is most likely due to the similarity between the dataset partitions. Since the dataset partitions contain images of similar furniture, the network overfits to those furniture instances, which brings the accuracy to such a high number. For future research, the dataset should be supplemented with additional images of furniture with doors that do not appear in the training set.
We also conducted experiments with detected ROIs. With these experiments, we show that a state-of-the-art network [
12] trained on a different dataset [
34], which contains images of furniture with doors, can reliably predict the ROIs. The results are better on the dataset without human demonstration, since there is no occlusion in form of human hands and arms. Furthermore, we show that the accuracy of our classification method on the images with human demonstration does slightly fall off. On the other hand, when considering images without human demonstration, the accuracy is similar for the ground truth ROIs and on the ROIs detected by the detector network. While our method can be used on scenes with multiple cabinets, drawers, etc., without human demonstration, our dataset is not labeled in such a way and thus we do not test it in this manner. When used on images with human demonstration and multiple cabinets, closets, or drawers, our method would need to be augmented with a discriminator that could differentiate between the ROIs with and without a human hand.
As mentioned earlier, the dataset should be supplemented with additional images of objects not appearing in the training set for the test set. With this new test set, more credible results could be obtained for classification without human demonstration. This classification could also be improved by using the depth information that is present in our dataset. Another future research option is robot manipulation of doors with push mechanisms and hidden handles, whereby our dataset could be used for teaching a robot how to handle these types of furniture doors based on human demonstration.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}