


A Novel Model for Instance Segmentation and Quantification of Bridge Surface Cracks—The YOLOv8-AFPN-MPD-IoU


 ,
,  and
and
Abstract
:1. Introduction
2. Literature Review
3. Research Methodology
4. Model Development
4.1. Basics of YOLOv8-Segmentation
- The YOLOv8 network offers support for object detection, tracking, and various additional tasks, including instance segmentation, image classification, and key-point detection. Similar to YOLOv5, YOLOv8 presents five distinct scales of models (n, s, m, l, x) with increasing depth and width from left to right [49].
- In alignment with the efficient layer aggregation network (ELAN) design philosophy, YOLOv8 replaces the C3 structure within the YOLOv5 backbone network with a C2f structure. This modification enables YOLOv8 to retain its lightweight characteristics while enhancing the flow of gradients [50]. In comparison to YOLOv5, YOLOv8 demonstrates more pronounced disparities in its head section due to the integration of the widely adopted decoupled head structure.
- YOLOv8 adopts the Task-Aligned-Assigner strategy for positive sample assignment in loss function calculation [51]. Additionally, it introduces the distribution focal loss (DFL). During training, the strategy of disabling mosaic augmentation in the final ten epochs is incorporated, as inspired by YOLOX, to effectively enhance precision in the data augmentation process.
- YOLOv8s-Seg is an extension of the YOLOv8 object detection model specifically tailored for performing segmentation tasks. This network draws upon the principles of the YOLACT network to achieve real-time instance segmentation of objects while maintaining a high segment mean average precision [52]. The structural overview of the YOLACT network is presented in Figure 3.
