
Redefining Accuracy: Underwater Depth Estimation for Irregular Illumination Scenes


Abstract
:1. Introduction
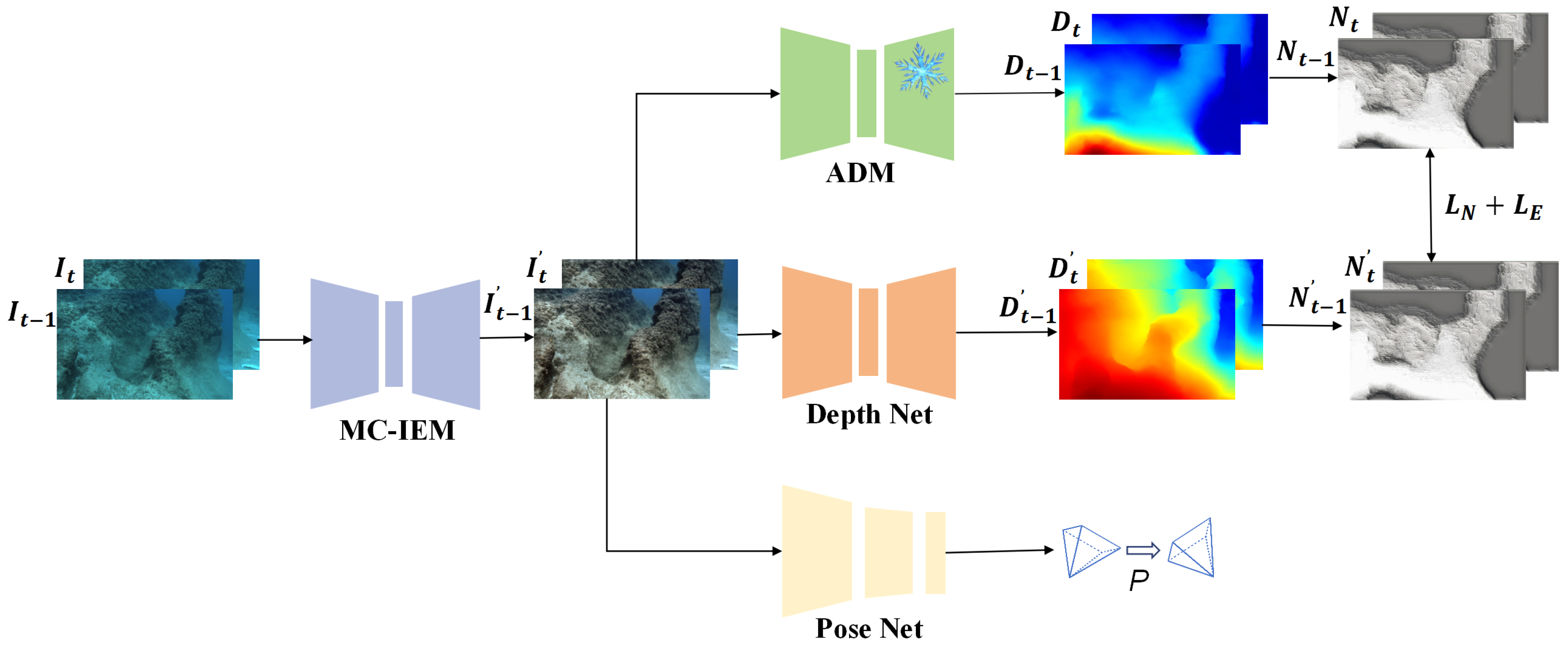
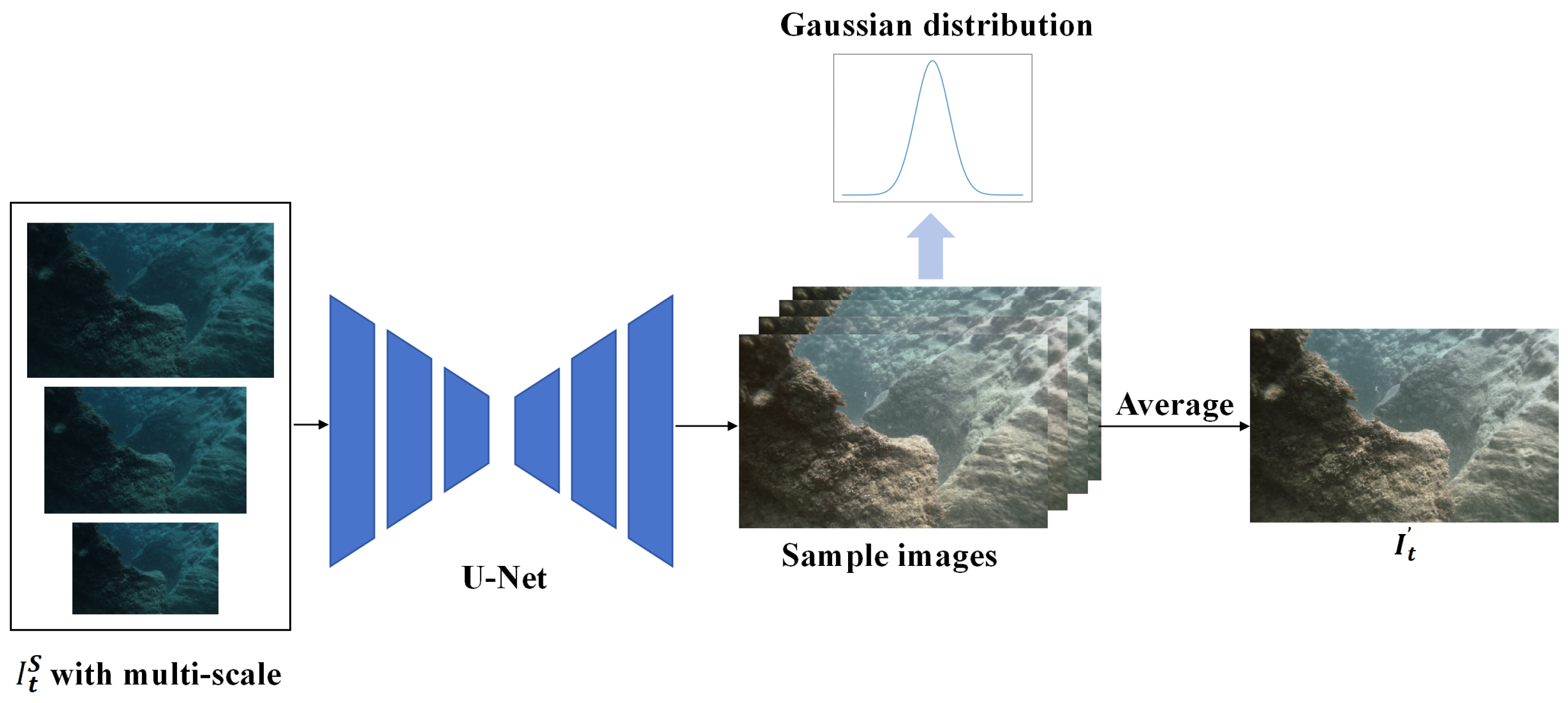
- We introduce the Monte Carlo image enhancement module (MC-IEM) to remove the interference caused by underwater low-light conditions and enhance depth estimation accuracy.
- We employ an auxiliary depth module (ADM) to provide extra geometric constraints to address the issue of distorted surface textures caused by overexposure between frames in underwater environments.
- We conduct extensive comparative experiments on two public underwater datasets. The experimental results demonstrate that our method surpasses other methods in the qualitative and quantitative sections.
