
SD-YOLOv8: An Accurate Seriola dumerili Detection Model Based on Improved YOLOv8


Abstract
1. Introduction
2. Methods
2.1. SD-YOLOv8
2.2. Small Object Detection Layer
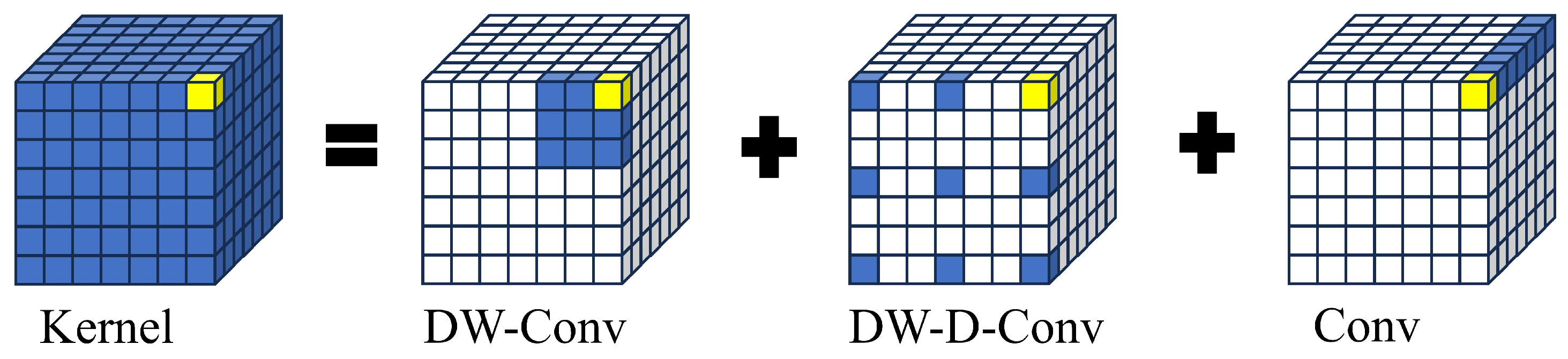
2.3. C2f_DCN
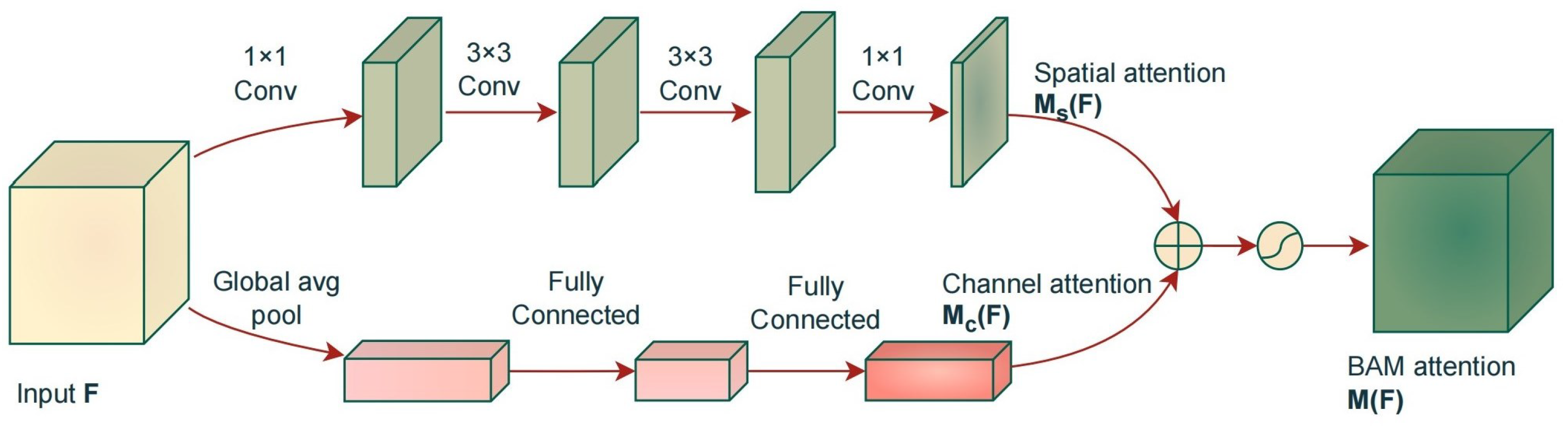
2.4. Bottleneck Attention Module
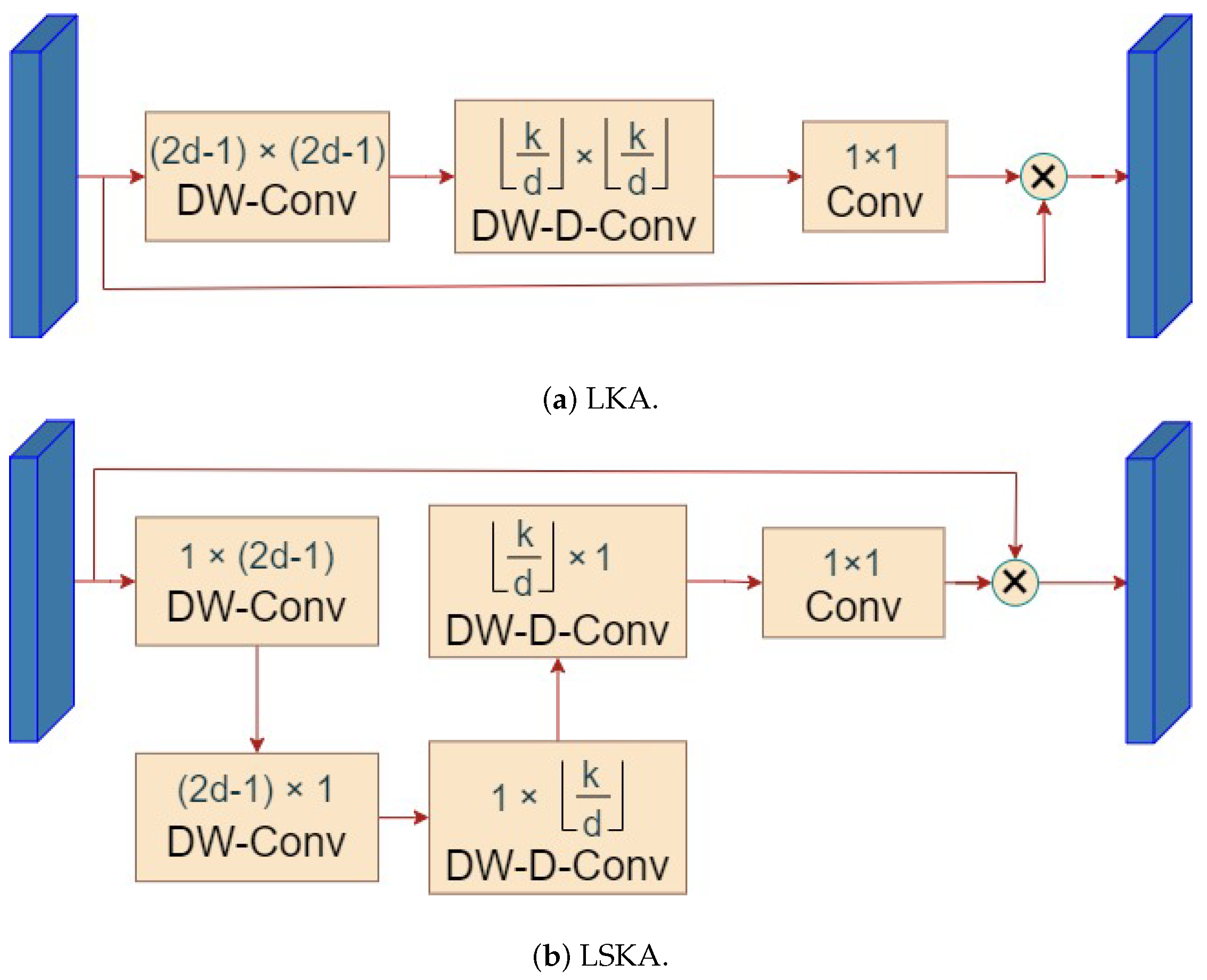
2.5. SPPF_LSKA
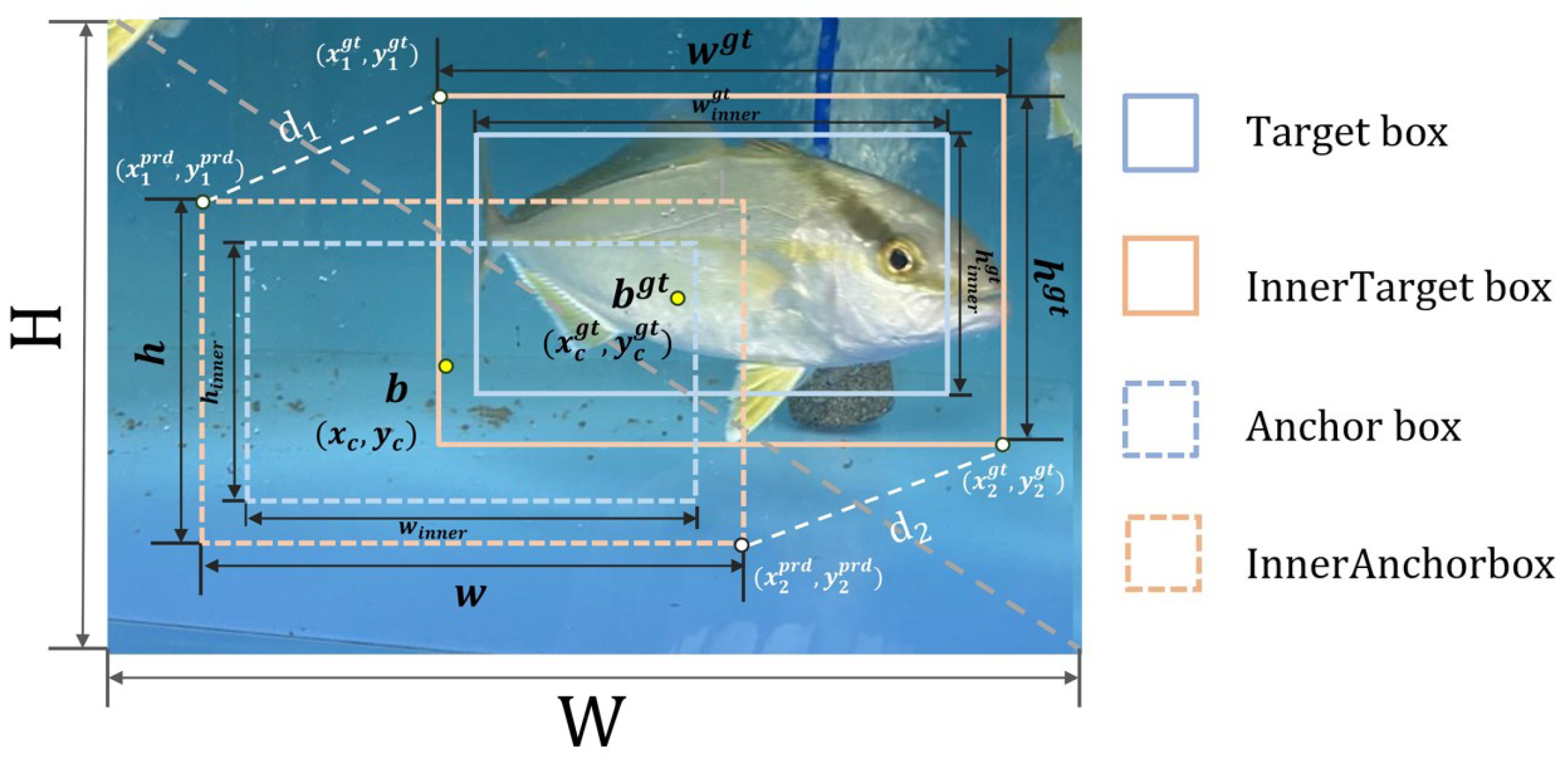
2.6. Inner-MDPIoU
3. Materials
3.1. Experimental Environment and Parameter Settings
3.2. Dataset
3.2.1. S. dumerili Dataset
3.2.2. Real-World Dataset
3.3. Evaluation Metrics
4. Results and Analysis
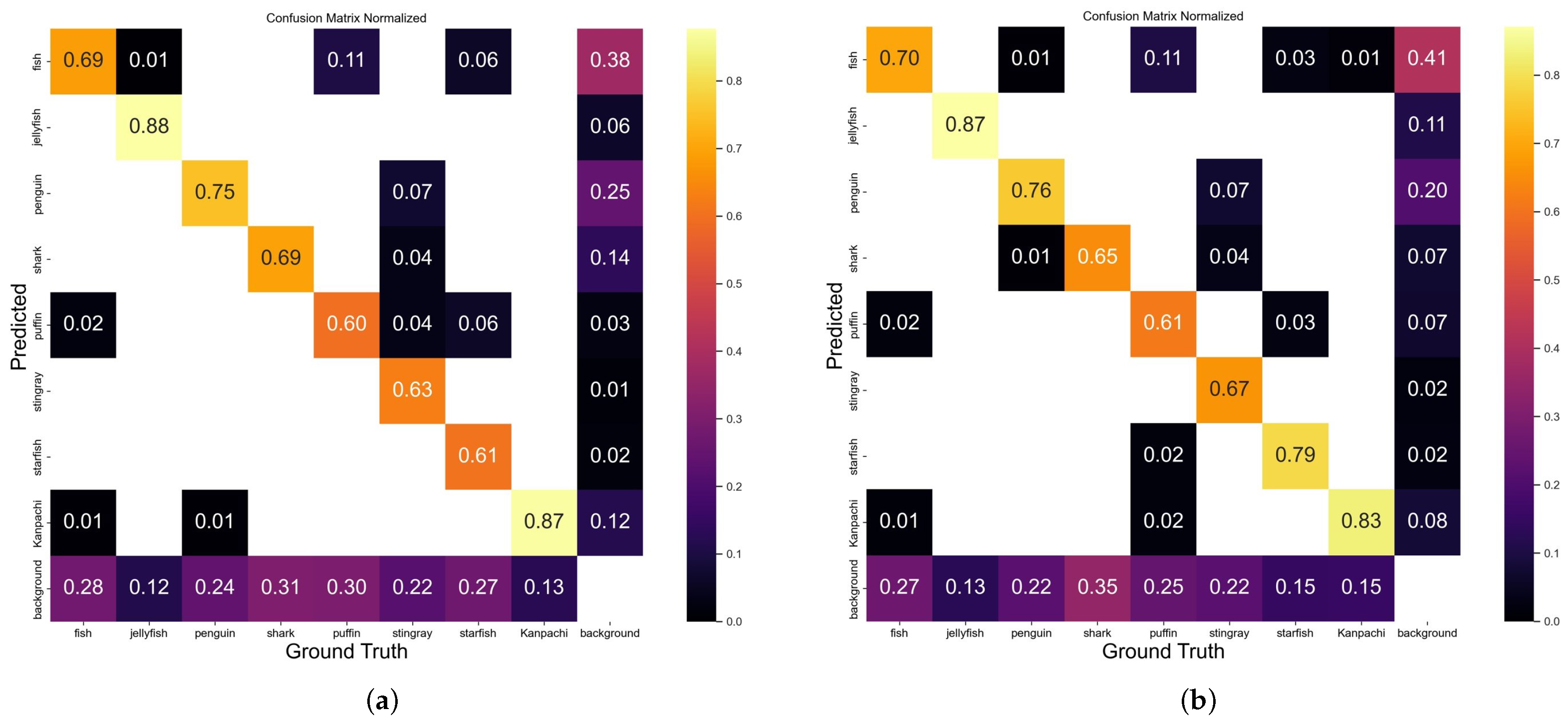
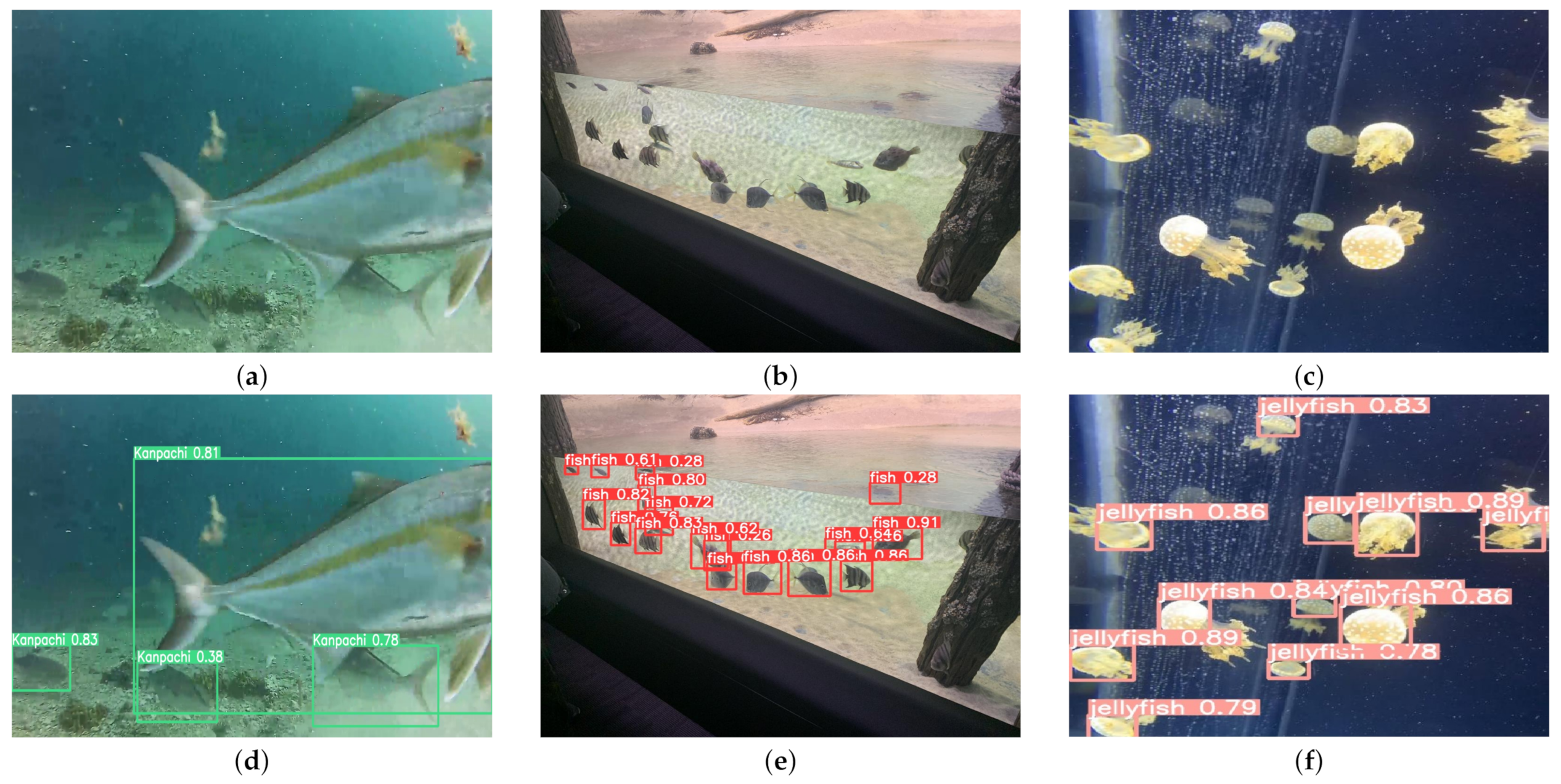
4.1. Model Comparison
4.2. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, H.; Li, J.; Li, X.; Ru, X.; Huang, Y.; Zhu, C.; Li, G. Survival pressure and tolerance of juvenile greater amberjack (Seriola dumerili) under acute hypo- and hyper-salinity stress. Aquac. Rep. 2024, 36, 102150. [Google Scholar] [CrossRef]
- Corriero, A.; Wylie, M.J.; Nyuji, M.; Zupa, R.; Mylonas, C.C. Reproduction of greater amberjack (Seriola dumerili) and other members of the family Carangidae. Rev. Aquac. 2021, 13, 1781–1815. [Google Scholar] [CrossRef]
