
Tiny-Machine-Learning-Based Supply Canal Surface Condition Monitoring


Abstract
1. Introduction
- We designed and evaluated a custom lightweight CNN architecture for remote sensing images and compared its performance with that of common CNN models.
- For the first time, we applied the proposed CNN model to classify cracks in supply water canals and deployed it on low-power, resource-constrained MCUs, and we also explored the deployability of other CNN models on MCUs.
- In addition to accuracy and model size, we also comprehensively compared deployable CNN models in terms of RAM, flash usage, energy consumption, and inference time, providing a feasibility exploration for continuous online health monitoring of hydraulic infrastructure based on remote sensing imagery.
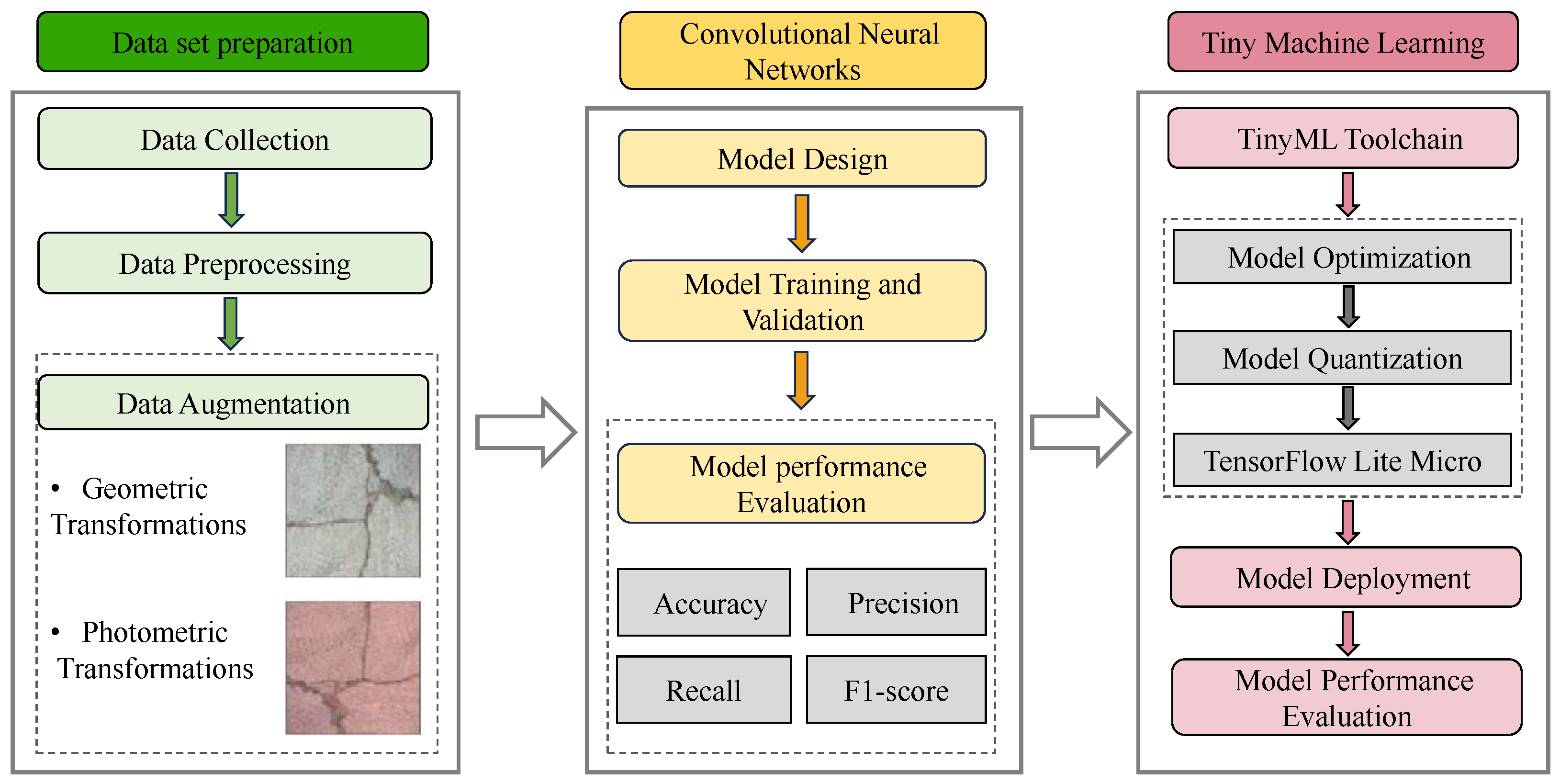
2. Datasets
2.1. Data Collection
2.2. Data Preprocessing
2.3. Data Augmentation
3. Convolutional Neural Networks
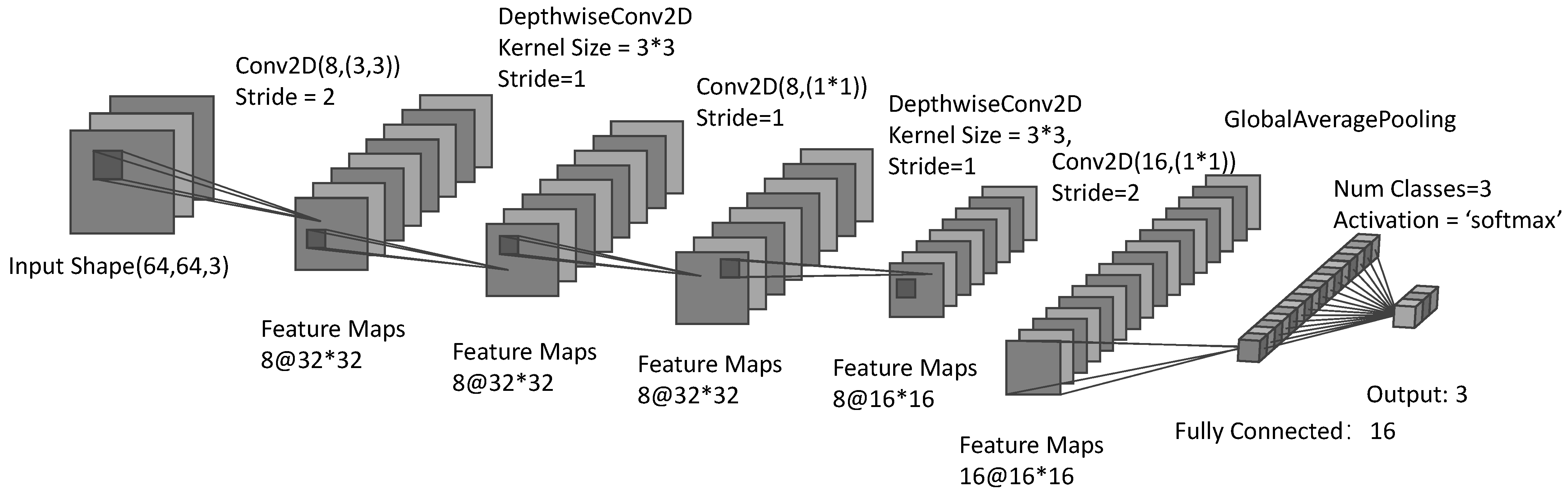
3.1. Model Design
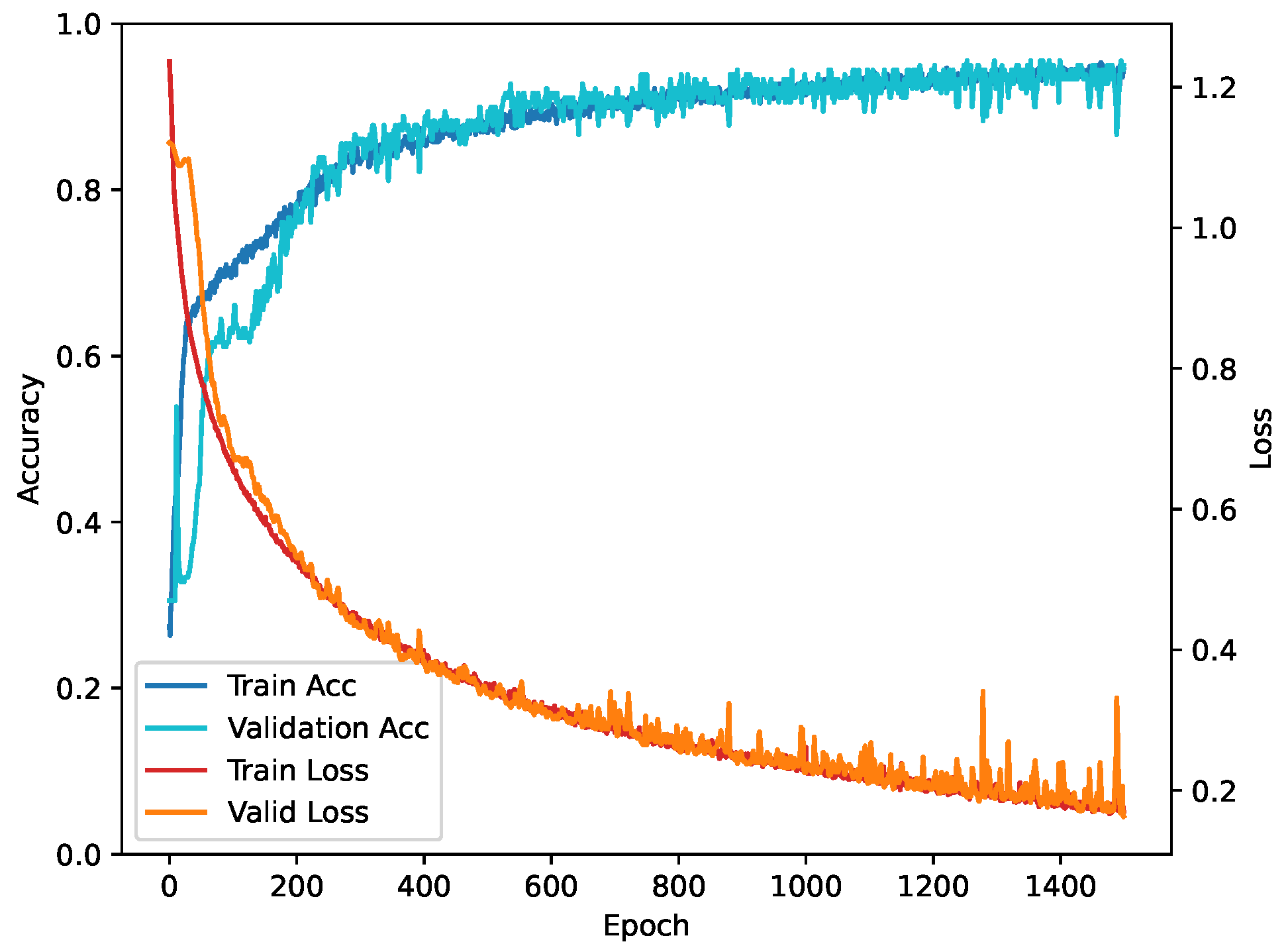
3.2. Model Training and Validation
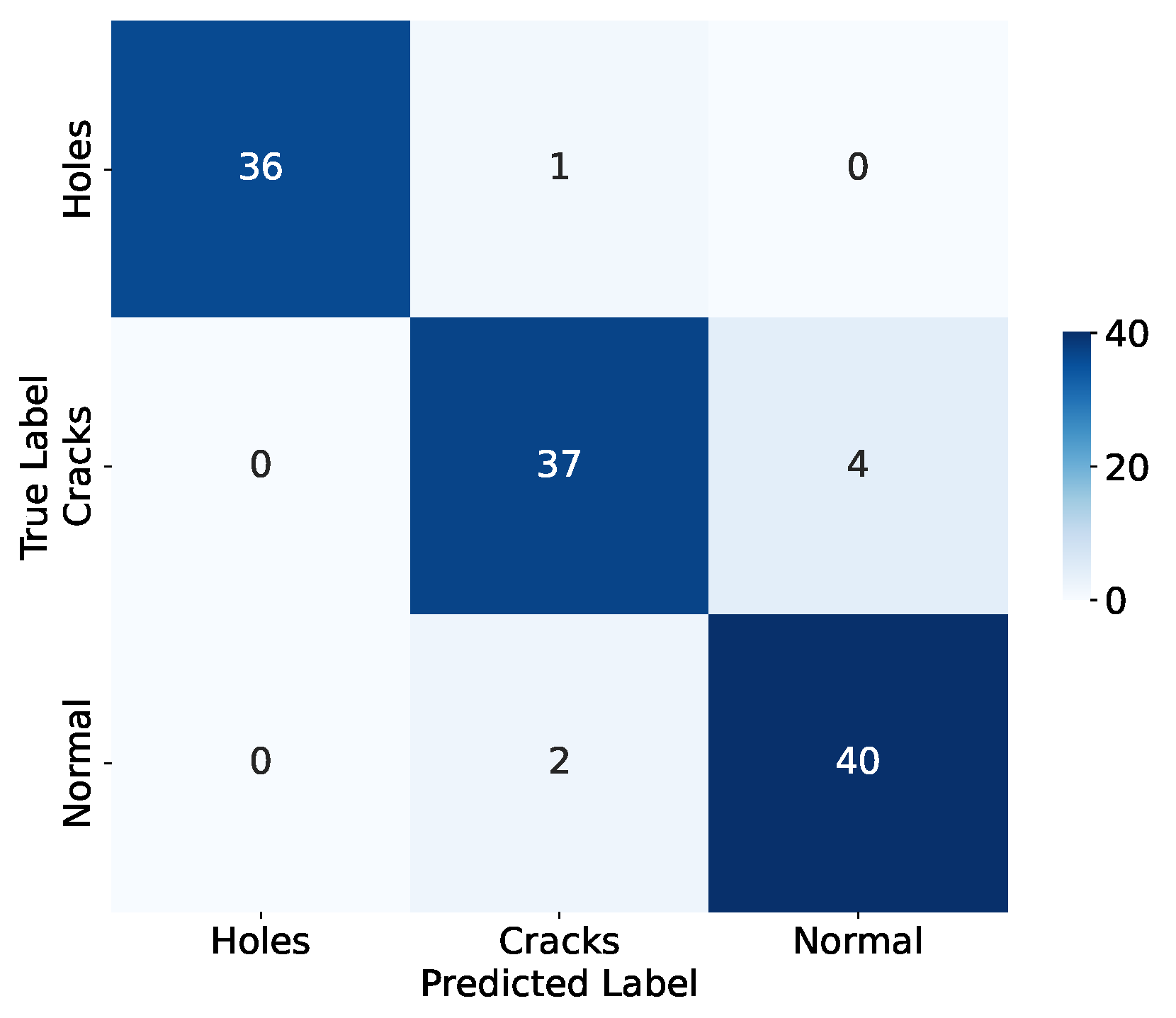
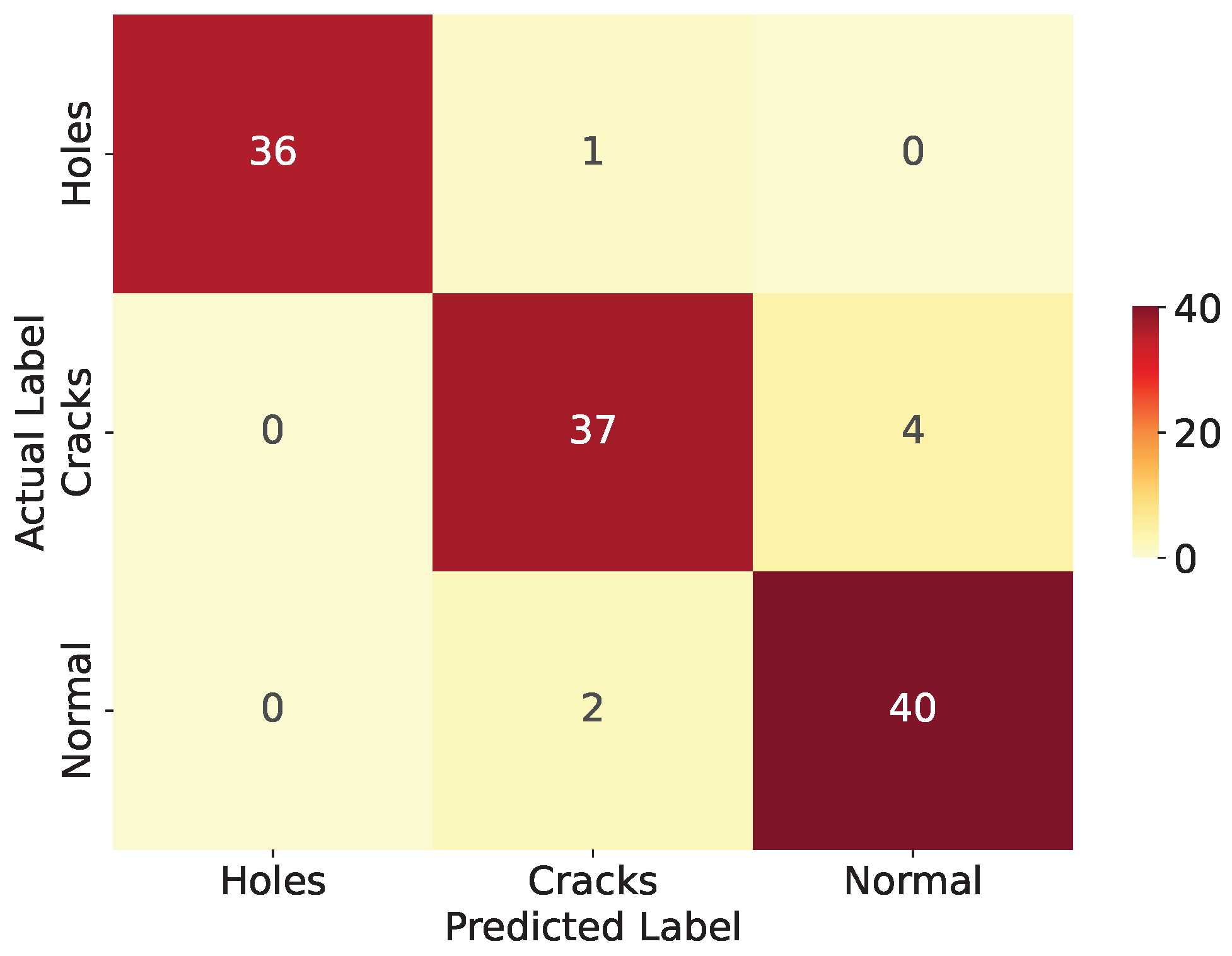
3.3. Model Performance Evaluation
4. Tiny Machine Learning
4.1. TinyML Toolchain
4.2. Model Deployment and Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Q. The South-to-North Water Transfer Project of China: Environmental Implications and Monitoring Strategy 1. JAWRA J. Am. Water Resour. Assoc. 2009, 45, 1238–1247. [Google Scholar] [CrossRef]
- Long, D.; Yang, W.; Scanlon, B.R.; Zhao, J.; Liu, D.; Burek, P.; Pan, Y.; You, L.; Wada, Y. South-to-North Water Diversion stabilizing Beijing’s groundwater levels. Nat. Commun. 2020, 11, 3665. [Google Scholar] [CrossRef]