2. Related Work
2.1. Physics-Based Methods
2.2. Deep-Learning-Based Methods
3. Methods
3.1. Overall Framework
3.2. Loss Functions
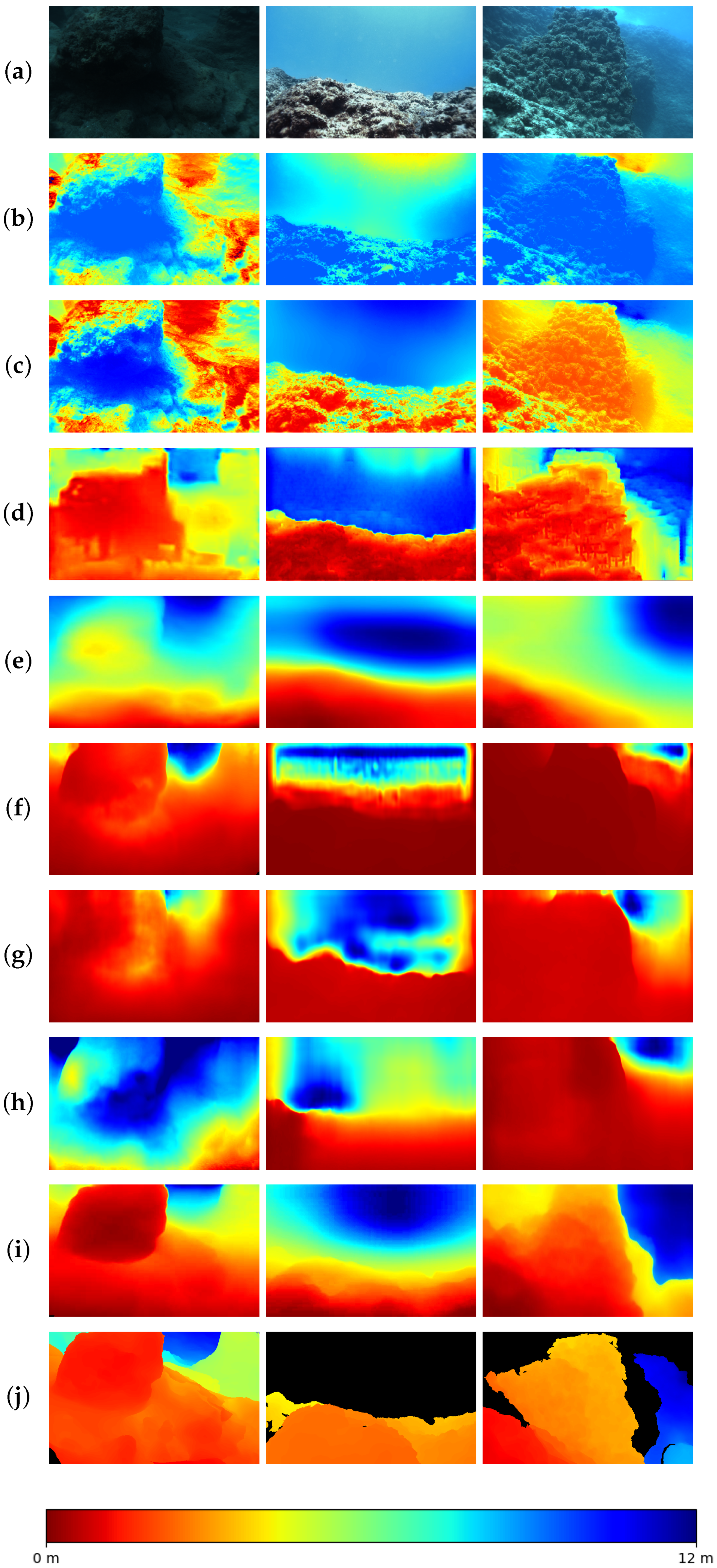
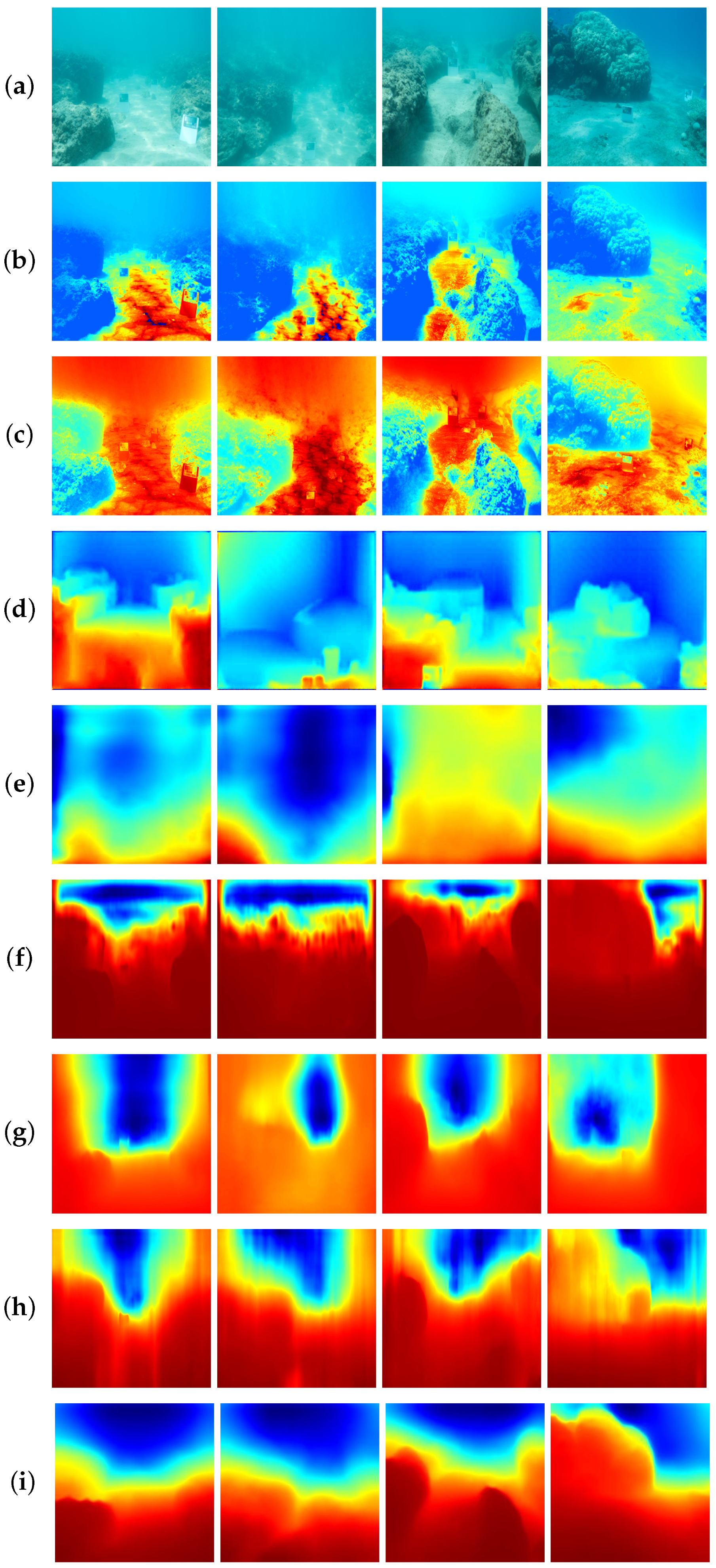
4. Results
4.1. Datasets and Experimental Details
4.2. Evaluation
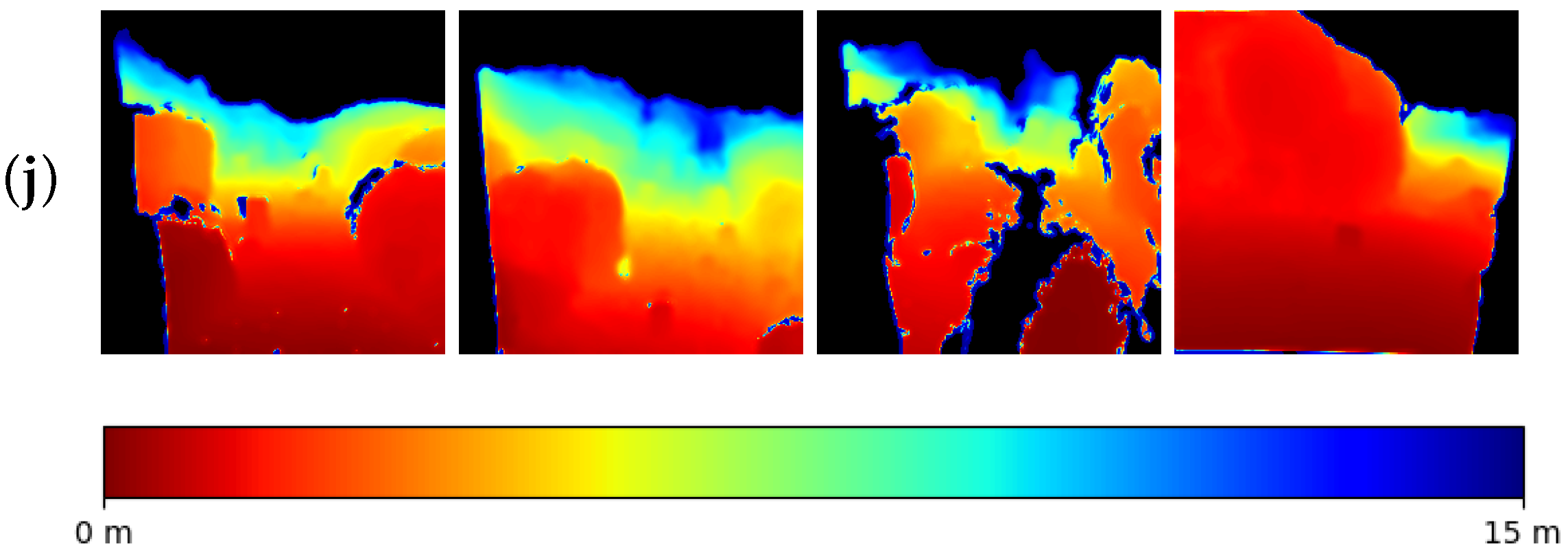
4.2.1. Qualitative Evaluation
4.2.2. Quantitative Evaluation
4.2.3. Ablation Study
5. Discussion
The Relationship between Image Enhancement and Depth Estimation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Q.; Xin, Z.; Yu, Z.; Zheng, B. Unpaired underwater image synthesis with a disentangled representation for underwater depth map prediction. Sensors 2021, 21, 3268. [Google Scholar] [CrossRef] [PubMed]
- Gutnik, Y.; Avni, A.; Treibitz, T.; Groper, M. On the adaptation of an auv into a dedicated platform for close range imaging survey missions. J. Mar. Sci. Eng. 2022, 10, 974. [Google Scholar] [CrossRef]
- Ludvigsen, M.; Sortland, B.; Johnsen, G.; Singh, H. Applications of geo-referenced underwater photo mosaics in marine biology and archaeology. Oceanography 2007, 20, 140–149. [Google Scholar] [CrossRef]
- Kim, A.; Eustice, R.M. Real-time visual SLAM for autonomous underwater hull inspection using visual saliency. IEEE Trans. Robot. 2013, 29, 719–733. [Google Scholar] [CrossRef]
- Park, J.; Zhou, Q.Y.; Koltun, V. Colored Point Cloud Registration Revisited. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Shao, L.; Han, J.; Xu, D.; Shotton, J. Computer vision for RGB-D sensors: Kinect and its applications [special issue intro.]. IEEE Trans. Cybern. 2013, 43, 1314–1317. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Ibanez-Guzman, J. Lidar for autonomous driving: The principles, challenges, and trends for automotive lidar and perception systems. IEEE Signal Process. Mag. 2020, 37, 50–61. [Google Scholar] [CrossRef]
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Wang, N.; Xin, G.; Hu, W. Underwater self-supervised depth estimation. Neurocomputing 2022, 514, 362–373. [Google Scholar] [CrossRef]
