

Towards Reliability in Smart Water Sensing Technology: Evaluating Classical Machine Learning Models for Outlier Detection


Abstract
1. Introduction
2. Related Work
3. Anomaly Detection
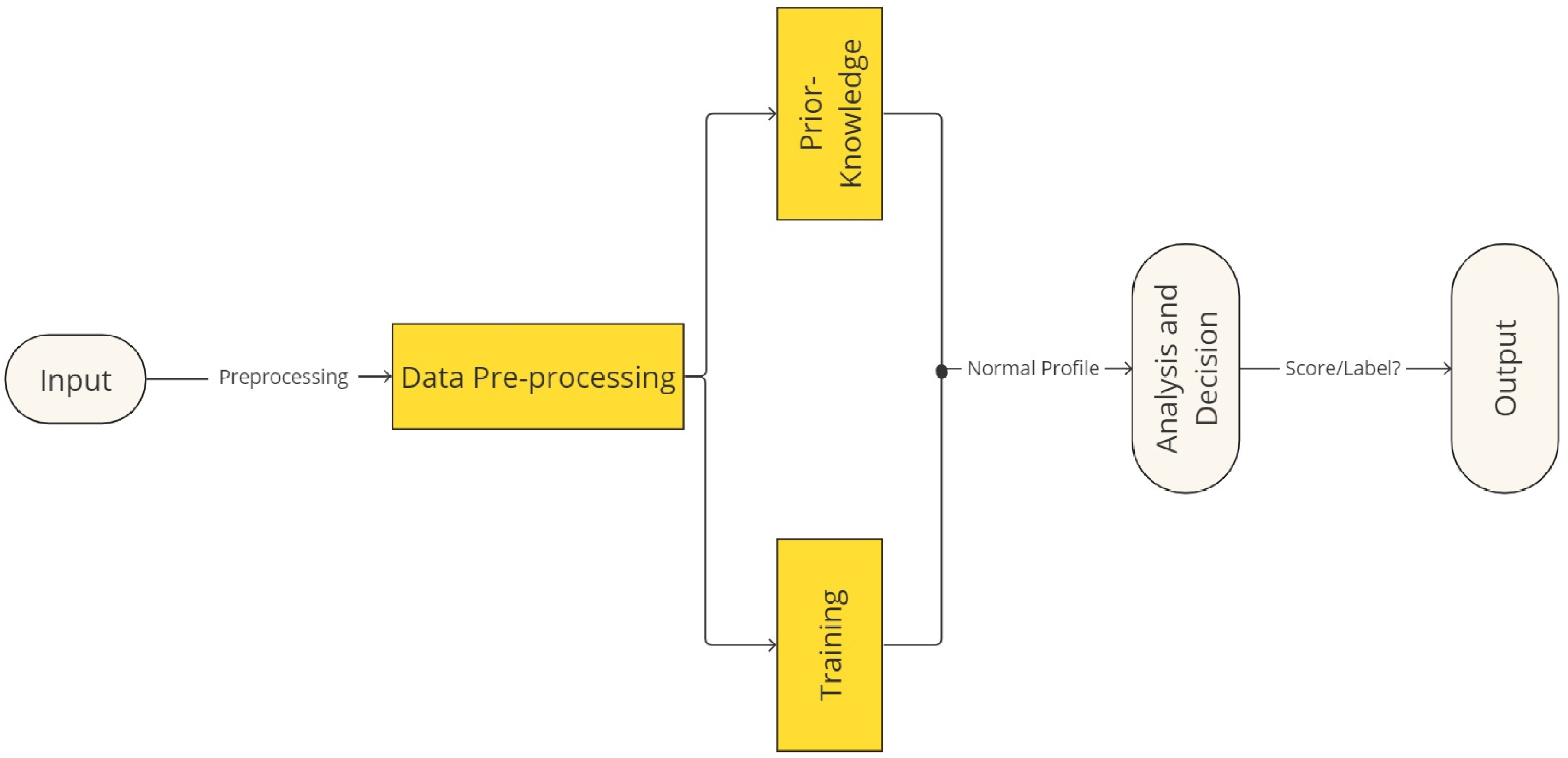
3.1. Anomaly Detection Framework
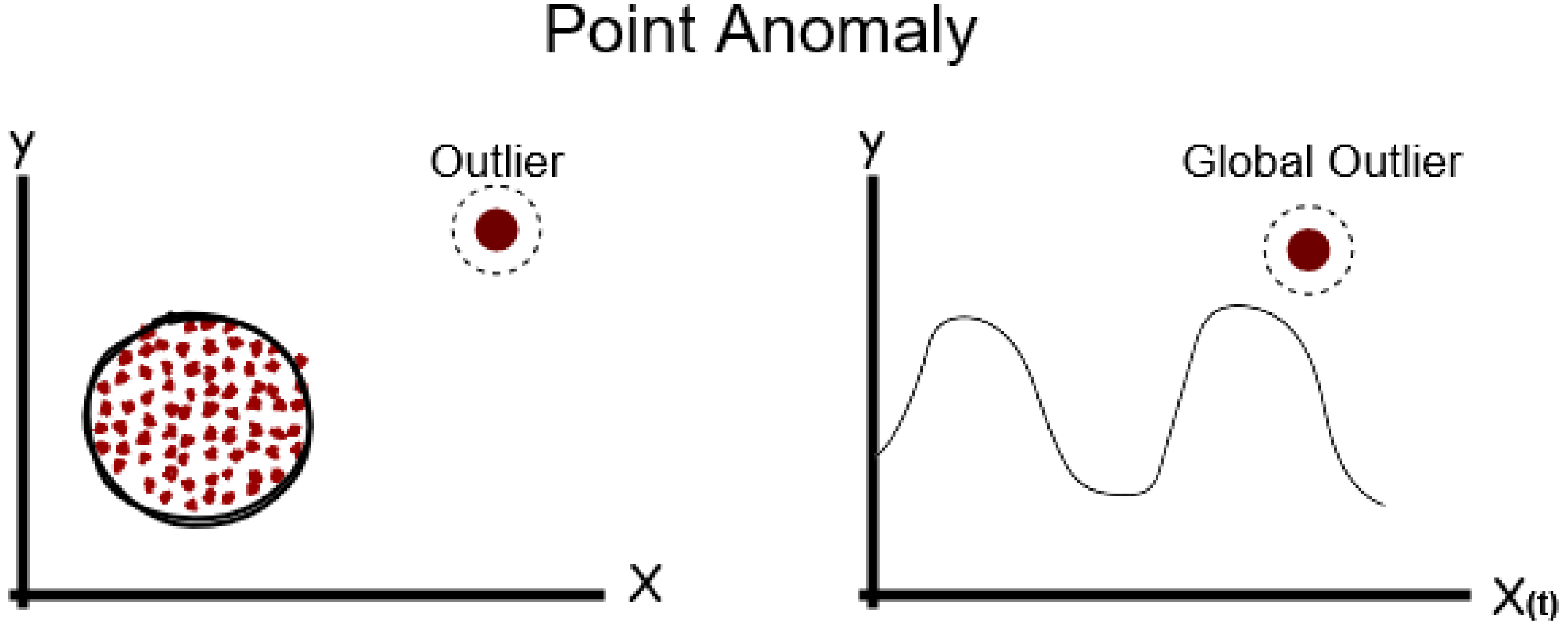
3.1.1. Point Anomalies
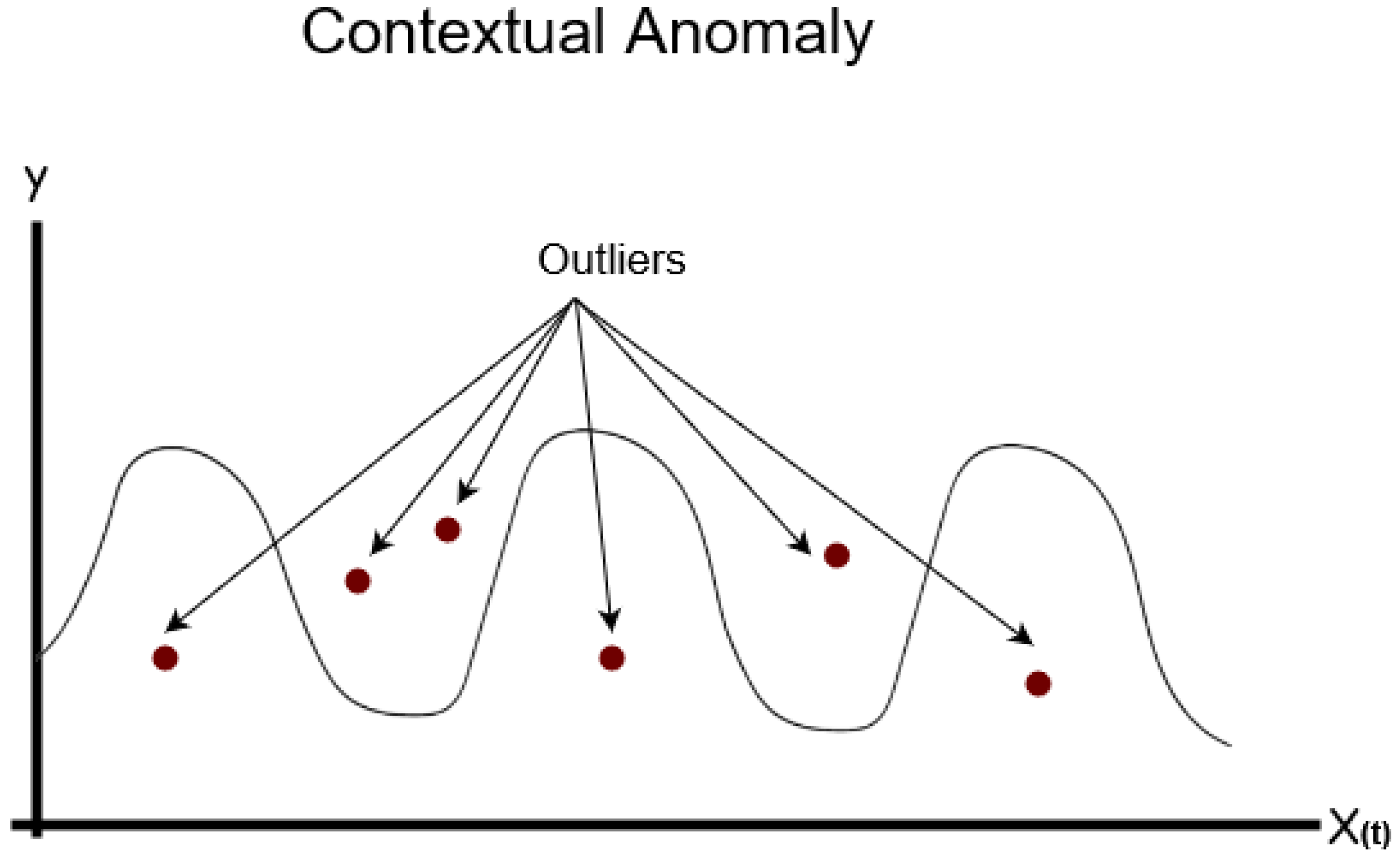
3.1.2. Contextual Anomalies
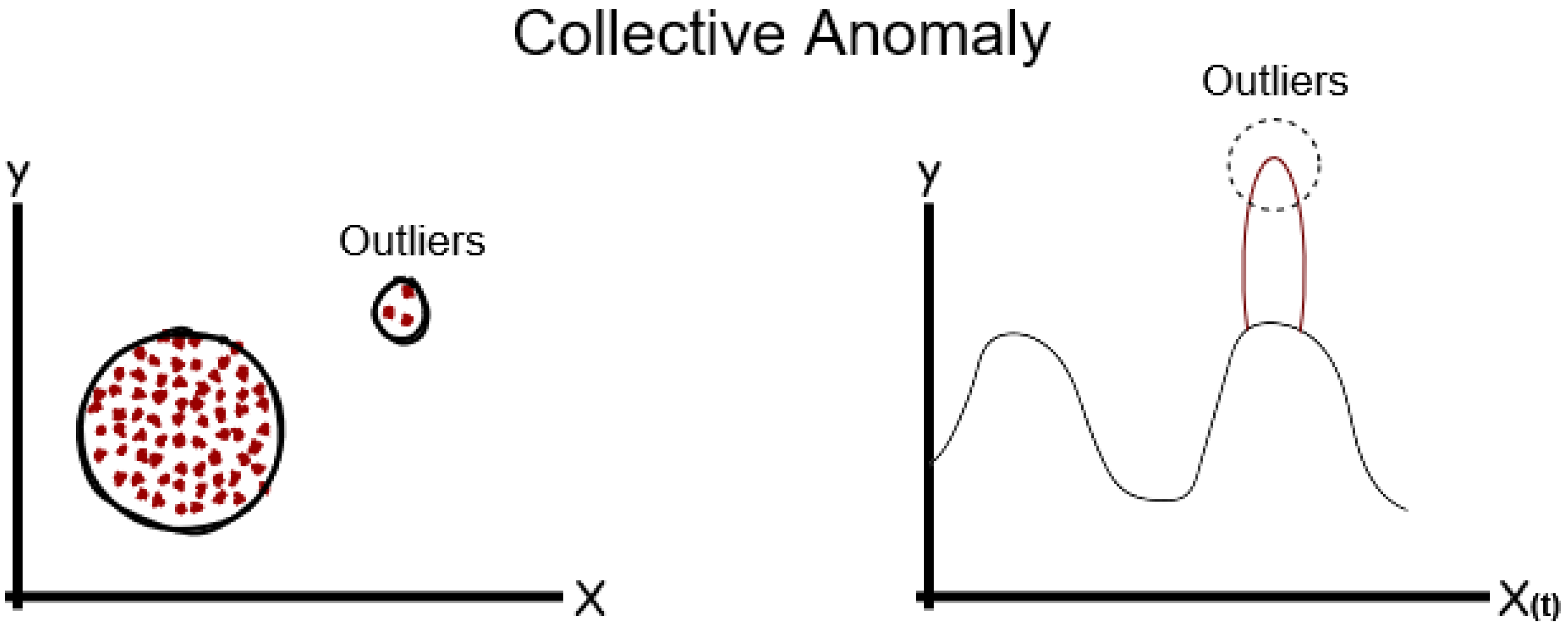