- Yan, H.; Lin, Y.; Chen, Q.; Zhang, J.; He, S.; Feng, T.; Wang, Z.; Chen, C.; Ding, J. A Review of the Eco-Environmental Impacts of the South-to-North Water Diversion: Implications for Interbasin Water Transfers. Engineering 2023, 30, 161–169. [Google Scholar] [CrossRef]
- Ge, W.; Li, Z.; Liang, R.Y.; Li, W.; Cai, Y. Methodology for establishing risk criteria for dams in developing countries, case study of China. Water Resour. Manag. 2017, 31, 4063–4074. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- He, Y.; Zhang, L.; Chen, Z.; Li, C.Y. A framework of structural damage detection for civil structures using a combined multi-scale convolutional neural network and echo state network. Eng. Comput. 2023, 39, 1771–1789. [Google Scholar] [CrossRef]
- Jayawickrema, U.; Herath, H.; Hettiarachchi, N.; Sooriyaarachchi, H.; Epaarachchi, J. Fibre-optic sensor and deep learning-based structural health monitoring systems for civil structures: A review. Measurement 2022, 199, 111543. [Google Scholar] [CrossRef]
- González-deSantos, L.M.; Martínez-Sánchez, J.; González-Jorge, H.; Navarro-Medina, F.; Arias, P. UAV payload with collision mitigation for contact inspection. Autom. Constr. 2020, 115, 103200. [Google Scholar] [CrossRef]
- Bui, K.T.T.; Tien Bui, D.; Zou, J.; Van Doan, C.; Revhaug, I. A novel hybrid artificial intelligent approach based on neural fuzzy inference model and particle swarm optimization for horizontal displacement modeling of hydropower dam. Neural Comput. Appl. 2018, 29, 1495–1506. [Google Scholar] [CrossRef]
- Li, Y.; Wang, H.; Dang, L.M.; Nguyen, T.N.; Han, D.; Lee, A.; Jang, I.; Moon, H. A deep learning-based hybrid framework for object detection and recognition in autonomous driving. IEEE Access 2020, 8, 194228–194239. [Google Scholar] [CrossRef]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Hussein, M.; Gabbouj, M.; Inman, D.J. A review of vibration-based damage detection in civil structures: From traditional methods to Machine Learning and Deep Learning applications. Mech. Syst. Signal Process. 