- Marburg, A.; Stewart, A. Extrinsic calibration of an RGB camera to a 3D imaging sonar. In Proceedings of the OCEANS 2015-MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–6. [Google Scholar]
- Neupane, D.; Seok, J. A review on deep learning-based approaches for automatic sonar target recognition. Electronics 2020, 9, 1972. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Muniraj, M.; Dhandapani, V. Underwater image enhancement by combining color constancy and dehazing based on depth estimation. Neurocomputing 2021, 460, 211–230. [Google Scholar] [CrossRef]
- Gupta, H.; Mitra, K. Unsupervised single image underwater depth estimation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 624–628. [Google Scholar]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 3828–3838. [Google Scholar]
- Peng, R.; Wang, R.; Lai, Y.; Tang, L.; Cai, Y. Excavating the potential capacity of self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15560–15569. [Google Scholar]
- Zhou, H.; Greenwood, D.; Taylor, S. Self-Supervised Monocular Depth Estimation with Internal Feature Fusion. In Proceedings of the British Machine Vision Conference (BMVC), Glasgow, UK, 25–28 November 2021. [Google Scholar]
- Zhao, C.; Zhang, Y.; Poggi, M.; Tosi, F.; Guo, X.; Zhu, Z.; Huang, G.; Tang, Y.; Mattoccia, S. Monovit: Self-supervised monocular depth estimation with a vision transformer. In Proceedings of the 2022 International Conference on 3D Vision (3DV), Prague, Czech Republic, 12–15 September 2022; pp. 668–678. [Google Scholar]
- Zhang, N.; Nex, F.; Vosselman, G.; Kerle, N. Lite-mono: A lightweight cnn and transformer architecture for self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18537–18546. [Google Scholar]
- Saunders, K.; Vogiatzis, G.; Manso, L.J. Self-supervised Monocular Depth Estimation: Let’s Talk About The Weather. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 8907–8917. [Google Scholar]