- The YOLOv8-Seg network, version ultralytics 8.0.201, comprises three primary components: the backbone, the neck, and the head. In the associated GitHub repository, five distinct scale models of the network are available, specifically YOLOv8n-Seg, YOLOv8s-Seg, YOLOv8m-Seg, YOLOv8l-Seg, and YOLOv8x-Seg. In this study, experiments were conducted using YOLOv8-Seg models at various scales to assess the segment mAP50 and model size. Given the minimal presence of cracks in each image, the first four scales of models were utilized to identify the most suitable scale.

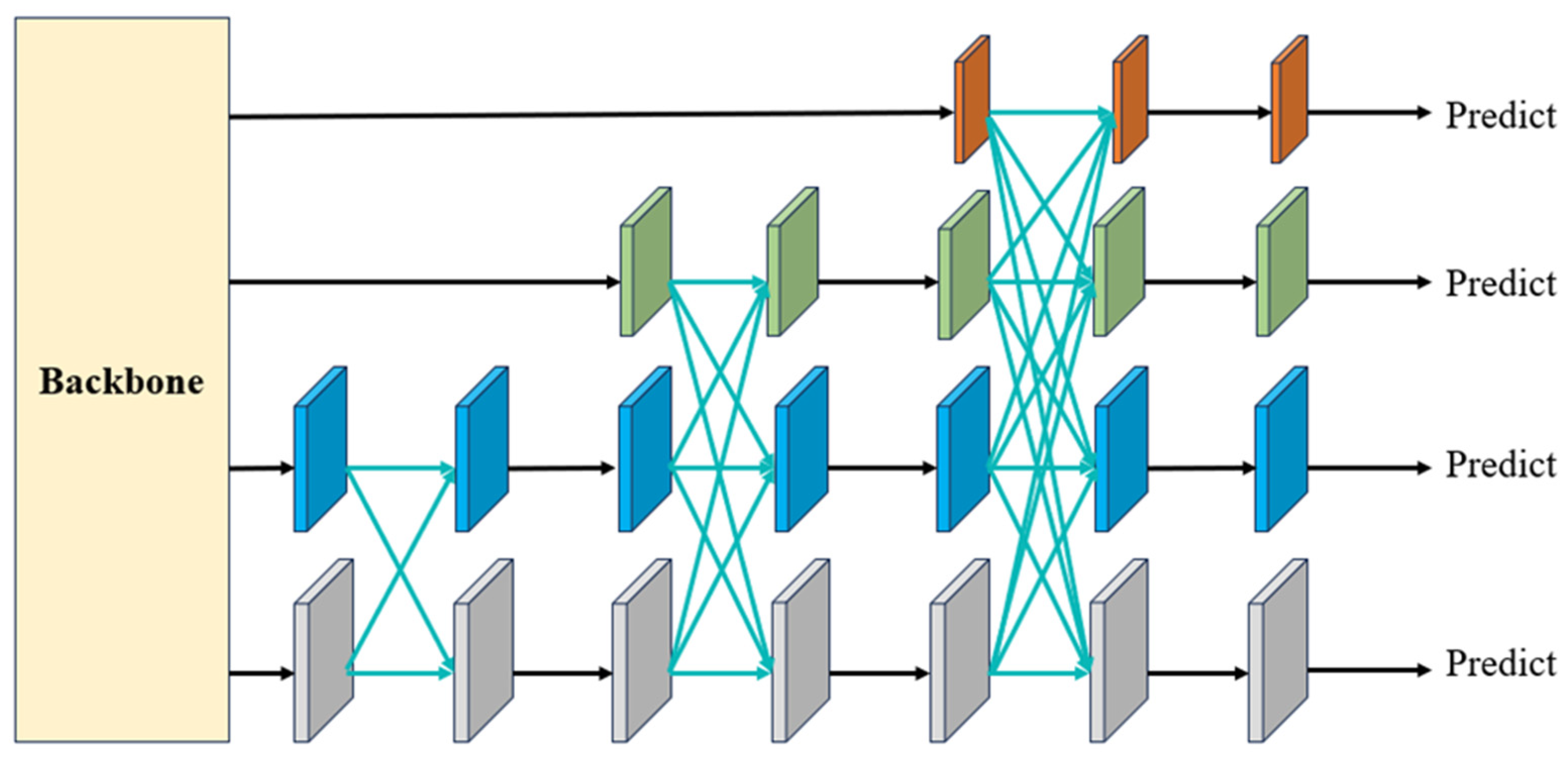
4.2. Asymptotic Feature Pyramid Network
4.2.1. Asymptotic Architecture
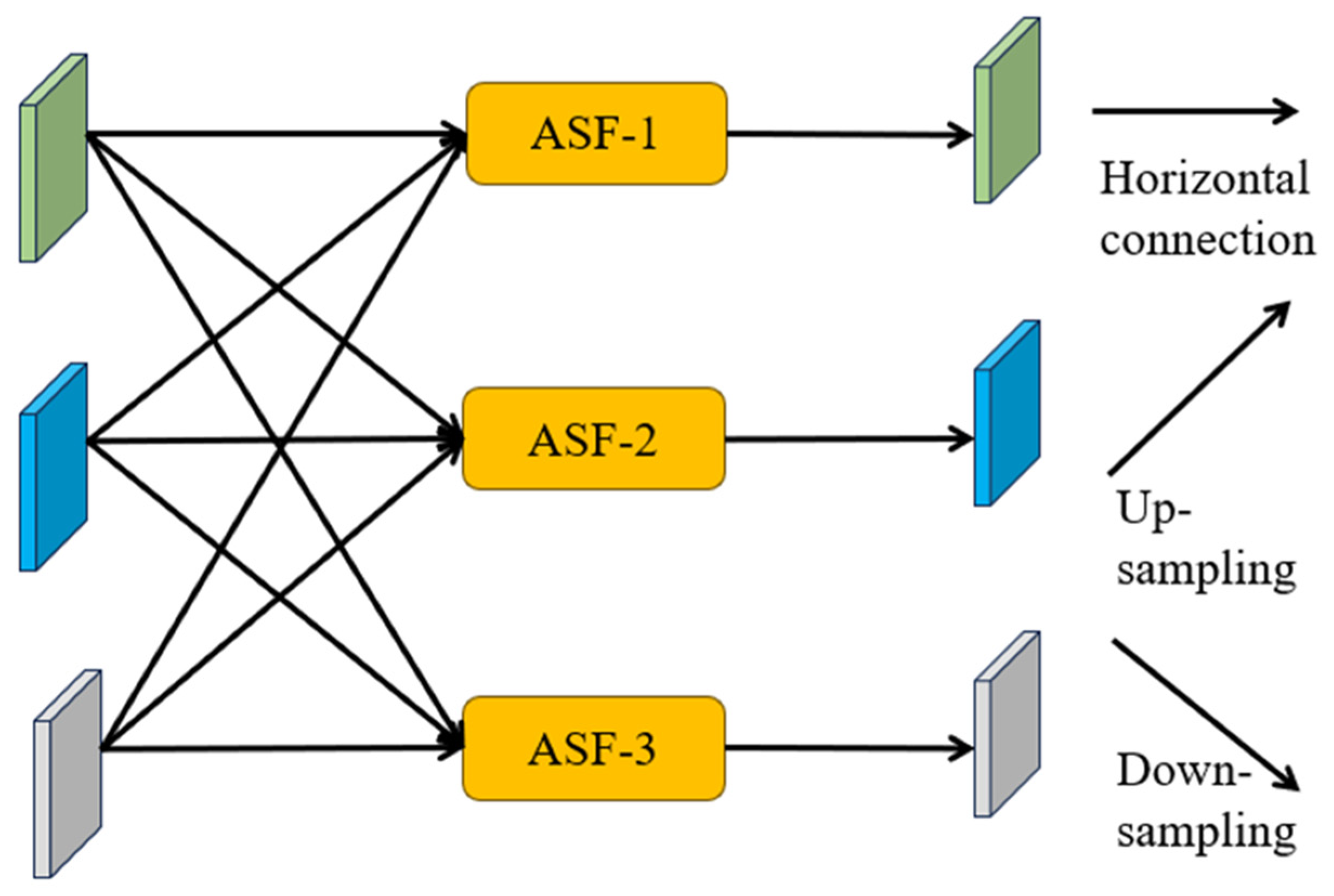
4.2.2. Adaptive Spatial Fusion
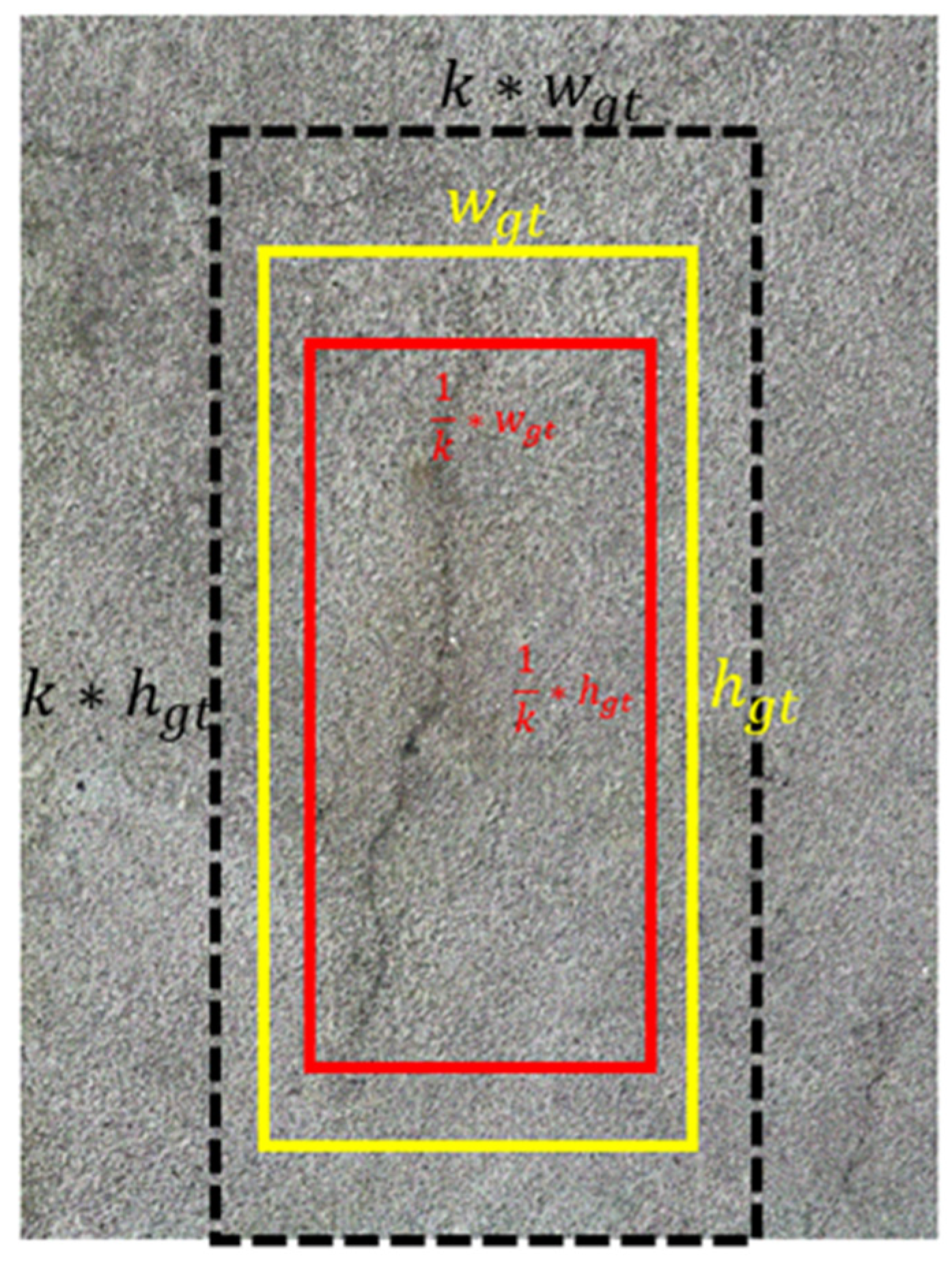