2021, 147, 107077. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Rosso, M.M.; Marasco, G.; Aiello, S.; Aloisio, A.; Chiaia, B.; Marano, G.C. Convolutional networks and transformers for intelligent road tunnel investigations. Comput. Struct. 2023, 275, 106918. [Google Scholar] [CrossRef]
- Resende, L.; Finotti, R.; Barbosa, F.; Garrido, H.; Cury, A.; Domizio, M. Damage identification using convolutional neural networks from instantaneous displacement measurements via image processing. Struct. Health Monit. 2024, 23, 1627–1640. [Google Scholar] [CrossRef]
- Zhang, Y.; Bader, S.; Oelmann, B. A Lightweight Convolutional Neural Network Model for Concrete Damage Classification using Acoustic Emissions. In Proceedings of the 2022 IEEE Sensors Applications Symposium (SAS), Sundsvall, Sweden, 1–3 August 2022; pp. 1–6. [Google Scholar]
- Adın, V.; Zhang, Y.; Oelmann, B.; Bader, S. Tiny Machine Learning for Damage Classification in Concrete Using Acoustic Emission Signals. In Proceedings of the 2023 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Kuala Lumpur, Malaysia, 22–25 May 2023; pp. 1–6. [Google Scholar]
- Wang, N.; Zhao, Q.; Li, S.; Zhao, X.; Zhao, P. Damage classification for masonry historic structures using convolutional neural networks based on still images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1073–1089. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road damage detection and classification using deep neural networks with smartphone images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Ercan, E.; Avcı, M.S.; Pekedis, M.; Hızal, Ç. Damage Classification of a Three-Story Aluminum Building Model by Convolutional Neural Networks and the Effect of Scarce Accelerometers. Appl. Sci. 2024, 14, 2628. [Google Scholar] [CrossRef]