- Fu, Z.; Wang, W.; Huang, Y.; Ding, X.; Ma, K.K. Uncertainty inspired underwater image enhancement. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 465–482. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; You, S.; Li, Y.; Fu, Y. Atlantis: Enabling Underwater Depth Estimation with Stable Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 17–21 June 2024; pp. 11852–11861. [Google Scholar]
- Peng, Y.T.; Zhao, X.; Cosman, P.C. Single underwater image enhancement using depth estimation based on blurriness. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4952–4956. [Google Scholar]
- Drews, P.L.; Nascimento, E.R.; Botelho, S.S.; Campos, M.F.M. Underwater depth estimation and image restoration based on single images. IEEE Comput. Graph. Appl. 2016, 36, 24–35. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.T.; Cosman, P.C. Underwater image restoration based on image blurriness and light absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef] [PubMed]
- Song, W.; Wang, Y.; Huang, D.; Tjondronegoro, D. A rapid scene depth estimation model based on underwater light attenuation prior for underwater image restoration. In Proceedings of the Advances in Multimedia Information Processing–PCM 2018: 19th Pacific-Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 678–688. [Google Scholar]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2822–2837. [Google Scholar] [CrossRef] [PubMed]
- Bekerman, Y.; Avidan, S.; Treibitz, T. Unveiling optical properties in underwater images. In Proceedings of the 2020 IEEE International Conference on Computational Photography (ICCP), Saint Louis, MO, USA, 24–26 April 2020; pp. 1–12. [Google Scholar]
- Ming, Y.; Meng, X.; Fan, C.; Yu, H. Deep learning for monocular depth estimation: A review. Neurocomputing 2021, 438, 14–33. [Google Scholar] [CrossRef]
- Ye, X.; Li, Z.; Sun, B.; Wang, Z.; Xu, R.; Li, H.; Fan, X. Deep joint depth estimation and color correction from monocular underwater images based on unsupervised adaptation networks. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3995–4008. [Google Scholar] [CrossRef]
- Zhao, Q.; Zheng, Z.; Zeng, H.; Yu, Z.; Zheng, H.; Zheng, B. The synthesis of unpaired underwater images for monocular underwater depth prediction. Front. Mar. Sci. 2021, 8, 690962. [Google Scholar] [CrossRef]