4.3. Minimum Point Distance-IoU Loss Function
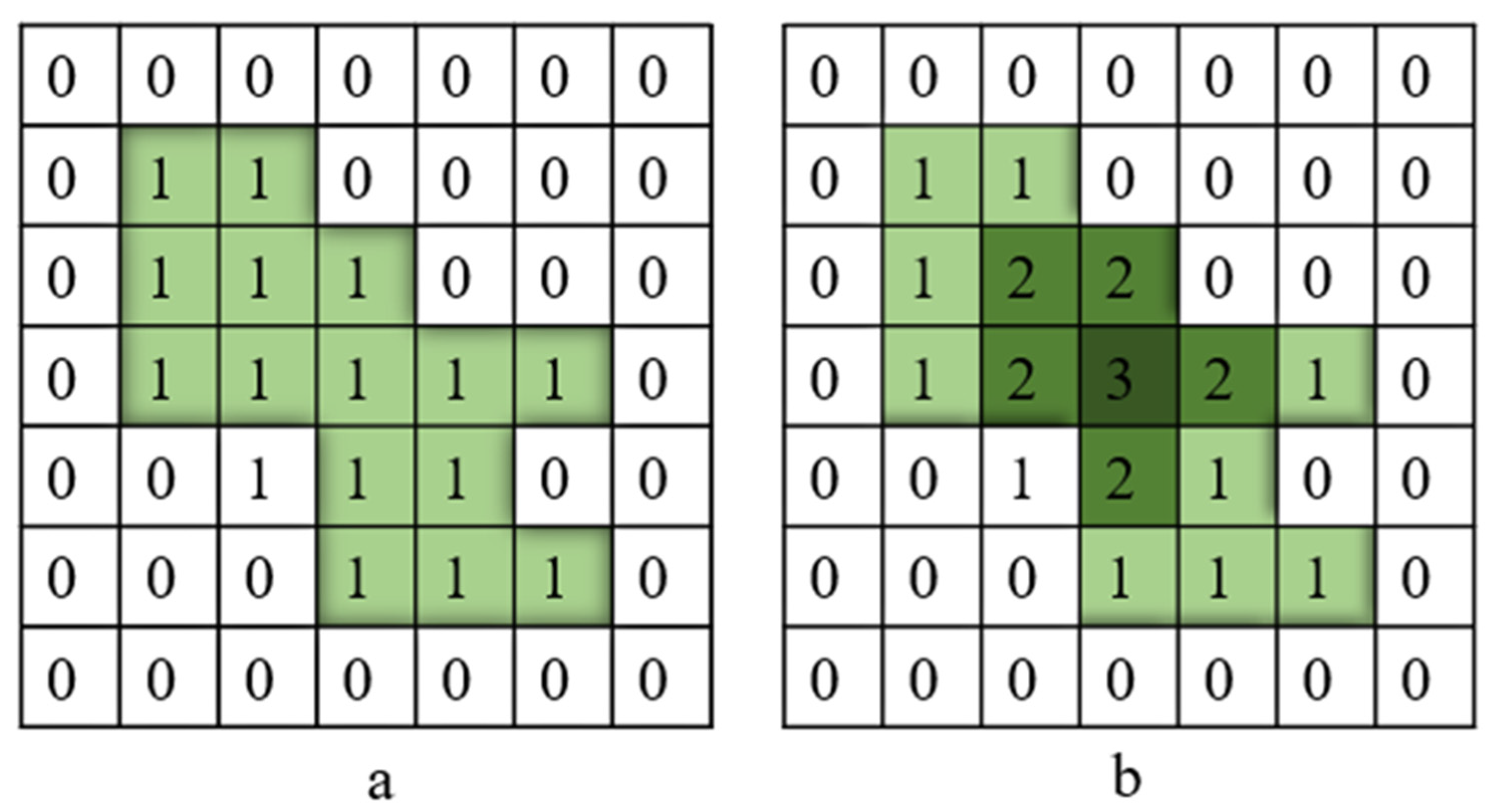
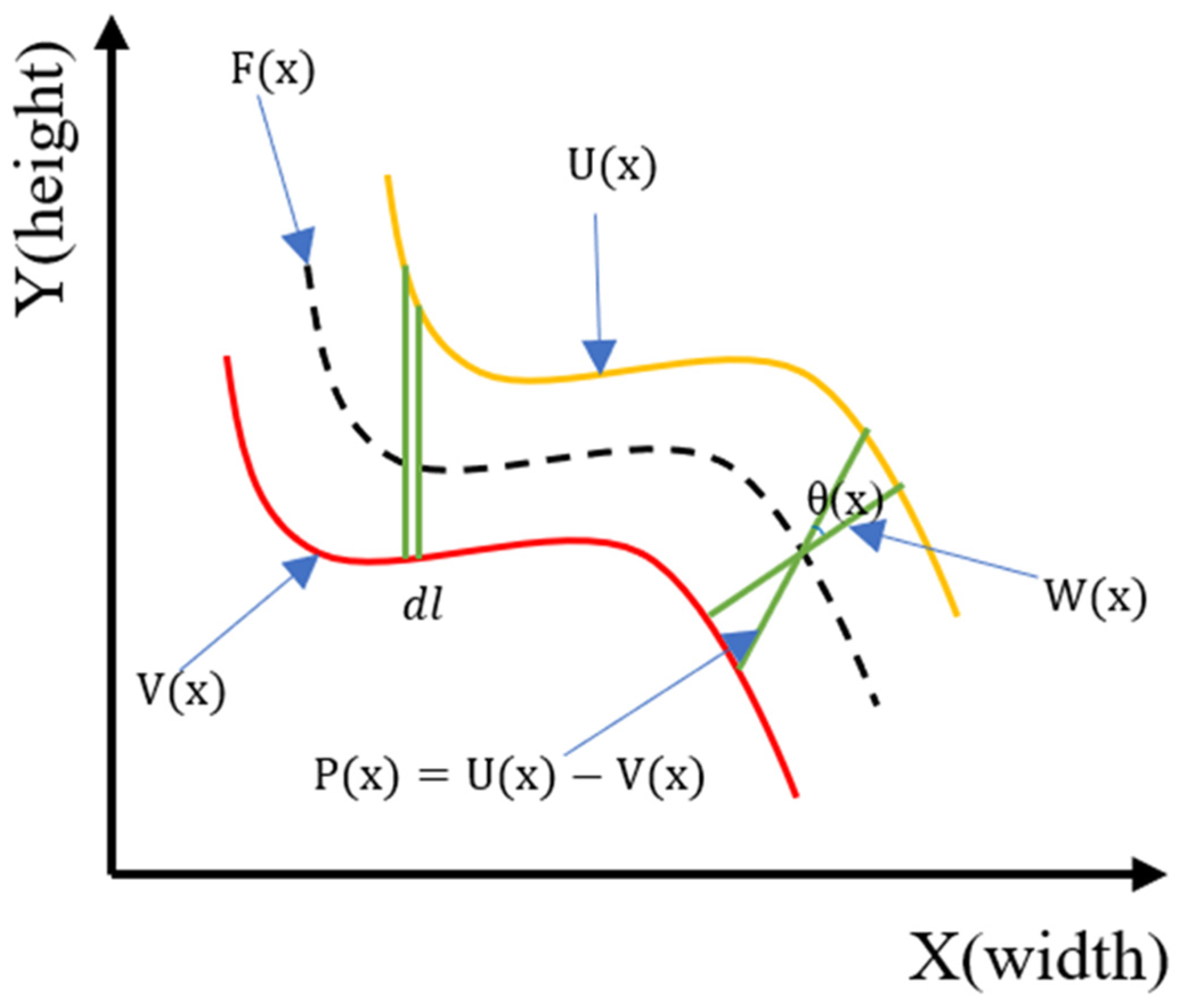
4.4. Crack Skeleton Extraction and Measurement
4.5. Performance Evaluation
4.5.1. Accuracy
4.5.2. Computational Time
4.5.3. Model Complexity
5. Model Implementation
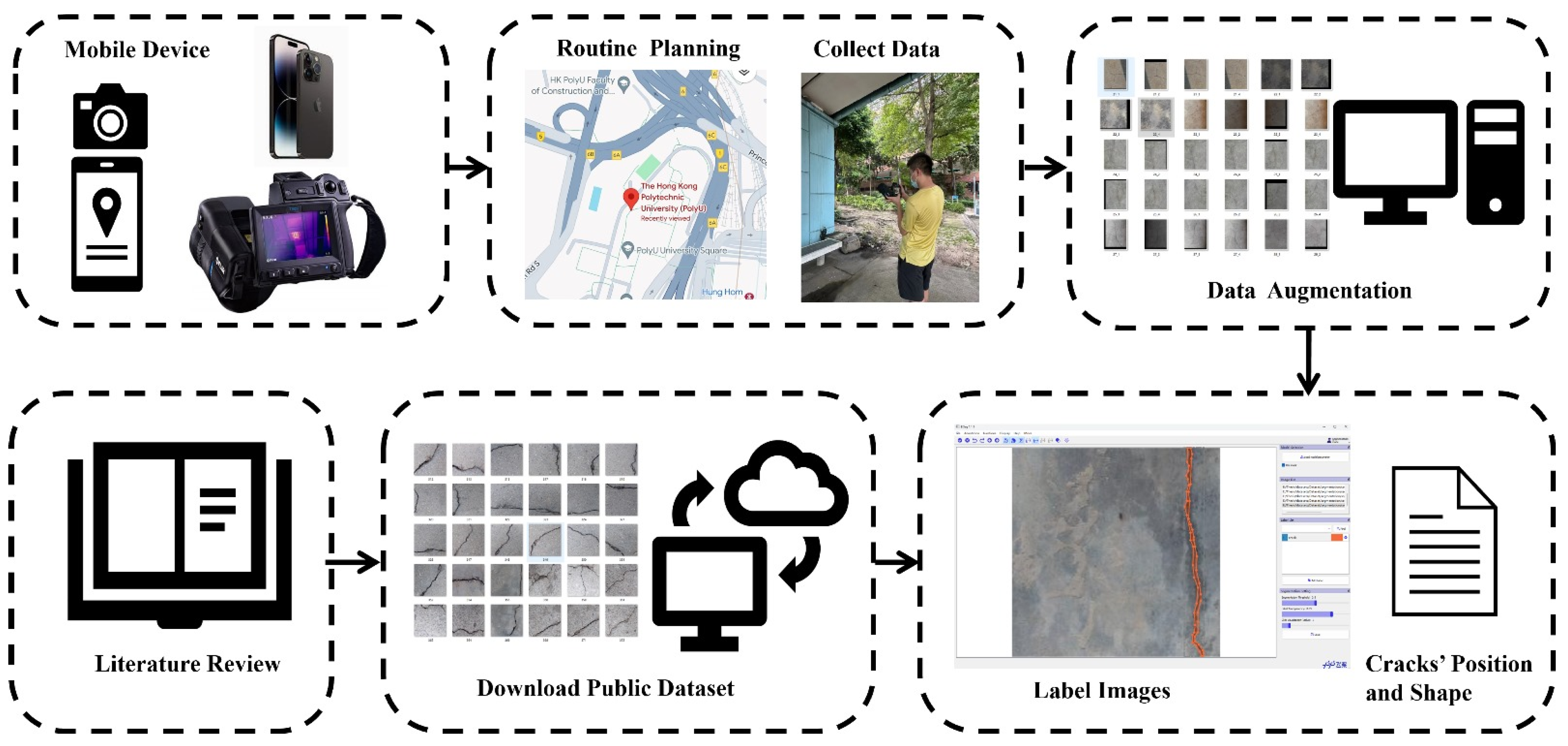
5.1. Data Collection
5.2. Performance Comparison of YOLOv8 Architectures
5.3. Performance Comparison of Different Loss Functions
5.4. Performance Comparison of Instance Segmentation Models
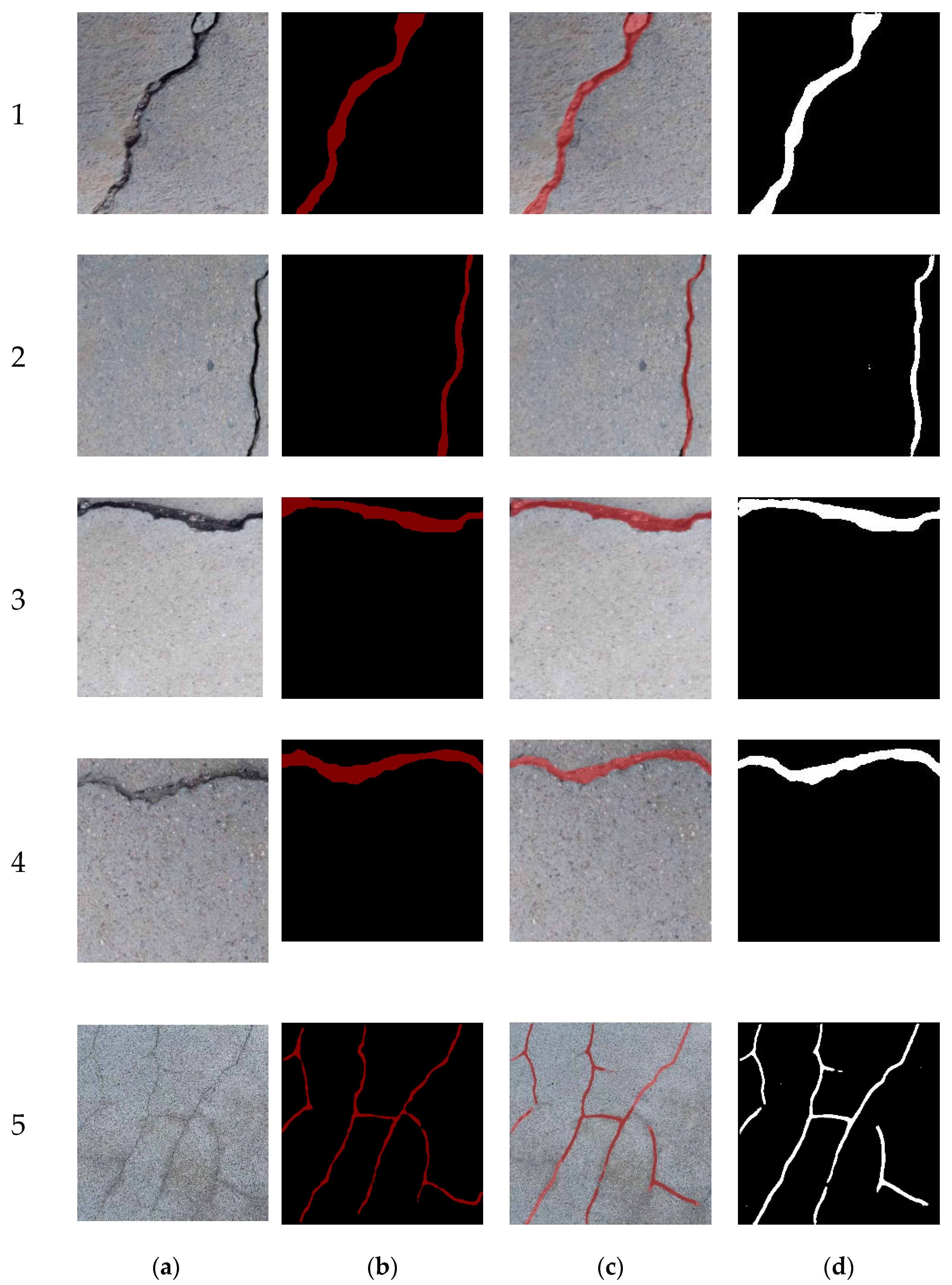
5.5. Crack Measurement Performance
6. Conclusions
- Balanced accuracy and speed: By employing a one-stage instance model, we strike a crucial balance between segmentation accuracy and processing speed. This approach avoids the limitations of two-stage methods that may not comprehensively capture the interplay between detection and segmentation. Multi-stage methods, often associated with extended processing times, are circumvented, enabling real-time segmentation.
- Innovative feature fusion: The incorporation of an asymptotic feature pyramid network in the YOLOv8-seg model replaces conventional top-down or bottom-up feature pyramid networks. This innovative choice addresses the loss and deterioration of feature information between non-adjacent layers, facilitating improved feature fusion and enhancing the overall model performance.
- Specialized loss function: The introduction of the minimum point distance-IoU loss function tackles issues arising when the predicted bounding box possesses the same aspect ratio as the ground-truth bounding box but exhibits distinct width and height values. This tailored loss function ensures a more accurate and reliable model.