- Zoubir, H.; Rguig, M.; El Aroussi, M.; Chehri, A.; Saadane, R.; Jeon, G. Concrete bridge defects identification and localization based on classification deep convolutional neural networks and transfer learning. Remote Sens. 2022, 14, 4882. [Google Scholar] [CrossRef]
- Kim, H.Y.; Kim, J.M. A load balancing scheme based on deep-learning in IoT. Clust. Comput. 2017, 20, 873–878. [Google Scholar] [CrossRef]
- Mishra, M.; Lourenço, P.B.; Ramana, G.V. Structural health monitoring of civil engineering structures by using the internet of things: A review. J. Build. Eng. 2022, 48, 103954. [Google Scholar] [CrossRef]
- Garcia Lopez, P.; Montresor, A.; Epema, D.; Datta, A.; Higashino, T.; Iamnitchi, A.; Barcellos, M.; Felber, P.; Riviere, E. Edge-centric computing: Vision and challenges. Comput. Commun. Rev. 2015, 45, 37–42. [Google Scholar] [CrossRef]
- Dutta, L.; Bharali, S. Tinyml meets iot: A comprehensive survey. Internet Things 2021, 16, 100461. [Google Scholar] [CrossRef]
- Adın, V.; Zhang, Y.; Andò, B.; Oelmann, B.; Bader, S. Tiny Machine Learning for Real-Time Postural Stability Analysis. In Proceedings of the 2023 IEEE Sensors Applications Symposium (SAS), Ottawa, ON, Canada, 18–20 July 2023; pp. 1–6. [Google Scholar]
- Bader, S. Instrumentation and Measurement Systems: Methods, Applications and Opportunities for Instrumentation and Measurement. IEEE Instrum. Meas. Mag. 2023, 26, 28–33. [Google Scholar] [CrossRef]