- Tone, K.; Nakamura, Y.; Chiang, W.C.; Yeh, H.M.; Hsiao, S.T.; Li, C.H.; Komeyama, K.; Tomisaki, M.; Hasegawa, T.; Sakamoto, T.; et al. Migration and spawning behavior of the greater amberjack Seriola dumerili in eastern Taiwan. Fish. Oceanogr. 2022, 31, 1–18. [Google Scholar] [CrossRef]
- Rigos, G.; Katharios, P.; Kogiannou, D.; Cascarano, C.M. Infectious diseases and treatment solutions of farmed greater amberjack Seriola dumerili with particular emphasis in Mediterranean region. Rev. Aquac. 2021, 13, 301–323. [Google Scholar] [CrossRef]
- Sinclair, C. Dictionary of Food: International Food and Cooking Terms from A to Z; A&C Black: London, UK, 2009. [Google Scholar]
- Li, D.; Du, L. Recent advances of deep learning algorithms for aquacultural machine vision systems with emphasis on fish. Artif. Intell. Rev. 2022, 55, 4077–4116. [Google Scholar] [CrossRef]
- Yang, L.; Liu, Y.; Yu, H.; Fang, X.; Song, L.; Li, D.; Chen, Y. Computer vision models in intelligent aquaculture with emphasis on fish detection and behavior analysis: A review. Arch. Comput. Methods Eng. 2021, 28, 2785–2816. [Google Scholar] [CrossRef]
- Islam, S.I.; Ahammad, F.; Mohammed, H. Cutting-edge technologies for detecting and controlling fish diseases: Current status, outlook, and challenges. J. World Aquac. Soc. 2024, 55, e13051. [Google Scholar] [CrossRef]
- Fayaz, S.; Parah, S.A.; Qureshi, G. Underwater object detection: Architectures and algorithms–a comprehensive review. Multimed. Tools Appl. 2022, 81, 20871–20916. [Google Scholar] [CrossRef]