3.1.3. Collective Anomalies
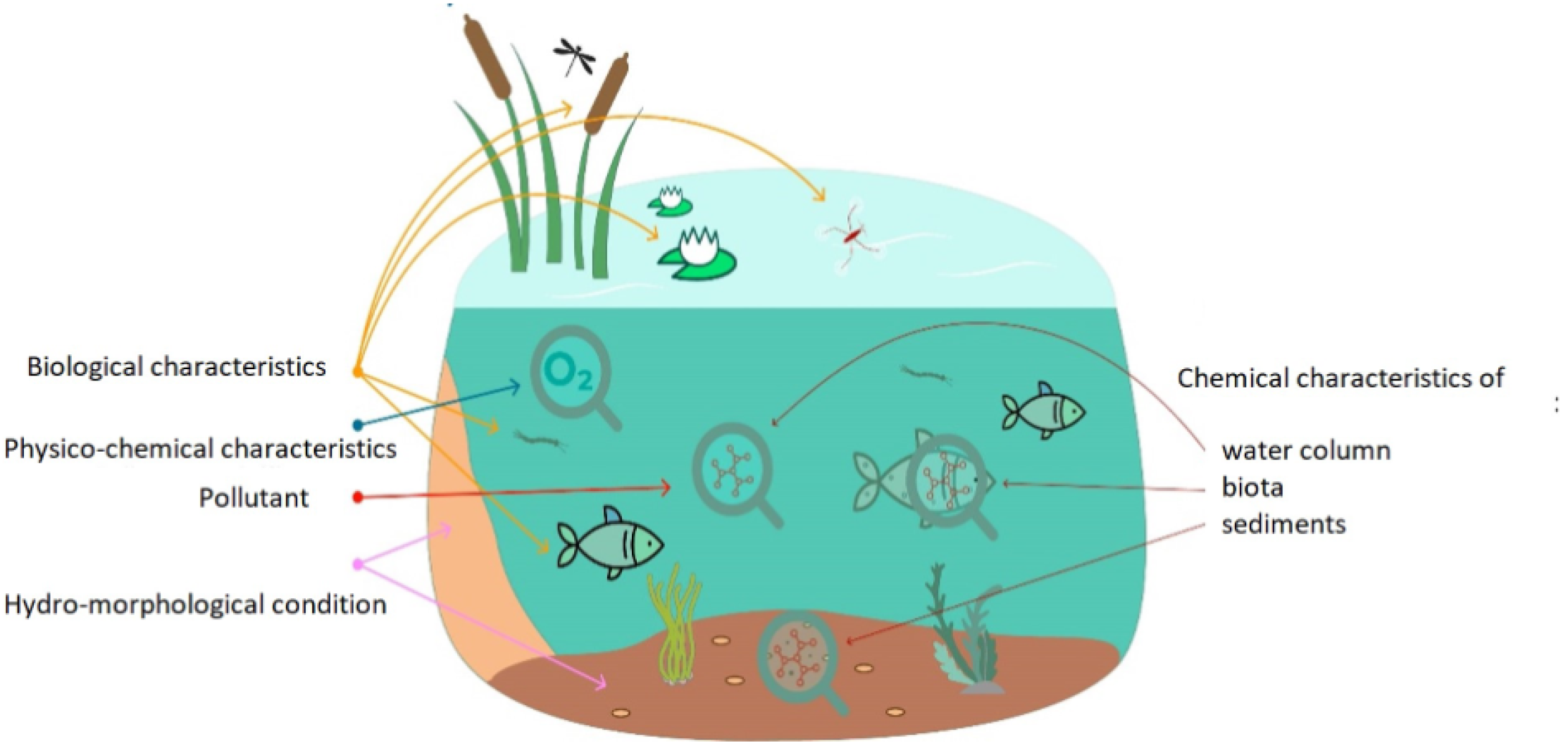
4. Sensing Parameters
- pH
- Temp
- EC
- DO
5. Methodology
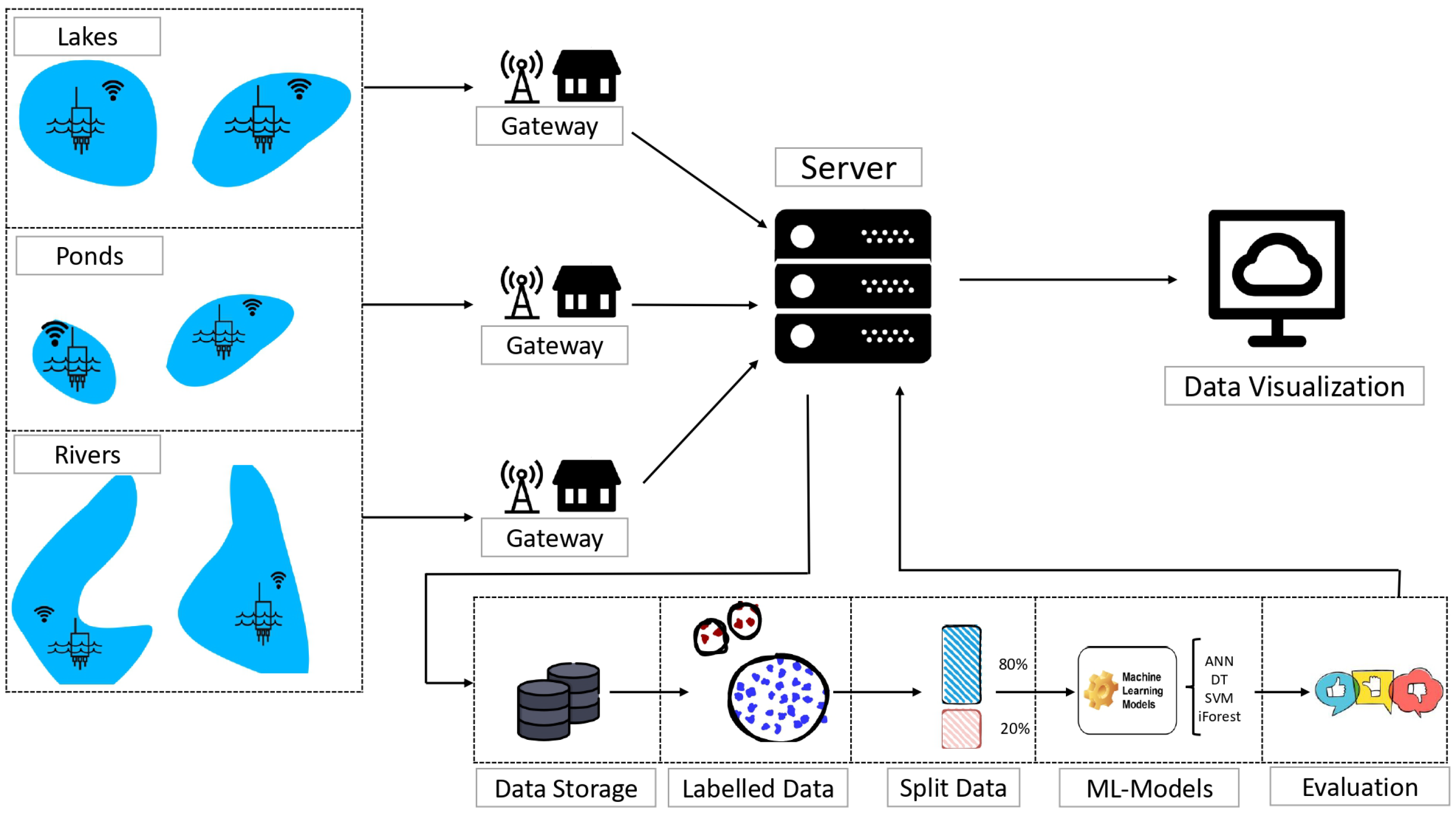
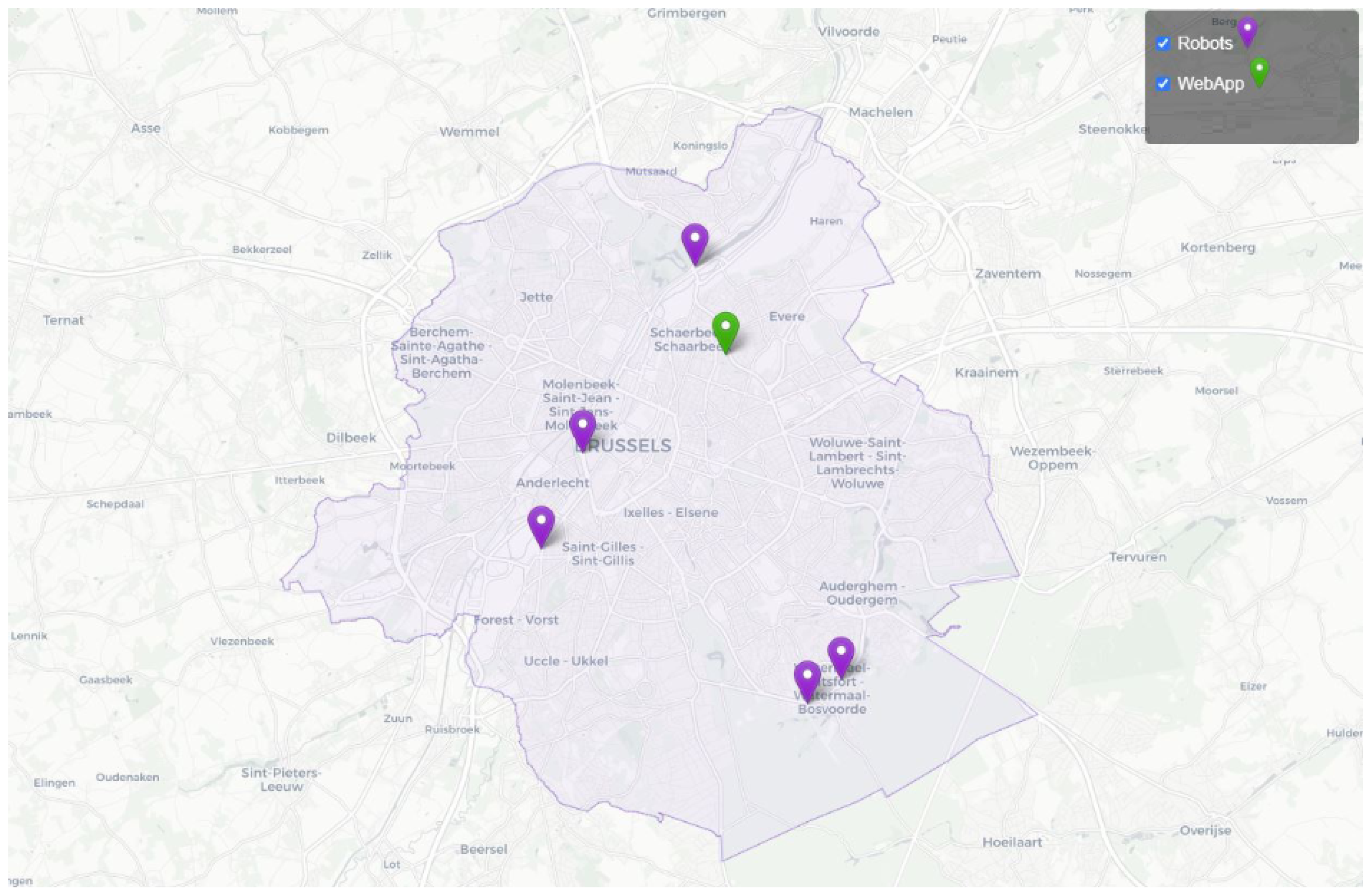
5.1. Deployment
5.2. Datasets Selection
5.3. Fine-Tuning and Classifiers
- ANN: It is a set of interconnected nodes designed to imitate the functioning of the human brain. Each node has a weighted connection to several other nodes in neighboring layers. Individual nodes take the input received from the connected nodes and use the weights together with a simple function to compute output values. Neural networks can be constructed for supervised or unsupervised learning. The user specifies the number of hidden layers as well as the number of nodes within a specific hidden layer. Depending on the application, the output layer of the neural network may contain one or several nodes. The multilayer perceptions (MLP) neural networks have succeeded in various applications and produced more accurate results than other computational learning models. They can approximate any continuous function to a random accuracy as long as they contain enough hidden units. Such models can form any classification decision boundary in feature space and thus act as a non-linear discriminate function [29]. ANN is known to be a good technique for the classification of complex datasets. In this study, we used ANN with two hidden layers and an output layer with a single neuron for binary classification, where the ReLu activation function is used in the hidden layer and a sigmoid activation function is used in the output layer. To train the model, we used the Adam optimizer, with a learning rate equal to 0.0001 and regularization parameter equal to 0.1.