- Quantitative measurement method: The combination of the middle aisle transformation method and Euclidean distance method to calculate the length and width of bridge cracks in segmented images provides a quantitative basis for maintenance suggestions. This method enhances the precision of crack assessment.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Leung, A.; Tanko, M.; Burke, M.; Shui, C.S. Bridges, tunnels, and ferries: Connectivity, transport, and the future of Hong Kong’s outlying islands. Isl. Stud. J. 2017, 12, 61–82. [Google Scholar] [CrossRef]
- Weng, X.; Huang, Y.; Wang, W. Segment-based pavement crack quantification. Autom. Constr. 2019, 105, 102819. [Google Scholar] [CrossRef]
- Song, L.; Sun, H.; Liu, J.; Yu, Z.; Cui, C. Automatic segmentation and quantification of global cracks in concrete structures based on deep learning. Measurement 2022, 199, 111550. [Google Scholar] [CrossRef]
- Adhikari, R.S.; Moselhi, O.; Bagchi, A. Image-based retrieval of concrete crack properties for bridge inspection. Autom. Constr. 2014, 39, 180–194. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Automated vision-based detection of cracks on concrete surfaces using a deep learning technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef] [PubMed]
- AASHTO. Manual for Maintenance Inspection of Bridges; AASHTO: Washington, DC, USA, 1983. [Google Scholar]
- Sterritt, G. Review of Bridge Inspection Competence and Training; Project Report; UK Bridges Board: London, UK, 2009. [Google Scholar]
- JTG/T H21-2011; Standards for Technical Condition Evaluation of Highway Bridges. China’s Ministry of Transportation: Beijing, China, 2011.
- Park, S.E.; Eem, S.H.; Jeon, H. Concrete crack detection and quantification using deep learning and structured light. Constr. Build. Mater. 2020, 252, 119096. [Google Scholar] [CrossRef]
- Ji, A.; Xue, X.; Wang, Y.; Luo, X.; Xue, W. An integrated approach to automatic pixel-level crack detection and quantification of asphalt pavement. Autom. Constr. 2020, 114, 103176. [Google Scholar] [CrossRef]
- Yu, L.; He, S.; Liu, X.; Jiang, S.; Xiang, S. Intelligent Crack Detection and Quantification in the Concrete Bridge: A Deep Learning-Assisted Image Processing Approach. Adv. Civ. Eng. 2022, 2022, 1813821. [Google Scholar] [CrossRef]
- Jang, K.; An, Y.K.; Kim, B.; Cho, S. Automated crack evaluation of a high-rise bridge pier using a ring-type climbing robot. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 14–29. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, X.; Zhao, C.; Chen, A.; Zhang, T. A UAV-based machine vision method for bridge crack recognition and width quantification through hybrid feature learning. Constr. Build. Mater. 2021, 299, 123896. [Google Scholar] [CrossRef]
- Deng, J.; Singh, A.; Zhou, Y.; Lu, Y.; Lee VC, S. Review on computer vision-based crack detection and quantification methodologies for civil structures. Constr. Build. Mater. 2022, 356, 129238. [Google Scholar] [CrossRef]
- Hamishebahar, Y.; Guan, H.; So, S.; Jo, J. A Comprehensive Review of Deep Learning-Based Crack Detection Approaches. Appl. Sci. 2022, 12, 1374. [Google Scholar] [CrossRef]
- Deng, L.; Zhang, A.; Guo, J.; Liu, Y. An Integrated Method for Road Crack Segmentation and Surface Feature Quantification under Complex Backgrounds. Remote Sens. 2023, 15, 1530. [Google Scholar] [CrossRef]
- Zhu, J.; Zhong, J.; Ma, T.; Huang, X.; Zhang, W.; Zhou, Y. Pavement distress detection using convolutional neural networks with images captured via UAV. Autom. Constr. 2022, 133, 103991. [Google Scholar] [CrossRef]
- Guo, J.; Liu, P.; Xiao, B.; Deng, L.; Wang, Q. Surface defect detection of civil structures using images: Review from data perspective. Autom. Constr. 2024, 158, 105186. [Google Scholar] [CrossRef]
- Chen, K.; Fu, K.; Yan, M.; Gao, X.; Sun, X.; Wei, X. Semantic Segmentation of Aerial Images with Shuffling Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 173–177. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. PGA-SiamNet: Pyramid feature-based attention-guided siamese network for remote sensing orthoimagery building change detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change Detection Based on Deep Siamese Convolutional Network for Optical Aerial Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Tong, X.; Guo, J.; Ling, Y.; Yin, Z. A New Image-Based Method for Concrete Bridge Bottom Crack Detection. In Proceedings of the 2011 International Conference on Image Analysis and Signal Processing, Wuhan, China, 21–23 October 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, X.; Wang, R.; Li, Z.; Deng, W. Detect concrete cracks based on OTSU algorithm with differential image. J. Eng. 2019, 2019, 9088–9091. [Google Scholar] [CrossRef]
- Hoang, N.D. Detection of Surface Crack in Building Structures Using Image Processing Technique with an Improved Otsu Method for Image Thresholding. Adv. Civ. Eng. 2018, 2018, 3924120. [Google Scholar] [CrossRef]