- Li, J.; Xu, W.; Deng, L.; Xiao, Y.; Han, Z.; Zheng, H. Deep learning for visual recognition and detection of aquatic animals: A review. Rev. Aquac. 2023, 15, 409–433. [Google Scholar] [CrossRef]
- Lin, C.; Qiu, C.; Jiang, H.; Zou, L. A Deep Neural Network Based on Prior-Driven and Structural Preserving for SAR Image Despeckling. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6372–6392. [Google Scholar] [CrossRef]
- Li, X.; Shang, M.; Hao, J.; Yang, Z. Accelerating fish detection and recognition by sharing CNNs with objectness learning. In Proceedings of the OCEANS 2016—Shanghai, Shanghai, China, 10–13 April 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Boom, B.J.; Huang, P.X.; He, J.; Fisher, R.B. Supporting ground-truth annotation of image datasets using clustering. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 1542–1545. [Google Scholar]
- Li, J.; Xu, C.; Jiang, L.; Xiao, Y.; Deng, L.; Han, Z. Detection and Analysis of Behavior Trajectory for Sea Cucumbers Based on Deep Learning. IEEE Access 2020, 8, 18832–18840. [Google Scholar] [CrossRef]
- Shah, S.Z.H.; Rauf, H.T.; IkramUllah, M.; Khalid, M.S.; Farooq, M.; Fatima, M.; Bukhari, S.A.C. Fish-Pak: Fish species dataset from Pakistan for visual features based classification. Data Brief 2019, 27, 104565. [Google Scholar] [CrossRef] [PubMed]