- SVM: SVM is a supervised machine learning algorithm introduced by [30], which can be used for classification and regression problems. The SVM technique separates the data belonging to different classes by fitting a hyperplane between them, which maximizes the separation. The data are mapped into a higher dimensional feature space where a hyperplane can easily separate it. Furthermore, a kernel function approximates the dot products between the mapped vectors in the feature space to find the hyperplane. In addition, using the binary classification approach, SVM uses one-class quarter sphere to reduce the effort of computational complexity and locally identify outliers generated by the sensors. Consequently, the sensor data outside the quarter sphere are considered as the outlier [31]. We tested different variants using SVM by changing the parameters kernel, regularization parameter, and gamma. After parameter tunning, kernel = ‘rbf’, regularization parameter = 0.1, and gamma = 0.001 achieved one of the best -score.
- DT: The DT algorithm is considered a powerful technique for detecting and manipulating outliers within datasets. It is a type of supervised machine learning algorithm that can be used for both classification and regression. When a DT is trained on datasets, it learns to recursively split the data based on feature values that minimize some measure of impurity [32]. During this process, the DT may isolate certain observations into internal nodes (leaf nodes) that are distinct from the majority of data points. These isolated instances could potentially be outliers. The DT algorithm can be effectively used for outliers detection because of its capability to partition the feature space and isolate instances that deviate significantly from the majority of data points [33]. In this study, we used DT with its default parameters, because after the fine tuning of its parameters, the model provided approximately the same values. In this context, we decided to go with the default parameters: Nestmators = 50, MinSampleSplit = 2, MinSampleLeaf = 1, Maxfeatures = auto.
- iForest: The iForest algorithm relies on creating a set of binary decision trees. Unlike the decision trees, the iForest trees randomly selected features and split points to create partitions. This process of randomly finding the trees can sometimes be powerful as outliers are often located in sparsely populated regions of the feature space. More specifically, the isolation forest algorithm gives an isolation score to each data point based on its average path length across all the trees in the forest. Data points with shorter average path length are considered outliers, as they demand fewer splits to isolate [34]. For the iForest, we used contamination with a value of 0.1 and N-estimators with 50 as the value.
5.4. Metrics
Accuracy
6. Evaluation and Platforms
6.1. Dataset Pre-Processing
6.2. Platforms and Experimental Setup
7. Results and Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- El-Shafeiy, E.; Alsabaan, M.; Ibrahem, M.I.; Elwahsh, H. Real-Time Anomaly Detection for Water Quality Sensor Monitoring Based on Multivariate Deep Learning Technique. Sensors 2023, 23, 8613. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Yu, W.; Rahayu, W.; Dillon, T. An Evaluative Study on IoT ecosystem for Smart Predictive Maintenance (IoT-SPM) in Manufacturing: Multi-view Requirements and Data Quality. IEEE Internet Things J. 2023, 10, 11160–11184. [Google Scholar] [CrossRef]
- Salemdawod, A.; Aslan, Z. Water and air quality in modern farms using neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Inoue, J.; Yamagata, Y.; Chen, Y.; Poskitt, C.M.; Sun, J. Anomaly detection for a water treatment system using unsupervised machine learning. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1058–1065. [Google Scholar]
- Leigh, C.; Alsibai, O.; Hyndman, R.J.; Kandanaarachchi, S.; King, O.C.; McGree, J.M.; Neelamraju, C.; Strauss, J.; Talagala, P.D.; Turner, R.D.; et al. A framework for automated anomaly detection in high frequency water-quality data from in situ sensors. Sci. Total Environ. 2019, 664, 885–898. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wang, P.; Jiang, D.; Nan, J.; Zhu, W. An integrated data-driven framework for surface water quality anomaly detection and early warning. J. Clean. Prod. 2020, 251, 119145. [Google Scholar] [CrossRef]
- van de Wiel, L.; van Es, D.M.; Feelders, A. Real-time outlier detection in time series data of water sensors. In Proceedings of the International Workshop on Advanced Analytics and Learning on Temporal Data, Ghent, Belgium, 14 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 155–170. [Google Scholar]
- Mokua, N.; Maina, C.; Kiragu, H. Anomaly Detection for Raw Water Quality—A Comparative Analysis of the Local Outlier Factor Algorithm and the Random Forest Algorithms. Int. J. Comput. Appl. 2021, 174, 49–54. [Google Scholar] [CrossRef]
- Fang, S.; Sun, W.; Huang, L. Anomaly Detection for Water Supply Data using Machine Learning Technique. J. Phys. Conf. Ser. 2019, 1345, 022054. [Google Scholar] [CrossRef]
- Raciti, M.; Cucurull, J.; Nadjm-Tehrani, S. Anomaly detection in water management systems. In Critical Infrastructure Protection: Information Infrastructure Models, Analysis, and Defense; Springer: Berlin/Heidelberg, Germany, 2012; pp. 98–119. [Google Scholar]