- Watson, J.; Mac Aodha, O.; Prisacariu, V.; Brostow, G.; Firman, M. The temporal opportunist: Self-supervised multi-frame monocular depth. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1164–1174. [Google Scholar]
- Bian, J.W.; Zhan, H.; Wang, N.; Li, Z.; Zhang, L.; Shen, C.; Cheng, M.M.; Reid, I. Unsupervised scale-consistent depth learning from video. Int. J. Comput. Vis. 2021, 129, 2548–2564. [Google Scholar] [CrossRef]
- Bian, J.W.; Zhan, H.; Wang, N.; Chin, T.J.; Shen, C.; Reid, I. Auto-rectify network for unsupervised indoor depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9802–9813. [Google Scholar] [CrossRef] [PubMed]
- Pillai, S.; Ambruş, R.; Gaidon, A. Superdepth: Self-supervised, super-resolved monocular depth estimation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, Canada, 20–24 May 2019; pp. 9250–9256. [Google Scholar]
- Poggi, M.; Aleotti, F.; Tosi, F.; Mattoccia, S. On the uncertainty of self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3227–3237. [Google Scholar]
- Mallya, A.; Lazebnik, S. Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7765–7773. [Google Scholar]
- Klingner, M.; Termöhlen, J.A.; Mikolajczyk, J.; Fingscheidt, T. Self-supervised monocular depth estimation: Solving the dynamic object problem by semantic guidance. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 582–600. [Google Scholar]
- Sun, L.; Bian, J.W.; Zhan, H.; Yin, W.; Reid, I.; Shen, C. Sc-depthv3: Robust self-supervised monocular depth estimation for dynamic scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 497–508. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zhang, R.; Jiang, J.; Wang, Y.; Li, G.; Li, T.H. Self-supervised monocular depth estimation: Solving the edge-fattening problem. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 5776–5786. [Google Scholar]
- Bae, J.; Moon, S.; Im, S. Deep digging into the generalization of self-supervised monocular depth estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 187–196. [Google Scholar]