- Fouad, M.M.M.; Zawbaa, H.M.; El-Bendary, N.; Hassanien, A.E. Automatic Nile Tilapia fish classification approach using machine learning techniques. In Proceedings of the 13th International Conference on Hybrid Intelligent Systems (HIS 2013), Gammarth, Tunisia, 4–6 December 2013; pp. 173–178. [Google Scholar] [CrossRef]
- Ravanbakhsh, M.; Shortis, M.R.; Shafait, F.; Mian, A.; Harvey, E.S.; Seager, J.W. Automated Fish Detection in Underwater Images Using Shape-Based Level Sets. Photogramm. Rec. 2015, 30, 46–62. [Google Scholar] [CrossRef]
- Iscimen, B.; Kutlu, Y.; Uyan, A.; Turan, C. Classification of fish species with two dorsal fins using centroid-contour distance. In Proceedings of the 2015 23nd Signal Processing and Communications Applications Conference (SIU), Malatya, Turkey, 16–19 May 2015; pp. 1981–1984. [Google Scholar] [CrossRef]
- Cutter, G.; Stierhoff, K.; Zeng, J. Automated Detection of Rockfish in Unconstrained Underwater Videos Using Haar Cascades and a New Image Dataset: Labeled Fishes in the Wild. In Proceedings of the 2015 IEEE Winter Applications and Computer Vision Workshops, Waikoloa, HI, USA, 6–9 January 2015; pp. 57–62. [Google Scholar] [CrossRef]
- Dhawal, R.S.; Chen, L. A copula based method for the classification of fish species. Int. J. Cogn. Inform. Nat. Intell. (IJCINI) 2017, 11, 29–45. [Google Scholar] [CrossRef]