- Talagala, P.D.; Hyndman, R.J.; Leigh, C.; Mengersen, K.; Smith-Miles, K. A feature-based procedure for detecting technical outliers in water-quality data from in situ sensors. Water Resour. Res. 2019, 55, 8547–8568. [Google Scholar] [CrossRef]
- Jesus, G.; Casimiro, A.; Oliveira, A. Using machine learning for dependable outlier detection in environmental monitoring systems. ACM Trans. Cyber-Phys. Syst. 2021, 5, 29. [Google Scholar] [CrossRef]
- Bourelly, C.; Bria, A.; Ferrigno, L.; Gerevini, L.; Marrocco, C.; Molinara, M.; Cerro, G.; Cicalini, M.; Ria, A. A preliminary solution for anomaly detection in water quality monitoring. In Proceedings of the 2020 IEEE International Conference on Smart Computing (SMARTCOMP), Bologna, Italy, 14–17 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 410–415. [Google Scholar]
- González-Vidal, A.; Cuenca-Jara, J.; Skarmeta, A. IoT for water management: Towards intelligent anomaly detection. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT), Limerick, Ireland, 15–18 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 858–863. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, X.; Yue, Y.; Wong, P.W. A real-time anomaly detection algorithm/or water quality data using dual time-moving windows. In Proceedings of the 2017 Seventh International Conference on Innovative Computing Technology (INTECH), Luton, UK, 16–18 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 36–41. [Google Scholar]
- Jáquez, A.D.B.; Herrera, M.T.A.; Celestino, A.E.M.; Ramírez, E.N.; Cruz, D.A.M. Extension of LoRa Coverage and Integration of an Unsupervised Anomaly Detection Algorithm in an IoT Water Quality Monitoring System. Water 2023, 15, 1351. [Google Scholar] [CrossRef]
- Grubbs, F.E. Procedures for detecting outlying observations in samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 15. [Google Scholar] [CrossRef]
- Rajasegarar, S.; Leckie, C.; Palaniswami, M. Anomaly detection in wireless sensor networks. IEEE Wirel. Commun. 2008, 15, 34–40. [Google Scholar] [CrossRef]
- Garcia-Teodoro, P.; Diaz-Verdejo, J.; Maciá-Fernández, G.; Vázquez, E. Anomaly-based network intrusion detection: Techniques, systems and challenges. Comput. Secur. 2009, 28, 18–28. [Google Scholar] [CrossRef]
- Görnitz, N.; Kloft, M.; Rieck, K.; Brefeld, U. Toward supervised anomaly detection. J. Artif. Intell. Res. 2013, 46, 235–262. [Google Scholar] [CrossRef]
- Types of Data Anomalies. Available online: https://medium.com/datadailyread/types-of-data-anomalies-2f6fb1747eb1 (accessed on 22 February 2024).
- Uddin, M.G.; Nash, S.; Olbert, A.I. A review of water quality index models and their use for assessing surface water quality. Ecol. Indic. 2021, 122, 107218. [Google Scholar] [CrossRef]
- Quevy, Q.; Lamrini, M.; Chkouri, M.; Cornetta, G.; Touhafi, A.; Campo, A. Open Sensing System for Long Term, Low Cost Water Quality Monitoring. IEEE Open J. Ind. Electron. Soc. 2023, 4, 27–41. [Google Scholar] [CrossRef]
- World Health Organization. Guidelines for Drinking-Water Quality; World Health Organization: Geneva, Switzerland, 2012; Volume 1. [Google Scholar]
- Das Kangabam, R.; Bhoominathan, S.; Kanagaraj, S.; Govindaraju, M. Development of a water quality index (WQI) for the Loktak Lake in India. Appl. Water Sci. 2017, 7, 2907–2918. [Google Scholar] [CrossRef]
- Ito, Y.; Momii, K. Impacts of regional warming on long-term hypolimnetic anoxia and dissolved oxygen concentration in a deep lake. Hydrol. Process. 2015, 29, 2232–2242. [Google Scholar] [CrossRef]
- Hendriarianti, E.; Wulandari, C.D.; Novitasari, E. River water quality performance from carbondeoxygenation rate. Int. J. Eng. Manag. 2017, 1, 28–34. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Outlier detection: A survey. ACM Comput. Surv. 2007, 14, 15. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Agrawal, S.; Agrawal, J. Survey on anomaly detection using data mining techniques. Procedia Comput. Sci. 2015, 60, 708–713. [Google Scholar] [CrossRef]
- Panasov, V.; Nechitaylo, N. Decision Trees-based Anomaly Detection in Computer Assessment Results. J. Phys. Conf. Ser. 2021, 2001, 012033. [Google Scholar] [CrossRef]
- Reif, M.; Goldstein, M.; Stahl, A.; Breuel, T.M. Anomaly detection by combining decision trees and parametric densities. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–4. [Google Scholar]
- Ding, Z.; Fei, M. An anomaly detection approach based on isolation forest algorithm for streaming data using sliding window. IFAC Proc. Vol. 2013, 46, 12–17. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Lipton, Z.C.; Elkan, C.; Naryanaswamy, B. Optimal thresholding of classifiers to maximize F1 measure. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2014, Nancy, France, 15–19 September 2014; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2014; pp. 225–239. [Google Scholar]
- Fujino, A.; Isozaki, H.; Suzuki, J. Multi-label text categorization with model combination based on f1-score maximization. In Proceedings of the Third International Joint Conference on Natural Language Processing, Hyderabad, India, 7–12 January 2008; Volume-II. [Google Scholar]
- Evaluating Multi-Class Classifier. Available online: https://medium.com/apprentice-journal/evaluating-multi-class-classifiers-12b2946e755b (accessed on 1 March 2024).