- Martinez-Rau, L.S.; Adın, V.; Giovanini, L.L.; Oelmann, B.; Bader, S. Real-Time Acoustic Monitoring of Foraging Behavior of Grazing Cattle Using Low-Power Embedded Devices. In Proceedings of the 2023 IEEE Sensors Applications Symposium (SAS), Ottawa, ON, Canada, 18–20 July 2023; pp. 1–6. [Google Scholar]
- Martinez-Rau, L.S.; Chelotti, J.O.; Giovanini, L.L.; Adin, V.; Oelmann, B.; Bader, S. On-Device Feeding Behavior Analysis of Grazing Cattle. IEEE Trans. Instrum. Meas. 2024, 73, 1–13. [Google Scholar] [CrossRef]
- Ratnam, M.M.; Ooi, B.Y.; Yen, K.S. Novel moiré-based crack monitoring system with smartphone interface and cloud processing. Struct. Control Health Monit. 2019, 26, e2420. [Google Scholar] [CrossRef]
- Atanane, O.; Mourhir, A.; Benamar, N.; Zennaro, M. Smart Buildings: Water Leakage Detection Using TinyML. Sensors 2023, 23, 9210. [Google Scholar] [CrossRef] [PubMed]
- James, G.L.; Ansaf, R.B.; Al Samahi, S.S.; Parker, R.D.; Cutler, J.M.; Gachette, R.V.; Ansaf, B.I. An Efficient Wildfire Detection System for AI-Embedded Applications Using Satellite Imagery. Fire 2023, 6, 169. [Google Scholar] [CrossRef]
- Coffen, B.; Mahmud, M. TinyDL: Edge Computing and Deep Learning Based Real-time Hand Gesture Recognition Using Wearable Sensor. In Proceedings of the 2020 IEEE International Conference on E-health Networking, Application and Services (HEALTHCOM), Virtual, 1–2 March 2021; pp. 1–6. [Google Scholar]
- de Prado, M.; Rusci, M.; Capotondi, A.; Donze, R.; Benini, L.; Pazos, N. Robustifying the deployment of tinyml models for autonomous mini-vehicles. Sensors 2021, 21, 1339. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, S.; Yu, F.; Xiong, S.; Dai, Z. Calculation method study of settlement process of high filling channel in south-to-north water diversion project. Chin. J. Rock Mech. Eng. 2014, 33, 4367–4374. [Google Scholar]