- Li, X.; Shang, M.; Qin, H.; Chen, L. Fast accurate fish detection and recognition of underwater images with Fast R-CNN. In Proceedings of the OCEANS 2015—MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Salman, A.; Siddiqui, S.A.; Shafait, F.; Mian, A.; Shortis, M.R.; Khurshid, K.; Ulges, A.; Schwanecke, U. Automatic fish detection in underwater videos by a deep neural network-based hybrid motion learning system. ICES J. Mar. Sci. 2019, 77, 1295–1307. [Google Scholar] [CrossRef]
- Lin, W.H.; Zhong, J.X.; Liu, S.; Li, T.; Li, G. ROIMIX: Proposal-Fusion Among Multiple Images for Underwater Object Detection. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2588–2592. [Google Scholar] [CrossRef]
- Jalal, A.; Salman, A.; Mian, A.; Shortis, M.; Shafait, F. Fish detection and species classification in underwater environments using deep learning with temporal information. Ecol. Inform. 2020, 57, 101088. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, G.; Li, H.; Liu, H.; Tan, J.; Xue, X. Underwater target detection algorithm based on improved YOLOv4 with SemiDSConv and FIoU loss function. Front. Mar. Sci. 2023, 10, 1153416. [Google Scholar] [CrossRef]
- Liu, Y.; Chu, H.; Song, L.; Zhang, Z.; Wei, X.; Chen, M.; Shen, J. An improved tuna-YOLO model based on YOLO v3 for real-time tuna detection considering lightweight deployment. J. Mar. Sci. Eng. 2023, 11, 542. [Google Scholar] [CrossRef]
- Hu, J.; Zhao, D.; Zhang, Y.; Zhou, C.; Chen, W. Real-time nondestructive fish behavior detecting in mixed polyculture system using deep-learning and low-cost devices. Expert Syst. Appl. 2021, 178, 115051. [Google Scholar] [CrossRef]
- Zhou, S.; Cai, K.; Feng, Y.; Tang, X.; Pang, H.; He, J.; Shi, X. An Accurate Detection Model of Takifugu rubripes Using an Improved YOLO-V7 Network. J. Mar. Sci. Eng. 2023, 11, 1051. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lau, K.W.; Po, L.M.; Rehman, Y.A.U. Large Separable Kernel Attention: Rethinking the Large Kernel Attention design in CNN. Expert Syst. Appl. 2024, 236, 121352. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Glasgow, UK, 2020; Volume 33, pp. 21002–21012. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Siliang, M.; Yong, X. MPDIoU: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More Effective Intersection over Union Loss with Auxiliary Bounding Box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Maharana, K.; Mondal, S.; Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transitions Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Fafa, D.L. Image-Augmentation. Available online: https://github.com/Fafa-DL/Image-Augmentation (accessed on 21 April 2024).