- Randall, Y. FLSea: Underwater Visual-Inertial and Stereo-Vision Forward-Looking Datasets. Ph.D. Thesis, University of Haifa, Haifa, Israel, 2023. [Google Scholar]
- Vijayanarasimhan, S.; Ricco, S.; Schmid, C.; Sukthankar, R.; Fragkiadaki, K. Sfm-net: Learning of structure and motion from video. arXiv 2017, arXiv:1704.07804. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12179–12188. [Google Scholar]
- Yin, W.; Zhang, J.; Wang, O.; Niklaus, S.; Mai, L.; Chen, S.; Shen, C. Learning to recover 3d scene shape from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 204–213. [Google Scholar]
- Wang, Z.; Cheng, P.; Tian, P.; Wang, Y.; Chen, M.; Duan, S.; Wang, Z.; Li, X.; Sun, X. RS-DFM: A Remote Sensing Distributed Foundation Model for Diverse Downstream Tasks. arXiv 2024, arXiv:2406.07032. [Google Scholar]
- Ma, J.; Fan, X.; Yang, S.X.; Zhang, X.; Zhu, X. Contrast limited adaptive histogram equalization-based fusion in YIQ and HSI color spaces for underwater image enhancement. Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1854018. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Guan, Y.; Liu, X.; Yu, Z.; Wang, Y.; Zheng, X.; Zhang, S.; Zheng, B. Fast underwater image enhancement based on a generative adversarial framework. Front. Mar. Sci. 2023, 9, 964600. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Error ↓ | Accuracy ↑ | |||||
|---|---|---|---|---|---|---|---|
| DCP [12] | 1.527 | 0.402 | 1.243 | 0.207 | 0.356 | 0.489 | |
| UDCP [15] | 0.577 | 0.217 | 0.646 | 0.337 | 0.575 | 0.731 | |
| UW-Net [14] | 0.502 | 0.207 | 0.648 | 0.366 | 0.615 | 0.760 | |
| SC-Depth V3 [38] | 0.500 | 0.233 | 0.730 | 0.306 | 0.550 | 0.728 | |
| MonoViT [21] | 0.482 | 0.336 | 1.310 | 0.370 | 0.606 | 0.769 | |
| Lite-Mono [22] | 0.379 | 0.136 | 0.408 | 0.502 | 0.774 | 0.894 | |
| Robust-Depth [23] | 0.463 | 0.204 | 0.644 | 0.340 | 0.592 | 0.769 | |
| Ours | 0.239 | 0.132 | 0.496 | 0.588 | 0.819 | 0.891 | |
| Method | Error ↓ | Accuracy ↑ | |||||
|---|---|---|---|---|---|---|---|
| DCP [12] | 3.641 | 0.410 | 1.240 | 0.177 | 0.343 | 0.479 | |