- Liu, M.; Wang, L.; Qin, Z.; Liu, J.; Chen, J.; Liu, X. Multi-scale feature extraction and recognition of slope damage in high fill channel based on Gabor-SVM method. J. Intell. Fuzzy Syst. 2020, 38, 4237–4246. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; Van Der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Jung, A. Imgaug documentation. Readthedocs. Io Jun 2019, 25. [Google Scholar]
- Gedraite, E.S.; Hadad, M. Investigation on the effect of a Gaussian Blur in image filtering and segmentation. In Proceedings of the Proceedings ELMAR-2011, Zadar, Croatia, 14–16 September 2011; pp. 393–396. [Google Scholar]
- Russo, F. A method for estimation and filtering of Gaussian noise in images. IEEE Trans. Instrum. Meas. 2003, 52, 1148–1154. [Google Scholar] [CrossRef]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Koonce, B.; Koonce, B. EfficientNet. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: New York, NY, USA, 2021; pp. 109–123. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Hsiao, T.Y.; Chang, Y.C.; Chou, H.H.; Chiu, C.T. Filter-based deep-compression with global average pooling for convolutional networks. J. Syst. Archit. 2019, 95, 9–18. [Google Scholar] [CrossRef]
- Haase, D.; Amthor, M. Rethinking depthwise separable convolutions: How intra-kernel correlations lead to improved mobilenets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 14600–14609. [Google Scholar]
- Eckle, K.; Schmidt-Hieber, J. A comparison of deep networks with ReLU activation function and linear spline-type methods. Neural Netw. 2019, 110, 232–242. [Google Scholar] [CrossRef]
- Lavin, A.; Gray, S. Fast algorithms for convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4013–4021. [Google Scholar]