- Hassan, N.; Akamatsu, N. A new approach for contrast enhancement using sigmoid function. Int. Arab J. Inf. Technol. 2004, 1, 221–225. [Google Scholar]
- Ali, M.; Clausi, D. Using the Canny edge detector for feature extraction and enhancement of remote sensing images. In Proceedings of the IGARSS 2001. Scanning the Present and Resolving the Future. Proceedings. IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No.01CH37217), Sydney, Australia, 9–13 July 2001; Volume 5, pp. 2298–2300. [Google Scholar]
- HumanSignal. LabelImg. Available online: https://github.com/HumanSignal/labelImg (accessed on 21 April 2024).
- Wang, F.; Zheng, J.; Zeng, J.; Zhong, X.; Li, Z. S2F-YOLO: An Optimized Object Detection Technique for Improving Fish Classification. J. Internet Technol. 2023, 24, 1211–1220. [Google Scholar] [CrossRef]
- Karthi, M.; Muthulakshmi, V.; Priscilla, R.; Praveen, P.; Vanisri, K. Evolution of YOLO-V5 Algorithm for Object Detection: Automated Detection of Library Books and Performace validation of Dataset. In Proceedings of the 2021 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), Chennai, India, 24–25 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation. In Advances in Information Retrieval; Losada, D.E., Fernández-Luna, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2018. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part I 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device Name | Resolution | ||
|---|---|---|---|
| Barlus Underwater Camera | 5 MP | 2592 × 1944 | 25 FPS |
| IPC5MPW-PBX10 | 4 MP | 2560 × 1440 | 25 FPS |
| TP-Link Network Camera | 4 MP | 2560 × 1440 | 15 FPS |
| TL-IPC44B | |||
| SJCAM Action Camera C300 | 4 K | 3840 × 2160 | 30 FPS |
| 2 K | 2560 × 1440 | 60/30 FPS | |
| 720 P | 1280 × 7201 | 20/60/30 FPS | |
| 1080 P | 1920 × 1080 | 120/60/30 FPS |
| Dataset | Models | Precision | Recall | F1 Score | Parameters | FLOPs | Size | |
|---|---|---|---|---|---|---|---|---|
| S. dumerili | Faster RCNN | 77.2% | 78.4% | 77.8% | 82.3% | 137.1 M | 370.2 G | 108.0 MB |
| CenterNet | 79.2% | 79.4% | 79.3% | 80.1% | 32.7 M | 70.2 G | 124.0 MB | |
| RetinaNet | 81.0% | 60.5% | 69.3 % | 56.2% | 37.9 M | 170.1 G | 108.0 MB | |
| SSD | 84.4% | 89.5% | 86.9% | 87.0% | 18.4 M | 15.5 G | 90.6 MB | |
| YOLOv4-tiny | 83.7% | 73.4% | 80.3% | 84.2% | 6.1 M | 6.9 G | 22.4 MB | |
| YOLOv5s | 90.6% | 87.8% | 89.2% | 93.3% | 2.6 M | 7.7 G | 7.7 MB | |
| YOLOX-s | 90.2% | 89.6% | 89.9% | 94.4% | 8.9 M | 26.6 G | 34.3 MB | |
| YOLOv7 | 88.5% | 89.0% | 88.8% | 92.4% | 37.2 M | 105.1 G | 74.3 MB | |
| YOLOv8n | 89.2% | 88.4% | 88.8% | 92.2% | 3.1 M | 8.1 G | 6.0 MB | |
| SD-YOLOv8 | 93.3% | 88.9% | 91.0% | 95.7% | 3.5 M | 12.7 G | 7.6 MB | |