| UDCP [15] | 1.827 | 0.371 | 1.090 | 0.183 | 0.346 | 0.487 | |
| UW-Net [14] | 1.262 | 0.315 | 0.954 | 0.224 | 0.417 | 0.573 | |
| SC-Depth V3 [39] | 1.044 | 0.297 | 0.901 | 0.234 | 0.440 | 0.596 | |
| MonoViT [21] | 1.044 | 0.315 | 1.085 | 0.263 | 0.481 | 0.625 | |
| Lite-Mono [22] | 1.426 | 0.328 | 0.981 | 0.211 | 0.404 | 0.550 | |
| Robust-Depth [23] | 0.762 | 0.218 | 0.729 | 0.367 | 0.614 | 0.763 | |
| Ours | 0.476 | 0.172 | 0.623 | 0.469 | 0.731 | 0.845 | |
| Ablation Section | Evaluation Criteria | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| MC-IEM | ADM | Error ↓ | Accuracy ↑ | ||||||
| 0.367 | 0.177 | 0.572 | 0.402 | 0.675 | 0.826 | ||||
| ✔ | 0.326 | 0.168 | 0.574 | 0.447 | 0.711 | 0.845 | |||
| ✔ | ✔ | 0.239 | 0.132 | 0.496 | 0.588 | 0.819 | 0.891 | ||
| Method | Error ↓ | ||
|---|---|---|---|
| DPT [50] | 0.851 | 0.875 | 2.084 |
| LeRes [51] | 0.786 | 0.739 | 1.180 |
| MIDAS [25] | 0.429 | 0.289 | 0.855 |
| Ours | 0.239 | 0.132 | 0.496 |
| Method | Error ↓ | Accuracy ↑ | |||||
|---|---|---|---|---|---|---|---|
| CLAHE [53] | 0.752 | 0.660 | 1.581 | 0.014 | 0.028 | 0.044 | |
| FUnIE-GAN [54] | 0.424 | 0.281 | 0.943 | 0.278 | 0.530 | 0.692 | |
| Water-Net [29] | 0.431 | 0.321 | 1.042 | 0.248 | 0.457 | 0.591 | |
| Ours | 0.239 | 0.132 | 0.496 | 0.588 | 0.819 | 0.891 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Zhang, S.; Yu, Z. Redefining Accuracy: Underwater Depth Estimation for Irregular Illumination Scenes. Sensors 2024, 24, 4353. https://doi.org/10.3390/s24134353
Liu T, Zhang S, Yu Z. Redefining Accuracy: Underwater Depth Estimation for Irregular Illumination Scenes. Sensors. 2024; 24(13):4353. https://doi.org/10.3390/s24134353
Chicago/Turabian StyleLiu, Tong, Sainan Zhang, and Zhibin Yu. 2024. "Redefining Accuracy: Underwater Depth Estimation for Irregular Illumination Scenes" Sensors 24, no. 13: 4353. https://doi.org/10.3390/s24134353
APA StyleLiu, T., Zhang, S., & Yu, Z. (2024). Redefining Accuracy: Underwater Depth Estimation for Irregular Illumination Scenes. Sensors, 24(13), 4353. https://doi.org/10.3390/s24134353