- Abadi, M. TensorFlow: Learning functions at scale. In Proceedings of the 21st ACM SIGPLAN International Conference on Functional Programming, Nara, Japan, 18–22 September 2016; p. 1. [Google Scholar]
- Smith, S.L.; Kindermans, P.J.; Ying, C.; Le, Q.V. Don’t decay the learning rate, increase the batch size. arXiv 2017, arXiv:1711.00489. [Google Scholar]
- Zhang, Y.; Adin, V.; Bader, S.; Oelmann, B. Leveraging Acoustic Emission and Machine Learning for Concrete Materials Damage Classification on Embedded Devices. IEEE Trans. Instrum. Meas. 2023, 72, 1–8. [Google Scholar] [CrossRef]
- Zhu, M.; Gupta, S. To prune, or not to prune: Exploring the efficacy of pruning for model compression. arXiv 2017, arXiv:1710.01878. [Google Scholar]
- Chai, S.M. Quantization-guided training for compact TinyML models. In Proceedings of the Research Symposium on Tiny Machine Learning, Virtual, 3–18 July 2020. [Google Scholar]
- David, R.; Duke, J.; Jain, A.; Janapa Reddi, V.; Jeffries, N.; Li, J.; Kreeger, N.; Nappier, I.; Natraj, M.; Wang, T.; et al. Tensorflow lite micro: Embedded machine learning for tinyml systems. Proc. Mach. Learn. Syst. 2021, 3, 800–811. [Google Scholar]
- Preuveneers, D.; Verheyen, W.; Joos, S.; Joosen, W. On the adversarial robustness of full integer quantized TinyML models at the edge. In Proceedings of the 2nd International Workshop on Middleware for the Edge, Bologna, Italy, 11 December 2023; pp. 7–12. [Google Scholar]
- Liu, Z.; Wang, Y.; Han, K.; Zhang, W.; Ma, S.; Gao, W. Post-training quantization for vision transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 28092–28103. [Google Scholar]
- Silicon Labs. Machine Learning Toolkit Documentation, 2023. Available online: https://github.com/siliconlabs/mltk (accessed on 9 June 2023).