| Real-world | Faster RCNN | 66.4% | 75.4% | 70.6% | 71.5% | 137.1 M | 370.2 G | 108.0 MB |
| CenterNet | 67.8% | 66.7% | 67.2% | 76.2% | 32.7 M | 70.2 G | 124.0 MB | |
| RetinaNet | 62.4% | 65.0% | 63.7% | 56.7% | 37.9 M | 170.1 G | 108.0 MB | |
| SSD | 70.6% | 64.9% | 67.6% | 71.8% | 26.3 M | 62.7 G | 94.1 MB | |
| YOLOv4-tiny | 75.3% | 61.5% | 67.7% | 66.4% | 6.4 M | 6.5 G | 22.4 MB | |
| YOLOv5s | 70.4% | 66.2% | 68.2% | 75.0% | 6.1 M | 6.9 G | 27.2 MB | |
| YOLOX-s | 81.5% | 54.7% | 65.5% | 69.8% | 8.9 M | 26.8 G | 34.3 MB | |
| YOLOv7 | 70.0% | 64.8% | 67.3% | 64.1% | 37.6 M | 106.5 G | 142.0 MB | |
| YOLOv8n | 78.5% | 65.7% | 71.5% | 69.5% | 3.1 M | 8.1 G | 7.6 MB | |
| SD-YOLOv8 | 81.6% | 66.5% | 73.1% | 73.9% | 3.7 M | 12.2 G | 7.6 MB |
| Models | Precision | Recall | F1 Score | ||
|---|---|---|---|---|---|
| YOLOv8n | 89.2% | 88.4% | 88.8% | 92.5% | 66.5% |
| YOLOv8n + Structure | 90.2% | 88.5% | 89.4% | 94.4% | 67.9% |
| Structure + C2f_DCN | 90.1% | 88.8% | 89.4% | 94.8% | 68.9% |
| Structure + BAM | 89.0% | 88.7% | 88.8% | 94.6% | 67.6% |
| Structure + SPPF_LSKA | 91.1% | 88.0% | 89.5% | 94.6% | 67.2% |
| Structure + C2f_DCN + BAM | 89.6% | 87.6% | 88.6% | 94.6% | 68.2% |
| Structure + C2f_DCN + SPPF_LSKA | 90.6% | 87.2% | 88.9% | 94.4% | 68.1% |
| Structure + BAM + SPPF_LSKA | 90.8% | 87.0% | 88.9% | 94.4% | 67.7% |
| Structure + C2f_DCN + BAM | 93.3% | 88.9% | 91.0% | 95.7% | 69.7% |
| + SPPF_LSKA (Ours) |
| Method | Precision | Recall | F1 Score | ||
|---|---|---|---|---|---|
| GIoU | 91.7% | 89.5% | 90.4% | 94.7% | 69.6% |
| CIoU | 90.5% | 87.6% | 89.0% | 94.3% | 68.5% |
| EIoU | 91.0% | 89.5% | 90.2% | 94.8% | 68.7% |
| SIoU | 90.7% | 88.5% | 89.4% | 94.8% | 68.7% |
| MPDIoU | 91.4% | 87.1% | 89.2% | 94.6% | 68.6% |
| InnerIoU | 91.8% | 89.8% | 90.8% | 95.3% | 69.1% |
| Inner-MPDIoU (Ours) | 93.3% | 88.9% | 91.0% | 95.7% | 69.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Li, R.; Hou, M.; Zhang, C.; Hu, J.; Wu, Y. SD-YOLOv8: An Accurate Seriola dumerili Detection Model Based on Improved YOLOv8. Sensors 2024, 24, 3647. https://doi.org/10.3390/s24113647
Liu M, Li R, Hou M, Zhang C, Hu J, Wu Y. SD-YOLOv8: An Accurate Seriola dumerili Detection Model Based on Improved YOLOv8. Sensors. 2024; 24(11):3647. https://doi.org/10.3390/s24113647
Chicago/Turabian StyleLiu, Mingxin, Ruixin Li, Mingxin Hou, Chun Zhang, Jiming Hu, and Yujie Wu. 2024. "SD-YOLOv8: An Accurate Seriola dumerili Detection Model Based on Improved YOLOv8" Sensors 24, no. 11: 3647. https://doi.org/10.3390/s24113647
APA StyleLiu, M., Li, R., Hou, M., Zhang, C., Hu, J., & Wu, Y. (2024). SD-YOLOv8: An Accurate Seriola dumerili Detection Model Based on Improved YOLOv8. Sensors, 24(11), 3647. https://doi.org/10.3390/s24113647