- Vivekananthan, V.; Vignesh, R.; Vasanthaseelan, S.; Joel, E.; Kumar, K.S. Concrete bridge crack detection by image processing technique by using the improved OTSU method. Mater. Today Proc. 2023, 74, 1002–1007. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J.Y.; Liu, J.X.; Zhang, Y.; Chen, Z.P.; Li, C.G.; He, K.; Yan, R.B. Research on Crack Detection Algorithm of the Concrete Bridge Based on Image Processing. Procedia Comput. Sci. 2018, 154, 610–616. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Xu, X.J.; Zhang, X.N. Crack detection of reinforced concrete bridge using video image. J. Cent. South Univ. 2013, 20, 2605–2613. [Google Scholar] [CrossRef]
- Zhang, L.; Luo, W.; Xu, Y. Bridge Crack Image Segmentation Based on Improved Watershed Algorithm. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 3537–3541. [Google Scholar] [CrossRef]
- Mirbod, M.; Shoar, M. Intelligent Concrete Surface Cracks Detection using Computer Vision, Pattern Recognition, and Artificial Neural Networks. Procedia Comput. Sci. 2022, 217, 52–61. [Google Scholar] [CrossRef]
- Moon, H.-G.; Kim, J.-H. Intelligent Crack Detecting Algorithm on The Concrete Crack Image Using Neural Network. In Proceedings of the 28th International Symposium on Automation and Robotics in Construction, Seoul, Republic of Korea, 29 June–2 July 2011; pp. 1–7. [Google Scholar] [CrossRef]
- Peng, J.; Zhang, S.; Peng, D.; Liang, K. Research on Bridge Crack Detection with Neural Network Based Image Processing Methods. In Proceedings of the 12th International Conference on Reliability, Maintainability, and Safety, ICRMS, Shanghai, China, 17–19 October 2018; pp. 419–428. [Google Scholar] [CrossRef]
- Liang, S.; Jianchun, X.; Xun, Z. An extraction and classification algorithm for concrete cracks based on machine vision. IEEE Access 2018, 6, 45051–45061. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.; Gucunski, N.; Basily, B. Computer Vision Based Crack Detection and Analysis. In Proceedings Volume 8345, Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems; SPIE: Bellingham, WC, USA, 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Yao, C.; Tao, M.; Xiaojie, W.; Feng, L.I. A Bridge Crack Image Detection and Classification Method Based on Climbing Robot. In Proceedings of the 35th Chinese Control Conference, Chengdu, China, 27–29 July 2016; pp. 4037–4042. [Google Scholar] [CrossRef]
- Li, Z.; Huang, M.; Ji, P.; Zhu, H.; Zhang, Q. One-step deep learning-based method for pixel-level detection of fine cracks in steel girder images. Smart Struct. Syst. 2022, 29, 153–166. [Google Scholar] [CrossRef]
- Zhang, J.; Qian, S.; Tan, C. Automated bridge surface crack detection and segmentation using computer vision-based deep learning model. Eng. Appl. Artif. Intell. 2022, 115, 105225. [Google Scholar] [CrossRef]
- Rosso, M.M.; Marasco, G.; Aiello, S.; Aloisio, A.; Chiaia, B.; Marano, G.C. Convolutional networks and transformers for intelligent road tunnel investigations. Comput. Struct. 2023, 275, 106918. [Google Scholar] [CrossRef]
- Park, M.J.; Kim, J.; Jeong, S.; Jang, A.; Bae, J.; Ju, Y.K. Machine learning-based concrete crack depth prediction using thermal images taken under daylight conditions. Remote Sens. 2022, 14, 2151. [Google Scholar] [CrossRef]
- Zhang, C.; Chang, C.-c.; Jamshidi, M. Concrete bridge surface damage detection using a single-stage detector. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 389–409. [Google Scholar] [CrossRef]
- Deng, J.; Lu, Y.; Lee VC, S. Imaging-based crack detection on concrete surfaces using You Only Look Once network. Struct. Health Monit. 2021, 20, 484–499. [Google Scholar] [CrossRef]
- Teng, S.; Liu, Z.; Chen, G.; Cheng, L. Concrete crack detection based on well-known feature extractor model and the YOLO_v2 network. Appl. Sci. 2021, 11, 813. [Google Scholar] [CrossRef]
- Qiu, Q.; Lau, D. Real-time detection of cracks in tiled sidewalks using YOLO-based method applied to unmanned aerial vehicle (UAV) images. Autom. Constr. 2023, 147, 104745. [Google Scholar] [CrossRef]
- Xiang, X.; Hu, H.; Ding, Y.; Zheng, Y.; Wu, S. GC-YOLOv5s: A Lightweight Detector for UAV Road Crack Detection. Appl. Sci. 2023, 13, 11030. [Google Scholar] [CrossRef]
- Choi, W.; Cha, Y.J. SDDNet: Real-Time Crack Segmentation. IEEE Trans. Ind. Electron. 2020, 67, 8016–8025. [Google Scholar] [CrossRef]
- Zhang, X.; Rajan, D.; Story, B. Concrete crack detection using context-aware deep semantic segmentation network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 951–971. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic bridge crack detection using a convolutional neural network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef]
- Yue, X.; Qi, K.; Na, X.; Zhang, Y.; Liu, Y.; Liu, C. Improved YOLOv8-Seg Network for Instance Segmentation of Healthy and Diseased Tomato Plants in the Growth Stage. Agriculture 2023, 13, 1643. [Google Scholar] [CrossRef]
- Wu, Y.; Han, Q.; Jin, Q.; Li, J.; Zhang, Y. LCA-YOLOv8-Seg: An Improved Lightweight YOLOv8-Seg for Real-Time Pixel-Level Crack Detection of Dams and Bridges. Appl. Sci. 2023, 13, 10583. [Google Scholar] [CrossRef]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. TOOD: Task-aligned One-stage Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar] [CrossRef]