- Performance Measures for Multi-Class Problems. Available online: https://www.datascienceblog.net/post/machine-learning/performance-measures-multi-class-problems/ (accessed on 7 March 2024).
- Experimental Platforms 2020: SmartWater: SmartWater Monitoring in Brussels. Available online: https://researchportal.vub.be/en/projects/experimental-platforms-2020-smartwater-smartwater-monitoring-in-b (accessed on 12 March 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Supervided | Semi-Supervised | Unupervised | |
|---|---|---|---|
| Prior-Knowledge? | Yes | Yes | No |
| Environment? | Static | Dynamic | Dynamic |
| Detection speed? | fast | Fast/Moderate | Moderate/slow |
| Detection generality? | No | Yes | Yes |
| Parameters | Units | WHO Standards [25] | Analytical Methods [26] |
|---|---|---|---|
| pH | - | 6.5–8.5 | pH meter |
| EC | μs/cm | 400 | Electrometric |
| Temp | °C | 12–25 | Digital thermometer |
| DO | mg/L | 4–6 | Winkler method |
| Models | Precision | Recall | -Score | |
|---|---|---|---|---|
| SVM | Train | 0.9599 | 1 | 0.9796 |
| Test | 0.9681 | 1 | 0.9838 | |
| iForest | Train | 0.775487 | 0.82154 | 0.7978 |
| Test | 0.754875 | 0.800014 | 0.7767 | |
| DT | Train | 0.9599 | 0.97002 | 0.9649 |
| Test | 0.9681 | 0.96004 | 0.9640 | |
| ANN | Train | 0.9 | 0.95 | 0.9243 |
| Test | 0.8925 | 0.9422 | 0.9167 |
| Models | Precision | Recall | -Score | |
|---|---|---|---|---|
| SVM | Train | 0.97145 | 0.984421 | 0.9778 |
| Test | 0.95998 | 0.97999 | 0.9698 | |
| iForest | Train | 0.7823 | 0.825574 | 0.8033 |
| Test | 0.76545 | 0.8021254 | 0.7833 | |
| DT | Train | 0.88 | 0.9 | 0.8898 |
| Test | 0.8732 | 0.8854 | 0.8792 | |
| ANN | Train | 0.94 | 0.96 | 0.9498 |
| Test | 0.9354 | 0.9588 | 0.9469 |
| Models | Precision | Recall | -Score | |
|---|---|---|---|---|
| SVM | Train | 0.9832 | 0.9745 | 0.9788 |
| Test | 0.9720 | 0.9610 | 0.9666 | |
| iForest | Train | 0.8054 | 0.7899 | 0.7976 |
| Test | 0.7921 | 0.7885 | 0.7903 | |
| DT | Train | 0.9 | 0.92 | 0.9098 |
| Test | 0.899 | 0.9125 | 0.9076 | |
| ANN | Train | 0.9877 | 0.9751 | 0.9813 |
| Test | 0.9835 | 0.9742 | 0.9788 |
| Models | Precision | Recall | -Score | |
|---|---|---|---|---|
| SVM | Train | 0.98400 | 0.97897 | 0.9814 |
| Test | 0.9752 | 0.9695 | 0.9723 | |
| iForest | Train | 0.8288 | 0.7756 | 0.8013 |
| Test | 0.72400 | 0.7766 | 0.7494 | |
| DT | Train | 0.8920 | 0.8854 | 0.8871 |
| Test | 0.8912 | 0.8766 | 0.8839 | |
| ANN | Train | 0.9900 | 0.9845 | 0.9872 |
| Test | 0.9802 | 0.9820 | 0.9811 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lamrini, M.; Ben Mahria, B.; Chkouri, M.Y.; Touhafi, A. Towards Reliability in Smart Water Sensing Technology: Evaluating Classical Machine Learning Models for Outlier Detection. Sensors 2024, 24, 4084. https://doi.org/10.3390/s24134084
Lamrini M, Ben Mahria B, Chkouri MY, Touhafi A. Towards Reliability in Smart Water Sensing Technology: Evaluating Classical Machine Learning Models for Outlier Detection. Sensors. 2024; 24(13):4084. https://doi.org/10.3390/s24134084
Chicago/Turabian StyleLamrini, Mimoun, Bilal Ben Mahria, Mohamed Yassin Chkouri, and Abdellah Touhafi. 2024. "Towards Reliability in Smart Water Sensing Technology: Evaluating Classical Machine Learning Models for Outlier Detection" Sensors 24, no. 13: 4084. https://doi.org/10.3390/s24134084
APA StyleLamrini, M., Ben Mahria, B., Chkouri, M. Y., & Touhafi, A. (2024). Towards Reliability in Smart Water Sensing Technology: Evaluating Classical Machine Learning Models for Outlier Detection. Sensors, 24(13), 4084. https://doi.org/10.3390/s24134084