- Sudharsan, B.; Yadav, P.; Breslin, J.G.; Ali, M.I. An sram optimized approach for constant memory consumption and ultra-fast execution of ml classifiers on tinyml hardware. In Proceedings of the 2021 IEEE International Conference on Services Computing (SCC), Virtual, 5–11 September 2021; pp. 319–328. [Google Scholar]
- Sarvajcz, K.; Ari, L.; Menyhart, J. AI on the Road: NVIDIA Jetson Nano-Powered Computer Vision-Based System for Real-Time Pedestrian and Priority Sign Detection. Appl. Sci. 2024, 14, 1440. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Original Quantity | Train | Validation | Test |
|---|---|---|---|---|
| Normal | 90 | 40 | 10 | 40 |
| Crack | 90 | 40 | 10 | 40 |
| Hole | 90 | 40 | 10 | 40 |
| Total | 270 | 120 | 30 | 120 |
| Category | Training | Validation | Test | Augmentation Method |
|---|---|---|---|---|
| Normal | 240 | 60 | 40 | Adjust contrast, image brightness, rotation, Gaussian noise |
| Crack | 240 | 60 | 40 | |
| Hole | 240 | 60 | 40 | |
| Total | 720 | 180 | 120 |
| Model | Parameters | FLOPs | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|
| ShuffleNetV2 | 1,194,515 | 20,652,799 | 94.95 ± 1.84 | 95.35 ± 1.82 | 95.09 ± 1.68 | 94.75 ± 1.70 |
| ResNet-50 | 23,593,859 | 632,909,458 | 92.25 ± 1.97 | 92.78 ± 1.99 | 92.36 ± 1.66 | 92.33 ± 1.90 |
| MobilenetV2 | 3,572,803 | 52,741,074 | 96.75 ± 1.21 | 96.32 ± 1.56 | 96.02 ± 1.76 | 96.17 ± 1.67 |
| EfficientNet-B0 | 4,053,414 | 66,654,953 | 94.35 ± 2.19 | 94.55 ± 1.74 | 94.50 ± 2.00 | 95.11 ± 1.89 |
| MnasNet | 5,402,239 | 57,892,038 | 94.85 ± 1.84 | 94.33 ± 1.95 | 94.00 ± 2.10 | 94.05 ± 2.10 |
| Our Model | 803 | 905,618 | 94.17 ± 1.67 | 94.47 ± 1.46 | 94.27 ± 1.57 | 94.26 ± 1.94 |
| Specification Category | Description |
|---|---|
| Microcontroller | nRF52840 (ARM Cortex-M4F 32-bit processor) |
| Clock Speed | 64 MHz |
| CPU Flash Memory | 1MB |
| Built-in Sensors | 9-axis IMU (accelerometer, gyroscope, magnetometer), barometer, humidity sensor, temperature sensor, light sensor, and digital microphone |
| Dimensions | 45 × 18 mm |
| Bluetooth | Bluetooth® 5.0 |
| Model | F1-Score (%) | Model Size (KB) | Inference Time (ms) | Flash (MB) | RAM (KB) | Power Consumption per Inference (J) |
|---|---|---|---|---|---|---|
| ShuffleNetV2 | 93.50 ± 1.88 | 4634.55 | —— | 4.70 | 167.5 | —— |
| ResNet-50 | 92.56 ± 2.78 | 91,783.55 | —— | —— | —— | —— |
| MobilenetV2 | 96.63 ± 1.39 | 13,795.55 | —— | 14.10 | 826.8 | —— |
| EfficientNet-B0 | 94.42 ± 2.65 | 15,666.59 | —— | 16.00 | 1200.0 | —— |
| MnasNet | 94.32 ± 2.32 | 20,947.63 | —— | 21.50 | 513.5 | —— |
| Our Model | 94.34 ± 1.64 | 7.54 | 296.94 | 0.35 | 96.0 | 5610.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.; Sun, X.; Zhang, Y. Tiny-Machine-Learning-Based Supply Canal Surface Condition Monitoring. Sensors 2024, 24, 4124. https://doi.org/10.3390/s24134124
Huang C, Sun X, Zhang Y. Tiny-Machine-Learning-Based Supply Canal Surface Condition Monitoring. Sensors. 2024; 24(13):4124. https://doi.org/10.3390/s24134124
Chicago/Turabian StyleHuang, Chengjie, Xinjuan Sun, and Yuxuan Zhang. 2024. "Tiny-Machine-Learning-Based Supply Canal Surface Condition Monitoring" Sensors 24, no. 13: 4124. https://doi.org/10.3390/s24134124
APA StyleHuang, C., Sun, X., & Zhang, Y. (2024). Tiny-Machine-Learning-Based Supply Canal Surface Condition Monitoring. Sensors, 24(13), 4124. https://doi.org/10.3390/s24134124