- Bolya, D.; Fanyi, C.Z.; Yong, X.; Lee, J. YOLACT Real-time Instance Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. arXiv 2023, arXiv:2306.15988. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Siliang, M.; Yong, X. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Yu, Z.; Shen, Y.; Sun, Z.; Chen, J.; Gang, W. Cracklab: A high-precision and efficient concrete crack segmentation and quantification network. Dev. Built Environ. 2022, 12, 100088. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, S.; Li, X.; Li, G.; Li, X. Lightweight bridge crack detection method based on segnet and bottleneck depth-separable convolution with residuals. IEEE Access 2021, 9, 161649–161668. [Google Scholar] [CrossRef]
- Bae, H.; An, Y.-K. Computer vision-based statistical crack quantification for concrete structures. Measurement 2023, 211, 112632. [Google Scholar] [CrossRef]
- Nabizadeh, E.; Parghi, A. Automated corrosion detection using deep learning and computer vision. Asian J. Civ. Eng. 2023, 24, 2911–2923. [Google Scholar] [CrossRef]
- Zhou, Y.C.; Hu, Z.Z.; Yan, K.X.; Lin, J.R. Deep learning-based instance segmentation for indoor fire load recognition. IEEE Access 2021, 9, 148771–148782. [Google Scholar] [CrossRef]
- Bai, R.; Wang, M.; Zhang, Z.; Lu, J.; Shen, F. Automated construction site monitoring based on improved YOLOv8-seg instance segmentation algorithm. IEEE Access 2023, 11, 139082–139096. [Google Scholar] [CrossRef]
- Jung, S.; Heo, H.; Park, S.; Jung, S.U.; Lee, K. Benchmarking deep learning models for instance segmentation. Appl. Sci. 2022, 12, 8856. [Google Scholar] [CrossRef]
- Pena-Caballero, C.; Kim, D.; Gonzalez, A.; Castellanos, O.; Cantu, A.; Ho, J. Real-time road hazard information system. Infrastructures 2020, 5, 75. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Dataset | Training | Validation | Testing | Total Number |
|---|---|---|---|---|---|
| Segmentation | BSD | 952 | 136 | 272 | 1360 |
| ours | 168 | 24 | 48 | 240 | |
| New dataset | 1120 | 160 | 320 | 1600 |
| Hardware | Information | Software | Information |
|---|---|---|---|
| GPUs | GeForce RTX 3090 | Operating System | Windows 10 (Version 23H2) |
| CPU | Intel(R) Core (TM) i9-10900 CPU @ 2.80 GHz | Deep Learning Framework | PyTorch |
| RAM | 22.6 GB | CUDA Version | 11.7 |
| Python Version | 3.8 |
| Model | Epoch | Size | Running Time | P | R | mAP50 | mAP75 | Map50-95 | F1 | Model Fitness |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 300 | 6.43 M | 4.028 h | 88.80% | 71.10% | 72.60% | 71.60% | 32.90% | 78.97% | 0.3687 |
| YOLOv8s | 300 | 22.7 M | 3.385 h | 92.60% | 68.60% | 74.00% | 73.40% | 33.60% | 78.81% | 0.3764 |
| YOLOv8m | 300 | 67.8 M | 3.783 h | 90.20% | 68.10% | 71.30% | 70.40% | 32.40% | 77.61% | 0.3629 |
| YOLOv8l | 300 | 151 M | 6.164 h | 88.90% | 70.20% | 73.70% | 73.20% | 33.50% | 78.45% | 0.3752 |
| Model | Epoch | Model Size | Running Time | P | R | mAP50 | mAP75 | F1 |
|---|---|---|---|---|---|---|---|---|
| YOLOv8s + AFPN + CIoU | 300 | 23.7 MB | 3.596 h | 0.935 | 0.694 | 0.74 | 0.735 | 79.69% |
| YOLOv8s + AFPN + MPDIoU | 300 | 22.7 MB | 3.661 h | 0.907 | 0.704 | 0.753 | 0.748 | 79.27% |
| YOLOv8s + AFPN + WIoU | 300 | 23.7 MB | 3.575 h | 0.936 | 0.677 | 0.75 | 0.74 | 78.57% |
| Model | Epoch | Model Size | Inference Time | Running Time | MASK | ||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | mAP50 | mAP75 | |||||
| YOLOv5s-seg | 282 | 18.79 M | 11.5 ms | 2.397 h | 90.50% | 68.80% | 78.17% | 72.30% | 70.60% |
| YOLOv8s-seg | 300 | 22.7 M | 8.9 ms | 3.385 h | 92.60% | 68.60% | 78.81% | 74.00% | 73.40% |
| YOLOv8m-seg | 300 | 67.8 M | 12.5 ms | 3.783 h | 90.20% | 68.10% | 77.61% | 71.30% | 70.40% |
| YOLOv8l-seg | 300 | 151 M | 12.5 ms | 6.164 h | 88.90% | 70.20% | 78.45% | 73.70% | 73.20% |
| Mask-RCNN | 300 | 335 M | 36 ms | 11.5 h | 49.82% | 26.10% | 34.25% | 49.80% | 7.60% |
| YOLOv8s + AFPN + MPDIoU (ours) | 300 | 22.7 MB | 12.2 ms | 3.661 h | 90.70% | 70.40% | 79.27% | 75.30% | 74.80% |
| Ground Truth | Segmentation | Error | |||||
|---|---|---|---|---|---|---|---|
| Image Number | Type | Max Length | Max Width | Max Length | Max Width | Max Length | Max Width |
| 1 | Diagonal | 254.00 | 23.75 | 259.00 | 24.83 | −1.97% | −4.56% |
| 2 | Diagonal | 225.00 | 7.64 | 229.00 | 7.64 | −1.78% | 0.00% |
| 3 | Transverse | 230.00 | 21.08 | 225.00 | 21.01 | 2.17% | 0.33% |
| 4 | Transverse | 227.00 | 19.93 | 228.00 | 18.02 | −0.44% | 5.31% |
| 5 | Reticular | 4568.00 | 40.11 | 4513.00 | 39.03 | 1.20% | 2.70% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, C.; Zayed, T.; Jiang, X.; Alfalah, G.; Abelkader, E.M. A Novel Model for Instance Segmentation and Quantification of Bridge Surface Cracks—The YOLOv8-AFPN-MPD-IoU. Sensors 2024, 24, 4288. https://doi.org/10.3390/s24134288
Xiong C, Zayed T, Jiang X, Alfalah G, Abelkader EM. A Novel Model for Instance Segmentation and Quantification of Bridge Surface Cracks—The YOLOv8-AFPN-MPD-IoU. Sensors. 2024; 24(13):4288. https://doi.org/10.3390/s24134288
Chicago/Turabian StyleXiong, Chenqin, Tarek Zayed, Xingyu Jiang, Ghasan Alfalah, and Eslam Mohammed Abelkader. 2024. "A Novel Model for Instance Segmentation and Quantification of Bridge Surface Cracks—The YOLOv8-AFPN-MPD-IoU" Sensors 24, no. 13: 4288. https://doi.org/10.3390/s24134288
APA StyleXiong, C., Zayed, T., Jiang, X., Alfalah, G., & Abelkader, E. M. (2024). A Novel Model for Instance Segmentation and Quantification of Bridge Surface Cracks—The YOLOv8-AFPN-MPD-IoU. Sensors, 24(13), 4288. https://doi.org/10.3390/s24134288